Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
RDFization of biomedical databases
Search
Tazro Inutano Ohta
September 28, 2017
Research
280
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
RDFization of biomedical databases
第6回生命医薬情報学連合大会 (IIBMP 2017) BoF "セマンティックウェブ時代におけるバイオデータベースとデータ解析の融合" 「生命科学DB構築におけるRDF化の実践」
Tazro Inutano Ohta
September 28, 2017
More Decks by Tazro Inutano Ohta
See All by Tazro Inutano Ohta
Yevis: System to support building a workflow registry with automated quality control
inutano
0
160
Standardization of biological sample information database
inutano
0
110
Describe data analysis workflow with workflow languages
inutano
5
6.2k
Container virtualization technologies and workflow languages improve portability and reproducibility of data analysis environment
inutano
3
380
次世代シーケンサーによるメタゲノム解析:桜の花びらに付着した環境DNAを解析する
inutano
0
130
Workflows that run everywhere and where to run them
inutano
0
200
The Sequence Read Archive search system to make use of public high-throughput sequencing data
inutano
0
330
Improve portability of bioinformatics software across HPC and cloud infrastructures
inutano
1
150
Container, Cloud, and HPC
inutano
0
200
Other Decks in Research
See All in Research
Apache Gravitinoで実現する Icebergカタログ統合とアクセスの一元化
matsumooon
0
350
研究室単位での自律的 IPv6接続性確立に向けたAS共同運用モデルの提案と実証
reokashiwa
PRO
0
150
Model Discovery and Graph Simulation: A Lightweight Gateway to Chaos Engineering
anatolykr
0
220
2026年度 生成AI を活用した論文執筆ガイド/ワークショップ / 2026 Academic Year Guide to Writing Papers Using Generative AI - Workshop
ks91
PRO
0
190
敵対生成プロンプト同時探索による内省型プロンプト最適化
kinoue_smarthr
0
310
データサイエンティストの就労意識~2015 → 2026 一般(個人)会員アンケートより
datascientistsociety
PRO
0
230
オーストリア流 都市の公共交通サービス水準評価@公共交通オープンデータ最前線2026
trafficbrain
0
210
多様なデータを許容し学習し続ける模倣学習 / Advanced Imitation Learning for VLA
prinlab
0
240
重要だけど測れていないもの:高齢者ケアの見えない課題
theoriatec2024
0
410
長時間動画QAにおけるマルチエージェント推論 ・SVAgent: Storyline-Guided Long Video Understanding via Cross-Modal Multi-Agent Collaboration
murakawatakuya
1
160
論文紹介:HalluCitation Matters
wasyro
0
130
Dual Quadric表現を用いた動的物体追跡とRGB-D・IMU制約の密結合によるオドメトリ推定
nanoshimarobot
0
440
Featured
See All Featured
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
Game over? The fight for quality and originality in the time of robots
wayneb77
1
220
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
350
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Mind Mapping
helmedeiros
PRO
1
280
GraphQLとの向き合い方2022年版
quramy
50
15k
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.3k
Producing Creativity
orderedlist
PRO
348
40k
Gemini Prompt Engineering: Practical Techniques for Tangible AI Outcomes
mfonobong
2
460
Optimizing for Happiness
mojombo
378
71k
Paper Plane (Part 1)
katiecoart
PRO
1
9.7k
Statistics for Hackers
jakevdp
799
230k
Transcript
生命科学DB 構築におけるRDF 化の実践 IIBMP 2017 BoF: SemWeb 時代におけるバイオデー タベー スとデー
タ解析の融合 ライフサイエンス統合デー タベー スセンター (DBCLS) 大田達郎 @inutano
話すこと 「 デー タをRDF 化する」 とは、 技術的に何をするのか 伝えたいこと 使いやすいデー タを共有してみんなで科学をやっていきましょう
RDF はそれを助ける1 つの有力な選択肢だが、 真に大事なのは作法 伝えたい人 測定/ 解析したデー タを公開する人、DB を作る人 生物学的解釈が付与される余地のあるデー タを出力するソフトウェ アを作っている人
宣伝 第2 回 RDF 講習会「RDF の作り方」 10/6 ( 金) @
JST 東京本部別館 ( 市ヶ谷) "RDF 講習会" で検索
問題: 公開されたデー タを使うと捗らない
公開DB を使うときに何をしますか 理想 URL 叩くと即、 自分の欲しい形でデー タが落ちてくる 現実 ウェブサイトを探す (
が見つからないもしくは落ちている) とりあえずダウンロー ド ( サイトにそれ以外何もないので) 謎の.tar.gz が落ちてくる ( 一晩かかる) 雑に展開してみる ( たまに開かない) 何かが入っている ( が何かよくわからない) README を読んでデー タ構造を調べる ( が何も書いてない) パー サー を書いて必要な部分を取り出す ( 何度も例外で落ちる) デー タの意味を調べるのに再度ドキュメントを読む ( つらい)
つらい 別ドメインのデー タをさらに結合するなんて考えたくもない
デー タ作る方もつらい ユー スケー スは10^n 人10^n 色 マニアックな使い方をされてこその研究資源 その全てを予測することはできない 「
自分でやれ」 ラインの見極めの難しさ なるべく柔軟なインター フェー ス、 柔軟な形式で用意したい と、 少なくとも思ってはいる
解決策: デー タ提供者が守るべきN 個のお作法
どうあってほしいのか ウェブサイトに情報を載せてくれ ドキュメント書いてくれ エントリID を体系的に管理してくれ 関連リソー スへのリンクを張ってくれ 変な略語使うのをやめろ 文字コー ドちゃんとしろ
特殊すぎる( 圧縮| 通信) プロトコルを使うな デー タ扱うのに特殊なソフトウェアを要求するな => どうすればデー タ提供者は従ってくれるのか?
FAIR principles www.force11.org/group/fairgroup/fairprinciples be Findable be Accessible be Interoperable be
Reusable => これらを突き詰めると Linked Data になる
Linked Data: is a method of publishing structured data built
upon standard Web technologies such as HTTP, RDF and URIs to share information in a way that can be read automatically by computers, from Wikipedia
Linked Data: お行儀の良いデー タ養成ギプス URI を使え デー タはRDF で表現しろ URI
にHTTP でアクセスされたらRDF も返せ
RDF 化の機運が高まる みんなやってるよ、 怖くないよ NBDC/DBCLS/DDBJ/PDBj SIB EBI RDF NCBI PubChem/MeSH
でもRDF 化って実際何をするの
パター ンA: RDB に入った表形式のDB から作る 1. 行ごとにURI で一意なID を付与する 2.
列のキー ワー ドを標準的な語彙 (predicates) に置き換える 3. 機械的に変換する 便利: D2RQ and D2RQ Mapper
パター ンB: NoSQL に入ったドキュメント型DB から作る 1. エントリごとにURI で一意なID を付与する 2.
適切なモデルを設計する 3. 必要な語彙を既存のオントロジー から選ぶ、 なければ作る 4. コンバー タ書いて変換する
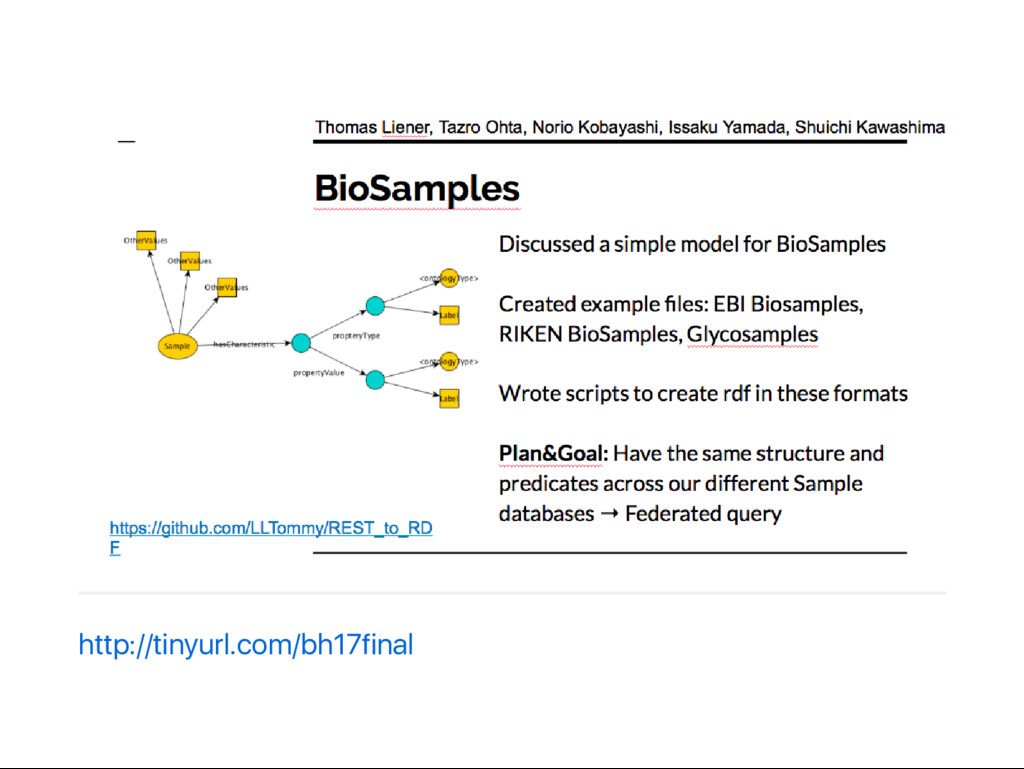
実例: BioSamples w/ EBI‑RDF @ BH17 配列デー タをDDBJ に登録する際にサンプルの情報を書くアレ DDBJ,
EBI, NCBI で交換されている 登録ユー ザが独自に key‑value を設定できる 元デー タはXML RDF モデルはEBI BioSamples API JSON の構造を流用 key‑value については適切な構造を設計した 語彙を決める ないものについては新規に作る コンバー タを書く API ‑> JSON ‑> RDF Turtle
http://tinyurl.com/bh17final
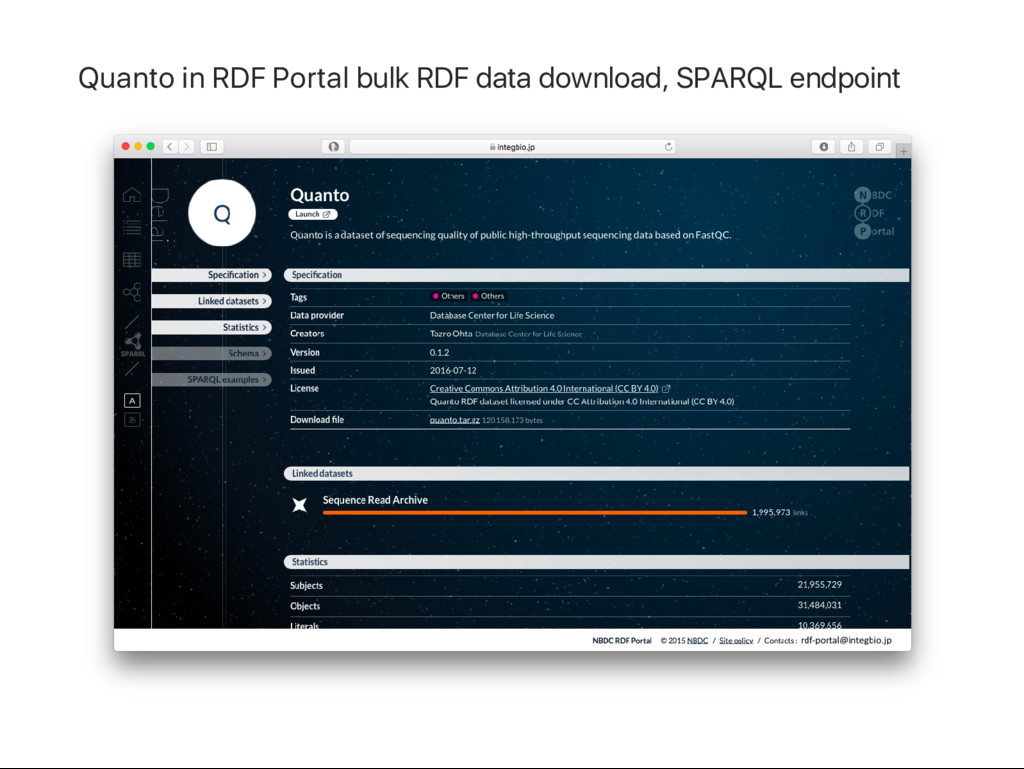
実例: Quanto Available at inutano/sra‑quanto and RDF Portal エントリ単位は FASTQ
ファイル単位 元デー タは FastQC の出力とそこから計算した値 テー ブルを内包するオブジェクト デー タモデルを作る bioruby‑fastqc で設計したオブジェクトの構造のままJSON に 必要な語彙を既存のオントロジー から選び、 ないものは作った コンバー タを書く JSON にcontext を追加してJSON‑LD に JSON‑LD からrdf/turtle に自動変換 txt ‑> JSON ‑> JSON‑LD ‑> RDF Turtle biogem になっています
元デー タ はただのテキストファイルなのでこれをパー スしてJSON オブ ジェクトに変換し、context を付与して JSON‑LD にする
RDF モデル made with draw.io
Quanto in RDF Portal bulk RDF data download, SPARQL endpoint
ね、 簡単でしょ? 全然簡単じゃない 特に語彙を探す/ 選ぶ/ 作るところがつらい BioPortal, EBI OLS 等があるが、
結局人に聞いている 独りでは難しい グルー プで取り掛かることでかなりコストを下げられる BioHackathon, SPARQLthon, etc.. いずれにせよ筋力の問題なのでやっていくしかない
RDF にすることで全ての問題が解決したか ウェブサイトに情報を載せてくれ: 筋力 ドキュメント書いてくれ: 筋力 エントリID を体系的に管理してくれ: URI を使う
関連リソー スへのリンクを張ってくれ: RDF でリンクを張る 変な略語使うのをやめろ: 適切な語彙を使う 文字コー ドちゃんとしろ: UTF‑8 or フォー マットの指定に従う 特殊すぎる( 圧縮| 通信) プロトコルを使うな: HTTP GET !!! デー タ扱うのに特殊なソフトウェアを要求するな !!! No Silver Bullet: RDF にすれば何もかも解決するとは誰も言ってない
特殊なソフトウェアを要求するな TripleStore, SPARQL は特殊か否か 依然扱える人は少ない 派閥 W3C 標準なんだからSPARQL 使おうよ派 いいからJSON
返せ、 あとはこっちでなんとかするから派 Neo4J ではあかんのか派
コストが十分下げられるなら提供する選択肢は増やすべき 元デー タ ‑> JSON ‑> JSON‑LD ‑> RDF の流れは比較的容易
JSON‑LD は @context を無視すればただの JSON エンドポイント SPARQL RESTful API smart API that returns JSON‑LD Elasticsearch バルクダウンロー ド 作法に則ったデー タとこれらが揃えば別ドメインのデー タと繋ぐことも 難しくない( はず)
繋がったその先: グラフ解析手法にそのまま入力できるのか Heterogenous Network: ノー ド、 エッジにバリエー ションがある 異なるDB 間で同じ概念を表すために別の
ontology term が使 われている場合がある => 別DB のRDF デー タを混ぜたグラフを作る際に、 語の使われ 方の違いが解析の精度に影響を及ぼすのでは? RDF 化されたデー タベー スはあらゆるものが繋がっている 不要なメタデー タ ( 登録の日付, デー タ登録者の所属, 文献ID, etc.) なども => 解析に必要なサブグラフをいかに簡単に取り出すか? そのデー タはグラフ化に向いているか bigBed をRDF にすることは技術的には可能だが…
まとめ 作法に則ってデー タを作りましょう コミュニティに参加して協調すると捗る デー タ元がやってくれないなら自分でやる RDF 化とはすなわち「 ちゃんとする」 こと
あなたとFAIR、 今すぐ実装 RDF とJSON‑LD, 目的に合ったものを使えるように デー タ解析にとっては異なる種類の前処理が必要になる可能性
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}