Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Mobi-𝜋: Mobilizing Your Robot Learning Policy
Search
Semantic Machine Intelligence Lab., Keio Univ.
PRO
March 25, 2026
160
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Mobi-𝜋: Mobilizing Your Robot Learning Policy
Semantic Machine Intelligence Lab., Keio Univ.
PRO
March 25, 2026
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
19
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
47
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
110
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
90
A Gentle Introduction to Transformers
keio_smilab
PRO
16
6.9k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
59
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
[Journal club] Improved Mean Flows: On the Challenges of Fastforward Generative Models
keio_smilab
PRO
0
200
Featured
See All Featured
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
16
2k
Between Models and Reality
mayunak
4
360
Git: the NoSQL Database
bkeepers
PRO
432
67k
The Invisible Side of Design
smashingmag
301
52k
Why Our Code Smells
bkeepers
PRO
340
58k
Building an army of robots
kneath
306
46k
Dealing with People You Can't Stand - Big Design 2015
cassininazir
367
27k
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
240
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
350
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.4k
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
330
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
2
880
Transcript
M1 八島大地 Mobi-𝜋: Mobilizing Your Robot Learning Policy Jingyun Yang1,
Isabella Huang2, Brandon Vu1, Max Bajracharya2, Rika Antonova3, Jeannette Bohg1 1Stanford University 2Toyota Research Institute 3University of Cambridge CoRL25 Jingyun Yang, et al. “Mobi-𝜋: Mobilizing Your Robot Learning Policy.” CoRL2025
概要 2 • 背景 • 固定視点で学習したmanipulation policyをmobile robotにそのまま載せると OODになり失敗しやすい •
提案 • 3DGSで再構成した環境画像からpolicy に適したbase poseを探索 • 追加データを集めずに既存policyをmobile化 • 結果 • simulationおよび実機の両方で baselineを上回る性能
背景: 固定視点で学習されたpolicyはmobile robotにて性能低下 3 • 学習時のobservationが限定されるとpolicyの入力分布は camera viewpointにoverfitする傾向 • policyを視点に対して頑健にするには多量の追加データ
および再学習が必要 • pi0: 10000時間以上のpretrainingデータ Physical Intelligence データ収集時と視点が 異なると成功率が急激に低下
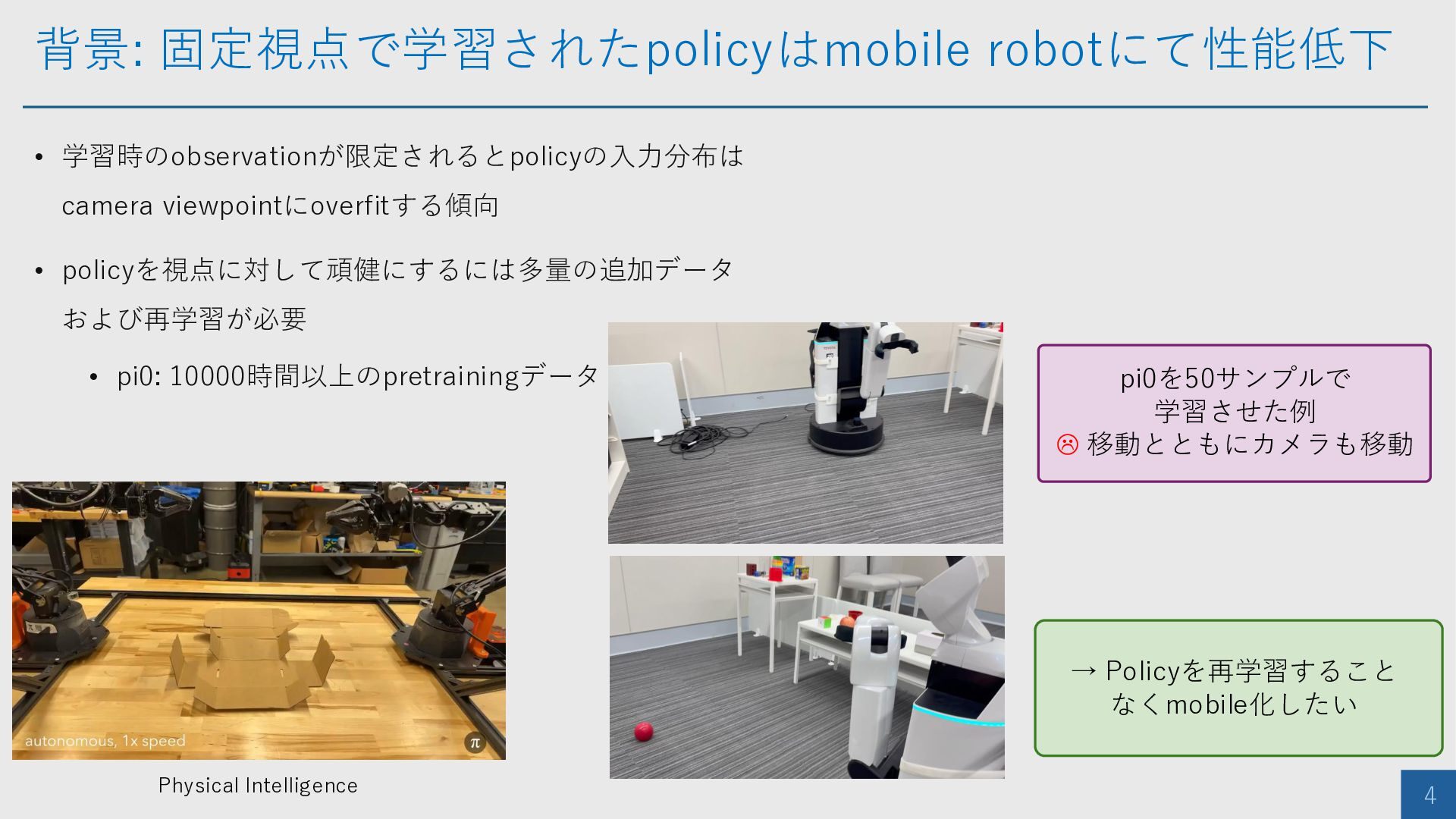
背景: 固定視点で学習されたpolicyはmobile robotにて性能低下 4 • 学習時のobservationが限定されるとpolicyの入力分布は camera viewpointにoverfitする傾向 • policyを視点に対して頑健にするには多量の追加データ
および再学習が必要 • pi0: 10000時間以上のpretrainingデータ pi0を50サンプルで 学習させた例 移動とともにカメラも移動 → Policyを再学習すること なくmobile化したい Physical Intelligence
関連研究 5 手法 概要 LeLaN [Hirose+, CoRL23] VLFM [Yokoyama+, ICRA24]
基盤モデルを用いてsemantic navigationや waypoint selectionを行う → 対象物体の近傍まで移動することには強いが,下流の manipulation policyが 成功しやすい視点・姿勢を明示的に最適化するわけではない pi0 [Black+, RSS24] pi05 [Black+, CoRL25] 大規模データでend-to-endに学習したVLA → 環境・embodimentごとにfinetuningが必要 MomanipVLA [Wu+, CVPR25] table-topで学習されたVLAに拡張 VLAが予測したEE pose を用いて,base と arm の動作を協調的に決定 [Yokoyama+, ICRA24] [Wu+, CVPR25]
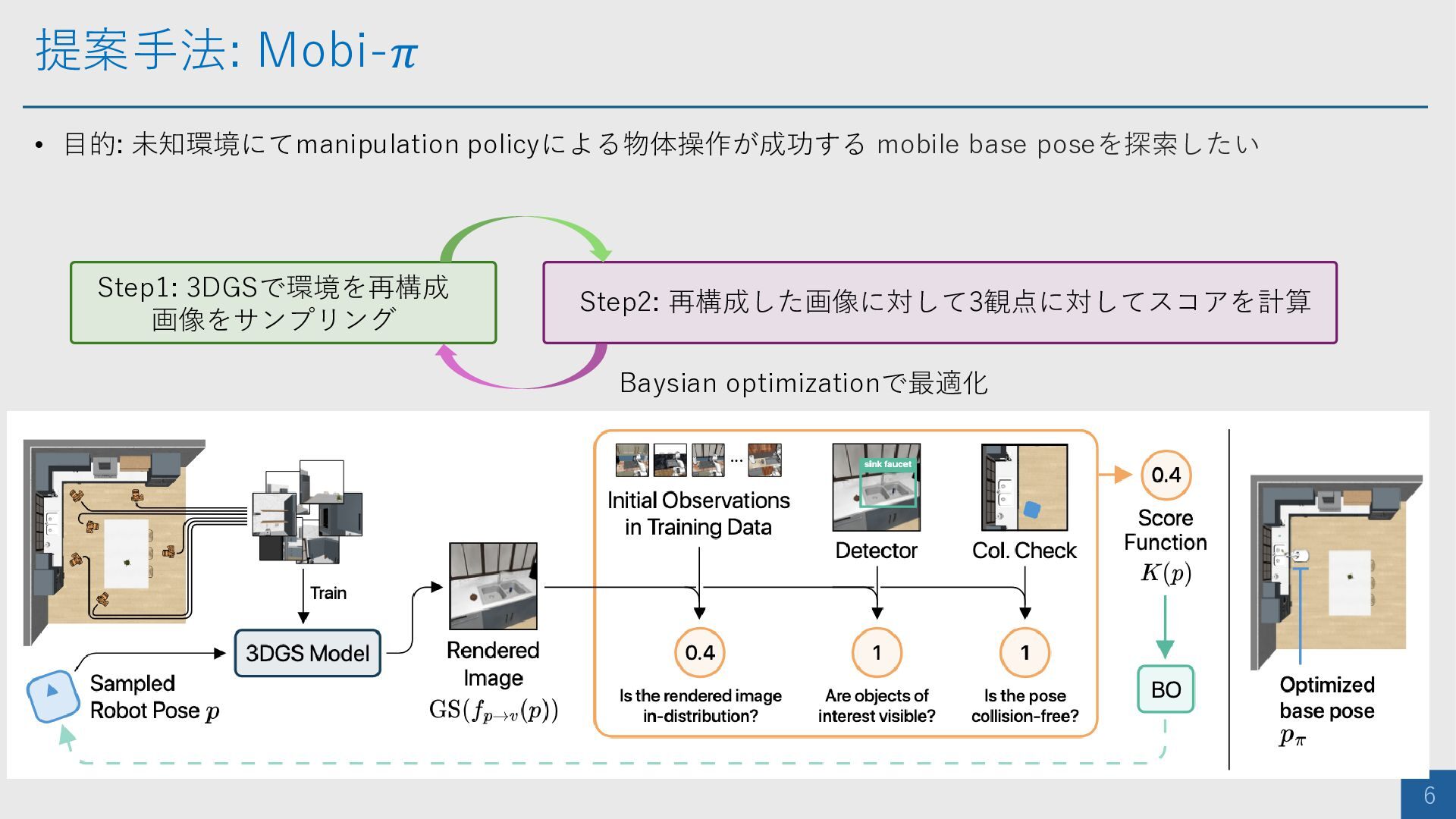
提案手法: Mobi-𝜋 6 • 目的: 未知環境にてmanipulation policyによる物体操作が成功する mobile base poseを探索したい
Step1: 3DGSで環境を再構成 画像をサンプリング Step2: 再構成した画像に対して3観点に対してスコアを計算 Baysian optimizationで最適化
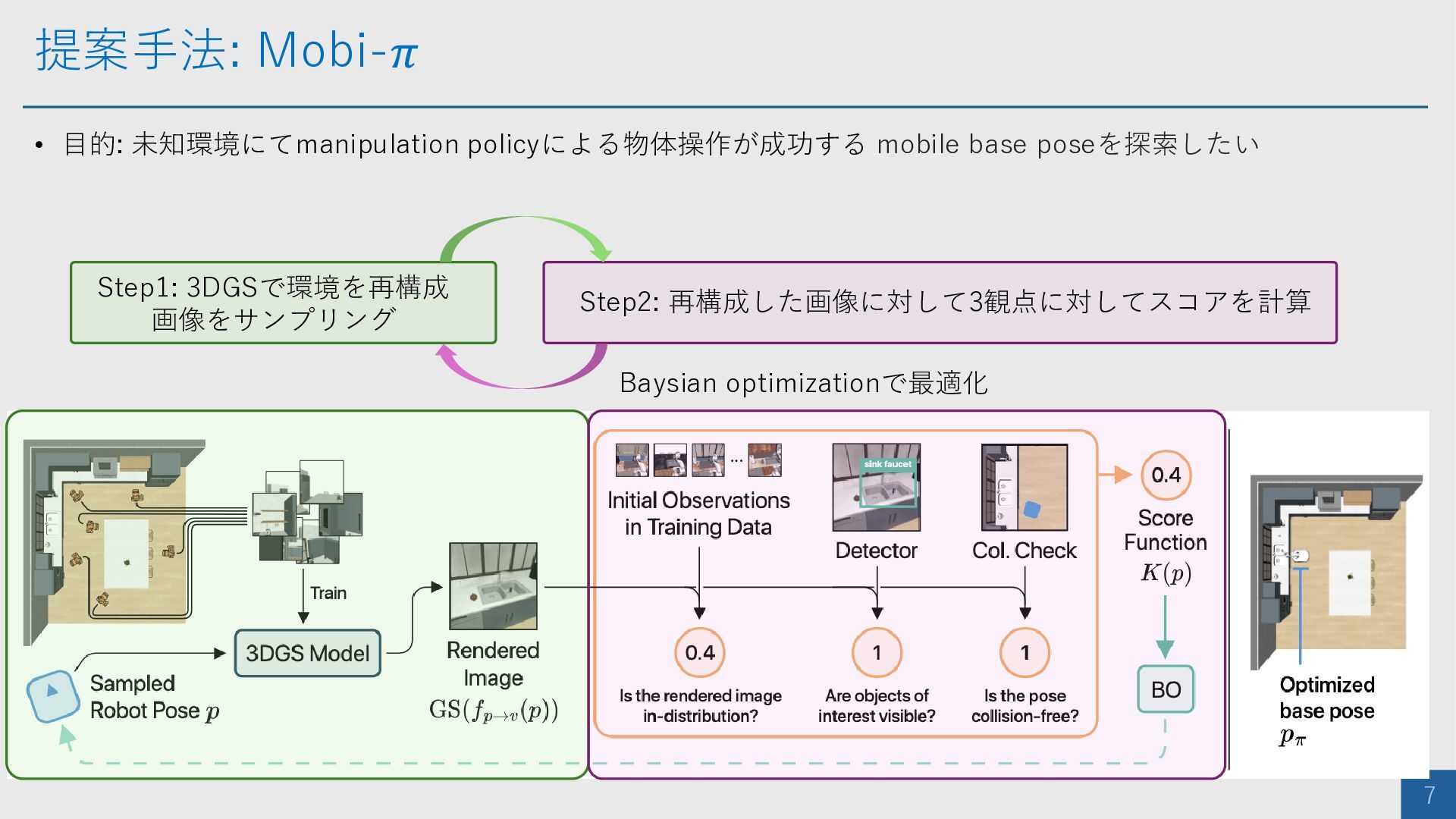
提案手法: Mobi-𝜋 7 • 目的: 未知環境にてmanipulation policyによる物体操作が成功する mobile base poseを探索したい
Step1: 3DGSで環境を再構成 画像をサンプリング Step2: 再構成した画像に対して3観点に対してスコアを計算 Baysian optimizationで最適化
提案手法: Mobi-𝜋 8 • 目的: 未知環境にてmanipulation policyによる物体操作が成功する mobile base poseを探索したい
Step1: 3DGSで環境を再構成 画像をサンプリング Step2: 再構成した画像に対して3観点に対してスコアを計算 Baysian optimizationで最適化
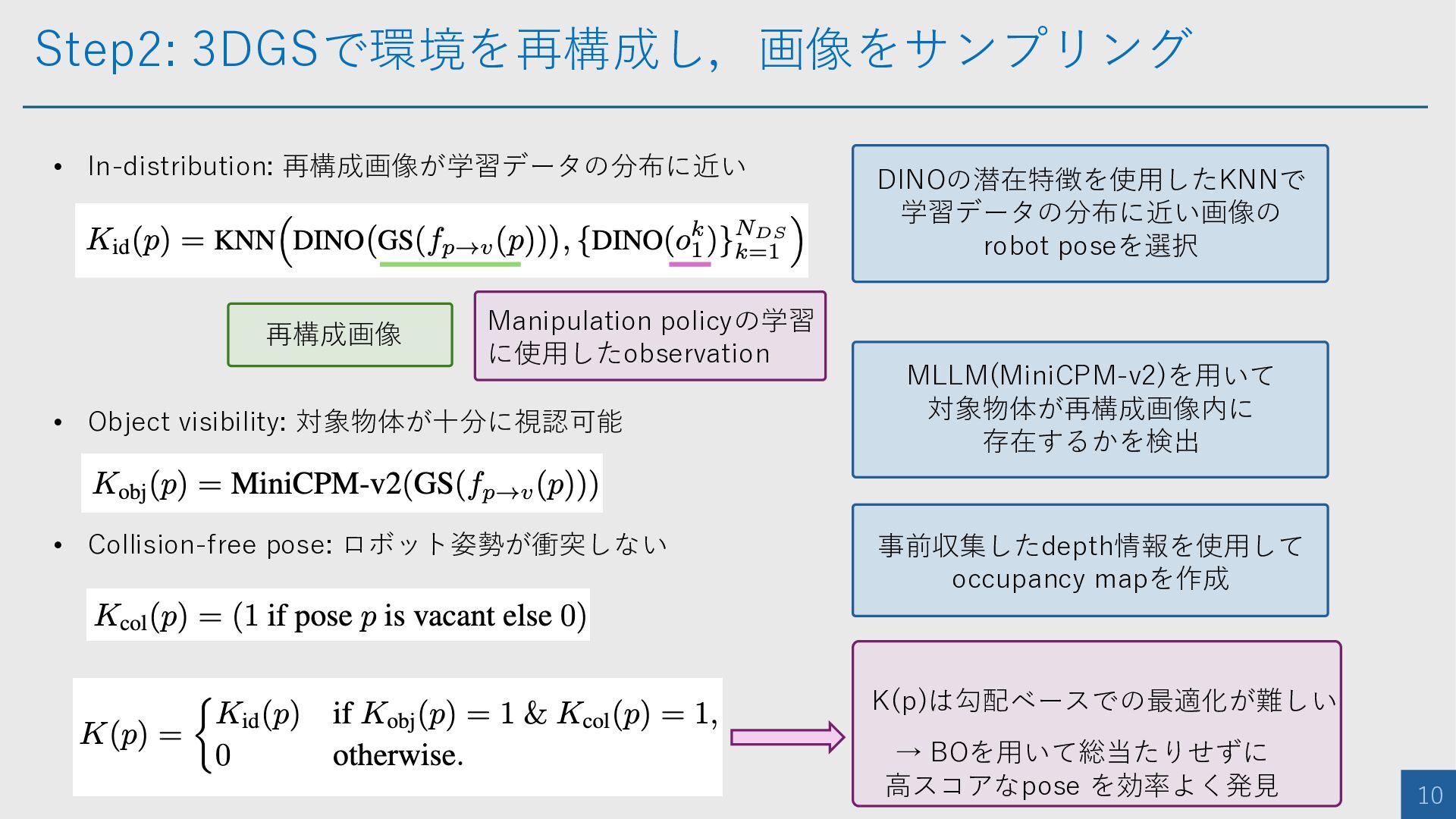
Step1: 3DGSで環境を再構成し,画像をサンプリング 9 • RGB-D画像を事前収集を通じて1000枚取得し3DGSを行う • 候補視点は以下の3観点から評価する • In-distribution: 再構成画像が学習データの分布に近い
• Object visibility: 対象物体が十分に視認可能 • Collision-free pose: ロボット姿勢が衝突しない
Step2: 3DGSで環境を再構成し,画像をサンプリング 10 • Collision-free pose: ロボット姿勢が衝突しない • In-distribution: 再構成画像が学習データの分布に近い
再構成画像 Manipulation policyの学習 に使用したobservation DINOの潜在特徴を使用したKNNで 学習データの分布に近い画像の robot poseを選択 • Object visibility: 対象物体が十分に視認可能 MLLM(MiniCPM-v2)を用いて 対象物体が再構成画像内に 存在するかを検出 事前収集したdepth情報を使用して occupancy mapを作成 → BOを用いて総当たりせずに 高スコアなpose を効率よく発見 K(p)は勾配ベースでの最適化が難しい
実験設定 11 • simulation • robocasa [Nasiriany+, RSS24]上で環境がunseenの5 task •
baseline • Policy aware: BC w/Nav • Non-policy aware: LeLaN [Hirose+, CoRL24], VLFM [Yokoyama+, ICRA24] • MimicGen [Mandlekar+, CoRL23] 300 episodeでBeTを学習 • real-world • 3つの難易度の異なるタスク • baseline • BC w/Nav, Human expert • 30-50 episodeをテレオペで収集し,diffusion policyを学習 • GPU: RTX 4090 • 実行時間: 3DGS (15min), pose search (6min)
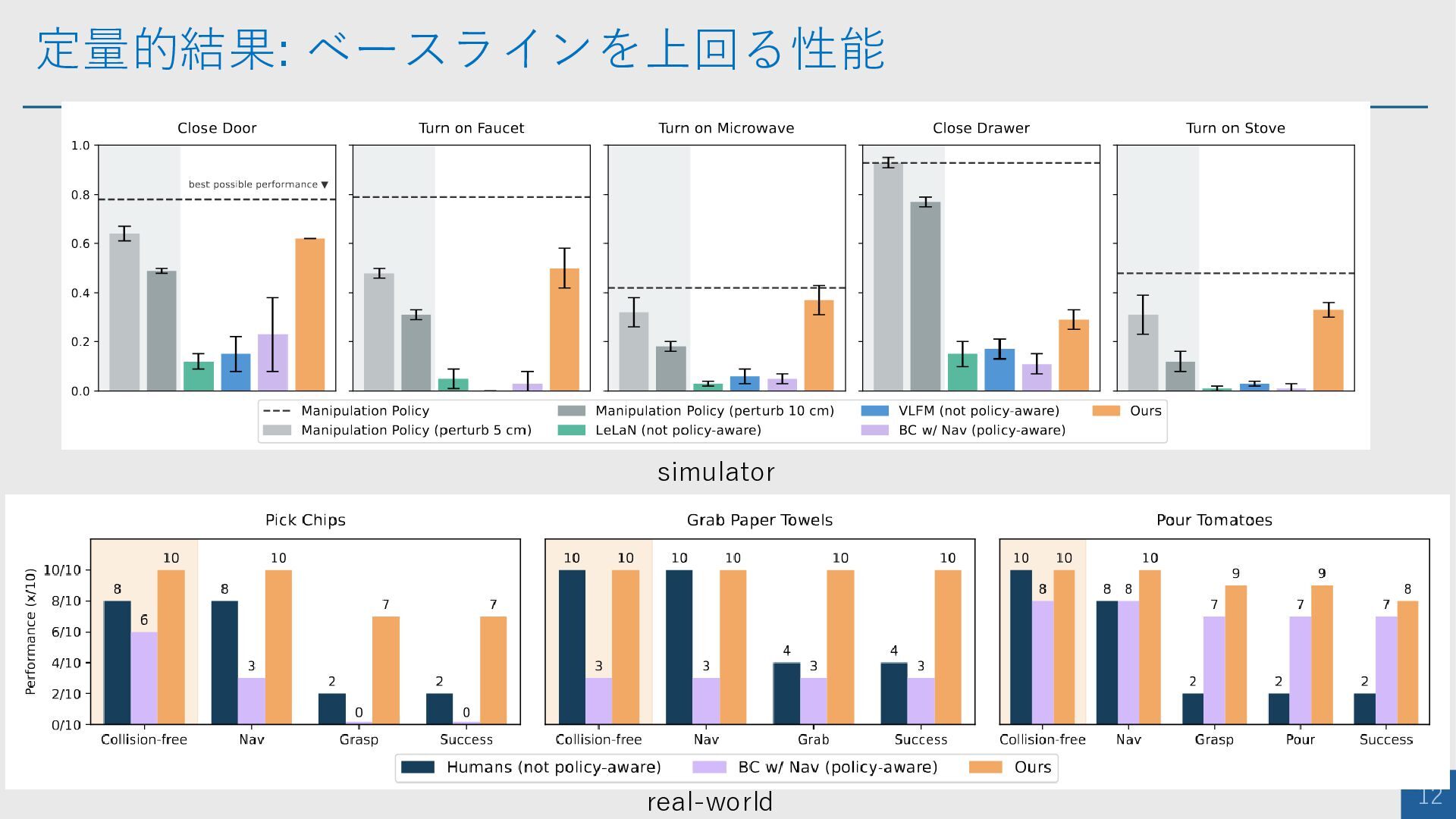
定量的結果: ベースラインを上回る性能 12 simulator real-world
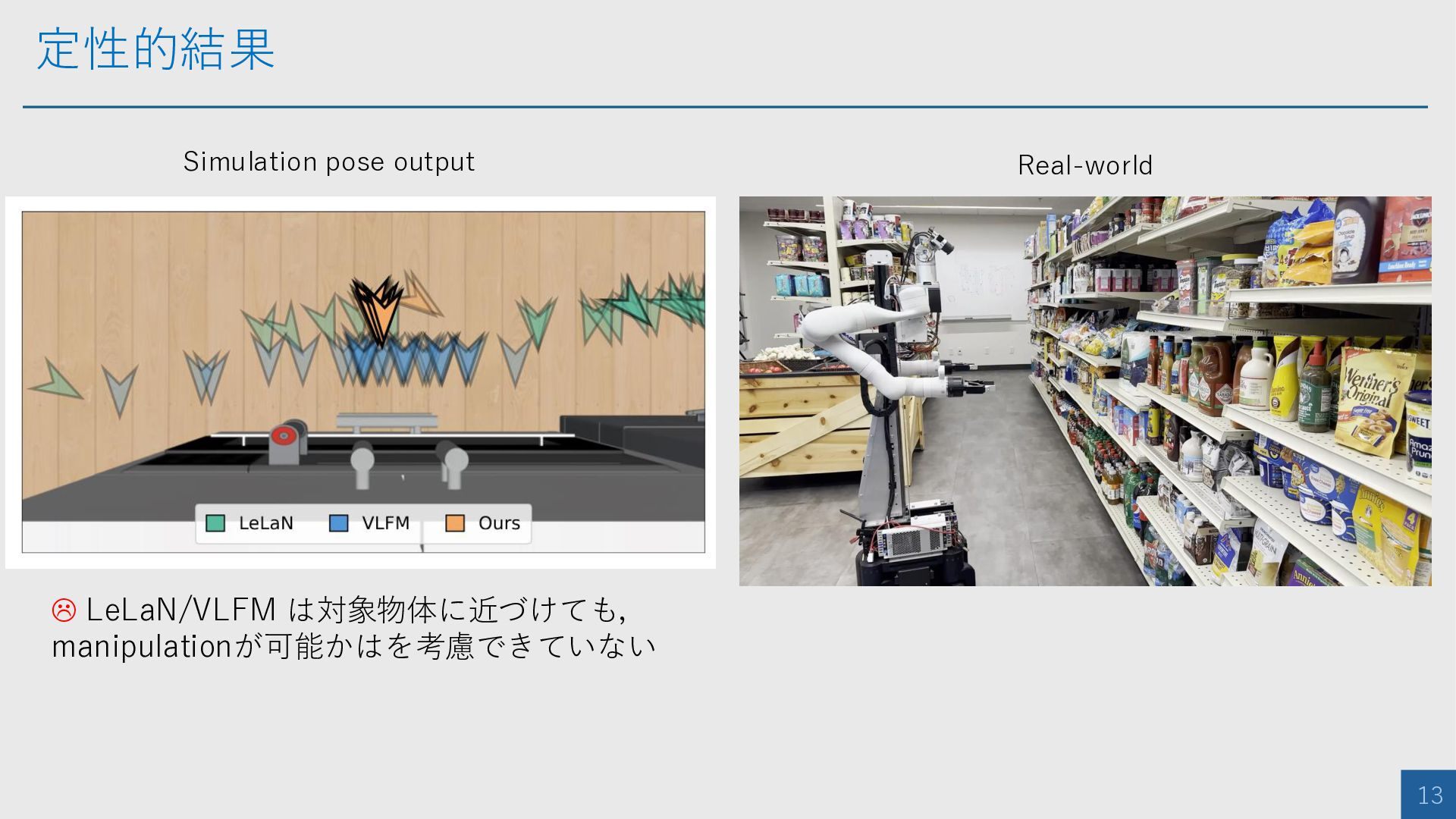
定性的結果 13 LeLaN/VLFM は対象物体に近づけても, manipulationが可能かはを考慮できていない Simulation pose output Real-world
• SR = 0.2 動作確認: Turn on stove 14
まとめ 15 • 背景 • 固定視点で学習したmanipulation policyをmobile robotにそのまま載せると OODになり失敗しやすい •
提案 • 3DGSで再構成した環境画像からpolicy に適したbase poseを探索 • 追加データを集めずに既存policyをmobile化 • 結果 • simulationおよび実機の両方で baselineを上回る性能
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![関連研究 5 手法 概要 LeLaN [Hirose+, CoRL23] VLFM [Yokoyama+, ICRA24]](https://files.speakerdeck.com/presentations/6a303f3411144fc69140d8e2c0f3bd52/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![実験設定 11 • simulation • robocasa [Nasiriany+, RSS24]上で環境がunseenの5 task •](https://files.speakerdeck.com/presentations/6a303f3411144fc69140d8e2c0f3bd52/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}