Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Journal club] Pix2seq: A Language Modeling Fra...
Search
Semantic Machine Intelligence Lab., Keio Univ.
PRO
November 17, 2022
Technology
0
290
[Journal club] Pix2seq: A Language Modeling Framework for Object Detection
Semantic Machine Intelligence Lab., Keio Univ.
PRO
November 17, 2022
Tweet
Share
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] V-DPO: Mitigating Hallucination in Large Vision Language Models via Vision-Guided Direct Preference Optimization
keio_smilab
PRO
0
110
[Journal club] Model Alignment as Prospect Theoretic Optimization
keio_smilab
PRO
0
120
[Journal club] DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models
keio_smilab
PRO
0
63
[Journal club] LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders
keio_smilab
PRO
2
88
Will multimodal language processing change the world?
keio_smilab
PRO
3
560
[Journal club] MOKA: Open-Vocabulary Robotic Manipulation through Mark-Based Visual Prompting
keio_smilab
PRO
0
170
[Journal club] Seeing the Unseen: Visual Common Sense for Semantic Placement
keio_smilab
PRO
0
160
[Journal club] Language-Embedded Gaussian Splats (LEGS): Incrementally Building Room-Scale Representations with a Mobile Robot
keio_smilab
PRO
0
160
[Journal club] RAM: Retrieval-Based Affordance Transfer for Generalizable Zero-Shot Robotic Manipulation
keio_smilab
PRO
1
200
Other Decks in Technology
See All in Technology
問 1:以下のコンパイラを証明せよ(予告編) #kernelvm / Kernel VM Study Kansai 11th
ytaka23
3
390
OPENLOGI Company Profile for engineer
hr01
1
26k
勝手に!深堀り!Cloud Run worker pools / Deep dive Cloud Run worker pools
iselegant
4
650
Part1 GitHubってなんだろう?その1
tomokusaba
3
580
大規模サーバーレスプロジェクトのリアルな零れ話
maimyyym
3
160
Асинхронная коммуникация в Go: от понятного к душному. Дима Некрасов, Otello, 2ГИС
lamodatech
0
2k
PagerDuty×ポストモーテムで築く障害対応文化/Building a culture of incident response with PagerDuty and postmortems
aeonpeople
3
570
AIエージェント開発手法と業務導入のプラクティス
ykosaka
9
2.7k
Azure × MCP 入門
ry0y4n
8
1.4k
意思決定を支える検索体験を目指してやってきたこと
hinatades
PRO
0
400
非root化Androidスマホでも動く仮想マシンアプリを試してみた
arkw
0
110
Pythonデータ分析実践試験 出題傾向や学習のポイントとテクニカルハイライト
terapyon
1
130
Featured
See All Featured
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
31
1.2k
Adopting Sorbet at Scale
ufuk
76
9.3k
jQuery: Nuts, Bolts and Bling
dougneiner
63
7.7k
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
30
2k
Music & Morning Musume
bryan
47
6.5k
The Invisible Side of Design
smashingmag
299
50k
It's Worth the Effort
3n
184
28k
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
29
2.6k
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
32
2.3k
A better future with KSS
kneath
239
17k
YesSQL, Process and Tooling at Scale
rocio
172
14k
Embracing the Ebb and Flow
colly
85
4.7k
Transcript
Ting Chen1, Saurabh Saxena1, Lala Li1, David J. Fleet1, Geoffrey
Hinton1 1: Google Research, Brain Team 慶應義塾大学 杉浦孔明研究室 小槻誠太郎 T. Chen, S. Saxena, L. Li, D.J. Fleet, and G. Hinton, “Pix2seq: A language modeling framework for object detection,” ICLR, 2022.
概要 – Pix2Seq 既存の物体検出モデルはタスクに特化した設定が多く為されていた ➔複雑な学習 / 汎用性の低下 物体検出を 入力画像で条件付けしたLanguage Modelingのような形で定式化
物体検出に特化した構造やengineeringを使用せず DETR, Faster R-CNNに対してcompetitiveな性能を達成 2
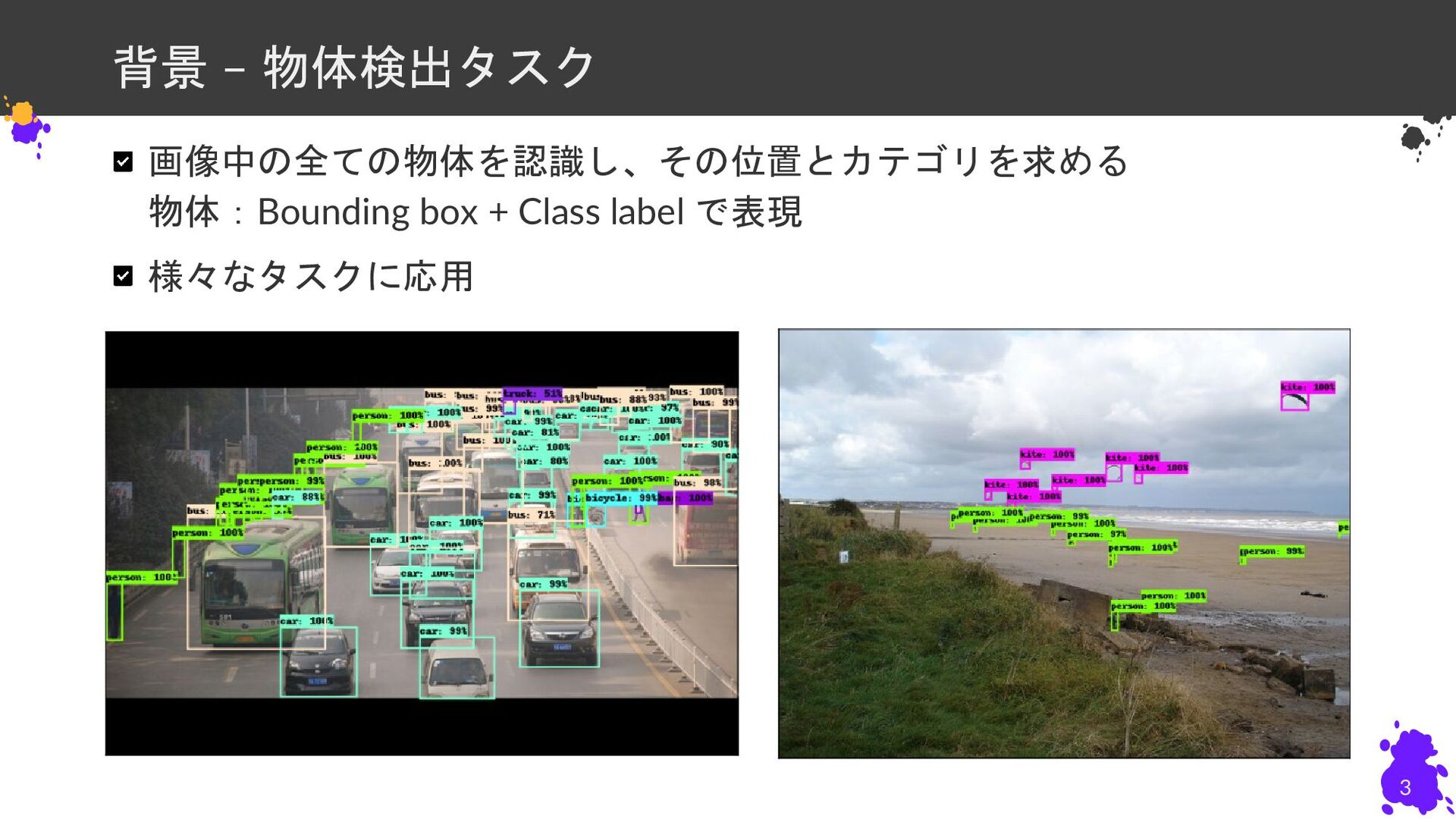
背景 – 物体検出タスク 画像中の全ての物体を認識し、その位置とカテゴリを求める 物体:Bounding box + Class label で表現
様々なタスクに応用 3
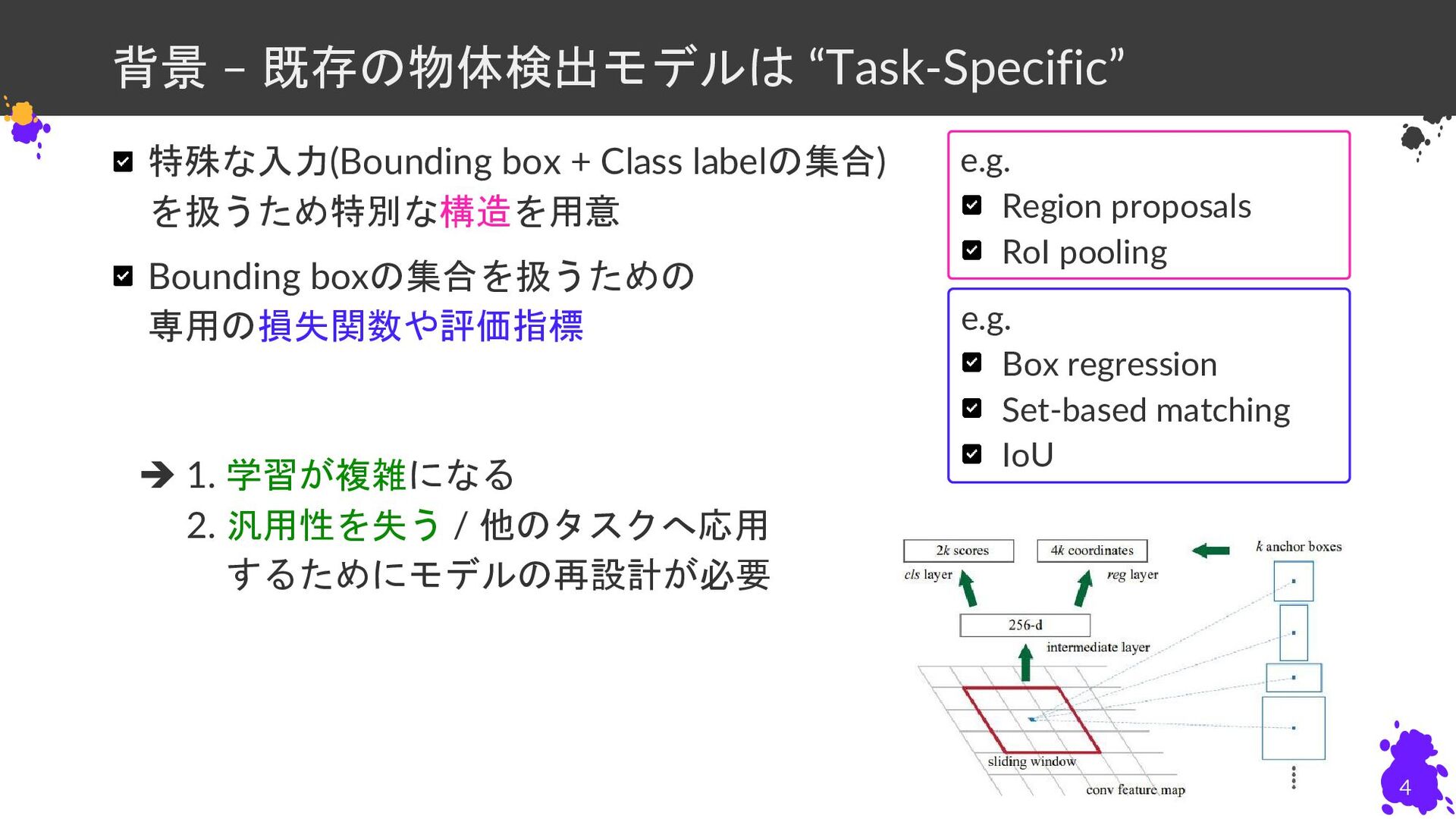
背景 – 既存の物体検出モデルは “Task-Specific” 特殊な入力(Bounding box + Class labelの集合) を扱うため特別な構造を用意
Bounding boxの集合を扱うための 専用の損失関数や評価指標 ➔ 1. 学習が複雑になる ➔ 2. 汎用性を失う / 他のタスクへ応用 ➔ 2. するためにモデルの再設計が必要 4 e.g. Region proposals RoI pooling e.g. Box regression Set-based matching IoU
関連研究 – 既存の物体検出モデルは “Task-Specific” 5 Faster R-CNN [Ren+, NeurIPS15] •
標準的な物体検出手法 • Bounding boxの集合を予測するため大量のProposal • 人手で設定する要素(Anchorsなど)に依存 • 重複を削除するためによくNMSが用いられる DETR [Carion+, ECCV20] • Transformerを採用し、End-to-Endの物体検出 • 大量のProposalを出してNMSを行うことを避けた • 学習で獲得する”object query”が必要
提案 – Pix2Seq : “Task-Agnostic”なモデル + 学習方法 “深層学習モデルがどこにどんな物体があるかを理解しているのであれば、 それを取り出す表現方法を教えれば良いだろう” ➔
画像を与え、Bounding boxの座標(y min , x min , y max , x max )とカテゴリを ➔ Language Modeling (LM) に似た形式 で順に出力 6
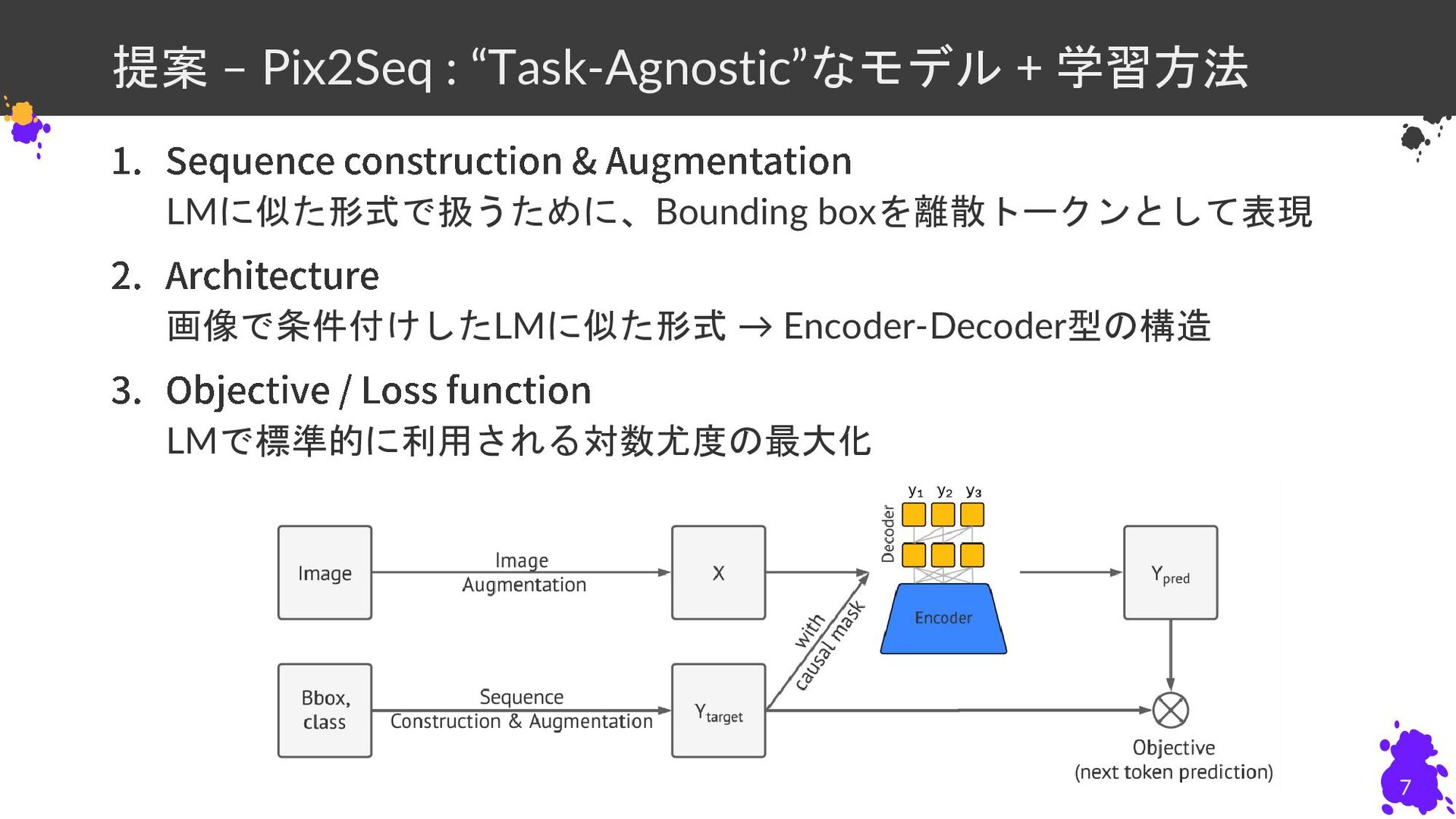
提案 – Pix2Seq : “Task-Agnostic”なモデル + 学習方法 LMに似た形式で扱うために、Bounding boxを離散トークンとして表現 画像で条件付けしたLMに似た形式
→ Encoder-Decoder型の構造 LMで標準的に利用される対数尤度の最大化 7
Sequence construction – Bounding boxを離散トークンに Class labelはもともと離散トークンとして表現される(object idなど) 8 1.
Bounding boxの位置座標 2. 正規化した位置座標 → (54, 261, 439, 409) → (0.11, 0.41, 0.91, 0.64) → (55, 205, 454, 319) 画像のサイズに寄らず一定の 整数値から選ばれるようになる
Sequence construction – Bounding boxを離散トークンに Class labelはもともと離散トークンとして表現される(object idなど) Bounding boxも離散トークンに変換
一つの物体に対して最終的に得られるトークン列は [ , class] ➔ LMにおけるDecoderの入力(全ての物体の情報)は [SOS, 1 1 1 1, class1, classL, EOS] 9 → (54, 261, 439, 409) → (0.11, 0.41, 0.91, 0.64) → (55, 205, 454, 319) → [55, 205, 454, 319, 1764]
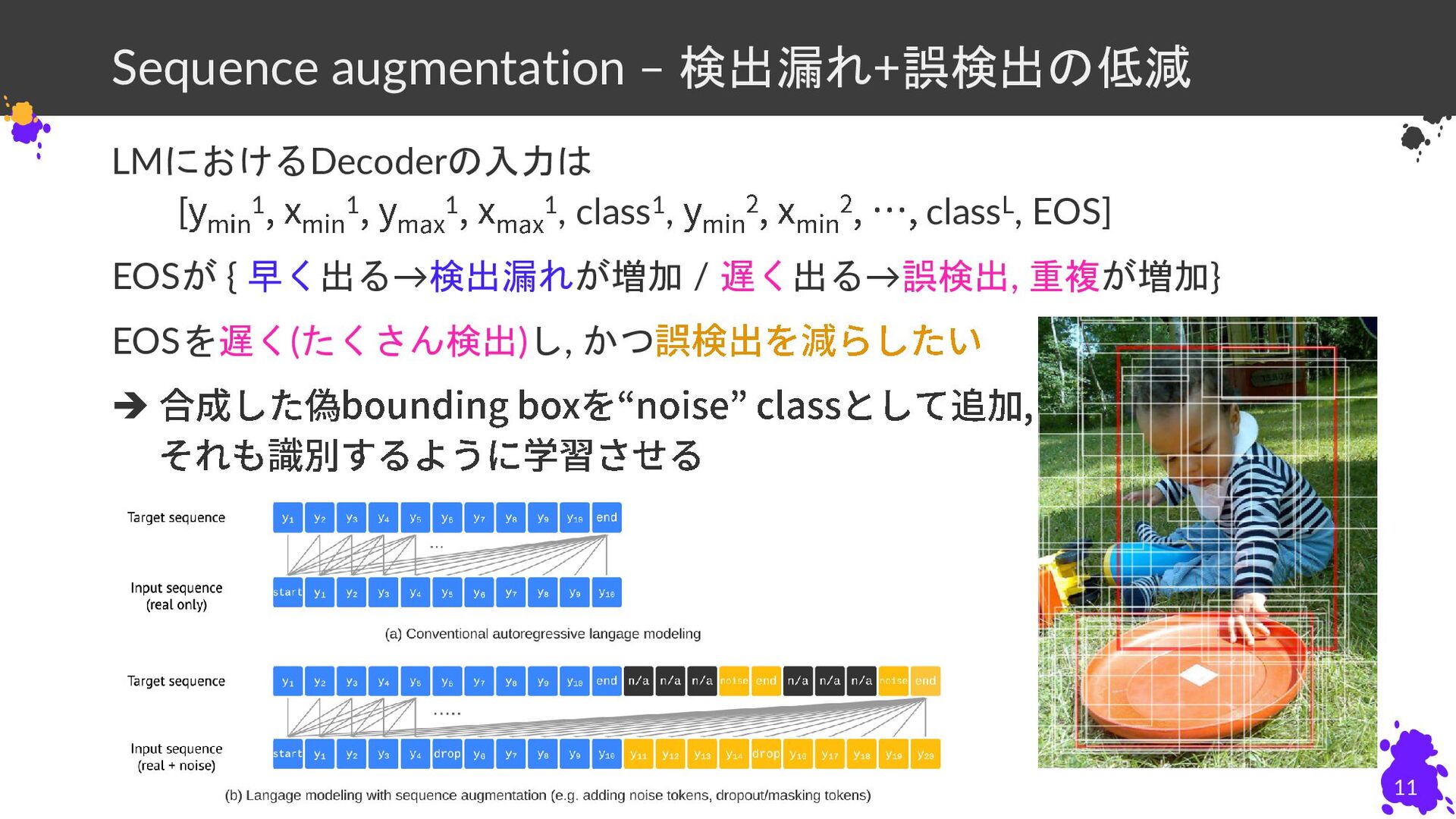
Sequence augmentation – 検出漏れ+誤検出の低減 LMにおけるDecoderの入力は [ 1 1 1 1,
class1, classL, EOS] EOSが { 早く出る→検出漏れが増加 / 遅く出る→誤検出, 重複が増加} EOSを遅く(たくさん検出)し, かつ ➔ ??? 10
Sequence augmentation – 検出漏れ+誤検出の低減 LMにおけるDecoderの入力は [ 1 1 1 1,
class1, classL, EOS] EOSが { 早く出る→検出漏れが増加 / 遅く出る→誤検出, 重複が増加} EOSを遅く(たくさん検出)し, かつ ➔ ➔ 11
LMにおけるDecoderの入力は [ 1 1 1 1, class1, classL, EOS] EOSが
{ 早く出る→検出漏れが増加 / 遅く出る→誤検出, 重複が増加} EOSを遅く(たくさん検出)し, かつ ➔ ➔ Sequence augmentation – 検出漏れ+誤検出の低減 12 後半に偽bounding boxを追加 偽bounding boxに対する座標の予測はback prop.しない (どこからが偽物かは学習時は分かるので狙ってdetach可能)
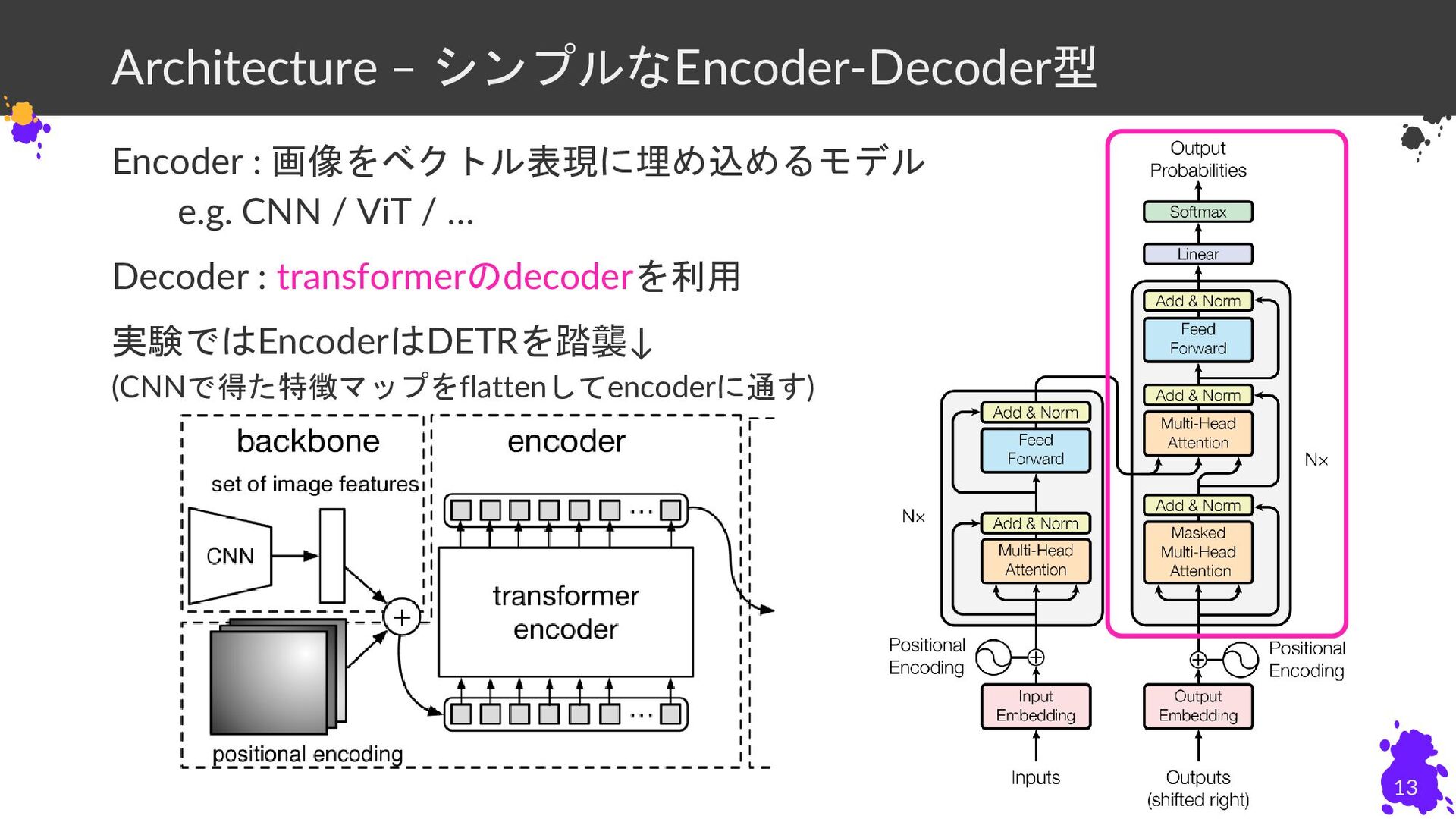
Architecture – シンプルなEncoder-Decoder型 Encoder : 画像をベクトル表現に埋め込めるモデル e.g. CNN / ViT
/ … Decoder : transformerのdecoderを利用 実験ではEncoderはDETRを踏襲↓ (CNNで得た特徴マップをflattenしてencoderに通す) 13
Objective / Loss function – Language Modelingと同様 LMで標準的に利用される対数尤度の最大化 maximize
𝑗 𝑤𝑗 log 𝑃 𝑦𝑗 𝑥, 𝑦1:𝑗−1 ) 𝑥 : 画像 𝑦 : トークン列のGround truth 𝑦 : 予測したトークン列 𝑤𝑗 : 著者らは1にしたが、class tokenへの重みづけを増やしたりできる 14
定性的結果 – 細かな物体も正確に予測 15
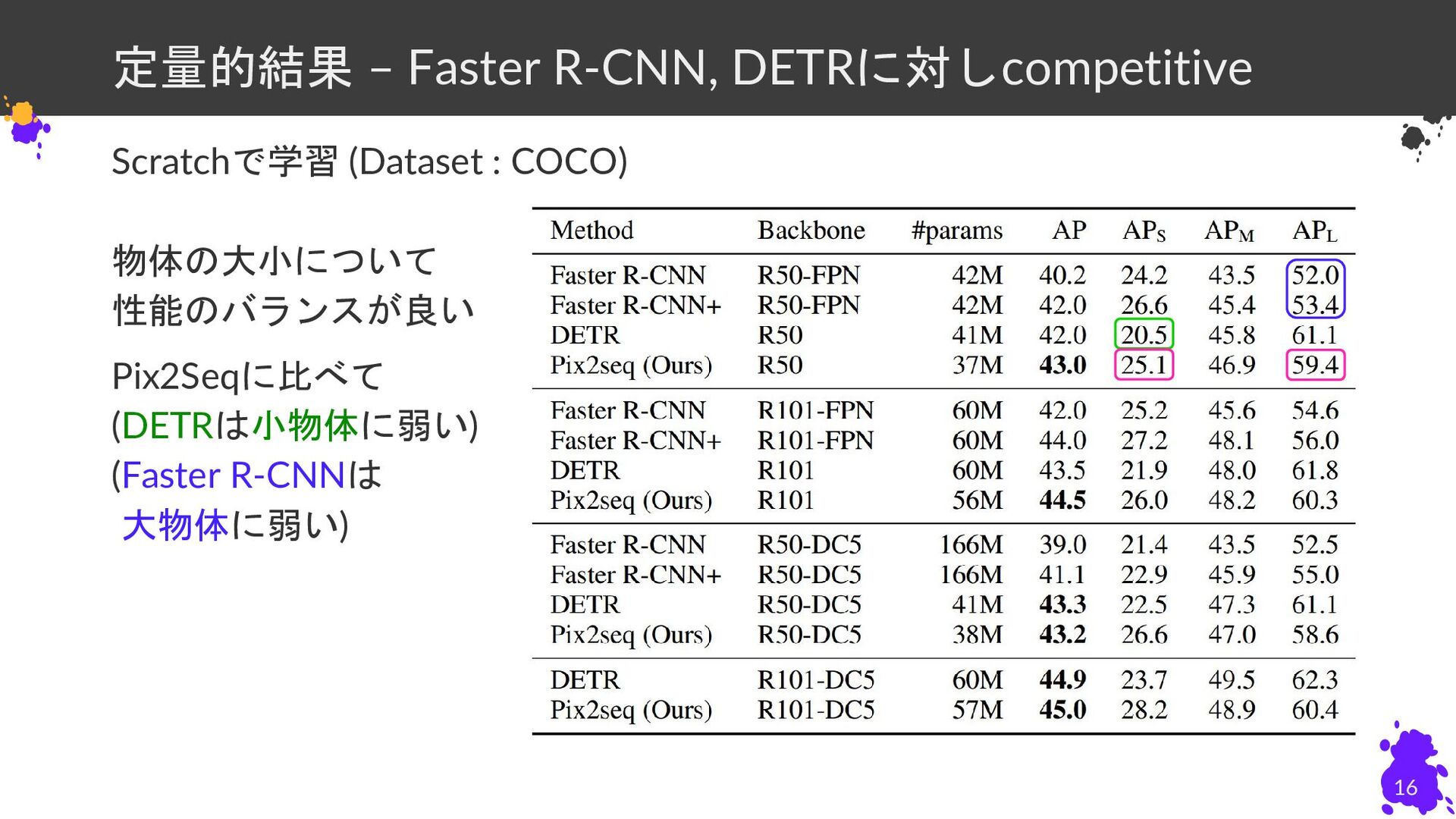
定量的結果 – Faster R-CNN, DETRに対しcompetitive Scratchで学習 (Dataset : COCO) 物体の大小について
性能のバランスが良い Pix2Seqに比べて (DETRは小物体に弱い) (Faster R-CNNは (大物体に弱い) 16
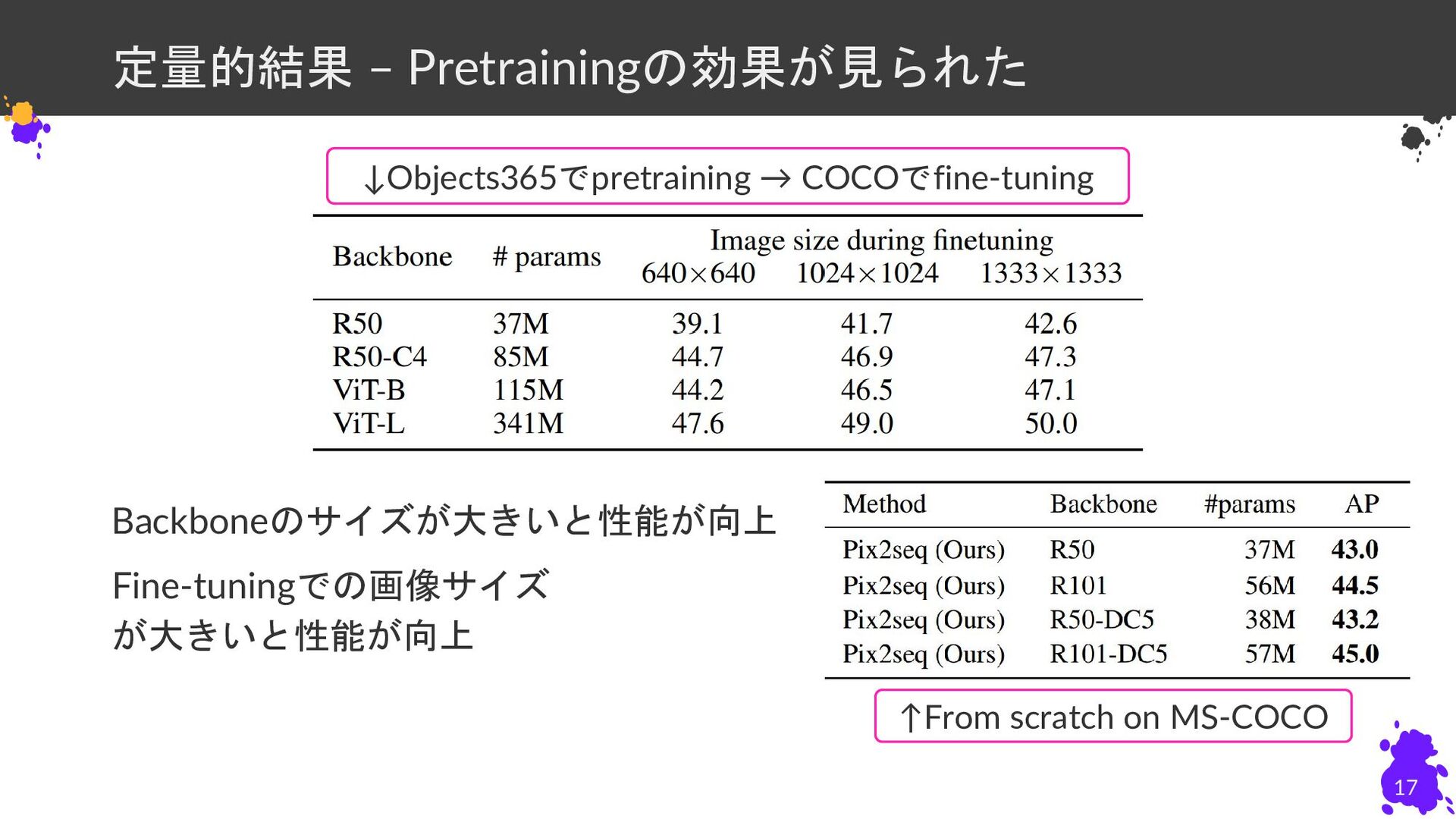
Backboneのサイズが大きいと性能が向上 Fine-tuningでの画像サイズ が大きいと性能が向上 定量的結果 – Pretrainingの効果が見られた 17 ↑From scratch on
MS-COCO ↓Objects365でpretraining → COCOでfine-tuning
まとめ – Pix2Seq 既存の物体検出モデルはタスクに特化した設定が多く為されていた ➔複雑な学習 / 汎用性の低下 物体検出を 入力画像で条件付けしたLanguage Modelingのような形で定式化
物体検出に特化した構造やengineeringを使用せず DETR, Faster R-CNNに対してcompetitiveな性能を達成 18
Appendix – Links • Paper (ICLR2022) • Discussion @OpenReview •
Official Implementation (TensorFlow) • Official Blog • Demo (Colab.) 19
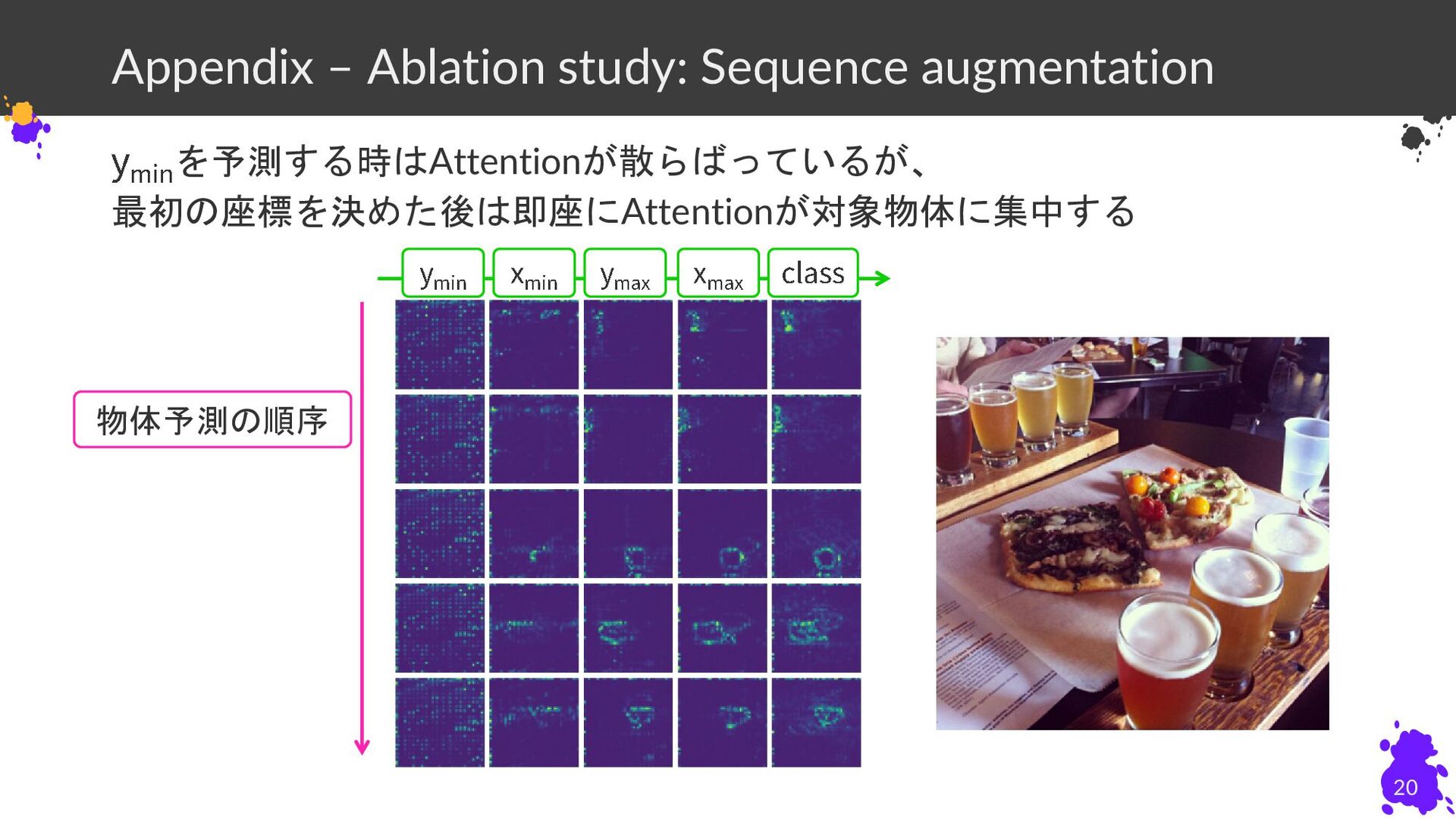
Appendix – Ablation study: Sequence augmentation 20 を予測する時はAttentionが散らばっているが、 最初の座標を決めた後は即座にAttentionが対象物体に集中する 物体予測の順序
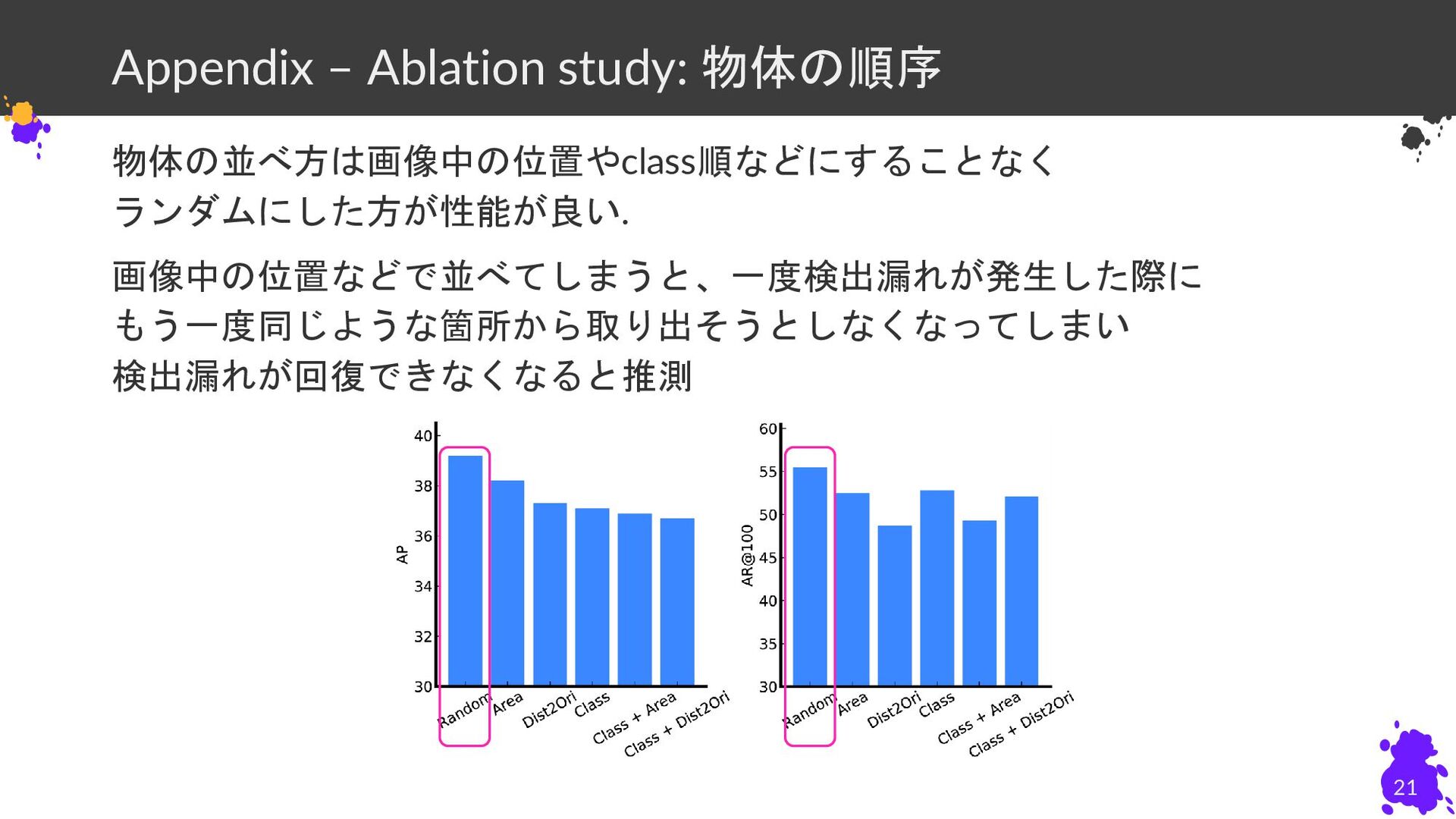
Appendix – Ablation study: 物体の順序 物体の並べ方は画像中の位置やclass順などにすることなく ランダムにした方が性能が良い. 画像中の位置などで並べてしまうと、一度検出漏れが発生した際に もう一度同じような箇所から取り出そうとしなくなってしまい 検出漏れが回復できなくなると推測
21
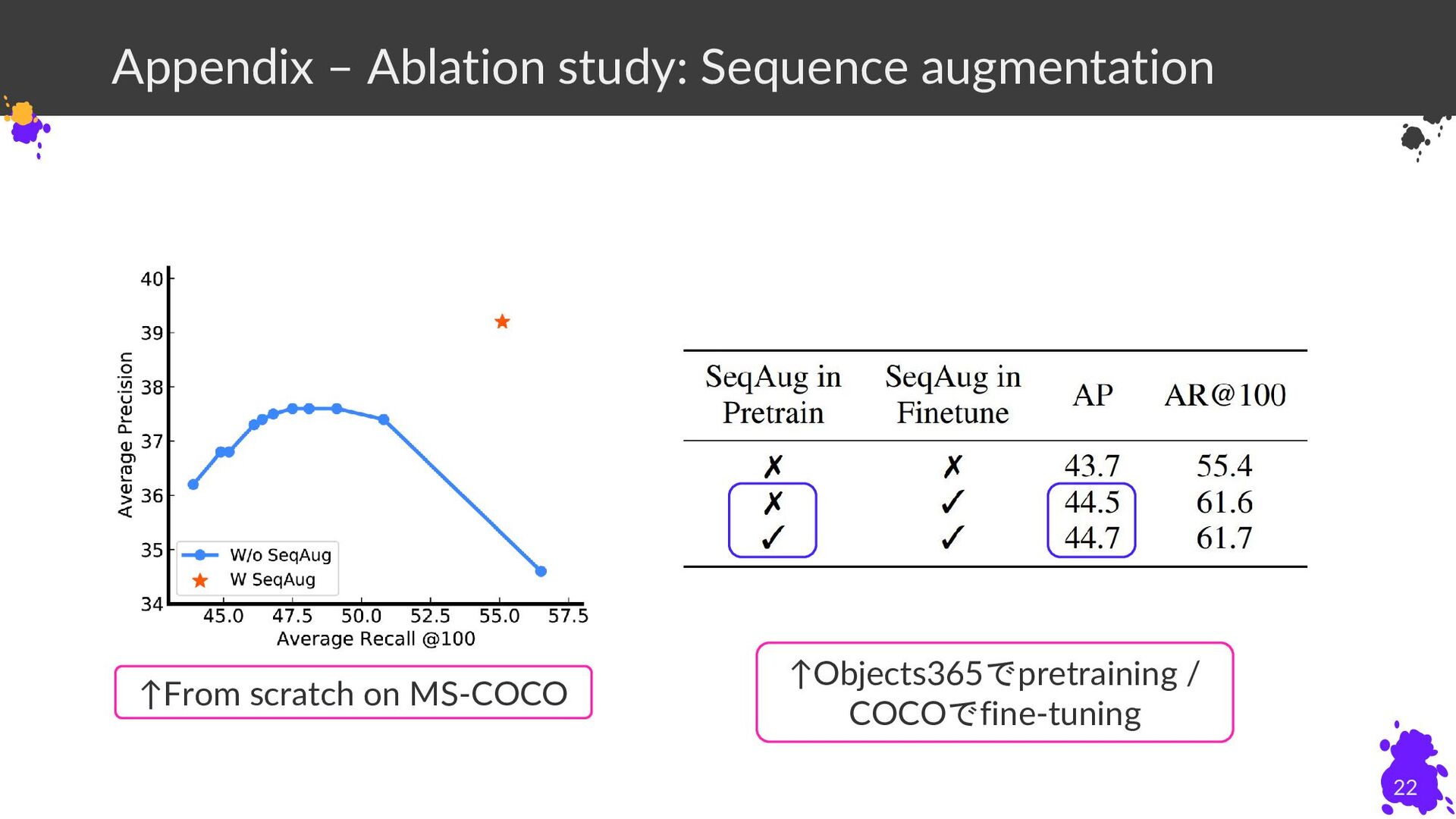
Appendix – Ablation study: Sequence augmentation 22 ↑From scratch on
MS-COCO ↑Objects365でpretraining / COCOでfine-tuning
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![関連研究 – 既存の物体検出モデルは “Task-Specific” 5 Faster R-CNN [Ren+, NeurIPS15] •](https://files.speakerdeck.com/presentations/54fd84c3d14546f599494f96bbde39a9/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![LMにおけるDecoderの入力は [ 1 1 1 1, class1, classL, EOS] EOSが](https://files.speakerdeck.com/presentations/54fd84c3d14546f599494f96bbde39a9/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}