Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
60分で学ぶクラウドとSRE・サービス運用 / GeekCAMPAcademia 2026-05
Search
Hatena
May 22, 2026
Technology
91
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
60分で学ぶクラウドとSRE・サービス運用 / GeekCAMPAcademia 2026-05
Hatena
May 22, 2026
More Decks by Hatena
See All by Hatena
エンジニアリング マネージャーの育成と評価軸の考え方
hatena
0
630
Perlブートキャンプ
hatena
0
5.2k
はてなサマーインターンシップ2025 Web API 講義資料
hatena
0
1.1k
はてなサマーインターンシップ2025 フロントエンド 講義資料
hatena
21
11k
はてなサマーインターンシップ2025 コンテナ + Kubernetesハンズオン 講義資料
hatena
0
760
はてなサマーインターンシップ2025 クラウドと運用 講義資料
hatena
0
810
はてなサマーインターンシップ2025 RDBMSの基礎 講義資料
hatena
0
870
はてなサマーインターンシップ2025 セキュリティ 講義資料
hatena
0
800
はてなサマーインターンシップ2025 AIエージェント活用 講義資料
hatena
1
2.7k
Other Decks in Technology
See All in Technology
DatabricksにおけるMCPソリューション
taka_aki
1
280
Terraform共通モジュールをチーム横断で“変えられる”運用へ ― リリースと適用の分離
kekke_n
1
3.4k
そのドキュメント、自動化しませんか?
yuksew
1
300
AI Driven AI Governance
pict3
0
490
オブザーバビリティ、本当に活用できてる? 〜API連携×生成AIで成熟度を自動評価〜
dmmsre
1
3.6k
Type-safe IaC for Dart
coborinai
0
160
第67回コンピュータビジョン勉強会CVPR2026読会前編
tsukamotokenji
0
150
ボーイスカウトルールでメモリやスキルを改善しよう
azukiazusa1
4
1.5k
タスクの複雑さでモデルを選ぶ ── Thompson Samplingで動かす“トークン/コスト最適化
satohy0323
0
570
「最後に責任を取るのはチーム」— 人間のPRレビューを最小化してアップデートしたメンタルモデル
jnishime_dresscode
0
920
ゴールデンパスは敷いただけでは道にならない ─ 企画部門のエンジニアが技術標準を事業価値に変えるまで
mhrtech
1
230
Claude Code公式skillで 自分の仕事を少しずつ手放そう!(Claude Code開発ノウハウ大公開スペシャル by クラスメソッド)
kaym
1
500
Featured
See All Featured
GraphQLとの向き合い方2022年版
quramy
50
15k
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
2
340
WCS-LA-2024
lcolladotor
0
710
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.4k
Typedesign – Prime Four
hannesfritz
42
3.1k
My Coaching Mixtape
mlcsv
0
170
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
エンジニアに許された特別な時間の終わり
watany
108
250k
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
390
Odyssey Design
rkendrick25
PRO
2
730
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.4k
Transcript
60分で学ぶ クラウドとSRE・サービス運 用 技育CAMPアカデミア masayosu | 株式会社はてな SRE
毎日、数百万人が使うサービスを支えている。 リリース直後、エラーレートが急上昇—— 原因をすばやく特定できるか? “ ”
はてなid: masayosu 所属: 株式会社はてな 組織基盤・開発本部 プラットフォーム部 サービスプラットフォームチーム SRE 担当業務: クラウドインフラ設計・運用、IaC
好きなAWSサービス: EKS 趣味: ゲーム、登山 ▹ ▹ ▹ ▹ ▹ 自己紹介
1. クラウドコンピューティング概論 2. ⾼可⽤性を実現するクラウド構成 3. Infrastructure as Code と⾃動化 4.
モニタリングとオブザーバビリティ 5. DevOps/SRE⼊⾨ 今日話すこと
クラウドコンピューティング概論 01 CHAPTER 1
IaaS / PaaS / SaaS の 違いと責任分界点
モデル 提供内容 (例) 利⽤者の管理範囲 メリット / デメリット IaaS 仮想マシン、ストレージ、ネットワーク OS〜アプリまで全て⾃分で管理
⾃由度↑ / △運⽤負荷↑ PaaS ランタイム / ミドルウェア / フレーム ワーク アプリケーションとデータのみ管 理 運⽤負荷↓ / △カスタマイズ性↓ SaaS 完全マネージドアプリケーション ユーザーデータと利⽤設定のみ管 理 ほぼ⼿間要らず / ベンダー依存度 ↑ モデル定義と特徴
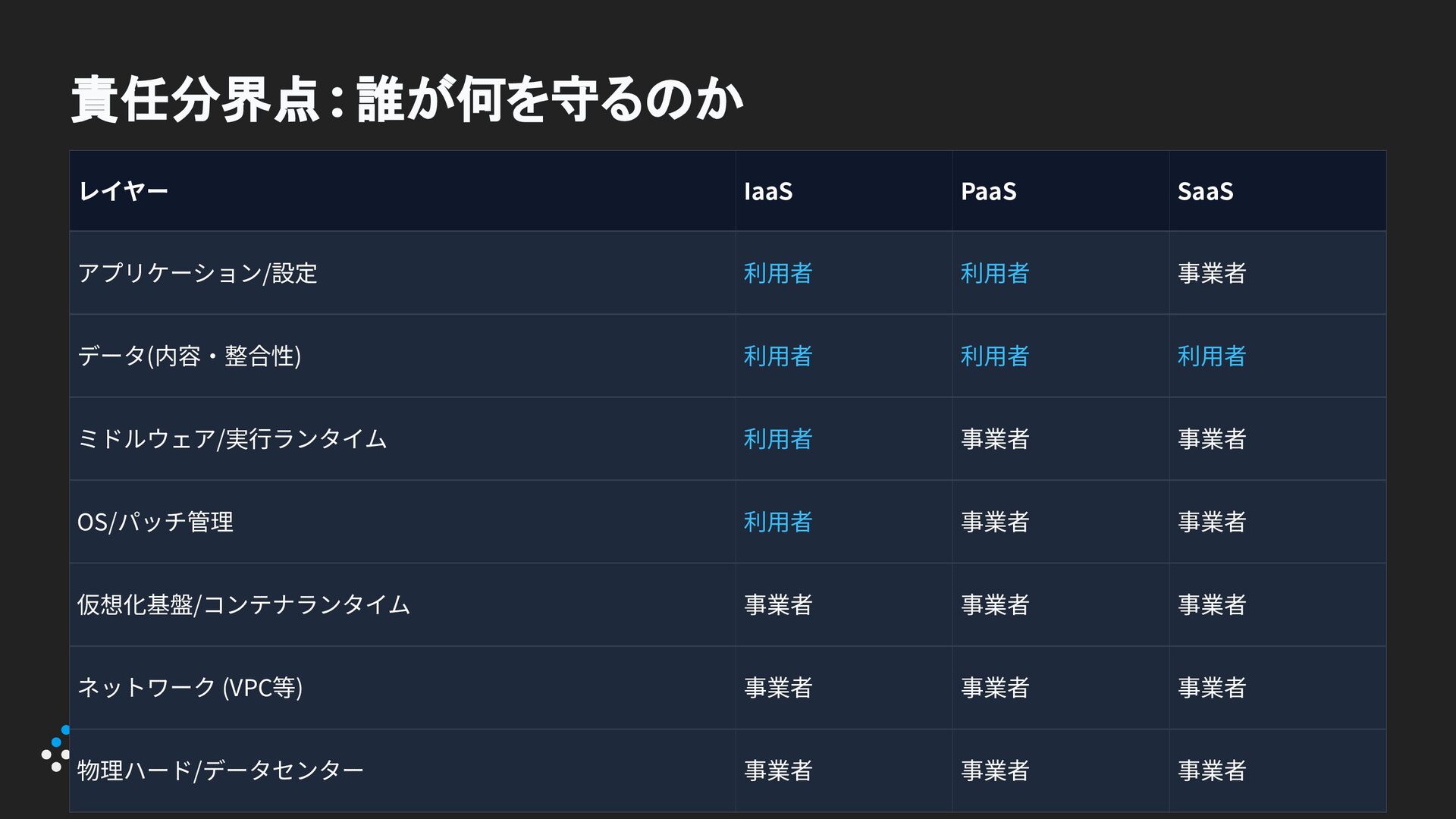
レイヤー IaaS PaaS SaaS アプリケーション/設定 利⽤者 利⽤者 事業者 データ(内容‧整合性) 利⽤者
利⽤者 利⽤者 ミドルウェア/実⾏ランタイム 利⽤者 事業者 事業者 OS/パッチ管理 利⽤者 事業者 事業者 仮想化基盤/コンテナランタイム 事業者 事業者 事業者 ネットワーク (VPC等) 事業者 事業者 事業者 物理ハード/データセンター 事業者 事業者 事業者 責任分界点 : 誰が何を守るのか
IaaS / PaaS / SaaS の責任分界を理解する 要件(可⽤性‧性能‧規制‧コスト)に合ったモデルのサービスを選択することが重要 提供モデルによってトラブル発⽣時の責任範囲が異なる → 選んだモデルによって「⾃分たちが守る範囲」が決まる。では、そのインフラをどう
⾼可⽤にするか? クラウドコンピューティング概論 (まとめ)
高可用性を実現するクラウド構成 02 CHAPTER 2
新しいWebサービスを開発したとき、最初はこういう構 成から始まることが多い Webの3層構造 (プレゼンテーション層‧アプリケーショ ン層‧データ層)を1台のサーバに集約したモノリシック アーキテクチャ ▹ ▹ 小規模なサービスのインフラ構成
課題 説明 単⼀障害点 ⼀部の障害がシステム全体を停⽌させるリスク スケーラビリティの制限 システム全体のスケールアップが必要で、リソース効率が悪い デプロイの難しさ ⼩さな変更でも全体の再デプロイが必要で、ダウンタイムが発⽣ チーム開発の⾮効率 複数チームでの同時作業が困難
保守性の低下 コードが⼤規模化し、変更‧リファクタリングが困難 モノリシックアーキテクチャの課題
アプローチ R(信頼性) / A(可⽤性) / S(保守性) / I(完全性) / S(セキュリティ)
分散アーキテクチャの導⼊ 可⽤性向上、保守性向上、(障害波及の防⽌) 冗⻑化‧⽔平スケーリングの導⼊ 可⽤性向上、信頼性向上、(負荷分散) CDNの導⼊ 可⽤性向上、セキュリティ強化 モニタリングとアラート 可⽤性維持、保守性向上 可用性を向上させるアプローチ
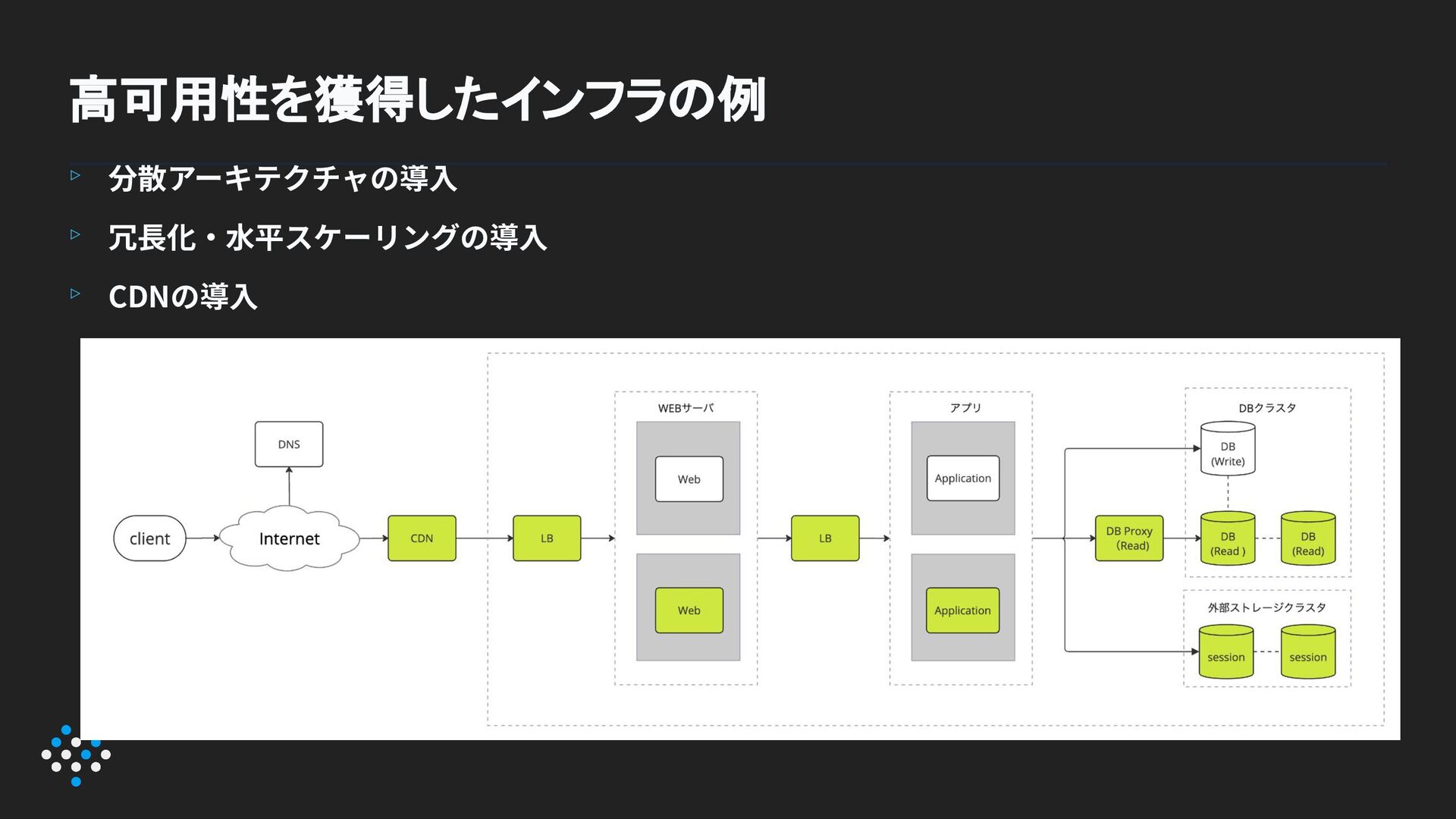
分散アーキテクチャ (Distributed Architecture)の導入
要素を分割し、独⽴して稼働させることで、単⼀障 害点を排除します。 Web層: リクエスト受け付け Application層: ビジネスロジック処理 DB/FS層: データ永続化 ▹ ▹
▹ モノリシックから分散アーキテクチャへ
メリット 説明 スケーラビリティ 個別のコンポーネントを独⽴してスケールアップ/ダウン可能 耐障害性 ⼀部の障害が全体に波及しにくい構造 継続的デプロイ 個別のコンポーネントを独⽴してデプロイ可能 開発の効率化 ⼩規模なチームが並⾏して開発可能
セキュリティの強化 コンポーネント間の境界でのセキュリティ制御が可能 分散アーキテクチャを採用する利点
垂直スケーリング (Scale Up) 水平スケーリング (Scale Out) 概要: 1台あたりのリソース(vCPU/メモリ)を増 やす。 例:
t3.medium → m6i.2xlarge に変更 ⻑所: 実装が容易、単⼀ノード性能が必要な ワークロードに有効 短所: 上限がある‧⾼コスト化しやすい 概要: 同⼀役割のノードを複数台並べて負荷分 散。 例: WebサーバをAuto ScalingやK8sのHPAで⾃ 動増減 ⻑所: 可⽤性/耐障害性が上がる‧無停⽌で段階 増設 短所: アプリのステートレス化など設計上の前 提が必要 ▹ ▹ ▹ ▹ ▹ ▹ スケーリングの 2つの方向: 垂直 vs 水平
DB層の冗⻑化 プライマリ‧レプリカ構成、⾃動フェイルオーバー → AWSではAmazon RDS‧Amazon Auroraのマネージドサービスを活⽤ アプリ層の冗⻑化 複数インスタンス+ロードバランサー、セッション外部管理 → ヘルスチェックで問題インスタンスを⾃動切り離し
Web層の冗⻑化 複数のWebサーバ+ロードバランサー → ⾃動⽔平スケーリングで負荷に応じてサーバ数を調整 3層構造の各層を冗長化して可用性を高める
CDNはエッジサーバーでコンテンツをキャッシュし、ユーザーに近い場所から配信する仕組み 代表的なCDNプロバイダー: Cloudflare / Amazon CloudFront / Akamai RASIS要素 CDN導⼊による効果
信頼性 コンテンツ複製で冗⻑性向上、単⼀障害点の削減 可⽤性 分散サーバーによる⾼可⽤性、DDoS攻撃の影響軽減 セキュリティ WAF提供、アクセス制御とモニタリング強化 CDNの導入
分散アーキテクチャの導⼊ 冗⻑化‧⽔平スケーリングの導⼊ CDNの導⼊ ▹ ▹ ▹ 高可用性を獲得したインフラの例
⾼可⽤構成は要素が増えて⼿作業では維持困難 → そこで登場するのが Infrastructure as Code モノリスの課題: 単⼀障害点 / スケール制限
/ デプロイの難しさ 解決の⽅向性 ‧ 分散アーキテクチャへの移⾏ ‧ Web/App/DB各層の冗⻑化と⽔平スケーリング CDNで配信最適化と負荷分散 高可用性を実現するクラウド構成 (まとめ)
Infrastructure as Code (IaC)と 自動化 03 CHAPTER 3
従来 (手動) IaC (コード化) ⼿順書を⾒ながら⼿動設定 ドキュメント依存、属⼈化しやすい 設定ミスが気づきにくい 環境間の差異が⽣まれやすい コードで実⾏、誰でも再現可能 Git管理、差分‧レビュー‧ロールバックが容易
コードのレビューでミスを未然に防ぐ 宣⾔的に「あるべき状態」を定義 ▹ ▹ ▹ ▹ ▹ ▹ ▹ ▹ IaC・自動化とは何か ? 従来の手動運用との違い
望ましい状態をコードで宣⾔ 「こうあるべき」を記述し、ツールに実現を任せる。 実際の状態とコードとの差分(ドリフト)を⾃動検知‧是正。 可読性と保守性の向上 コードを追うだけで「何がどう構成されるか」が明確。 再利⽤性の⾼いモジュール化 共通パターンをモジュール化し、複数環境で簡単に再利⽤。 チーム開発との親和性 GitOps的な運⽤に組み込みやすく、チーム全体で共通理解を担保。 宣言的設計のメリット
はてなでは CDK と Terraform が多く使われています ツール 特徴 ユースケース例 Terraform 宣⾔的HCL
/ マルチクラウド対応 マルチクラウド/ハイブリッド運⽤ CloudFormation AWS専⽤YAML/JSONテンプレート 純AWS環境のマネージドリソース構築 AWS CDK TypeScript/Python等で記述→CFNに変換 複雑ロジックをコードで表現したい場合 Pulumi 任意⾔語(Go, Java等)でIaC 既存開発⾔語スキルを活かした導⼊ 代表的なIaCツール
PRベース運用 自動検証 (ガードレール ) Git Push ⾃動Lint/Validate Plan差分確認 Code Review
⾃動適⽤ モニタリング セキュリティスキャン: tfsec, Checkov Policy-as-Code: Open Policy Agent, Sentinel 差分プランの⾃動コメント: PRレビューを効率化 ▹ ▹ ▹ ▹ ▹ ▹ ▹ ▹ ▹ CI/CD連携とGitOps ワークフロー
インフラが動いていれば安⼼、というわけではない。 → では、動いているものをどう⾒るか? コード化で再現性と安定性を確保 ⼿動作業を排除し、いつでも同じ環境を構築可能にする 宣⾔的設計で「望ましい状態」を⾃動維持 差分検知と⾃⼰修復により運⽤負荷を削減 CI/CD連携でフィードバックループをまわす GitOpsワークフローで安全かつ迅速な運⽤を実現 Infrastructure
as Code と自動化 (まとめ)
モニタリングとオブザーバビリティ 04 CHAPTER 4
サービス運⽤で⼀番困るのは「気づかない不具合」 ユーザーが「遅い」「落ちる」と感じる前に、システムの異常を早く⾒つける ことが⼤切 そのために モニタリング と オブザーバビリティ がある そもそも「見える化」がなぜ大事か ?
定義: あらかじめ決めた指標(CPU、メモリ、レスポンス時間など)を監視し、異 常を検知すること ⽬的: システムの「今の状態」を知る 例: ‧ CPU使⽤率が90%以上になったらアラート ‧ エラーログが1分間に100件以上出たら通知
モニタリングとは
項⽬ モニタリング オブザーバビリティ ⽬的 状態を検知する 原因を理解する ⼿段 メトリクス/ログ中⼼ MELT (Metrics
/ Events / Logs / Traces) 得意 「異常に気づく」 「なぜ異常が起きたか掘る」 例: モニタリング → 「EC2のCPUが90%超」 オブザーバビリティ → 「APIがボトルネック、特定クエリが遅延」 ▹ ▹ モニタリングとオブザーバビリティの違い
Metrics: リソース使⽤率やレスポンスタイムなど定量的指標 Events: デプロイや障害などの出来事 Logs: アプリやミドルウェアが出す詳細な履歴 Traces: リクエストの流れを追跡(どのサービスが遅いか⼀⽬でわかる) 得られる効果: 未知の異常に気づける
(例: イベントとメトリクスの相関でデプロイ由来の不具合を検知) 原因調査が速い (トレースでボトルネック特定→ログで詳細確認→メトリクスで影響範囲 を把握) 複雑な環境でも俯瞰できる (マイクロサービスや外部APIの依存関係を⼀望) ▹ ▹ ▹ MELT (4つの柱) と得られる効果
「⾃分たちが作ったツールで⾃分たちのサービスを守る」 Mackerel + OpenTelemetry Metrics: OpenTelemetry形式(OTLP)でメトリクスを送 信‧収集 Events: デプロイや障害をグラフアノテーションとして メトリクスと関連づけて把握
Traces: OpenTelemetryからのトレースを受け取り、 Vaxila (APM) でリクエスト単位の遅延‧エラー を分析 ▹ ▹ ▹ はてなでのオブザーバビリティ実践
この体制を組織としてどう維持するか? それが DevOps/SRE モニタリング: 状態を「知る」仕組み オブザーバビリティ: 原因を「理解する」仕組み MELTを組み合わせることで、複雑なシステムでも素早く問題を特定できる 最終的なゴールは「ユーザーに影響する前に異常を検知し、すぐに直せる体制」を作る こと
モニタリングとオブザーバビリティ (まとめ)
DevOps/SRE入門 05 CHAPTER 5
DevOps: 開発と運⽤を統合し、迅速なデリバリーと改善を実現する⽂化 SRE: Google発の信頼性エンジニアリング。運⽤をソフトウェア化し、速度と 可⽤性を両⽴ 位置づけ: SREはDevOpsを実現する⼿法の⼀つ 共通点: ⾃動化と可観測性で、品質とスピードを両⽴ DevOps/SREの概要
単なる数値ではなく「リリースや改善の判断材料」になる SLI Service Level Indicator 品質を数値で測る指標 (例: リクエスト成功率、レスポンス タイム) SLO
Service Level Objective その指標に対する⽬標 (例: リクエスト成功率 99.9%) エラーバジェット 許容される失敗率 → 開発速度と信頼 性の調整に使う 信頼性をどう数値で管理するか ?
稼働率 = (総稼動時間 - 障害時間) / 総稼動時間 × 100 可⽤性
年間ダウンタイム ⽉間ダウンタイム 週間ダウンタイム 99% 3.6⽇ 7.2h 1.7h 99.9% 8.7h 43m 10m 99.99% 53m 4m 1m 99.999% 5m 26s 6s 「⾼可⽤性」ほどコストや仕組みが複雑になる → 「⾃分たちのサービスにとって何%が適切か」をチームで合意することが重要 可用性目標とダウンタイム
「失敗から学ぶ⽂化」がSREの根幹にある 既存メトリクス/ログの活⽤と拡充 カスタムメトリクス追加、JSONログ化 SLI/SLO‧エラーバジェットのダッシュボード作成、アラート設定 インシデント発⽣時: オンコール → 復旧 → Postmortem
(振り返り) 定期レビューで閾値‧項⽬を更新 SREの日常: 計測→可視化→改善のサイクル
DevOps/SRE: ⾃動化と可観測性で品質と速度を両⽴ SLI/SLO/エラーバジェット: 数値を使い運⽤判断を明確化 可⽤性とダウンタイム: ⽬標値の選択はビジネス要件との合意が必要 計測→可視化→改善のサイクルが鍵 技術だけでなく「信頼性を守る姿勢」が⼤切 DevOps/SRE入門 (まとめ)
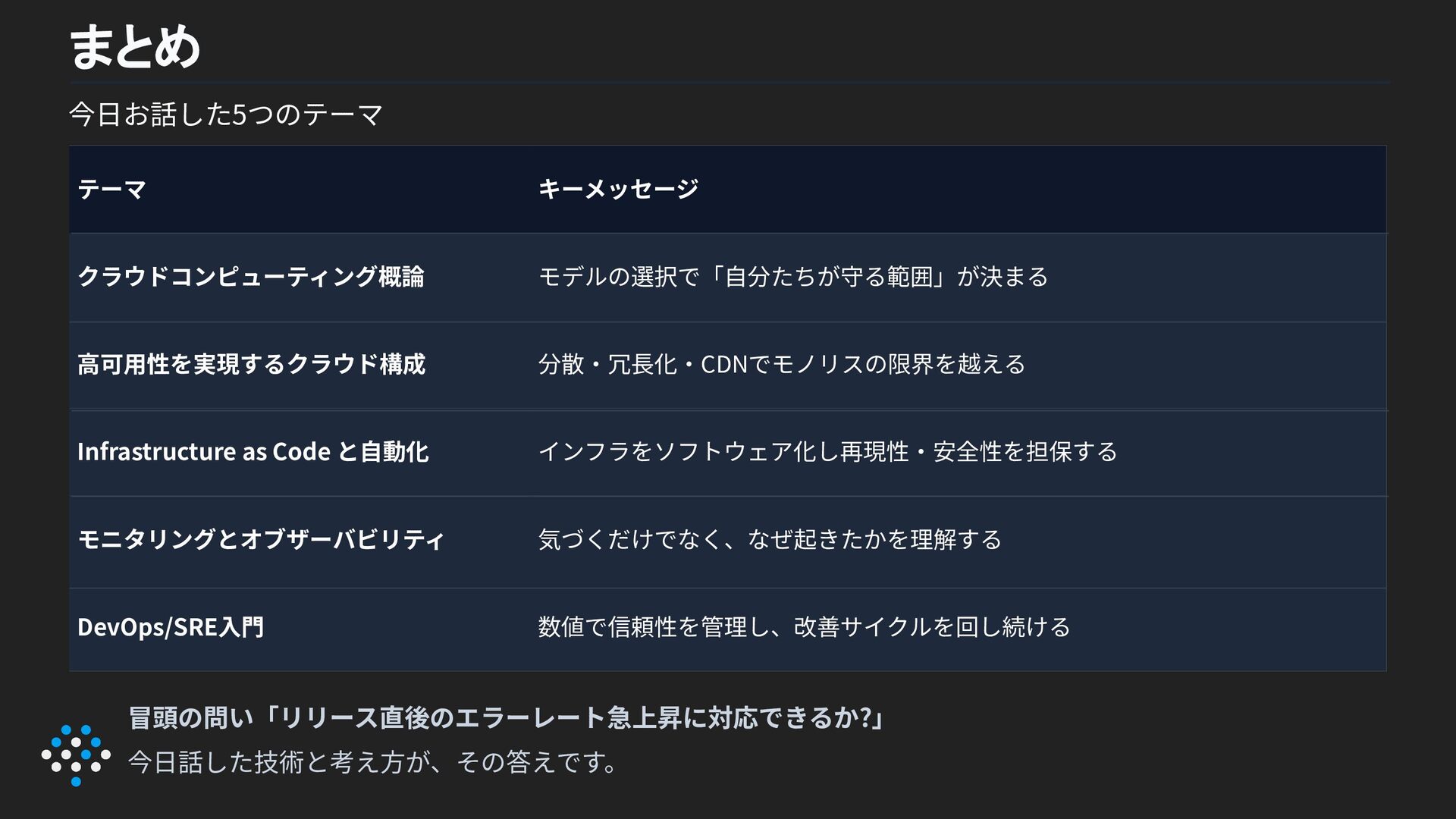
今⽇お話した5つのテーマ テーマ キーメッセージ クラウドコンピューティング概論 モデルの選択で「⾃分たちが守る範囲」が決まる ⾼可⽤性を実現するクラウド構成 分散‧冗⻑化‧CDNでモノリスの限界を越える Infrastructure as Code
と⾃動化 インフラをソフトウェア化し再現性‧安全性を担保する モニタリングとオブザーバビリティ 気づくだけでなく、なぜ起きたかを理解する DevOps/SRE⼊⾨ 数値で信頼性を管理し、改善サイクルを回し続ける 冒頭の問い「リリース直後のエラーレート急上昇に対応できるか?」 今⽇話した技術と考え⽅が、その答えです。 まとめ
実践‧実験している領域 設計・実装フェーズ 運用・調査フェーズ アーキテクチャの壁打ち相⼿としてAIを活⽤ Coding Agent で Terraform / Kubernetes
Manifest の修正‧レビュー クラウドベンダー提供のAIエージェントで、リ ソース異常分析‧コスト最適化ポイントの抽出 Grafana / Mackerel の MCP サーバー経由で、 AIエージェントから観測データを直接参照 ▹ ▹ ▹ ▹ Appendix: SREでのAI活用
はてな サマーインターンシッ プ 2026!! • はてな京都オフィスでの講義パー ト & オンラインの実践パート! •
8月17日(月)~9月4日(金) ◦ 前半1週間: 京都オフィス ◦ 後半2週間: オンライン • 応募フォームにたどり着くために はクイズに回答する必要がありま す。腕試しにぜひチャレンジして ください! 43
X アカウント @hatenatech • 本日の講義資料、インター ンや就活情報、はてなの技 術情報などを発信するアカ ウントです • 是非フォローしてくださ
い! 44
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}