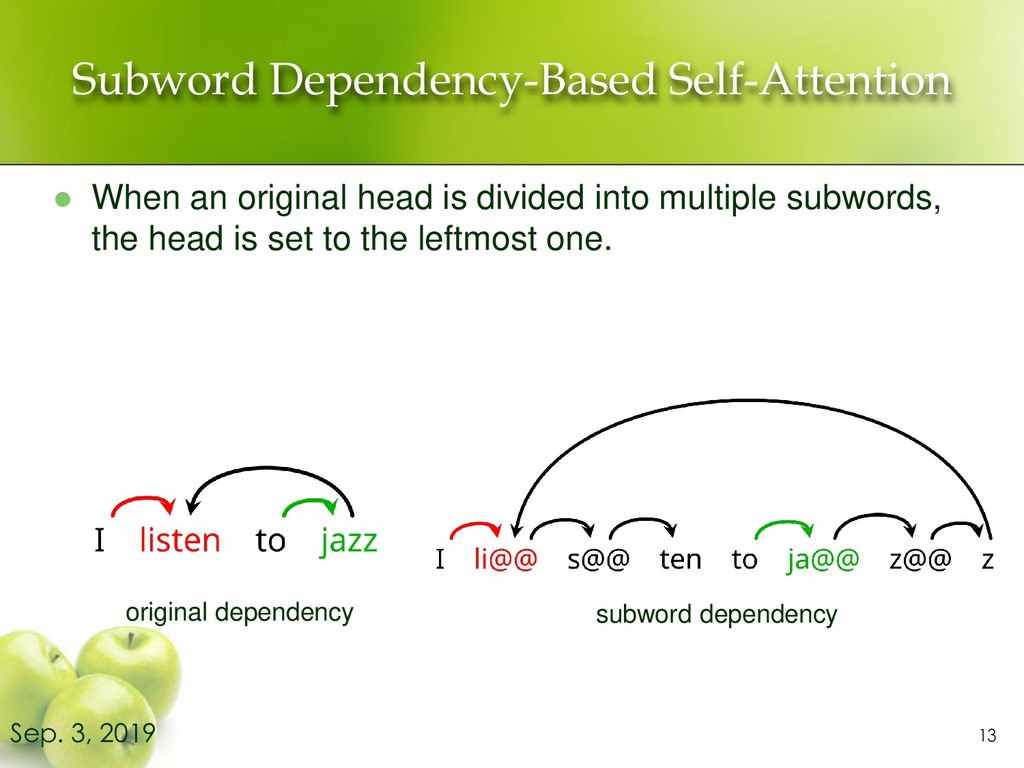
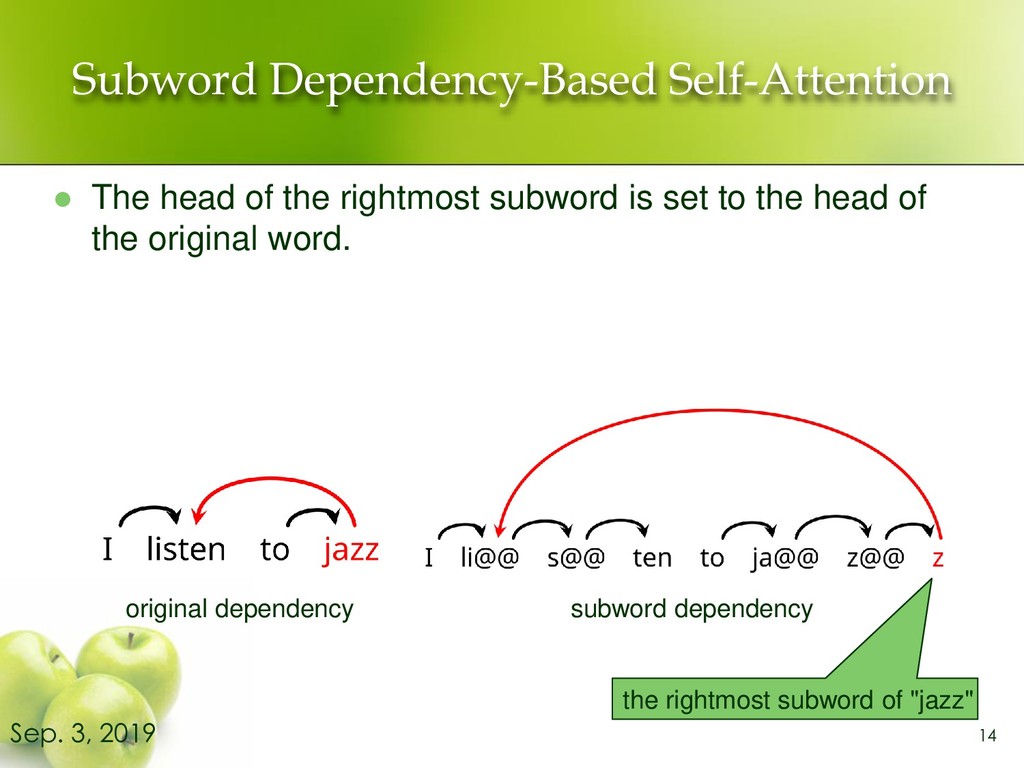
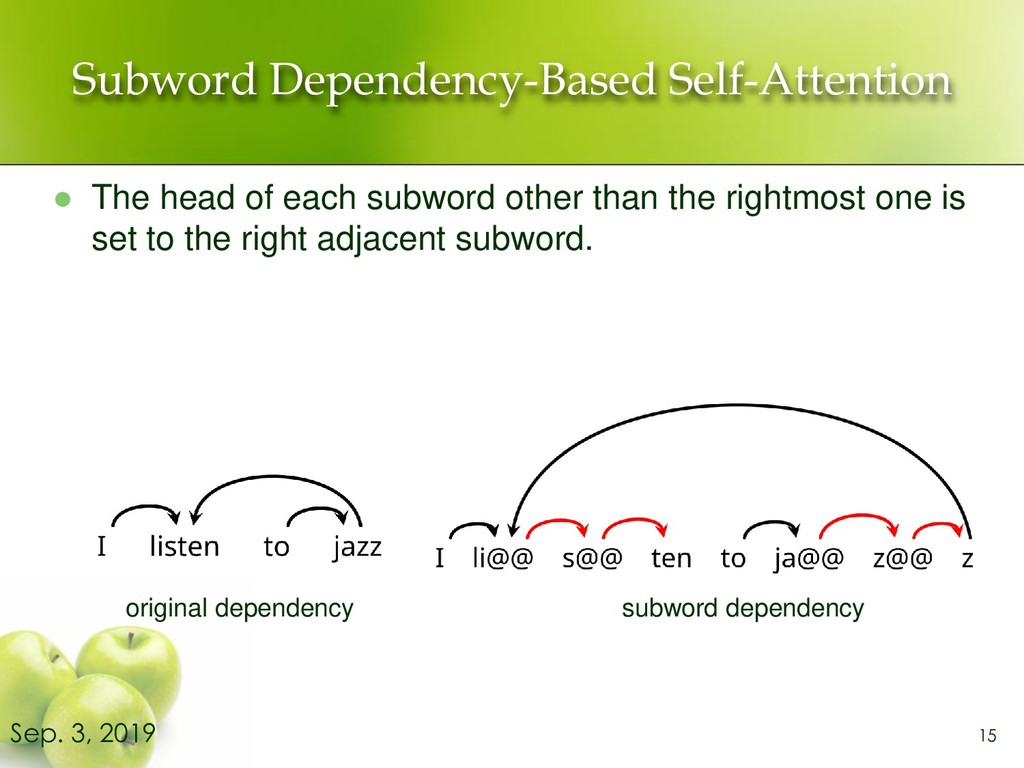
relationships between two words in the same sentence. ⚫ Encoder-decoder attention computes the strength of relationships between a source word and a target word. 3 Sep. 3, 2019 I listen to jazz I listen to jazz ➢ e.g. Self-Attention (Encoder side)
RNN <s> SH SH LR SH SH SH LR SH RR Transformer Encoder I listen to jazz ℎ1 ℎ2 ℎ3 ℎ4 Transformer Decoder <s> Ich höre jazz Ich höre jazz </s> ℎ2 ℎ1 ℎ4 ℎ3 CES Syntax-aware Encoder ℎ1 ℎ3 ℎ4 ℎ2 HES I to jazz listen listen I jazz to The model structures of Transformer NMT have not been modified.
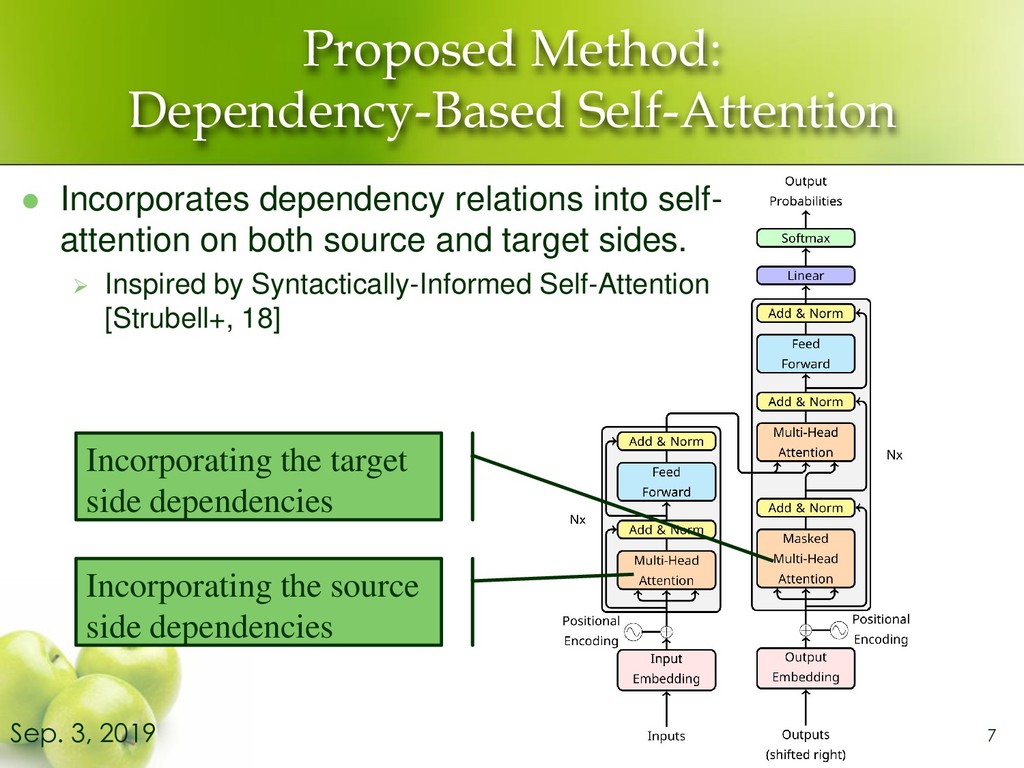
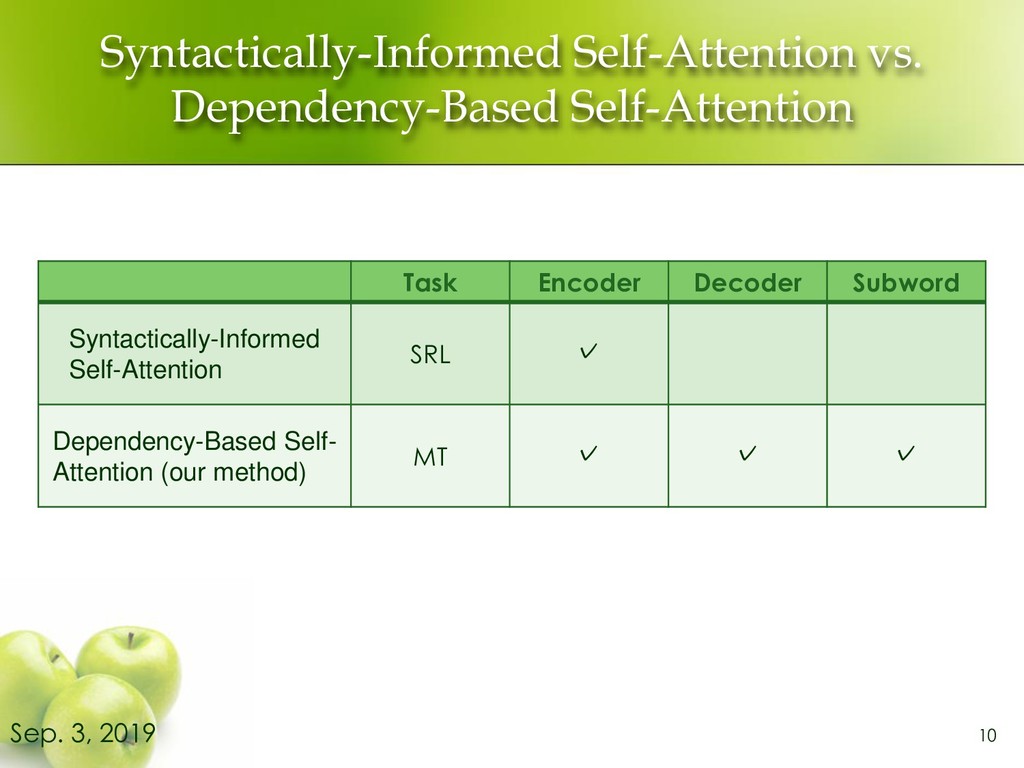
Transformer NMT ⚫ Extend self-attention to incorporate dependency relations on both source and target sides ⚫ Extend our method to work for subword sequences 6 Sep. 3, 2019
attention on both source and target sides. ➢ Inspired by Syntactically-Informed Self-Attention [Strubell+, 18] 7 Sep. 3, 2019 Incorporating the source side dependencies Incorporating the target side dependencies
giving a constraint based on the dependency relationship. 8 Sep. 3, 2019 ➢ self-attention: ➢ training data: I listen to jazz I listen to jazz I listen to jazz I listen to jazz
the biaffine transformations. ⚫ = ( + ) ➢ , : query and key representations ➢ , : parameters ⚫ loss function: = _(, ) 9 Sep. 3, 2019 ➢ self-attention: ➢ training data: I listen to jazz I listen to jazz I listen to jazz I listen to jazz , = ( = ℎ ) probability of being the head of
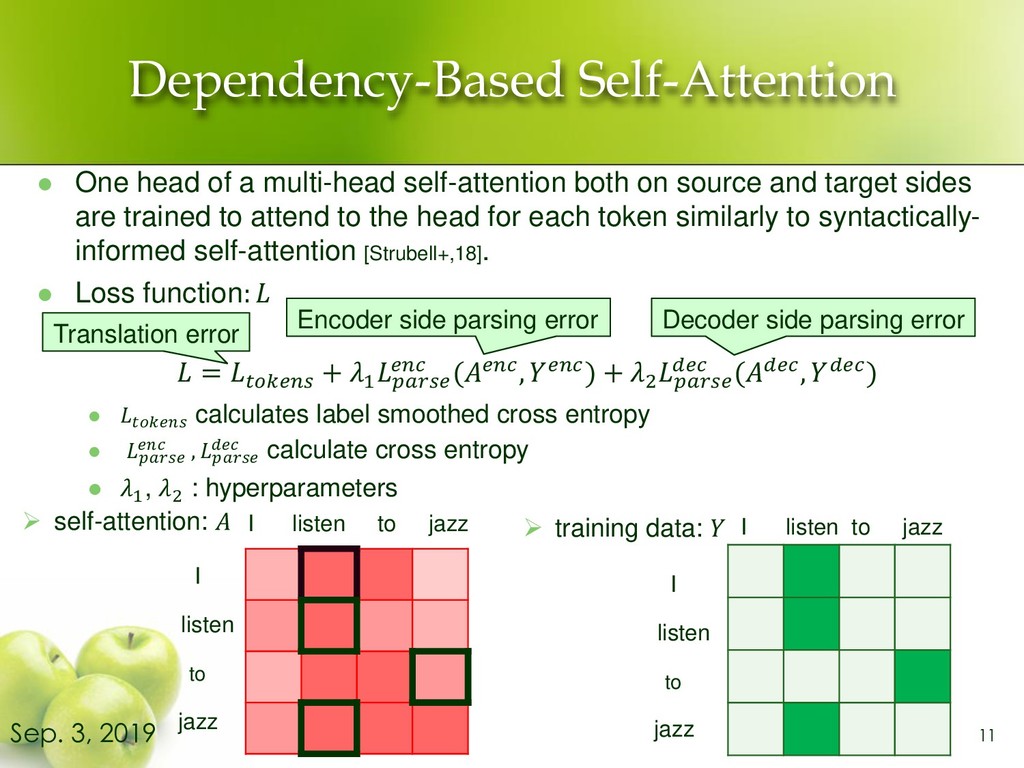
on source and target sides are trained to attend to the head for each token similarly to syntactically- informed self-attention [Strubell+,18]. ⚫ Loss function: = + 1 (, ) + 2 (, ) ⚫ calculates label smoothed cross entropy ⚫ , calculate cross entropy ⚫ 1, 2 : hyperparameters 11 Sep. 3, 2019 ➢ self-attention: ➢ training data: Encoder side parsing error Decoder side parsing error I listen to jazz I listen to jazz Translation error I listen to jazz I listen to jazz
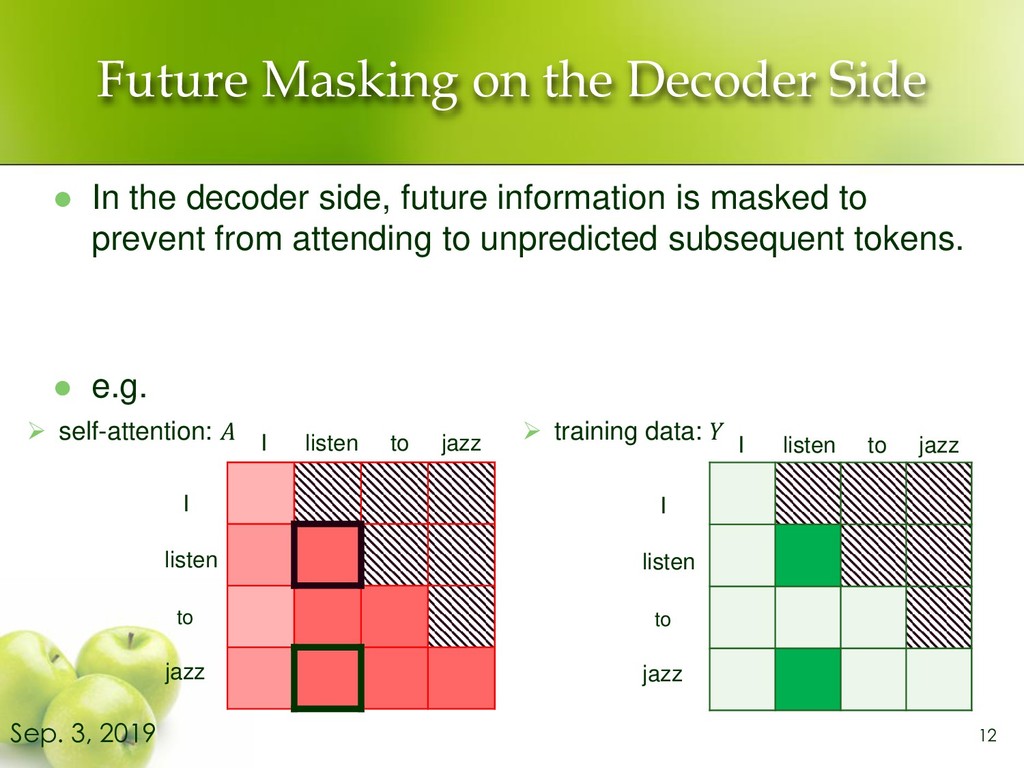
side, future information is masked to prevent from attending to unpredicted subsequent tokens. ⚫ e.g. 12 Sep. 3, 2019 ➢ self-attention: ➢ training data: I listen to jazz I listen to jazz I listen to jazz I listen to jazz
Training data: 1,198,149 sentence pairs, Test data: 1,812 sentence pairs ⚫ We used the vocabulary of 100K subword tokens based on BPE for both languages. ⚫ Tokenizer ⚫ Ja: KyTea, En: Moses Tokenizer ⚫ Dependency Parser ⚫ Ja: EDA, En: Stanford Dependencies ⚫ The dependency parsers are NOT used in decoding. 16 Sep. 3, 2019
achieved a 1.0 point gain in BLEU over the baseline Transformer model 18 Sep. 3, 2019 Model BLEU [%] Transformer 27.29 Transformer + S-DBSA(Enc) 28.05 Transformer + S-DBSA(Dec) 27.86 Transformer + S-DBSA(Enc&Dec) 28.29 (+1.0)
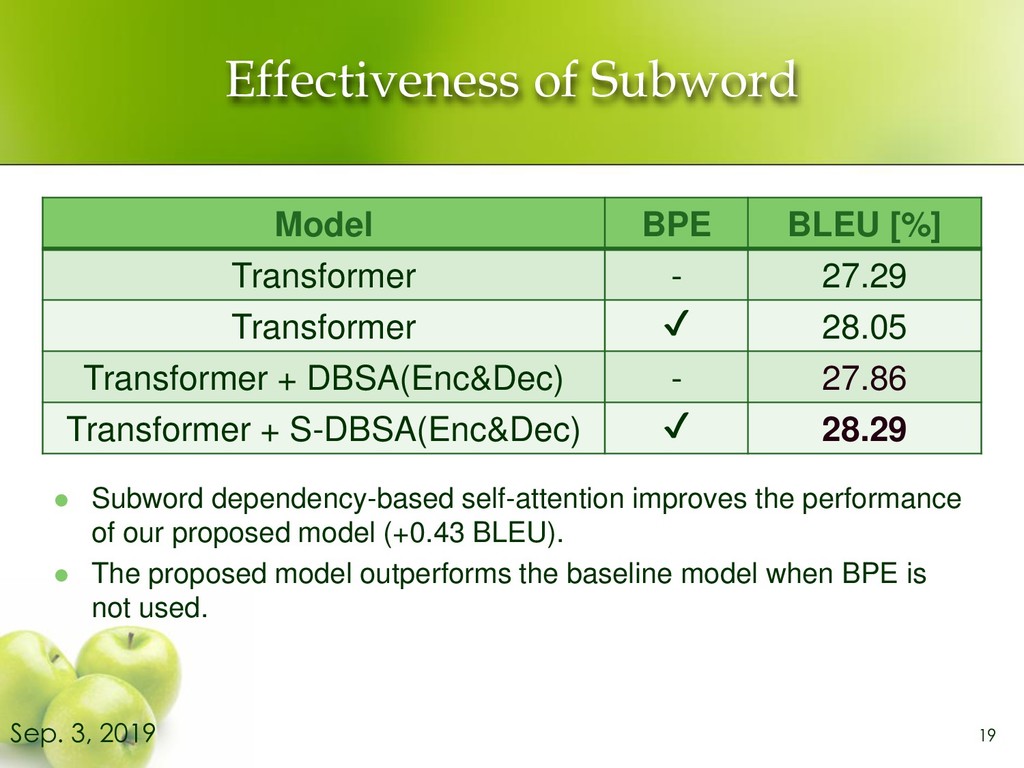
of our proposed model (+0.43 BLEU). ⚫ The proposed model outperforms the baseline model when BPE is not used. 19 Sep. 3, 2019 Model BPE BLEU [%] Transformer - 27.29 Transformer ✔ 28.05 Transformer + DBSA(Enc&Dec) - 27.86 Transformer + S-DBSA(Enc&Dec) ✔ 28.29
translation by incorporating the dependency relations into the self- attention of each encoder and decoder of Transformer. ➢ We extended dependency-based self-attention to work well for subword sequences. ⚫ Future works ➢ Explore the effectiveness of our proposed model for language pairs other than Japanese-to-English ➢ Explore the effectiveness of our proposed model for larger corpora 20 Sep. 3, 2019
{kind=link}
{kind=link}
![Transformer Model [Vaswani+, 17] ⚫ Self-attention computes the strength of](https://files.speakerdeck.com/presentations/84e9fc79fafc477a9a159449e93af347/slide_2.jpg){kind=link}
{kind=link}
![Existing Syntactic Transformer NMT [Wu+,18] 5 Sep. 3, 2019 Action](https://files.speakerdeck.com/presentations/84e9fc79fafc477a9a159449e93af347/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
![Syntactically-Informed Self-Attention [Strubell+, 18] ⚫ The self-attention is trained by](https://files.speakerdeck.com/presentations/84e9fc79fafc477a9a159449e93af347/slide_7.jpg){kind=link}
![Syntactically-Informed Self-Attention [Strubell+, 18] ⚫ Syntactically-Informed Self-Attention is calculated by](https://files.speakerdeck.com/presentations/84e9fc79fafc477a9a159449e93af347/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Experiments ⚫ Baseline: Transformer [Vaswani+, 17] ➢ Encoder: 6 layers,](https://files.speakerdeck.com/presentations/84e9fc79fafc477a9a159449e93af347/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}