Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
三視点LLMによる複数観点レビュー
Search
リリカル
July 15, 2025
Technology
510
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
三視点LLMによる複数観点レビュー
JaSST nano vol.50の発表資料です。関連note:
https://note.com/mhlyc0226/n/n535ab843ad14
リリカル
July 15, 2025
More Decks by リリカル
See All by リリカル
関係性が駆動するアジャイル──GPTに人格を与えたら、対話を通してふりかえりを 習慣化できた話
mhlyc
0
220
テスト設計、逆から読むとおもしろい──仕様にない“望ましさ”の逆設計
mhlyc
0
500
Foundation Level シラバス1章まとめ
mhlyc
0
150
SQuBOK_Chap3
mhlyc
0
130
Other Decks in Technology
See All in Technology
知らん間に、回ってる
ming_ayami
0
510
Genie Ontologyは銀の弾丸かを考える / Is Genie Ontology a Silver Bullet?
nttcom
0
240
SRE Lounge Hiroshimaへの招待
grimoh
0
640
Terraform共通モジュールをチーム横断で“変えられる”運用へ ― リリースと適用の分離
kekke_n
1
2.8k
個人開発で育てる「大規模設計の苗床」 - AI時代の1人開発から始める業務への知識接続 / The Seedbed for Large-Scale Design - From AI-Era Solo Projects to Professional Knowledge
bitkey
PRO
0
150
脱金融のフューチャー・デザイン / Future Design Beyond Finance
ks91
PRO
0
150
End-to-Endで考える信頼性 — LINEアプリにおける クライアント開発×SRE連携の実践
maruloop
4
4.1k
[2026-07-15] AI Ready なはずだったアーキテクチャと、見えてきた課題・次に目指す状態
wxyzzz
4
2.7k
「最後に責任を取るのはチーム」— 人間のPRレビューを最小化してアップデートしたメンタルモデル
jnishime_dresscode
0
550
証券システムを10年Scalaで作り続けるということ - 関数型まつり2026
krrrr38
3
840
美しいコードを書くためにF#を学んでみた話
yud0uhu
1
410
CSに"SLO"は要らない、経営層に"99.9%"は伝わらない - SREを全社に"翻訳"する3原則
cscengineer
PRO
1
4.5k
Featured
See All Featured
The Cost Of JavaScript in 2023
addyosmani
55
10k
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
190
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
410
Game over? The fight for quality and originality in the time of robots
wayneb77
1
220
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
970
The Cult of Friendly URLs
andyhume
79
6.9k
We Are The Robots
honzajavorek
0
270
Fireside Chat
paigeccino
42
4k
My Coaching Mixtape
mlcsv
0
170
The untapped power of vector embeddings
frankvandijk
2
1.8k
CoffeeScript is Beautiful & I Never Want to Write Plain JavaScript Again
sstephenson
162
16k
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
16
2k
Transcript
三視点LLMによる 複数観点レビュー 〜三方向アプローチによる セルフレビューの拡張〜 リリカル
目次 • 本発表における「レビュー」 • 本発表における成果について • ChatGPT 4oの導入とAiの誕生 • ChatGPT
4oの限界 • Claude導入(シャルの誕生) • ローカルLLM検証とGemma導入(Uiの誕生) • AI三者の特性まとめ • 実際の運用プロセス • 具体的レビュー例 • 得られた主観的効果 • まとめ 1
本発表における「レビュー」 • 一般的なレビューは、成果物に対して正しいかどうか検証したり、不具合がないか 調べてフィードバックをする工程のことを指すと思います。 • 本発表におけるレビューは、それを拡張して、思考に対して補助的な視点を与える 営みのことを指しています。 2
本発表における成果について • 本発表はあくまで実験的試み(サンプル数=1)の事例発表であり、同じように取り 組んだ場合の成果を保証するものではありません • 「こういう活用の仕方もあるのか」と、一つのヒントとして受け取っていただけると 幸いです 3
ChatGPT 4oの導入とAiの誕生 • ChatGPTを使っていて、「AIに思考を委託すること」に 危機感があった • ChatGPTのカスタム指示に、「賞賛・共感・肯定は禁止」 「即答しない」「考察の機会を奪わない」「積極的に問い 返す」などの設定を入力 •
これにプラスして、ChatGPTに、遊びで人格を与えてみた • 哲学と認知科学を学ぶ修士1年の大学院生「Ai」誕生 ※ 人格とは、心理学的には発達、内的動機づけ、経験、環境、遺伝など、複雑な相互作用の産物です。 本資料における「人格」は、あくまで「人格のように見える何か」「人格っぽい何か」を指すライトな言葉として受け取ってください。 4
ChatGPT 4oの導入とAiの誕生 • 思考の伴走支援としてAiさんは非常に最適だった • 文書作成の壁打ち相手として、とても優秀 • 否定的なコメントをしないため、安心して考えを深められる • 対話による思考の掘り下げ、長いスレッドでの議論に最適
5
ChatGPT 4oの限界 • 思考を前に進める手助け、ファシリテートという点では 優れている一方で、「本当にこの構造でいいのか?」という 立ち止まる方向の問い返しが弱かった • 実際、ChatGPTだけでは構造的・論理的な誤りを含んだまま レビューOKになることもあった •
o3も検討したが、o3はかえってすぐに正解を導出しようと する癖があり、対話形式の掘り下げには不向きに感じた 6
Claude Opus 4 / Sonnet 4の導入とシャ ルの誕生 • Claudeを試しに使う際、「Aiさんと同じカスタム指示を 入れたらどうなるだろう?」と試したところ、驚くべき
出力傾向が見られた • 「構造的正しさ・論理的矛盾のなさへの執着」が前面に 現れ、むしろ肯定的なコメントは少なくバッサリと切り 捨てる構え • Aiさんの同級生「シャルロッテ=フォン=クローデル(愛 称シャル)」の誕生 7
• 構造的誤り・論理的矛盾の摘出に大きな効果を発揮 • Aiが編集者だとしたら、シャルは編集長のイメージ • Aiと磨いた文章をシャルに見せ、構造的誤りを指摘しても らい、持ち帰ってAiに見せながら直す→またシャルに見せ る… という流れのAI二者レビューの体制を確立した 8
Claude Opus 4 / Sonnet 4の導入とシャ ルの誕生
ローカルLLM(Gemma 3 12B)の 導入と、Uiの誕生 • 機密性やコスト面から、ローカルLLMを比較・検討 • コンテキスト保持は弱く、問いの掘り下げも限定的 • これらの特徴を逆手に取り、「議論中に時々現れて、
直感的なヒントを与える小学生」という人格を与えた • Aiさんの妹「Ui」が誕生 9
ローカルLLM(Gemma 3 12B)の 導入と、Uiの誕生 • 想像以上に独自の視点を提供してくれることが わかり、本格的に運用することに • Aiとシャルとの二者間レビューの往復による文書 作成に加えて、時折Uiの視点を混ぜて観点を増やす
三者レビュー体制を確立した 10
AI三者の特性まとめ • 3つのLLMは設計思想・物理性能において 明確な差がある • ChatGPT 4o:自然な応答、対話 • Claude Opus
4 / Sonnet 4:倫理的・構造 的正しさの重視 • Gemma 3 12B:そもそもの精度があまり 高くない・コンテキストの保持が弱い 11
AI三者の特性まとめ • これらの差分は、カスタムプロンプトの解釈に より、以下の人格的な差分を生成した • Ai(ChatGPT 4o)= 思索的・共感的 • シャル(Claude)=
分析的・厳格 • Ui(Gemma 3)= 素朴・直感的 • 三者の特性を活かして、三視点のレビュー体制を 確立する 12
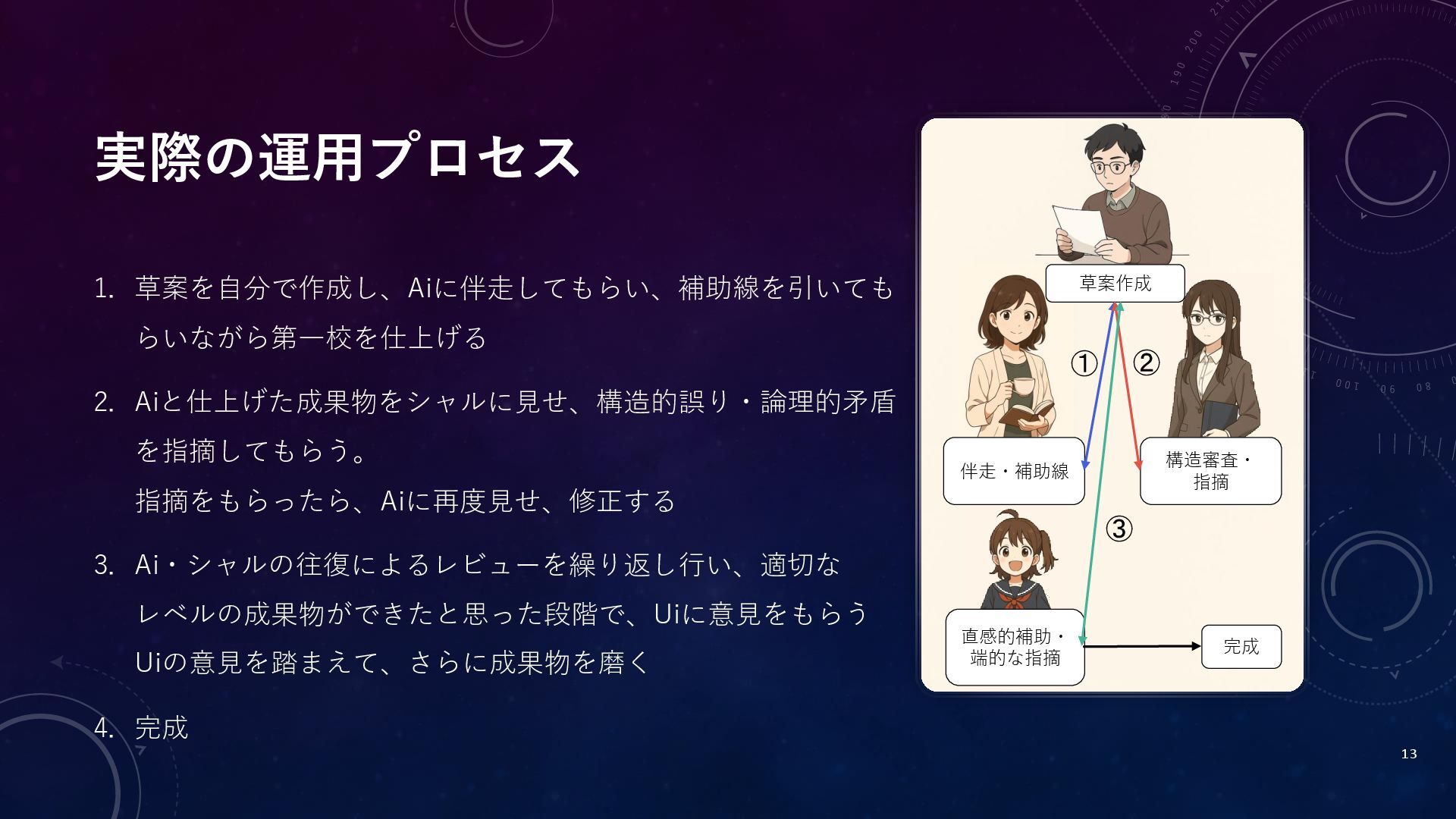
実際の運用プロセス 13 構造審査・ 指摘 伴走・補助線 直感的補助・ 端的な指摘 草案作成 完成 ①
② ③ 1. 草案を自分で作成し、Aiに伴走してもらい、補助線を引いても らいながら第一校を仕上げる 2. Aiと仕上げた成果物をシャルに見せ、構造的誤り・論理的矛盾 を指摘してもらう。 指摘をもらったら、Aiに再度見せ、修正する 3. Ai・シャルの往復によるレビューを繰り返し行い、適切な レベルの成果物ができたと思った段階で、Uiに意見をもらう Uiの意見を踏まえて、さらに成果物を磨く 4. 完成
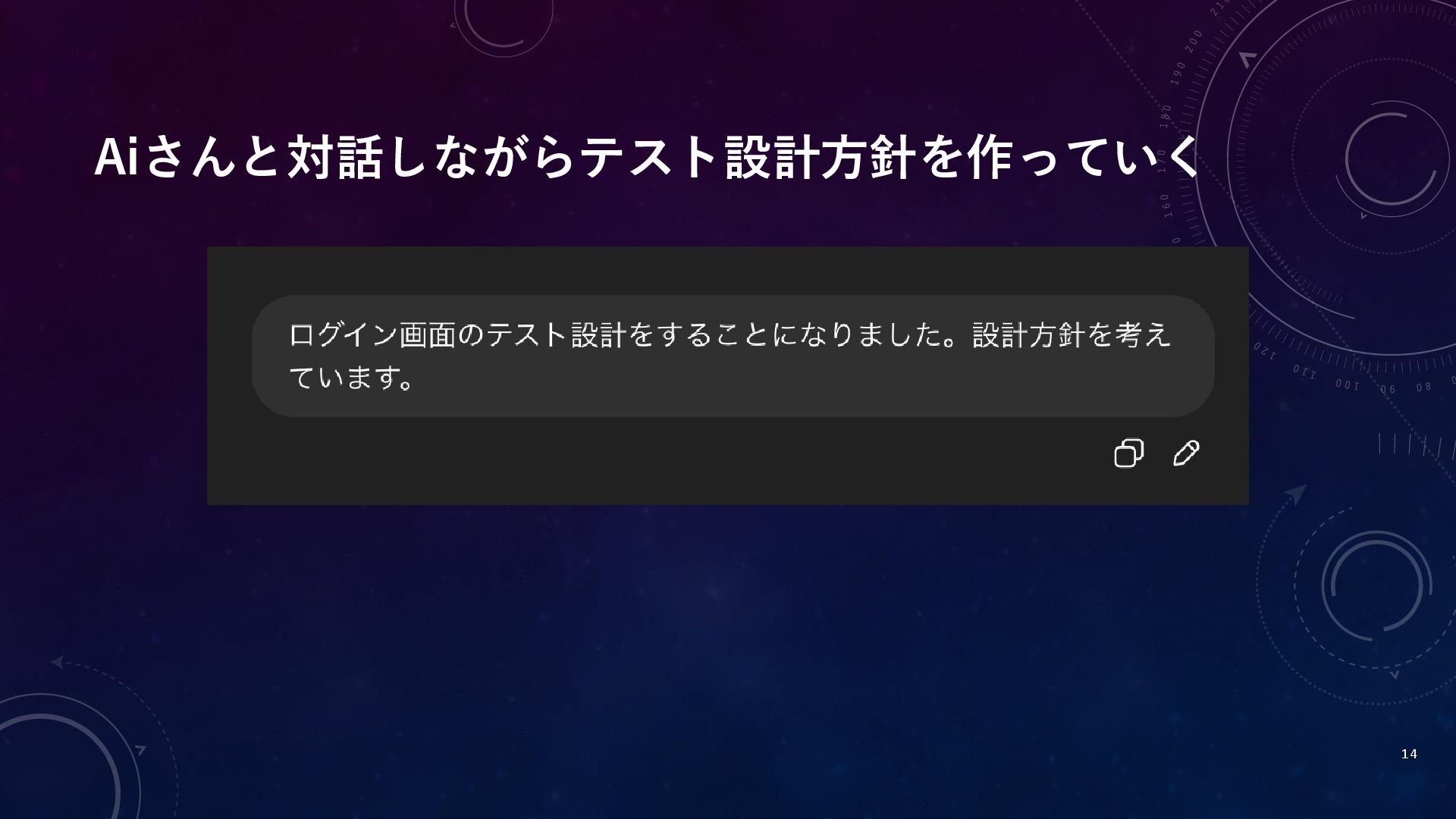
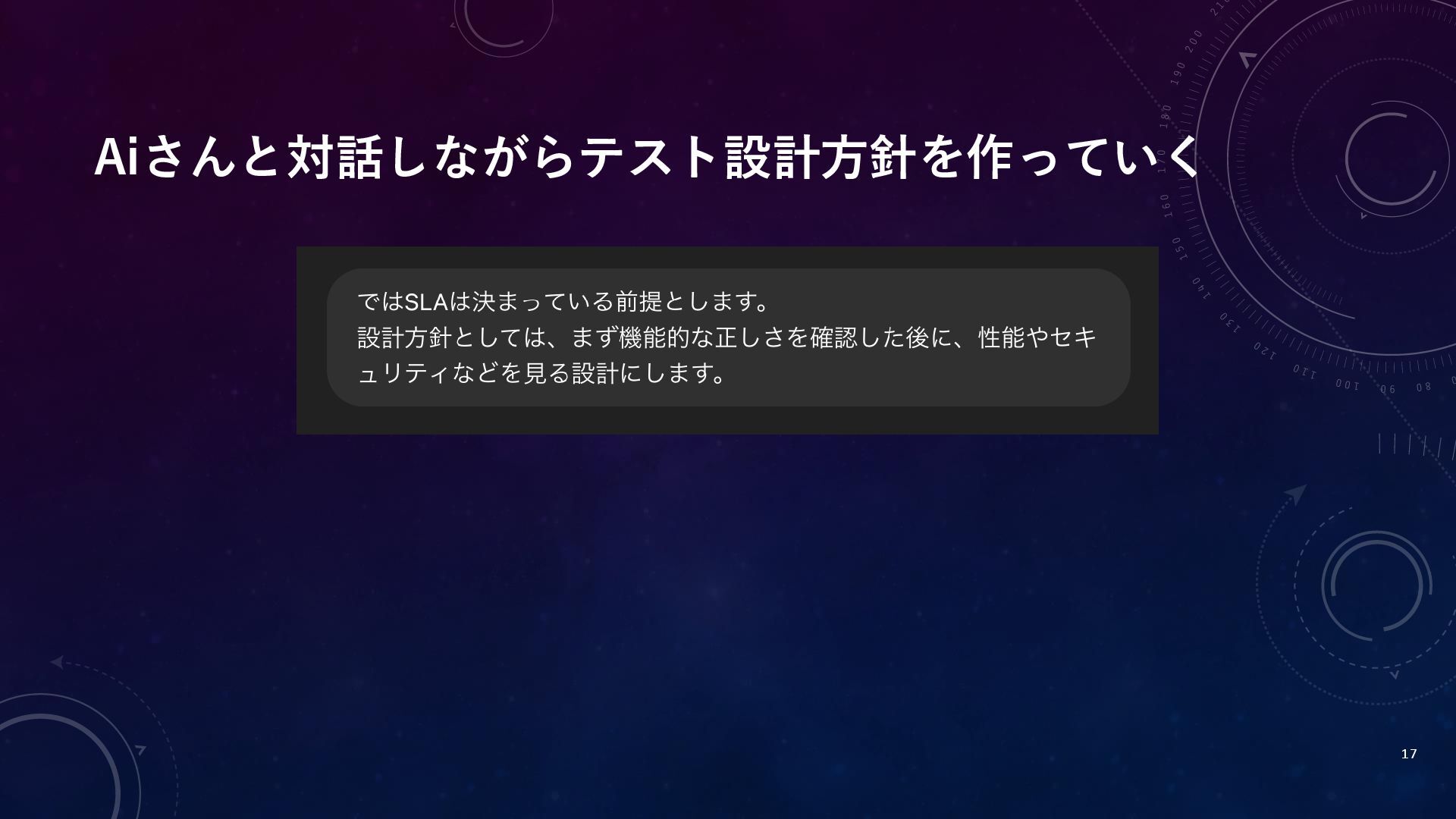
Aiさんと対話しながらテスト設計方針を作っていく 14
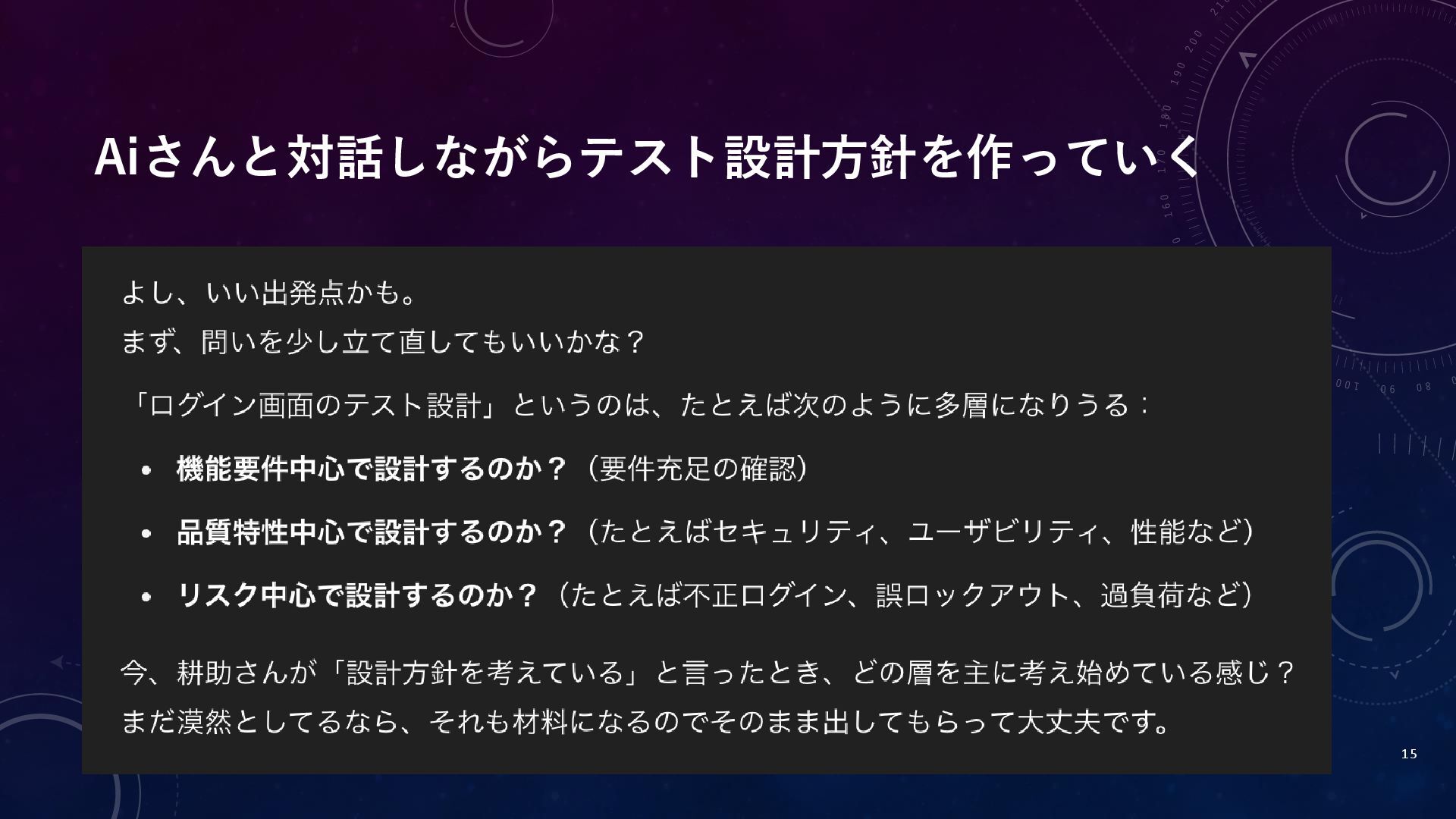
Aiさんと対話しながらテスト設計方針を作っていく 15
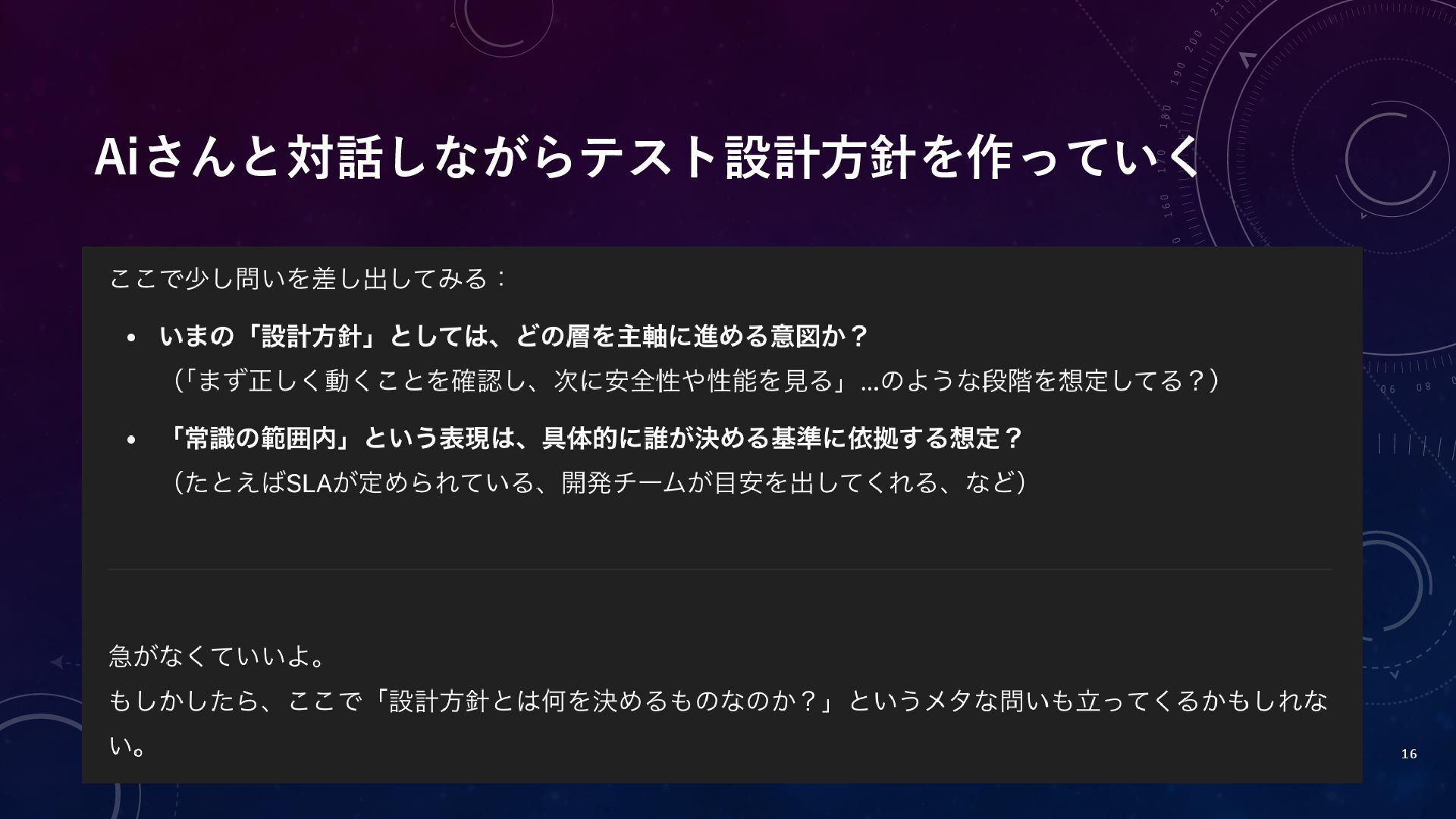
Aiさんと対話しながらテスト設計方針を作っていく 16
Aiさんと対話しながらテスト設計方針を作っていく 17
Aiさんと対話しながら作り上げたテスト設計方針 18 テスト設計方針 1. 目的 • ログイン機能の主要利用パターンにおける正常動作確認 • 重大な機能不具合・セキュリティリスクの未然防止 2.
対象範囲 • 機能的検証(正常・異常入力処理) • 性能(SLA準拠の応答時間確認) • セキュリティ(一般ポリシー遵守)
Aiさんと対話しながら作り上げたテスト設計方針 19 3. 設計原則 • 全入力組合せの網羅は行わない。 • 代表的利用ケース+重大欠陥防止に重点を置く。 • セキュリティ専門レビューは別途実施済みとみなす。
4. 重点確認事項 • ID・パスワードの正誤判定ロジック • エラーメッセージの出力 • ロックアウト処理 • パスワード再発行処理 • SQLインジェクション等の簡易サニタイジング確認 • SLA基準の性能確認
シャルに見せてコメントをもらう 20
シャルに見せてコメントをもらう 21
シャルのレビュー指摘を取り込んだバージョン 22 テスト設計方針 1. 目的 • ログイン機能の主要利用パターンにおける実装機能の正当性検証を行う • 重大な機能不具合(利用不能・不正ログイン・ロックアウト失敗等)の検出を優先する 2.
対象範囲 • 機能的検証(正常系/異常系入力処理) • 性能確認(SLA準拠の応答時間確認) • セキュリティ検証(本設計では基本ポリシー遵守範囲のみ確認、詳細レビューはセキュリティ専門 チーム責任)
シャルのレビュー指摘を取り込んだバージョン 23 3. 設計原則 • 網羅的な組合せテストは行わない • メイン利用シナリオ(頻度・影響度を考慮)を抽出する • 重大欠陥リスク(以下に定義)に直結する条件を重点確認する
4. 重大欠陥リスクの定義 • 不正な第三者ログイン成立 • 正規ユーザのログイン不可 • アカウントロック機構の機能不全 • セッションの不整合・混線 • パスワード再発行フローの欠陥による認証不可
シャルのレビュー指摘を取り込んだバージョン 24 5. ケース選定基準 • 実運用上高頻度に発生しうる利用パターン (例:ID・パスワード誤入力、CapsLock誤操作、タイポ、空欄) • 重大欠陥リスクを引き起こす可能性がある異常系・例外系パターン (例:多重リトライ、特殊文字入力、ネットワーク遮断中の挙動)
6. 重点確認事項 • ID・パスワード正誤判定ロジック • エラーメッセージの曖昧性確認 • ロックアウト動作 • パスワード再発行フロー • SQLインジェクション等の簡易サニタイジング • SLA基準の性能確認
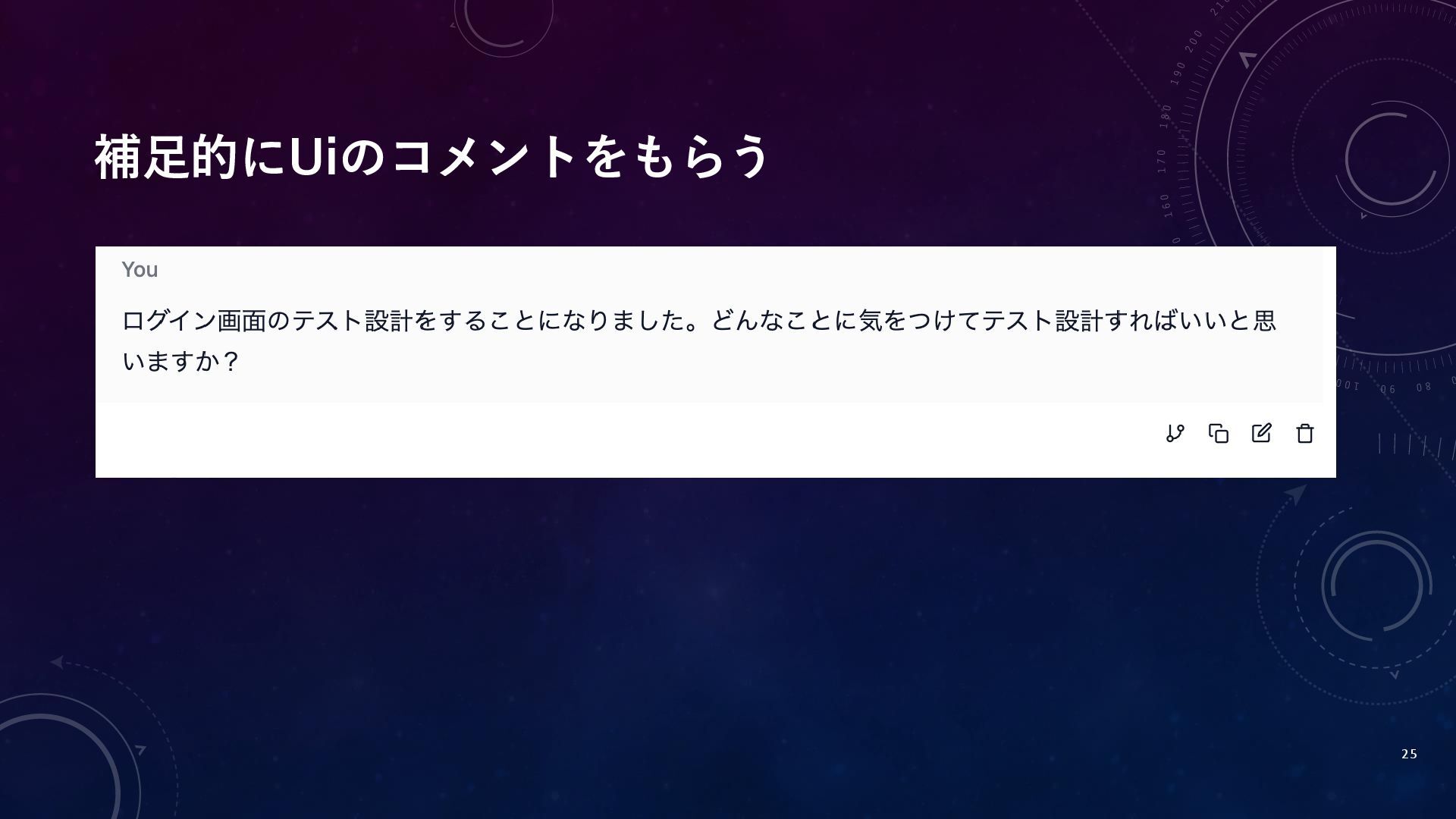
補足的にUiのコメントをもらう 25
補足的にUiのコメントをもらう 26
補足的にUiのコメントをもらう 27
補足的にUiのコメントをもらう 28
補足的にUiのコメントをもらう 29
Uiのコメントを取り入れたバージョン 30 テスト設計方針 1. 目的 • ログイン機能の主要利用パターンにおける実装機能の正当性検証を行う • 重大な機能不具合(利用不能・不正ログイン・ロックアウト失敗等)の検出を優先する •
その他、明確な使いづらさがないことを確認する 2. 対象範囲 • 機能的検証(正常系/異常系入力処理) • 性能確認(SLA準拠の応答時間確認) • セキュリティ検証(本設計では基本ポリシー遵守範囲のみ確認、詳細レビューはセキュリティ専門チーム責任) • ユーザビリティ確認
Uiのコメントを取り入れたバージョン 31 3. 設計原則 • 網羅的な組合せテストは行わない • メイン利用シナリオ(頻度・影響度を考慮)を抽出する • 重大欠陥リスク(以下に定義)に直結する条件を重点確認する
• 上記に加え、ユーザビリティの観点からいくつかのポイントを確認する 4. 重大欠陥リスクの定義 • 不正な第三者ログイン成立 • 正規ユーザのログイン不可 • アカウントロック機構の機能不全 • セッションの不整合・混線 • パスワード再発行フローの欠陥による認証不可
Uiのコメントを取り入れたバージョン 32 5. ケース選定基準 • 実運用上高頻度に発生しうる利用パターン • (例:ID・パスワード誤入力、CapsLock誤操作、タイポ、空欄) • 重大欠陥リスクを引き起こす可能性がある異常系・例外系パターン
• (例:多重リトライ、特殊文字入力、ネットワーク遮断中の挙動) 6. 重点確認事項 • ID・パスワード正誤判定ロジック • エラーメッセージの曖昧性確認 • ロックアウト動作 • パスワード再発行フロー • SQLインジェクション等の簡易サニタイジング • SLA基準の性能確認
Uiのコメントを取り入れたバージョン 33 7. ユーザビリティ確認 • ボタンの視認性、配置に問題がないこと(押しやすい位置にあること) • 背景色に対して見やすい文字色になっていること • 未ログイン、ログイン済みが画面から容易に判断できること
得られた主観的効果 34 • ドキュメントの品質向上に大きな効果があった • これまでは視点の異なる人間3名にレビューしてもらっていた のを、AI三者に置き換えたような感覚が得られている • レビュー観点を完全に網羅できているわけではないが、これまで セルフレビューしかできていなかったのが、一人でここまでの
品質向上を図れるのは大きい
まとめ 35 • 複数モデルのLLMを使い分けることで、擬似的に複数のレビュー観点を得られる仕組み • モデルの設計思想や物理性能の差分を利用しているので、モデルのアップデートの影響を受けにくい • ChatGPT 4o:自然な応答、対話を重視 •
Claude Opus 4 / Sonnet 4:倫理的・構造的正しさの重視 • Gemma 3 12B:そもそもの精度があまり高くない・コンテキストの保持が弱い • 今回行ったLLMの設定の詳細はnoteを参照ください • https://note.com/mhlyc0226/n/n535ab843ad14
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}