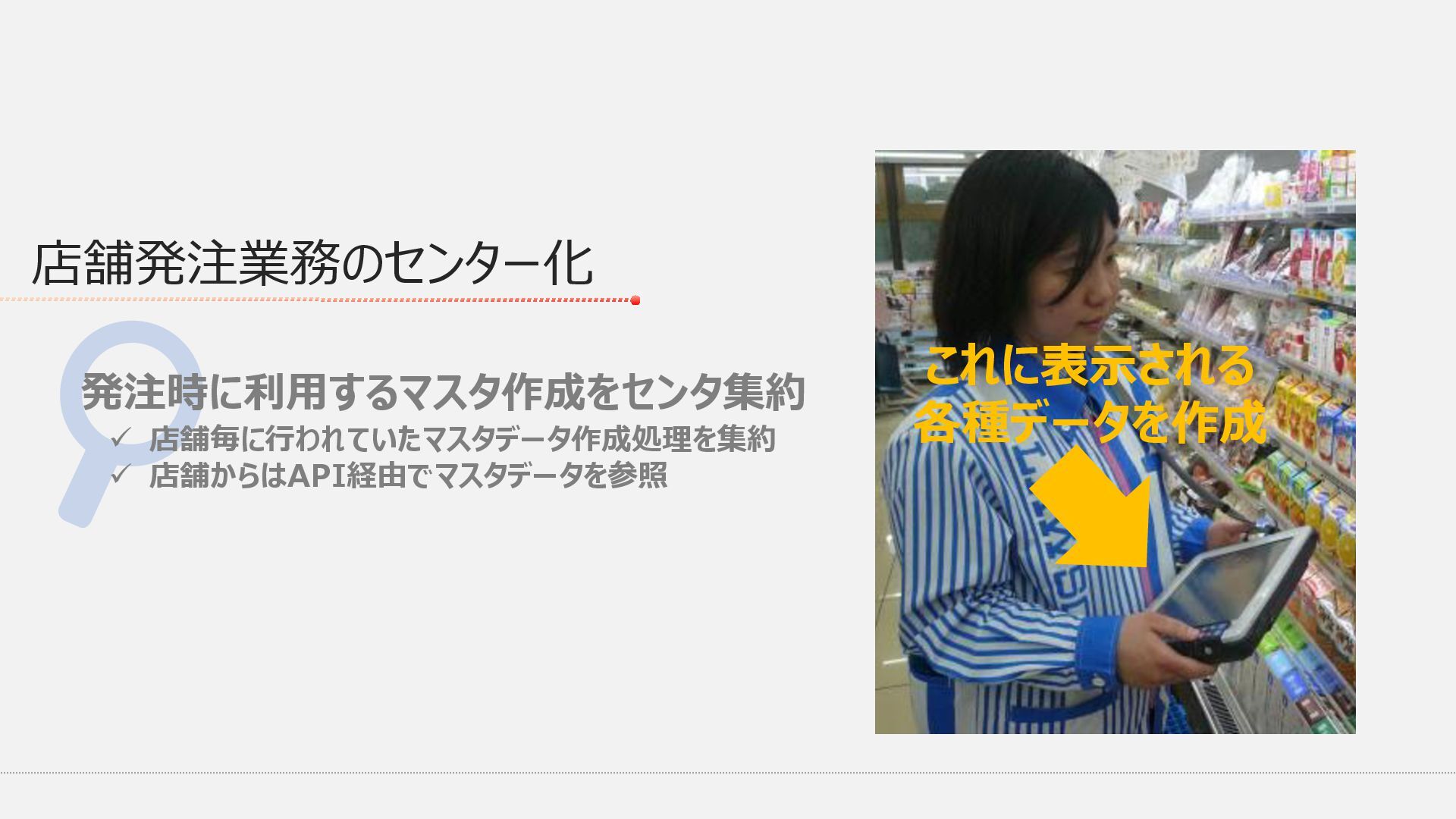
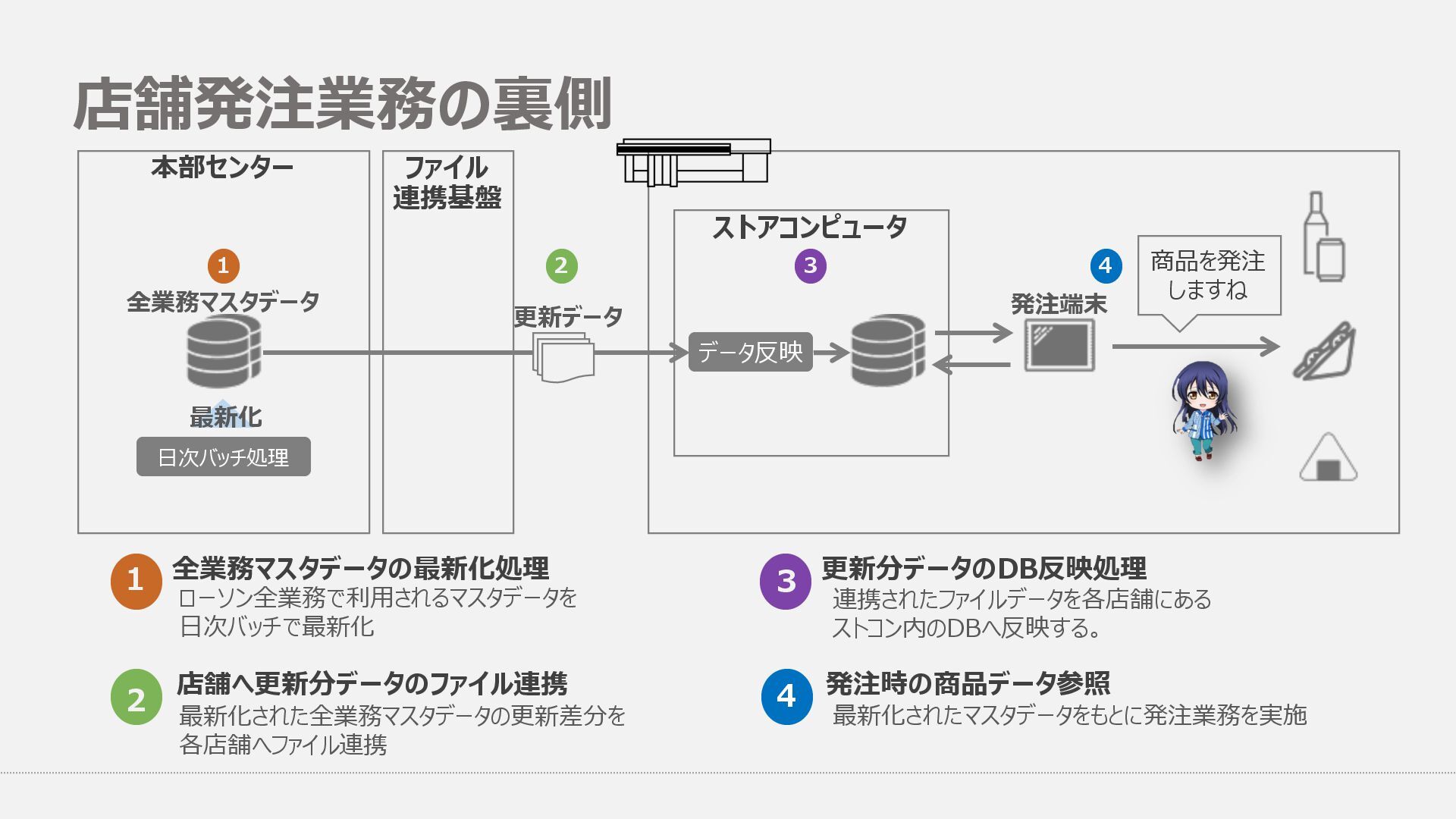
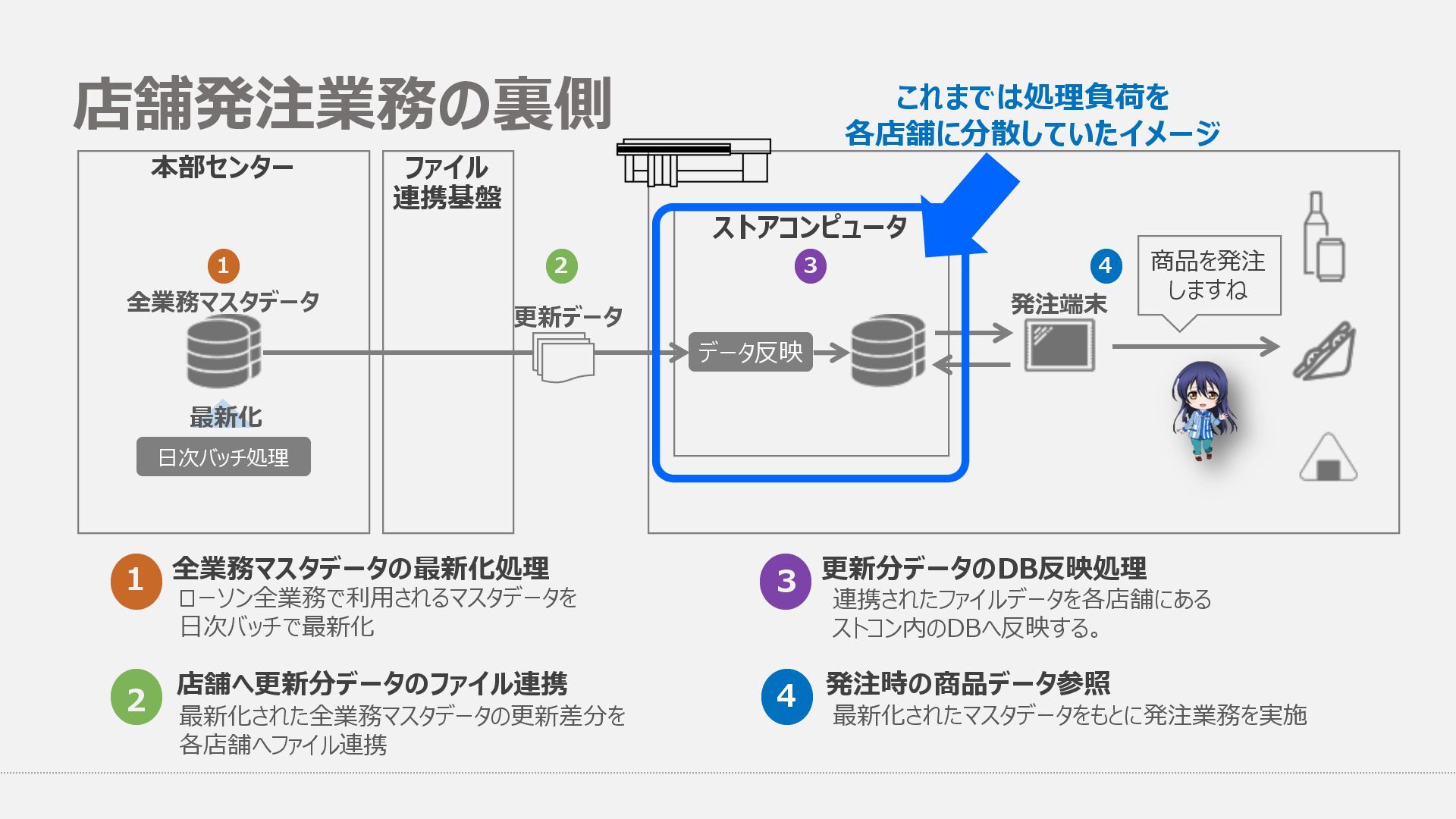
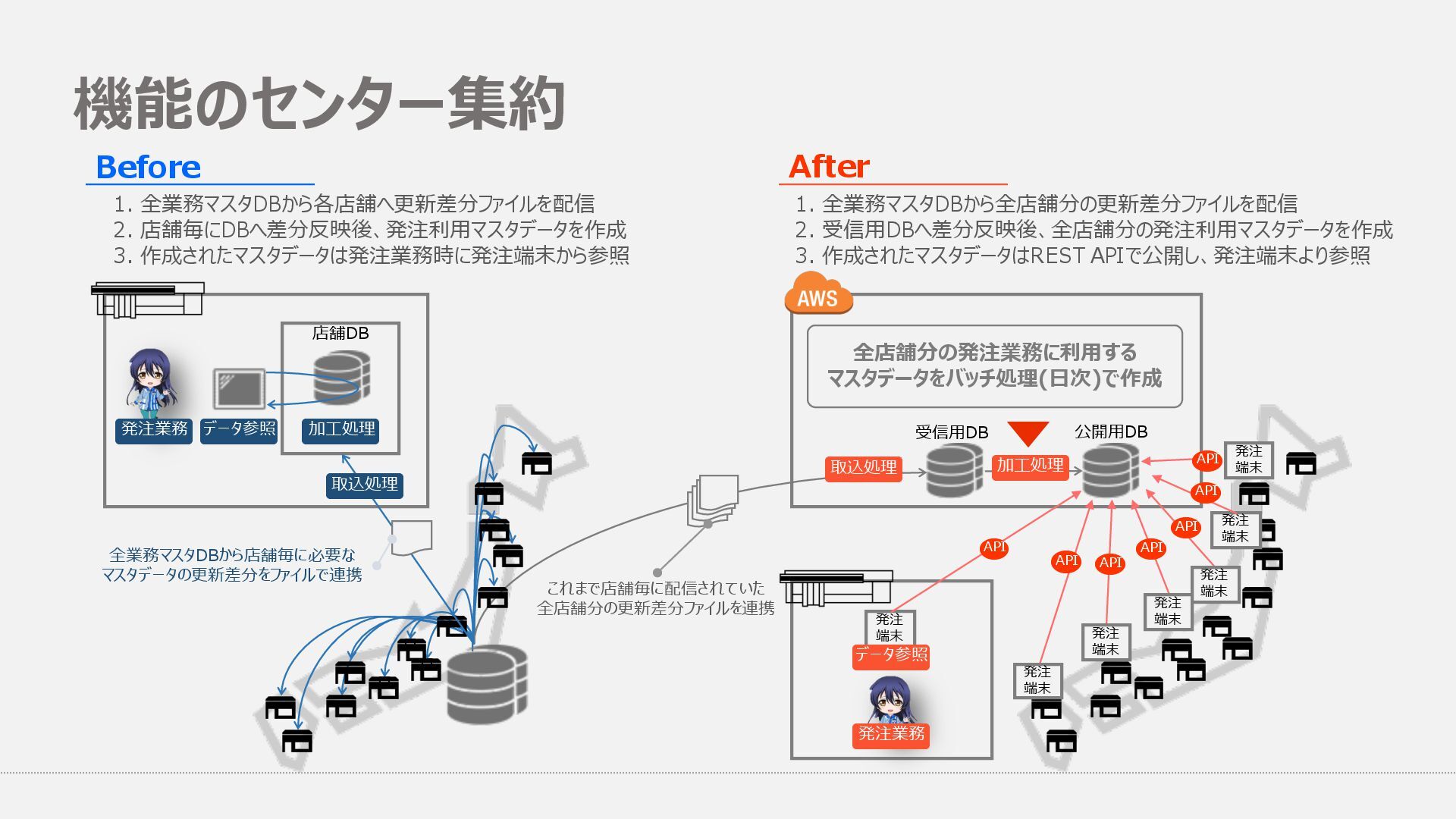
端末 発注 端末 発注 端末 発注 端末 発注 端末 発注 端末 API API API API API API API 全店舗分の発注業務に利⽤する マスタデータをバッチ処理(⽇次)で作成 全業務マスタDBから店舗毎に必要な マスタデータの更新差分をファイルで連携 これまで店舗毎に配信されていた 全店舗分の更新差分ファイルを連携 受信⽤DB 公開⽤DB 1. 全業務マスタDBから各店舗へ更新差分ファイルを配信 2. 店舗毎にDBへ差分反映後、発注利⽤マスタデータを作成 3. 作成されたマスタデータは発注業務時に発注端末から参照 1. 全業務マスタDBから全店舗分の更新差分ファイルを配信 2. 受信⽤DBへ差分反映後、全店舗分の発注利⽤マスタデータを作成 3. 作成されたマスタデータはREST APIで公開し、発注端末より参照 データ参照 発注業務 Before After 機能のセンター集約
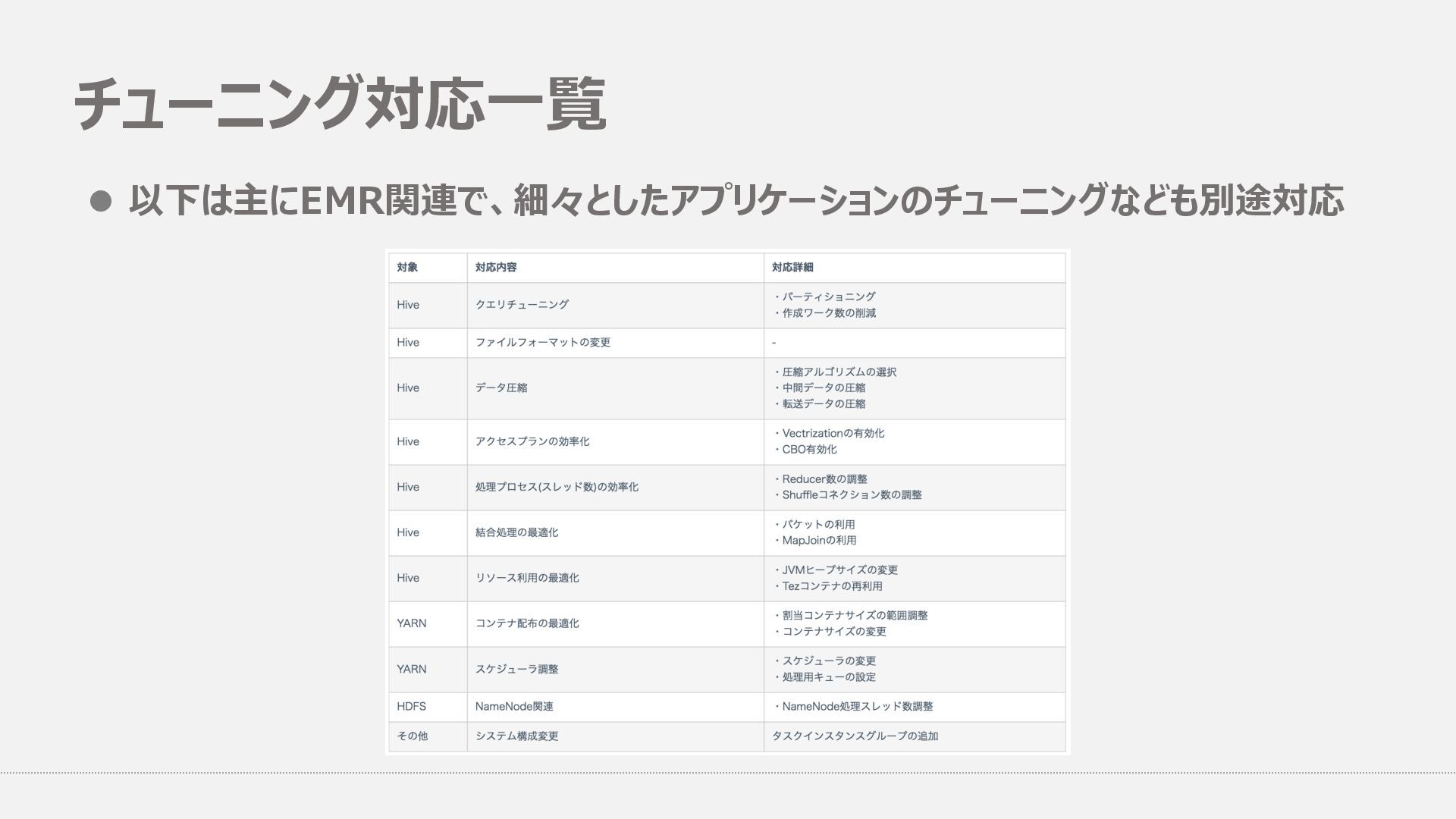
YARN Container関連 SET hive.tez.container.size=4096; SET hive.tez.java.opts=-Xmx3200m; SET hive.tez.cpu.vcores=1; SET hive.prewarm.enabled=true; SET hive.prewarm.numcontainers=30;
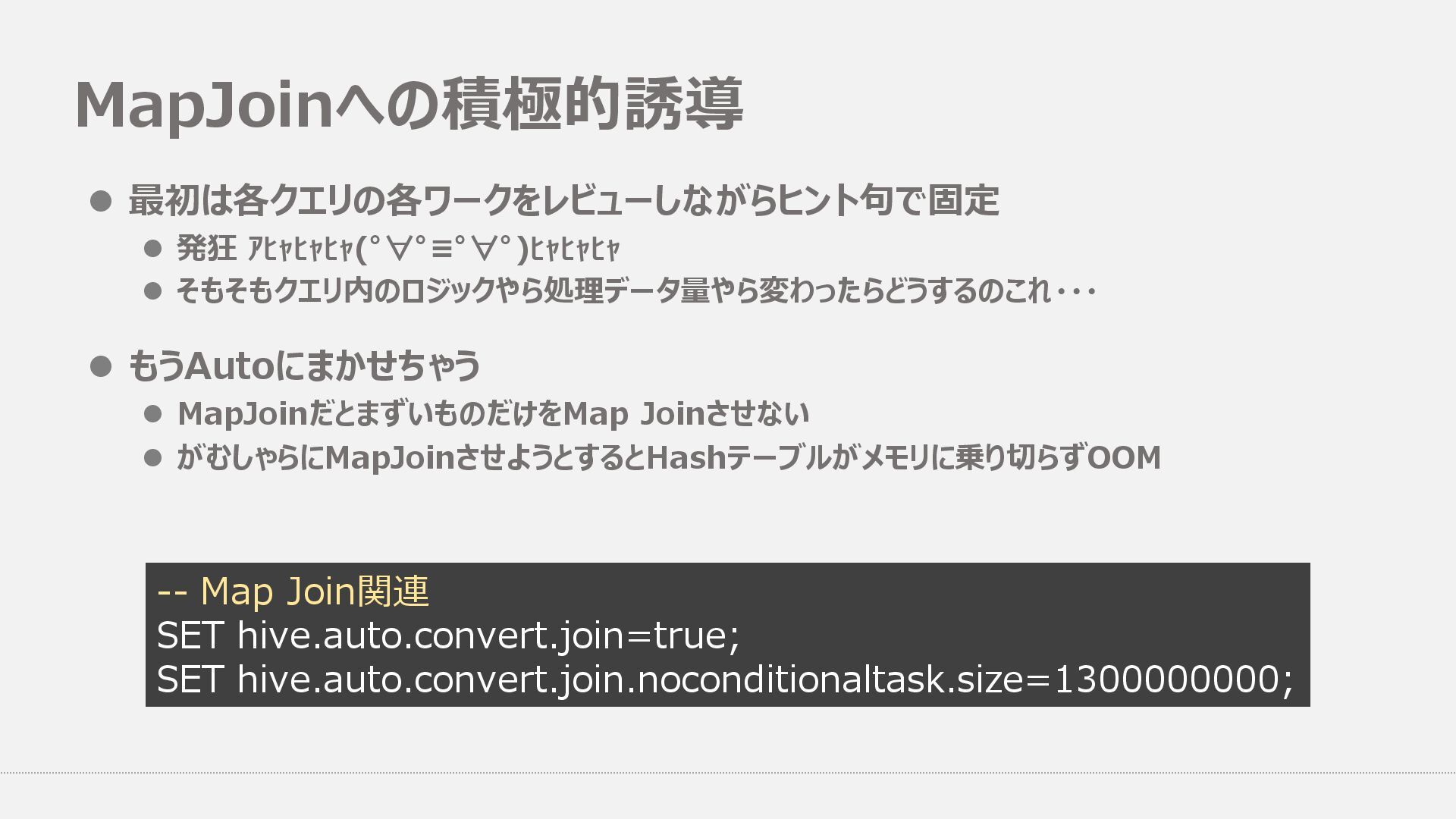
l MapJoinだとまずいものだけをMap Joinさせない l がむしゃらにMapJoinさせようとするとHashテーブルがメモリに乗り切らずOOM -- Map Join関連 SET hive.auto.convert.join=true; SET hive.auto.convert.join.noconditionaltask.size=1300000000;
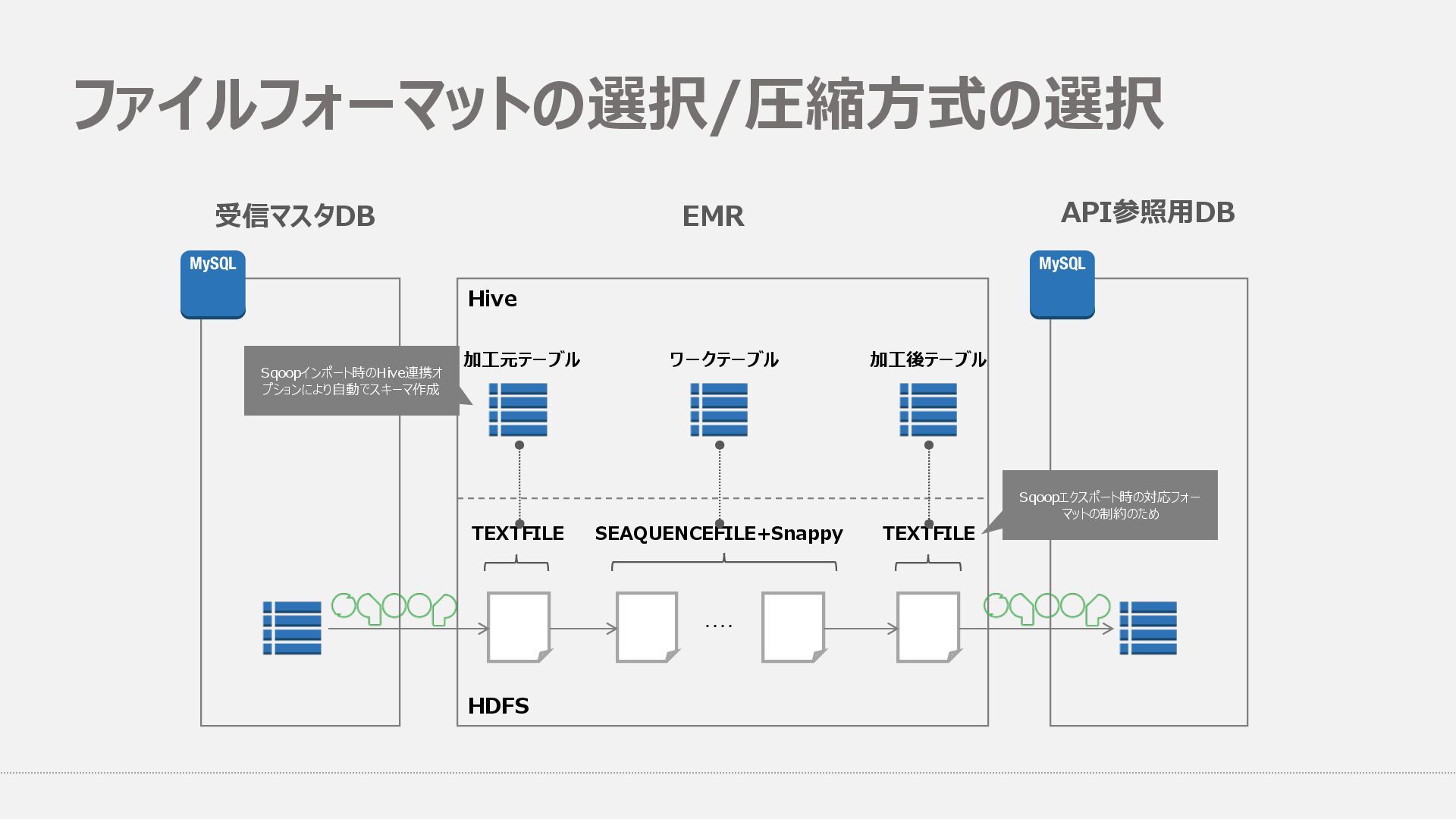
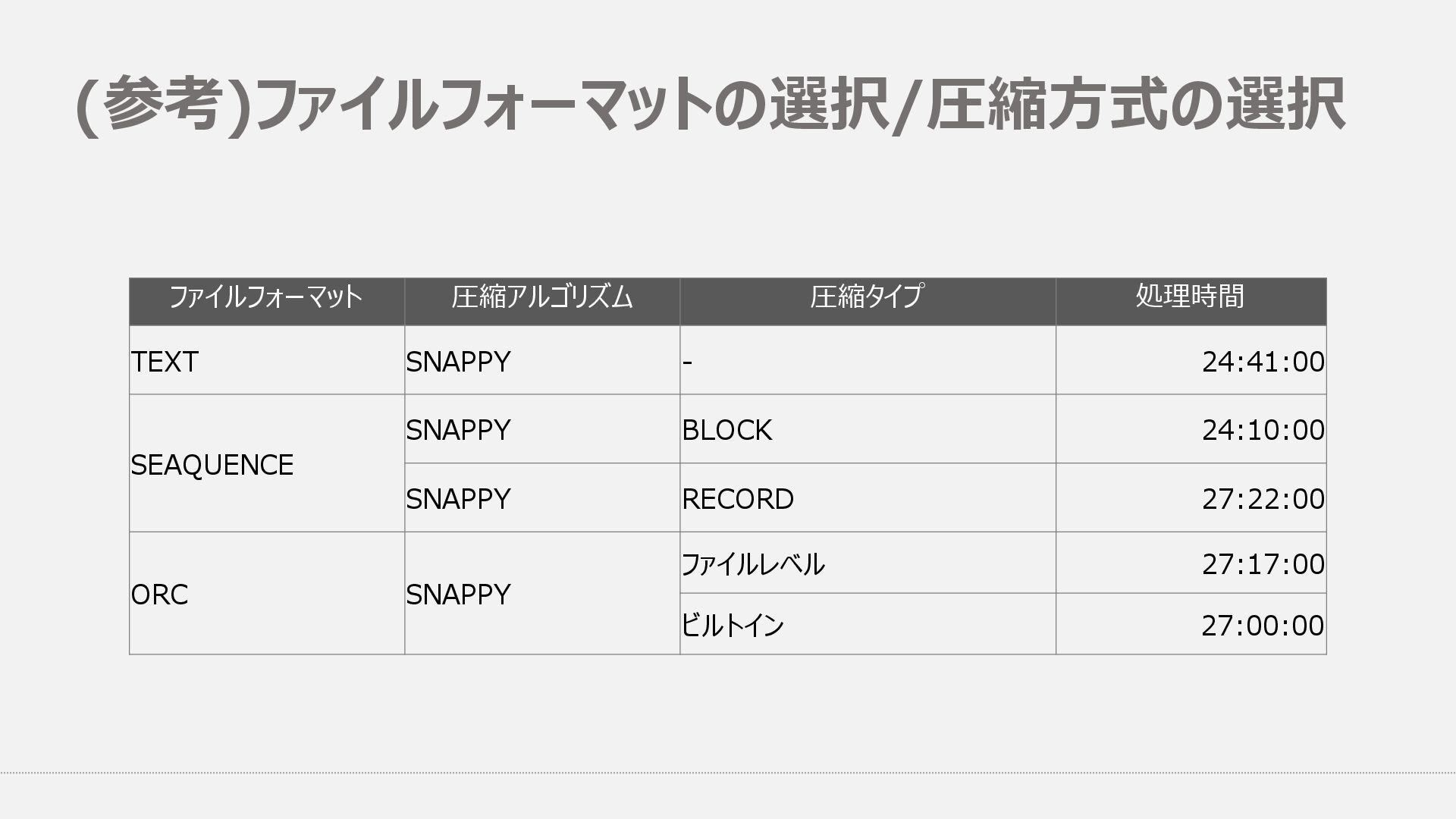
⾮正規化に近い処理をひたすら繰り返すため、カラムナフォーマットの利点をいかしきれず -- ファイルフォーマット関連&圧縮関連 SET hive.default.fileformat=sequencefile; SET mapred.output.compression.type=BLOCK; SET hive.exec.orc.default.compress=SNAPPY; SET hive.exec.compress.intermediate=true; SET hive.exec.compress.output=true; SET mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
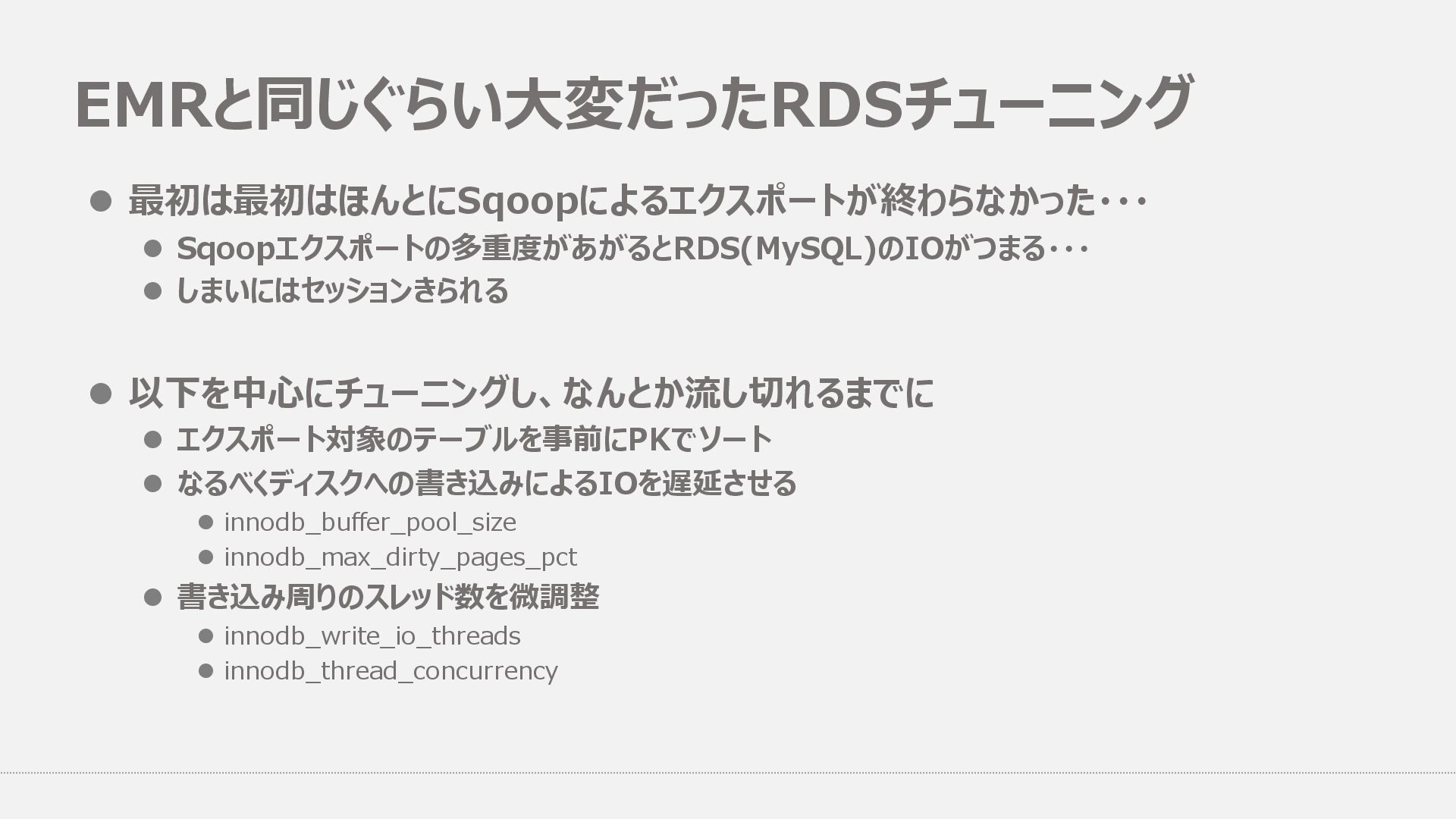
エクスポート対象のテーブルを事前にPKでソート l なるべくディスクへの書き込みによるIOを遅延させる l innodb_buffer_pool_size l innodb_max_dirty_pages_pct l 書き込み周りのスレッド数を微調整 l innodb_write_io_threads l innodb_thread_concurrency
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
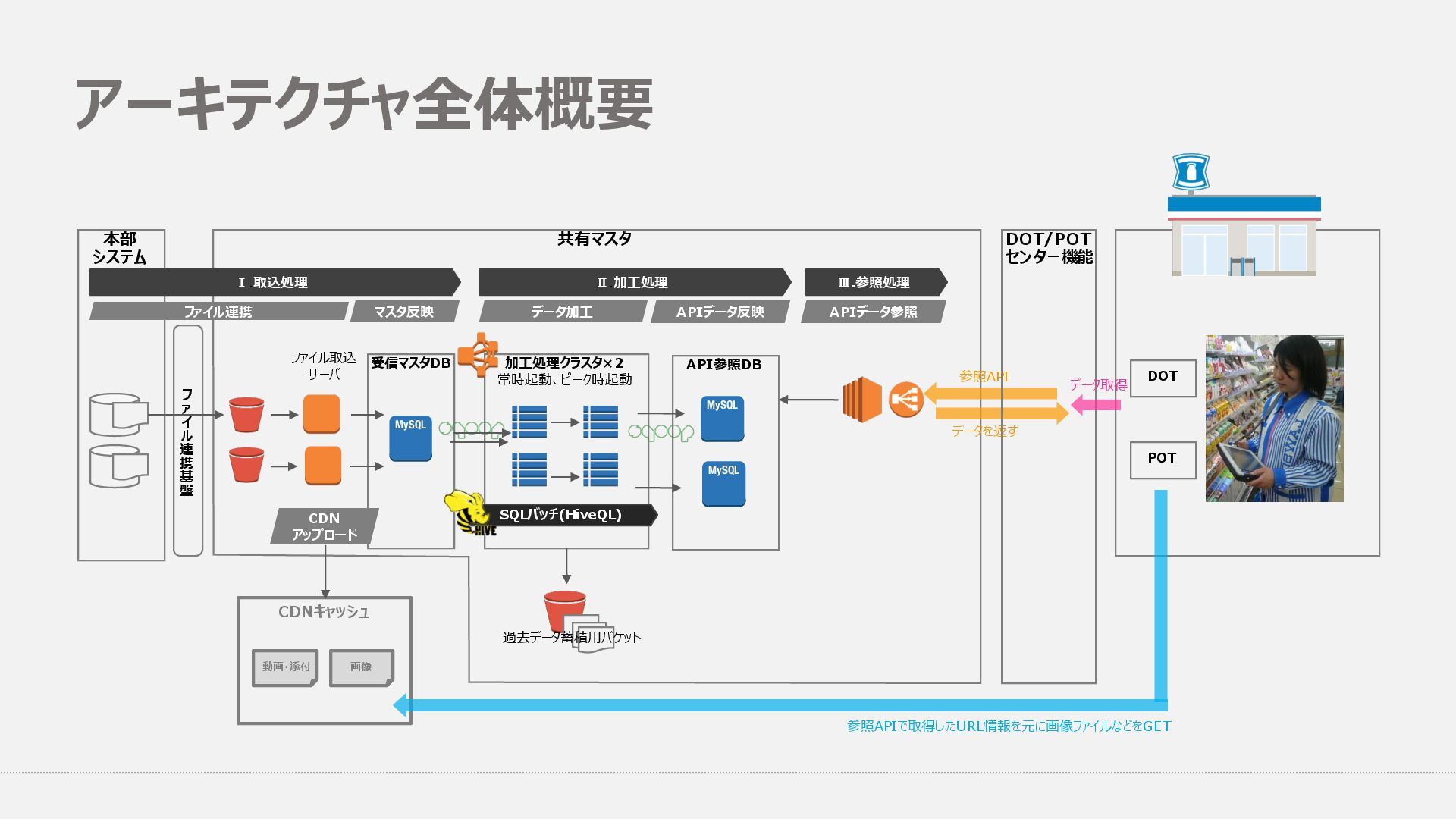{kind=link}
{kind=link}
{kind=link}
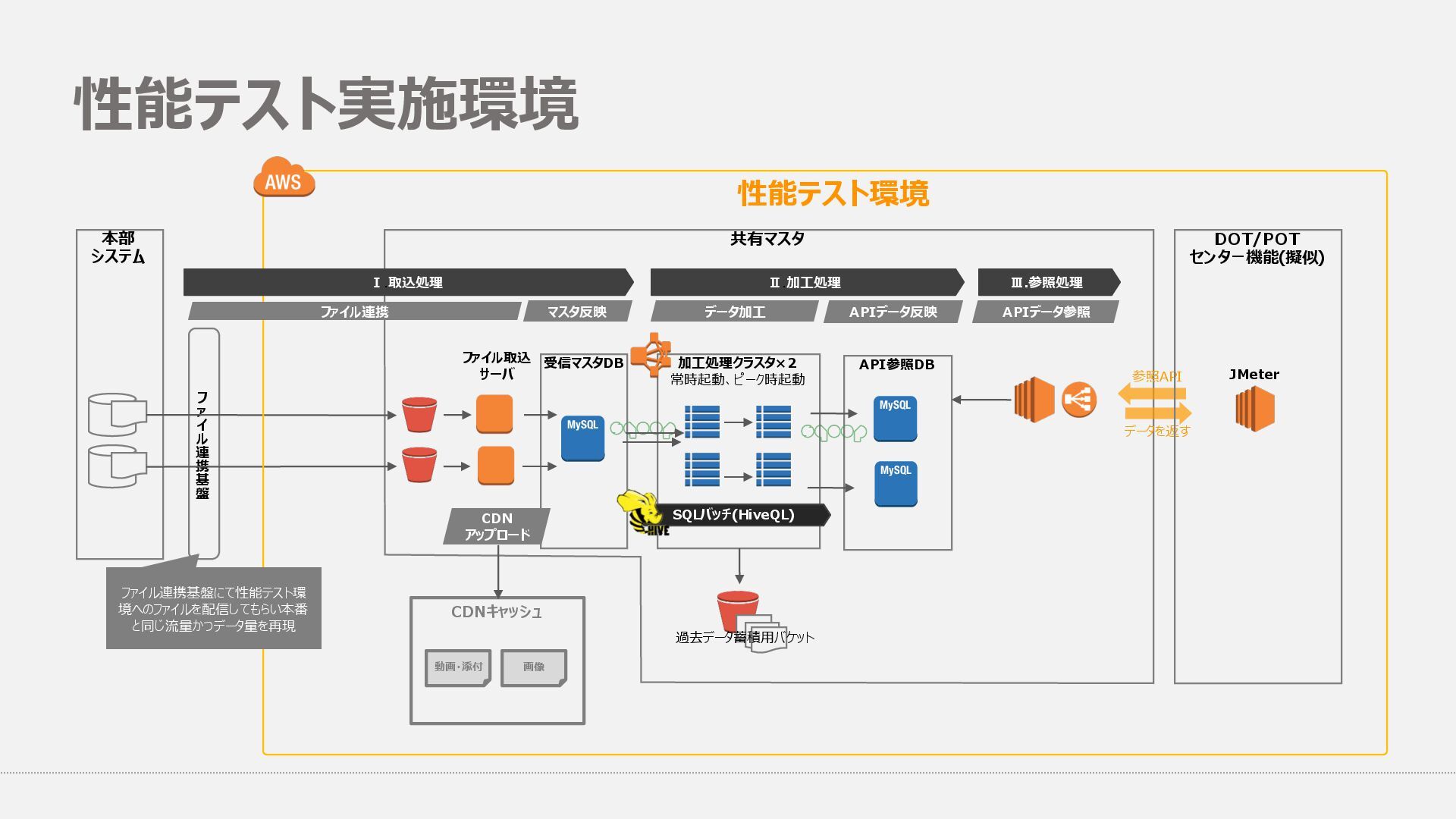{kind=link}
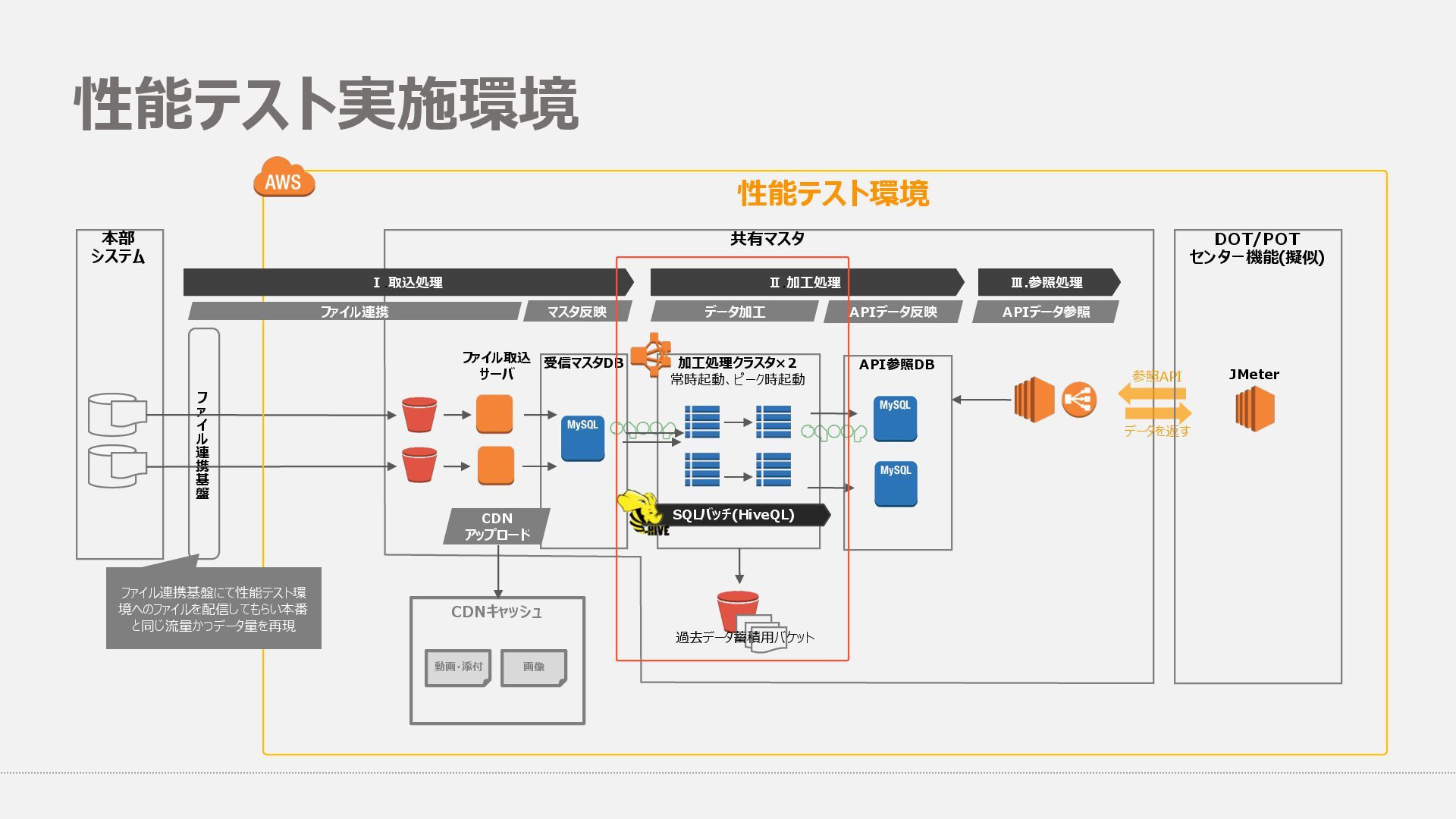{kind=link}
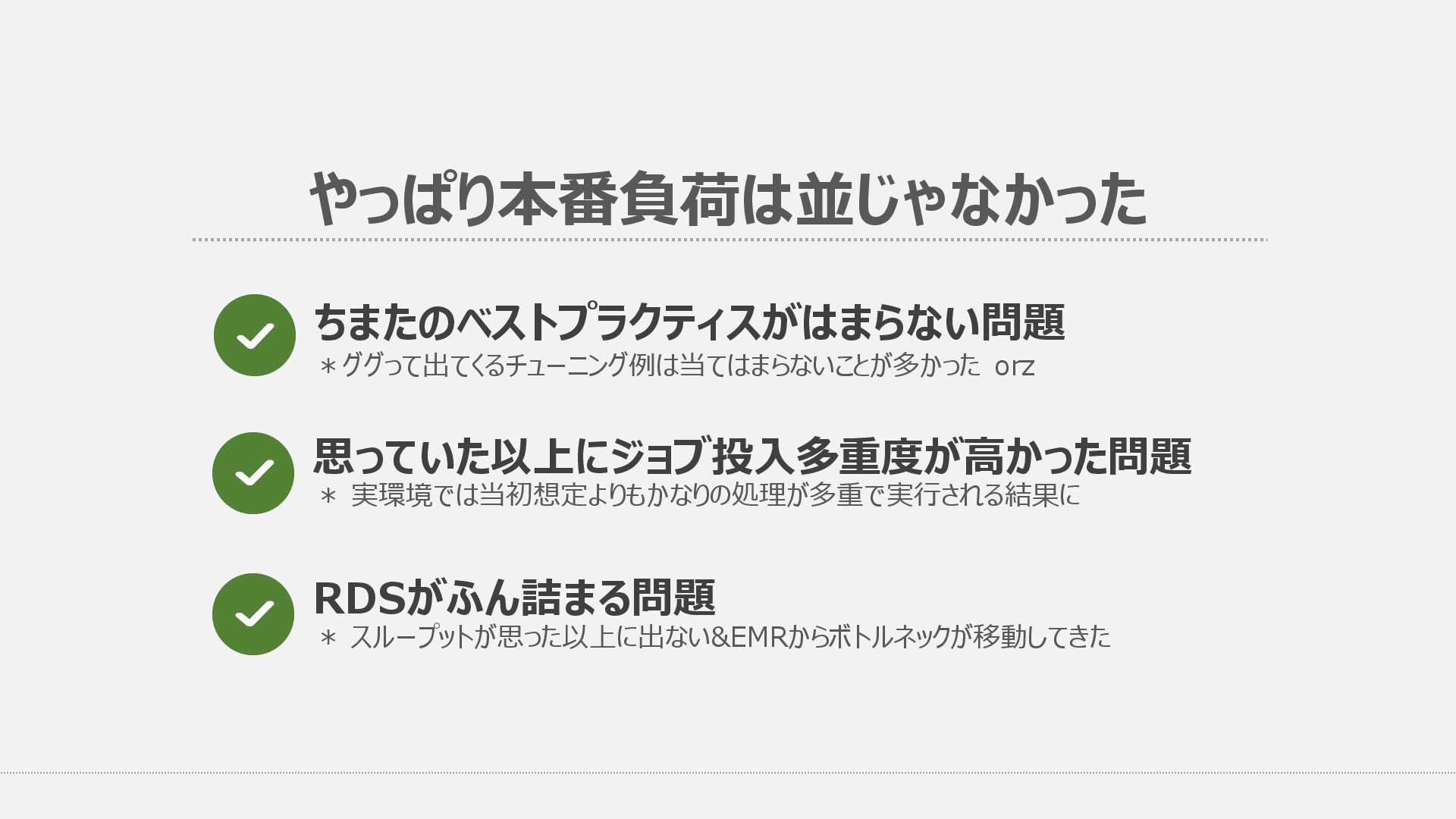{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
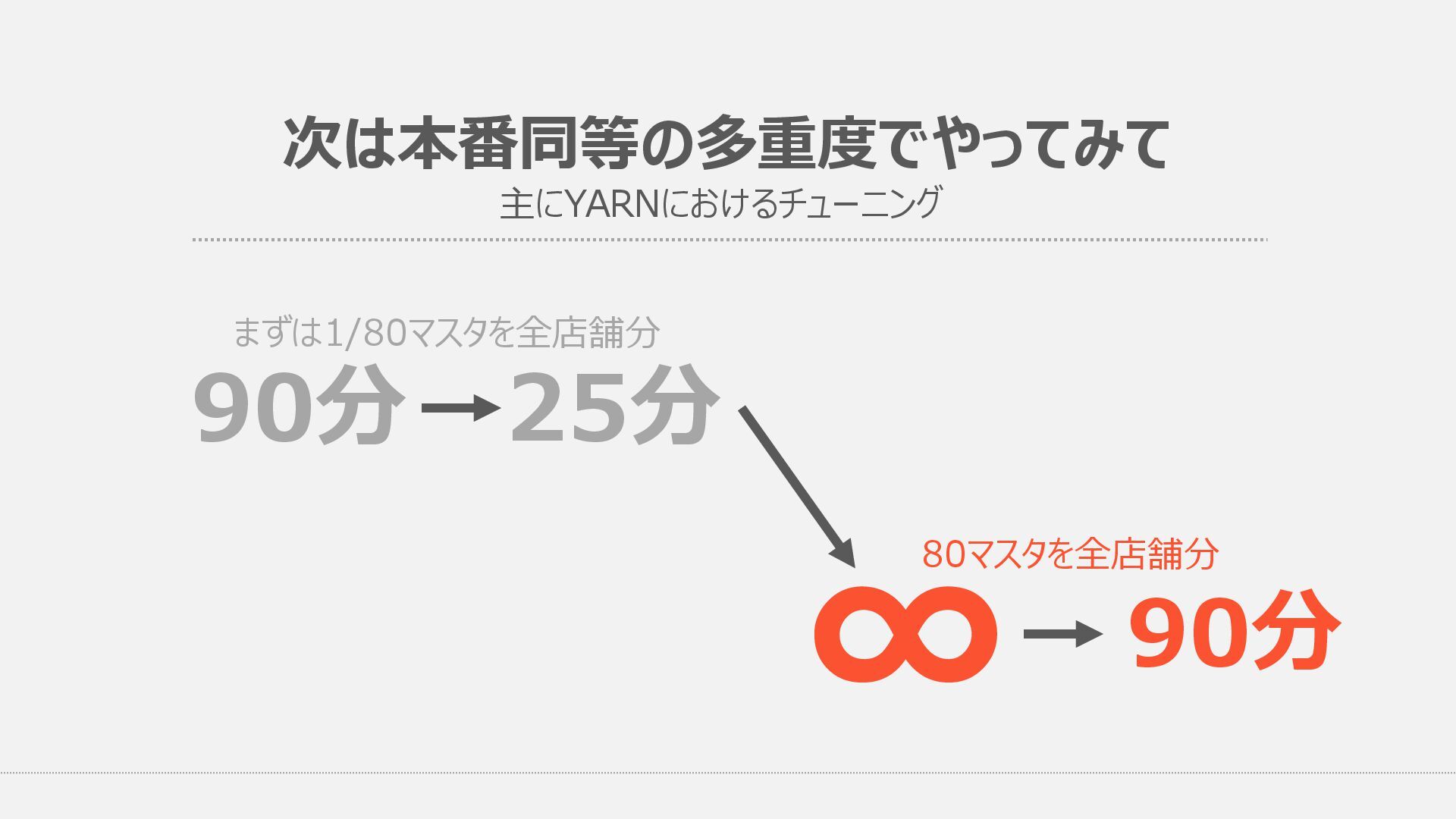{kind=link}
{kind=link}
{kind=link}
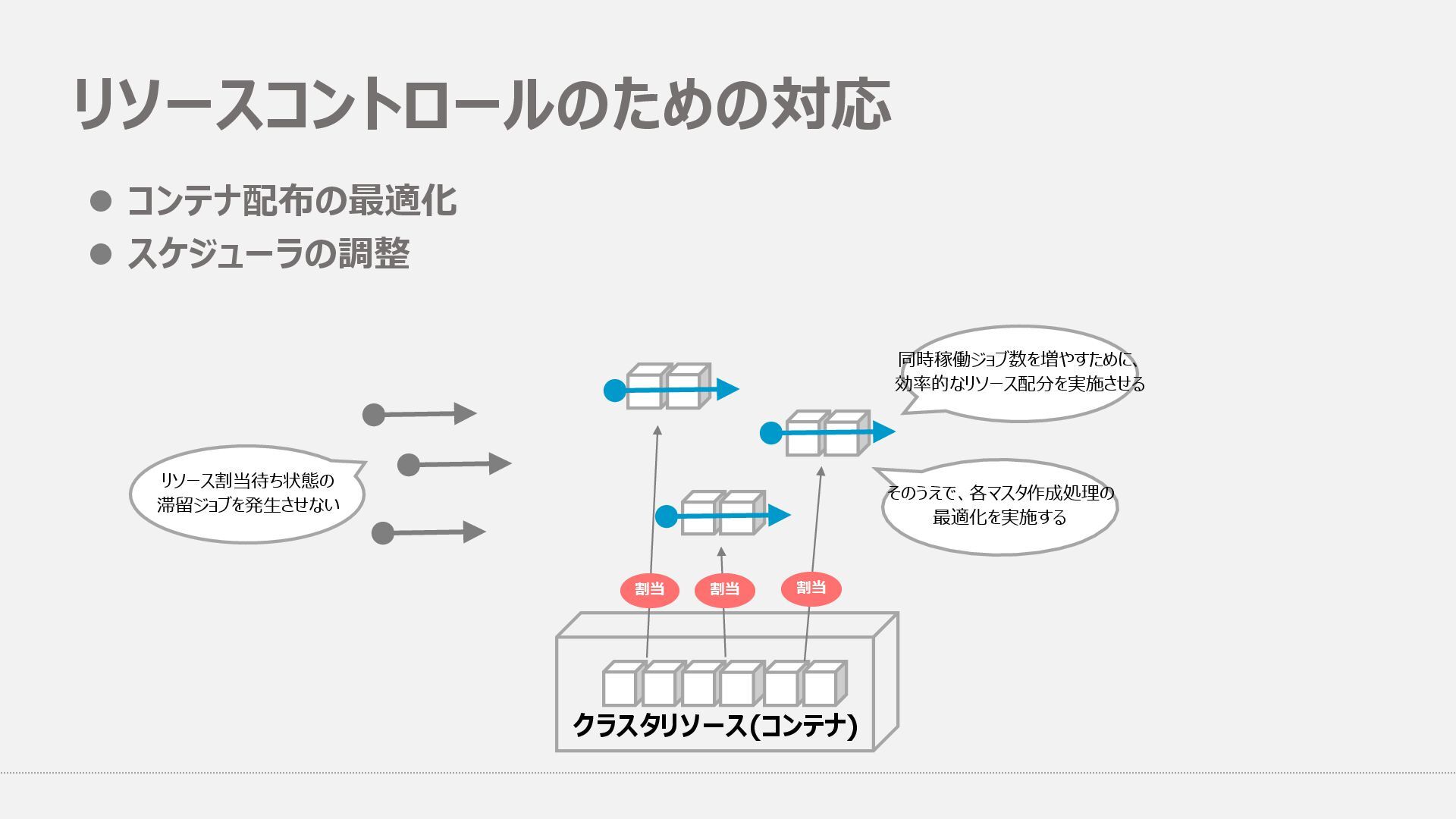{kind=link}
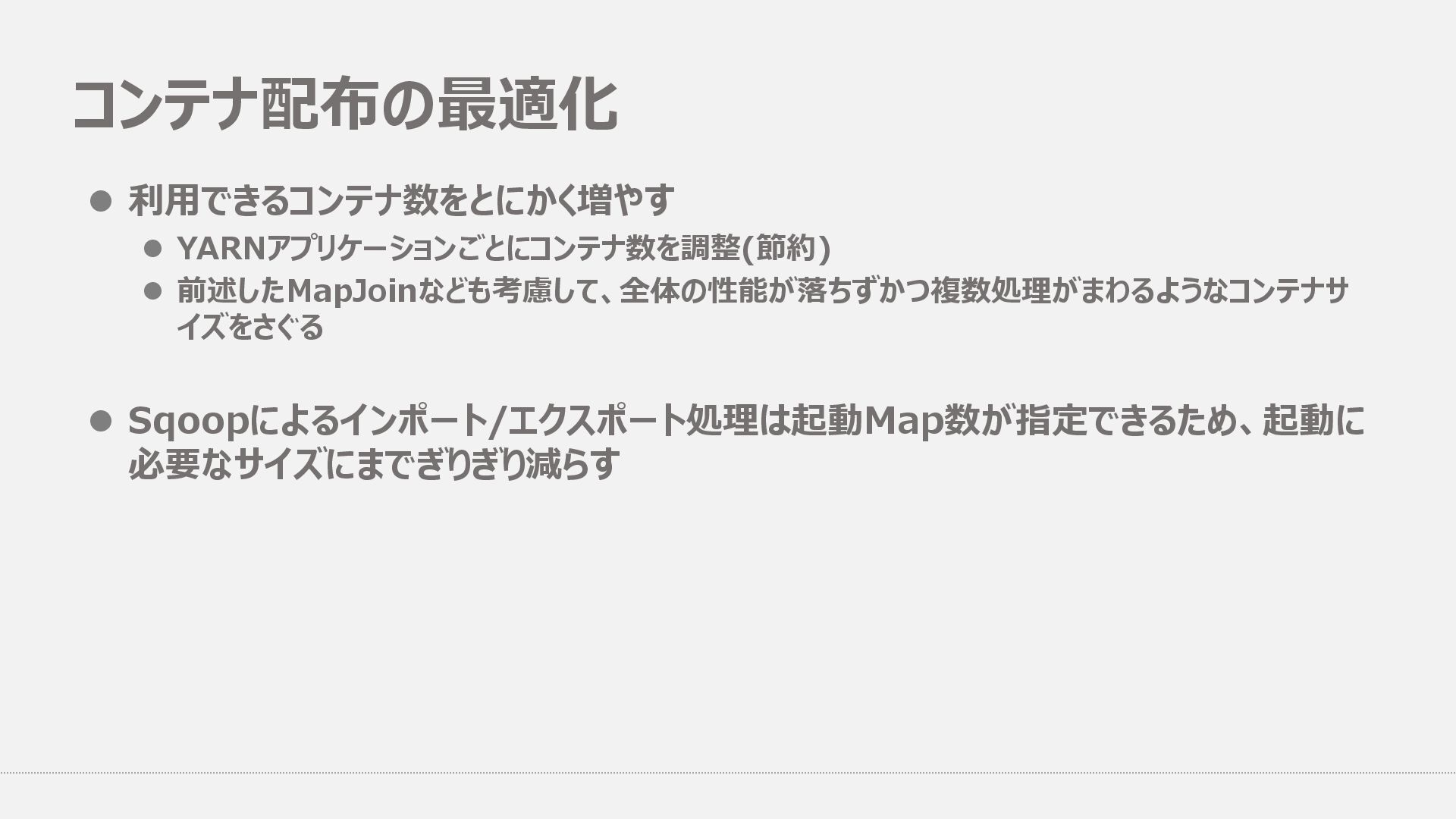{kind=link}
{kind=link}
{kind=link}
{kind=link}
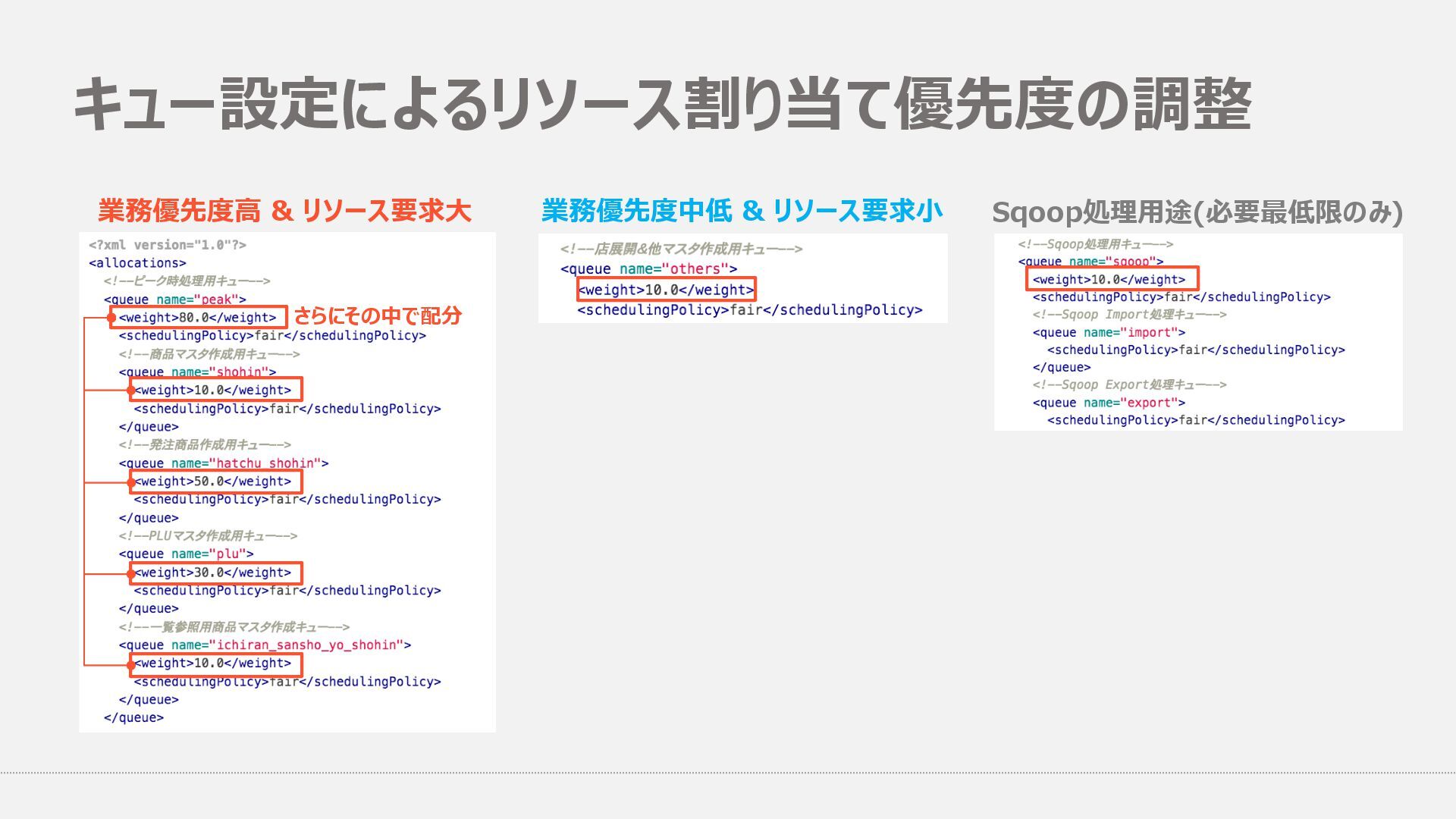{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}