sample. • : negative sample. It can be a set of samples . K + 1 x x− {x− k }K k=1 Contrastive unsupervised representation learning 3 Anchor x Negative x− k
, we draw and apply two data augmentations . • For negative image , we draw and apply single data augmentation . x a, a+ x− a− Contrastive unsupervised representation learning 4 Anchor x Negative x− k a+ a− k a
representations . • : a similarity function, such as a dot product or cosine similarity. Lcon z, z+, z− k sim( . ⋅ . ) Contrastive unsupervised representation learning 6 Anchor x Negative x− k a a+ a− k f z z− k z+ } : Make similar. : Make dissimilar. z, z+ z, z− contrastive loss [1]: Lcon −ln exp[sim(z, z+)] exp[sim(z, z+)] + ∑K k=1 exp[sim(z, z− k )]
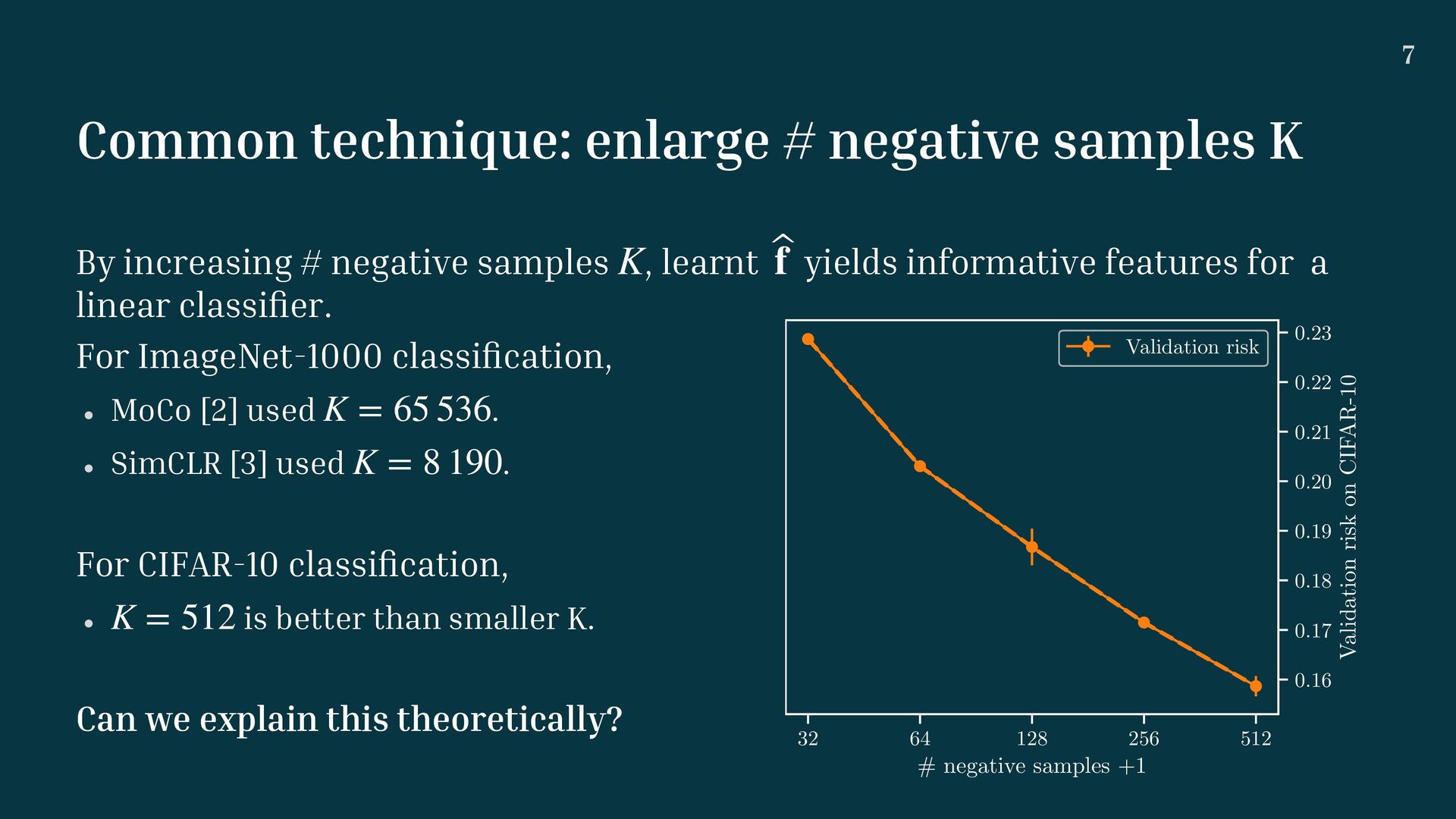
# negative samples , learnt yields informative features for a linear classi fi er. For ImageNet-1000 classi fi cation, w MoCo [2] used . w SimCLR [3] used . For CIFAR-10 classi fi cation, w is better than smaller K. Can we explain this theoretically? K ̂ f K = 65 536 K = 8 190 K = 512 32 64 128 256 512 # negative samples +1 0.16 0.17 0.18 0.19 0.20 0.21 0.22 0.23 Validation risk on CIFAR-10 Validation risk
modi fi ed for our setting: , . • : Supervised loss with feature encoder . • : Collision probability represents whether the anchor’s label is also in negatives' ones or not. Note: the original bound is for a meta-learning-ish loss rather than a single supervised loss. Lsup (f) ≤ 1 1 − τK (Lcon (f) + 𝒪 (f, K)) ∀f ∈ ℱ Lsup (f) f τK [4] Arora et al. A Theoretical Analysis of Contrastive Unsupervised Representation Learning, In ICML, 2019.
necessary to draw various classes to solve the downstream task. • Ex: if we solve the ImageNet-1000 classi fi cation as a downstream task, in the contrastive task. • Use Coupon collector’s problem [5]’s probability that represents whether drawn samples’ labels include all supervised classes or not. K K + 1 ≥ 1 000 υK+1 K + 1
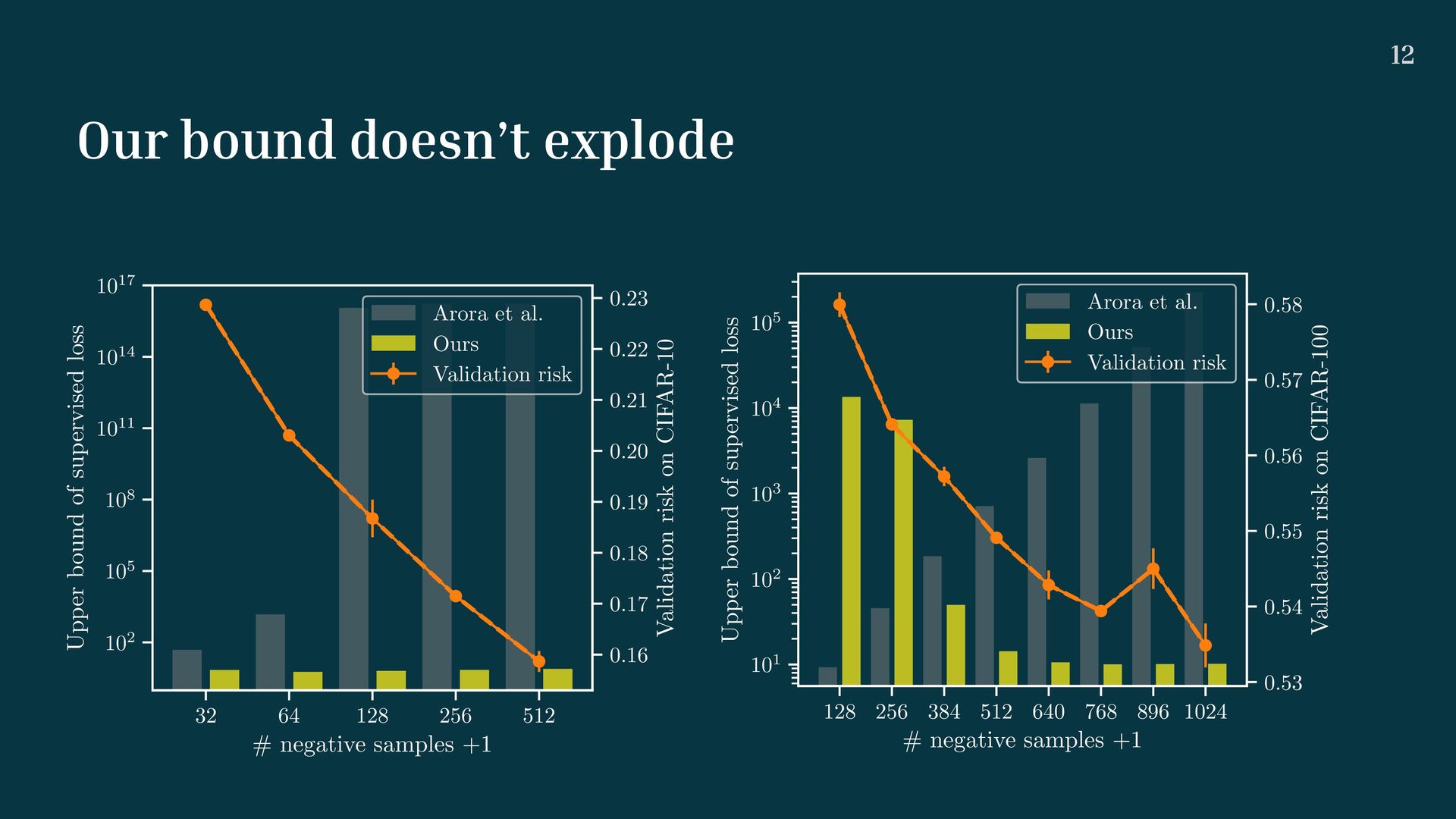
cient of converges 1 when increases. • Additional insight from : the expected to sample all supervised labels from ImageNet-1000 is about . • Recall that in MoCo and in SimCLR. Lsup (f) ≤ 1 υK+1 (2Lcon (f) + 𝒪 (f, K)) ∀f ∈ ℱ 1/υK+1 Lcon K υK+1 K + 1 7 700 K = 65 536 K = 8 190 Proposed upper bound of supervised loss 11
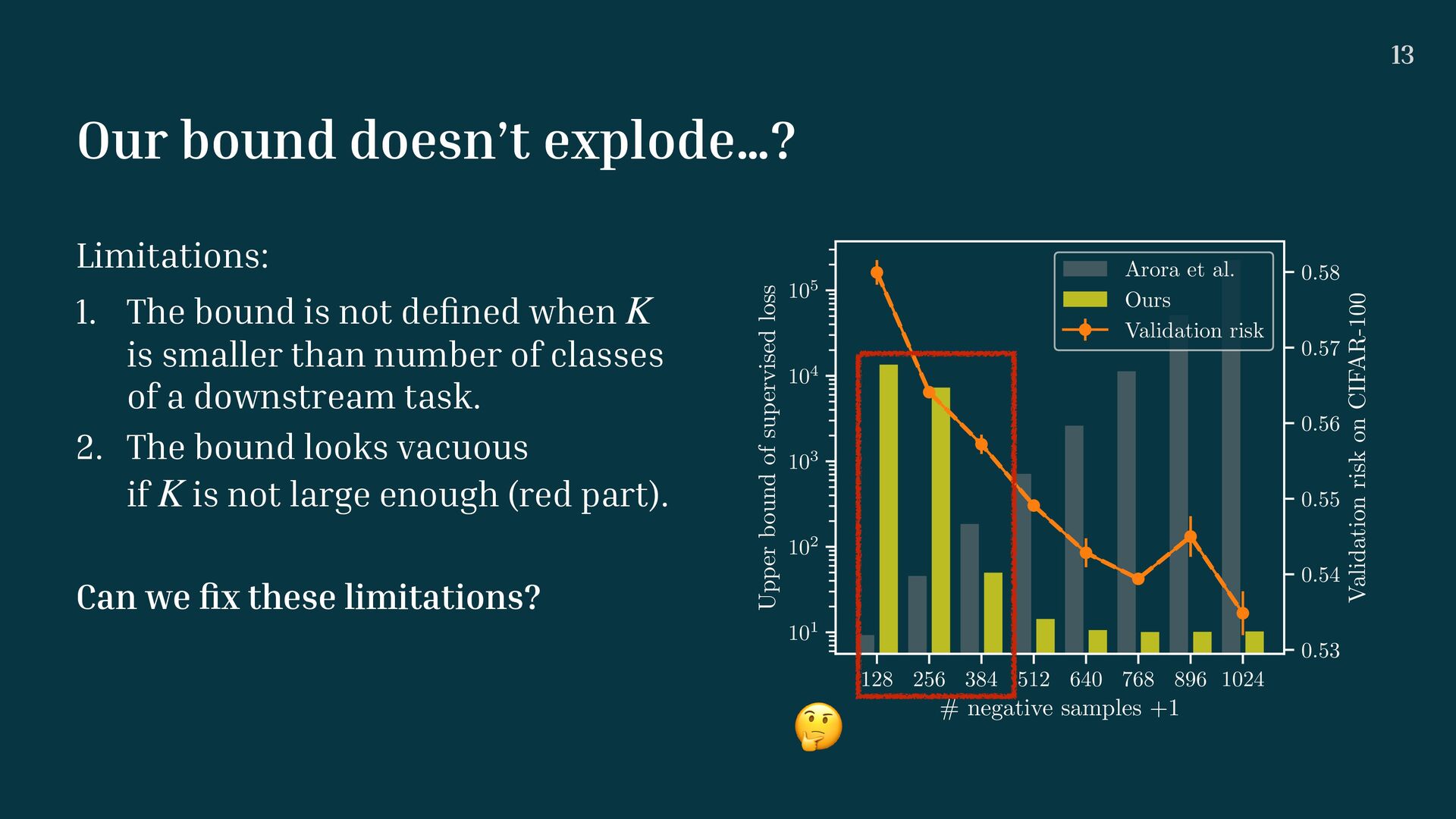
768 896 1024 # negative samples +1 101 102 103 104 105 Upper bound of supervised loss Arora et al. Ours Validation risk 0.53 0.54 0.55 0.56 0.57 0.58 Validation risk on CIFAR-100 🤔 Limitations: 1. The bound is not de fi ned when is smaller than number of classes of a downstream task. 2. The bound looks vacuous if is not large enough (red part). Can we fi x these limitations? K K
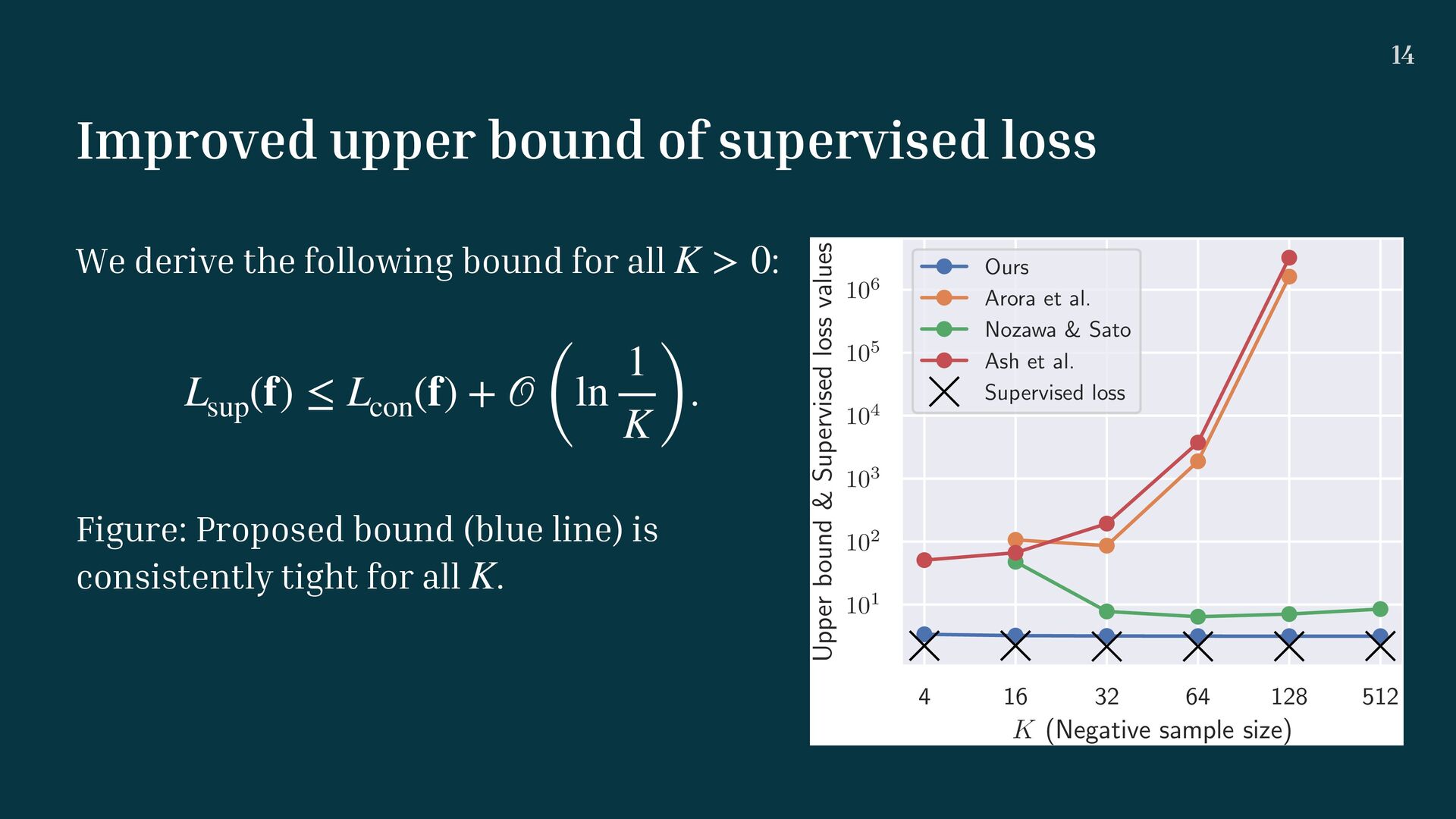
following bound for all : . Figure: Proposed bound (blue line) is consistently tight for all . K > 0 Lsup (f) ≤ Lcon (f) + 𝒪 (ln 1 K ) K 4 16 32 64 128 512 K (Negative sample size) 101 102 103 104 105 106 Upper bound & Supervised loss values Ours Arora et al. Nozawa & Sato Ash et al. Supervised loss
learning. • Practice: Large negative sample size doesn’t hurt classi fi cation performance. • Theory: large hurts classi fi cation performance. • We proposed • The new bound using Coupon collector’s problem with smaller limitation. • Much tighter upper bound for all > 0. • More recent topic from Prof. Arora’s group • Saunshi et al., “Understanding Contrastive Learning Requires Incorporating Inductive Biases”, In ICML, 2022. K K K K
Predictive Coding”, arXiv, 2018 2. He et al., “Momentum Contrast for Unsupervised Visual Representation Learning”, In CVPR, 2020. 3. Chen et al., “A Simple Framework for Contrastive Learning of Visual Representations”, In ICML, 2020. 4. Arora et al., “A Theoretical Analysis of Contrastive Unsupervised Representation Learning”, In ICML, 2019. 5. Nakata & Kubo. “A Coupon Collector’s Problem with Bonuses”. In Fourth Colloquium on Mathematics and Computer Science, 2006.
Negative Samples in Instance Discriminative Self-supervised Representation Learning. In NeurIPS, 2021. • Han Bao, Yoshihiro Nagano and Kento Nozawa. On the Surrogate Gap between Contrastive and Supervised Losses. In ICML, 2022. • Bonus (another extension of Arora et al. 2019) • Kento Nozawa, Pascal Germain and Benjamin Guedj. PAC-Bayesian Contrastive Unsupervised Representation Learning. In UAI, 2020.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![exp[sim(z, z−)] exp[sim(z, z+)] Minimise a contrastive loss given extracted](https://files.speakerdeck.com/presentations/c44f9f5f5177478bb293f370b31fc723/slide_5.jpg){kind=link}
{kind=link}
![A theory of contrastive representation learning 8 Informal bound [4]](https://files.speakerdeck.com/presentations/c44f9f5f5177478bb293f370b31fc723/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}