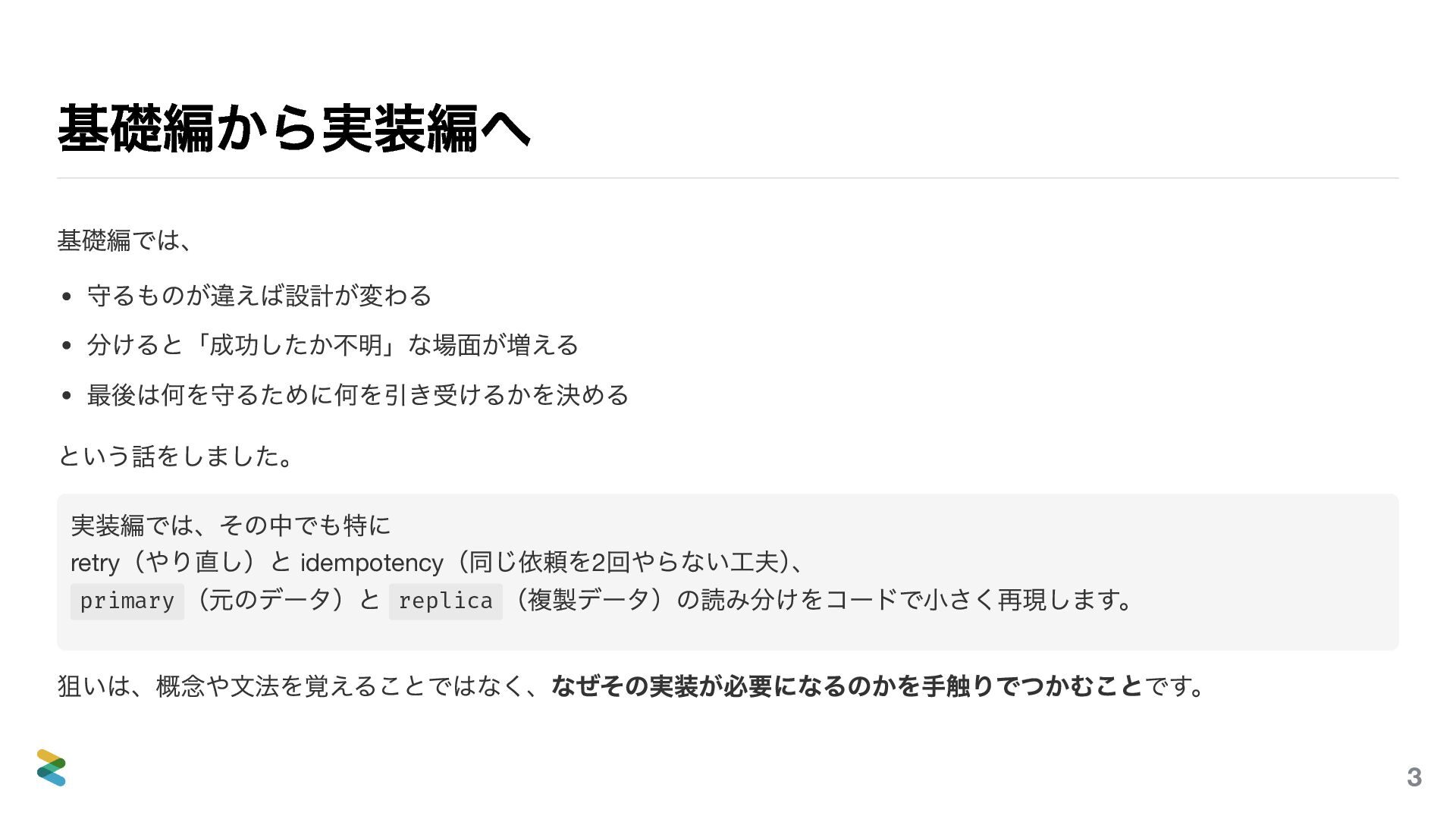
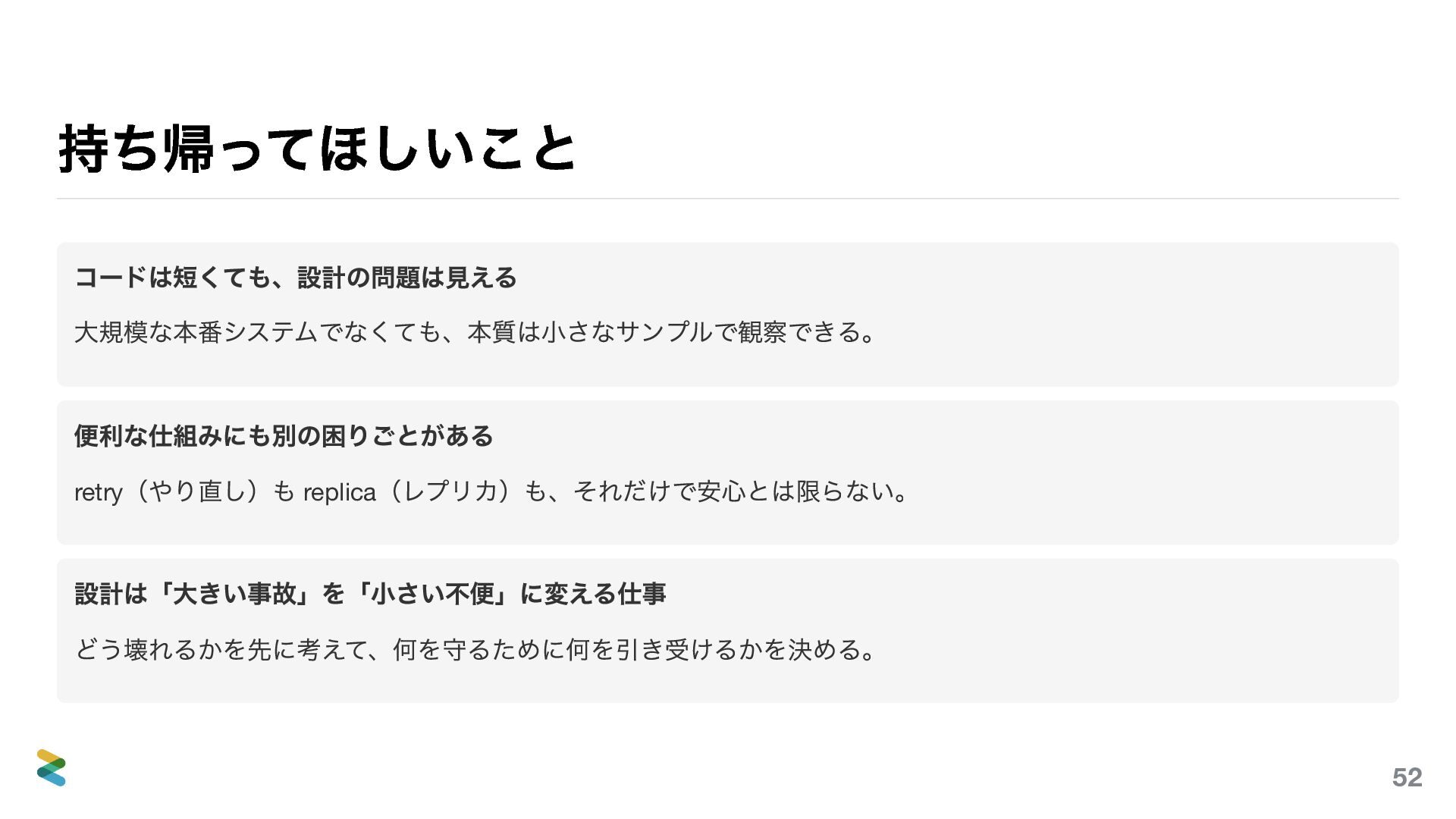
前作では「何を守るかを決める」という視点から、非機能要件・分散システム・トレードオフの考え方を紹介しました。「面白そうだけど、実際のコードはどうなっているの?」——この続編はその問いへの答えです。
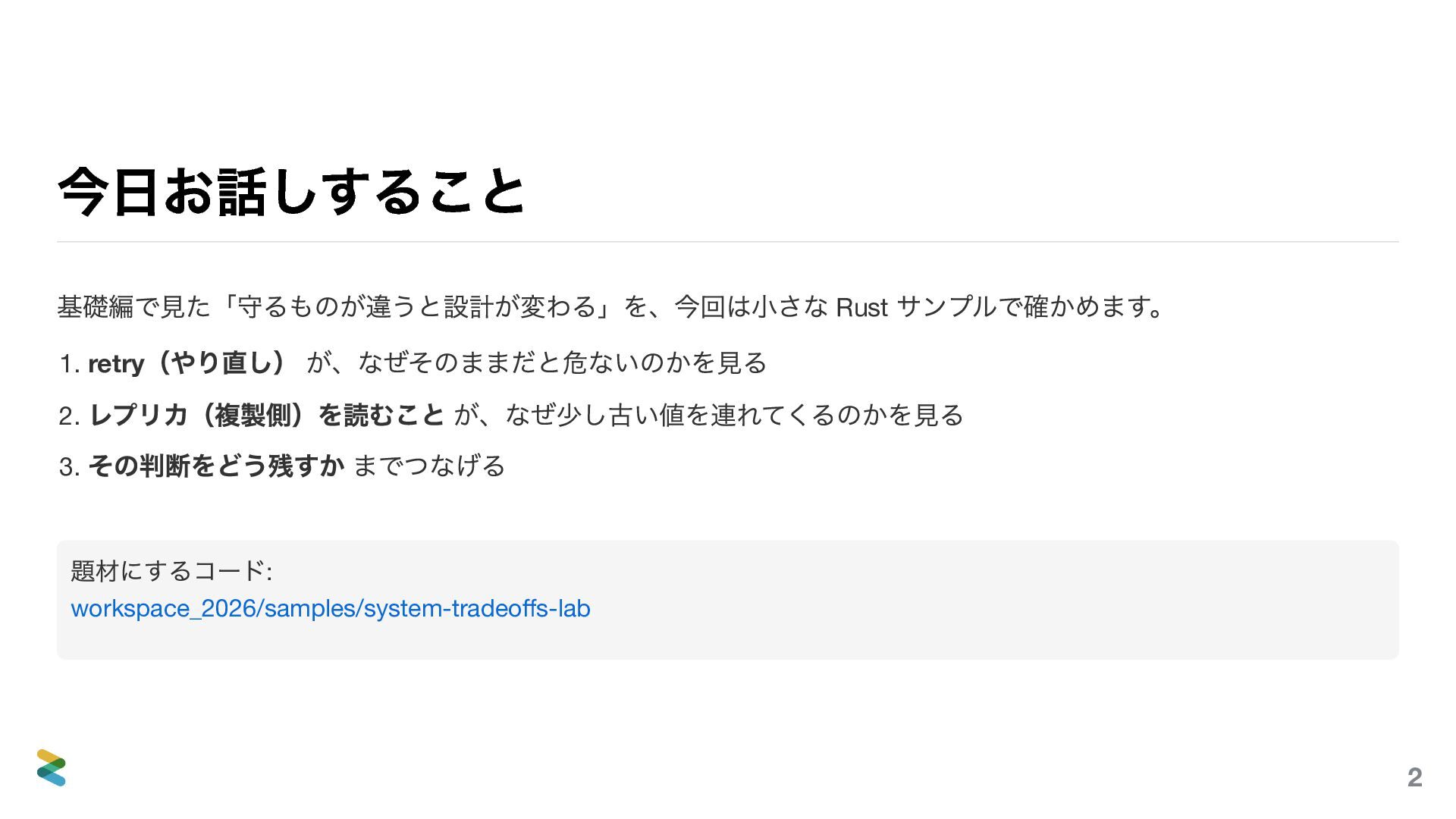
概念として語っていたことを、今度はコードの上で見ていきます。リトライはどう書くか。タイムアウトをどこに置くか。冪等性はどう担保するか。「なんとなく知っている」を「動くコードで理解している」に変えることを目指した発表です。
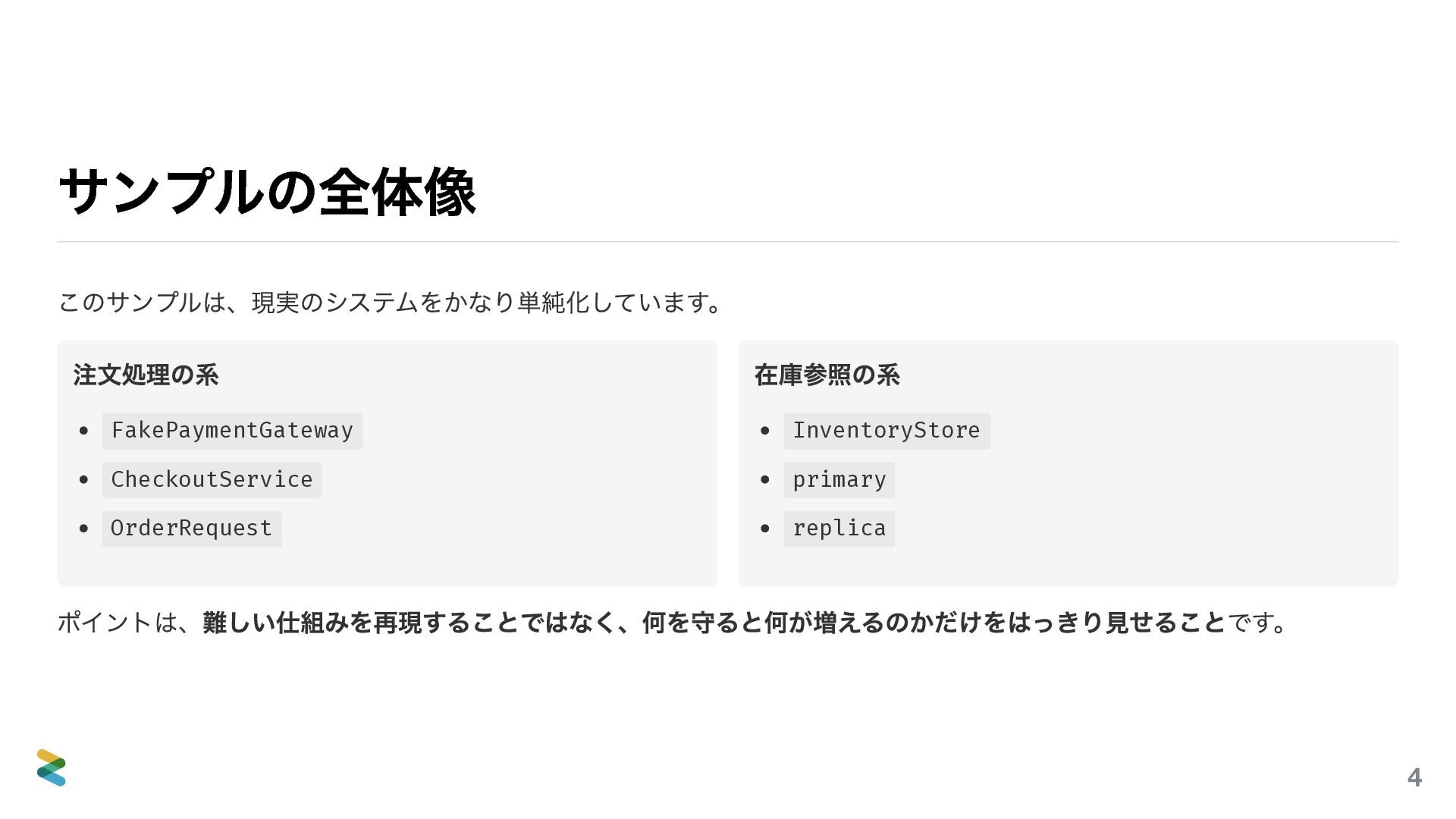
ただし、コードを読む会ではありません。一行一行を追うのではなく、「なぜそう書くのか」「何を諦めて何を得ているのか」に焦点を当てます。設計の判断はコードに刻まれている——その読み方を一緒に考えます。
前作を見ていなくても楽しめますが、見ていると2倍楽しめます。知らんけど。そして今作も、20分で終わらせるのはとても難しい。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
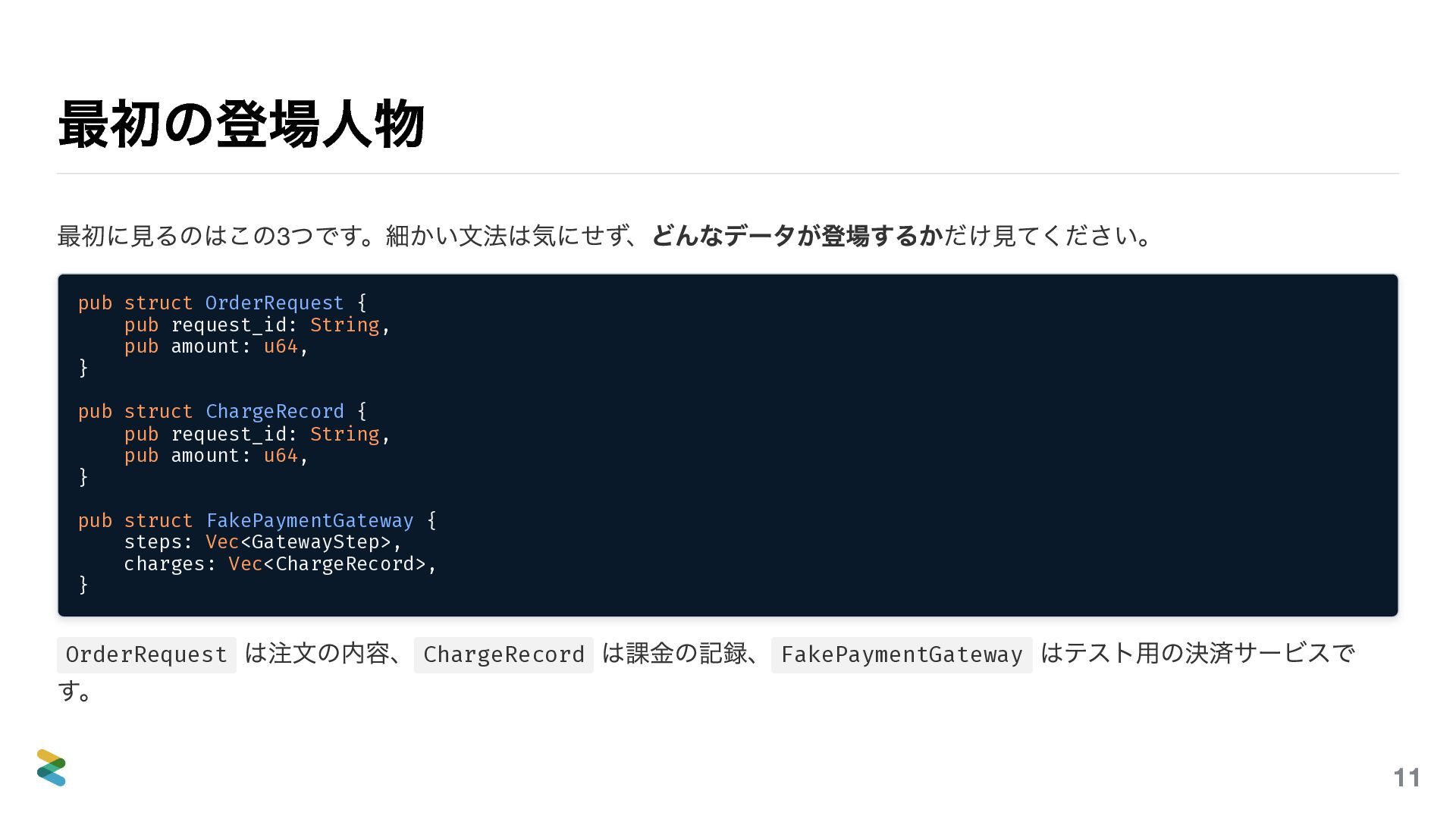{kind=link}
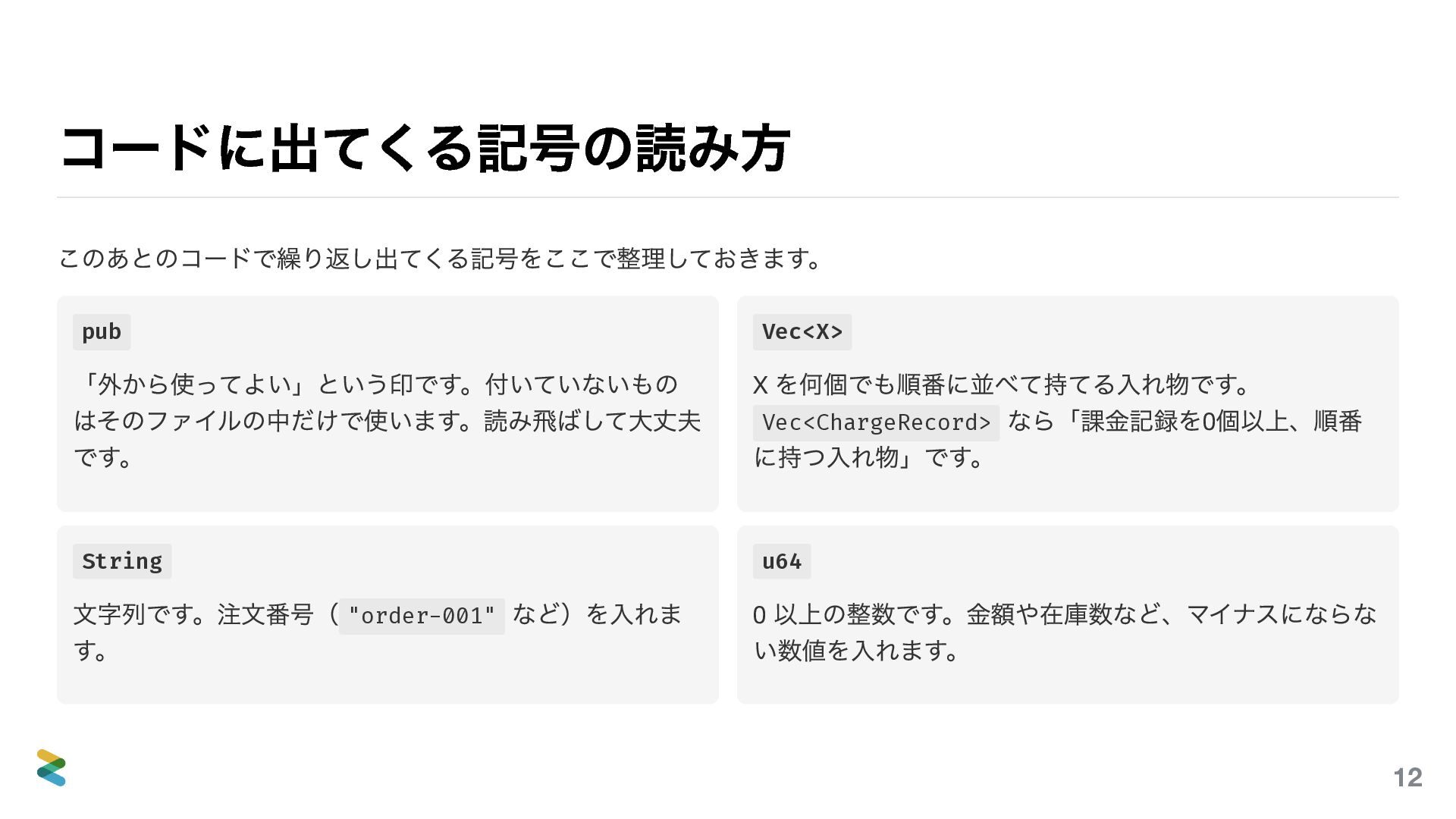{kind=link}
{kind=link}
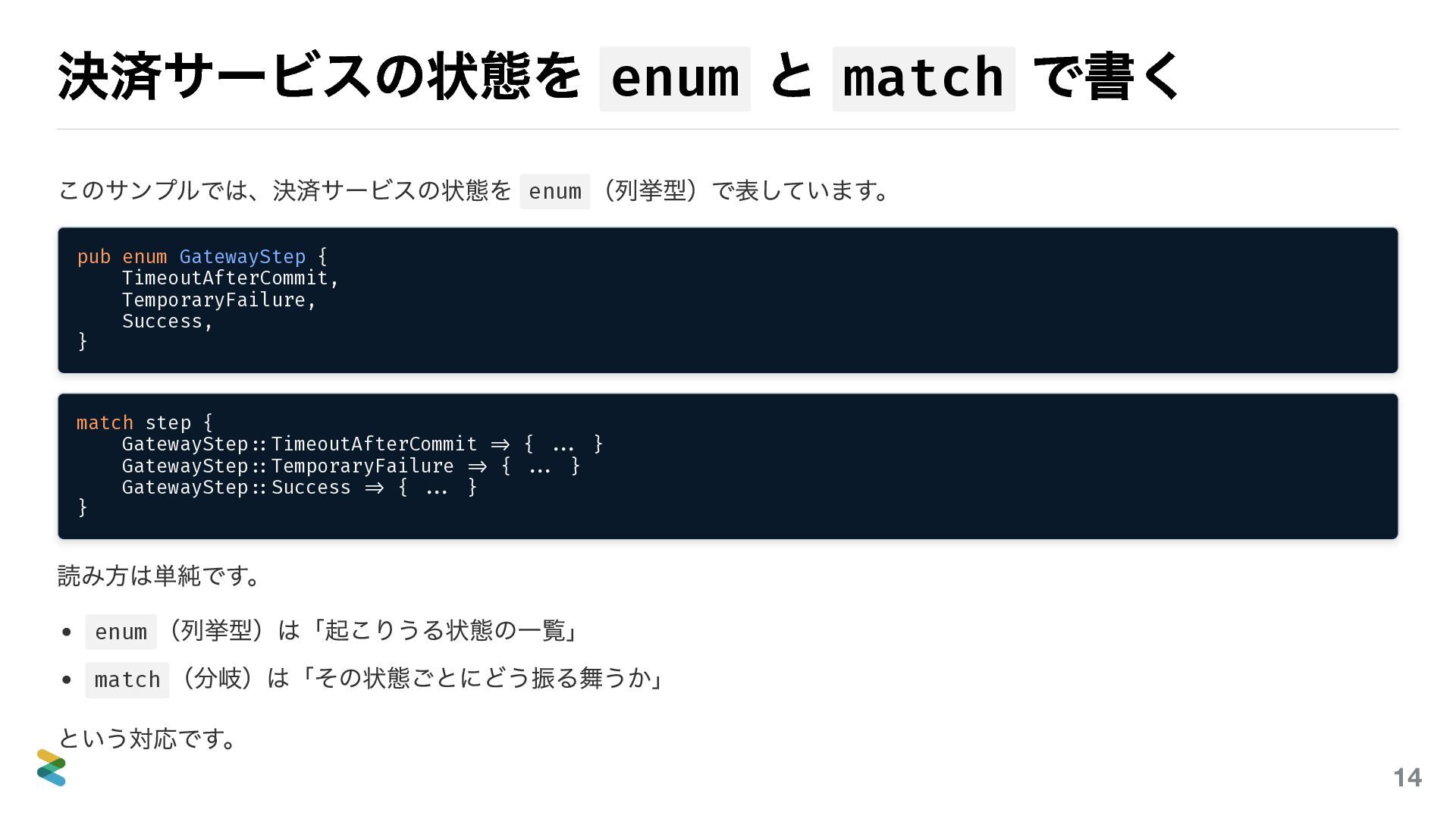{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
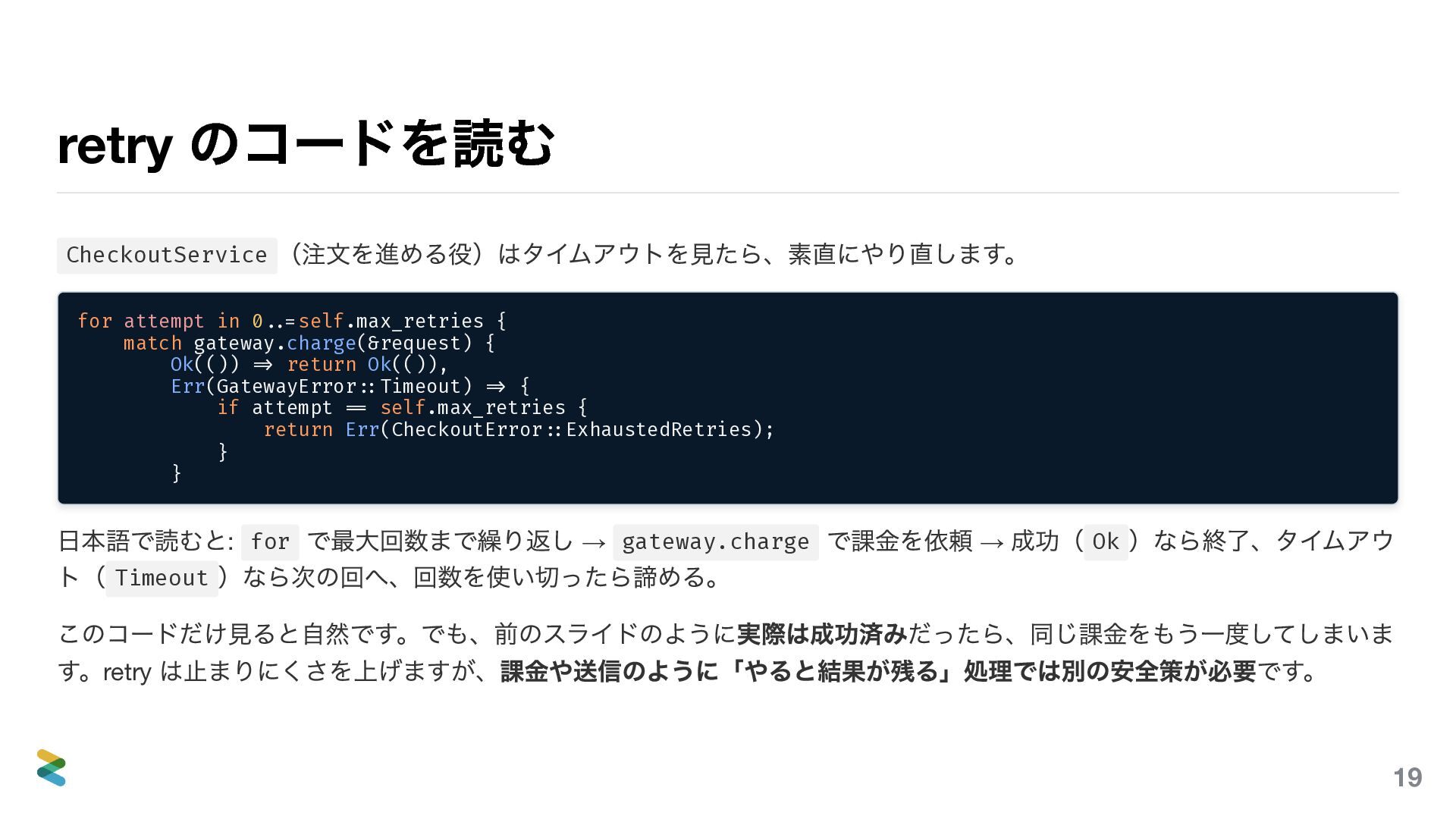{kind=link}
{kind=link}
{kind=link}
{kind=link}
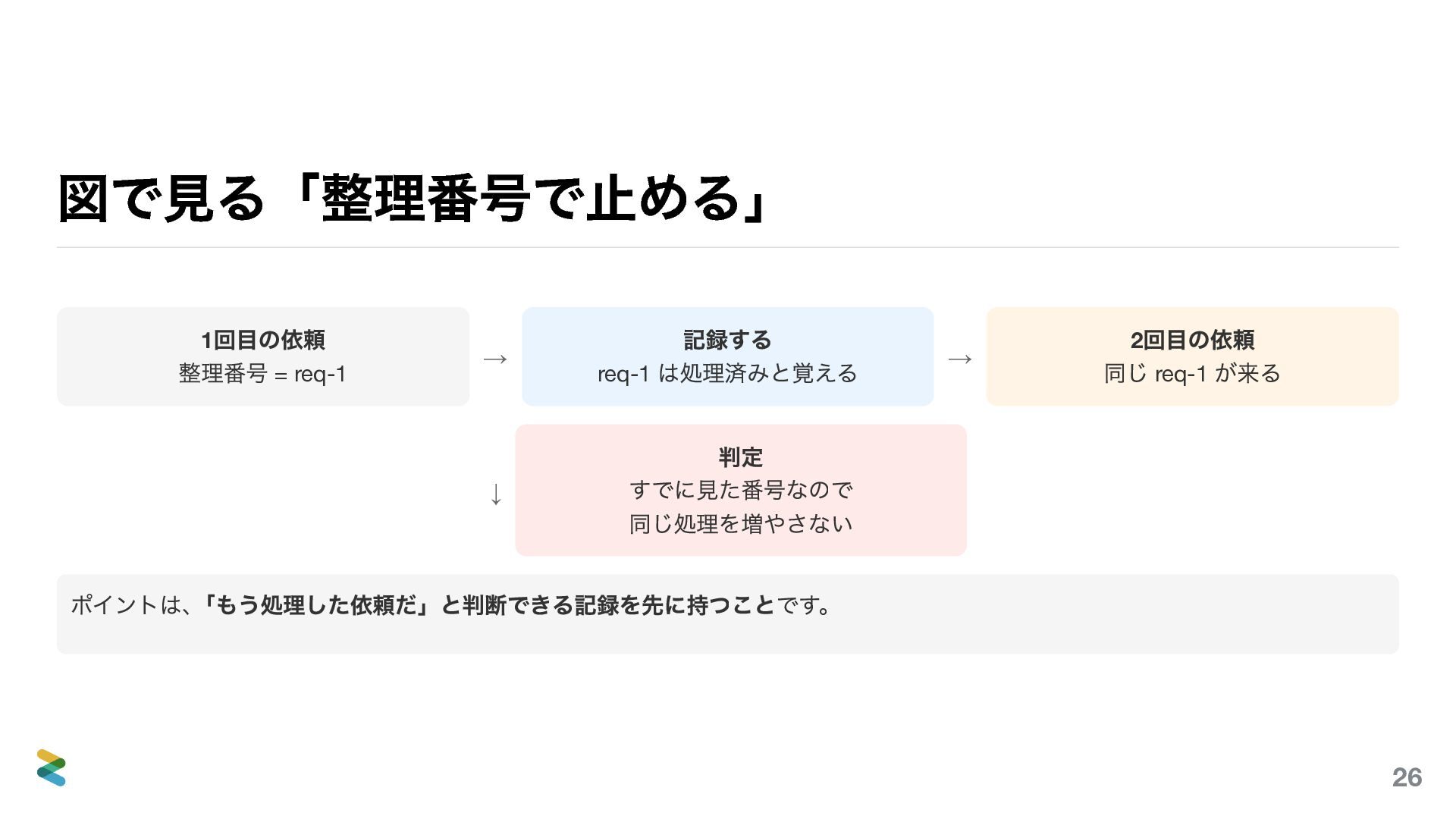
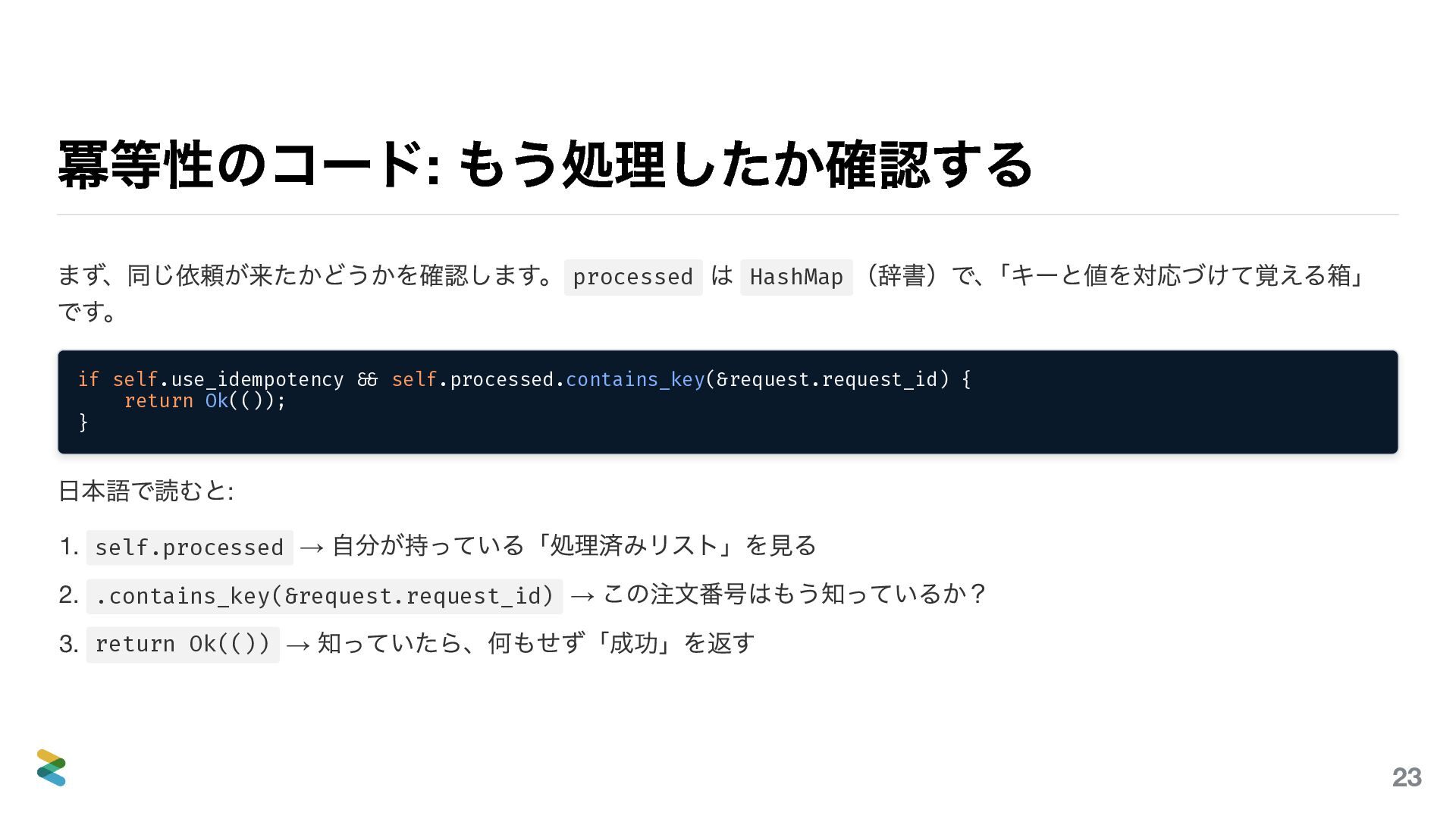{kind=link}
{kind=link}
{kind=link}
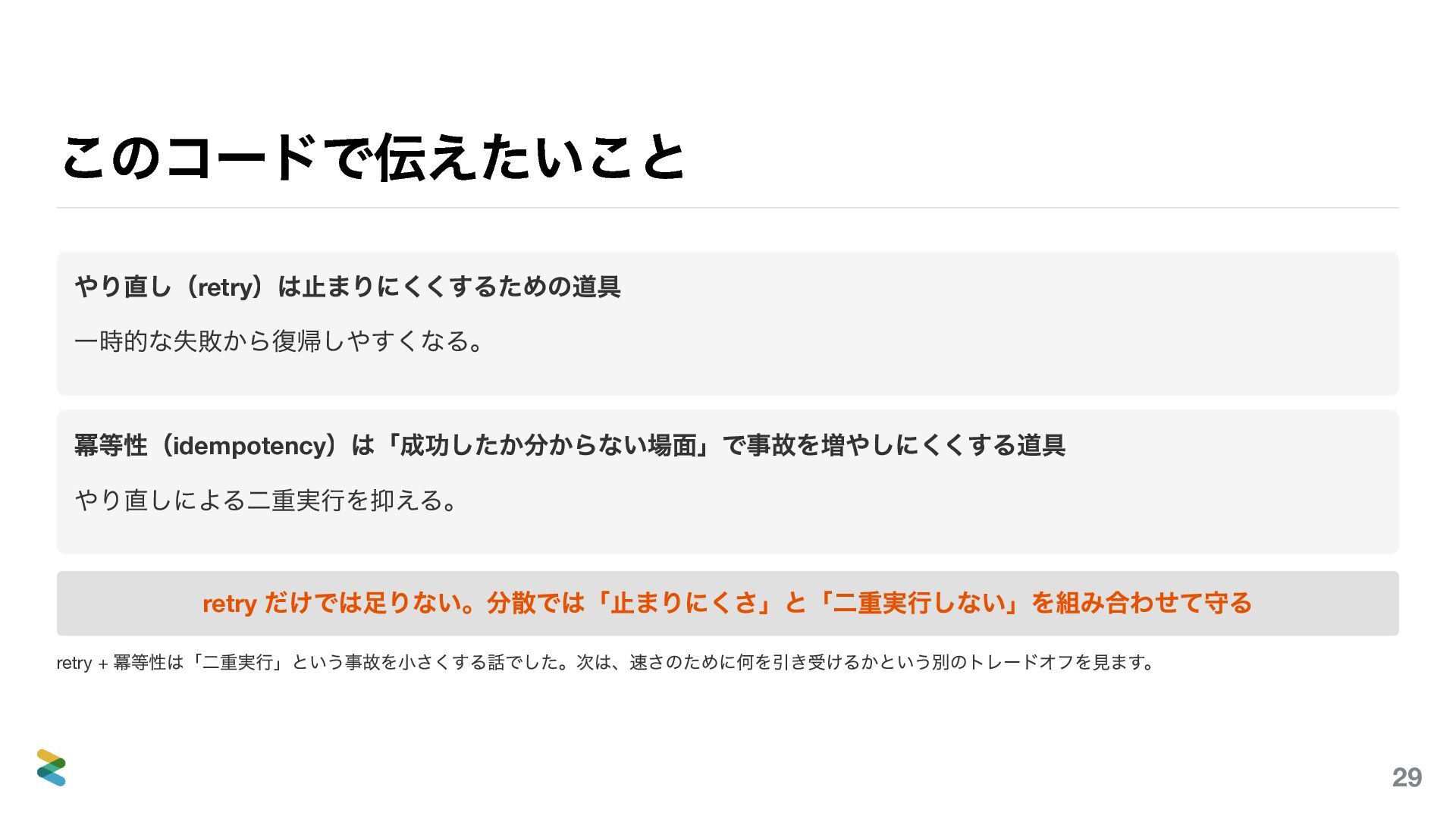
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
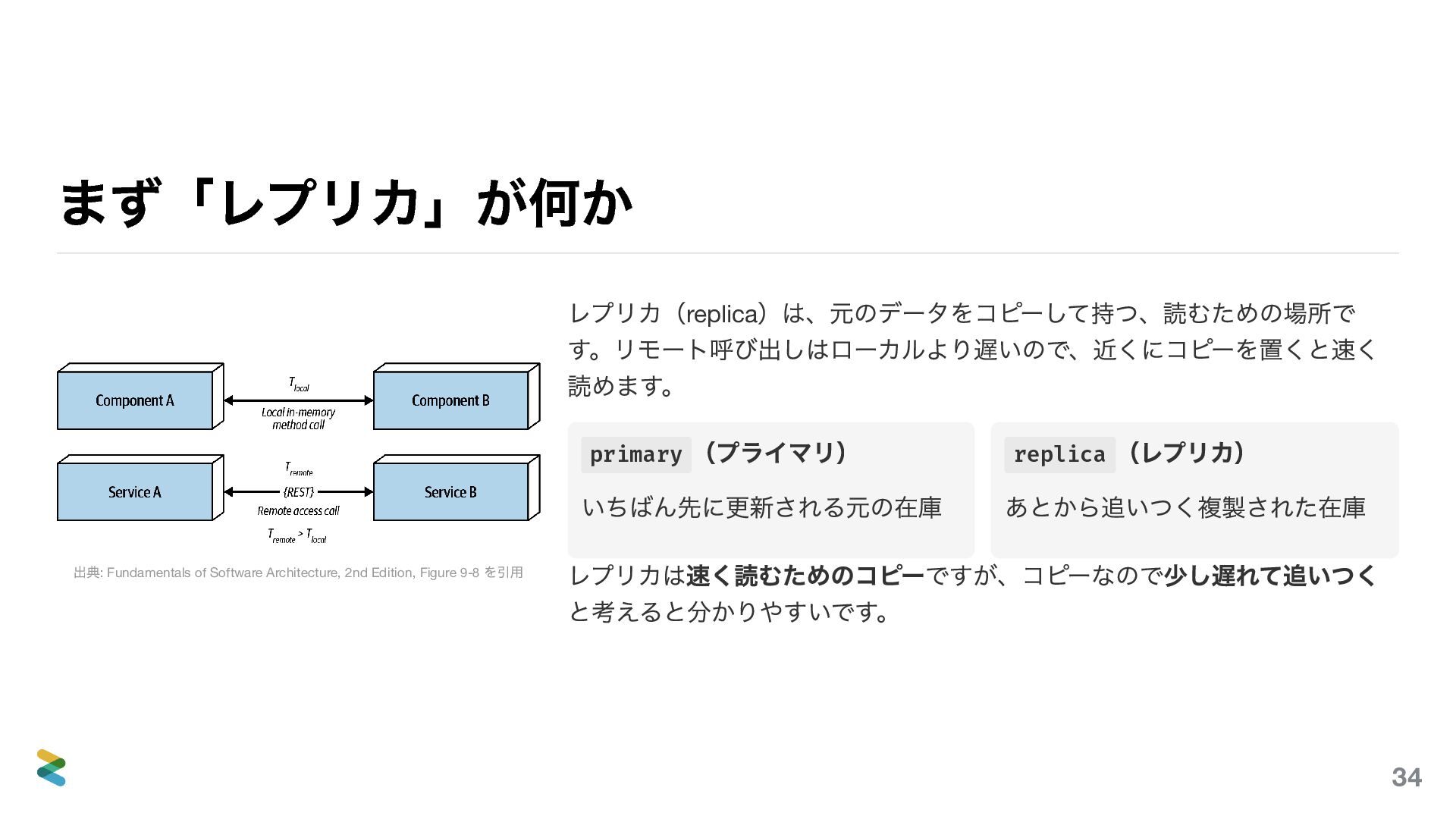{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}