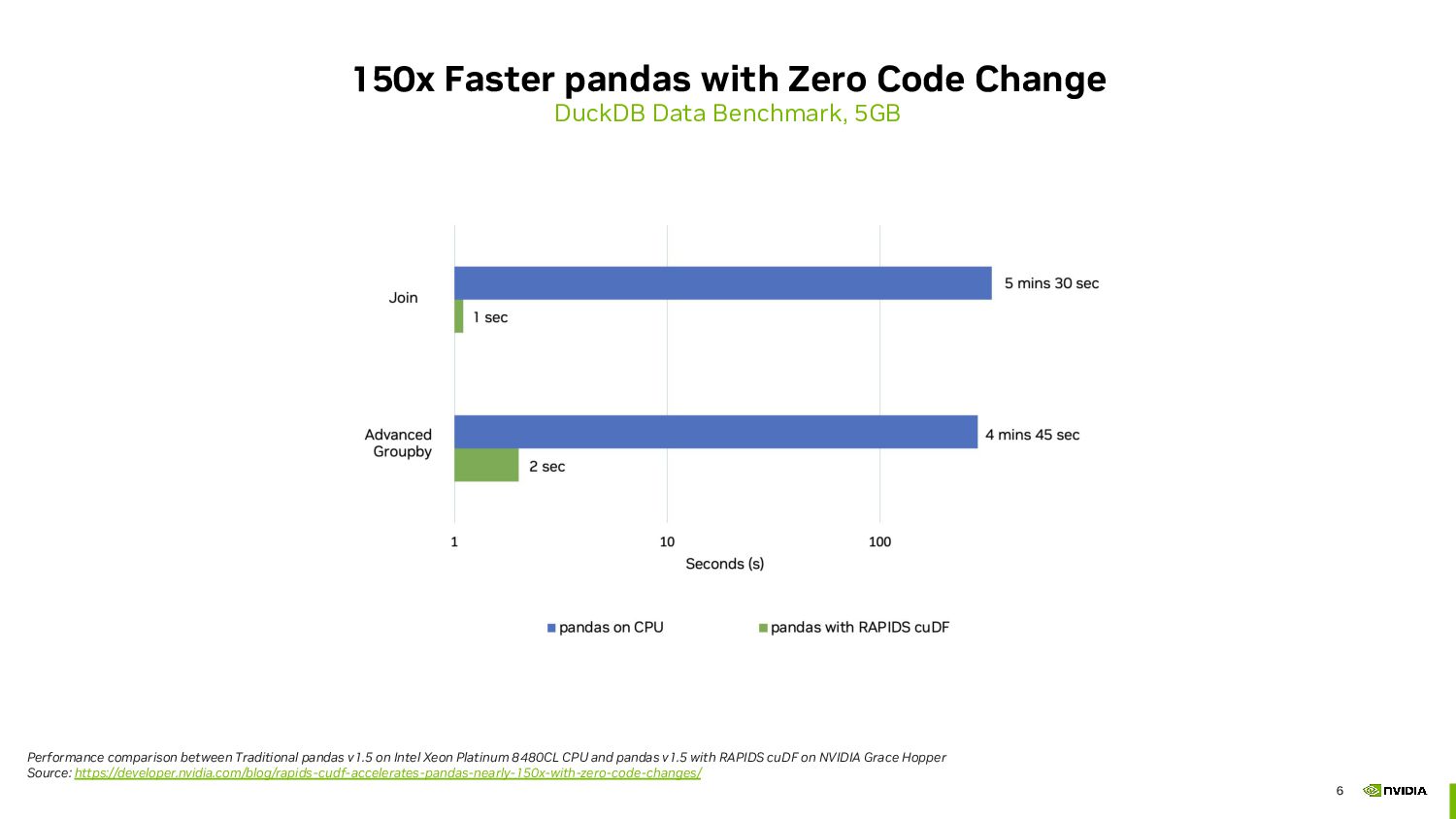
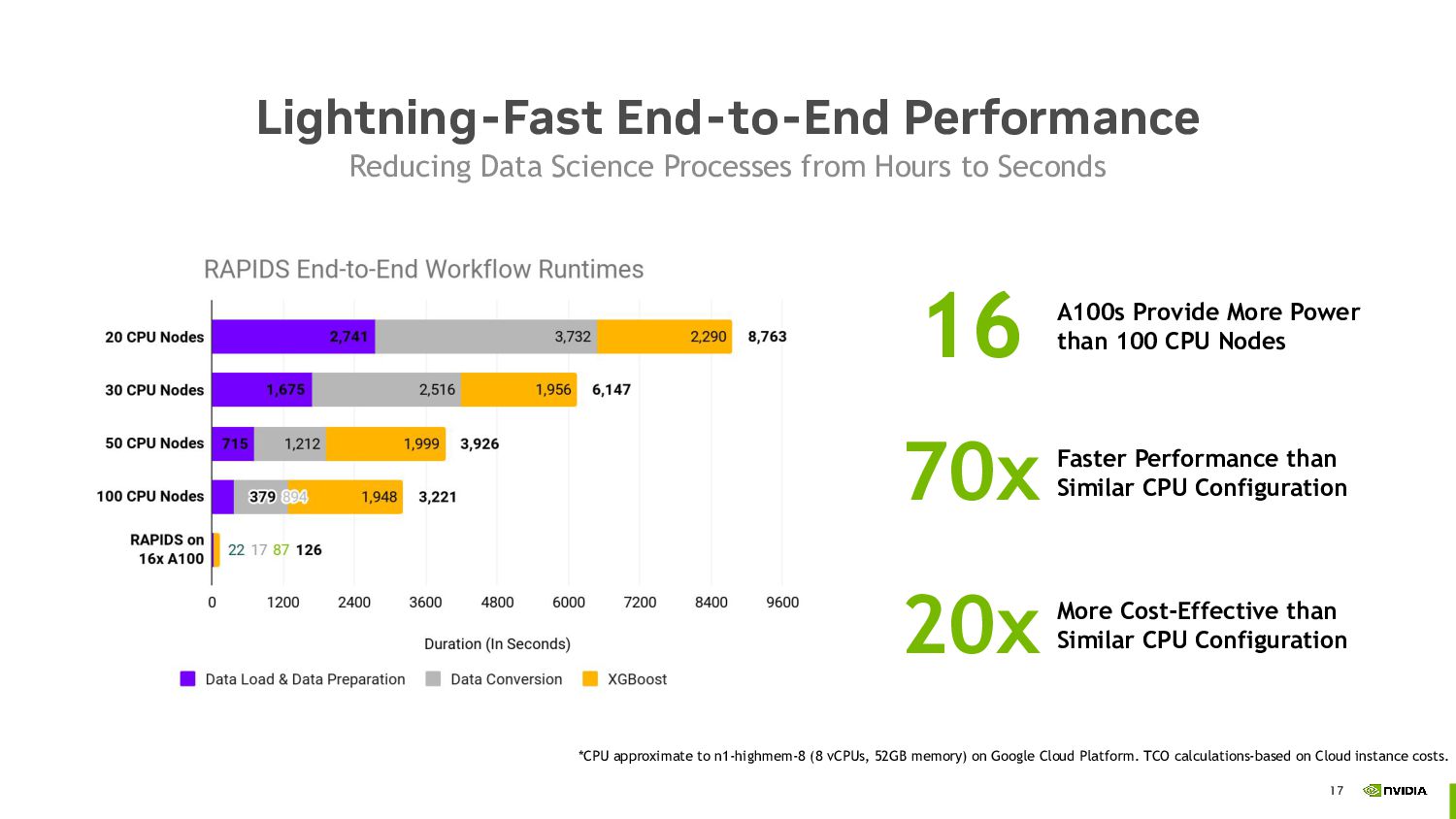
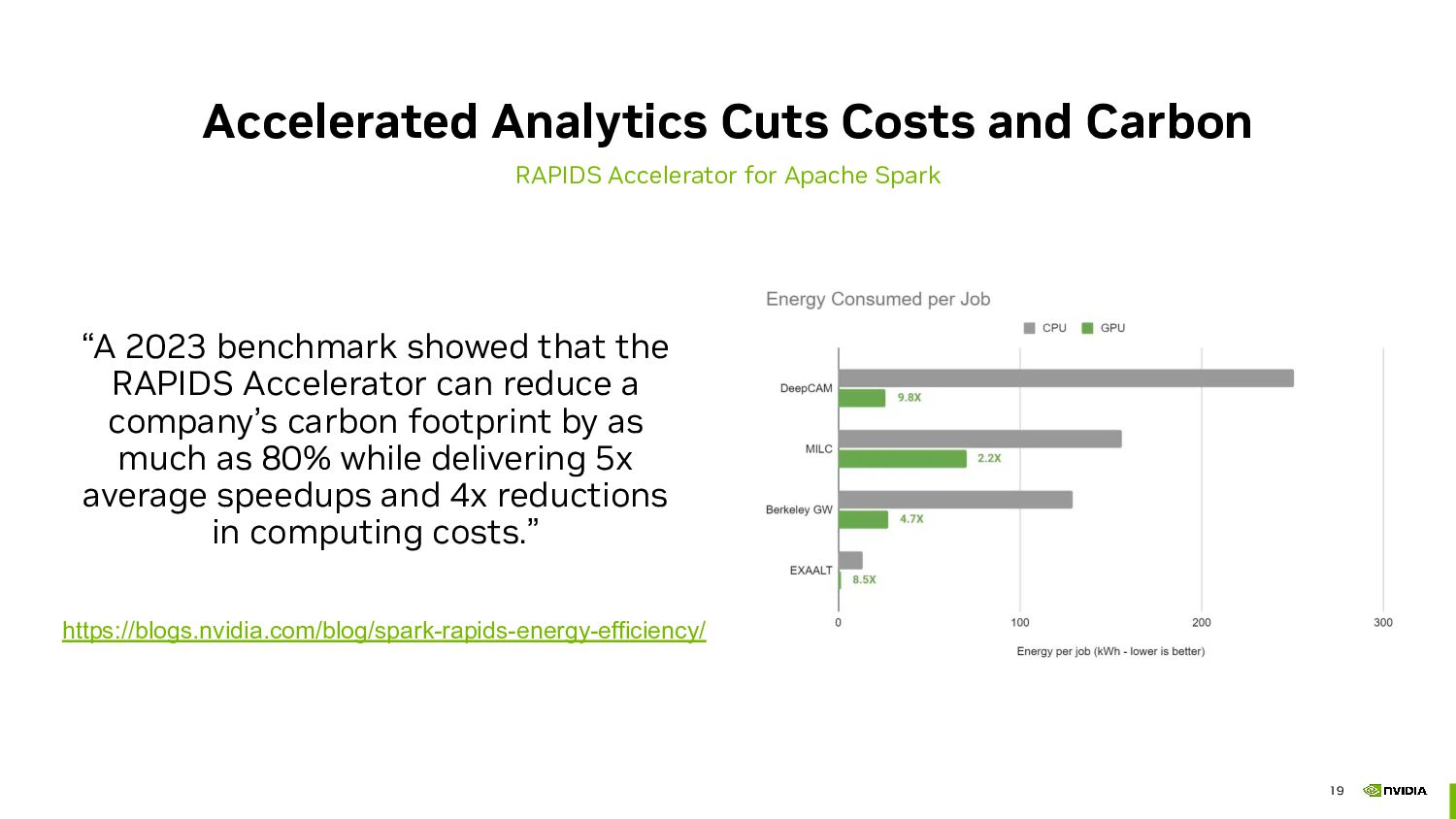
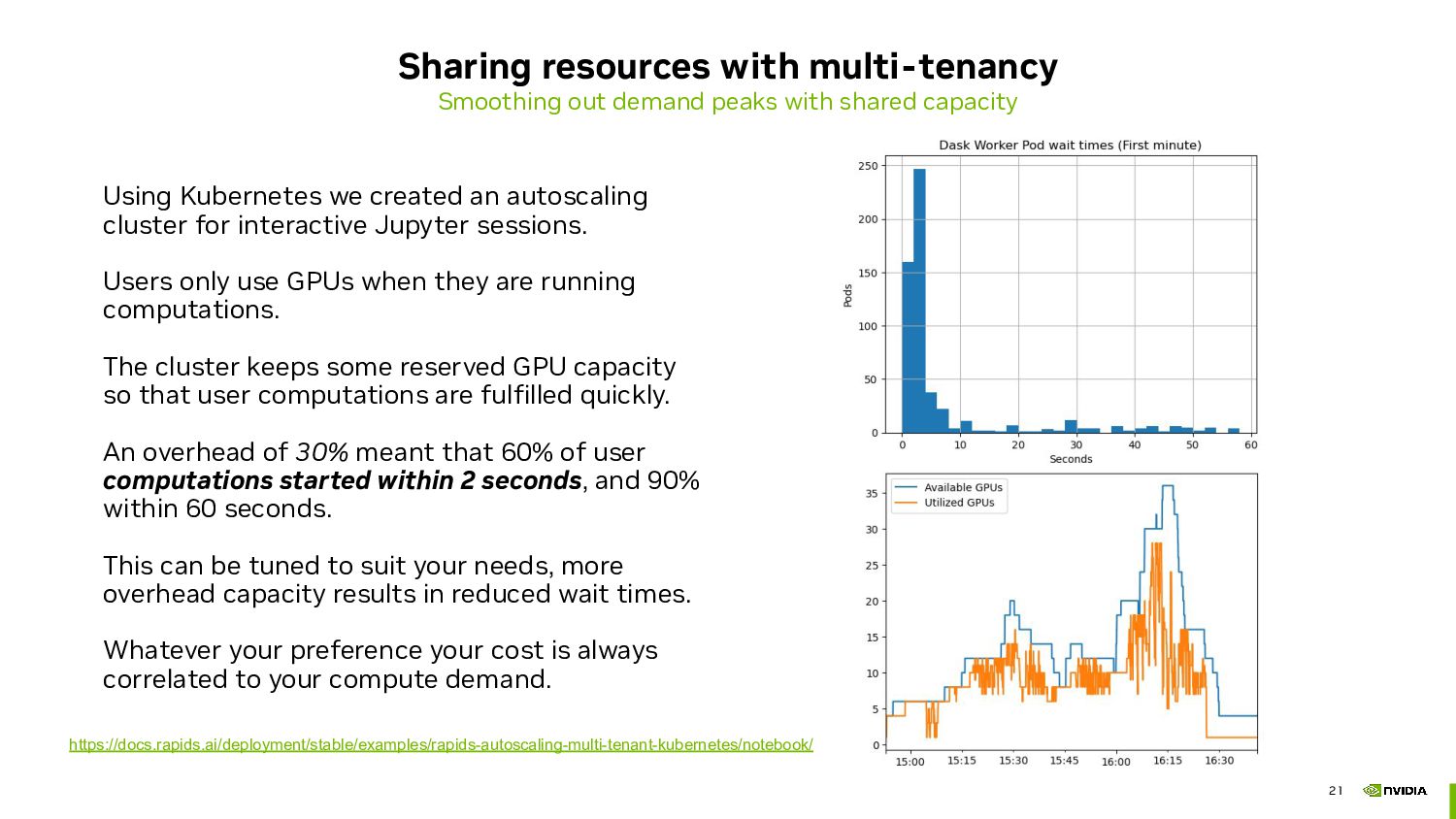
By leveraging cloud computing resources, you can pay for just the computing power you need, when you need it. Additionally, GPU acceleration can significantly decrease the amount of time you need computing resources, reducing your overall cost.
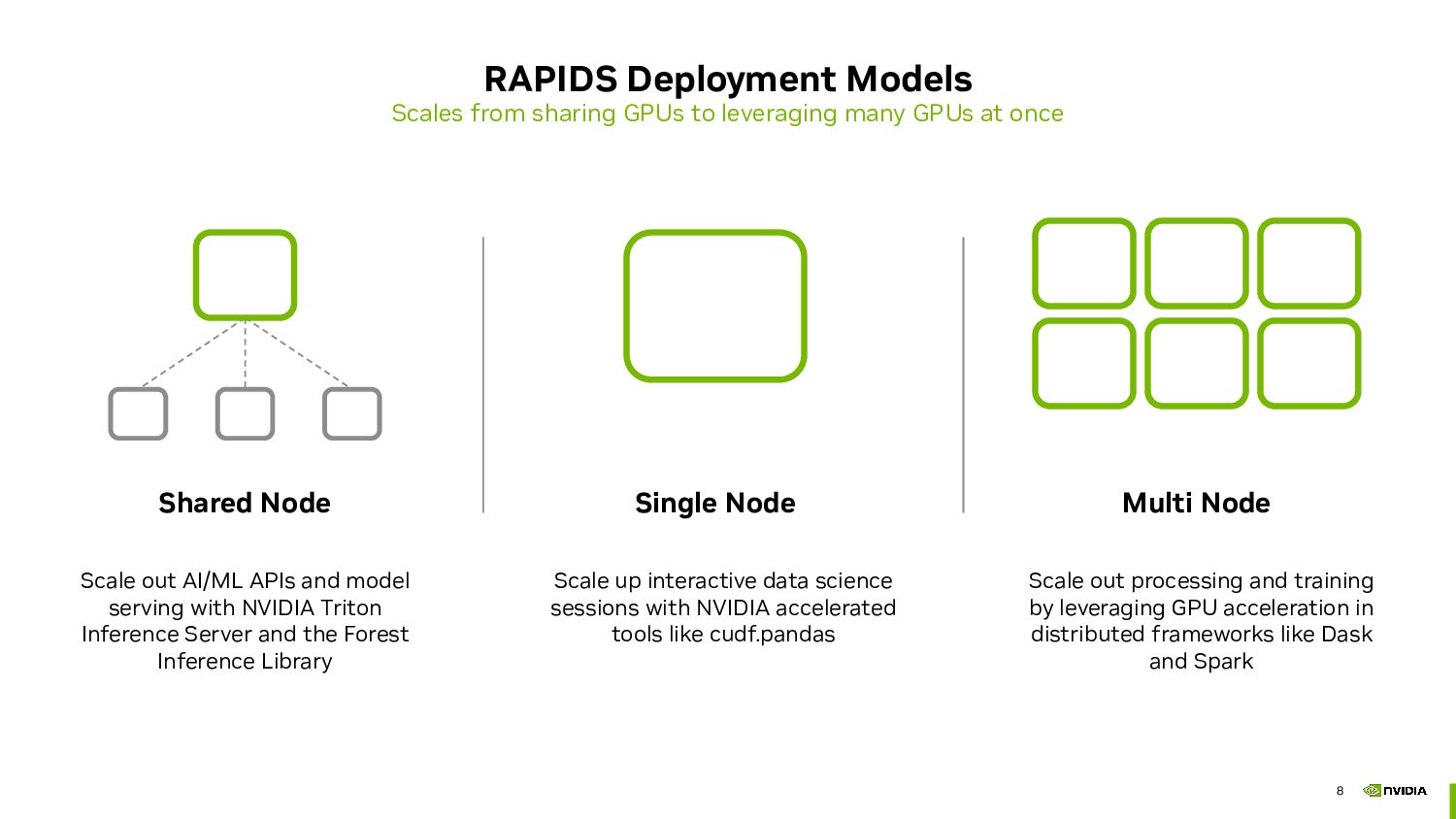
We'll discuss RAPIDS, an open-source collection of Python libraries that offer exceptional speed in data science tasks. RAPIDS provides familiar APIs from popular PyData libraries, making it simple to run your data science workloads in the cloud. By using RAPIDS, you can scale your workload and get things done faster and more efficiently.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}