‣Oracle ACE Director, specialising in Oracle BI&DW ‣14 Years Experience with Oracle Technology ‣Regular columnist for Oracle Magazine •Author of two Oracle Press Oracle BI books ‣Oracle Business Intelligence Developers Guide ‣Oracle Exalytics Revealed ‣Writer for Rittman Mead Blog : http://www.rittmanmead.com/blog •Email : [email protected] •Twitter : @markrittman About the Speaker
bank Oracle DW project •Our tools were Oracle 7.3.4, SQL*Plus, PL/SQL and shell scripts •Went on to use Oracle Developer/2000 and Designer/2000 •Our initial users queried the DW using SQL*Plus •And later on, we rolled-out Discoverer/2000 to everyone else •And life was fun… 20 Years in Oracle BI and Data Warehousing
of the business ‣Single place to store key data and metrics ‣Joined-up view of the business ‣Aggregates and conformed dimensions ‣ETL routines to load, cleanse and conform data •BI tools for simple, guided access to information ‣Tabular data access using SQL-generating tools ‣Drill paths, hierarchies, facts, attributes ‣Fast access to pre-computed aggregates ‣Packaged BI for fast-start ERP analytics Data Warehouses and Enterprise BI Tools Oracle MongoDB Oracle Sybase IBM DB/2 MS SQL MS SQL Server Core ERP Platform Retail Banking Call Center E-Commerce CRM Business Intelligence Tools Data Warehouse Access & Performance Layer ODS / Foundation Layer 4
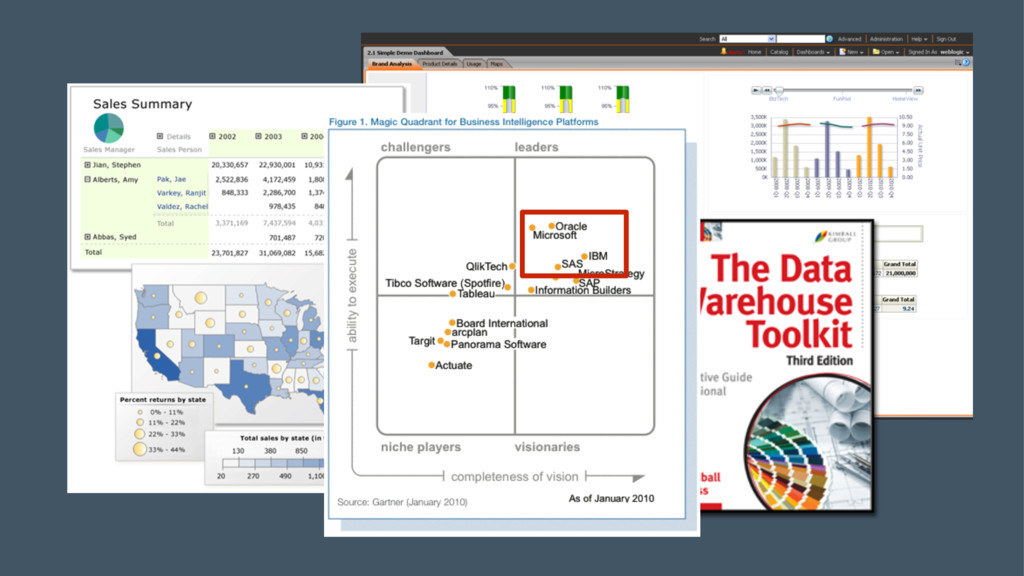
Cognos Impromptu, Business Objects •Report written against carefully-curated BI dataset, or directly connecting to ERP/CRM •Adding data from external sources, or other RDBMSs, was difficult and involved IT resources •Report-writing was a skilled job •High ongoing cost for maintenance and changes •Little scope for analysis, predictive modeling •Often user frustration and pace of delivery Reporting Back Then… 5
Objects, IBM Cognos •Full-featured, IT-orientated enterprise BI platforms •Metadata layers, integrated security, web delivery •Pre-build ERP metadata layers, dashboards + reports •Federated queries across multiple sources •Single version of the truth across the enterprise •Mobile, web dashboards, alerts, published reports •Integration with SOA and web services Then Came Enterprise BI Tools 6
/ ODS Performance / Dimensional ETL ETL BI Tool (OBIEE) with metadata layer OLAP / In-Memory Tool with data load into own database Direct Read Data Load Traditional structured data sources Data Load Data Load Data Load Traditional Relational Data Warehouse •Three-layer architecture - staging, foundation and access/performance •All three layers stored in a relational database (Oracle) •ETL used to move data from layer-to-layer
Modern BI Platform Data source Upfront dimensional modeling required (IT-built star schemas) Upfront modeling not required (flat files/ flat tables) Data ingestion and preparation IT-produced IT-enabled Content authoring Primarily IT staff, but also some power users Business users Analysis Predefined, ad hoc reporting, based on predefined model Free-form exploration Insight delivery Distribution and notifications via scheduled reports or portal Sharing and collaboration, storytelling, open APIs Gartner’s View of A “Modern BI Platform” in 2016
when we got the infrastructure right Doesn’t anyone appreciate a single version of the truth? Don’t say we didn’t warn you No you can’t just export it to Excel Watch out OLAP you’re next
NoSQL databases and Cloud Storage •Flexible data storage platform with cheap storage, flexible schema support + compute •Data lands in the data lake or reservoir in raw form, then minimally processed •Data then accessed directly by “data scientists”, or processed further into DW Meet the New Data Warehouse : The “Data Reservoir” Data Transfer Data Access Data Factory Data Reservoir Business Intelligence Tools Hadoop Platform File Based Integration Stream Based Integration Data streams Discovery & Development Labs Safe & secure Discovery and Development environment Data sets and samples Models and programs Marketing / Sales Applications Models Machine Learning Segments Operational Data Transactions Customer Master ata Unstructured Data Voice + Chat Transcripts ETL Based Integration Raw Customer Data Data stored in the original format (usually files) such as SS7, ASN.1, JSON etc. Mapped Customer Data Data sets produced by mapping and transforming raw data
Analytics •Enterprise High-End RDBMSs such as Oracle can scale into the petabytes, using clustering ‣Sharded databases (e.g. Netezza) can scale further but with complexity / single workload trade-offs •Hadoop was designed from outside for massive horizontal scalability - using cheap hardware •Anticipates hardware failure and makes multiple copies of data as protection •More nodes you add, more stable it becomes •And at a fraction of the cost of traditional RDBMS platforms
historic data •Typically comes in non-tabular form •JSON, log files, key/value pairs •Users often want it speculatively •Haven’t thought it through •Schema can evolve •Or maybe there isn’t one •But the end-users want it now •Not when you’re ready 35 But Why Hadoop? Reason #1 - Flexible Storage Big Data Management Platform Discovery & Development Labs Safe & secure Discovery and Development environment Data sets and samples Models and programs Single Customer View Enriched Customer Profile Correlating Modeling Machine Learning Scoring Schema-on Read Analysis
Scalability •Enterprise High-End RDBMSs such as Oracle can scale ‣Clustering for single-instance DBs can scale to >PB ‣Exadata scales further by offloading queries to storage ‣Sharded databases (e.g. Netezza) can scale further ‣But cost (and complexity) become limiting factors ‣Typically $1m/node is not uncommon
Scalability •Hadoop’s main design goal was to enable virtually-limitless horizontal scalability •Rather than a small number of large, powerful servers, it spreads processing over large numbers of small, cheap, redundant servers •Processes the data where it’s stored, avoiding I/O bottlenecks •The more nodes you add, the more stable it becomes! •At an affordable cost - this is key •$50k/node vs. $1m/node •And … the Hadoop platform is a better fit for new types of processing and analysis
load data in/out of Hadoop platforms ‣Bulk extract ‣External tables ‣Query federation •Use high-end RDBMSs as specialist engines •a.k.a. "Data Marts" But … Analytic RDBMSs Are The New Data Mart Discovery & Development Labs Safe & secure Discovery and Development environment Data Warehouse Curated data : Historical view and business aligned access Business Intelligence Tools Big Data Management Platform Data sets and samples Models and programs Big Data Platform - All Running Natively Under Hadoop YARN (Cluster Resource Management) Batch (MapReduce) HDFS (Cluster Filesystem holding raw data) Interactive (Impala, Drill, Tez, Presto) Streaming + In-Memory (Spark, Storm) Graph + Search (Solr, Giraph) Enriched Customer Profile Modeling Scoring
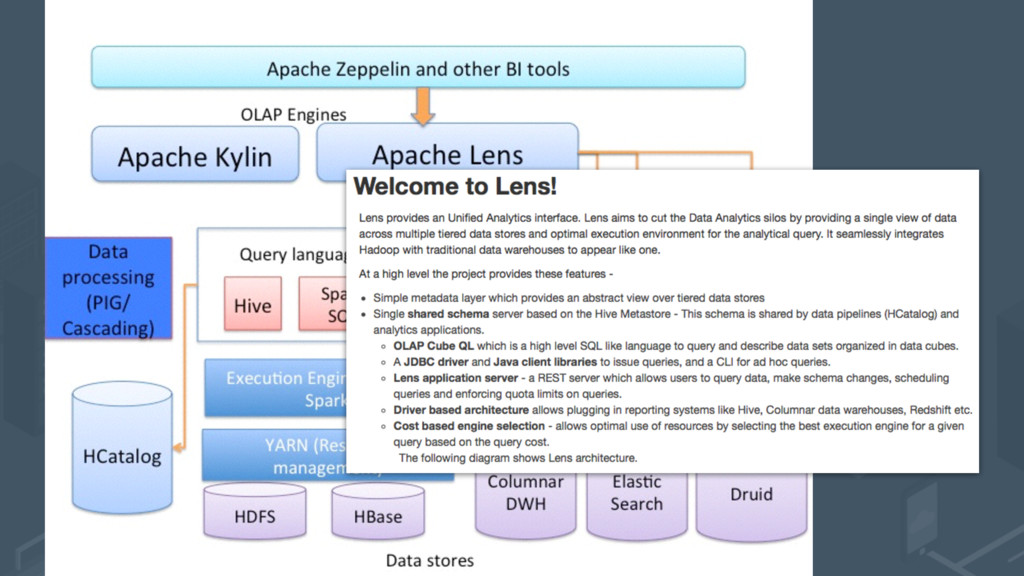
time issues •MPP SQL query engine running on Hadoop, bypasses MapReduce for direct data access •Mostly in-memory, but spills to disk if required •Uses Hive metastore to access Hive table metadata •Similar SQL dialect to Hive - not as rich though and no support for Hive SerDes, storage handlers etc Cloudera Impala - Fast, MPP-style Access to Hadoop Data
using text file formats (CSV) but these have limitations •Apache AVRO often used for general-purpose processing ‣Splitability, schema evolution, in-built metadata, support for block compression •Parquet now commonly used with Impala due to column-orientated storage ‣Mirrors work in RDBMS world around column-store ‣Only return (project) the columns you require across a wide table Apache Parquet - Column-Orientated Storage for Analytics
limitation for real-time analytics applications ‣Append-only orientation, focus on column-store makes streaming ingestion harder •Cloudera Kudu aims to combine best of HDFS + HBase ‣Real-time analytics-optimised ‣Supports updates to data ‣Fast ingestion of data ‣Accessed using SQL-style tables and get/put/update/delete API Cloudera Kudu - Combining Best of HBase and Column-Store
create tables using Kudu storage handler •Can now UPDATE, DELETE and INSERT into Hadoop tables, not just SELECT and LOAD DATA Example Impala DDL + DML Commands with Kudu CREATE TABLE `my_first_table` ( `id` BIGINT, `name` STRING ) TBLPROPERTIES( 'storage_handler' = 'com.cloudera.kudu.hive.KuduStorageHandler', 'kudu.table_name' = 'my_first_table', 'kudu.master_addresses' = 'kudu-master.example.com:7051', 'kudu.key_columns' = 'id' ); INSERT INTO my_first_table VALUES (99, "sarah"); INSERT IGNORE INTO my_first_table VALUES (99, "sarah"); UPDATE my_first_table SET name="bob" where id = 3; DELETE FROM my_first_table WHERE id < 3; DELETE c FROM my_second_table c, stock_symbols s WHERE c.name = s.symbol;
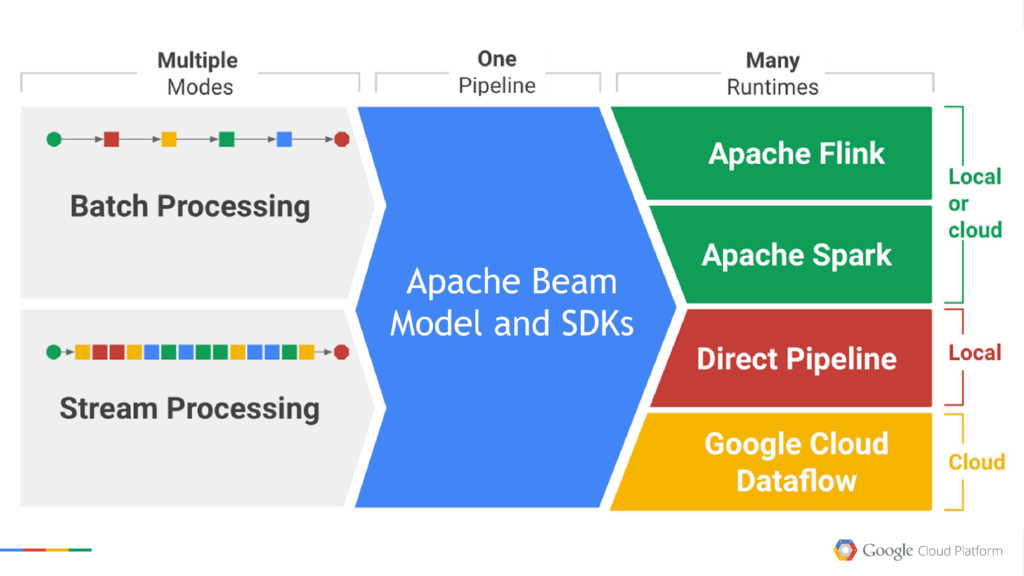
YARN •More mature than TEZ, with richer API and more vendor support •Uses concept of an RDD (Resilient Distributed Dataset) ‣RDDs like tables or Pig relations, but can be cached in-memory ‣Great for in-memory transformations, or iterative/cyclic processes •Spark jobs comprise of a DAG of tasks operating on RDDs •Access through Scala, Python or Java APIs •Related projects include ‣Spark SQL ‣Spark Streaming Apache Spark
RDDs in Spark to be processed using SQL queries •Bring in and federate additional data from JDBC sources •Load, read and save data in Hive, Parquet and other structured tabular formats Spark SQL - Adding SQL Processing to Apache Spark val accessLogsFilteredDF = accessLogs .filter( r => ! r.agent.matches(".*(spider|robot|bot|slurp).*")) .filter( r => ! r.endpoint.matches(".*(wp-content|wp-admin).*")).toDF() .registerTempTable("accessLogsFiltered") val topTenPostsLast24Hour = sqlContext.sql("SELECT p.POST_TITLE, p.POST_AUTHOR, COUNT(*) as total FROM accessLogsFiltered a JOIN posts p ON a.endpoint = p.POST_SLUG GROUP BY p.POST_TITLE, p.POST_AUTHOR ORDER BY total DESC LIMIT 10 ") // Persist top ten table for this window to HDFS as parquet file topTenPostsLast24Hour.save("/user/oracle/rm_logs_batch_output/topTenPostsLast24Hour.parquet" , "parquet", SaveMode.Overwrite)
All rights reserved. | Proprietary ETL engines die circa 2015 – folded into big data Oracle Open World 2015 21 Proprietary ETL is Dead. Apache-based ETL is What’s Next Scripted SQL Stored Procs ODI for Columnar ODI for In-Mem ODI for Exadata ODI for Hive ODI for Pig & Oozie 1990’s Eon of Scripts and PL-SQL Era of SQL E-LT/Pushdown Big Data ETL in Batch Streaming ETL Period of Proprietary Batch ETL Engines Informatica Ascential/IBM Ab Initio Acta/SAP SyncSort 1994 Oracle Data Integrator ODI for Spark ODI for Spark Streaming Warehouse Builder
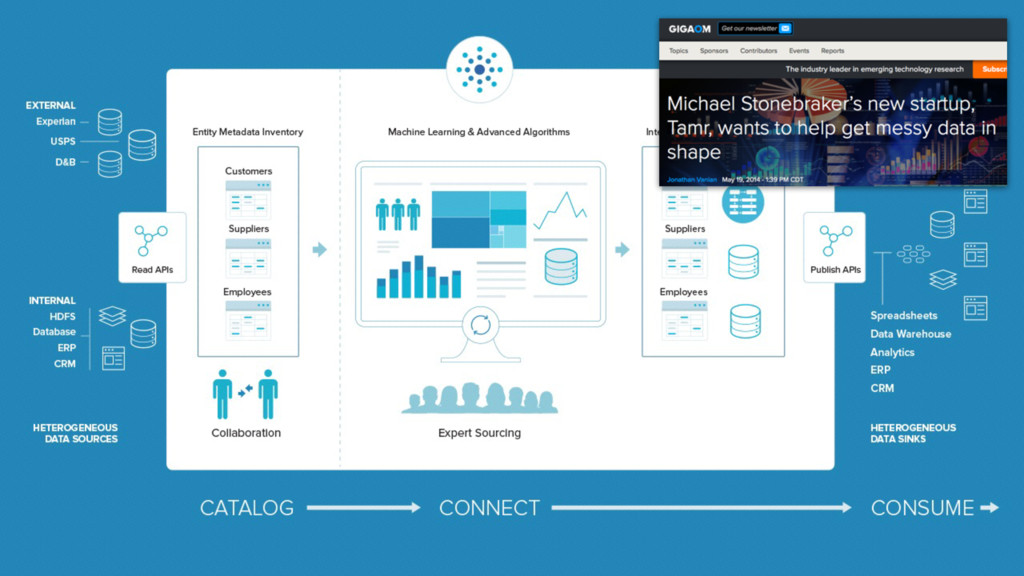
a big data system ... so how do you find the data you want? •Google's own internal solution - GOODS ("Google Dataset Search") •Uses crawler to discover new datasets •ML classification routines to infer domain •Data provenance and lineage •Indexes and catalogs 26bn datasets •Other users, vendors also have solutions •Oracle Big Data Discovery •Datameer •Platfora •Cloudera Navigator Google GOODS - Catalog + Search At Google-Scale
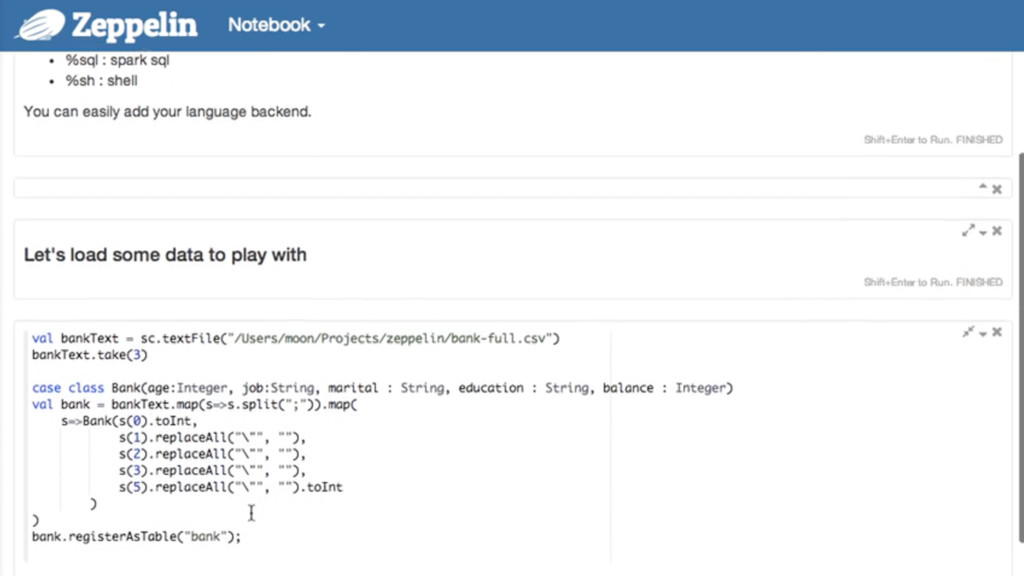
as a way to "show workings" •A set of reproducible steps that tell a story about the data •as well as being a better command-line environment for data analysis •One example is Jupyter, evolution of iPython notebook •supports pySpark, Pandas etc •See also Apache Zepplin Web-Based Data Analysis Notebooks
{kind=link}
![[email protected] www.rittmanmead.com @rittmanmead 2 •Mark Rittman, Co-Founder of Rittman Mead](https://files.speakerdeck.com/presentations/71a2d1fa2312475bbd2f9d7626ea6f47/slide_1.jpg){kind=link}
![[email protected] www.rittmanmead.com @rittmanmead 3 •Started back in 1996 on a](https://files.speakerdeck.com/presentations/71a2d1fa2312475bbd2f9d7626ea6f47/slide_2.jpg){kind=link}
![[email protected] www.rittmanmead.com @rittmanmead 4 •Data warehouses provided a unified view](https://files.speakerdeck.com/presentations/71a2d1fa2312475bbd2f9d7626ea6f47/slide_3.jpg){kind=link}
![[email protected] www.rittmanmead.com @rittmanmead 5 •Examples were Crystal Reports, Oracle Reports,](https://files.speakerdeck.com/presentations/71a2d1fa2312475bbd2f9d7626ea6f47/slide_4.jpg){kind=link}
![[email protected] www.rittmanmead.com @rittmanmead 6 •For example Oracle OBIEE, SAP Business](https://files.speakerdeck.com/presentations/71a2d1fa2312475bbd2f9d7626ea6f47/slide_5.jpg){kind=link}
![[email protected] www.rittmanmead.com @rittmanmead Traditional Three-Layer Relational Data Warehouses Staging Foundation](https://files.speakerdeck.com/presentations/71a2d1fa2312475bbd2f9d7626ea6f47/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
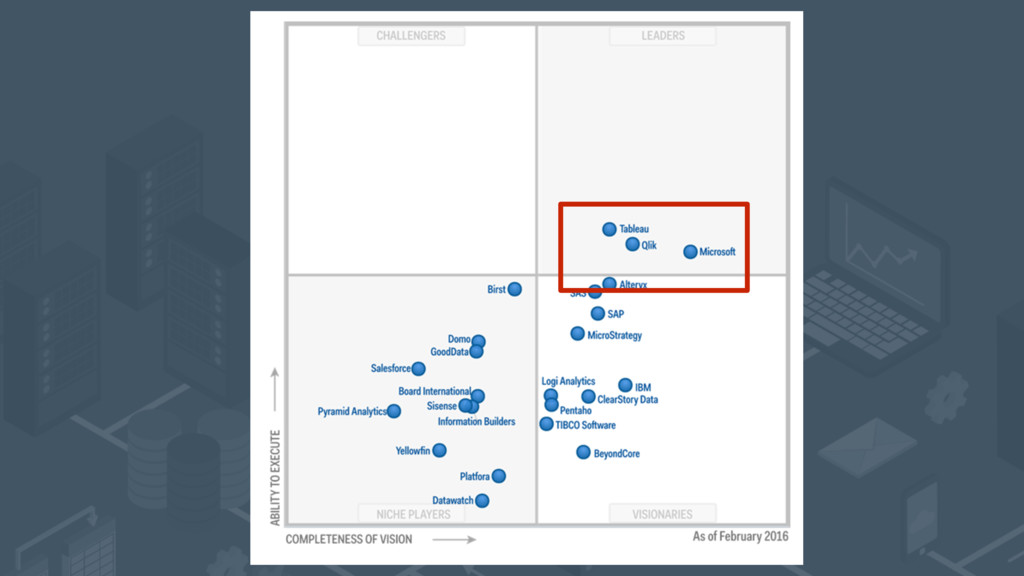
![[email protected] www.rittmanmead.com @rittmanmead The Gartner BI & Analytics Magic Quadrant](https://files.speakerdeck.com/presentations/71a2d1fa2312475bbd2f9d7626ea6f47/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
![[email protected] www.rittmanmead.com @rittmanmead 29 Analytic Workflow Component Traditional BI Platform](https://files.speakerdeck.com/presentations/71a2d1fa2312475bbd2f9d7626ea6f47/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
![[email protected] www.rittmanmead.com @rittmanmead 32 •Data now landed in Hadoop clusters,](https://files.speakerdeck.com/presentations/71a2d1fa2312475bbd2f9d7626ea6f47/slide_31.jpg){kind=link}
{kind=link}
![[email protected] www.rittmanmead.com @rittmanmead Hadoop : The Default Platform Today for](https://files.speakerdeck.com/presentations/71a2d1fa2312475bbd2f9d7626ea6f47/slide_33.jpg){kind=link}
![[email protected] www.rittmanmead.com @rittmanmead •Data from new-world applications is not like](https://files.speakerdeck.com/presentations/71a2d1fa2312475bbd2f9d7626ea6f47/slide_34.jpg){kind=link}
![[email protected] www.rittmanmead.com @rittmanmead But Why Hadoop? Reason #2 - Massive](https://files.speakerdeck.com/presentations/71a2d1fa2312475bbd2f9d7626ea6f47/slide_35.jpg){kind=link}
![[email protected] www.rittmanmead.com @rittmanmead But Why Hadoop? Reason #2 - Massive](https://files.speakerdeck.com/presentations/71a2d1fa2312475bbd2f9d7626ea6f47/slide_36.jpg){kind=link}
![[email protected] www.rittmanmead.com @rittmanmead But Why Hadoop? Reason #2 - Massive](https://files.speakerdeck.com/presentations/71a2d1fa2312475bbd2f9d7626ea6f47/slide_37.jpg){kind=link}
![[email protected] www.rittmanmead.com @rittmanmead Big Data Platform - All Running Natively](https://files.speakerdeck.com/presentations/71a2d1fa2312475bbd2f9d7626ea6f47/slide_38.jpg){kind=link}
![[email protected] www.rittmanmead.com @rittmanmead Combine With DW for Old-World/New-World Solution](https://files.speakerdeck.com/presentations/71a2d1fa2312475bbd2f9d7626ea6f47/slide_39.jpg){kind=link}
![[email protected] www.rittmanmead.com @rittmanmead •Most high-end RDBMS vendors provide connectors to](https://files.speakerdeck.com/presentations/71a2d1fa2312475bbd2f9d7626ea6f47/slide_40.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[email protected] www.rittmanmead.com @rittmanmead 56 Hadoop 2.0 Processing Frameworks + Tools](https://files.speakerdeck.com/presentations/71a2d1fa2312475bbd2f9d7626ea6f47/slide_55.jpg){kind=link}
![[email protected] www.rittmanmead.com @rittmanmead 57 •Cloudera’s answer to Hive query response](https://files.speakerdeck.com/presentations/71a2d1fa2312475bbd2f9d7626ea6f47/slide_56.jpg){kind=link}
![[email protected] www.rittmanmead.com @rittmanmead 58 •Beginners usually store data in HDFS](https://files.speakerdeck.com/presentations/71a2d1fa2312475bbd2f9d7626ea6f47/slide_57.jpg){kind=link}
![[email protected] www.rittmanmead.com @rittmanmead 59 •But Parquet (and HDFS) have significant](https://files.speakerdeck.com/presentations/71a2d1fa2312475bbd2f9d7626ea6f47/slide_58.jpg){kind=link}
![[email protected] www.rittmanmead.com @rittmanmead 60 •Kudu storage used with Impala -](https://files.speakerdeck.com/presentations/71a2d1fa2312475bbd2f9d7626ea6f47/slide_59.jpg){kind=link}
{kind=link}
{kind=link}
![[email protected] www.rittmanmead.com @rittmanmead 63 •Another DAG execution engine running on](https://files.speakerdeck.com/presentations/71a2d1fa2312475bbd2f9d7626ea6f47/slide_62.jpg){kind=link}
![[email protected] www.rittmanmead.com @rittmanmead 64 •Spark SQL, and Data Frames, allow](https://files.speakerdeck.com/presentations/71a2d1fa2312475bbd2f9d7626ea6f47/slide_63.jpg){kind=link}
![[email protected] www.rittmanmead.com @rittmanmead 65 Accompanied by Innovations in Underlying Platform](https://files.speakerdeck.com/presentations/71a2d1fa2312475bbd2f9d7626ea6f47/slide_64.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[email protected] www.rittmanmead.com @rittmanmead Copyright © 2015, Oracle and/or its affiliates.](https://files.speakerdeck.com/presentations/71a2d1fa2312475bbd2f9d7626ea6f47/slide_69.jpg){kind=link}
{kind=link}
{kind=link}
![[email protected] www.rittmanmead.com @rittmanmead •By definition there's lots of data in](https://files.speakerdeck.com/presentations/71a2d1fa2312475bbd2f9d7626ea6f47/slide_72.jpg){kind=link}
{kind=link}
![[email protected] www.rittmanmead.com @rittmanmead •Came out if the data science movement,](https://files.speakerdeck.com/presentations/71a2d1fa2312475bbd2f9d7626ea6f47/slide_74.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}