Systems architect Michael Laing gave this presentation at FOSDEM 2014
Cassandra provides the global persistence layer for the New York Times nyt⨍aбrik project. This presentation focuses on the use of Cassandra as the high performance distributed data store supporting the nyt⨍aбrik.
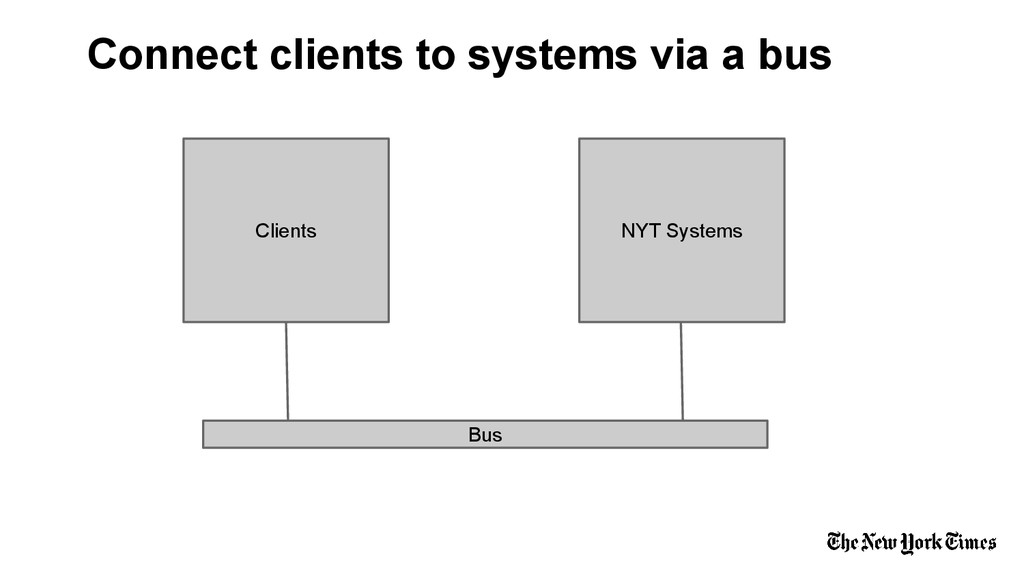
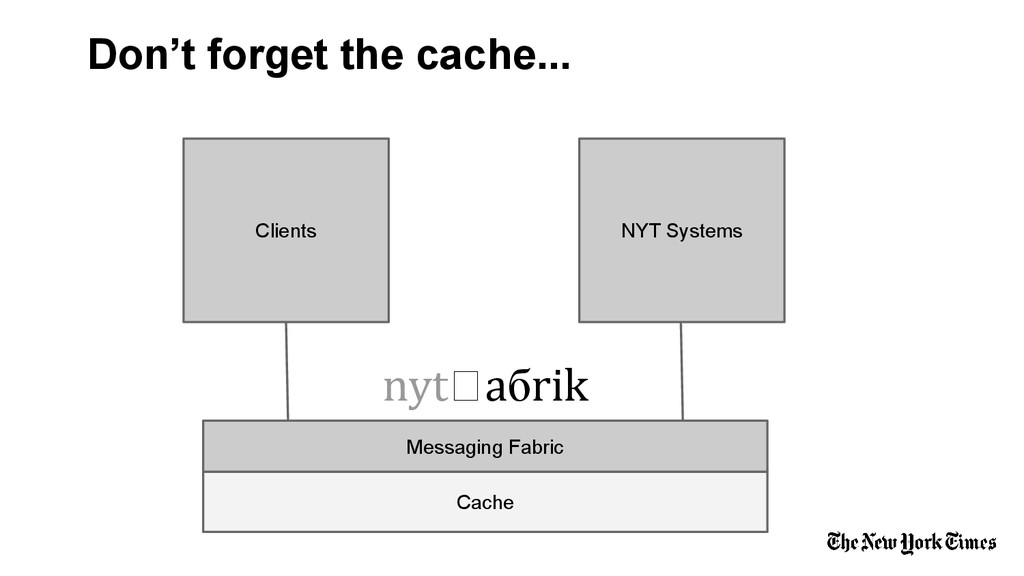
nyt⨍aбrik (in production January 2014) is reliable, low latency messaging middleware connecting internal clients at the New York Times (breaking news, user generated content, etc) with millions of external clients around the world. The primary technologies employed are: RabbitMQ (AMQP), Cassandra, and websockets/sockjs. Components developed by the New York TImes will be made open source beginning in 2014.
{kind=link}
{kind=link}
![Me Systems Architect NYTimes [email protected]](https://files.speakerdeck.com/presentations/9f51ce10e2a4013146e77681cc07b3ff/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}