data science, and machine learning on single-node machines or clusters. Key Features - Batch/streaming data - SQL analytics - Data science at scale - Machine learning Apache Spark https://spark.apache.org/
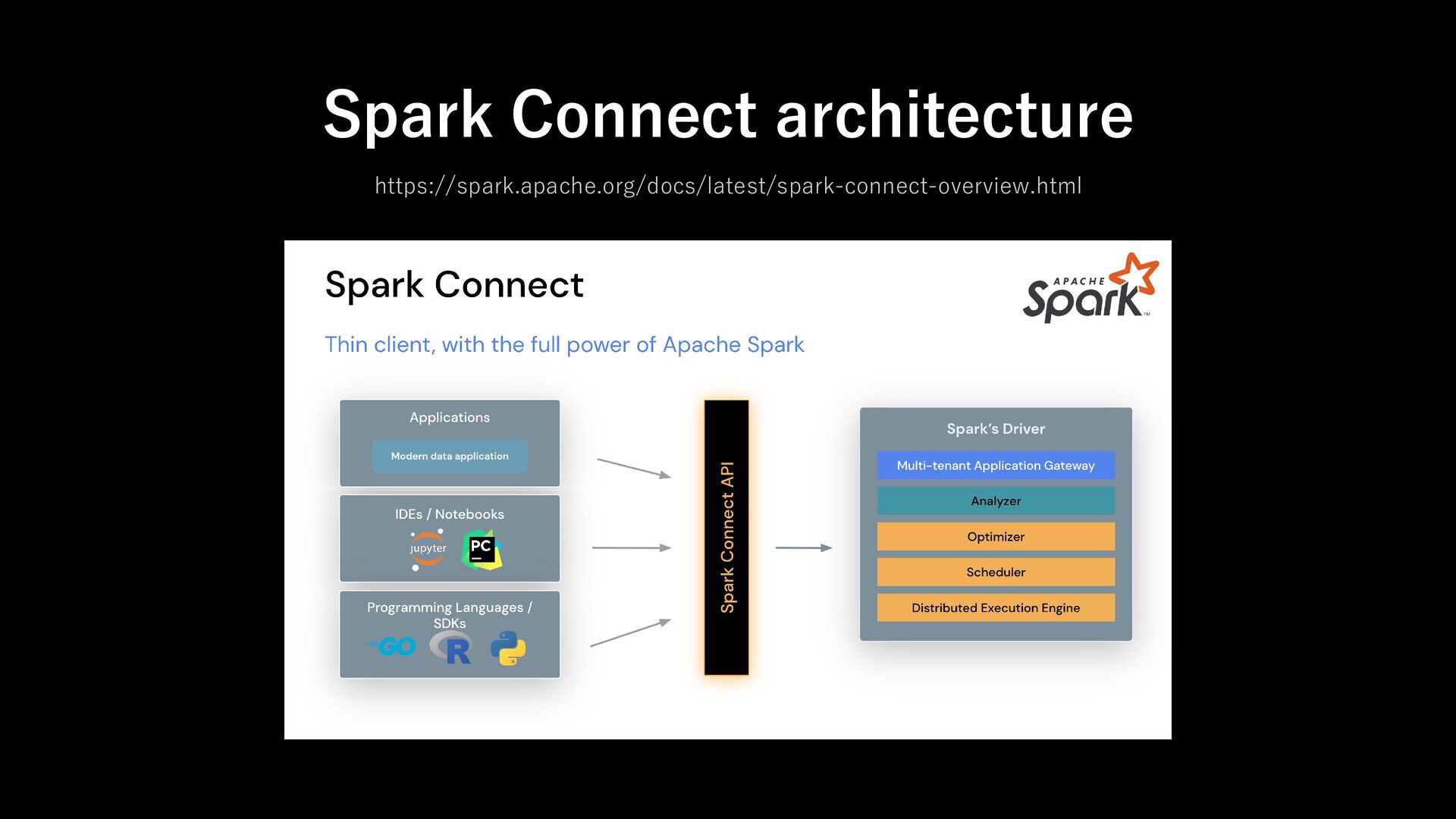
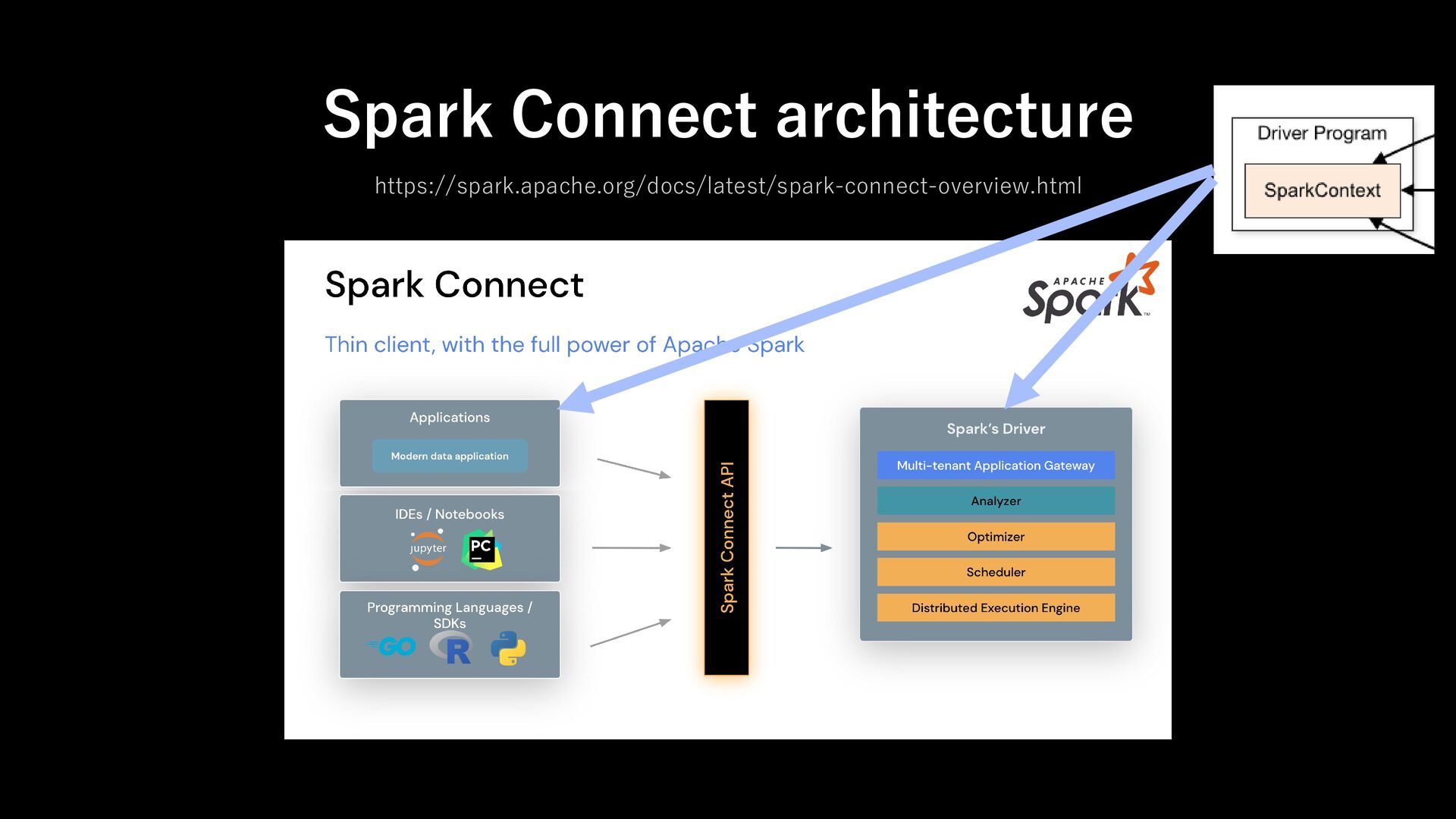
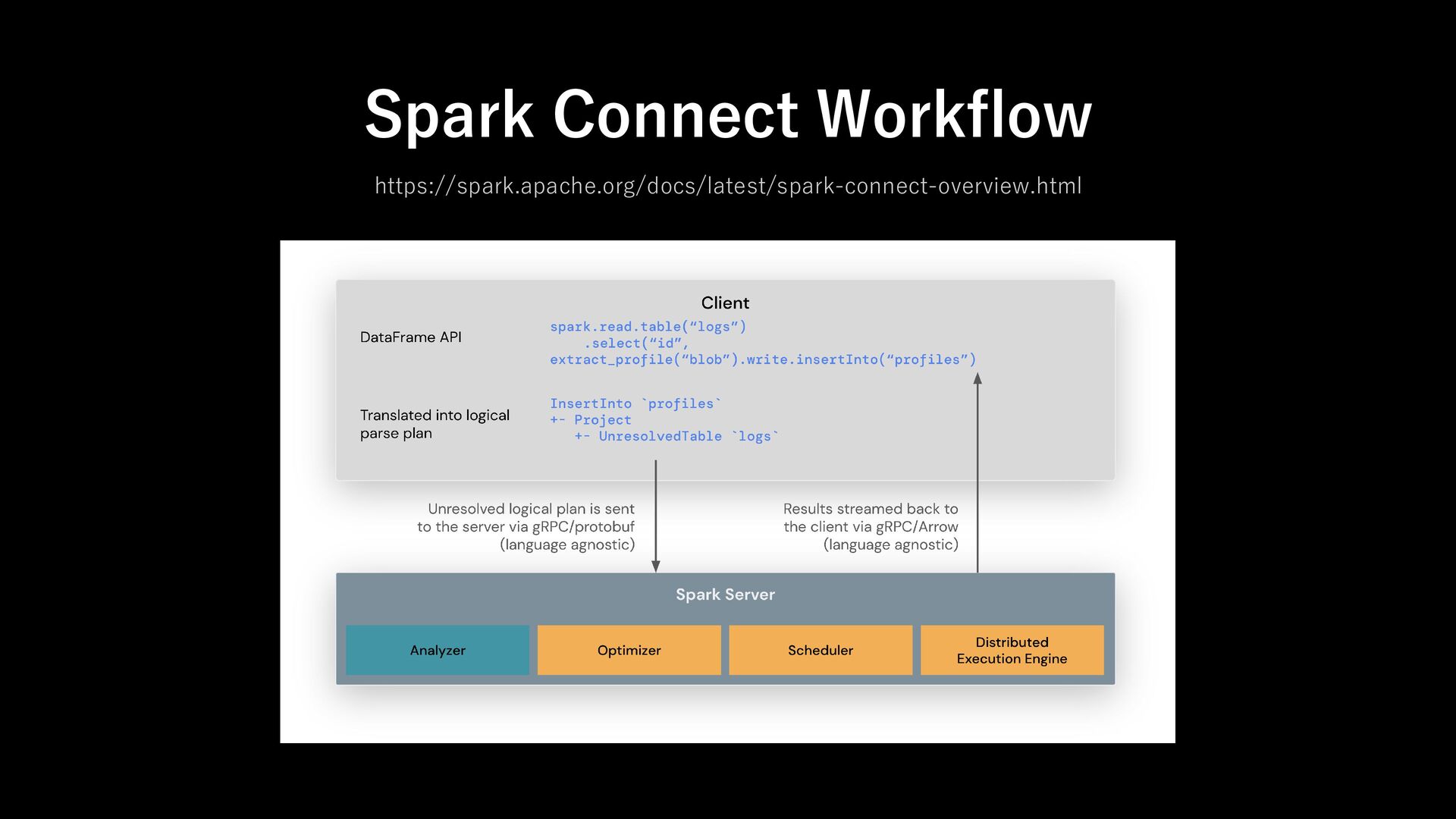
unresolved logical plans - via gRPC with Apache Arrow encoded row batches Can be embedded everywhere - application servers, IDEs, notebooks and programming languages About Spark Connect Decouple layer between Client and Driver
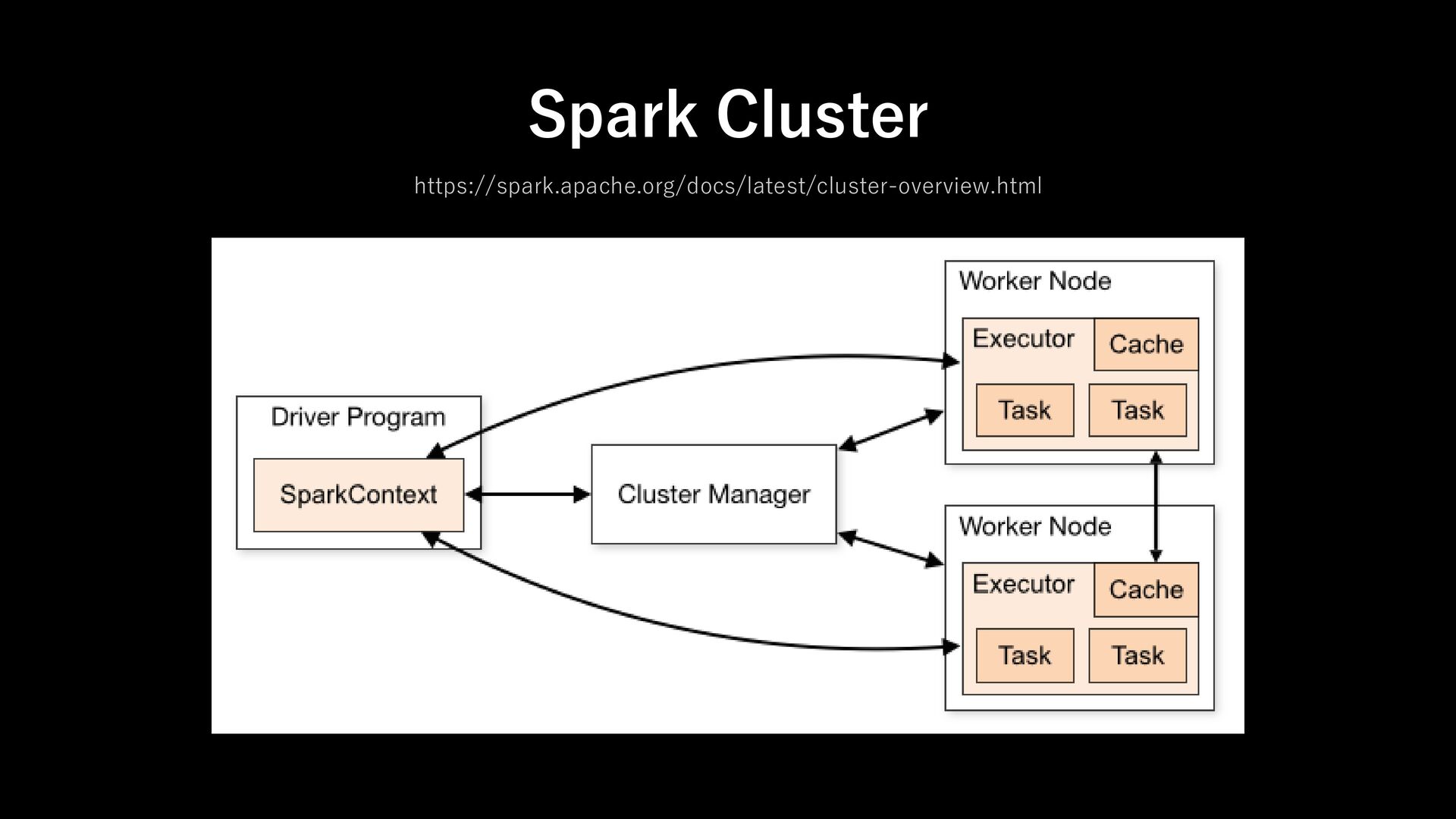
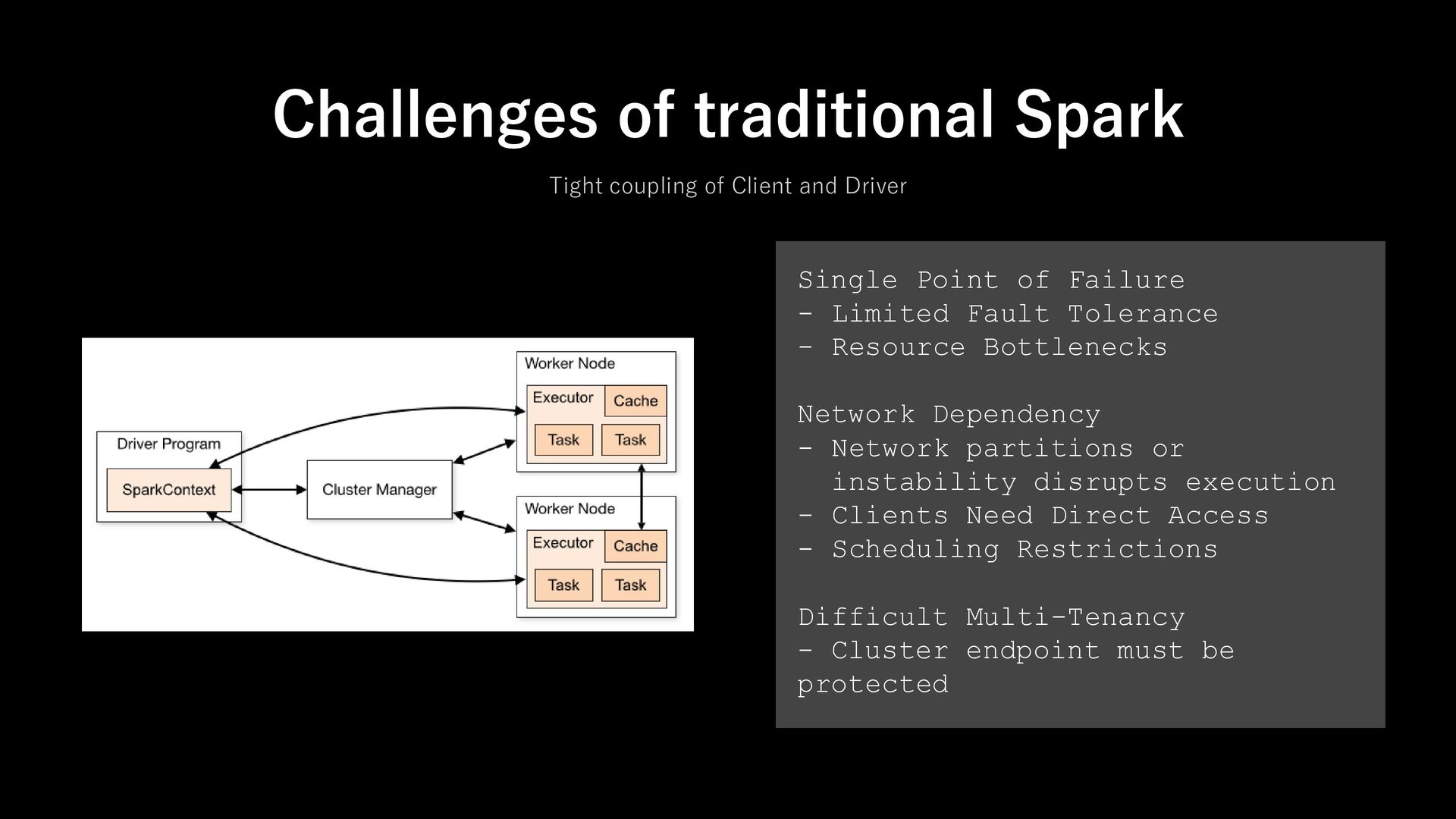
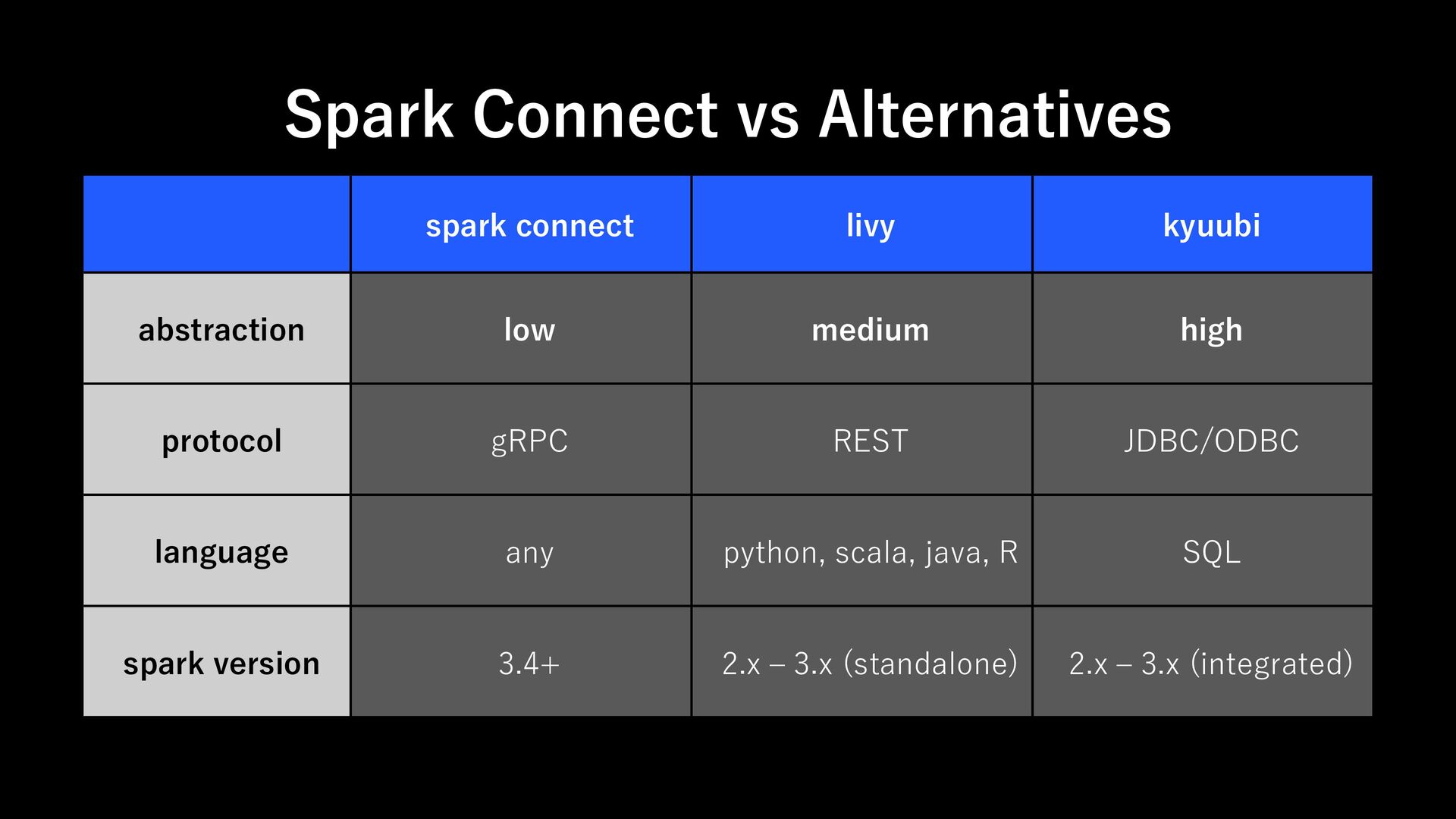
cluster out cluster client requirement full spark, cluster access and JVM-based thin client: minimal gRPC client with DataFrame Library network topology must have direct network access to the cluster remote access via gRPC scalability driver + client handles all scheduling and coordination driver runs on cluster; clients are stateless fault tolerance client crash causes job lost client can disconnect and reconnect
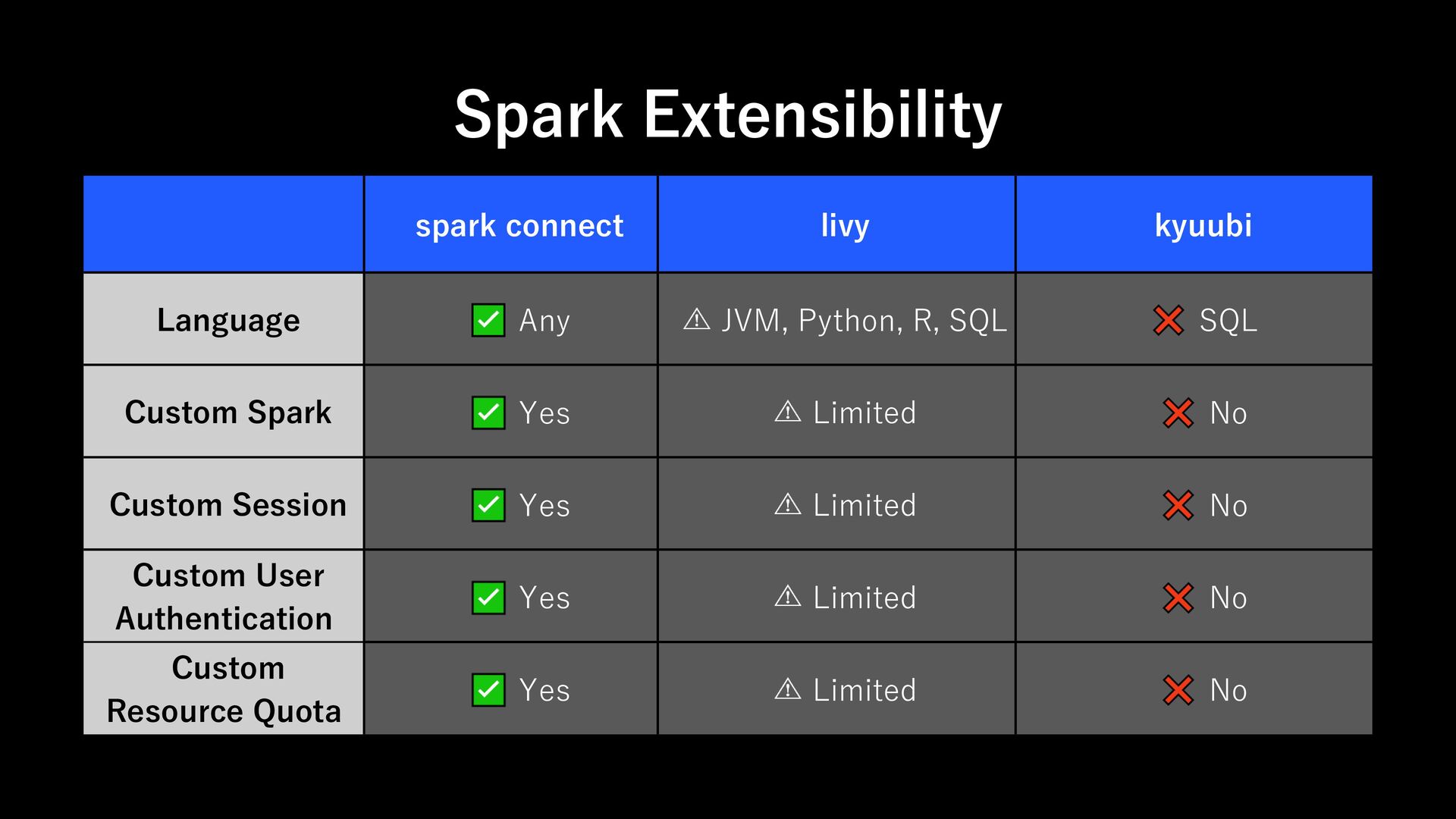
to spark supported languages: JVM, PySpark, R any ex) javascript, go, c#, rust cloud native tight coupling and driver requirements limit flexibility designed for cloud-native, containerized and serverless security exposing cluster endpoints can raise security concerns can secure gRPC channel with centralized control versioning client and server must be tightly version-matched client and server can evolve independently
and KeyValueGroupedDataset User Defined Functions Streaming APIs: DataStreamReader, DataStreamWriter, StreamingQuery and StreamingQueryListener Supported APIs https://spark.apache.org/docs/latest/spark-connect-overview.html#what-is-supported
Rust, Go, Javascript, etc - Interactivity - Notebooks: Jupyter, VSCode - Integrated Development Environment - Minimality - Web UI or BI Tools - Mobile or Microservices - MCP servers Use Cases
Rust, Go, Javascript, etc - Interactivity - Notebooks: Jupyter, VSCode - Integrated Development Environment - Minimality - Web UI or BI Tools - Mobile or Microservices - MCP servers Use Cases
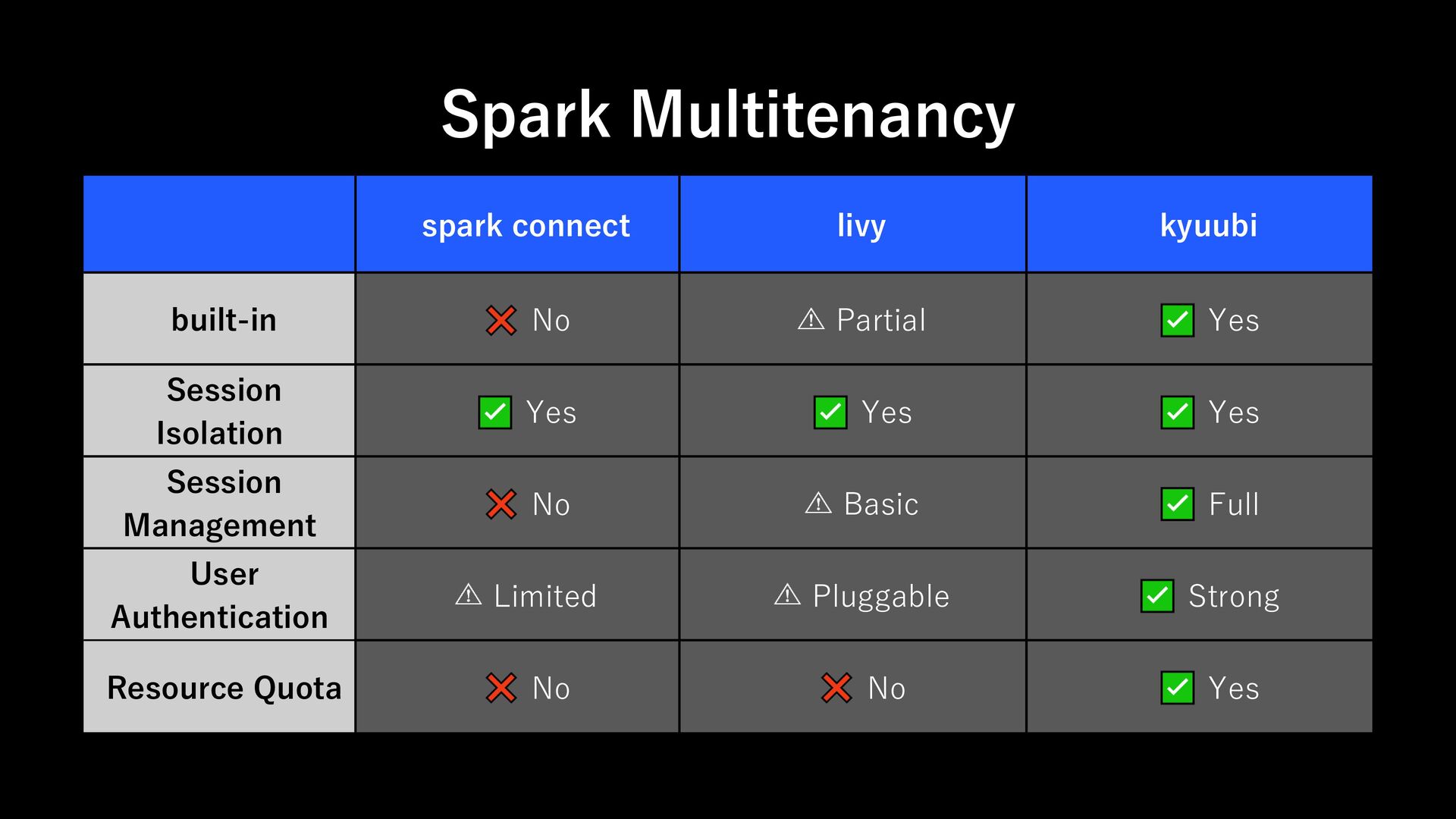
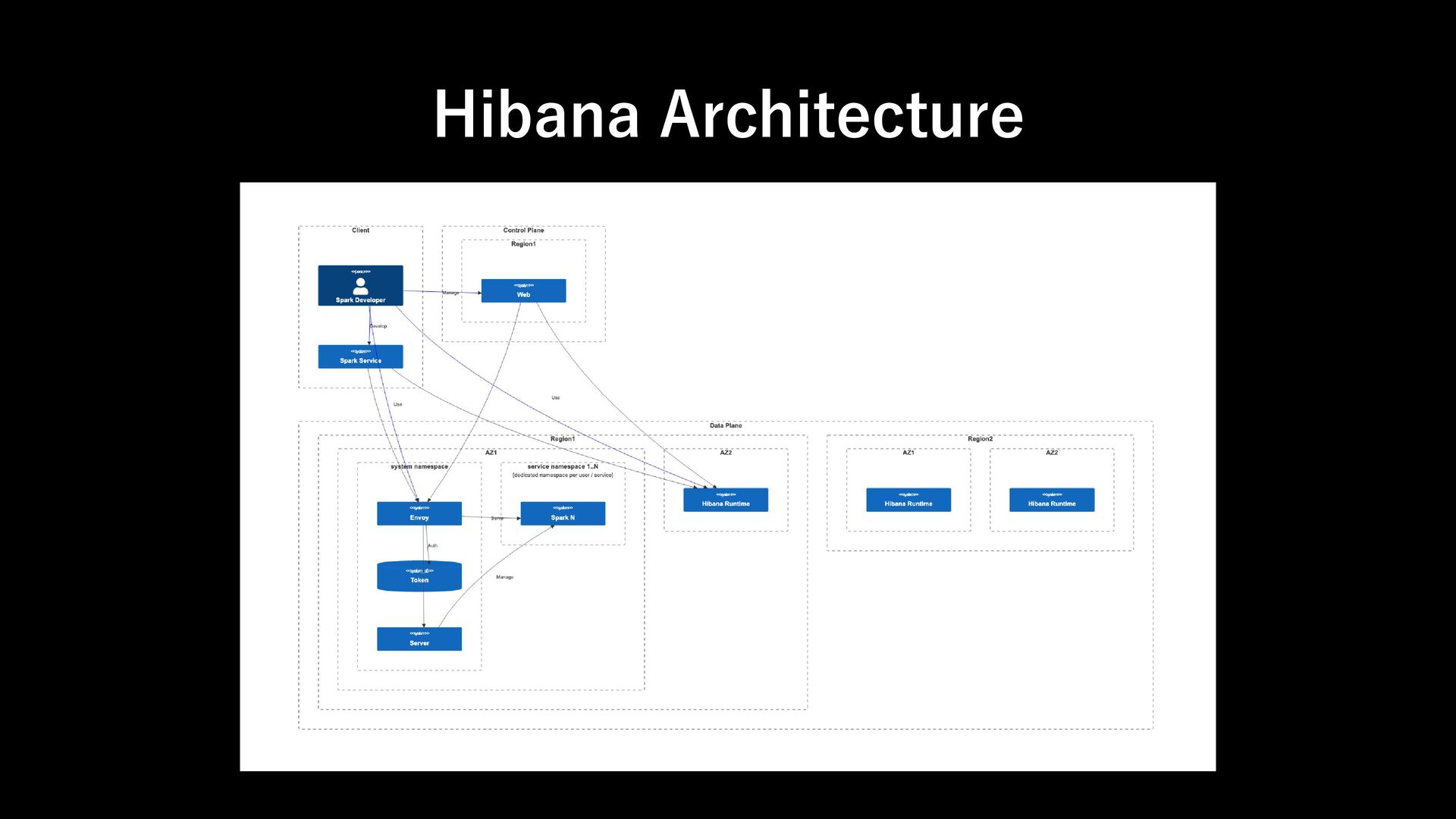
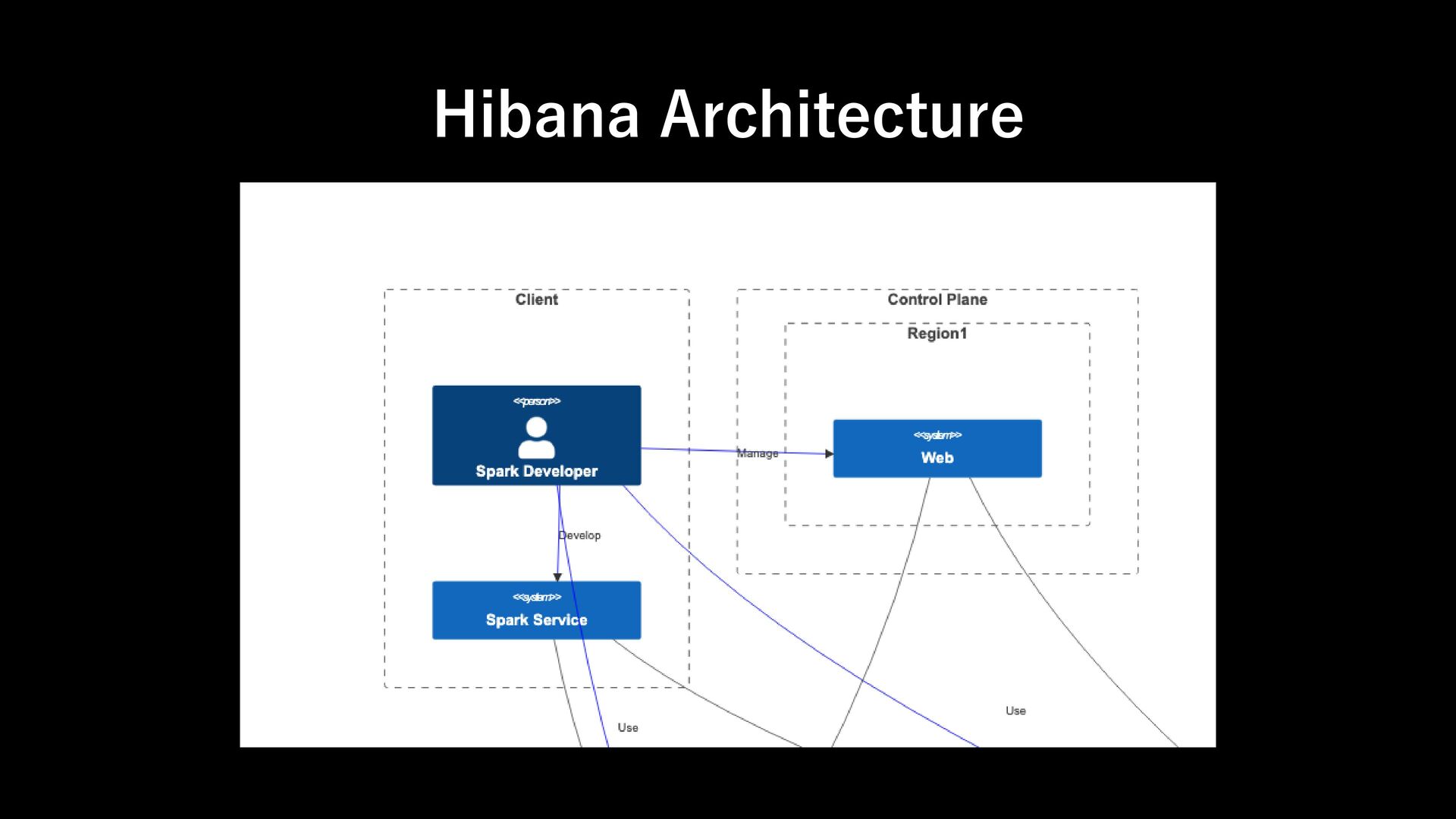
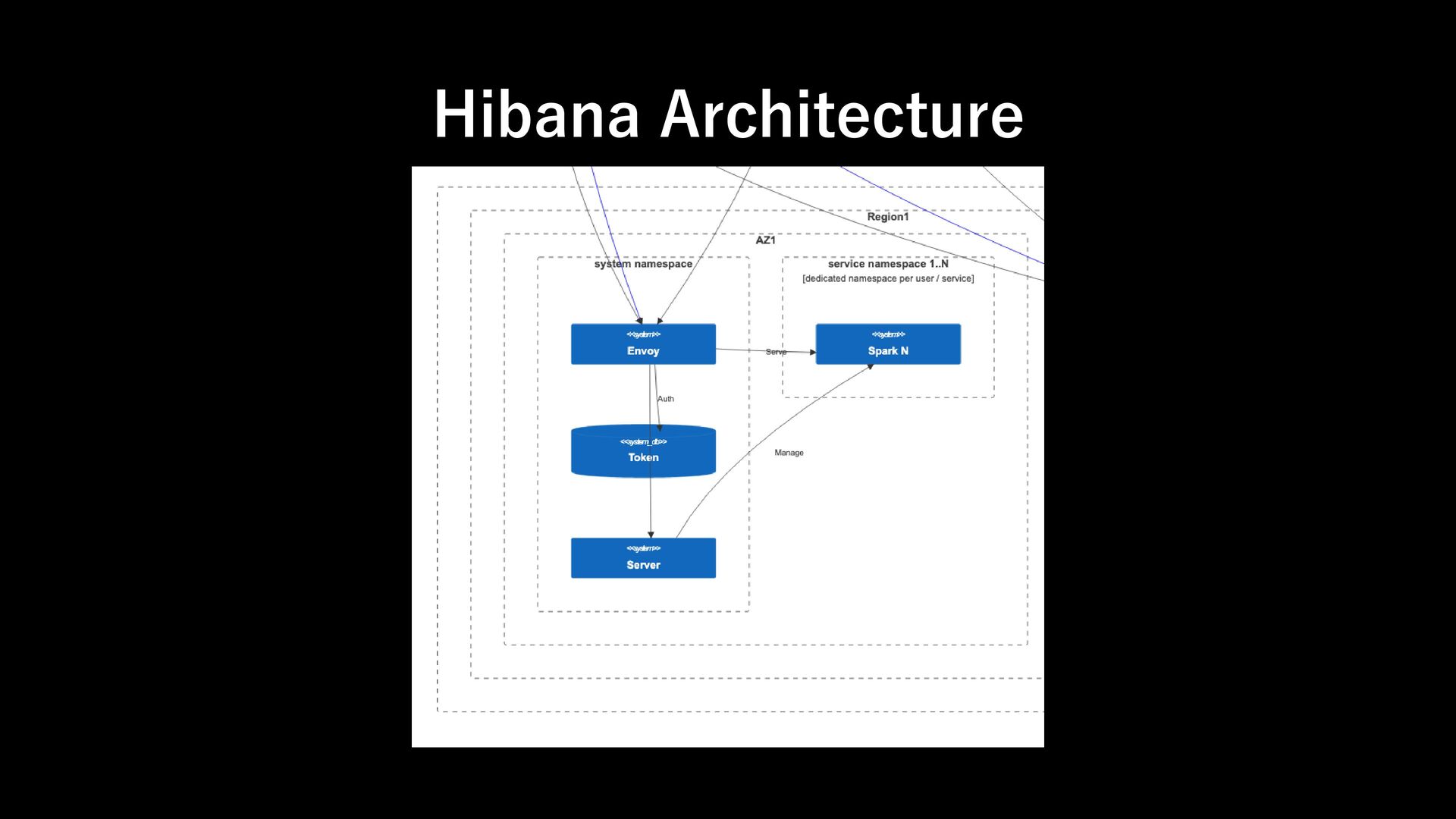
Support Spark Credentials: kerberos keytab - Support resource quotas - Support role management - Support audit logging - Horizontally Scalable Requirement 1: Runtime
designed to work seamlessly with your existing authentication infrastructure. Its gRPC HTTP/2 interface allows for the use of authenticating proxies, which makes it possible to secure Spark Connect without having to implement authentication logic in Spark directly. Requirement 2: Auth https://spark.apache.org/docs/latest/spark-connect-overview.html#what-is-supported
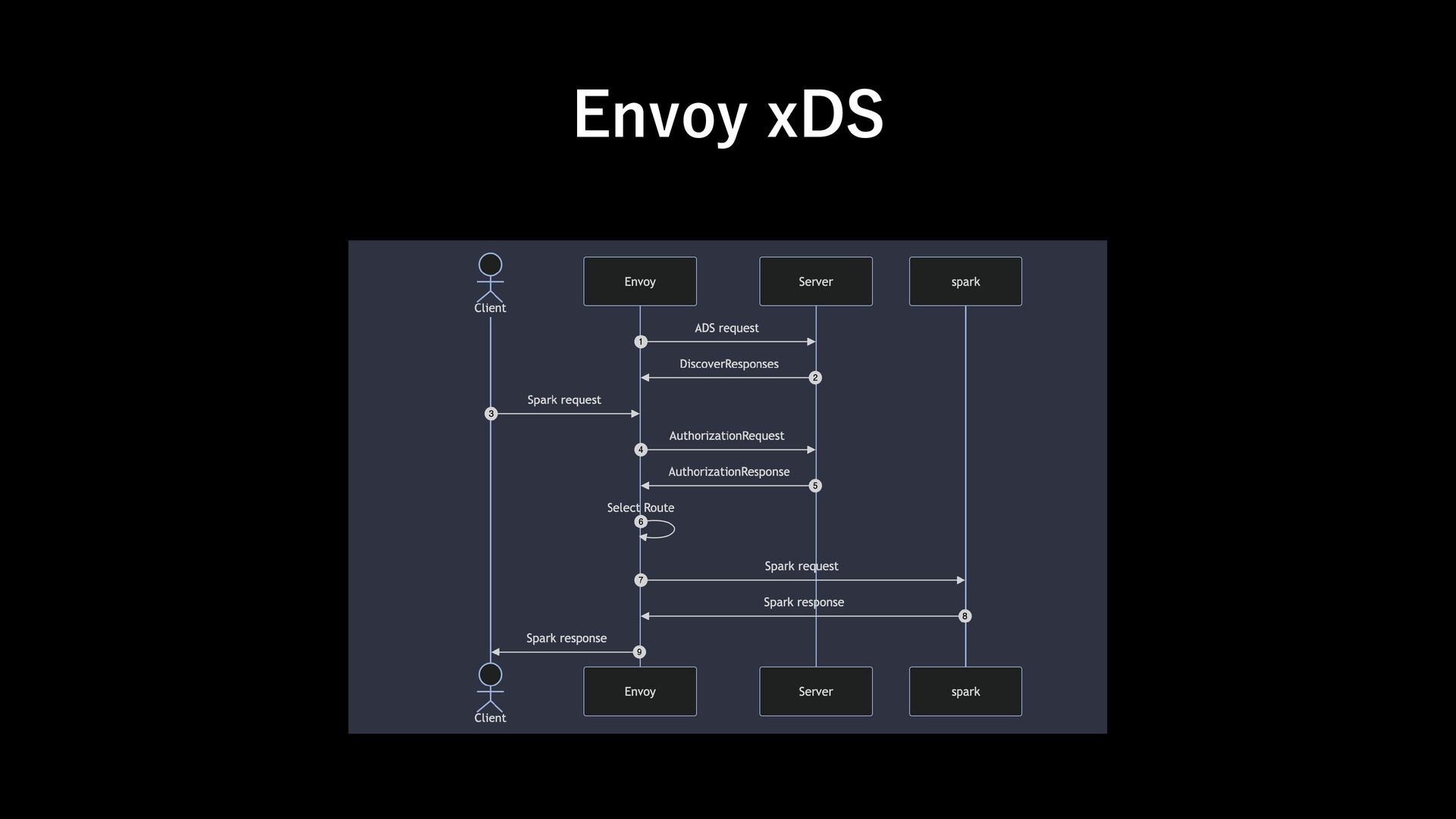
designed to work seamlessly with your existing authentication infrastructure. Its gRPC HTTP/2 interface allows for the use of authenticating proxies, which makes it possible to secure Spark Connect without having to implement authentication logic in Spark directly. ➔Envoy xDS ExtAuthz filter Requirement 2: Auth https://spark.apache.org/docs/latest/spark-connect-overview.html#what-is-supported
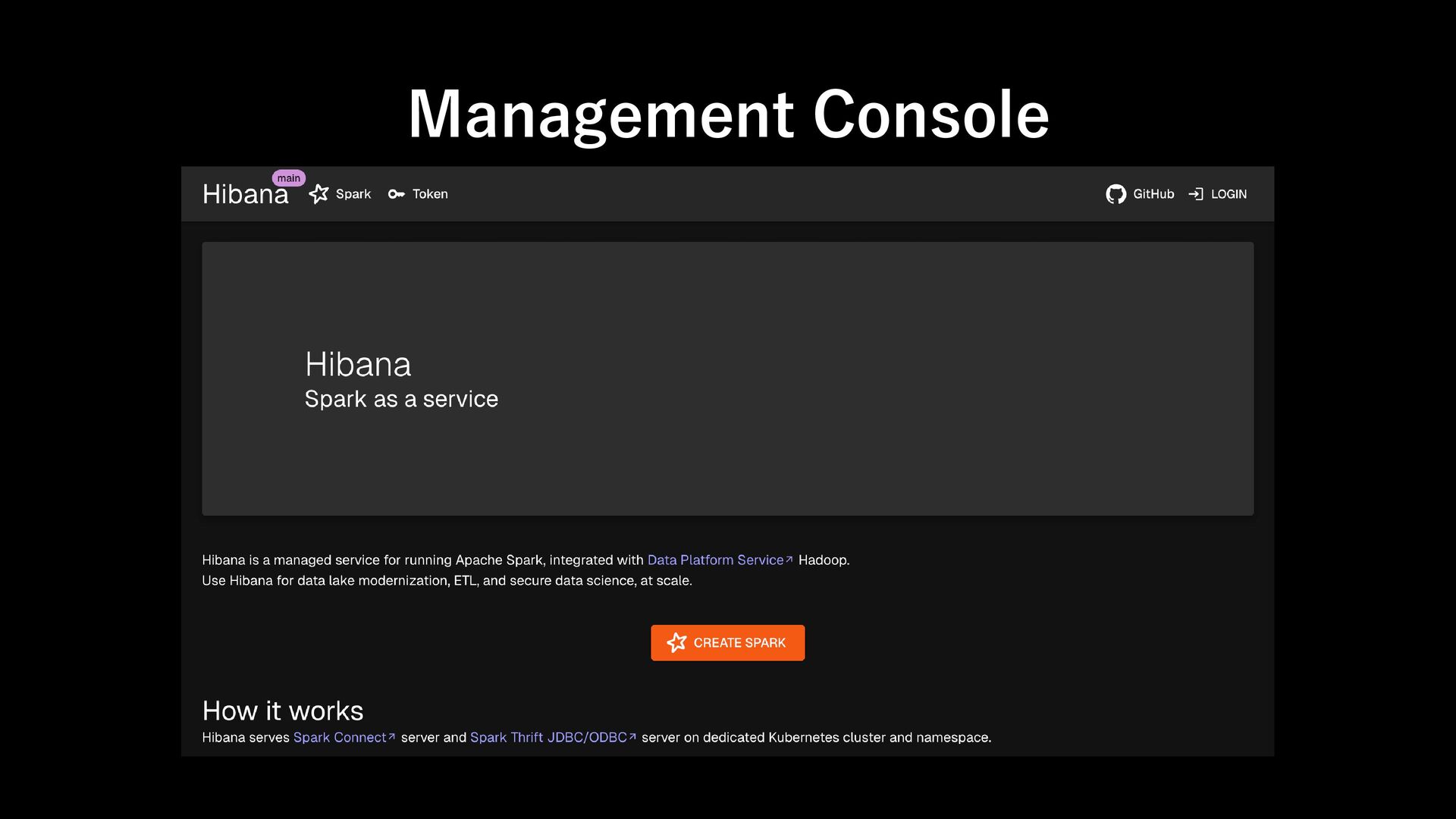
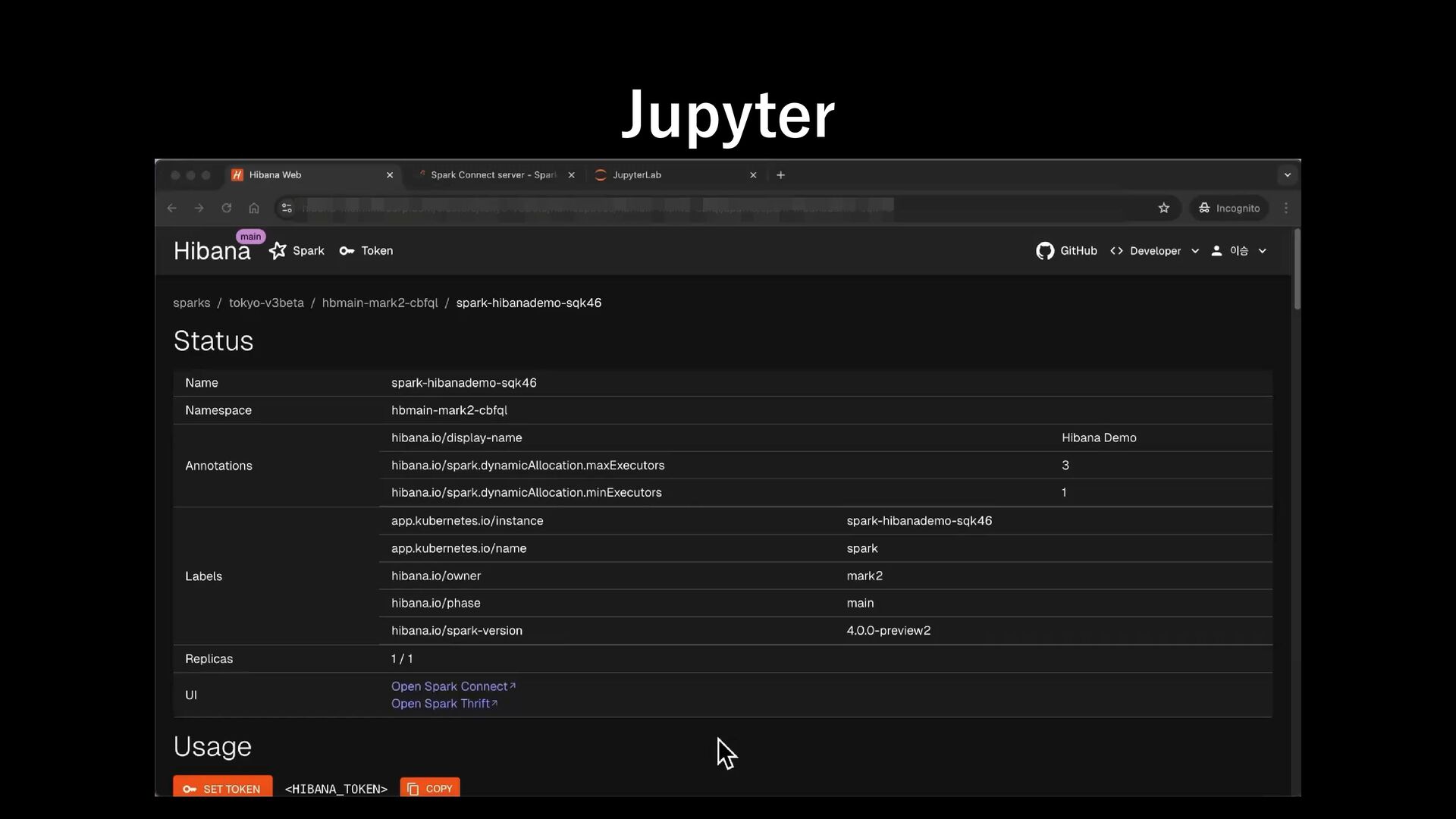
remote, interactive access to Apache Spark using the native DataFrame and SQL APIs. - Spark Connect can be used with external job tracker, job scheduler and user/session management Spark Connect
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}