Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
〜小さく始めて大きく育てる〜データ分析基盤の開発から活用まで
Search
Niino
April 15, 2024
Technology
3.4k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
〜小さく始めて大きく育てる〜データ分析基盤の開発から活用まで
2024/4/11に開催された、DevelopersIO OSAKA Day One -re:union-でのセッションスライドです。
Niino
April 15, 2024
More Decks by Niino
See All by Niino
祝!Iceberg祭開幕!re:Invent 2024データレイク関連アップデート10分総ざらい
kniino
4
1.1k
Amazon Personalizeの レコメンドシステム構築、実際何するの? 〜大体10分で具体的なイメージをつかむ〜
kniino
1
950
Iceberg で Amazon Athena をデータウェアハウスぽく使おう
kniino
0
8.1k
20分で大体わかる! AWS Glue Data Qualityによる データ品質検査
kniino
0
31k
ダッシュボードもコード管理!Amazon QuickSightで考えるBIOps
kniino
0
3.3k
Other Decks in Technology
See All in Technology
大量データに対しても、生成AIを用いてリーズナブルにデータ加工をしたい!Databricksのai_queryについて調べてみた
kamoshika
1
270
クラウドを使う側から、作る側へ / 大吉祥寺.pm 2026前夜祭
fujiwara3
4
1k
Alphaモジュール使っていいのかい!?いけないのかい!?どっちなんだいっ!?
watany
1
320
変更し続けられるシステムをどう保つか — AI時代のSSoTという設計原則
kawauso
1
1k
アップデートで何が変わった?デモで学んで使いこなすIBM Bob2.0
muehara
0
220
AI時代におけるエンジニアの新たな役割──FDEとクオリアの探求/登壇資料(戸井田 裕貴)
hacobu
PRO
0
300
壊して学ぶAWS CDK: そのcdk deployで消えるもの、残るもの
k_adachi_01
1
470
AIが実装を自走する時代の認知負債との戦い
lycorptech_jp
PRO
2
1.1k
『モデル + ハーネス』で読み解く AIエージェント入門
oracle4engineer
PRO
2
160
AIとハーネスで育てるトランスコンパイラ / 20260722 Yasushi Katayama
shift_evolve
PRO
3
760
”AIを使う” から ”AIに任せる” へ ─ 開発プロセスを再設計してAIを組織標準にするまで
cyberagentdevelopers
PRO
1
130
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
Featured
See All Featured
[SF Ruby Conf 2025] Rails X
palkan
2
1.2k
Statistics for Hackers
jakevdp
799
230k
Designing Powerful Visuals for Engaging Learning
tmiket
1
450
Joys of Absence: A Defence of Solitary Play
codingconduct
1
420
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
260
How to Build an AI Search Optimization Roadmap - Criteria and Steps to Take #SEOIRL
aleyda
1
2.1k
The Curse of the Amulet
leimatthew05
2
13k
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.6k
CoffeeScript is Beautiful & I Never Want to Write Plain JavaScript Again
sstephenson
162
16k
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
Transcript
〜⼩さく始めて⼤きく育てる〜 データ分析基盤の開発から活⽤まで クラスメソッド株式会社 データアナリティクス事業本部
⾃⼰紹介 niino • データアナリティクス事業本部 インテグレーション部 機械学習チーム • 2023 Japan AWS
Top Engineer(Analytics) • データ分析基盤に関するコンサルティング • 最近の⾼い買い物︓ベース • 奈良県出⾝ ⼤阪オフィス所属 この辺の出身
もくじ • はじめに • データ分析をもっと簡単にするために ◦ データ品質(Glue Data Quality) ◦
データの保存(Apache Iceberg) ◦ オーケストレーション(dbt) ◦ データ共有(Redshift Data Sharing) • マネージドサービスを使って⼿軽にデータ活⽤を 始める • 機械学習の例(レコメンド)
機械学習チームのミッション 事業会社のあらゆる機械学習課題を解決する
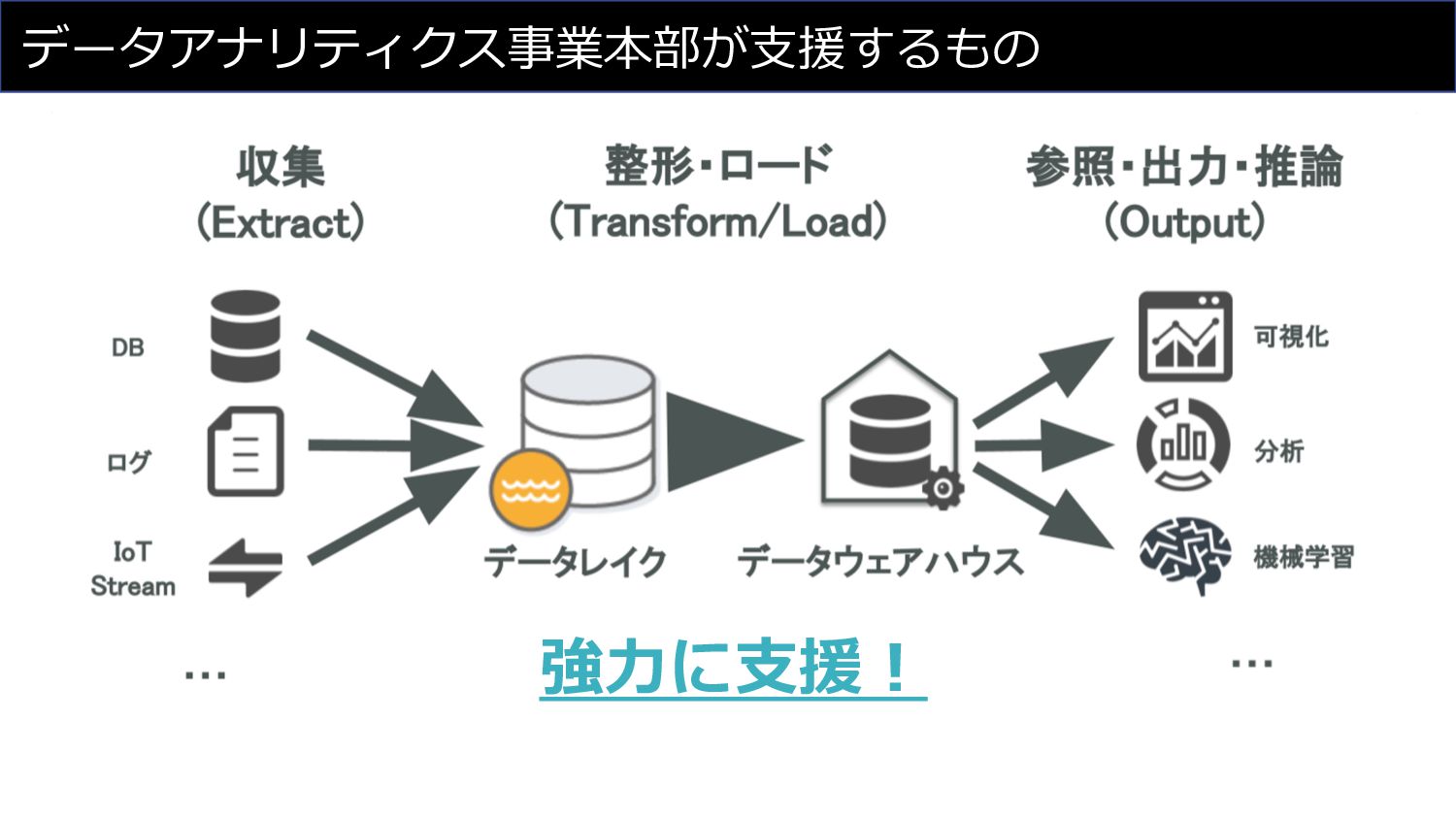
データアナリティクス事業本部が⽀援するもの 強⼒に⽀援︕
機械学習案件の対応実績 (概要) • 機械学習のコア部分 • 機械学習モデル開発、評価 • AI・機械学習関連のクラウドサービス(SaaS)の適⽤ • MLOpsを考慮した機械学習基盤の構築⽀援
• クラウドサービスを活⽤した機械学習基盤の構築 • データ前処理、後処理 • 機械学習パイプライン • CI/CD • AI・機械学習関連のクラウドサービスのレクチャー • Amazon SageMaker(AI・機械学習の開発環境)と周辺サービスの活⽤ • そのほか対応可能なAI・機械学習関連のクラウドサービス 本⽇はレコメンドの機械 学習課題の例と、機械学 習に⼗分な品質のデータ を⽤意するための観点・ ツールをご紹介します。
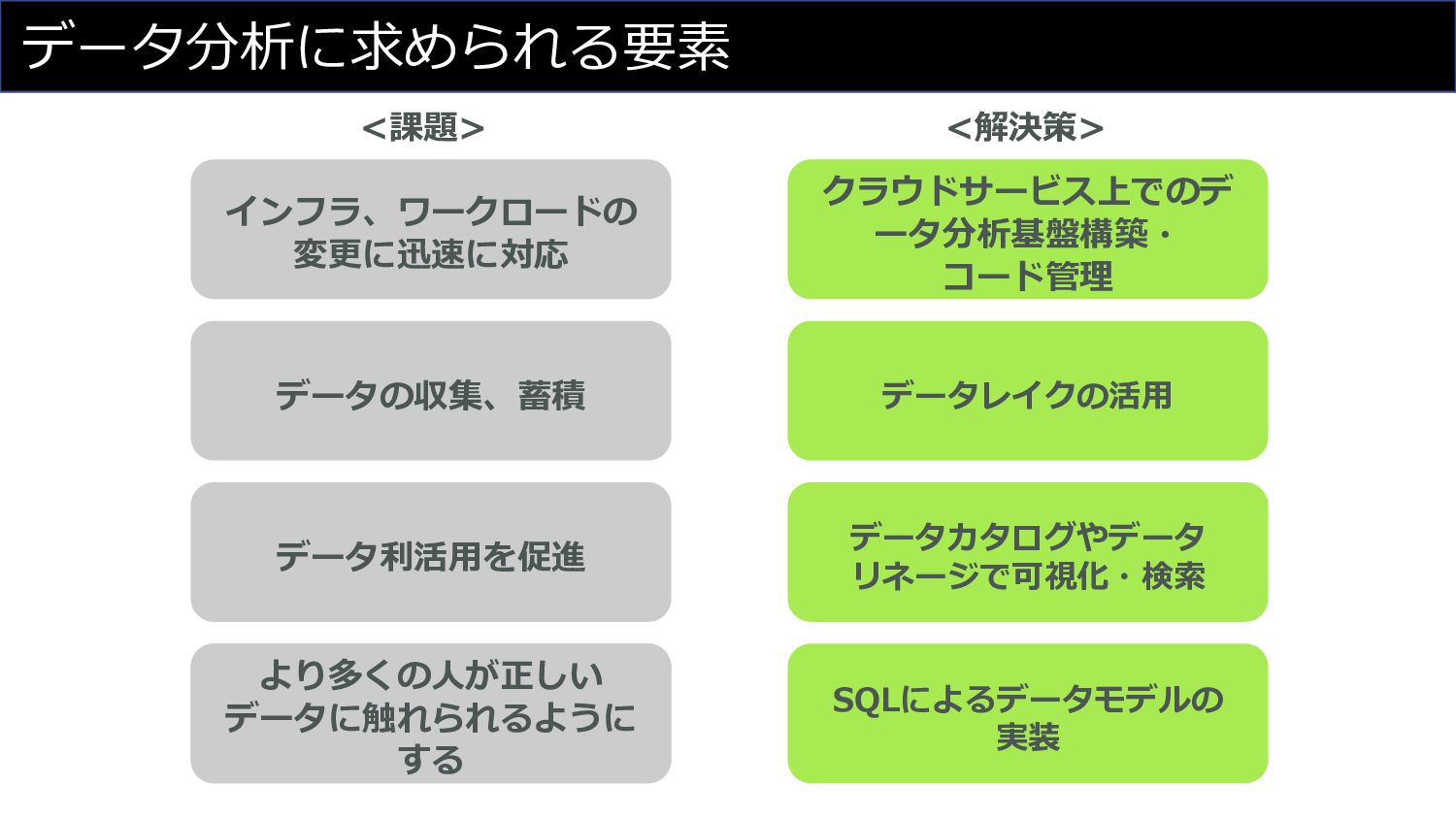
データ分析に求められる要素 インフラ、ワークロードの 変更に迅速に対応 データの収集、蓄積 データ利活⽤を促進 より多くの⼈がデータ分析 を触れられるようにする より多くの⼈が正しい データに触れられるように する
<課題>
データ分析に求められる要素 クラウドサービス上でのデ ータ分析基盤構築・ コード管理 データレイクの活⽤ データカタログやデータ リネージで可視化・検索 SQLによるデータモデルの 実装 <解決策>
インフラ、ワークロードの 変更に迅速に対応 データの収集、蓄積 データ利活⽤を促進 より多くの⼈がデータ分析 を触れられるようにする より多くの⼈が正しい データに触れられるように する <課題>
データ分析に求められる要素 クラウドサービス上でのデ ータ分析基盤構築・ コード管理 データレイクの活⽤ データカタログやデータ リネージで可視化・検索 SQLによるデータモデルの 実装 <解決策>
インフラ、ワークロードの 変更に迅速に対応 データの収集、蓄積 データ利活⽤を促進 より多くの⼈がデータ分析 を触れられるようにする より多くの⼈が正しい データに触れられるように する <課題> 結構⼤変
データ分析をもっと簡単にするために • データ品質(Glue Data Quality) • データの保存(Apache Iceberg) • オーケストレーション(dbt)
• データ共有(Redshift Data Sharing)
データ品質
データ分析においてデータの品質は重要︕ データパイプラインがエ ラーになった… 分析結果が 間違ってる…
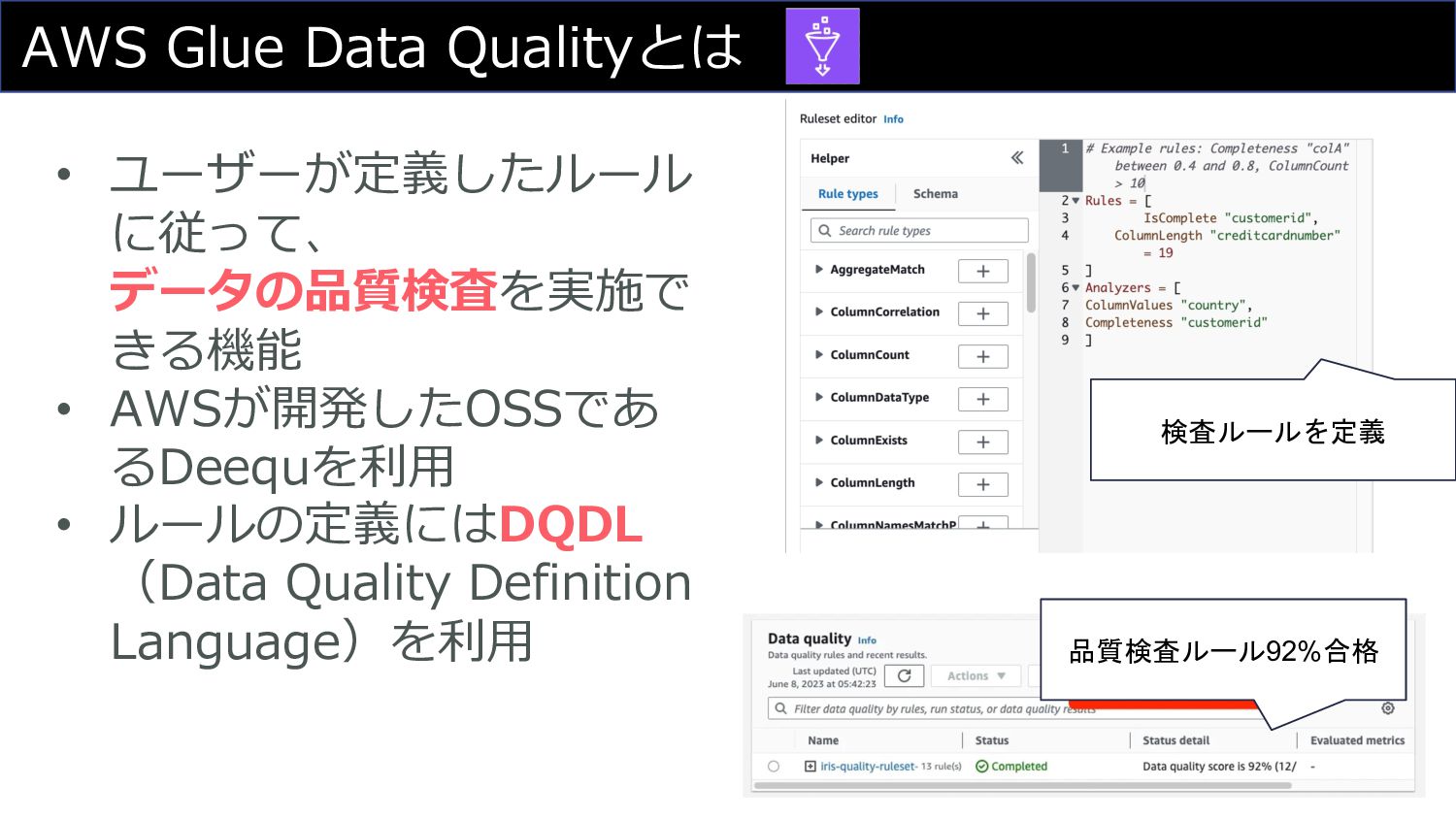
AWS Glue Data Qualityとは • ユーザーが定義したルール に従って、 データの品質検査を実施で きる機能 •
AWSが開発したOSSであ るDeequを利⽤ • ルールの定義にはDQDL (Data Quality Definition Language)を利⽤ 品質検査ルール92%合格 検査ルールを定義
Data Qualityの便利なところ • DQDLを使って簡単にデータ品質検査のルールを定義可能 • CloudWatchやSNSを組み合わせることで通知可能 • 既存データを⾃動で分析して最適なルールを レコメンド •
Glue Job同様、ワーカーを増やしてスケールアップが 可能 • 静的なルールに合致しないデータを検出するだけでなく、 意図しない変化や異常を⾃動的に検出可能(プレビュー 機能)
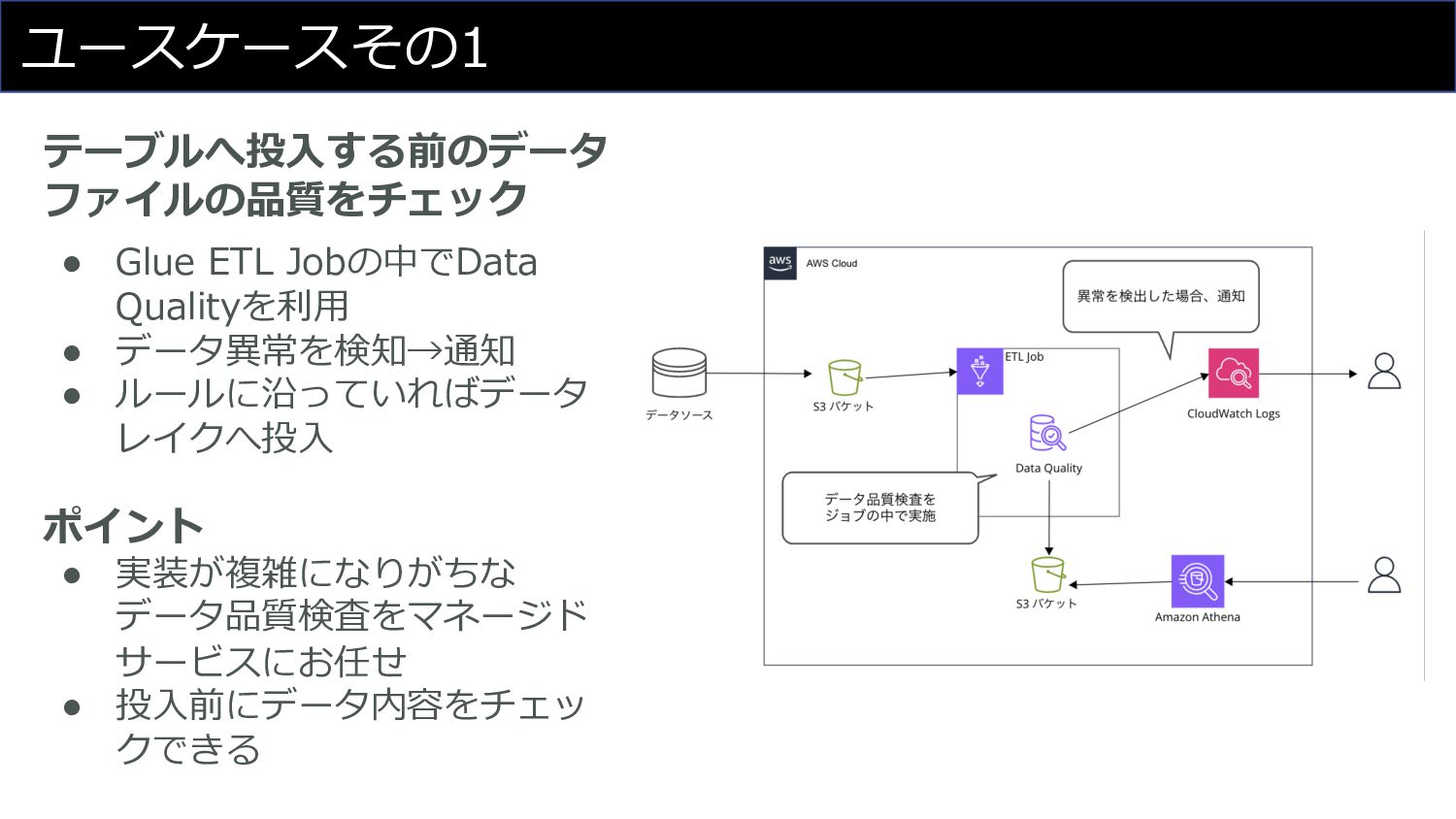
ユースケースその1 テーブルへ投⼊する前のデータ ファイルの品質をチェック • Glue ETL Jobの中でData Qualityを利⽤ • データ異常を検知→通知
• ルールに沿っていればデータ レイクへ投⼊ ポイント • 実装が複雑になりがちな データ品質検査をマネージド サービスにお任せ • 投⼊前にデータ内容をチェッ クできる
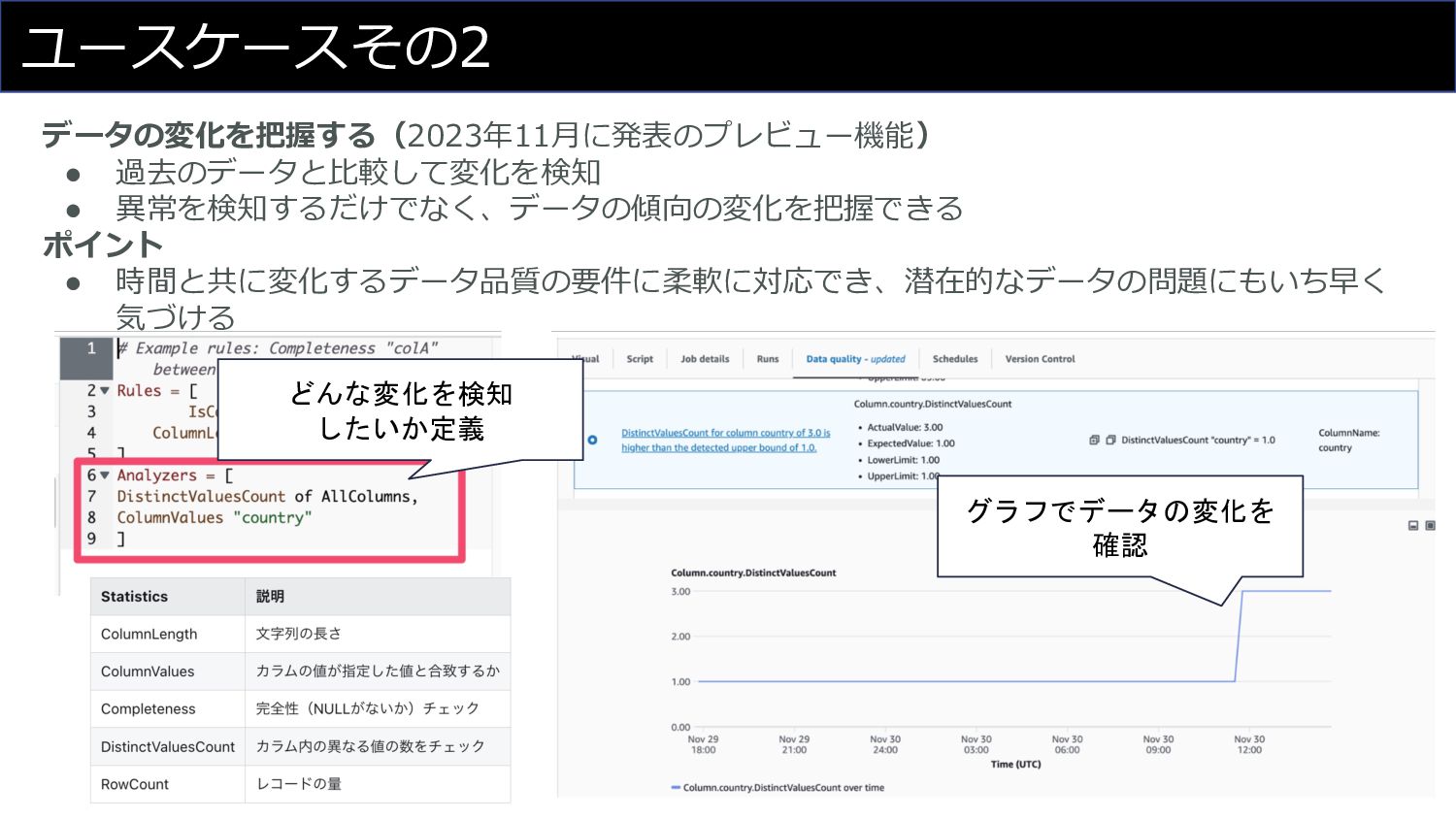
ユースケースその2 データの変化を把握する(2023年11⽉に発表のプレビュー機能) • 過去のデータと⽐較して変化を検知 • 異常を検知するだけでなく、データの傾向の変化を把握できる ポイント • 時間と共に変化するデータ品質の要件に柔軟に対応でき、潜在的なデータの問題にもいち早く 気づける
どんな変化を検知 したいか定義 グラフでデータの変化を 確認
データの保存
Icebergとは データウェアハウスのように使える データレイクのテーブルフォーマット 従来のテーブルフォーマット Iceberg データファイルを編集できない UPDATE/DELETE/MERGEによる データの編集・削除が可能 トランザクションがサポート されておらずデータの⼀貫性を保てない
ACIDトランザクションによる 同時アクセス時の整合性を担保 過去のデータの状態を復元できない テーブルのタイムトラベル機能 ファイルの物理的な構造を元にパーティ ション構造を参照 メタデータを元にパーティション構造 を把握する、より精度の⾼い パーティショニング
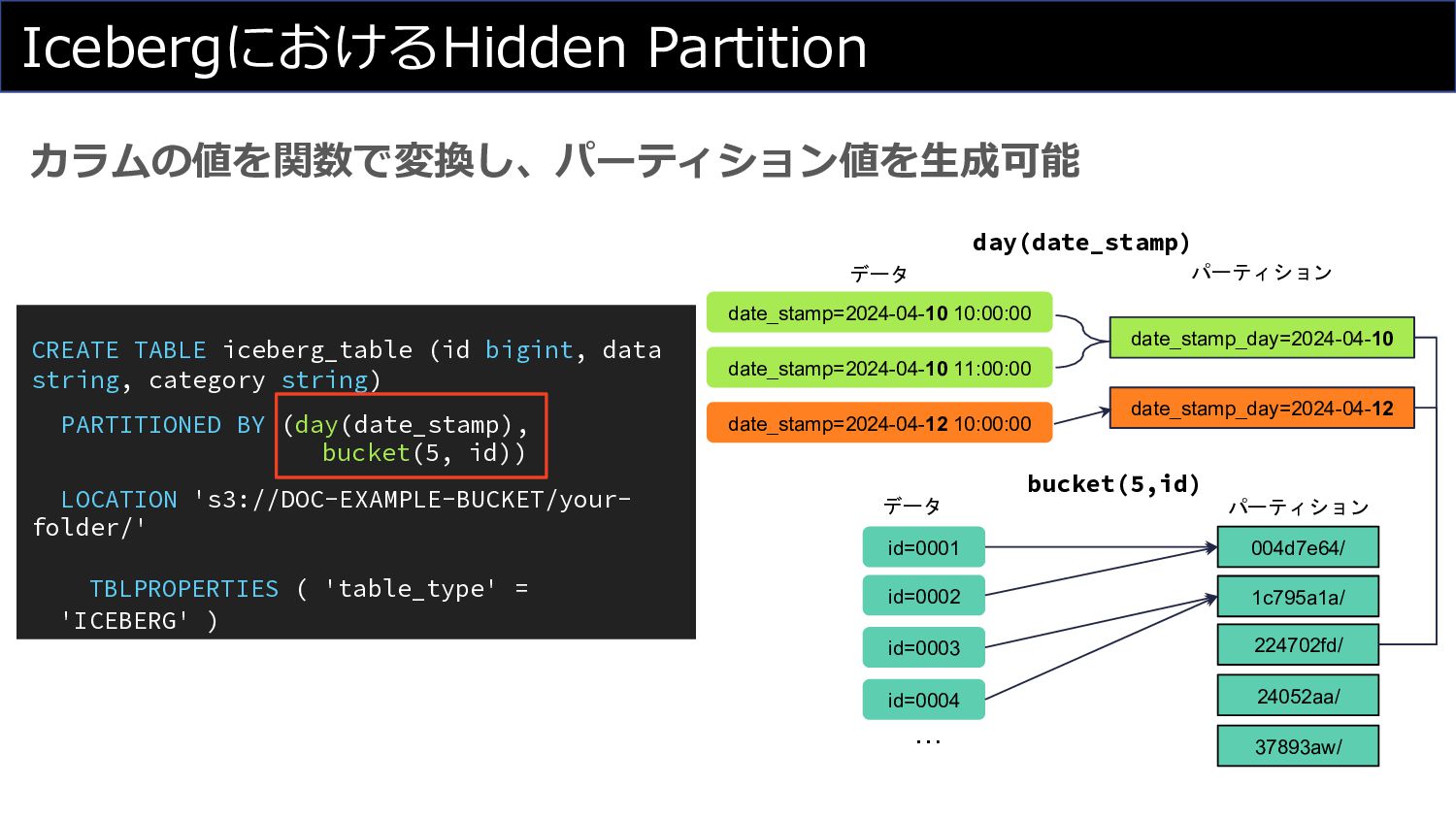
IcebergにおけるHidden Partition カラムの値を関数で変換し、パーティション値を⽣成可能 CREATE TABLE iceberg_table (id bigint, data string,
category string) PARTITIONED BY (day(date_stamp), bucket(5, id)) LOCATION 's3://DOC-EXAMPLE-BUCKET/your- folder/' TBLPROPERTIES ( 'table_type' = 'ICEBERG' ) date_stamp=2024-04-10 10:00:00 date_stamp=2024-04-10 11:00:00 date_stamp=2024-04-12 10:00:00 date_stamp_day=2024-04-10 date_stamp_day=2024-04-12 データ パーティション 004d7e64/ id=0001 id=0002 パーティション 1c795a1a/ 224702fd/ 24052aa/ 37893aw/ id=0003 id=0004 … day(date_stamp) bucket(5,id) データ
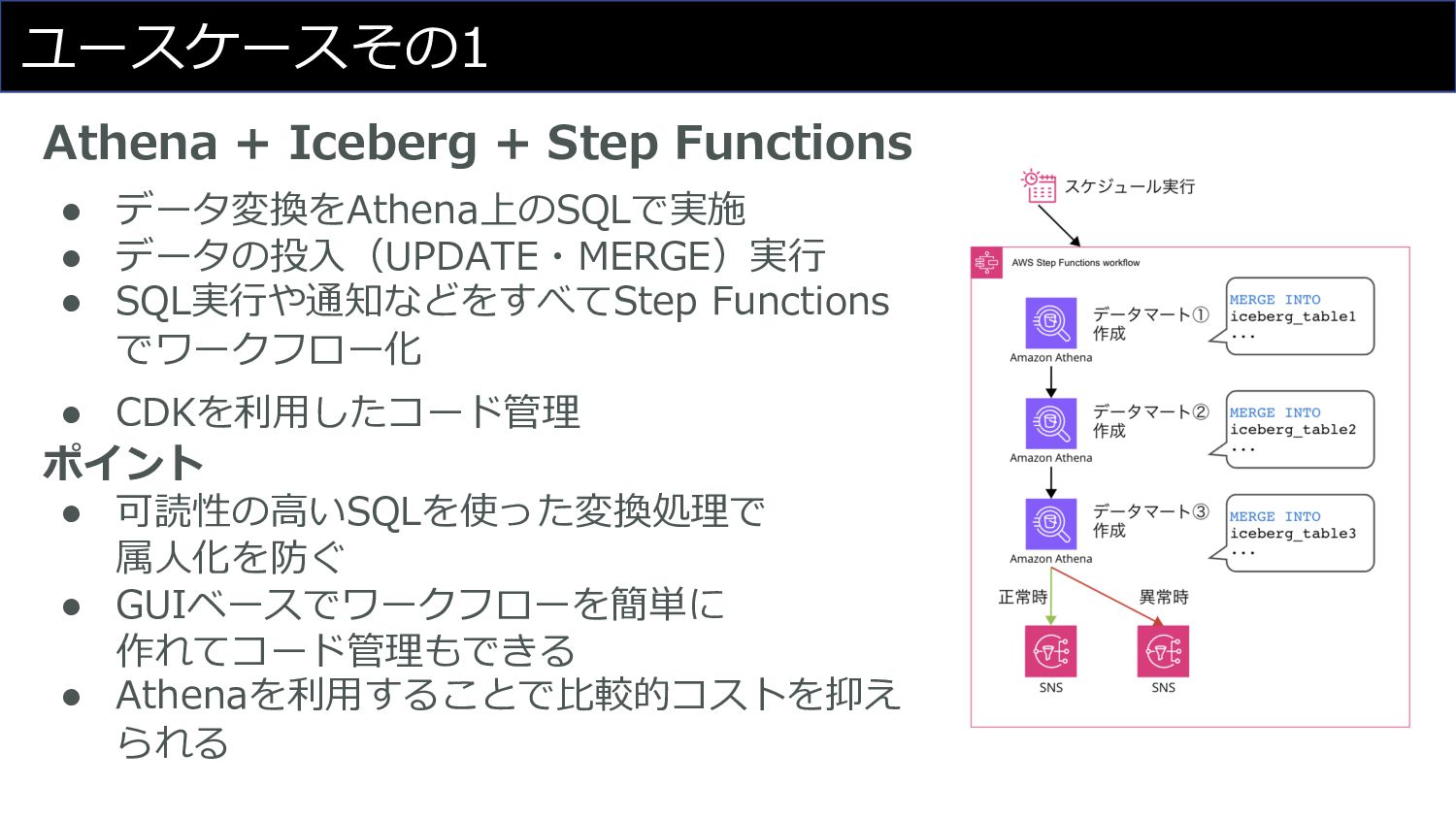
ユースケースその1 Athena + Iceberg + Step Functions • データ変換をAthena上のSQLで実施 •
データの投⼊(UPDATE・MERGE)実⾏ • SQL実⾏や通知などをすべてStep Functions でワークフロー化 • CDKを利⽤したコード管理 ポイント • 可読性の⾼いSQLを使った変換処理で 属⼈化を防ぐ • GUIベースでワークフローを簡単に 作れてコード管理もできる • Athenaを利⽤することで⽐較的コストを抑え られる
オーケストレーション
dbt(data build tool)とは ELT(データ抽出→ロード→変換)のT(変換)を担う SQLを使えればデータマート開発ができるサービス • データモデルをSQLで作成 • モデルのテストを⾃動化 •
モデルの依存関係やDAGに基づいてテーブル情報や データリネージのドキュメントを⽣成 • バージョン管理、CI/CD、テスト⾃動化など、アプリ開発の ⼿法でデータマートの開発が可能 • 様々なデータソースに対応
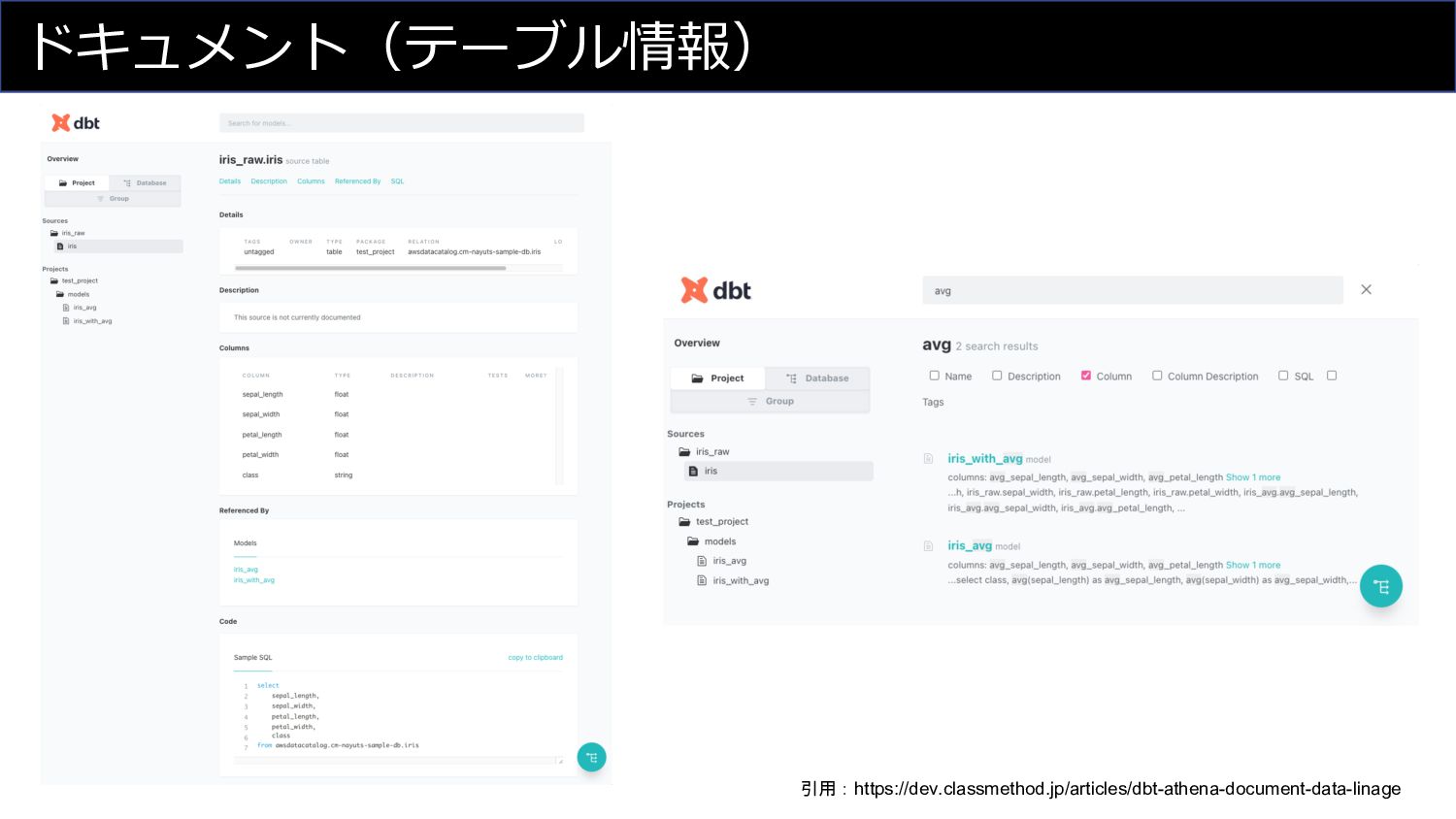
ドキュメント(テーブル情報) 引用:https://dev.classmethod.jp/articles/dbt-athena-document-data-linage
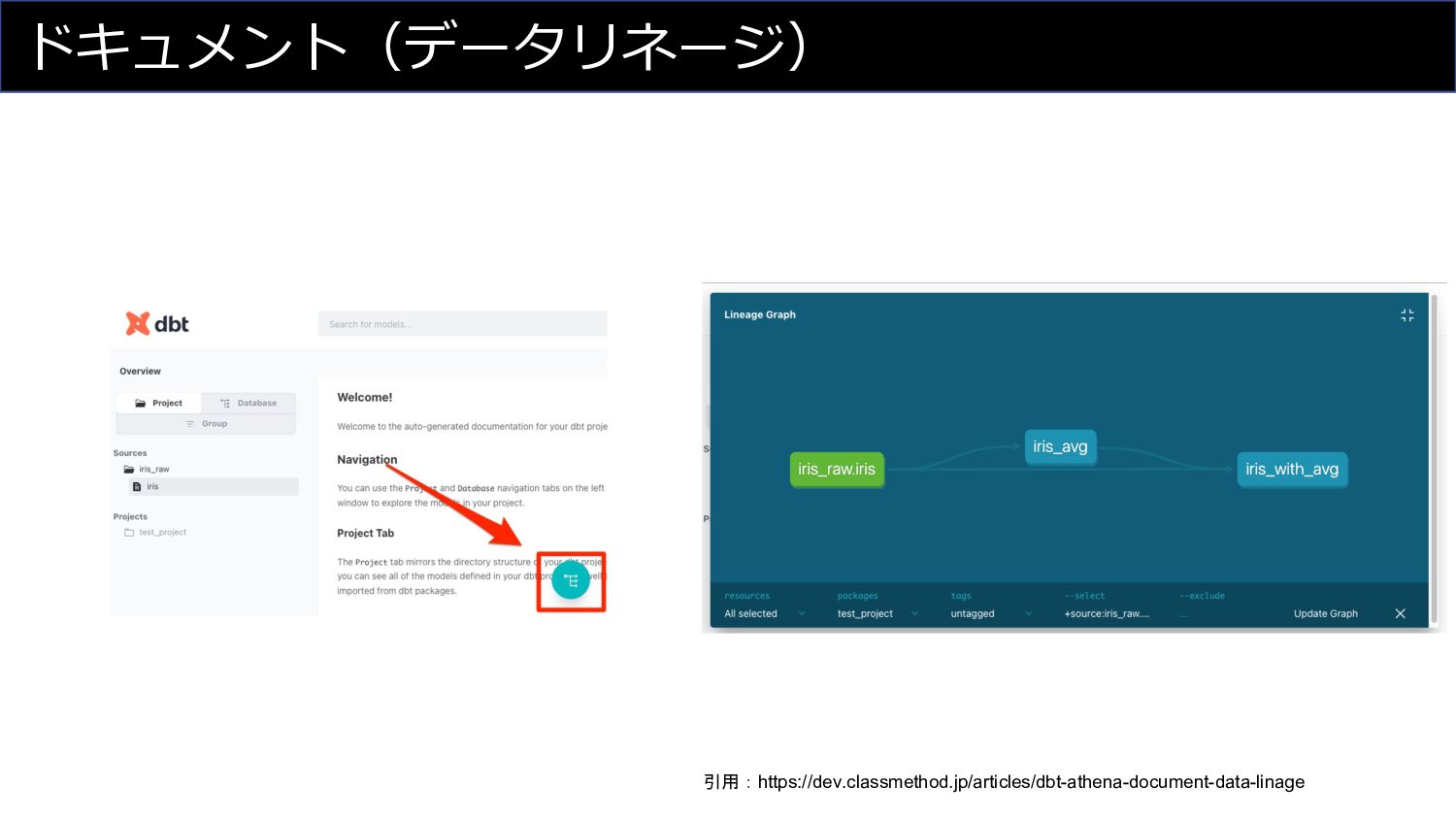
ドキュメント(データリネージ) 引用:https://dev.classmethod.jp/articles/dbt-athena-document-data-linage
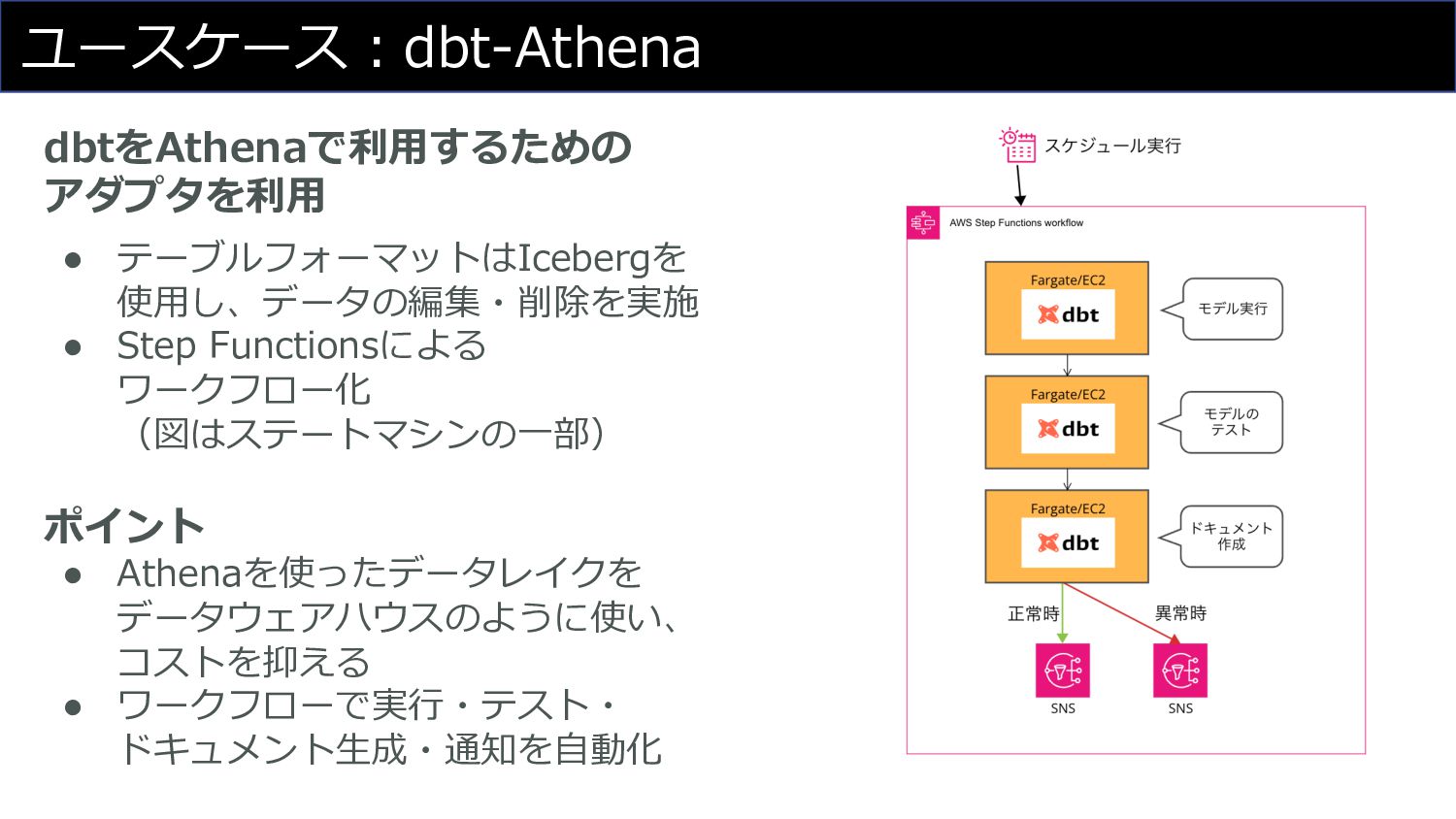
ユースケース︓dbt-Athena dbtをAthenaで利⽤するための アダプタを利⽤ • テーブルフォーマットはIcebergを 使⽤し、データの編集・削除を実施 • Step Functionsによる ワークフロー化
(図はステートマシンの⼀部) ポイント • Athenaを使ったデータレイクを データウェアハウスのように使い、 コストを抑える • ワークフローで実⾏・テスト・ ドキュメント⽣成・通知を⾃動化
データ共有
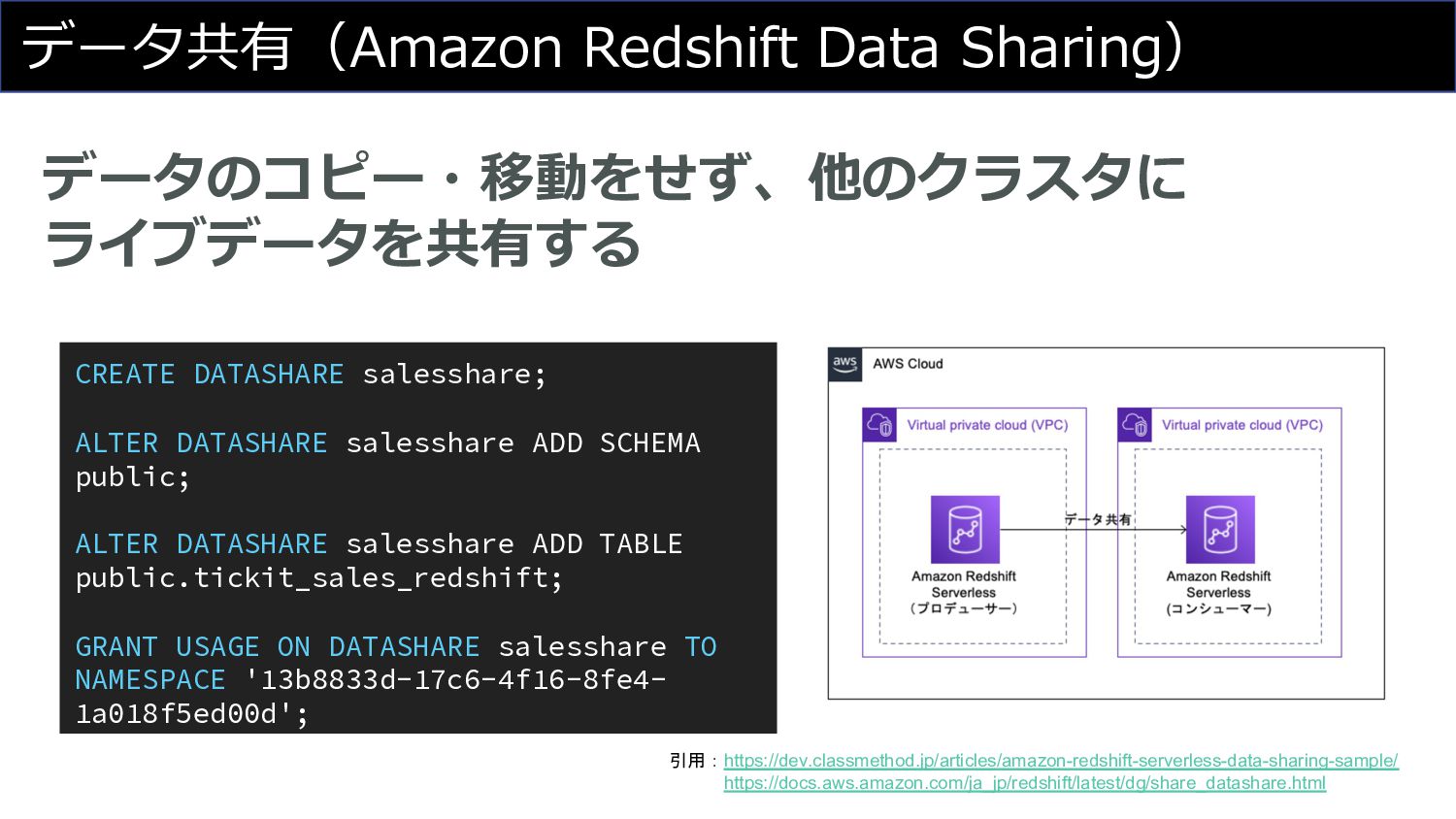
データ共有(Amazon Redshift Data Sharing) データのコピー・移動をせず、他のクラスタに ライブデータを共有する CREATE DATASHARE salesshare; ALTER
DATASHARE salesshare ADD SCHEMA public; ALTER DATASHARE salesshare ADD TABLE public.tickit_sales_redshift; GRANT USAGE ON DATASHARE salesshare TO NAMESPACE '13b8833d-17c6-4f16-8fe4- 1a018f5ed00d'; 引用:https://dev.classmethod.jp/articles/amazon-redshift-serverless-data-sharing-sample/ https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/share_datashare.html
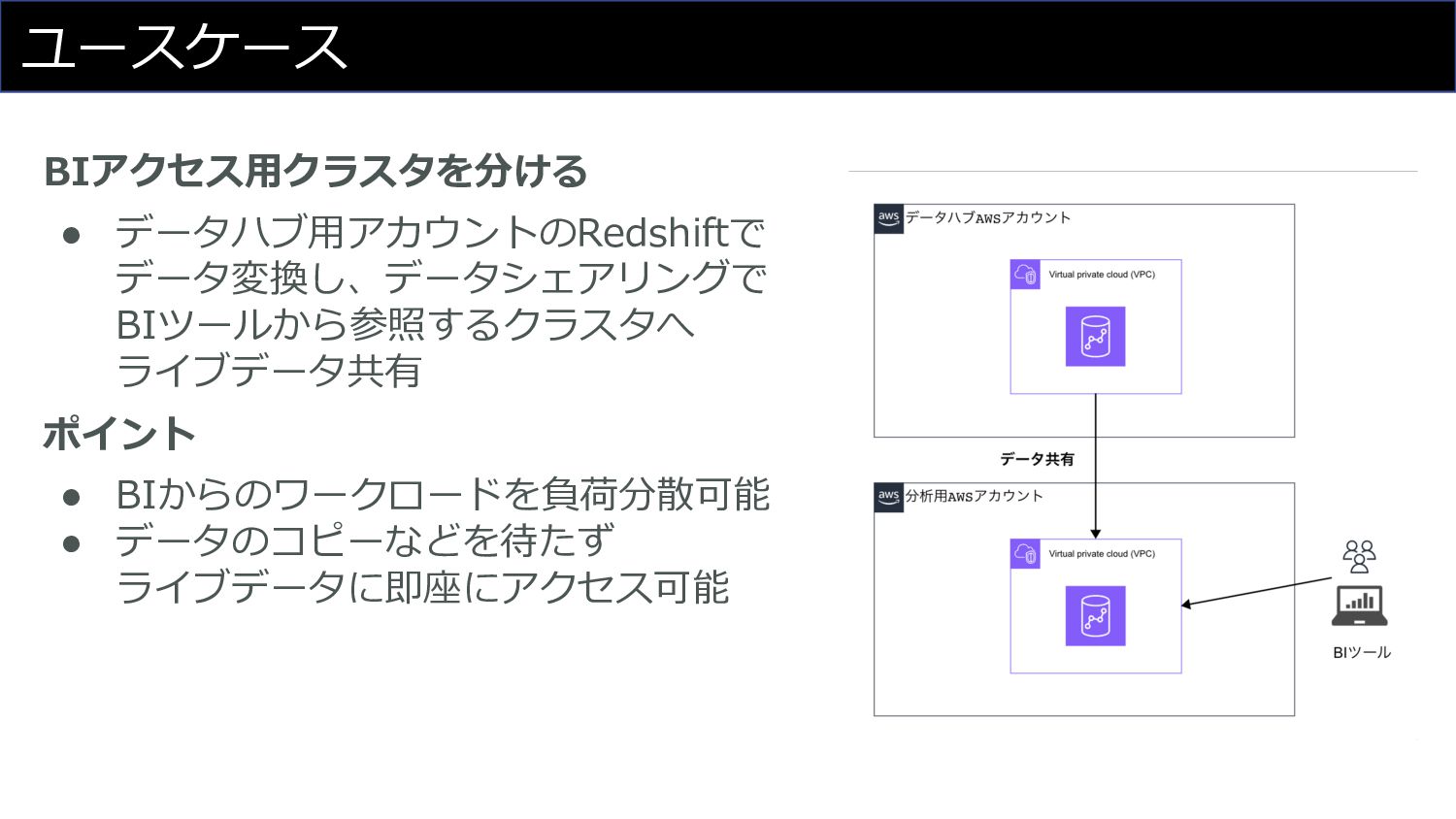
ユースケース BIアクセス⽤クラスタを分ける • データハブ⽤アカウントのRedshiftで データ変換し、データシェアリングで BIツールから参照するクラスタへ ライブデータ共有 ポイント • BIからのワークロードを負荷分散可能
• データのコピーなどを待たず ライブデータに即座にアクセス可能
再掲︓データ分析をもっと簡単にするために • データ品質(Glue Data Quality) • データの保存(Apache Iceberg) • オーケストレーション(dbt)
• データ共有(Redshift Data Sharing)
⾃⼰紹介 ⽒名 鈴⽊ 那由太(スズキ ナユタ) 所属 データアナリティクス事業本部 インテグレーション部 機械学習チーム システムエンジニア
受賞 Japan AWS Top Engineers (Analytics) (2022-2023) Japan AWS All Certifications Engineers (2022-2023)
機械学習案件の対応実績 (概要) • 機械学習のコア部分 • 機械学習モデル開発、評価 • AI・機械学習関連のクラウドサービス(SaaS)の適⽤ • MLOpsを考慮した機械学習基盤の構築⽀援
• クラウドサービスを活⽤した機械学習基盤の構築 • データ前処理、後処理 • 機械学習パイプライン • CI/CD • AI・機械学習関連のクラウドサービスのレクチャー • Amazon SageMaker(AI・機械学習の開発環境)と周辺サービスの活⽤ • そのほか対応可能なAI・機械学習関連のクラウドサービス 本⽇はレコメンドの機械 学習課題の例と、機械学 習に⼗分な品質のデータ を⽤意するための観点・ ツールをご紹介します。
33 マネージドサービスを使って⼿軽にデータ活⽤を始める 機械学習 • データのパターンを⾒出し、対応の⾃動化を⾏う。 • 過去の実績から、未来の予測やデータの理解を⽀援する。 パブリッククラウドのマネージドサービスを利⽤することで低いコストで実現できる。 例︓Amazon Personalize
タスクごとのサービス例 タスクごとに必要なデータを⽤意し、対応するサービスを利⽤できる。 • テーブルデータ(トランザクションデータなど) • KPIのモニタリング、分類、予測、異常検知、レコメンデーション • テキスト(⾃然⾔語) • アンケート分析、ドキュメント分類、キーワード抽出、回答⽣成など
• 画像・動画 • 画像分類、物体検出 など Amazon QuickSight Amazon Forecast Amazon Comprehend Amazon Personalize Amazon Rekognition Amazon Bedrock <マネージドサービスの例>
適⽤領域毎の課題への適⽤ 適⽤領域ごとの課題に合わせて機能を適⽤する。 • 流通・⼩売 • 需要・売上・在庫の予測・分析、⾃動発注、レコメンデーション など • 製造 •
異常検知、故障予測、予知保全 など • ⾦融 • 契約数の推移の分析、不正検出、与信判定 など • エンターテイメント・ゲーム • 実施施策の決定、⾒込み顧客判定、離反予測、不正検出、レコメンデーション など Amazon Rekognitionでは画像に写っている現場の状態が 安全か危険かを判別する機能もある。 • https://aws.amazon.com/jp/rekognition/workplace- safety/
機械学習の例(レコメンド)
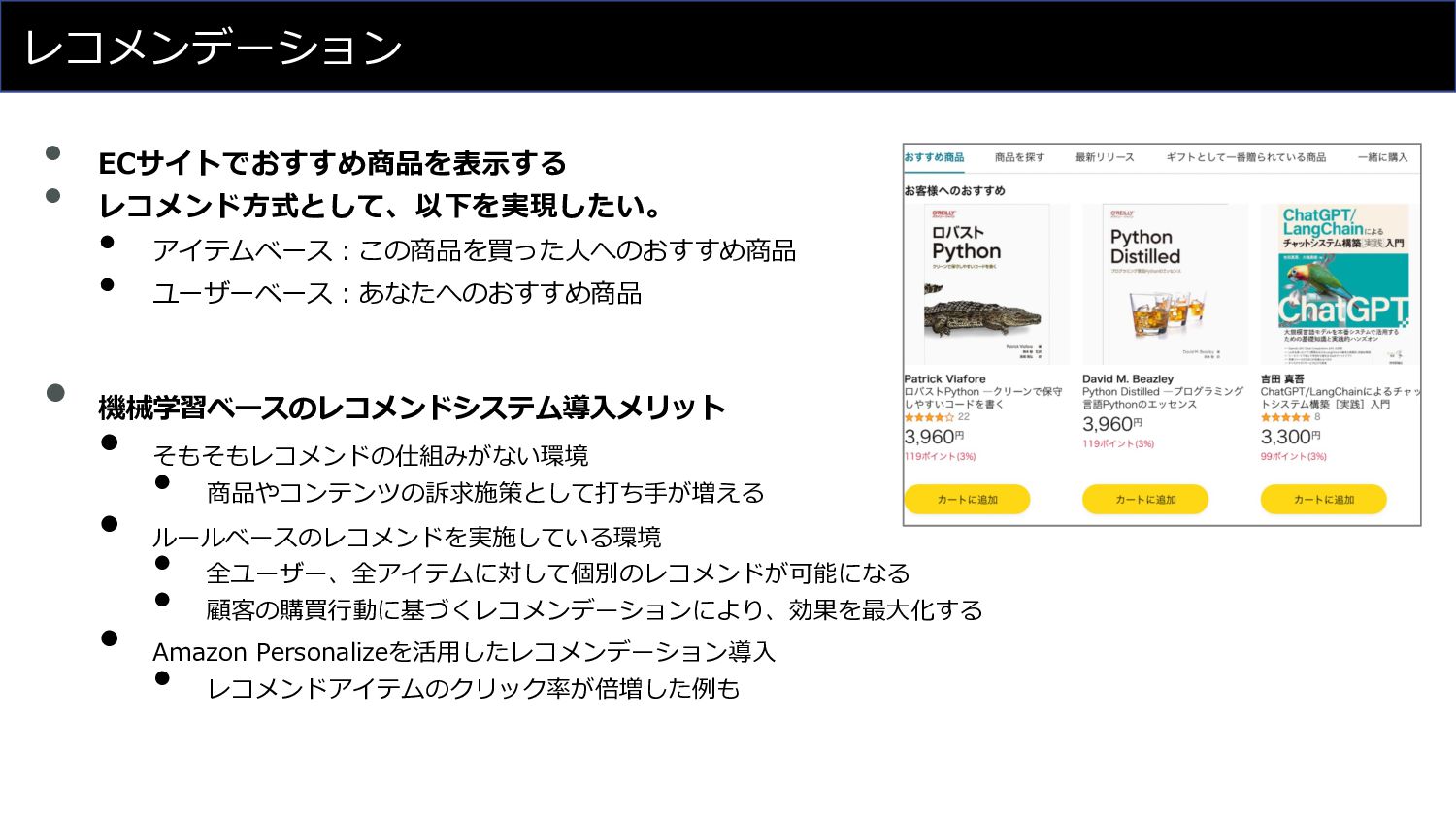
レコメンデーション • ECサイトでおすすめ商品を表⽰する • レコメンド⽅式として、以下を実現したい。 • アイテムベース︓この商品を買った⼈へのおすすめ商品 • ユーザーベース︓あなたへのおすすめ商品 •
機械学習ベースのレコメンドシステム導⼊メリット • そもそもレコメンドの仕組みがない環境 • 商品やコンテンツの訴求施策として打ち⼿が増える • ルールベースのレコメンドを実施している環境 • 全ユーザー、全アイテムに対して個別のレコメンドが可能になる • 顧客の購買⾏動に基づくレコメンデーションにより、効果を最⼤化する • Amazon Personalizeを活⽤したレコメンデーション導⼊ • レコメンドアイテムのクリック率が倍増した例も
レコメンデーション Amazon Personalizeで具体的に出来ること •ユーザーのパーソナライズ •ユーザーの⾏動に基づき、ユーザーに合わせた製品やコンテンツをレコメンドする (ユーザーベース) •類似アイテムのレコメンデーション •ユーザーの⾏動に基づいて、あるアイテムに対する類似のアイテムをレコメンドする (アイテムベース) •パーソナライズされたランキング
•ユーザー毎にアイテムのランキングを⽣成する Amazon Personalizeを活⽤ • Amazonがレコメンデーションを20年以上 提供してきた経験と機械学習を活⽤して⾏った 調査をベースにしたレコメンデーションサービス
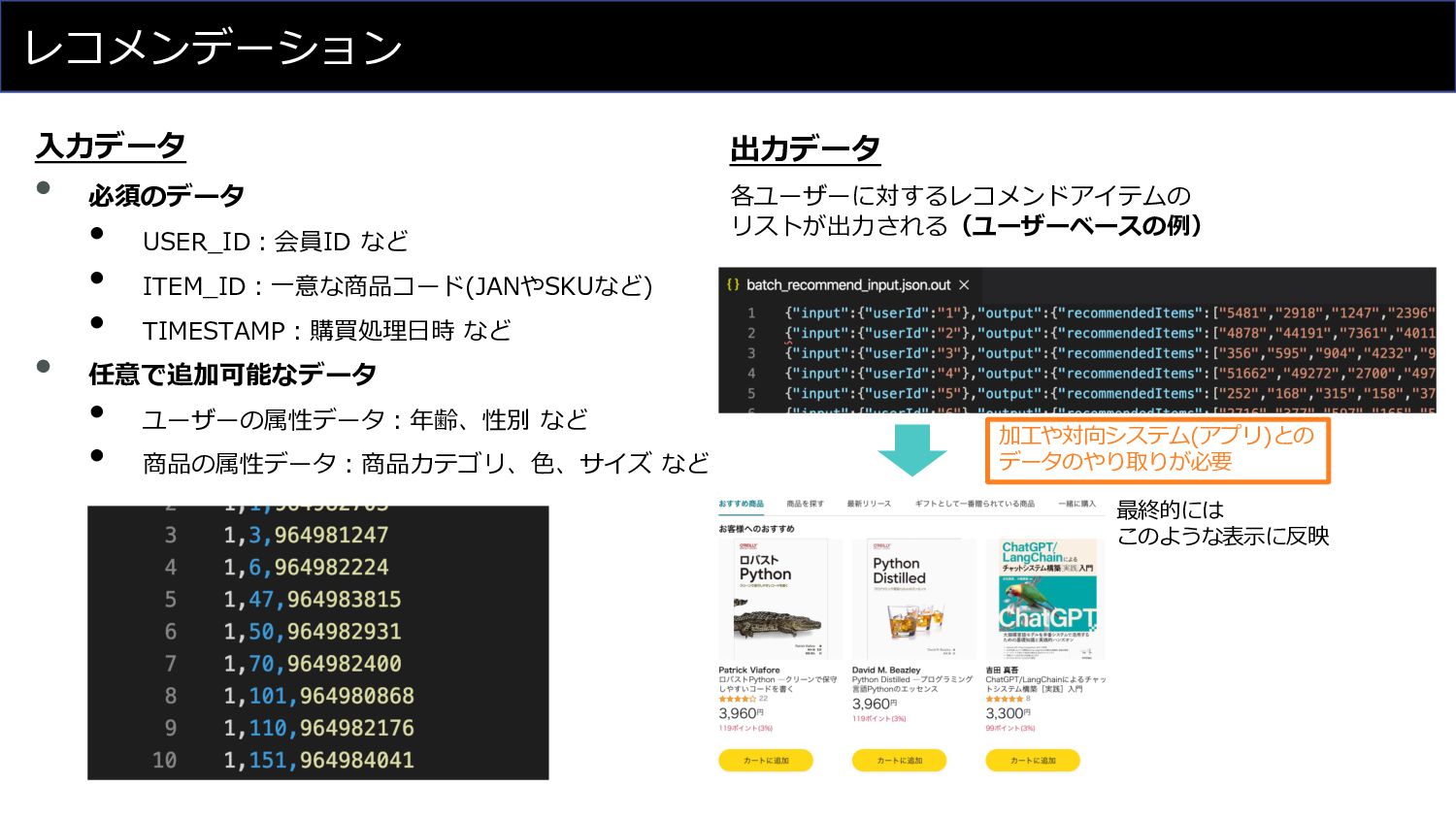
レコメンデーション • 必須のデータ • USER_ID︓会員ID など • ITEM_ID︓⼀意な商品コード(JANやSKUなど) • TIMESTAMP︓購買処理⽇時
など • 任意で追加可能なデータ • ユーザーの属性データ︓年齢、性別 など • 商品の属性データ︓商品カテゴリ、⾊、サイズ など ⼊⼒データ 出⼒データ 各ユーザーに対するレコメンドアイテムの リストが出⼒される(ユーザーベースの例) 加⼯や対向システム(アプリ)との データのやり取りが必要 最終的には このような表⽰に反映
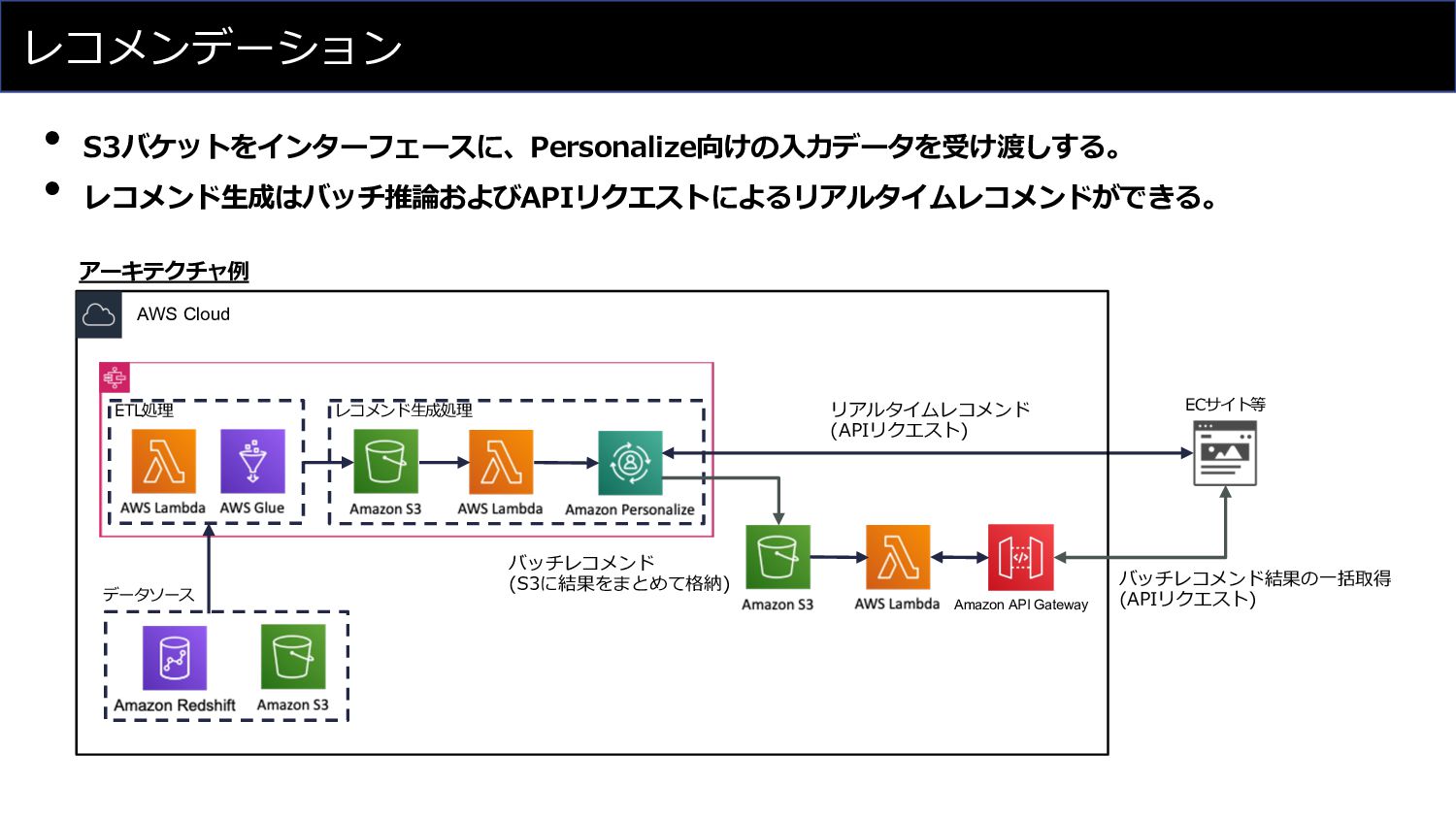
レコメンデーション ETL処理 レコメンド⽣成処理 データソース アーキテクチャ例 AWS Cloud ECサイト等 リアルタイムレコメンド (APIリクエスト)
バッチレコメンド (S3に結果をまとめて格納) Amazon API Gateway バッチレコメンド結果の⼀括取得 (APIリクエスト) • S3バケットをインターフェースに、Personalize向けの⼊⼒データを受け渡しする。 • レコメンド⽣成はバッチ推論およびAPIリクエストによるリアルタイムレコメンドができる。
41 まとめ データ分析に求められる要素と、より簡単に実現するための技術をご紹介した。 • データ品質 • データ共有 • dbt •
Icebergフォーマット データの活⽤に便利なマネージドサービスをご紹介した。 • 機械学習︓Amazon Personalize 発表の内容や対応実績についてご興味があれば、 相談ブースにてお待ちしております︕
42
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}