Movie (in Japanese)
---
CloudNative Days Spring 2021 ONLINE
Observability is important to operate Cloud Native applications.
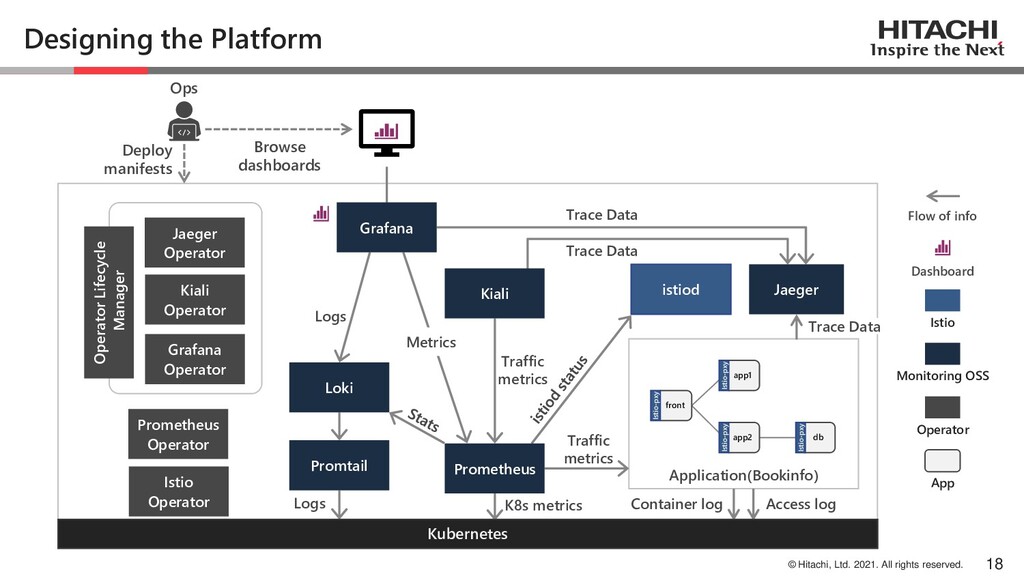
Currently, there are a variety of OSS and their operators to achieve observability. Integrating those OSS into Istio enables us to construct a platform to acquire metrics related to user experience, such as latency and error rate, without modifying the application.
However, there is not much information about the case studies of constructing and operating the platform. Each user is working on constructing the environment by trial and error.
In this session, we will introduce the knowledge we have gained while constructing an Observability platform integrating Istio and observability OSS (Prometheus, Loki, Jaeger, Grafana) and operating it using Operator.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}