O N D S LLMs know a lot. They don't know your data. 0 1 Embed the question text → vector 0 2 Search your docs nearest-neighbor chunks 0 3 Pass chunks as context to the LLM with the question 0 4 LLM answers from context not from training data
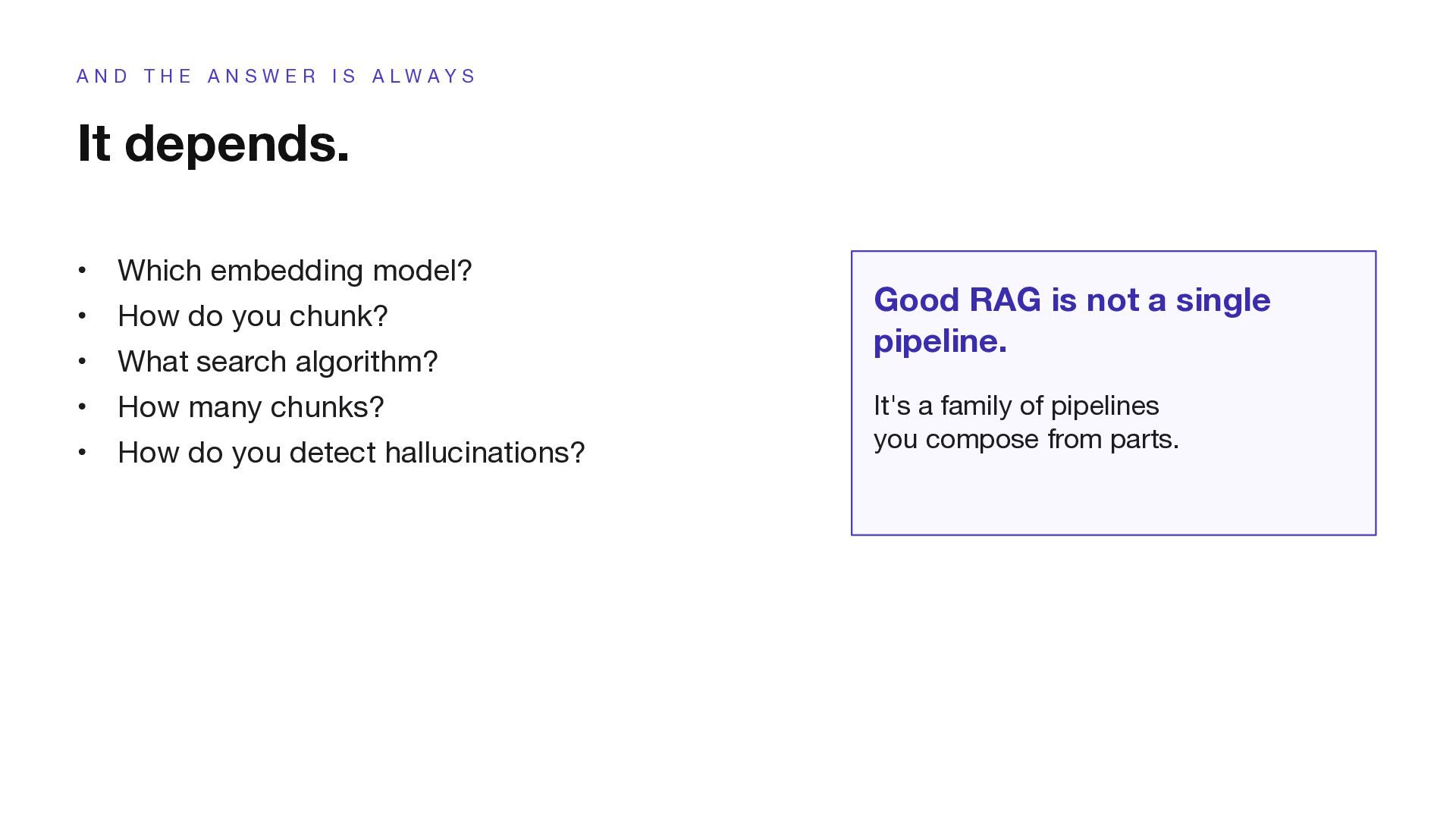
E R I S A L W A Y S It depends. • Which embedding model? • How do you chunk? • What search algorithm? • How many chunks? • How do you detect hallucinations? Good RAG is not a single pipeline. It's a family of pipelines you compose from parts.
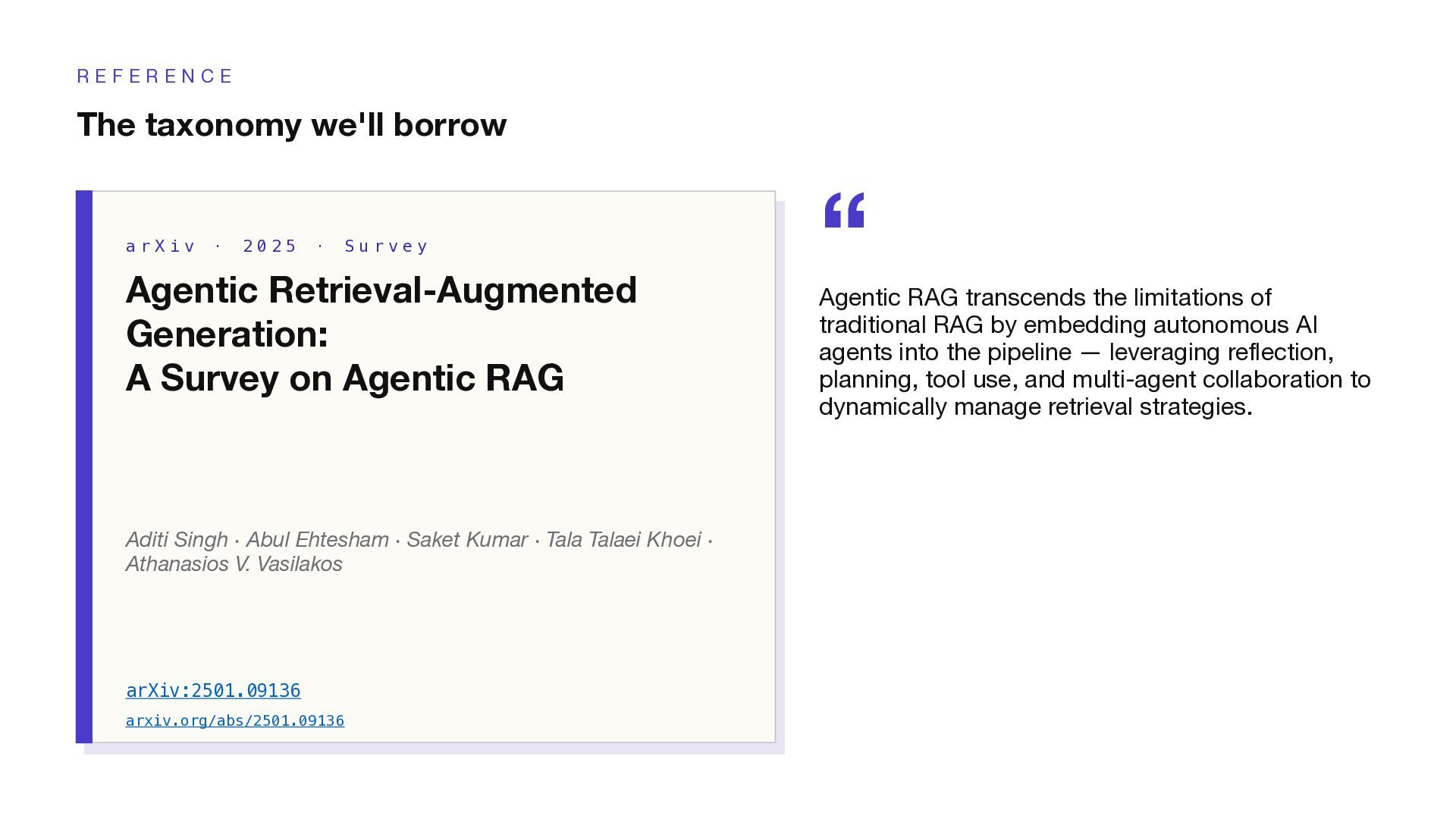
taxonomy we'll borrow a r X i v · 2 0 2 5 · S u r v e y Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG Aditi Singh · Abul Ehtesham · Saket Kumar · Tala Talaei Khoei · Athanasios V. Vasilakos arXiv:2501.09136 arxiv.org/abs/2501.09136 “ Agentic RAG transcends the limitations of traditional RAG by embedding autonomous AI agents into the pipeline — leveraging reflection, planning, tool use, and multi-agent collaboration to dynamically manage retrieval strategies.
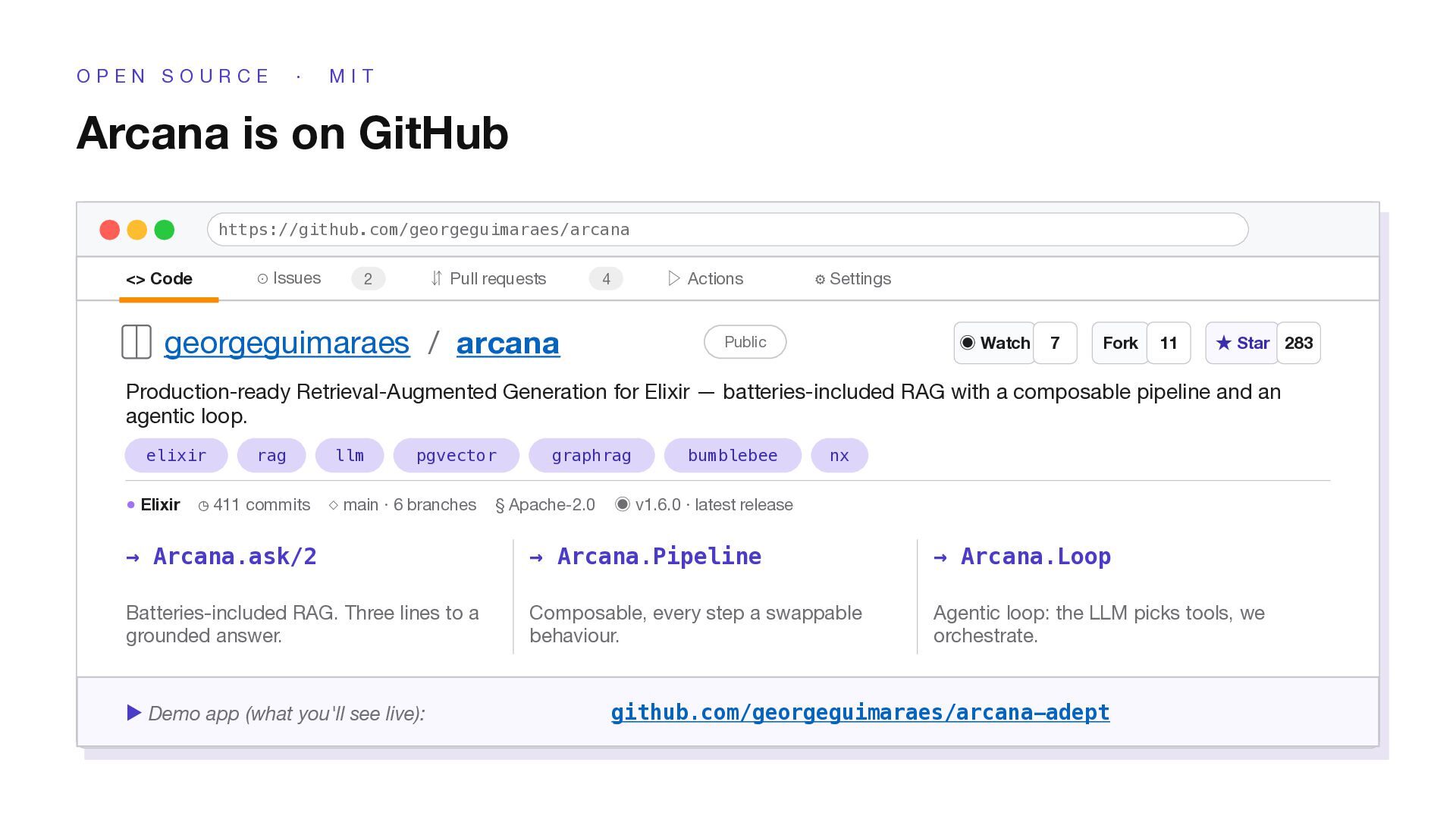
( 2 0 2 5 ) Four modes on a continuum Mode Shape When to use Arcana surface Naive embed → search → answer Demos, hello-world. Falls over on vague or compound queries. Arcana.search/2 minimal options Advanced + rewrite · hybrid · rerank Where most production RAG lives today. Arcana.ask/2 batteries-included Modular composition of optional steps You pick the composition at call time. Deterministic, tunable. Arcana.Pipeline (pipes) Agentic LLM controls the loop Open-ended synthesis across many chunks. More flexible, more expensive, new failure modes. Arcana.Loop (controller + tools)
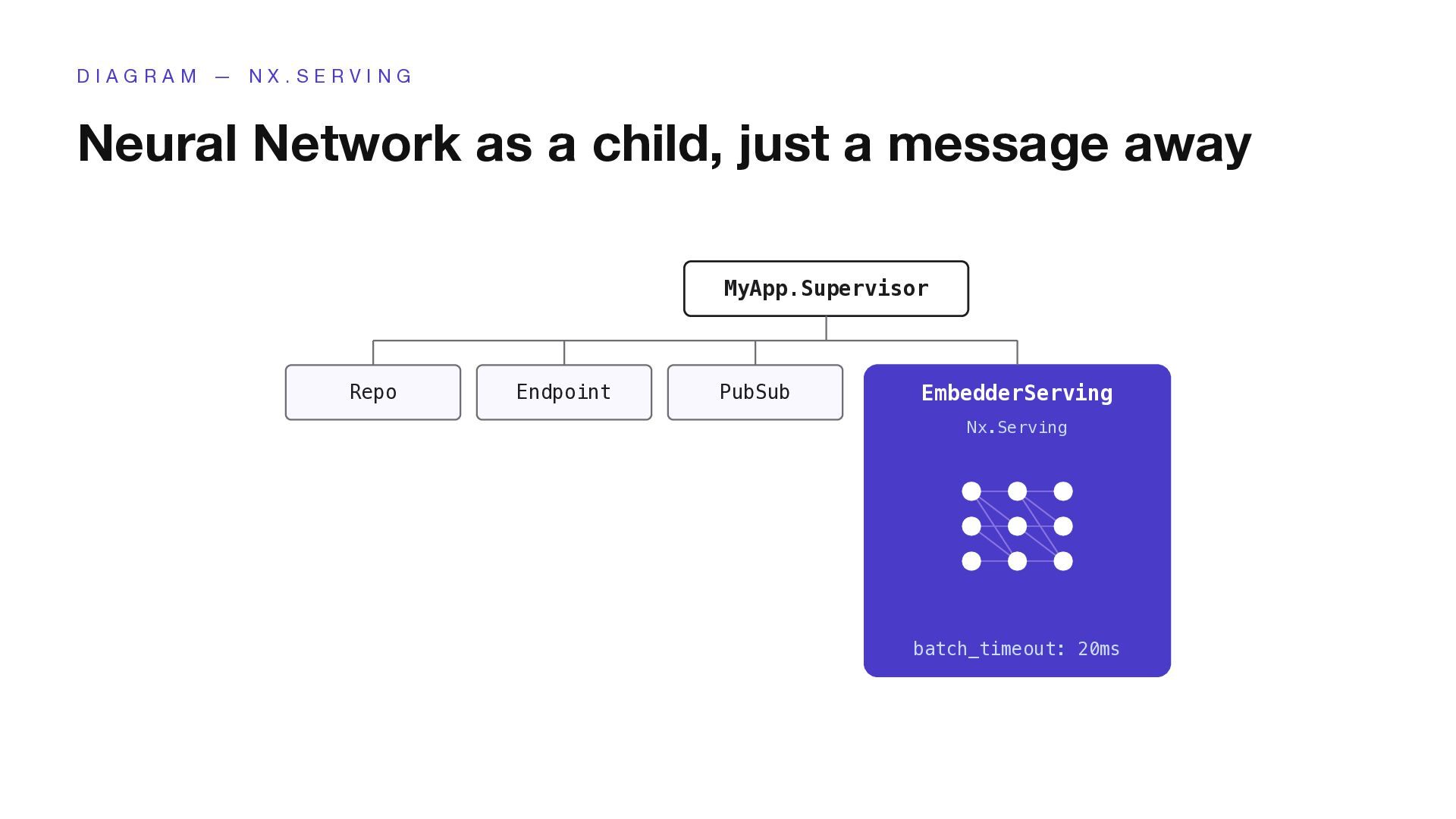
B E D D I N G ? Text in, fixed-length vector out “Cybermen originated on Mondas.” [0.0423, -0.118, 0.891, 0.0021, …, -0.234] (384 dims) A fingerprint of meaning. Two sentences with similar meanings land close to each other in this space. Most people Call OpenAI POST api.openai.com/v1/embeddings model: text-embedding-3-small Every chunk crosses the network. Every query crosses the network. Rate limits, outages, cost. Arcana default Run it locally with Bumblebee Arcana.Embedder.Local model: BAAI/bge-small-en-v1.5 (~130MB) No network hop. No rate limit. Runs on the same BEAM node as Phoenix, batched by Nx.Serving.
A behaviour, not a service defmodule Arcana.Embedder do @callback embed(text, opts) :: {:ok, [float()]} | {:error, term()} @callback embed_batch(texts, opts) :: {:ok, [[float()]]} | {:error, term()} @callback dimensions(opts) :: pos_integer() end # In your application supervisor children = [ {Arcana.Embedder.Local, model: "BAAI/bge-small-en-v1.5"} ]
C T O R · K E Y W O R D · H Y B R I D Three modes, one API Arcana.search(query, mode: :vector) # cosine on embeddings Arcana.search(query, mode: :keyword) # Postgres tsvector / tsquery Arcana.search(query, mode: :hybrid) # both, fused via RRF • Vectors live in pgvector columns next to your Ecto schemas • SELECT ... ORDER BY embedding <=> $1 LIMIT 10 (HNSW-indexed) • pgvector is the default. Swap in TurboPuffer, Pinecone, or a Req mock via the Search behaviour
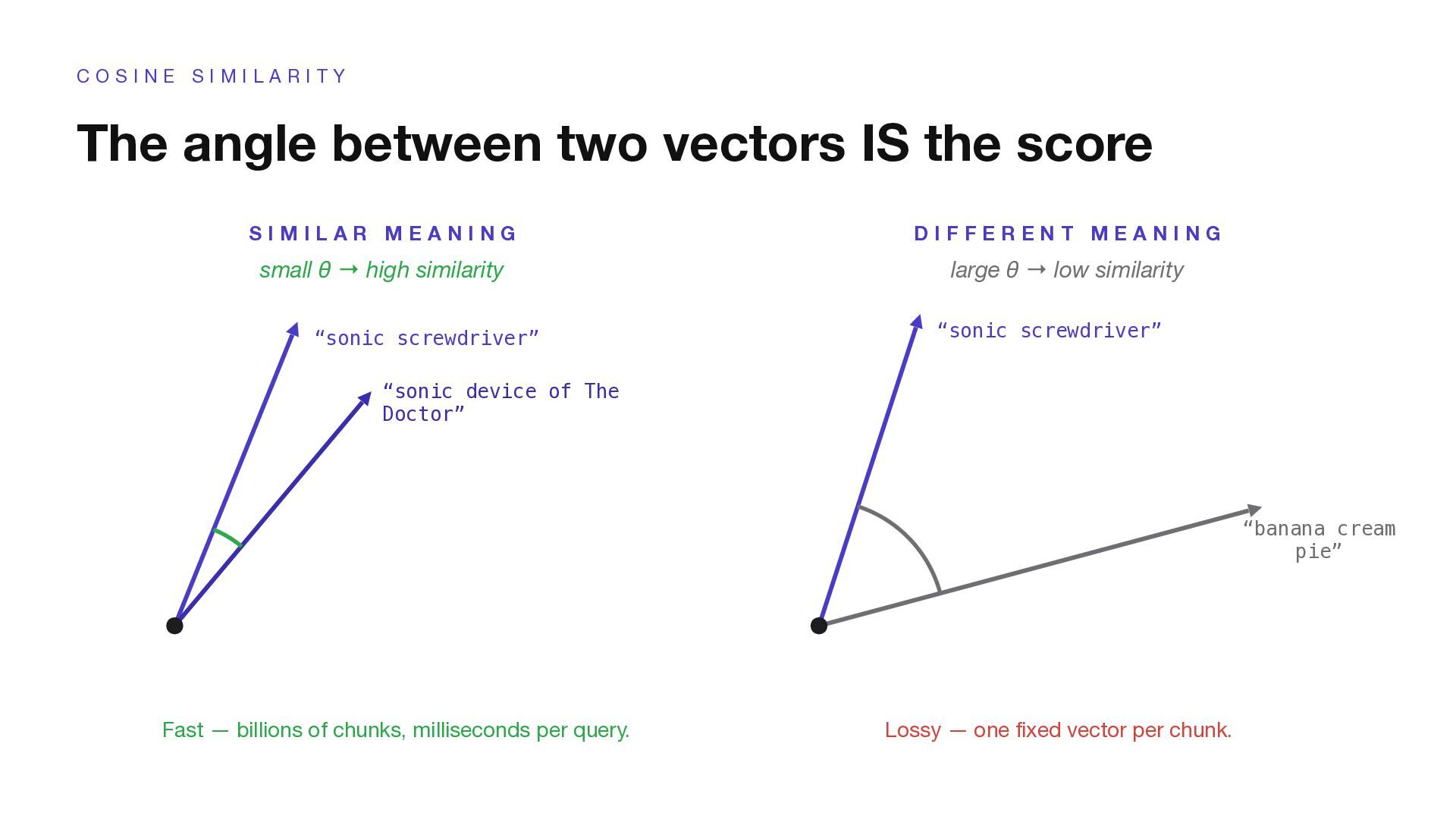
L A R I T Y The angle between two vectors IS the score S I M I L A R M E A N I N G small θ → high similarity “sonic screwdriver” “sonic device of The Doctor” D I F F E R E N T M E A N I N G large θ → low similarity “sonic screwdriver” “banana cream pie” Fast — billions of chunks, milliseconds per query. Lossy — one fixed vector per chunk.
paper behind hybrid fusion S I G I R · 2 0 0 9 · A C M Reciprocal Rank Fusion outperforms Condorcet and individual Rank Learning Methods Gordon V. Cormack · Charles L. A. Clarke · Stefan Büttcher University of Waterloo DOI:10.1145/1571941.1572114 cormack.uwaterloo.ca/cormacksigir09-rrf.pdf “ Reciprocal Rank Fusion (RRF), a simple method for combining the document rankings from multiple IR systems, consistently yields better results than any individual system, and better results than the standard method Condorcet Fuse.
R A N K F U S I O N Two ranked lists, one answer Vectors are great at meaning. Keywords are great at exact terms. Neither alone is enough. query “How did the Cybermen originate?” vector search keyword 1. Cybermen · upgrade 2. Mondas origin 3. Doctor vs. Cybus 4. Earthshock 1. Tenth Planet 2. Mondas origin 3. Spare Parts 4. Cybermen · upgrade fused (RRF) 1. Mondas origin 1/(60+2) + 1/(60+2) = 0.0323 2. Cybermen · upgrade 1/(60+1) + 1/(60+4) = 0.0320 rrf_score(doc) = Σ 1 / (k + rank_in_list_i) · k = 60 Rank-based — not score-based. A doc that shows up in both lists wins, even if neither list put it first. why k=60? empirical — from the 2009 paper. Small k lets rank-1 dominate; large k flattens rank info. k=60 keeps rank signal without letting one system bully the fusion.
C H H A S A S H A P E P R O B L E M Meaning-close ≠ question-answering “Which companions have become Time Lords?” vector search returns… • Companions of the Doctor (overview) • Time Lord biology and regeneration • The role of the companion in Classic Who • TARDIS crew across eras All topically close to the words. None answer the question. the answer is a graph walk: Romana companion → became a Time Lord (always was) Susan companion · granddaughter of the Doctor River Song companion · absorbed Time Lord DNA in utero Jenny "generated Anomaly" · biological daughter Connections live in the entities, not the words. GraphRAG (Microsoft, 2024) — build a second index alongside the vector store. Nodes and edges, not just chunks.
paper we follow for GraphRAG a r X i v · M i c r o s o f t R e s e a r c h · 2 0 2 4 From Local to Global: A Graph RAG Approach to Query-Focused Summarization Darren Edge · Ha Trinh · Newman Cheng · Joshua Bradley · Alex Chao · Apurva Mody · Steven Truitt · Dasha Metropolitansky · Robert Osazuwa Ness · Jonathan Larson arXiv:2404.16130 arxiv.org/abs/2404.16130 “ RAG fails on global questions directed at an entire corpus (“what are the main themes?”) — these are summarization tasks, not retrieval tasks. GraphRAG builds a graph index: first an entity graph, then pre- generated community summaries for groups of closely related entities.
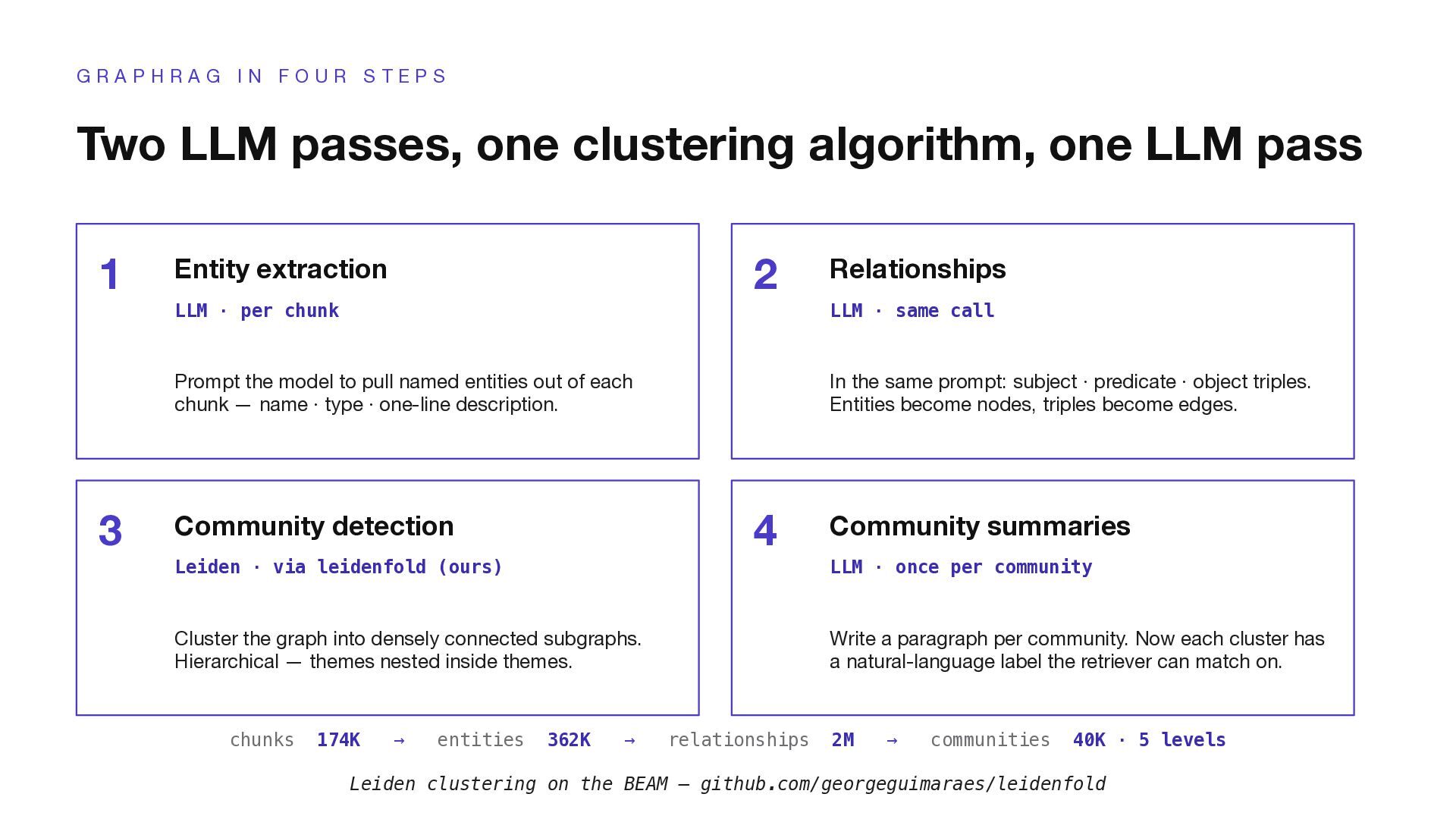
F O U R S T E P S Two LLM passes, one clustering algorithm, one LLM pass 1 Entity extraction LLM · per chunk Prompt the model to pull named entities out of each chunk — name · type · one-line description. 2 Relationships LLM · same call In the same prompt: subject · predicate · object triples. Entities become nodes, triples become edges. 3 Community detection Leiden · via leidenfold (ours) Cluster the graph into densely connected subgraphs. Hierarchical — themes nested inside themes. 4 Community summaries LLM · once per community Write a paragraph per community. Now each cluster has a natural-language label the retriever can match on. chunks 174K → entities 362K → relationships 2M → communities 40K · 5 levels Leiden clustering on the BEAM — github.com/georgeguimaraes/leidenfold
P H A C T U A L L Y L O O K S L I K E One entity, three views E N T I T Y The Doctor type: Character · appears in 847 chunks A time-travelling Time Lord from Gallifrey, travelling in the TARDIS across thirteen+ regenerations. produced by: LLM · extraction pass R E L A T I O N S H I P S · 2 1 4 e d g e s (Doctor) — pilots → (TARDIS) (Doctor) — travels with → (Romana) (Doctor) — travels with → (Susan) (Doctor) — travels with → (River Song) (Doctor) — fathered → (Jenny) (Doctor) — originates from → (Gallifrey) (Doctor) — enemy of → (The Master) … produced by: LLM · same call C O M M U N I T Y · l e v e l 3 Time Lord lineage & the TARDIS circle 38 entities · Doctor · Romana · Susan · River · Jenny · Master · Gallifrey … Time Lords from Gallifrey regenerate across lifetimes. The Doctor is the central figure — their travels bring together companions across centuries, other Time Lords (Romana, Susan), humans who become Time Lords (Jenny), and recurring antagonists (The Master). Connected by the TARDIS as a through-line, not a shared era. produced by: LLM · one pass per community L O C A L S E A R C H · A T Q U E R Y T I M E embed query → match entities → fetch chunks they appear in → RRF with vector → inject all
T A L L ? Top-k from a bi-encoder is plausible, not precise The vectors were made before the query existed. Top-10 looks reasonable; rank order inside it is mostly luck. Bi-encoder Query and chunk embed independently. Model never sees them together. query → vector chunk → vector cos(q, c) Fast · Scalable Lossy · can't say which top-10 chunk is best Cross-encoder Query and chunk go into one forward pass. Attention sees the pair. (query, chunk) → score Actually reads the chunk against the question ~10× more accurate on retrieval benchmarks One forward pass per chunk · can't run on millions
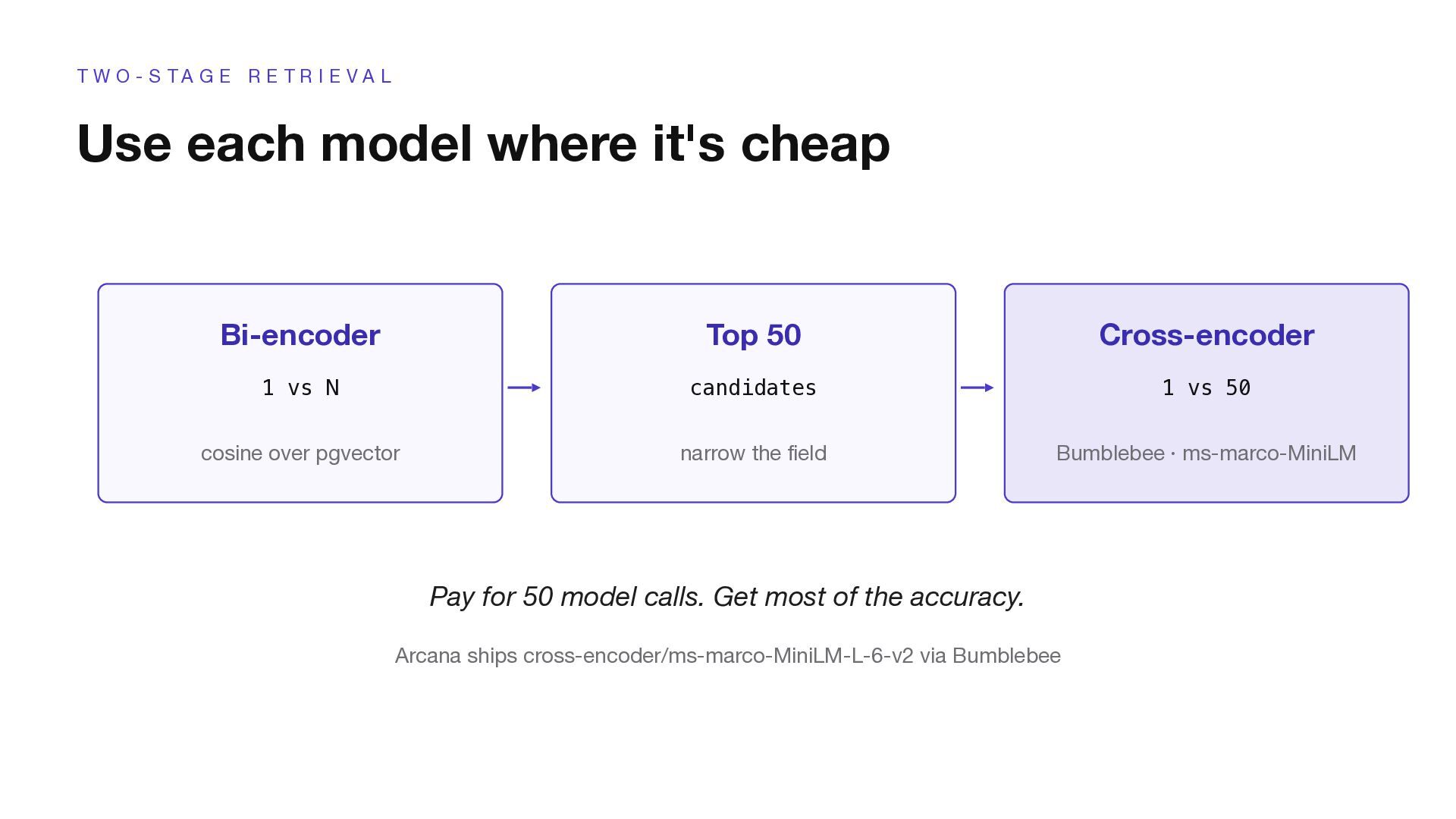
E T R I E V A L Use each model where it's cheap Bi-encoder 1 vs N cosine over pgvector Top 50 candidates narrow the field Cross-encoder 1 vs 50 Bumblebee · ms-marco-MiniLM Pay for 50 model calls. Get most of the accuracy. Arcana ships cross-encoder/ms-marco-MiniLM-L-6-v2 via Bumblebee
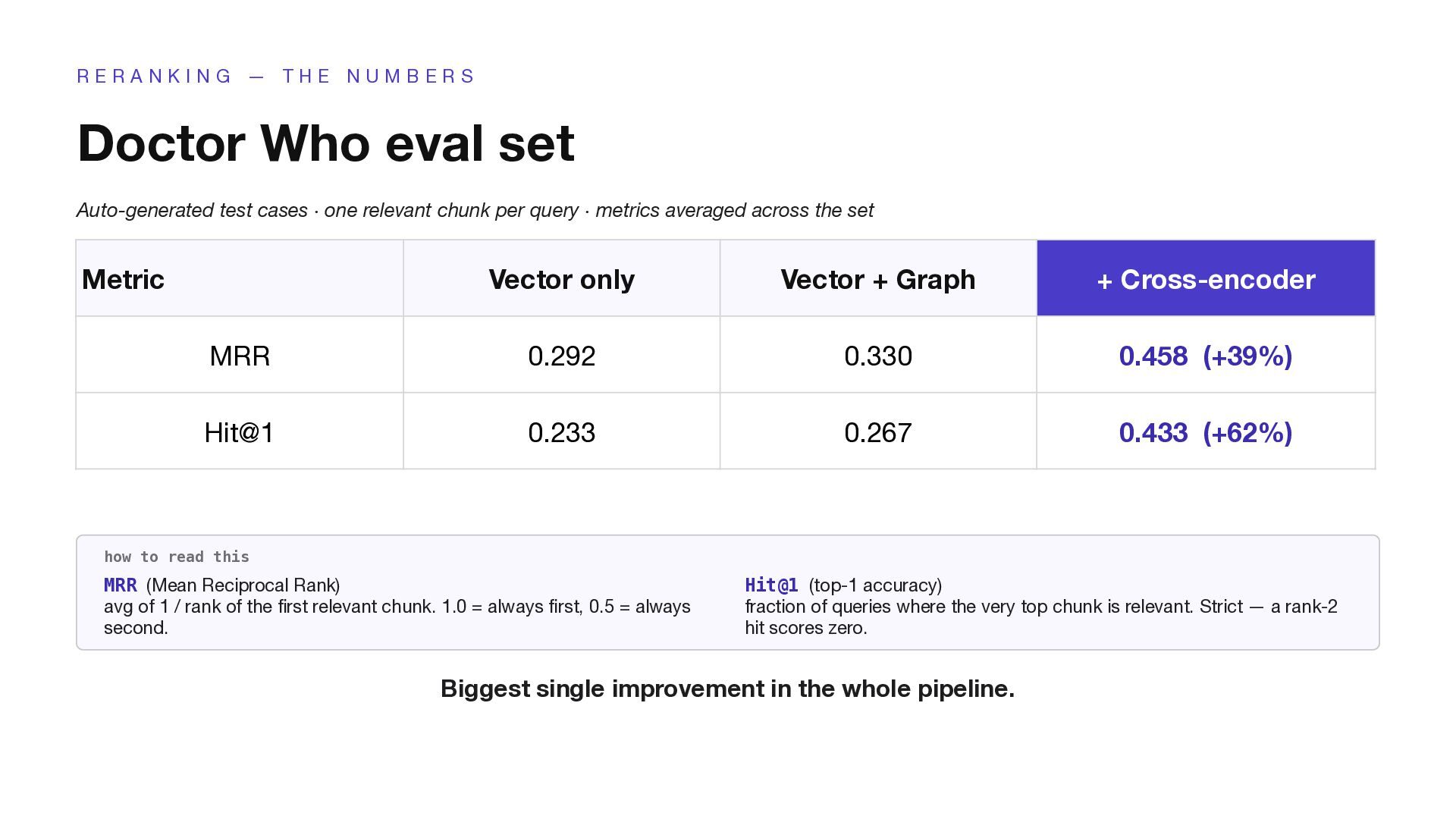
T H E N U M B E R S Doctor Who eval set Auto-generated test cases · one relevant chunk per query · metrics averaged across the set Metric Vector only Vector + Graph + Cross-encoder MRR 0.292 0.330 0.458 (+39%) Hit@1 0.233 0.267 0.433 (+62%) how to read this MRR (Mean Reciprocal Rank) avg of 1 / rank of the first relevant chunk. 1.0 = always first, 0.5 = always second. Hit@1 (top-1 accuracy) fraction of queries where the very top chunk is relevant. Strict — a rank-2 hit scores zero. Biggest single improvement in the whole pipeline.
A G R A M — A R C A N A . P I P E L I N E Every step optional. Every step a behaviour. Arcana.Pipeline.new(question, repo: Repo, llm: llm) |> Arcana.Pipeline.gate() # skip retrieval if not needed |> Arcana.Pipeline.rewrite() # clean conversational input |> Arcana.Pipeline.expand() # add synonyms and related terms |> Arcana.Pipeline.decompose() # split compound questions |> Arcana.Pipeline.search() # retrieve chunks |> Arcana.Pipeline.reason() # multi-hop: search again if thin |> Arcana.Pipeline.rerank() # cross-encoder |> Arcana.Pipeline.answer() # generate |> Arcana.Pipeline.ground() # check for hallucinations
H A T F L O W S B E T W E E N S T E P S Rewrite and retrieval — concrete a f t e r r e w r i t e ( ) user: "who's that tin-head guy again?" :question → "Cybermen origin introduction Doctor Who" user: "wait, which one had the celery?" :question → "Fifth Doctor Peter Davison celery TARDIS" user: "and after he regenerated?" :question → "Doctor regeneration aftermath — prior turn: 5th→6th" a f t e r s e a r c h ( ) :chunks = [ %Chunk{ score: 0.89, doc: "cybermen.md" text: "Cyborgs from Mondas who augmented themselves …" }, %Chunk{ score: 0.77, doc: "tenth_planet.md" text: "First appeared 1966, Hartnell's final serial …" }, %Chunk{ score: 0.71, doc: "earthshock.md" …
W O F A I L U R E M O D E S Iterate the chunks, or iterate the answer Pipeline.reason/2 retrieval-side iteration W H E N Chunks feel thin for the question W H E R E Between search() and rerank() S E E S Chunks only — never the answer D O E S Writes a follow-up query, searches again, merges L O O P S :max_iterations (default 2) F I X E S Not enough chunks e.g. "Which Time Lords betrayed the Doctor?" — first search finds the Master; reason follows up for Rassilon & the Valeyard. answer(self_correct: true) answer-side iteration W H E N After an answer is generated W H E R E After answer(), before ground() S E E S The answer AND the chunks D O E S Grounded? If no, regenerate with feedback L O O P S :max_corrections F I X E S Answer drifted from the chunks e.g. model said "the Fifth Doctor wore a red coat" — chunks don't support it. Self-correct rewrites tighter. search → reason ↻ → rerank → answer → self_correct ↻ → ground You can run neither, one, or both — all off by default.
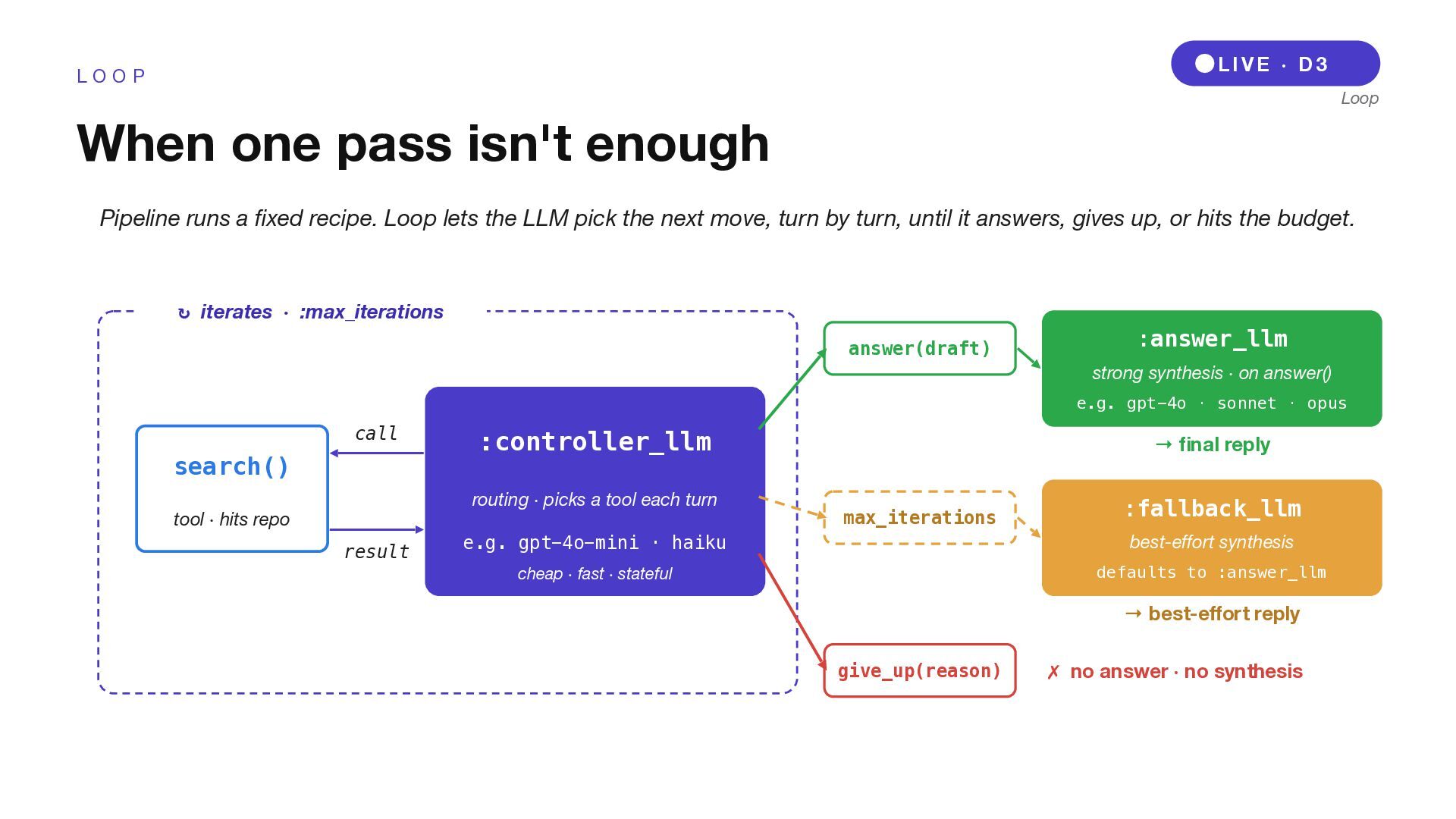
O P When one pass isn't enough Pipeline runs a fixed recipe. Loop lets the LLM pick the next move, turn by turn, until it answers, gives up, or hits the budget. ↻ iterates · :max_iterations search() tool · hits repo :controller_llm routing · picks a tool each turn e.g. gpt-4o-mini · haiku cheap · fast · stateful call result answer(draft) :answer_llm strong synthesis · on answer() e.g. gpt-4o · sonnet · opus → final reply max_iterations :fallback_llm best-effort synthesis defaults to :answer_llm → best-effort reply give_up(reason) ✗ no answer · no synthesis
D E S I G N C H O I C E S W O R T H C A L L I N G O U T Things I only learned by running it Full chunk text in tool results Previews made the controller over-search. Sending full chunks fixed it. Controller / answerer split :controller_llm cheap & fast for routing. :answer_llm strong for synthesis. 10× cost delta. Tool-call attribution Every chunk tagged with iteration + tool call that retrieved it. Grounding can point at the search.
R A D E O F F These test cases measure what Loop doesn't optimize for Same auto-generated set · each case has ONE relevant chunk · which is exactly Pipeline's sweet spot Metric Pipeline Loop Δ MRR 0.458 0.243 −47% Hit@1 0.433 0.134 −69% Loop isn't optimized for "find the one right chunk".
the model make stuff up? Hallmark (NLI) grounder: Arcana.Grounder.Hallmark • Vectara HHEM — Hughes Hallucination Evaluation Model • Given (context, answer), predicts faithful vs. hallucinated • Distilled from ModernBERT · runs locally in Bumblebee • REALLY FAST · free · no API calls • Used by Pipeline — small, fixed chunk set LLM Judge grounder: Arcana.Grounder.LLMJudge • Decomposes answer into atomic claims • Verifies each claim vs. chunks • Per-claim verdicts + chunk attribution • Used by Loop — large chunk sets https://github.com/georgeguimaraes/hallmark
O U T P U T S H A P E Every answer gets a score and spans ctx |> Arcana.Pipeline.ground(grounder: Arcana.Grounder.Hallmark) |> Map.get(:grounding) # => %{ # score: 0.92, # faithful_spans: [...], # hallucinated_spans: [...] # } faithful span hallucinated span
paper behind the eval metrics E A C L · 2 0 2 4 · A C L A n t h o l o g y Ragas: Automated Evaluation of Retrieval Augmented Generation Shahul Es · Jithin James · Luis Espinosa-Anke · Steven Schockaert · Exploding Gradients / Cardiff University arXiv:2309.15217 arxiv.org/abs/2309.15217 “ Evaluating a RAG pipeline has several dimensions: whether retrieval finds the right passages, whether the LLM uses them faithfully, and whether the final answer is relevant. RAGAS is a suite of reference- free metrics for each of these — no ground-truth annotations required.
What Arcana.Evaluation measures R E T R I E V A L Compare search results to the expected chunk Hit@K Did a relevant chunk land in the top K? Recall@K Fraction of relevant chunks found in top K. Precision@K Fraction of top K that are relevant. MRR Mean of 1 / rank of the first relevant chunk. K ∈ {1, 3, 5, 10} A N S W E R Q U A L I T Y LLM-as-judge, 0–10 scores Faithfulness Every claim in the answer grounded in retrieved chunks? No reference_answer needed — catches hallucinations. Correctness Same facts as the reference_answer? Catches wrong answers that happen to be faithful to the retrieved chunks.
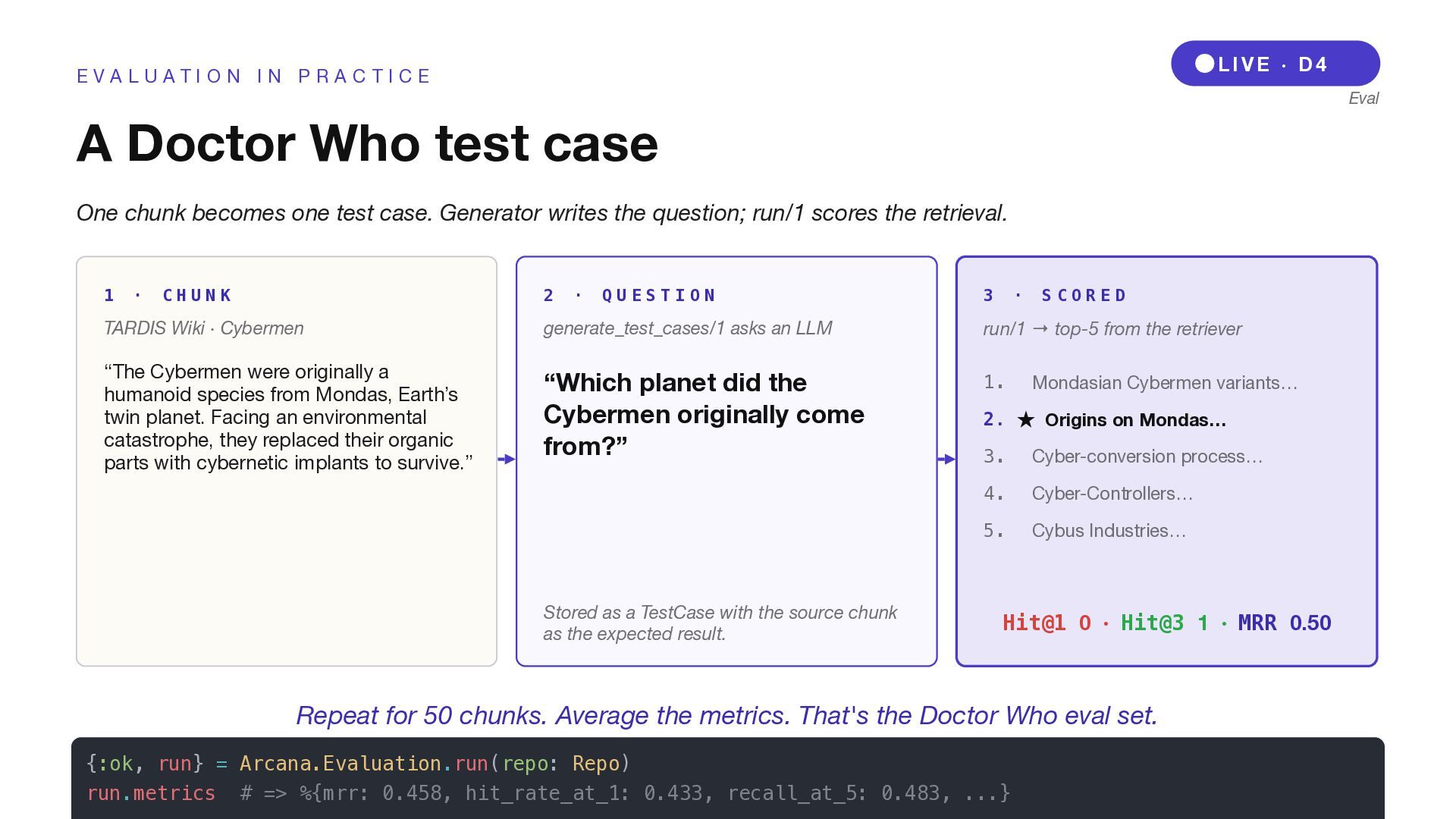
A L U A T I O N I N P R A C T I C E A Doctor Who test case One chunk becomes one test case. Generator writes the question; run/1 scores the retrieval. 1 · C H U N K TARDIS Wiki · Cybermen “The Cybermen were originally a humanoid species from Mondas, Earth’s twin planet. Facing an environmental catastrophe, they replaced their organic parts with cybernetic implants to survive.” 2 · Q U E S T I O N generate_test_cases/1 asks an LLM “Which planet did the Cybermen originally come from?” Stored as a TestCase with the source chunk as the expected result. 3 · S C O R E D run/1 → top-5 from the retriever 1. Mondasian Cybermen variants… 2. ˒ Origins on Mondas… 3. Cyber-conversion process… 4. Cyber-Controllers… 5. Cybus Industries… Hit@1 0 · Hit@3 1 · MRR 0.50 Repeat for 50 chunks. Average the metrics. That's the Doctor Who eval set. {:ok, run} = Arcana.Evaluation.run(repo: Repo) run.metrics # => %{mrr: 0.458, hit_rate_at_1: 0.433, recall_at_5: 0.483, ...}
O U S T I T C H E D T O G E T H E R S E R V I C E S . Today, you don't leave the BEAM. Nx.Serving and Bumblebee local embeddings + automatic batching pgvector vectors in your existing Postgres ReqLLM tool-calling primitive for agentic loops supervision · OTP fault tolerance you already understand
crash! T R Y I T $ mix igniter.install arcana S T A R github.com/georgeguimaraes/arcana D E M O A P P github.com/georgeguimaraes/arcana-adept S A Y H I @georgeguimaraes · find me in the hallway George Guimarães · Member of Technical Staff @ new-gen.ai · ElixirConf EU 2026
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}