Share
ICLR'26論文の紹介
- ViTにおいて[CLS]とpatchは役割が異なるが同様に処理される - 学習時にLayerNormがそれらを暗黙的に分離していることを指摘 - [CLS]とpatchの処理を部分的に分けるアーキテクチャを提案 - Patch表現が改善し下流タスクの性能が向上
![AI Community 内田 祐介 GOドライブ株式会社 Revisiting [CLS] and Patch Token](https://files.speakerdeck.com/presentations/95642d4ecac54666a1586533b178fe03/slide_0.jpg){kind=link}
![2 ▪ViTにおいて[CLS]とpatchは役割が異なるが同様に処理される ▪学習時にLayerNormがそれらを暗黙的に分離していることを指摘 ▪[CLS]とpatchの処理を部分的に分けるアーキテクチャを提案 ▪Patch表現が改善し下流タスクの性能が向上 サマリ A. Marouani et al.,](https://files.speakerdeck.com/presentations/95642d4ecac54666a1586533b178fe03/slide_1.jpg){kind=link}
![3 ▪入力をパッチ分割し埋め込み、[CLS] tokenを付与しencoderに入力 ▪[CLS] tokenに対応する出力で分類 ViTにおける [CLS] token A. Dosovitskiy](https://files.speakerdeck.com/presentations/95642d4ecac54666a1586533b178fe03/slide_2.jpg){kind=link}
![4 ▪現論文ではオリジナルのTransformerに合わせ [CLS] tokenベースだ がGAPとの比較も実施 ▪最適なLRが異なり、調整すれば同等の精度という結論 ViTにおける [CLS] token vs.](https://files.speakerdeck.com/presentations/95642d4ecac54666a1586533b178fe03/slide_3.jpg){kind=link}
![5 ▪[CLS] token ▪ViT, DeiT, BEiT, CLIP, DINOシリーズ, MAE ▪GAP](https://files.speakerdeck.com/presentations/95642d4ecac54666a1586533b178fe03/slide_4.jpg){kind=link}
![6 ▪Attention前のLayerNormで [CLS]-patch間の類似度が大幅に低下 ▪モデル内部で [CLS] とpatchが暗黙的に分離されている 観測:[CLS] とpatchが分離されて処理されている DINOv2 ViT-L](https://files.speakerdeck.com/presentations/95642d4ecac54666a1586533b178fe03/slide_5.jpg){kind=link}
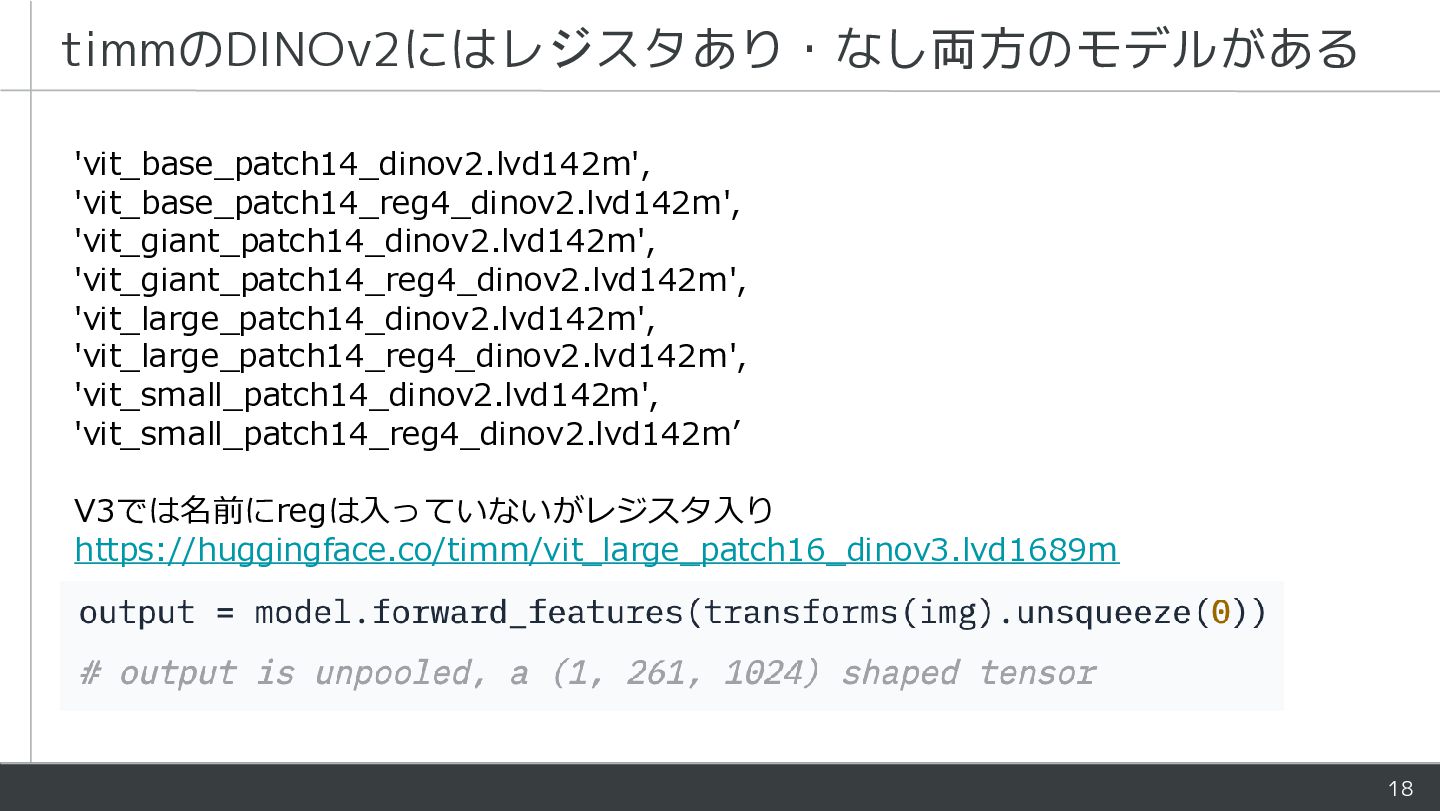
![7 レジスタありの場合、[CLS], レジスタ, patchは全て分離されているのか? 他のモデルやレジスタありでも同様](https://files.speakerdeck.com/presentations/95642d4ecac54666a1586533b178fe03/slide_6.jpg){kind=link}
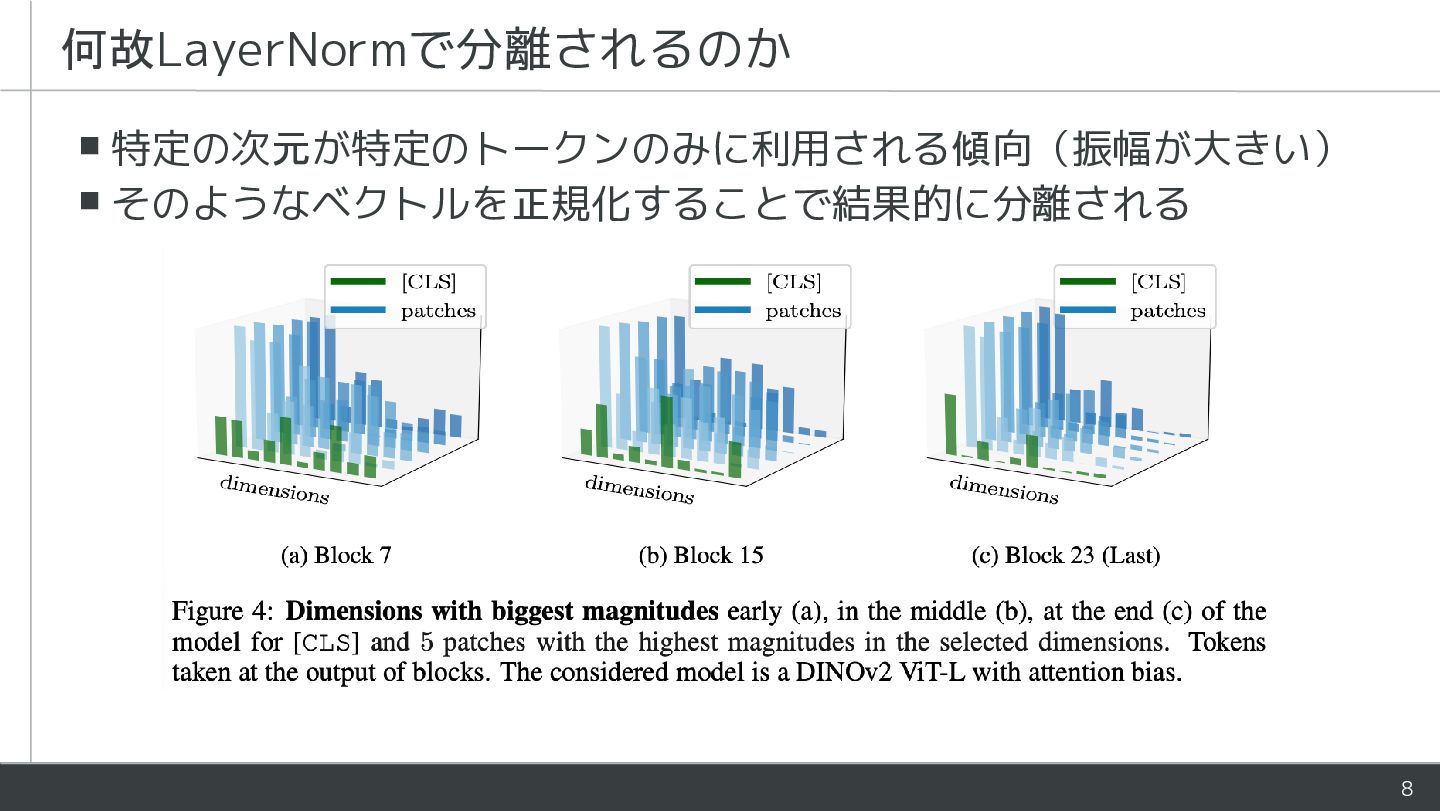{kind=link}
![9 ▪モデルは両者を内部で分離するために余計な表現能力を使っている ▪この問題を解決するため本論文は [CLS] とpatchをダイレクトに 分離して処理する方法を提案 提案手法](https://files.speakerdeck.com/presentations/95642d4ecac54666a1586533b178fe03/slide_8.jpg){kind=link}
{kind=link}
![11 ▪正規化レイヤの分離だけでも [CLS] - patchが分離されている ▪パラメータは0.05%増 ▪画像分類の精度が若干低下、seg、depthが改善 ▪分離することで [CLS] の大域情報が取りづらくなった?](https://files.speakerdeck.com/presentations/95642d4ecac54666a1586533b178fe03/slide_10.jpg){kind=link}
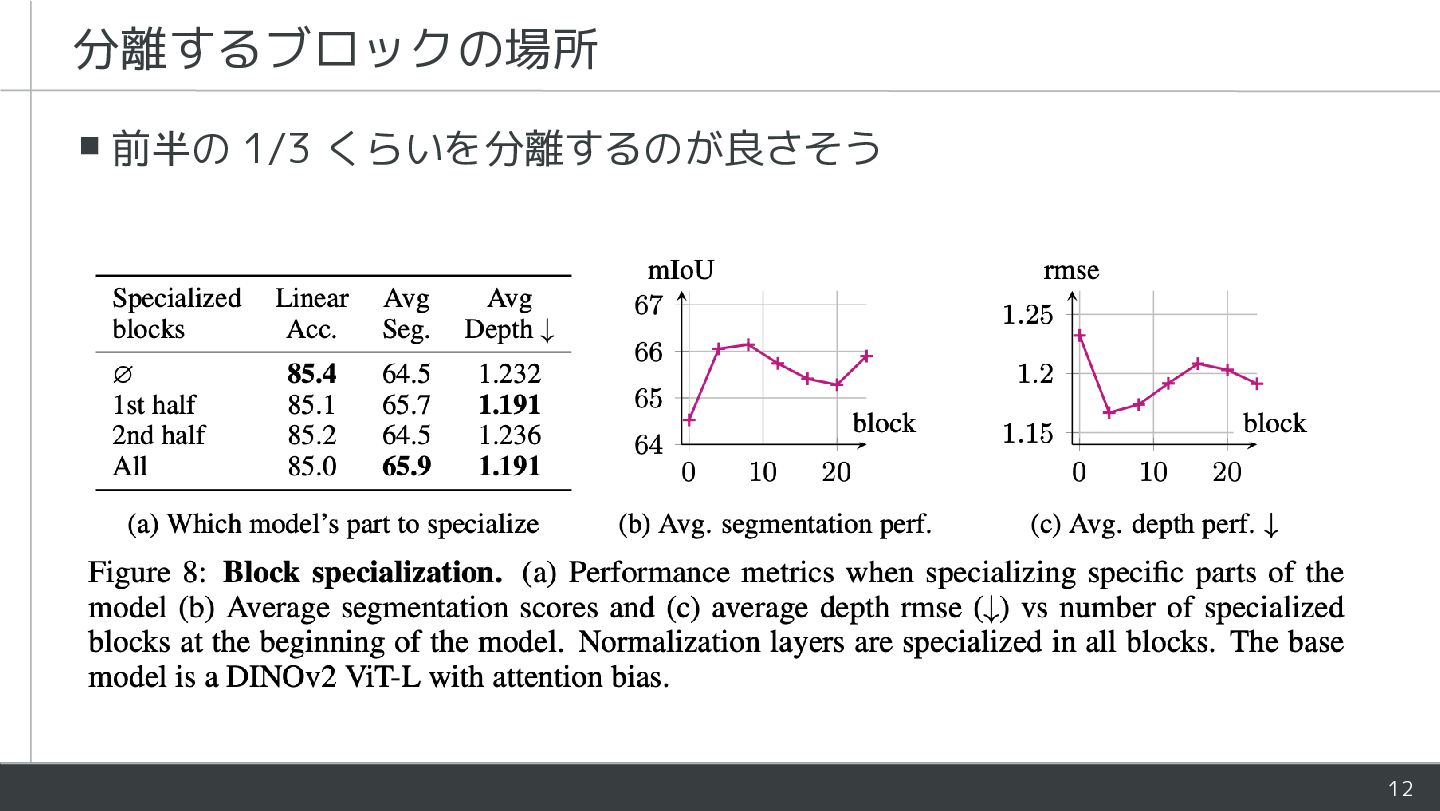{kind=link}
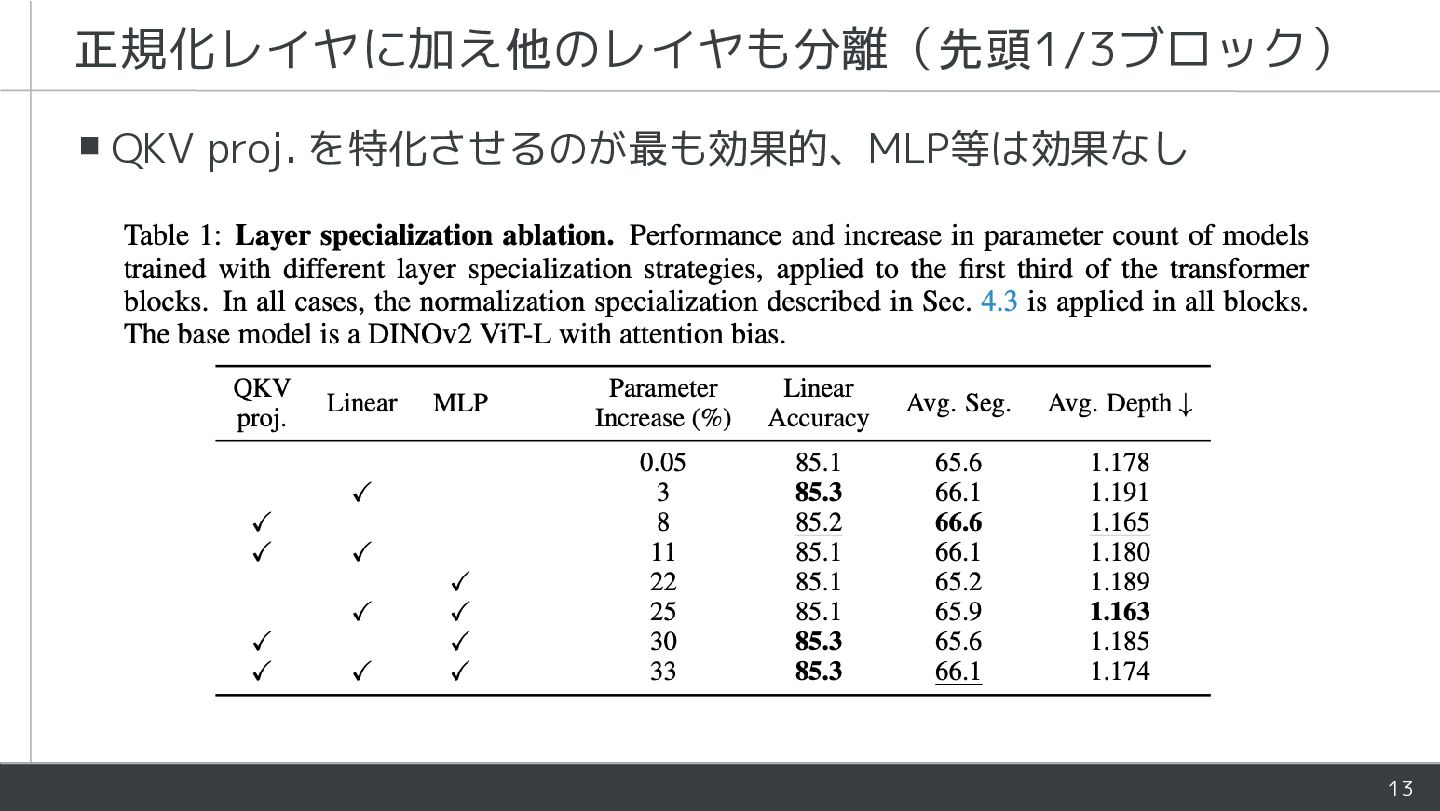{kind=link}
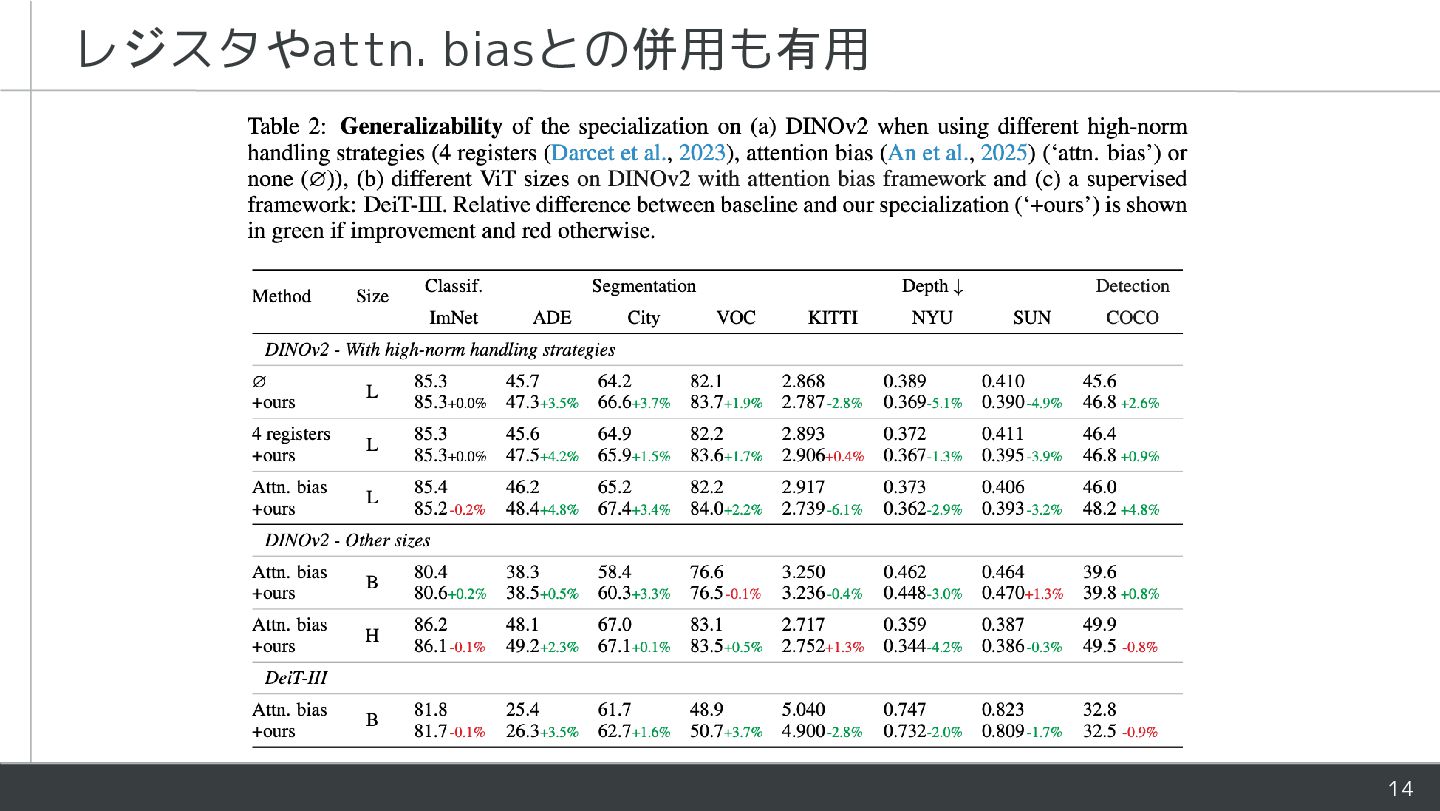{kind=link}
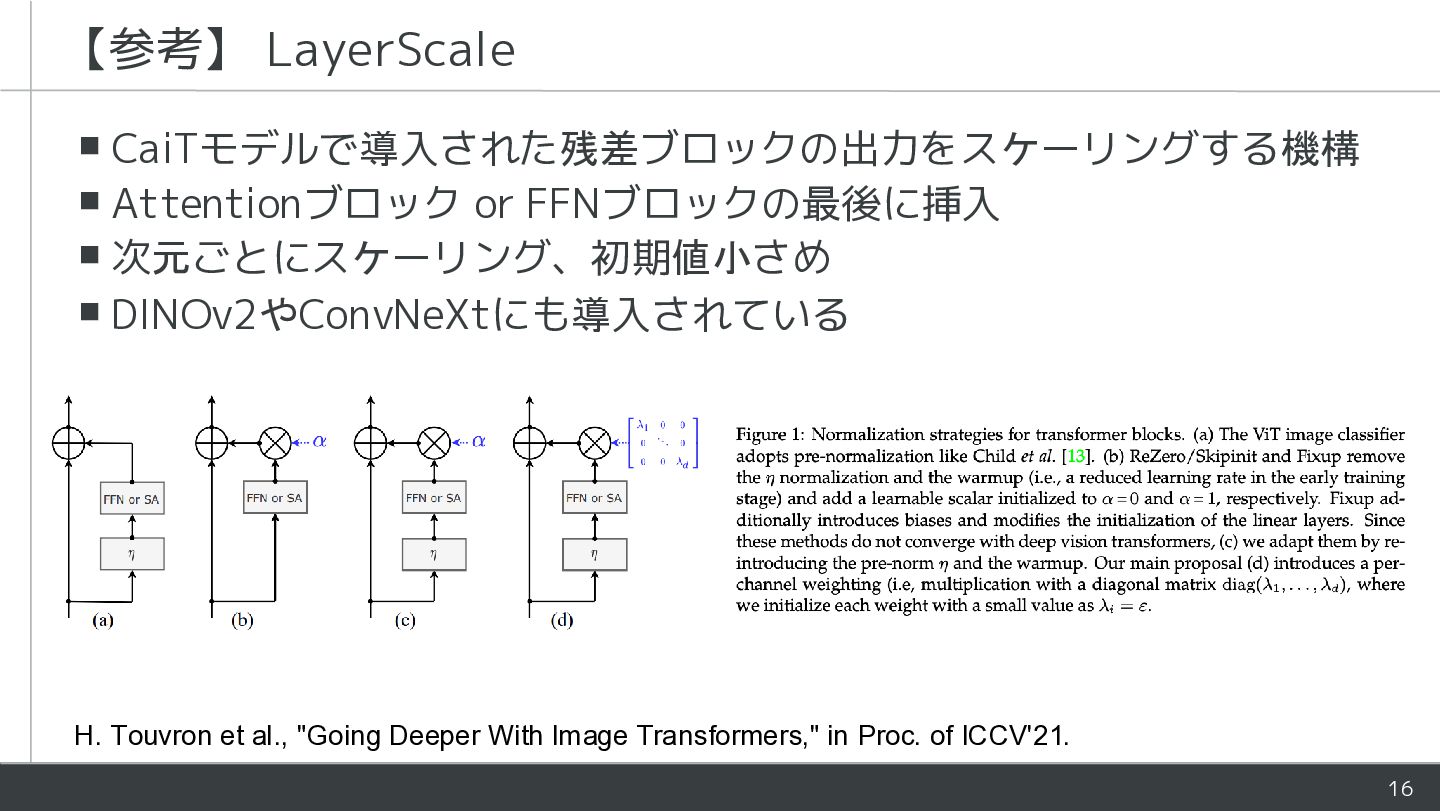
![15 ▪正規化層とQKVの処理を [CLS] とpatchで分離して性能向上! ▪もともと [CLS] vs. GAPに興味があった ▪Transformer内部でFFNとかだけ分離したモデルを作ったことも ▪本論文での実験は全てバックボーンをフリーズしたlinear](https://files.speakerdeck.com/presentations/95642d4ecac54666a1586533b178fe03/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}