N., Kirillov, A., & Zagoruyko, S. (2020, August). End-to-end object detection with transformers. In European Conference on Computer Vision (pp. 213-229). Springer, Cham. 2. Yang, Z., Gong, B., Wang, L., Huang, W., Yu, D., & Luo, J. (2019). A fast and accurate one-stage approach to visual grounding. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 4683-4693) 3. Hinami, R., & Satoh, S. I. (2017). Discriminative learning of open-vocabulary object retrieval and localization by negative phrase augmentation. arXiv preprint arXiv:1711.09509. 4. Yu, L., Poirson, P., Yang, S., Berg, A. C., & Berg, T. L. (2016, October). Modeling context in referring expressions. In European Conference on Computer Vision (pp. 69-85). Springer, Cham. 5. Wu, C., Lin, Z., Cohen, S., Bui, T., & Maji, S. (2020). Phrasecut: Language-based image segmentation in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 10216-10225). 6. Hudson, D. A., & Manning, C. D. (2019). Gqa: A new dataset for real-world visual reasoning and compositional question answering. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 6700-6709). 7. Johnson, J., Hariharan, B., Van Der Maaten, L., Fei-Fei, L., Lawrence Zitnick, C., & Girshick, R. (2017). Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2901-2910). 8. Plummer, B. A., Wang, L., Cervantes, C. M., Caicedo, J. C., Hockenmaier, J., & Lazebnik, S. (2015). Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. In Proceedings of the IEEE international conference on computer vision (pp. 2641-2649).
{kind=link}
{kind=link}
{kind=link}
![関連研究:下流タスクの性能向上は実証されていない 4 カテゴリ 文献 概要 物体検出 [Carion+,ECCV20] Transformerを用いた物体検出モデルDETRを提案 テキスト 条件付き](https://files.speakerdeck.com/presentations/9987246b1c6c435abd9acff659c771df/slide_3.jpg){kind=link}
{kind=link}
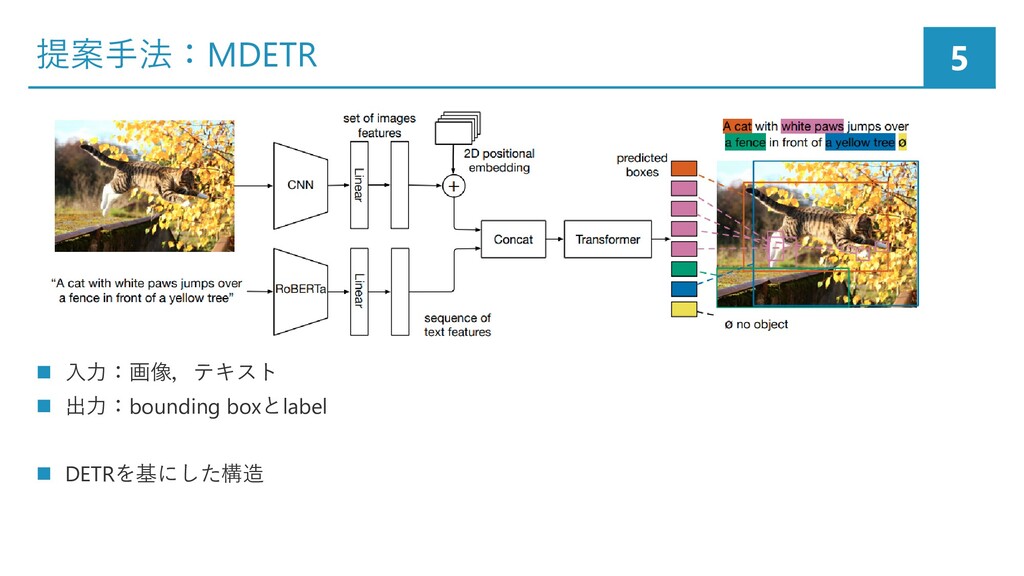
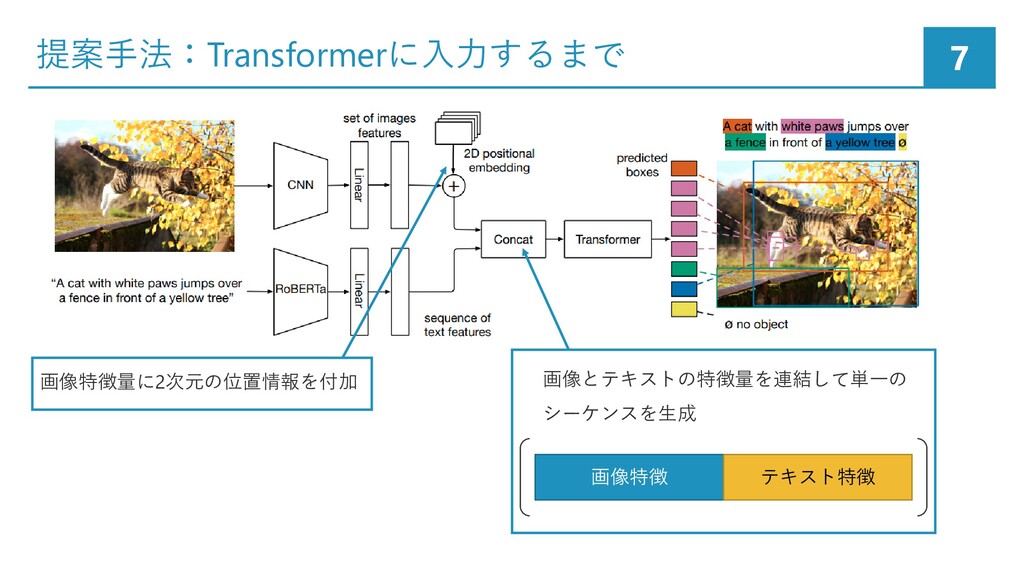
![提案手法:画像,テキストから特徴量の抽出 6 • CNN backbone:画像から特徴量を抽出 • ResNet/EfficientNetを使用 事前学習済みのRoBERTa[Liu+, 19]を用いて テキストをエンコーディング](https://files.speakerdeck.com/presentations/9987246b1c6c435abd9acff659c771df/slide_5.jpg){kind=link}
{kind=link}
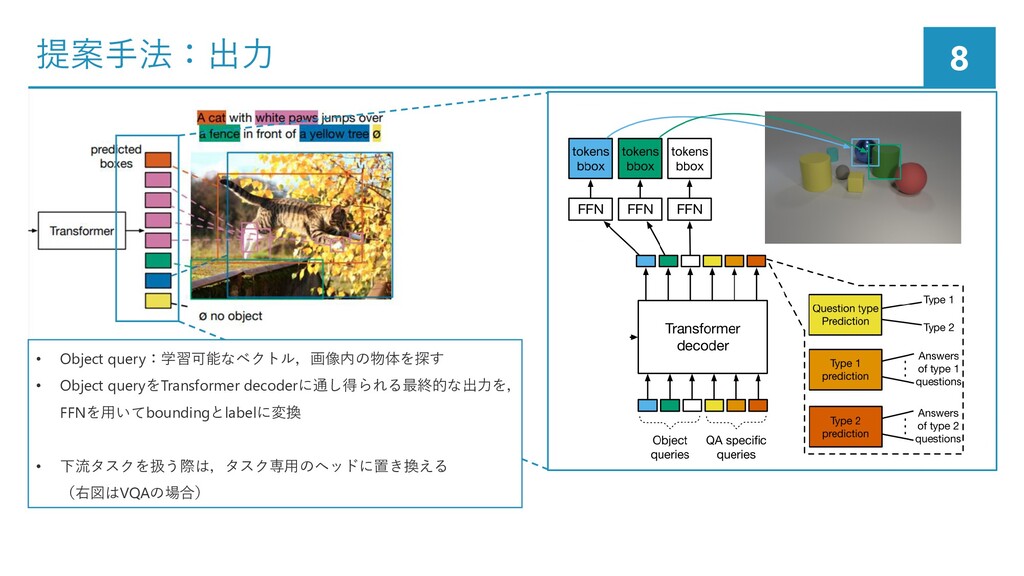{kind=link}
{kind=link}
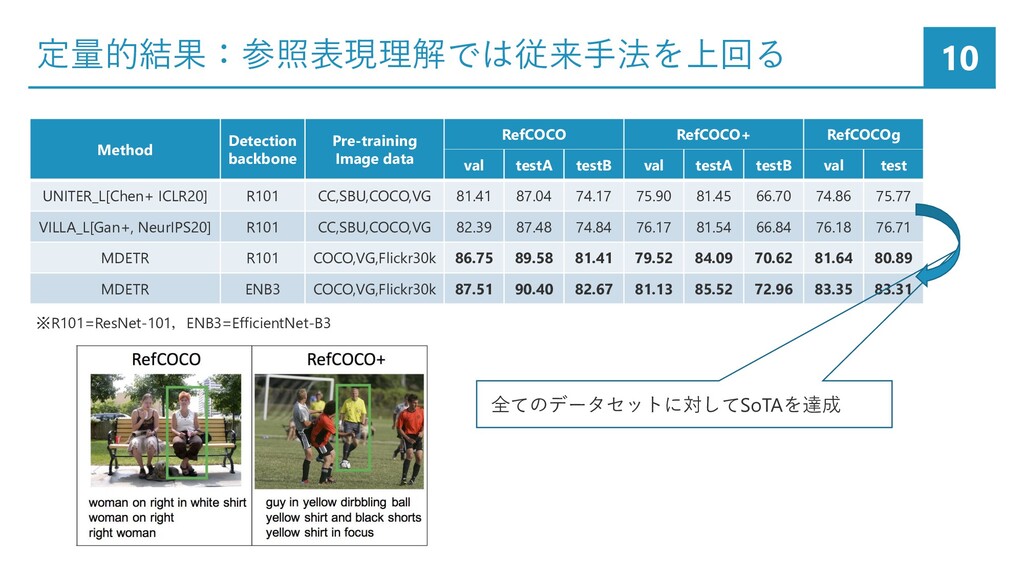{kind=link}
![Method Backbone PhraseCut M-IoU [email protected] [email protected] [email protected] RMI[Chen+,ICCV19] R101 21.1](https://files.speakerdeck.com/presentations/9987246b1c6c435abd9acff659c771df/slide_10.jpg){kind=link}
![Method Pre-training img data Test-dev Test-std LXMERT[Tan+, 19] VG, COCO(180k)](https://files.speakerdeck.com/presentations/9987246b1c6c435abd9acff659c771df/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}