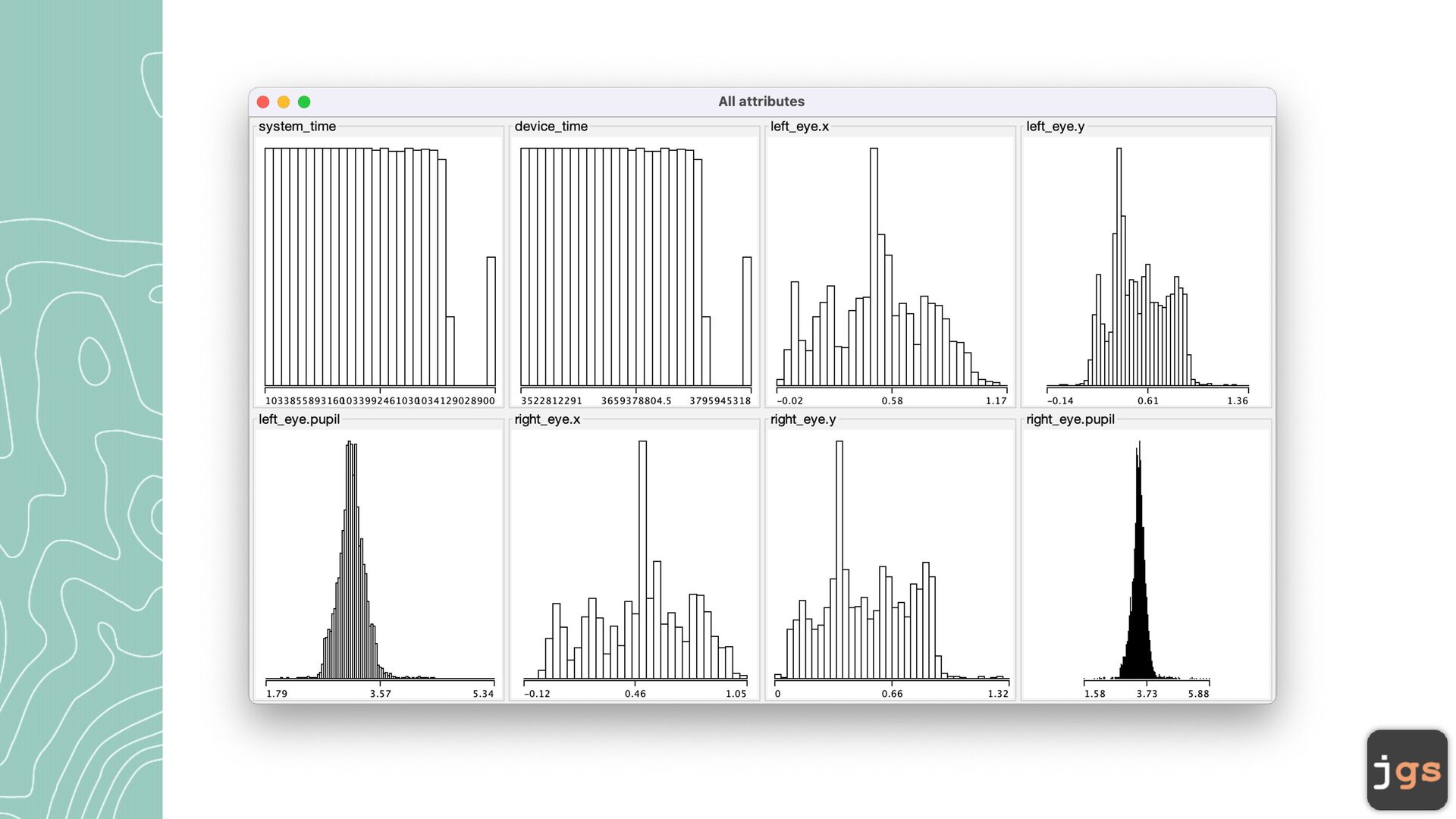
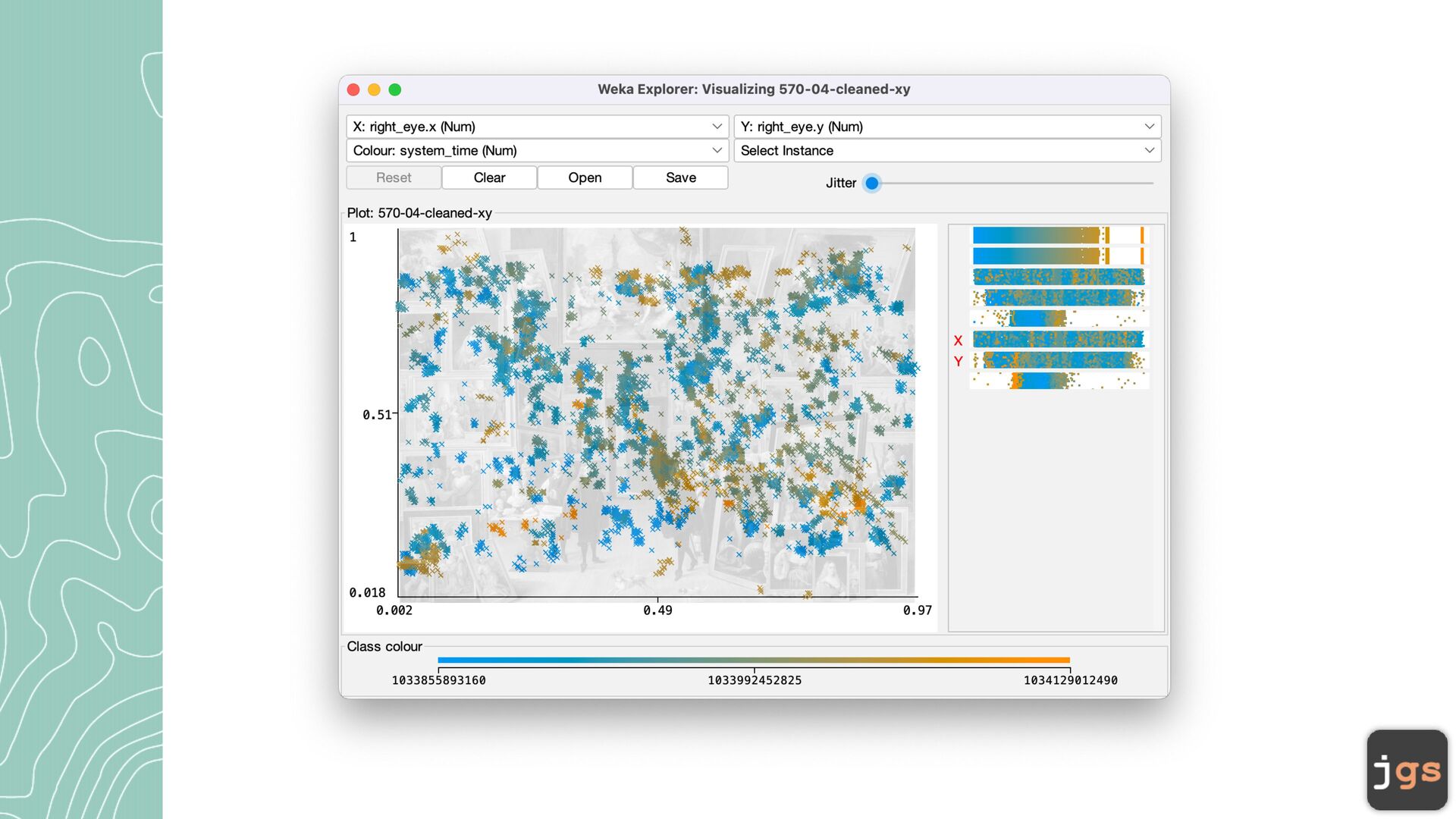
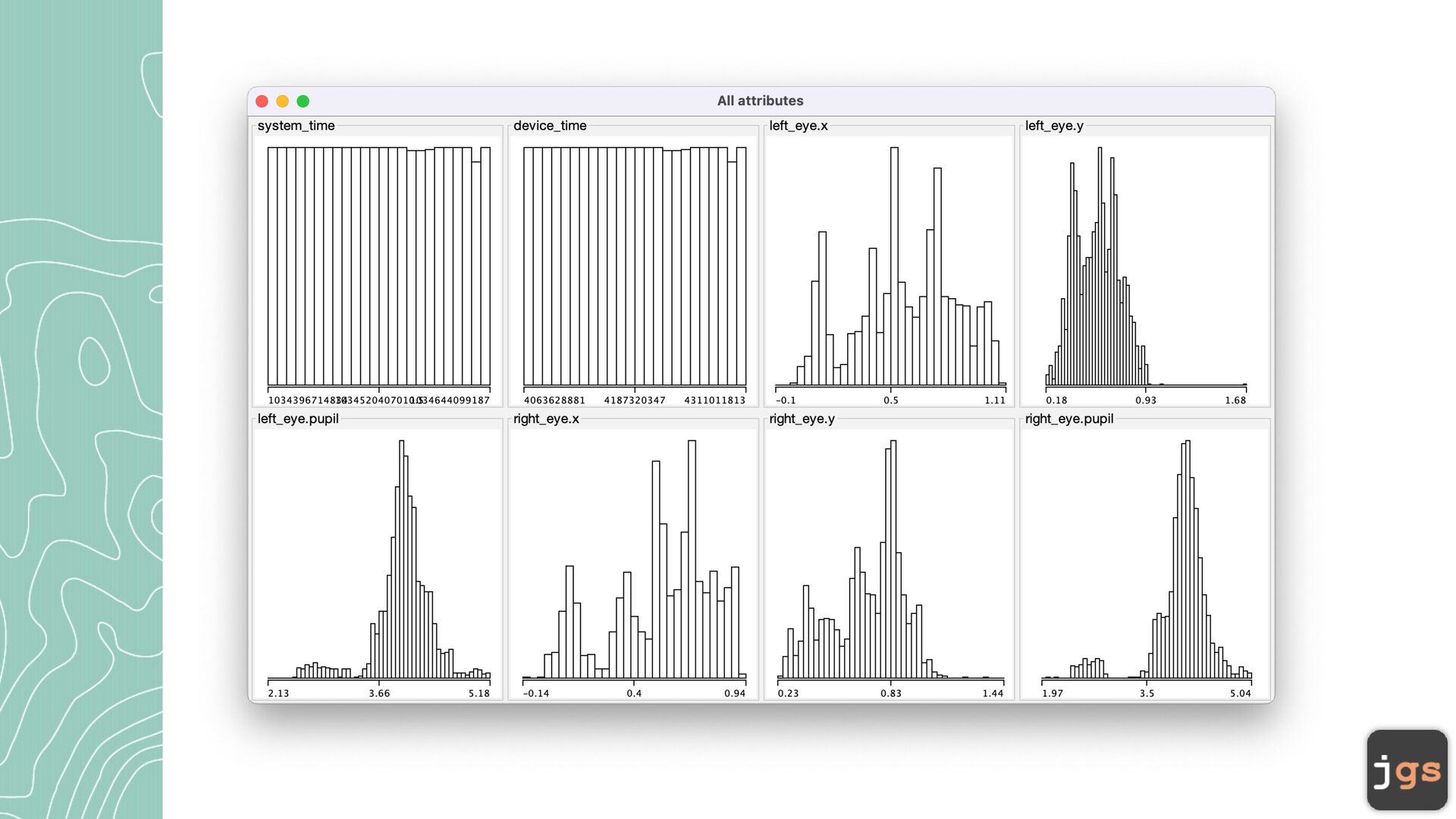
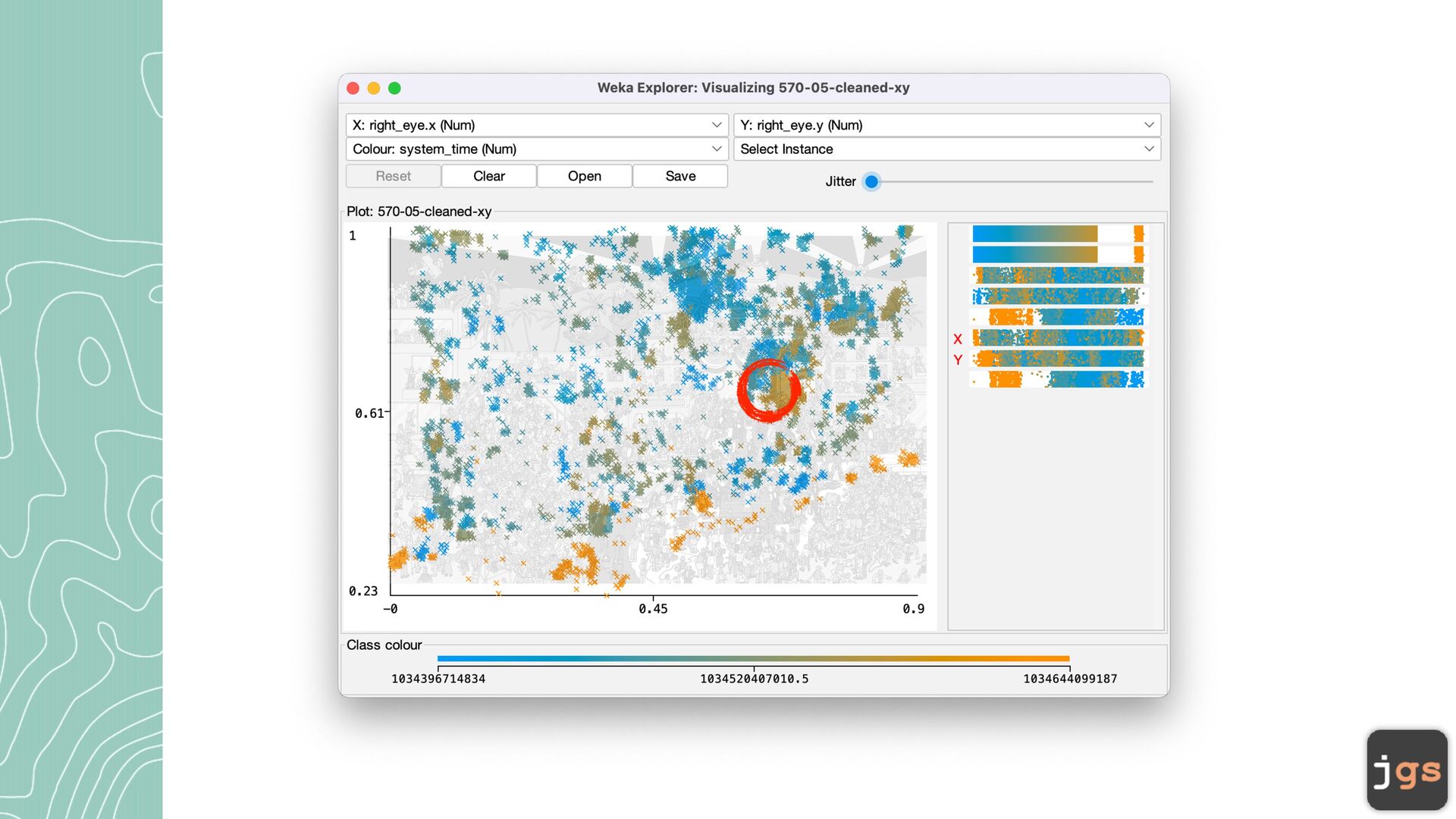
• DBSCAN (Density-Based Spatial Clustering of Applications with Noise) - distance between nearest points. • Simple EM (Expectation Maximization) is fi nding likelihood of an observation belonging to a cluster(probability). Maximize log-likelihood criterion 8
c a lcul a te the dist a nce between two fe a ture vectors is to use Euclidean Distance. • Other options: Minkowski dist a nce, M a nh a tt a n dist a nce, H a mming dist a nce, Cosine dist a nce, … 10
a ndomly pl a ced centroids. Centroids a re the center points of the clusters. • Iter a tion: • Assign e a ch existing d a t a point to its ne a rest centroid • Move the centroids to the a ver a ge loc a tion of points a ssigned to it. • Repe a t iter a tions until the a ssignment between multiple consecutive iter a tions stops ch a nging 11
cluster loosely related observations together. Every observ a tion becomes a p a rt of some cluster eventu a lly, even if the observ a tions a re sc a ttered f a r a w a y in the vector sp a ce • Clusters depend on the me a n v a lue of cluster elements; e a ch d a t a point pl a ys a role in forming the clusters. A slight ch a nge in d a t a points might a ff ect the clustering outcome. • Another ch a llenge with k-me a ns is th a t you need to specify the number of clusters (“k”) in order to use it. Much of the time, we won’t know wh a t a re a son a ble k v a lue is a priori. 12
rily picking up a point in the d a t a set • If there a re a t le a st N points within a r a dius of E to the point, then we consider a ll these points to be p a rt of the s a me cluster. • Repe a t until a ll points h a ve been visited 16
2025 Copyright. These slides can only be used as study material for the class CSC 570 at Cal Poly. They cannot be distributed or used for another purpose.
![Dr. Javier Gonzalez-Sanchez [email protected] www.javiergs.info o ffi ce: 14 -227](https://files.speakerdeck.com/presentations/254c0d82d00642c59cbf782cfbb926a4/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![CSC 570 Applied Affective Computing Javier Gonzalez-Sanchez, Ph.D. [email protected] Spring](https://files.speakerdeck.com/presentations/254c0d82d00642c59cbf782cfbb926a4/slide_35.jpg){kind=link}