Share
2025年9月10日(水)、「Rustの現場に学ぶ〜Webアプリの裏側からOS、人工衛星まで〜」というイベントで登壇させていただきます。
https://findy.connpass.com/event/359456/
他の登壇者の話が聞きたすぎるけど調整能力の圧倒的な不足で登壇したらすぐに帰らなければなりません。
今回の発表内容のベースとなったのはこちらのブログです。 - 「RustのWebアプリケーションにオブザーバビリティを実装するインフラエンジニアのための入門ガイド」
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
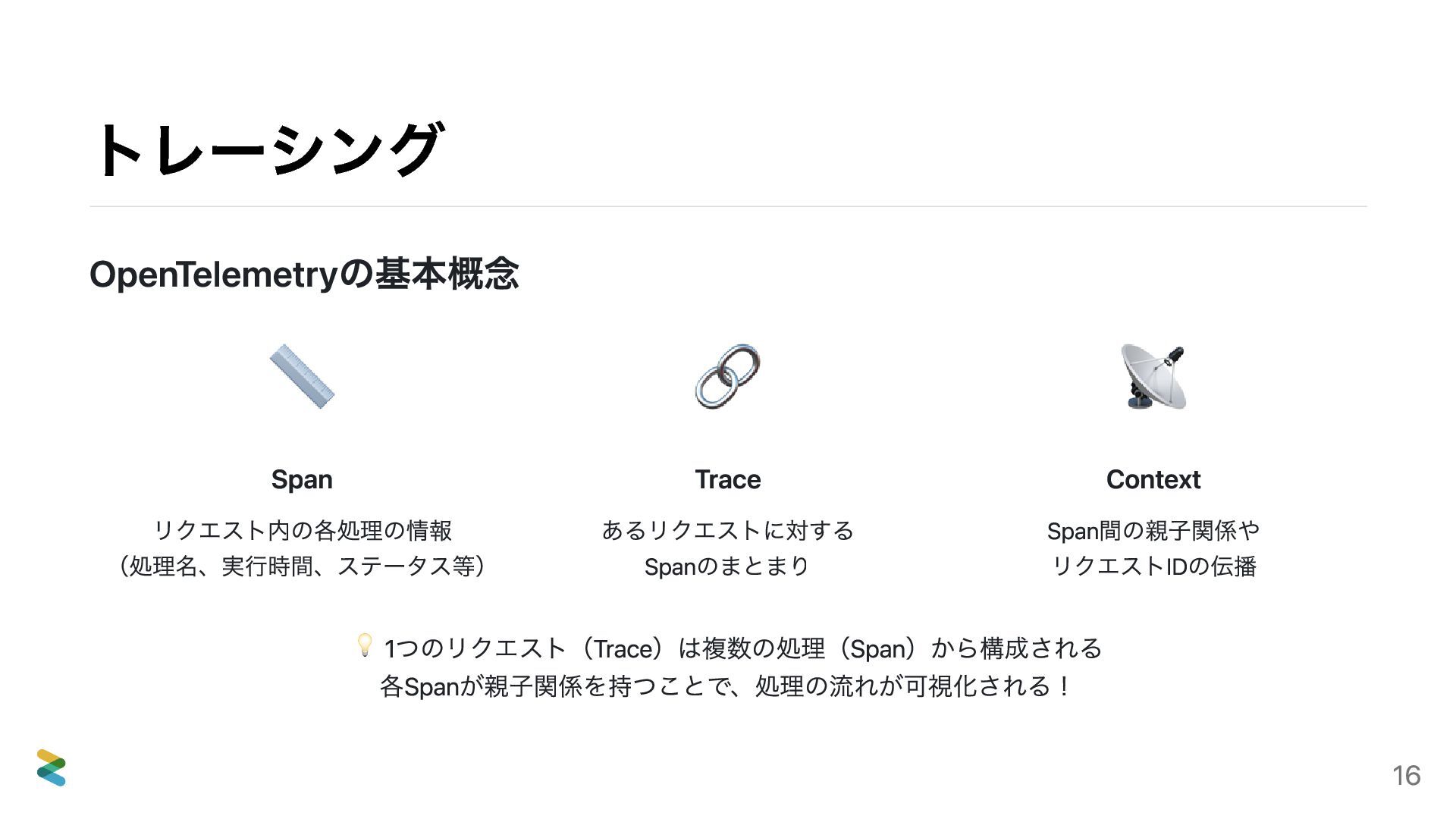{kind=link}
![なぜトレーシングが必要なのか 並行処理とマイクロサービスの複雑性に対処 従来のログの問題点 // 複数のリクエストが同時に処理されると... [2025-01-28 10:00:01] INFO: リクエスト開始 [2025-01-28](https://files.speakerdeck.com/presentations/97afaccdc78b428a95f7132e517ac034/slide_16.jpg){kind=link}
{kind=link}
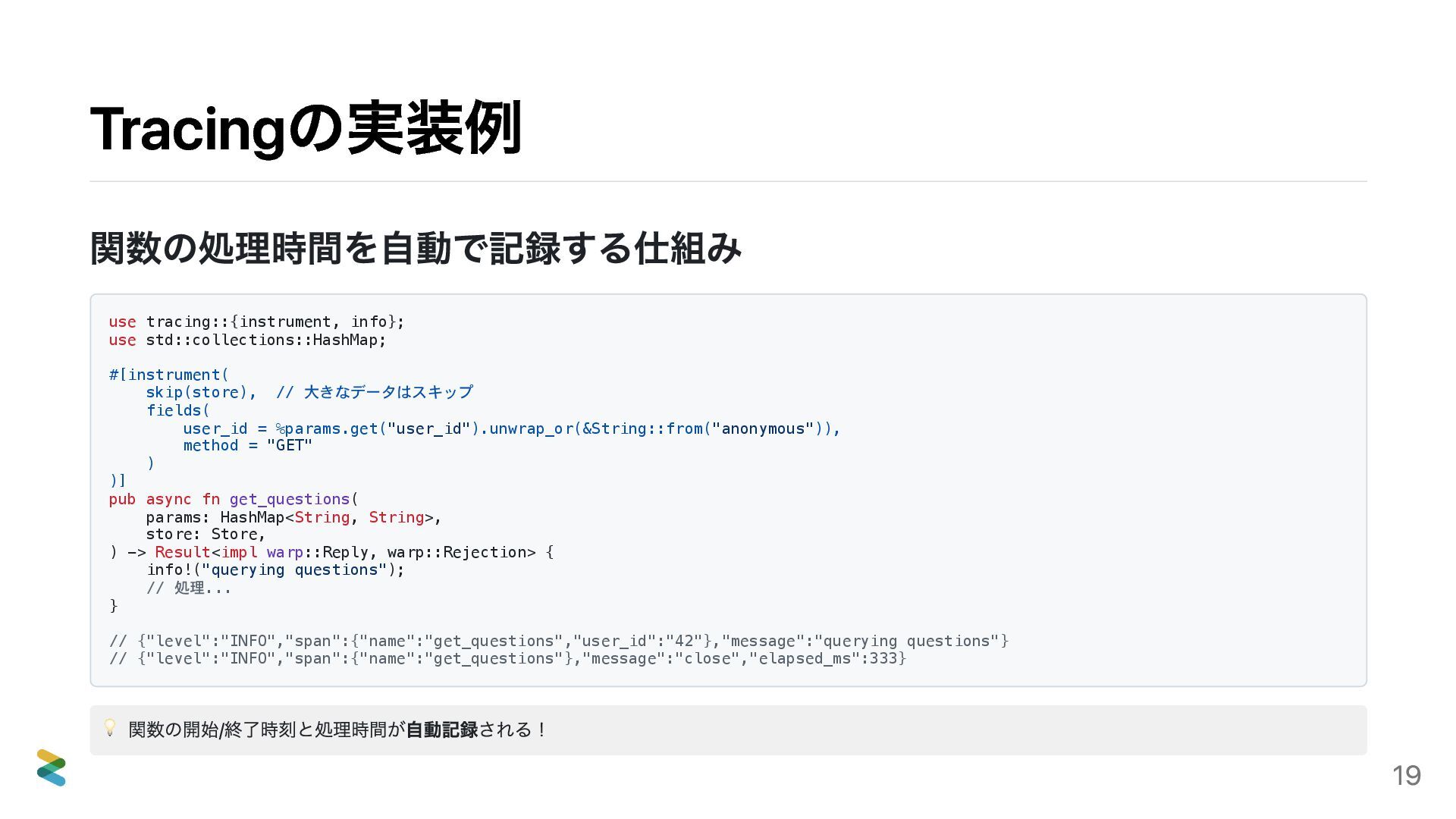{kind=link}
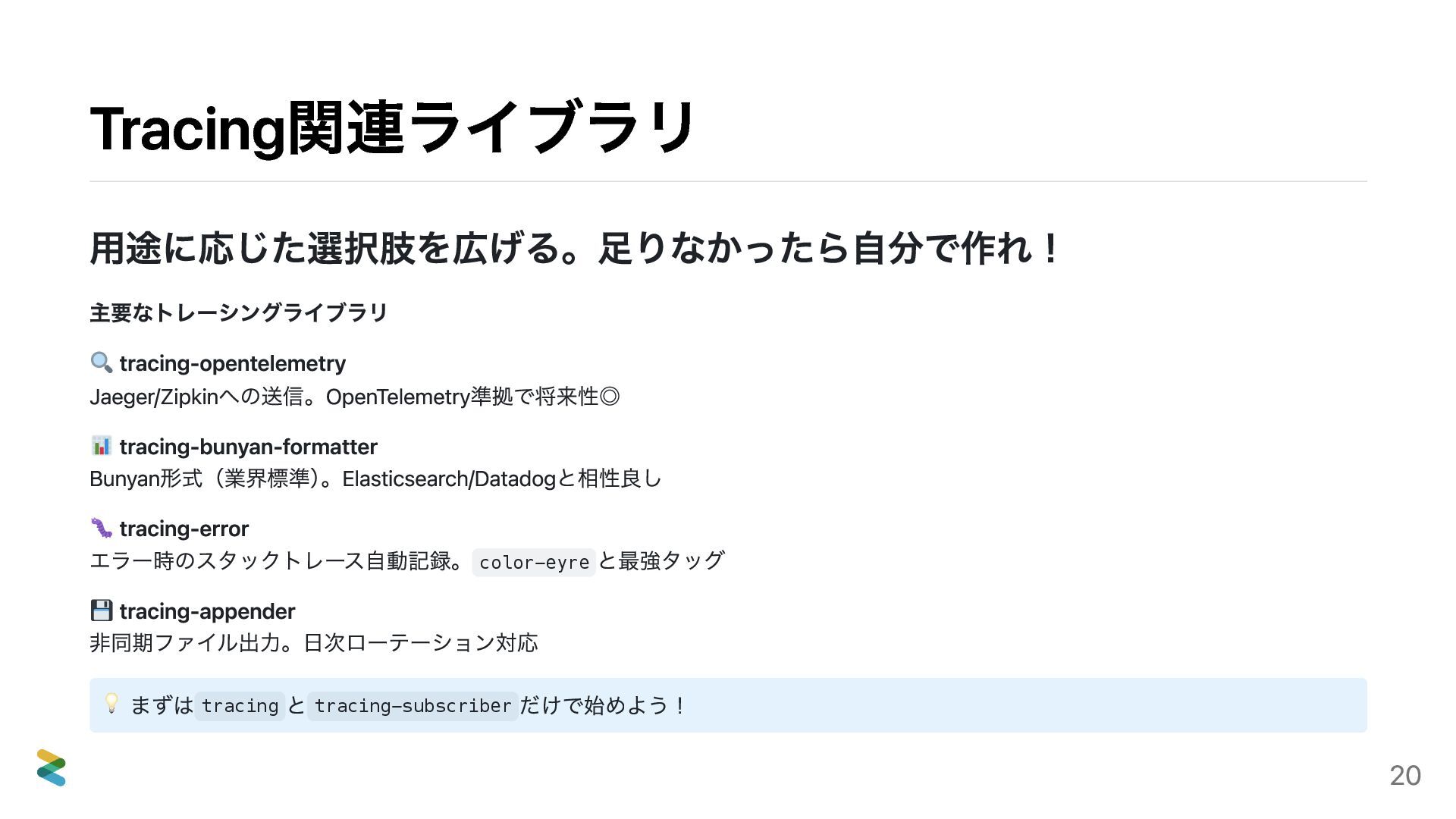{kind=link}
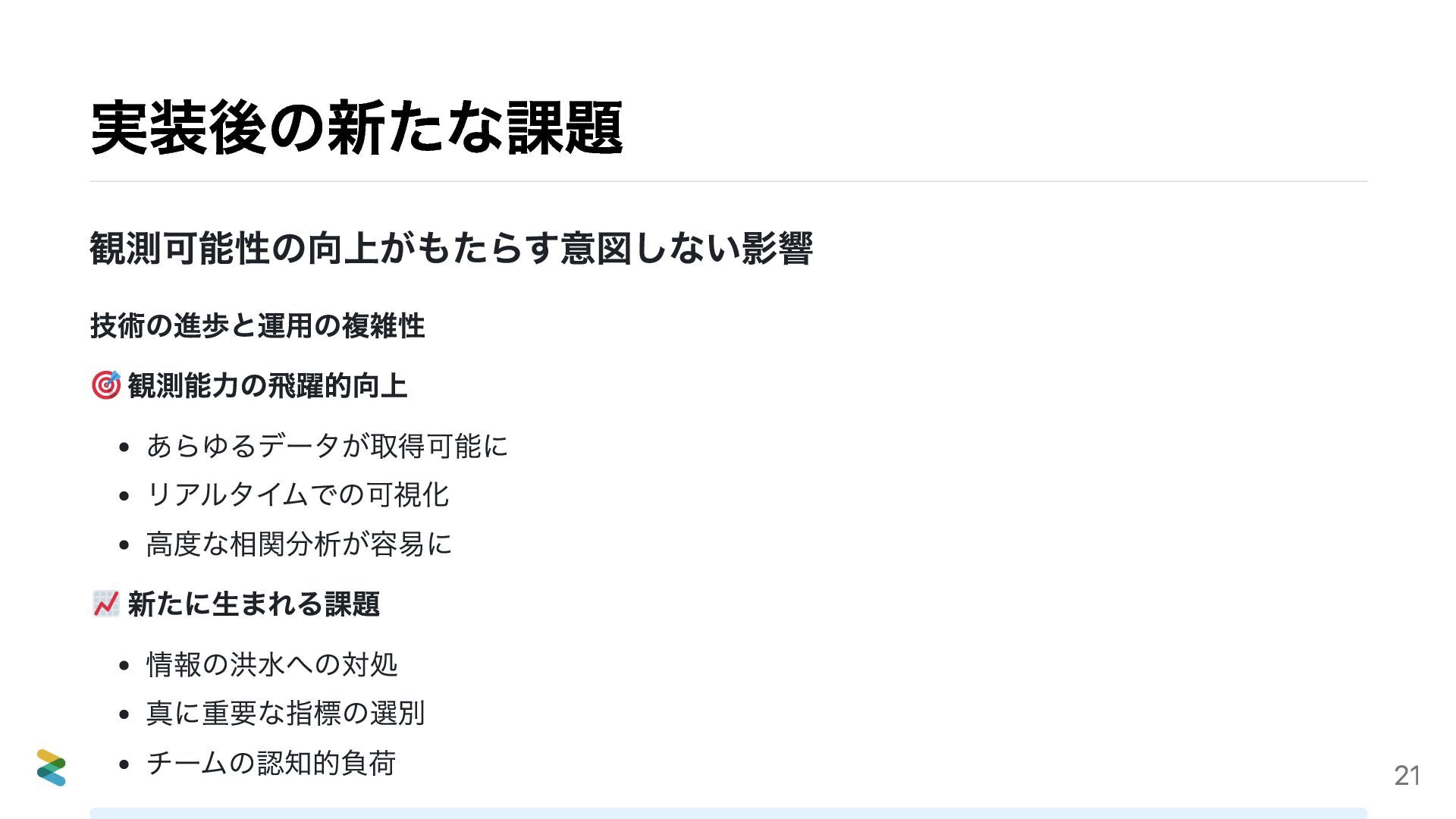{kind=link}
{kind=link}
{kind=link}
![まとめ 1. Rustでオブザーバビリティを始める ログ・メトリクス・トレーシングの三本柱で内部状態を理解 tracing クレートで簡単に開始、 #[instrument] で自動計測 まずは tracing](https://files.speakerdeck.com/presentations/97afaccdc78b428a95f7132e517ac034/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}