Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Monitoringについてあれこれ語ろう - A Feedback from Cloud N...
Search
Kazuto Kusama
March 19, 2019
Technology
3.7k
9
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Monitoringについてあれこれ語ろう - A Feedback from Cloud Native Deep Dive
Rancher Meetup #18で発表した資料です。
Monitoring、Logging、Alertingについてディスカッションした結果をまとめて共有しました。
Kazuto Kusama
March 19, 2019
More Decks by Kazuto Kusama
See All by Kazuto Kusama
趣味でイベント配信をやっている者だ
jacopen
1
25
自宅LLMの話
jacopen
2
900
プラットフォームエンジニアリングはAI時代の開発者をどう救うのか
jacopen
9
5.5k
OpenClawで回す組織運営
jacopen
3
1.3k
SREの仕事を自動化する際にやっておきたい5つのポイント
jacopen
6
1.7k
AI時代のインシデント対応 〜時代を切り抜ける、組織アーキテクチャ〜
jacopen
4
410
AI時代の開発とPlatform Engineeringについて考える
jacopen
0
270
AI によってシステム障害が増える!? ~AI エージェント時代だからこそ必要な、インシデントとの向き合い方~
jacopen
4
420
インシデント対応に必要となるAIの利用パターンとPagerDutyの関係
jacopen
0
450
Other Decks in Technology
See All in Technology
OpenTelemetryにおけるGoのゼロコード・コンパイル時計装について #fukuokago
quiver
0
280
AI_Dev_Day_製造業領域でのAI活用から見た活用の罠と成功に導く実践知.pdf
kintotechdev
0
180
10年目を迎えた「ABEMA」がどのように AI 活用を推進して、AI 駆動開発にシフトしているのか / How ABEMA, entering its 10th year, is promoting the use of AI and shifting toward AI-driven development
miyukki
0
370
AI時代の開発生産性は、個人技からチーム設計へ
moongift
PRO
4
2.6k
大 AI 時代におけるC# の事情 ~ぶっちゃけトークを交えながら~
nenonaninu
1
160
Webアプリ認証の全体像 / The Big Picture of Web App Authentication
kitano_yuichi
1
440
副作用のある Lambda でも Lambda Power Tuning は使えるのか / lambda-power-tuning-side-effects
koukihosaka
2
150
AI x 開発生産性を取り巻く予算戦略と投資対効果
i35_267
7
3.1k
AI時代こそ、スケールしないことをしよう -「作る人」から「なぜ作るか」を考える人へ / Do Things That Don't Scale in the AI Era — From How to Why
kaminashi
1
110
テックカンファレンス三大ステークホルダーの文化人類学 ─ 違いを認め合う関係性作り
bash0c7
1
260
AWS環境のセキュリティ不安を解消した企業事例 ~よくある課題と対策を一挙公開~
asanoharuki
0
150
AI、CDK と協働する Full TypeScript アプリケーション開発 / Full TypeScript Application with AI and CDK
geekplus_tech
2
490
Featured
See All Featured
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.4k
A better future with KSS
kneath
240
18k
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
Speed Design
sergeychernyshev
33
1.9k
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
420
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
My Coaching Mixtape
mlcsv
0
180
Making Projects Easy
brettharned
120
6.7k
AI: The stuff that nobody shows you
jnunemaker
PRO
9
840
Chasing Engaging Ingredients in Design
codingconduct
0
240
Evolving SEO for Evolving Search Engines
ryanjones
0
240
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
Transcript
A Feedback from Cloud Native Deep Dive Monitoringについてあれこれ語ろう
Pivotal Japan - Solutions Architect Kazuto Kusama @jacopen
None
None
Cloud Native Deep Dive • 従来ながらの講義形式は取らない • あらかじめ決められたテーマについて、全員参加で ディスカッションを行う •
ディスカッションを通じて、実戦で使える知識と経験を深め ていく • 参加登録時にはアンケート回答が必須。 アンケート未回答者は参加不可。
テーマ #1 Manifest管理 #2 Service Mesh #3 Release Engineering #JKD
総集編 #4 Monitoring
今回は、#4の内容を 共有します
- Monitoring - Logging - Alerting
Monitoring
- Blackbox Monitoring - Whitebox Monitoring 分けて考えるべき
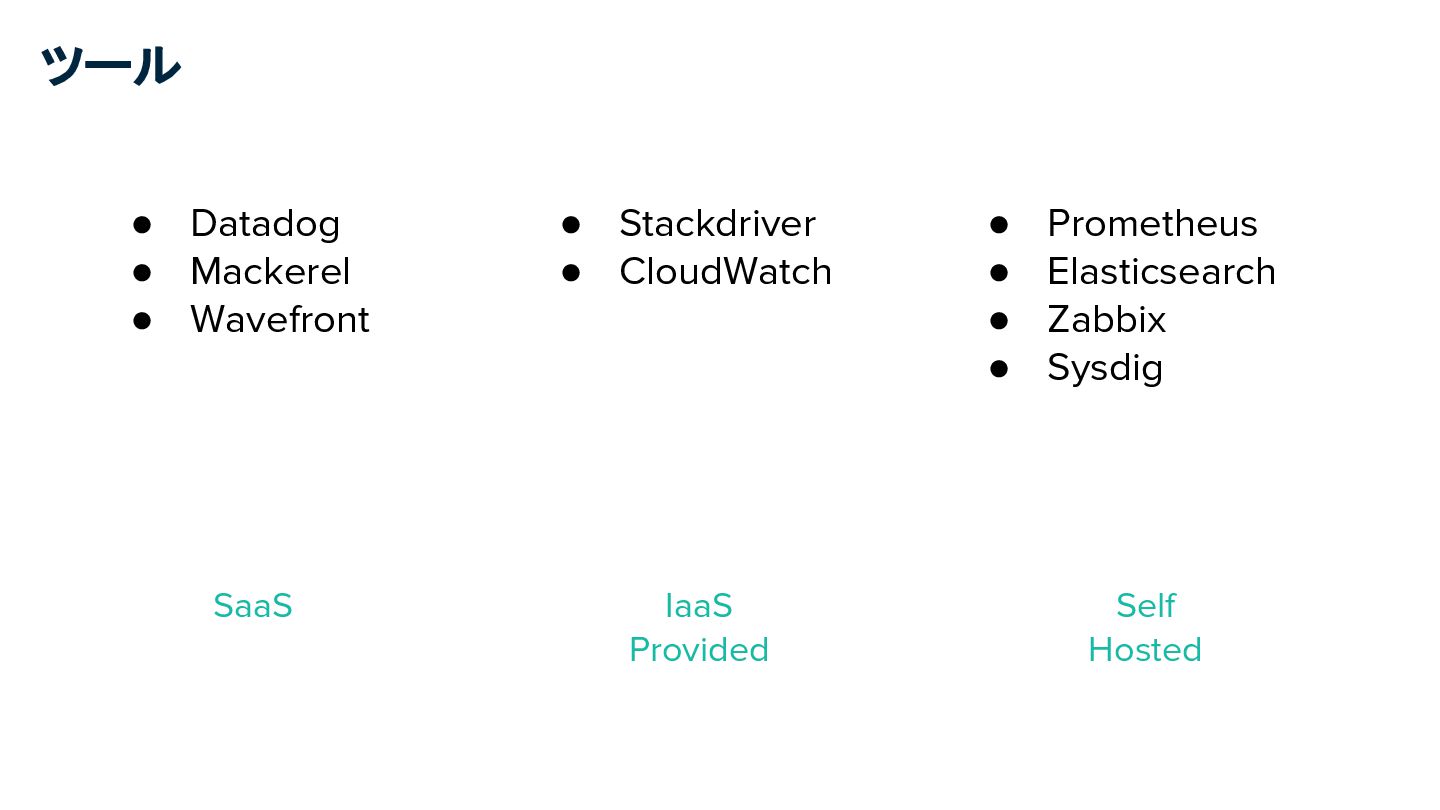
ツール • Datadog • Mackerel • Wavefront • Stackdriver •
CloudWatch • Prometheus • Elasticsearch • Zabbix • Sysdig SaaS IaaS Provided Self Hosted
監視する対象 • Baremetal • VM • Container • Security •
Networking • Backend • Frontend • Business KPI ・・・他にもいろいろ • Pod • Node • Cluster
みんなの課題 • どんなメトリクスを監視すればいいのか ◦ Kubernetesだけでも膨大な種類のメトリクスが • Kubernetesのクラスタ管理者とアプリ開発者への 通知切り分け • ロングタームのメトリクス管理方法・
ダウンサンプリング方法
みんなの課題 • 外れ値出たときどうするか? ◦ ここのハンドリング重要 ◦ DatadogやElasticsearchには検出する機能があるが・・・
みんなの課題 • Prometheusのメモリ使用量多い • モニタリングのモニタリング • そもそもPrometheus難しい ◦ relabel_configs ◦
PromQL ▪ Prometheusおじさんの発生!
みんなの課題 • Dashboardの作り方 ◦ JSONのレビュー大変 ▪ GrafanaならDashboard Shopあるが・・・ ◦ できる限りコード管理したい
▪ Grafanaでexportするたびに形が変わっててキツい • Jsonnetで生成⇒Grafanaに反映 を試そう • (Prometheusの場合) Prometheus Operator良い ◦ 最初からいい感じに作り込まれている ◦ 必要ならば自分で拡張することも出来る
みんなの課題 • そもそもDashboardいつ見る? ◦ 常に見る? ◦ デプロイ時に見る ◦ 週次でみる ◦
朝会時に見る ◦ 常に廊下に表示させる
みんなの課題 • Monitoring 101は読んでおくべき ◦ https://www.datadoghq.com/blog/tag/monitoring-101/
Logging
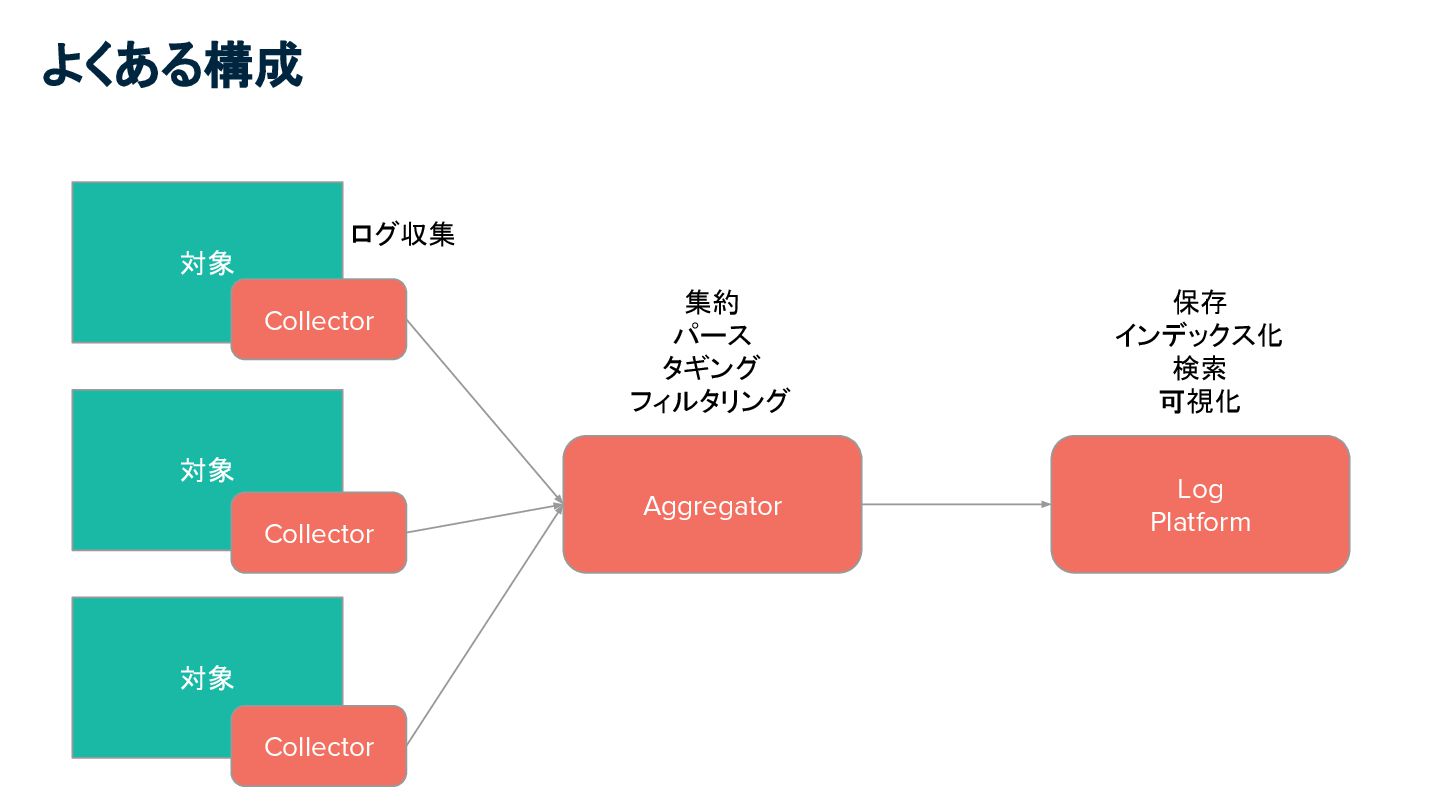
よくある構成 対象 対象 対象 Collector Collector Collector Aggregator Log Platform
ログ収集 集約 パース タギング フィルタリング 保存 インデックス化 検索 可視化
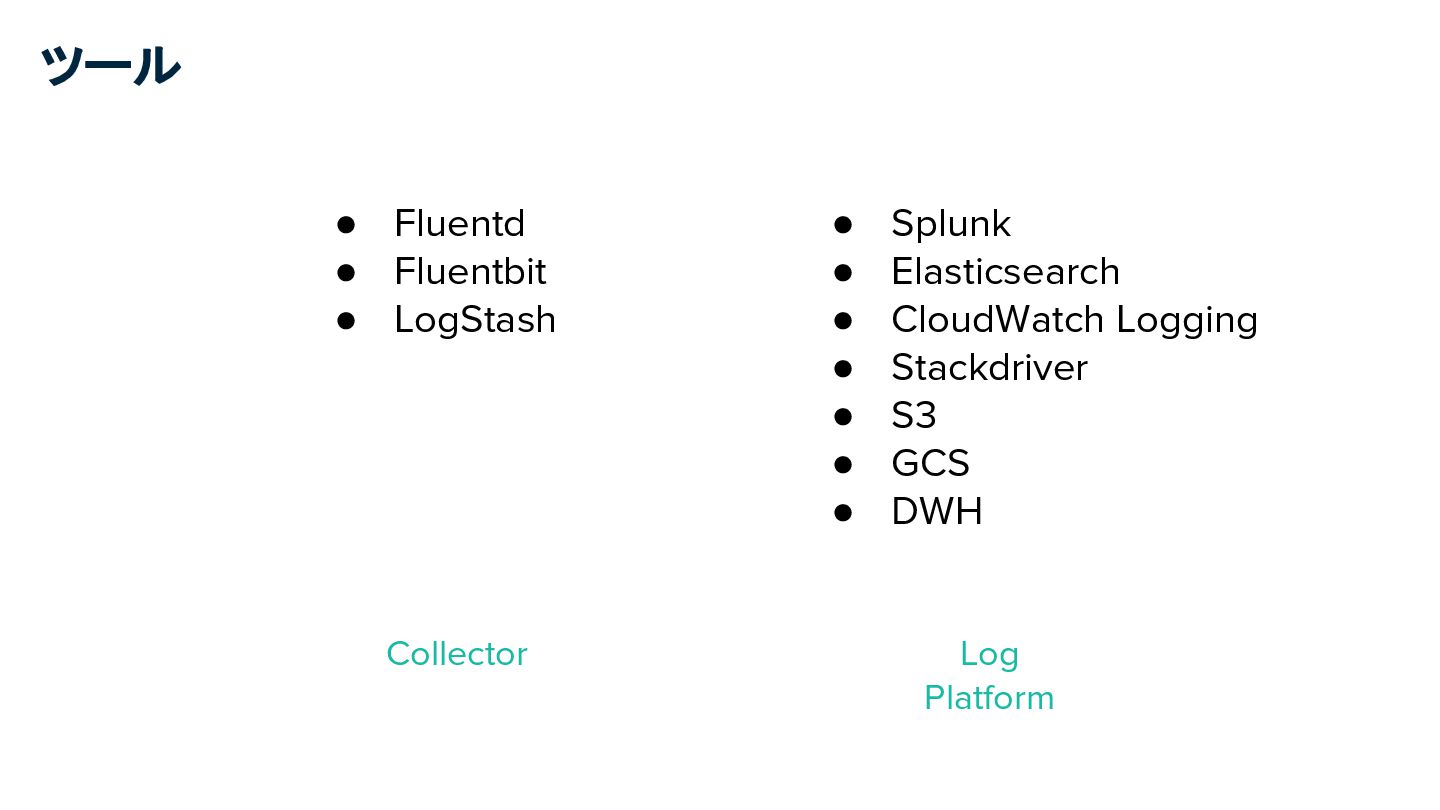
ツール • Fluentd • Fluentbit • LogStash • Splunk •
Elasticsearch • CloudWatch Logging • Stackdriver • S3 • GCS • DWH Collector Log Platform
Logging =
Logging = 課金
みんなの課題 • ロギングはカネがかかる!! ◦ SaaS高い ▪ ログ量に比例してガンガン金がかかる ◦ Self Hostedにしてもかなりの運用・インフラコストかかる
▪ 最終的には監視対象と同じくらいのインフラリソースがログ基 盤だけで必要になることも ◦ 結局は金
みんなの課題 • Aggregatorの運用辛すぎ ◦ とにかくここが死ぬ ◦ ログの保存量を制御することは出来るが、 ログの流量を制御するのは難しい ▪ アプリ側が大量のログ吐くとすぐ死ぬ
▪ Collector側で工夫する?⇒収集すべきものとしないものの判 断難しい ◦ パースやフィルタリングなどをやりやすい場所 ▪ でも処理に比例して負荷が増す • 死
みんなの課題 • ログの形式バラバラ問題 ◦ ミドルウェアによって吐く形式が違う ◦ チーム間でもログ形式は往々にして異なる ▪ チーム間で形式統一を試みた⇒無理だった ◦
パースせずに生データで保存 ▪ 正規表現地獄 ◦ ログ基盤側でなんとかする ▪ 負荷で激重になる
みんなの課題 • ログとメトリクスの横断検索が難しい問題 ◦ 何か問題が発生したとき、特定の時刻・特定のコンポーネントにおい て、ログとメトリクスを突き合わせて見たい ▪ ログ基盤とメトリクスが分断していると、 横断して調べるのが辛い ▪
SaaSや商用ソフトウェアだと、この機能を 備えているものもある
Alerting
みんなの課題 • 閾値の根拠は? • 通知先 ◦ Slack ◦ Chatwork ◦
Pagerduty ◦ メール • オンコール担当は誰か ◦ アプリのログはアプリ開発者に ◦ 基盤のログは基盤運用チームに
みんなの課題 • 突発的なアラート対応による生産性低下 ◦ Scrum開発しているのに、アラート対応によってスプリント計画が めちゃくちゃに ◦ 不安定な生活リズムによる生産性の低下 ◦ ベロシティバラバラ
みんなの課題 • オンコール先任者・部門を作るか? ◦ 対象アプリや基盤の知識が無い人がオンコール対応しても、 結局そのままエスカレーションされる ⇒ コミュニケーションロス • オンコールローテーション
◦ オンコール対応後の休暇など、制度の確立も必要 ◦ 少人数のチームだとどうする?
みんなの課題 • 誤検知・過剰なアラーティングへの対応 ◦ アラートのレベル分け大事 • 閾値やアラートレベルの見直しはいつやるか ◦ 定期的に見直す ◦
アドホックに対応 • アラートルールのコード化はどうやるか
みんなの課題 • 通知すべきメトリクスのベストプラクティスはあるか? ◦ ない! ◦ そもそも組織によって結構異なる ◦ アラーティングは、運用しながら育てる意識を持つこと
共通課題
それぞれ共通する課題 • コード化・自動化 ◦ Toilは極限まで減らす意識を持つこと ◦ 監視ルールは育てていくもの • 対応する人・組織・ロール ◦
できる限り自動化が前提 ◦ 単にコールを受けるだけのロールは悪手になりやすい • OSSか商用製品かManaged Serviceか ◦ ケースバイケース ◦ 無理に自前主義に走るのは考え物
Cloud Native Deep Dive https://www.meetup.com/ja-JP/Cloud-Native-Deep-Dive/ まずはJoin!
CloudNative Days
技術書典6 https://techbookfest.org/event/tbf06/circle/56220002 チェックリストに 追加してね!
おわり
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}