Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ざっくりとわかる分析
Search
hayata-yamamoto
March 20, 2019
Science
260
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ざっくりとわかる分析
社内向けのプレゼンで使いました。理論的なところは厳密性を欠いてる可能性あります。詳細な理解の際には専門書を合わせて読むのをお勧めします。
hayata-yamamoto
March 20, 2019
More Decks by hayata-yamamoto
See All by hayata-yamamoto
東京でも_広島でも__ひろしま_でつながる.pdf
hayata_yamamoto
0
17
生成AI動向まとめ 2025年7月
hayata_yamamoto
1
83
テック系起業家のための 会計入門 数字を味方につける経営ガイド
hayata_yamamoto
0
58
バランスト・スコアカード(BSC)
hayata_yamamoto
0
51
データ同化入門
hayata_yamamoto
0
110
中小企業のための 行政デジタルID活用ガイド
hayata_yamamoto
0
55
AIエージェントにおける評価指標と評価方法:本番環境での包括的検証戦略
hayata_yamamoto
0
110
統計的意思決定論の入門
hayata_yamamoto
0
270
コンテキストエンジニアリング入門
hayata_yamamoto
0
270
Other Decks in Science
See All in Science
知能とはなにか -ヒトとAIのあいだ-
tagtag
PRO
1
110
生成AI・プレプリント時代における 研究成果公開の再設計 ― トップカンファレンス文化はどこへ向かうのか / Redesigning the Dissemination of Research Outputs in the Age of Generative AI and Preprints — Where Is the Top-Conference Culture Heading?
ykiyota
0
29k
機械学習 - K-means & 階層的クラスタリング
trycycle
PRO
0
1.8k
AIを用いた PID制御で部屋 の温度制御をしてみた
nearme_tech
PRO
0
170
Tensor Factorization Meets Deformed Information Geometry: Convex Relaxation under Deformed Algebra
gkazunii
0
110
(2025) Balade en cyclotomie
mansuy
0
640
ITTF卓球世界ランキングのポイント比を用いた試合結果予測モデルの性能評価 / Performance evaluation of match result prediction models using the point ratio of the ITTF Table Tennis World Ranking
konakalab
0
140
機械学習 - 決定木からはじめる機械学習
trycycle
PRO
0
1.5k
データベース09: 実体関連モデル上の一貫性制約
trycycle
PRO
0
1.4k
AI(人工知能)の過去・現在・未来 ~AIは人類を越えるのか~
tagtag
PRO
0
120
東北地方における過去20年間の降水量の変化
naokimuroki
1
330
Kaggle: NeurIPS - Open Polymer Prediction 2025 コンペ 反省会
calpis10000
0
620
Featured
See All Featured
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
Building Flexible Design Systems
yeseniaperezcruz
330
40k
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.3k
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4.1k
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
410
The untapped power of vector embeddings
frankvandijk
2
1.8k
New Earth Scene 8
popppiees
3
2.4k
Technical Leadership for Architectural Decision Making
baasie
3
430
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
220
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
180
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
170
Transcript
ざっくりとわかる分析
Agenda 1. Purpose 2. Workflow 3. Conclusion
Hayata Yamamoto (23) • Role ◦ Data Scientist @RareJob •
BackGround ◦ Sales -> ML eng. -> DS • Interest ◦ Statistics
Purpose
【ねらい】 • データ分析の全体像がわかる • 業務内容が理解できる • モデルの雰囲気がわかる • 実験レポートの6割くらい理解できるようになる 【やらないこと】
• 数学の厳密な説明 • モデルの詳細な説明 • 全体的な説明の厳密性の担保
Workflow
データ取得 ハンドリング 特徴抽出 学習準備 学習 テスト 原因調査 分析業務の流れ
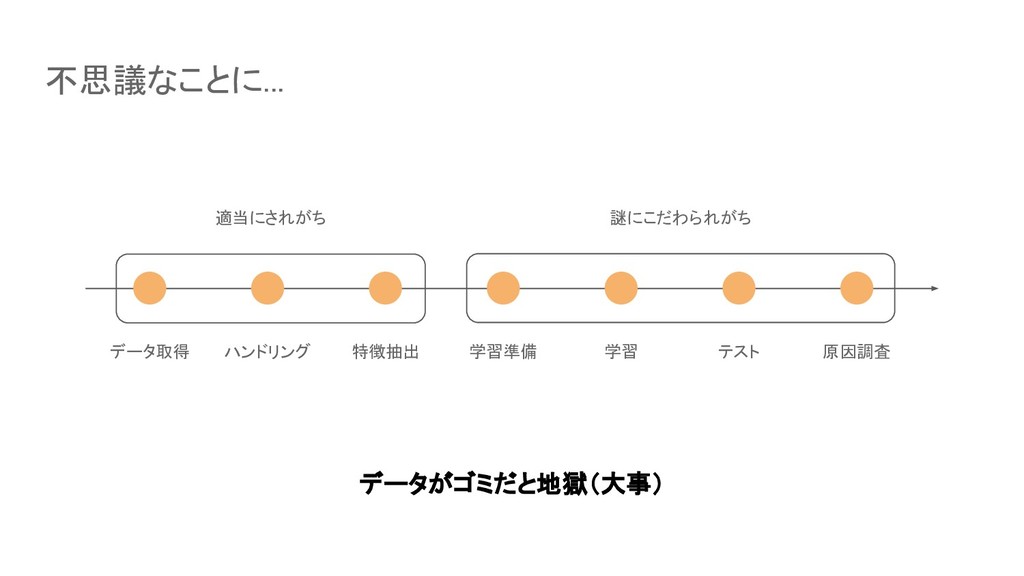
データ取得 ハンドリング 特徴抽出 学習準備 学習 テスト 原因調査 不思議なことに... 適当にされがち 謎にこだわられがち
データ取得 ハンドリング 特徴抽出 学習準備 学習 テスト 原因調査 不思議なことに... 適当にされがち 謎にこだわられがち
データがゴミだと地獄(大事)
それぞれ何やってるの?
データ取得 ハンドリング 特徴抽出 学習準備 学習 テスト 原因調査
データ取得 【目的】 • データ自体をプログラムに読み込むため 【やること】 • CSV, JSON, SQL, API,
HTMLなどいろんなソースからデータを取得してくる • 企業の場合、プロダクションのRDBとのやりとりが主体 • 直接SQL叩いて取ってくることもあるし、CSVにして違うデータと結合してから使うことも。 • クラウド上のデータとやりとりすることが多いので、インフラ的な知識がある方が好ましい。
データ取得 ハンドリング 特徴抽出 学習準備 学習 テスト 原因調査
ハンドリング 【目的】 • 読み込んだデータを処理しやすい形に変形するため • ノイズになるデータを削除しておくため(≠欠損データ) 【やること】 • HTMLをスクレイピングしたり、APIのレスポンスをパースしたりする。 •
システムエラーや仕様上のバグなど、100%ノイズになるデータを削除する • ログ収集とかのETLと考え方は一緒。
データ取得 ハンドリング 特徴抽出 学習準備 学習 テスト 原因調査
特徴抽出 【目的】 • 予測したい数値やカテゴリ間の違いが出る情報をデータから取り出すため • 特徴をうまく出して機械学習モデルの性能をあげるため • ドメイン知識を反映した情報を作り出すため • データから知識を取り出すため
特徴抽出 【やること】 • 変数同士の差分や対数、指数などをとる • 新しい変数を既存の変数から作成する • 入力変数間、入力変数と出力変数の関係性を調べる(相関係数や相互情報量など) • カテゴリデータを変換する
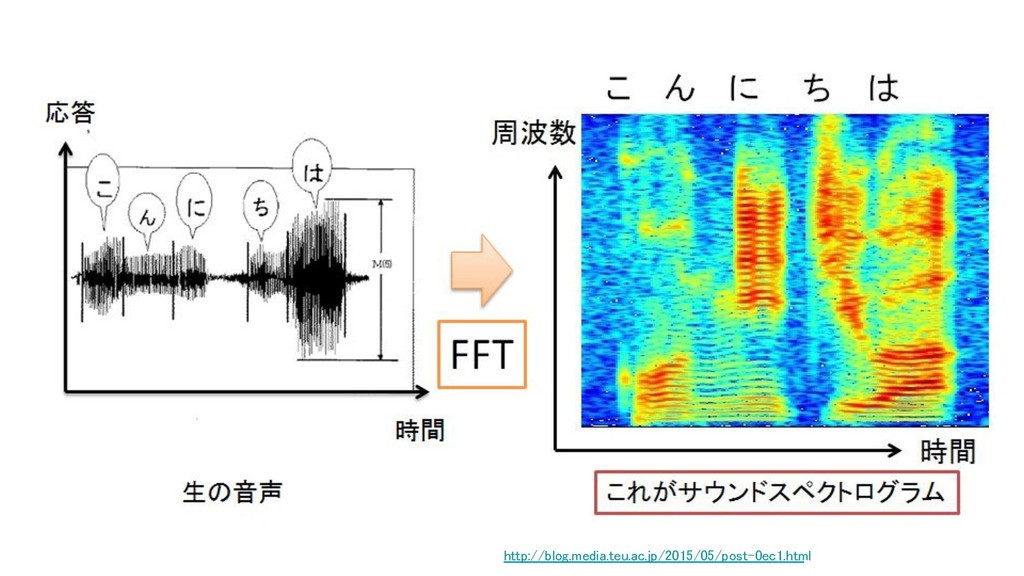
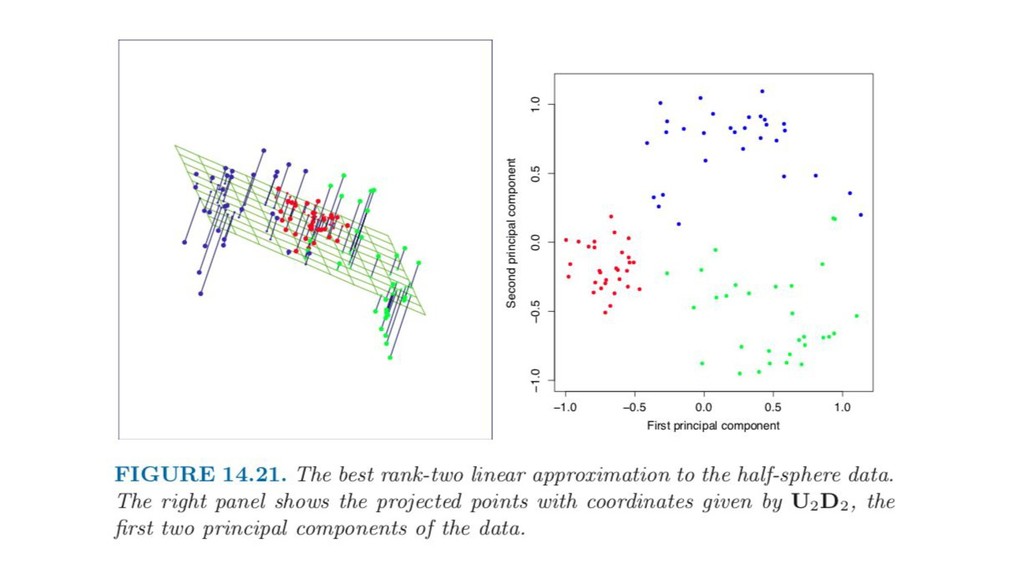
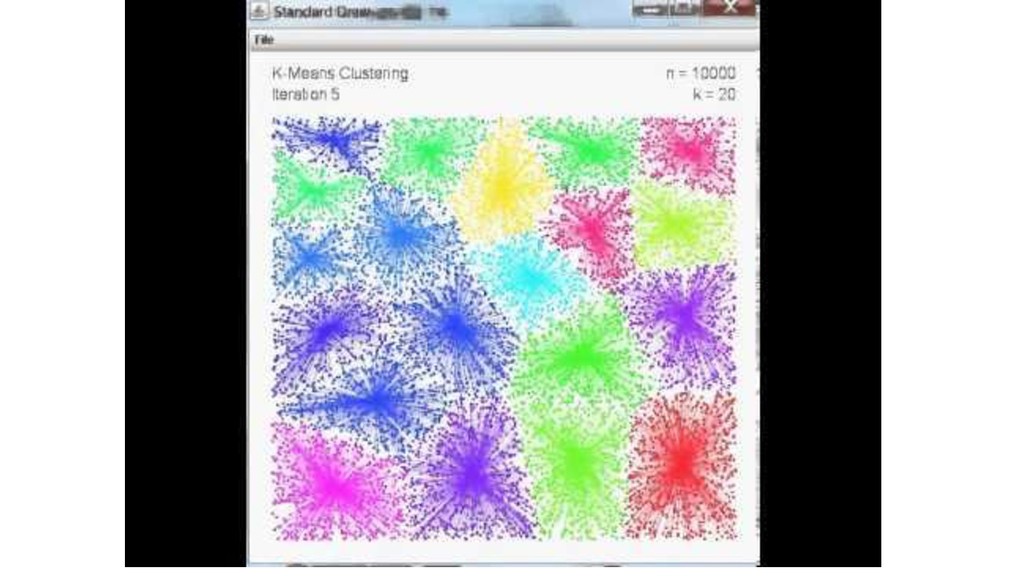
• データの正規化 • テキストデータのベクトル化する(Bag-of-X, Word2vec, PMI+SVDなど) • 波形データをフーリエ変換する • いらない変数を削除する(統計的仮説検定、予測モデルによる貢献度分析) • スパースなデータを圧縮する(PCA) • データをベクトルの値を用いてグルーピングする(クラスタリング) など
None
http://blog.media.teu.ac.jp/2015/05/post-0ec1.html
None
None
データ取得 ハンドリング 特徴量抽出 学習準備 学習 テスト 原因調査
学習準備 【目的】 • ときたい問題を定義する • データの不均衡を解消する • 分類や回帰を行えるモデルを用意する • パイプライン作る
◦ データ流すと学習から予測までやってくれるやつ • モデルをどのように評価するかを決める ◦ 最終的にモデルの性能はどのようになっていてほしいかを決める
学習準備 【やること】 • 不均衡データに対する対処 ◦ 偏っているまま何もしないと、不均衡の比率の高い方ばかり当てるモデルができる ◦ サンプリング手法を導入する(imblanced-learnなど) ◦ 不均衡度合いなどを用いて罰則項を変える
◦ クラスの重みを考慮できる評価関数を用いる ◦ 不均衡データに対応している交差検証法を用いる • モデルを作成する ◦ sklearn, XGBoost, LightGBMなどはインスタンス生成するだけ ◦ GitHubとかから学習済みの良いモデルを拝借することもある ◦ 自前でニューラルネットワークのモデルを作る(あんまり推奨できないかも) • 各種パラメータを決める ◦ 最適化手法、罰則項の値、学習率、活性化関数など可変なもの全てがパラメータ ◦ どのパラメータが良いかを事前に誰も知らない(先行研究がある場合は除く)
どんな問題があるか • 教師あり学習 ◦ 回帰問題 ◦ 分類問題 <- これから説明する問題 •
教師なし学習 ◦ 次元削減 ◦ クラスタリング • 半教師あり学習(詳しくない) • 強化学習(詳しくない)
モデルの種類(ざっくり) • 線形モデルの仲間たち ◦ OLS, GLS, Logistic Regression (初学者向け) ◦
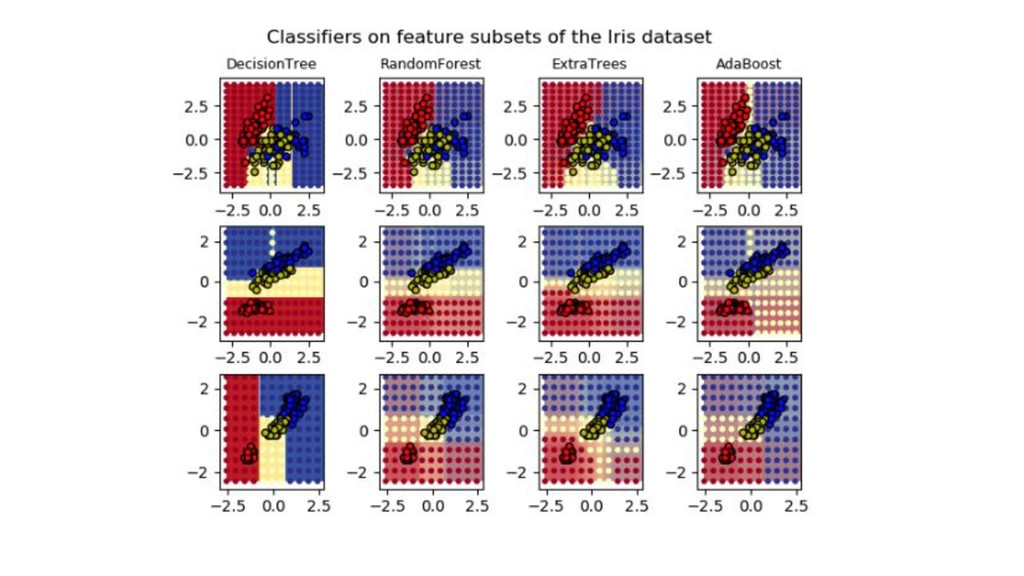
Ridge, Lasso (難しい) ◦ Neural Network (とても難しい) • 分離超平面をつかいたいやつ ◦ Support Vector Machine (とても難しい) • 木をベースにしたやつ ◦ Decision Tree (初学者向け) ◦ Bagging, RandomForest (難しい) ◦ AdaBoost, Gradient Boosting (難しい) ◦ XGBoost, LightGBM (とても難しい)
モデルの種類(ざっくり) • 線形モデルの仲間たち ◦ OLS, GLS, Logistic Regression (初学者向け) ◦
Ridge, Lasso (難しい) ◦ Neural Network (とても難しい) • 分離超平面を使いたいやつ ◦ Support Vector Machine (とても難しい) • 木の仲間たち ◦ Decision Tree (初学者向け) ◦ Bagging, RandomForest (難しい) ◦ AdaBoost, Gradient Boosting (難しい) ◦ XGBoost, LightGBM (とても難しい)
None
予測のミスを最小にしたいやつ 【概要】 • 予測と正解の差(関数による)を最小にするようにしたい。 • 入力変数それぞれにかける重みの値を最適にすることで達成を目指す。 【やること】 • 以下の基本形をいい感じに拡張したモデルを使って予測する。
ロジスティック回帰 【概要】 • 名前は回帰だけど、分類のモデル • 線形回帰にロジスティック関数(下図)を導入して出力の範囲を[0, 1]に収めたもの 【気持ち】 • 線形回帰がわかってれば、理解は多少楽
• ニューラルネットワークへの橋渡しにもなる • 初学者が最初に学ぶことの多い分類モデル
モデルの種類(ざっくり) • 線形モデルの仲間たち ◦ OLS, GLS, Logistic Regression (初学者向け) ◦
Ridge, Lasso (難しい) ◦ Neural Network (とても難しい) • 分離超平面を使いたいやつ ◦ Support Vector Machine (とても難しい) • 木の仲間たち ◦ Decision Tree (初学者向け) ◦ Bagging, RandomForest (難しい) ◦ AdaBoost, Gradient Boosting (難しい) ◦ XGBoost, LightGBM (とても難しい)
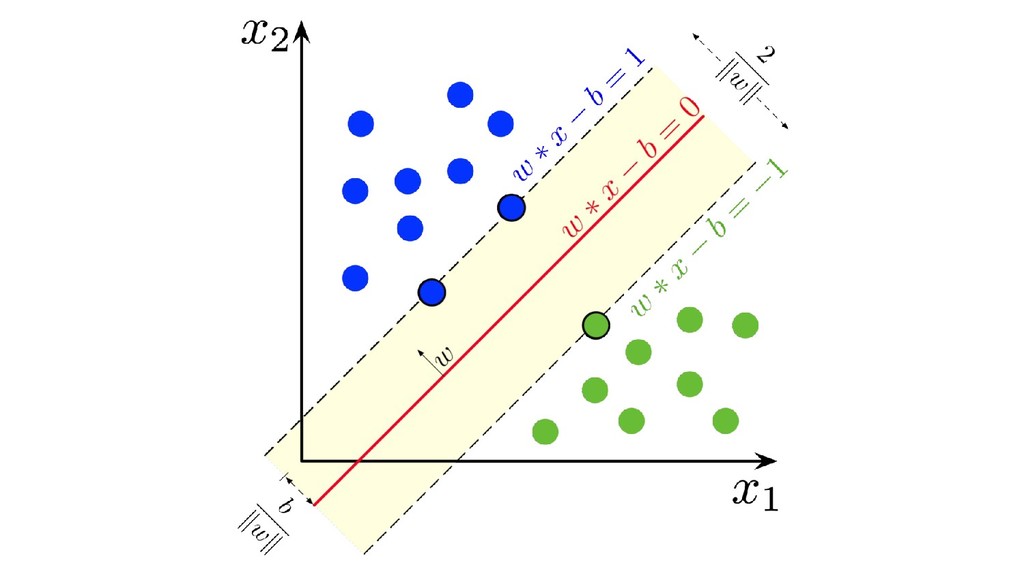
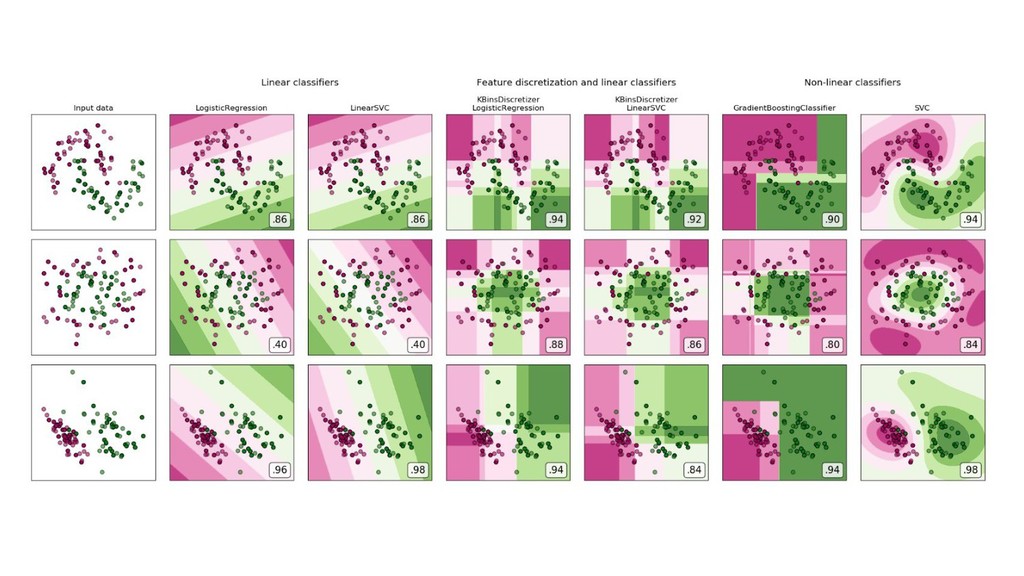
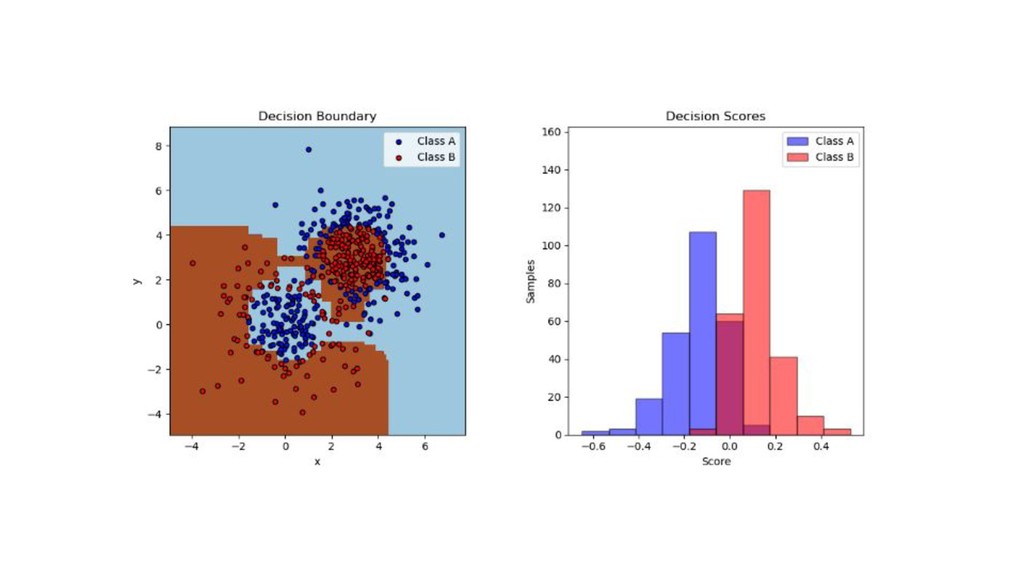
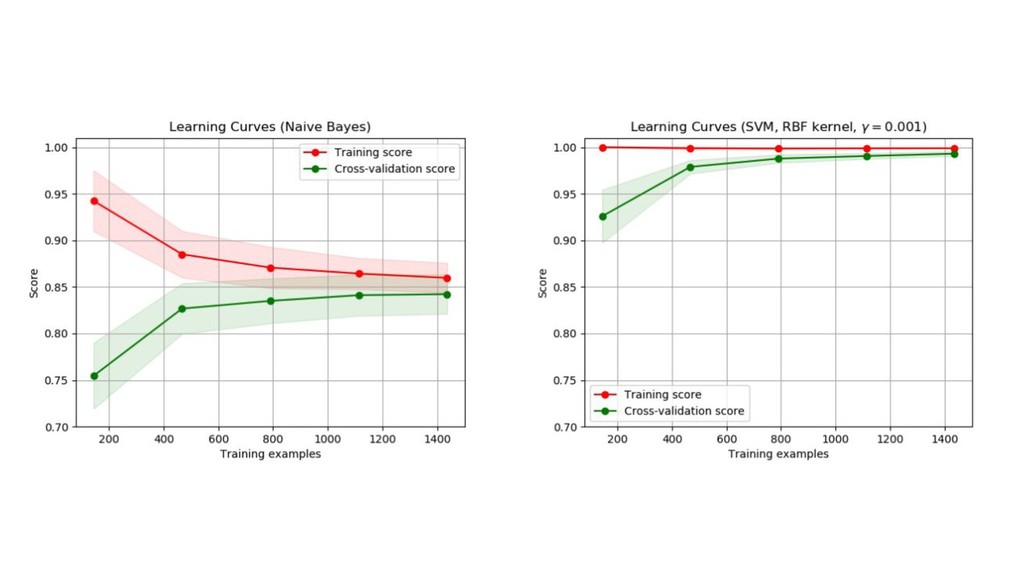
分離超平面つかいたいやつ(サポートベクターマシン) 【概要】 • 入力変数の空間をうまく分けたい • クラス間のマージン(空白部分の大きさ)を最大にするように分ける • 統計的学習理論という分野の話(らしい) • 識別関数ベースなので、確率を返さないことが多い(返せるモデルもある)
【やること】 • 以下のような関数を考えます。(難しいので詳細は専門書へ)
None
分離超平面つかいたいやつ(サポートベクターマシン) 【気持ち】 • できる限り線形分離可能だと嬉しい • 入力空間を効率的に特徴量空間に展開できて、線形分離可能性を増やせる(カーネルトリック) • 非線形分離しないといけない入力空間も特徴量空間では線形分離可能な場合もある • 多クラスの分離になると計算量が増えがち(One
vs One, One vs Rest) • データが少ない実験では意外とよく使われる印象(医療とか)
None
None
モデルの種類(ざっくり) • 線形モデルの仲間たち ◦ OLS, GLS, Logistic Regression (初学者向け) ◦
Ridge, Lasso (難しい) ◦ Neural Network (とても難しい) • 分離超平面を使いたいやつ ◦ Support Vector Machine (とても難しい) • 木の仲間たち ◦ Decision Tree (初学者向け) ◦ Bagging, RandomForest (難しい) ◦ AdaBoost, Gradient Boosting (難しい) ◦ XGBoost, LightGBM (とても難しい)
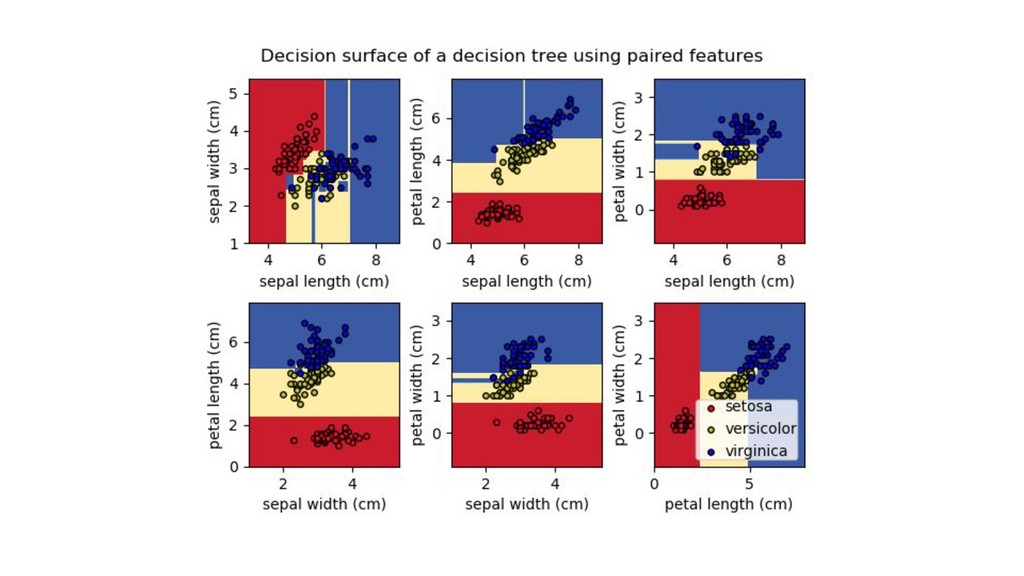
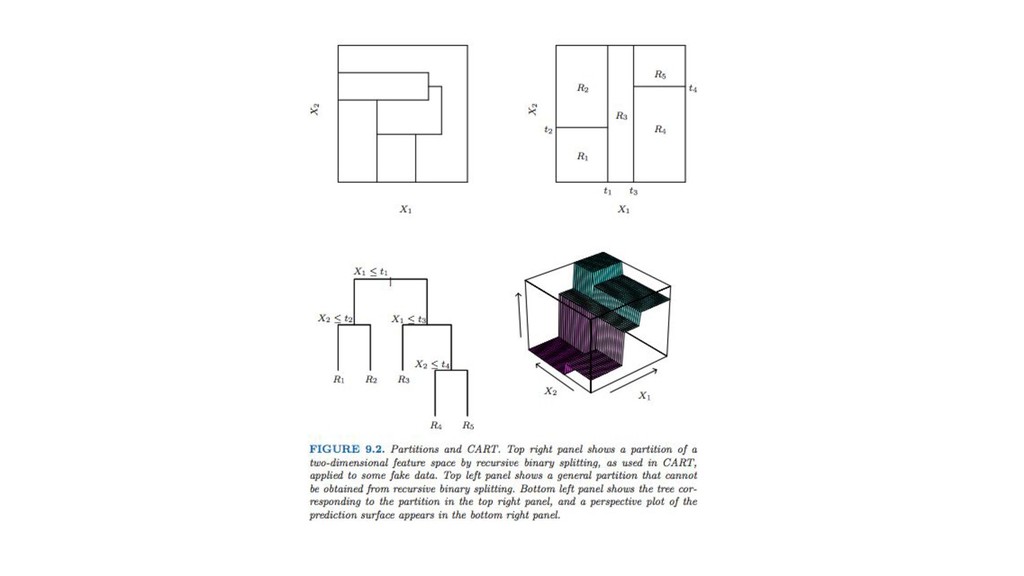
木を使うやつ 【概要】 • 二分技などを用いて、再帰的に変数の範囲を分割することを考える • 一本だけ、複数、大量に使うこともある • 人間の感覚に近く、直感的でわかりやすい • 入力変数間の関係を補足しやすい
• 未来予測だけでなく、既存のデータに対するマイニングでもよく使われる
決定木 【概要】 • 一つの木を使って、予測する問題を考える • 分割することで情報量が変化するかどうかを見ている • 分離平面がガタガタしがち(平滑化の問題) 【気持ち】 •
シンプルでわかりやすい。マイニングでもよく使われる • 学習データに過学習してしまうことも • 独裁政治みたいな感じ
None
None
None
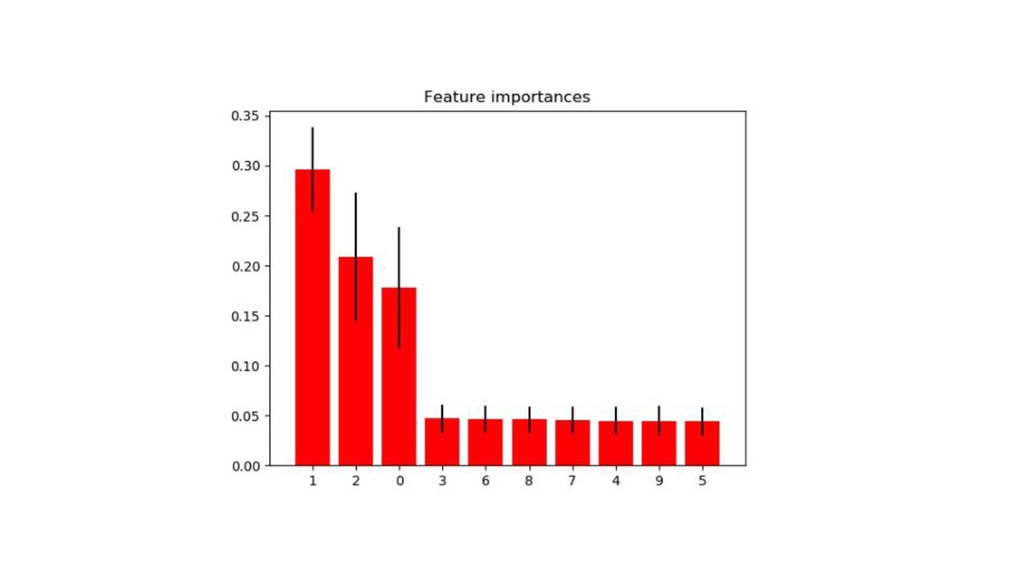
Bagging, RandomForest 【概要】 • 複数の木の合議(committee)の投票によって予測結果が決まる。 • それぞれの木が、各入力変数についてみるので多角的な結果を提供できる • RandomForestは、Baggingの重要な拡張 •
あるブートストラップ標本で任意の変数の候補を取り出して、ランダムにその中から分割する変数を決め ることを繰り返す(雑) 【気持ち】 • 予測時の視点が増える • 実質的に変数間の関係性が考慮されているように見える • 変数重要度取れるので嬉しい • 元老院みたいなイメージ
AdaBoost, Gradient Boosting 【概要】 • 弱い分類器を用いて最終的な結果を出力する • あまり結果に貢献しなかった変数の重みを下げる仕組みがある • 最終的には重み付きの合意形成が行われる
• パラメータ多くなりがち 【気持ち】 • 期待値よりも少し高いくらいの分類器をたくさん使って結果出すのすごい • パラメータ探索が勝負 • 過学習しやすいが、良い性能が出ることも多い • 「お前の言ってることあんまり信用ならないから、ごめん不採用にするわ」的なイメージ
None
None
None
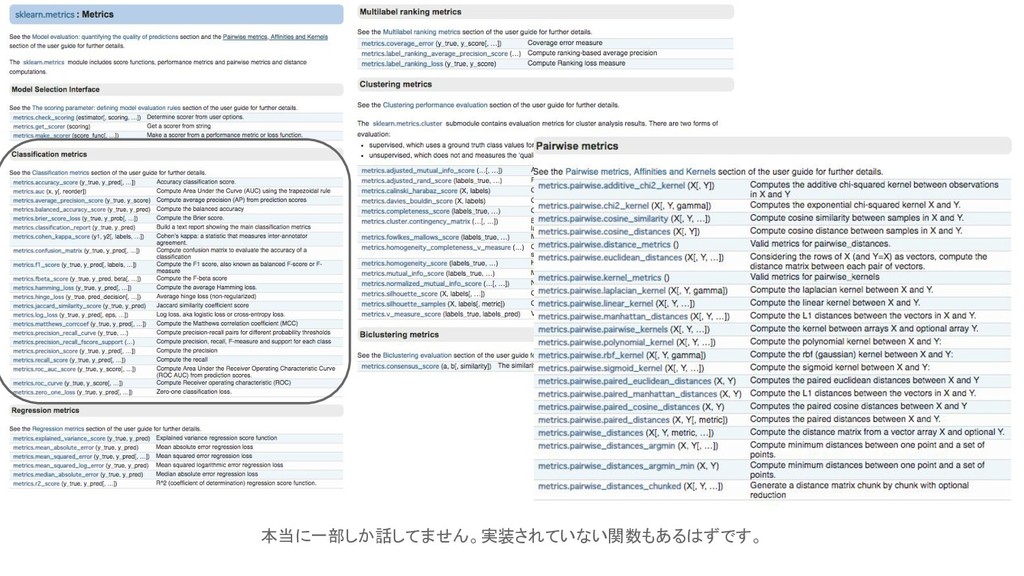
何を評価するか(分類の場合) 【概要】 • モデルにどうなってほしいのかを数学的に表現する。 • トレードオフを意識して、「何を取るのか」「何を捨てるのか」をはっきりしとくと良い 【代表的な候補】 • 正答率 :
Accuracy • 再現率 : Recall • 適合度 : Precision • 特異度 : Specificity • F値 : F-measure, F1 score • ROC:Receiver Operating Characteristic • AUC: Area Under the Curve など
本当に一部しか話してません。実装されていない関数もあるはずです。
どのように評価するか 【概要】 • 評価する関数が決まったら、どのように性能を評価するかを決める • 主な目的は、「このモデルの汎化性能はどのくらいあるかを確認すること」 【代表的な候補】 • ホールドアウト法 ◦
あらかじめトレーニングとテストを任意の比率で分けておく • 交差検証法 ◦ データのうち任意の数個を抜いて学習して性能評価する ◦ これを任意の回数繰り返して、性能をみる ◦ クラスの不均衡を考慮するものもある • ブートストラップ法 ◦ サンプルを重複を許して部分抽出するやり方(詳しくない) ◦ BaggingやRandomForestもこれやってる ◦ https://qiita.com/tjmnmn/items/3aed6fb85f75446f74ca <- 丁寧
None
None
パイプラインを組む 【概要】 • 中身の実装が異なっているだけで、やりたいことの大枠はみんな一緒 • 評価したいときは、正解と予測を入れて評価を返すだけ、モデルはxを入れてyを返すだけ • それをデータ入れたらうまく動くようにしておきたい(その方が楽) • パラメータ最適化ができるならそれも対応しちゃう
【やること】 • 特徴量抽出、モデル、評価、検証の方法を決めてパイプラインを作る • 最適化関数を作成する
最適化関数の作成 パイプラインの作成
データ取得 ハンドリング 特徴量抽出 モデル作成 学習 テスト 原因調査
学習 【目的】 • トレーニングデータの特徴をモデルに教える 【やること】 • 学習用データ(x, y)をモデルに与えて学習させる • 学習時のデータxをモデルに渡して、yを予測させる
• 評価関数に正解と予測のyを与えて、うまく学習できているかを確認する ◦ 学習用データでいい性能が出ないとテストではもっと悪くなる
データ取得 ハンドリング 特徴抽出 学習準備 学習 テスト 原因調査
テスト 【目的】 • 未知のデータに対するモデルの振る舞いを確認する • 作成したモデルが”ある程度”汎用的に使えるものかを確認する 【やること】 • 学習済みのモデルで新しいデータを予測する •
正解と予測を評価関数に入れて、評価する
None
None
None
None
データ取得 ハンドリング 特徴抽出 学習準備 学習 テスト 原因調査
原因調査 【目的】 • モデルが苦手としてるサンプルの特徴を見つける • 新しい特徴量の抽出に知見を生かす 【やること】 • 誤答したサンプルの特徴量を洗って、傾向を分析する •
誤答の分布をプロットしたり、散布図描いたりする • 既存の特徴量だけでは識別が難しそうな場合は、新しい特徴量の作成方法を考える
Conclusion
【ねらい】 • データ分析の全体像がわかる • 業務内容が理解できる • モデルの雰囲気がわかる • 実験レポートの6割くらい理解できるようになる どうですか?わかりましたか?
考えることたくさんあるので、細かいところは理解できなくても大丈夫です。 全体的にこういう感じか〜〜という流れができていれば十分です。
おわり
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ロジスティック回帰 【概要】 • 名前は回帰だけど、分類のモデル • 線形回帰にロジスティック関数(下図)を導入して出力の範囲を[0, 1]に収めたもの 【気持ち】 • 線形回帰がわかってれば、理解は多少楽](https://files.speakerdeck.com/presentations/778104567078411682a2daa3b4b96dea/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}