that matches the requirements of the pod and the pod remains unscheduled, which could cause an outage. ▪ While debugging these types of issues a common error message in autoscaler logs is pod didn't trigger scale-up (it wouldn't fit if a new node is added) ▪ Using too big instances in node groups, which leads to low resource utilization and increased cost. ▪ Using too low instances in Node groups, which leads to node groups maxing out and resulting in unscheduled pods. ▪ No way to identify the optimal choice of instance types based on workloads. Reason to use Karpenter (vs Cluster Autoscaler)
{kind=link}
{kind=link}
{kind=link}
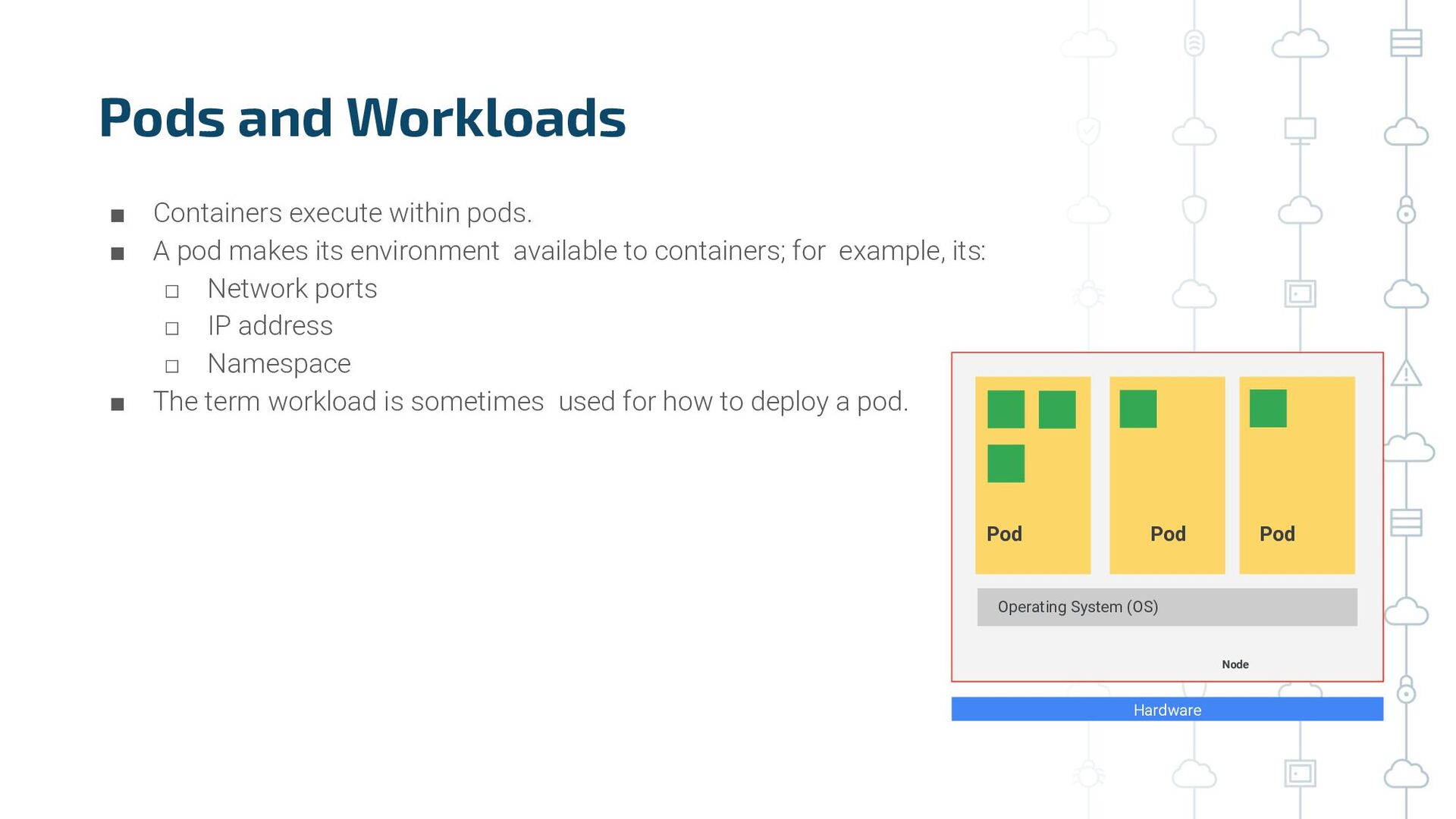{kind=link}
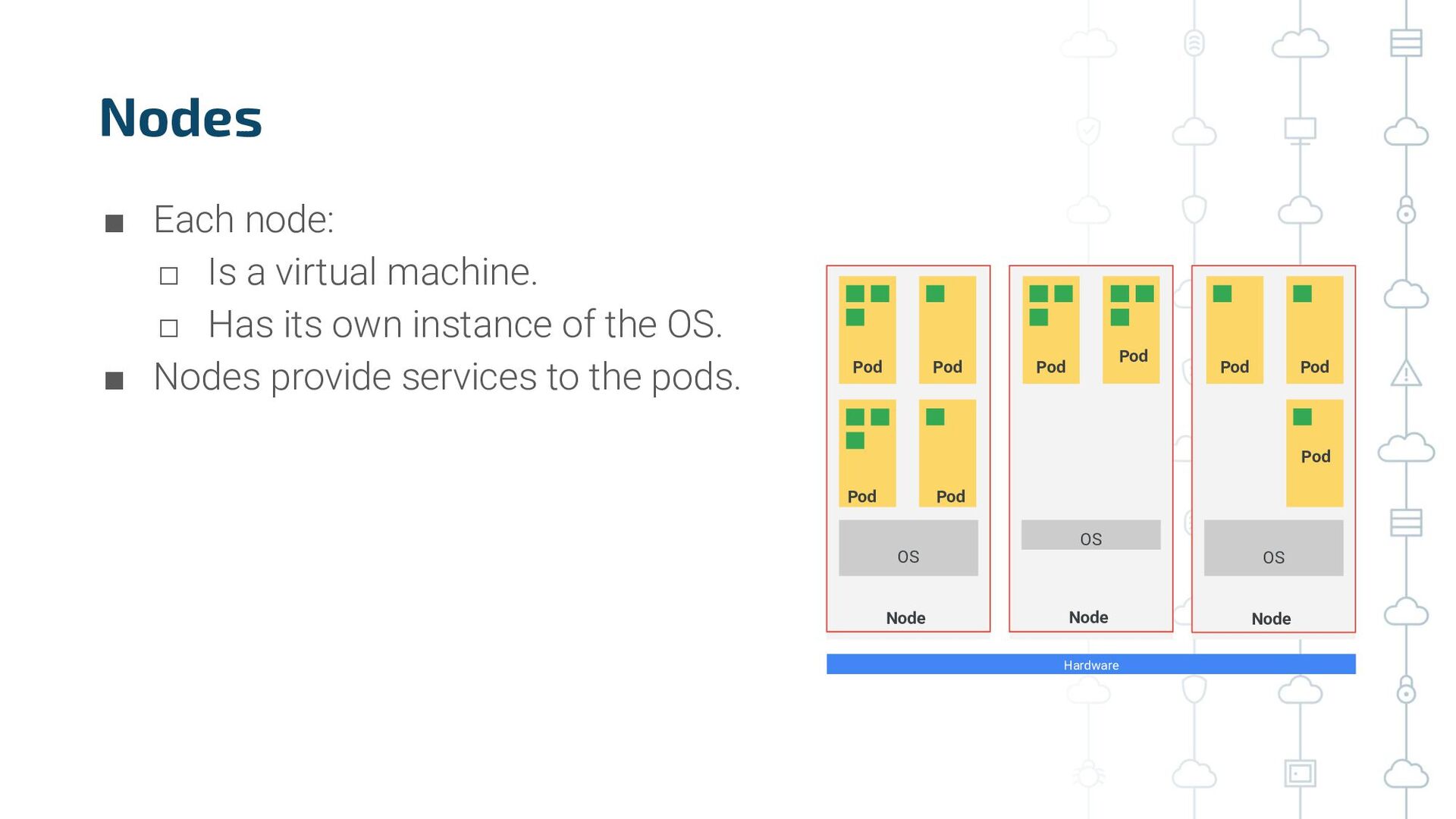{kind=link}
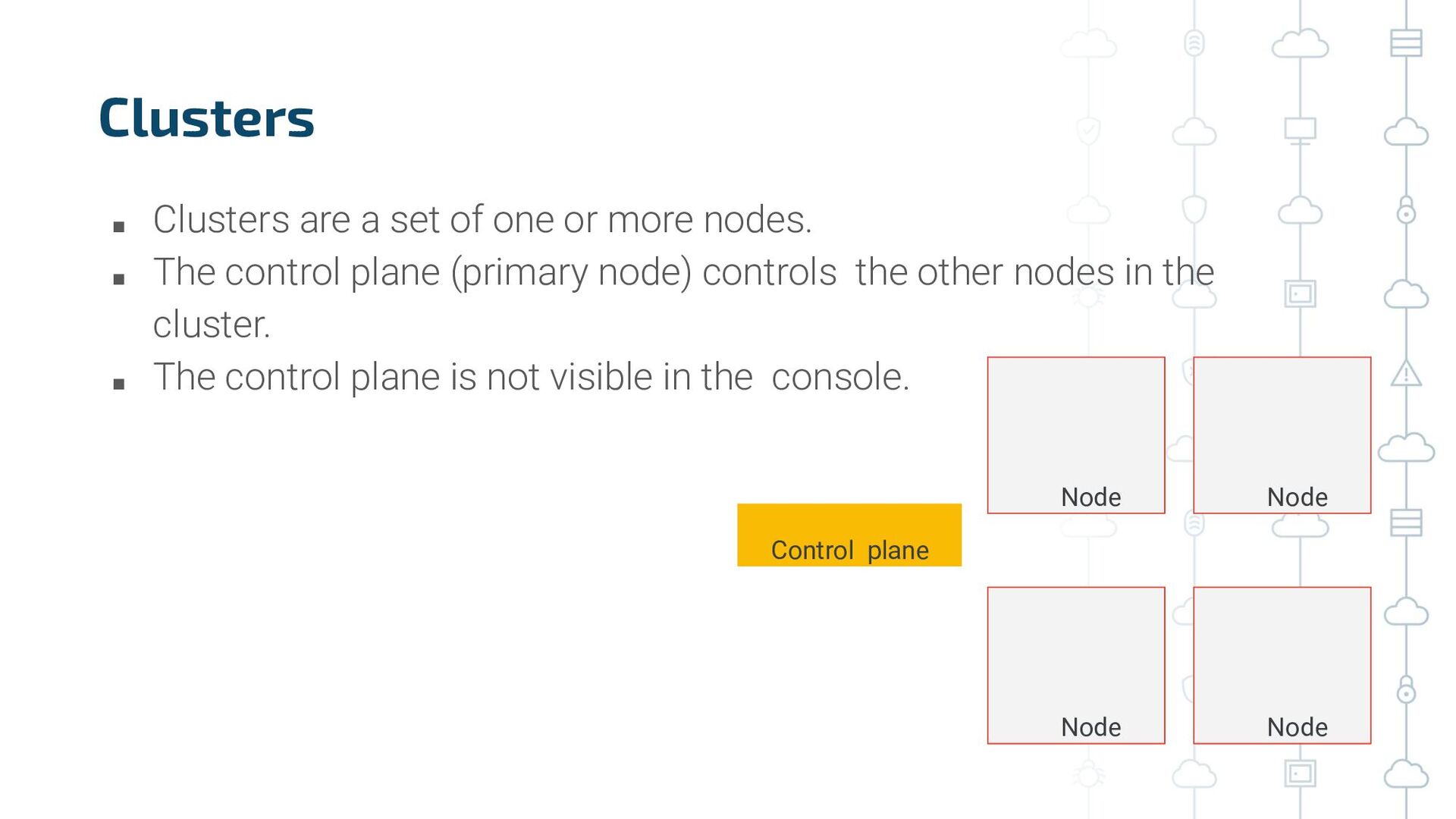{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
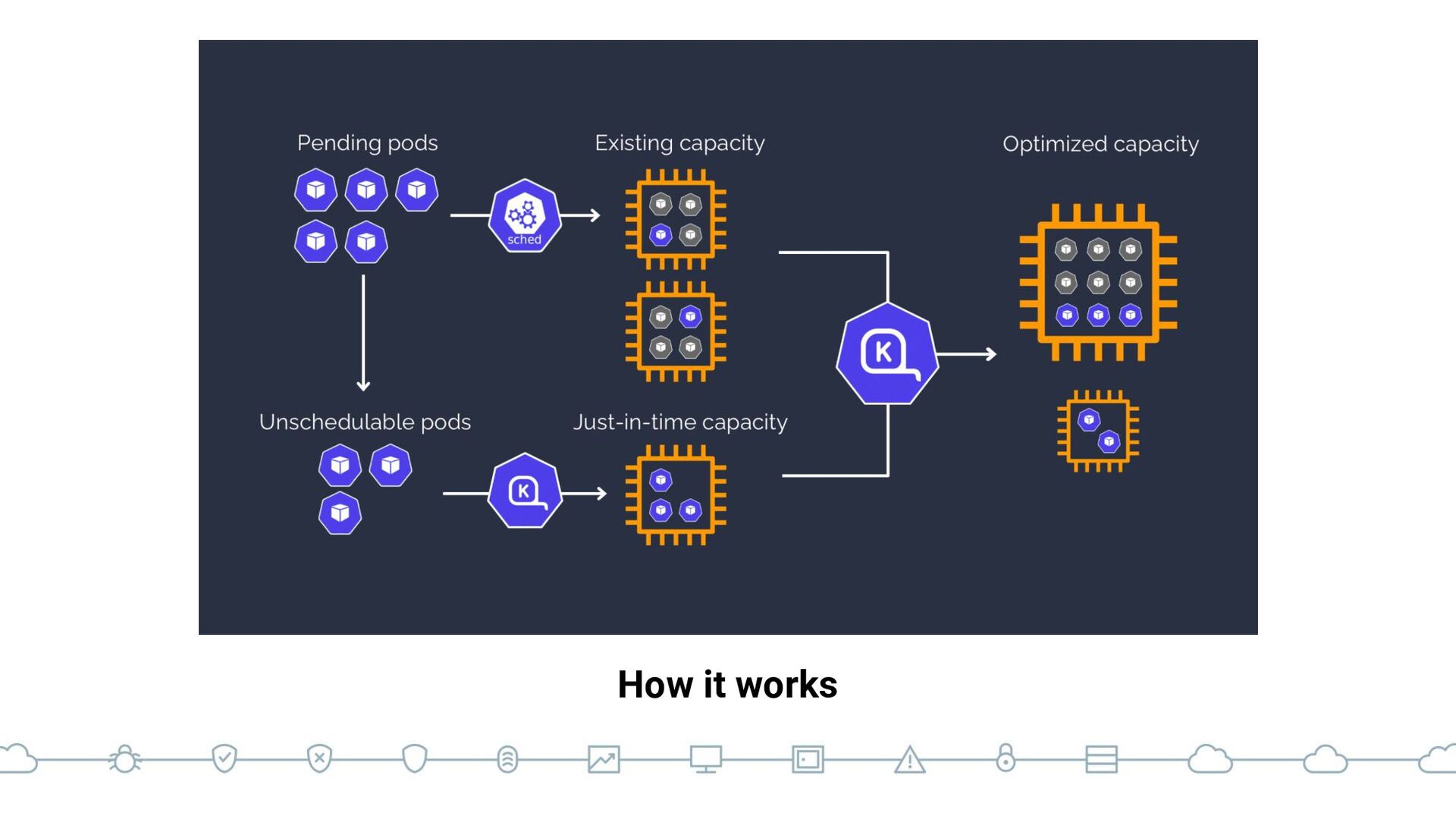{kind=link}
{kind=link}
{kind=link}
{kind=link}