exibility of representation learning, we have various ways to evaluate representation learning algorithms in practice. • Evaluation methods are critical part when we design a novel algorithm or analyse existing algorithms. • We organise the existing evaluation methods into four categories.
seen as a pre-trained model [Hinton et al., 2006] to solve a task. • We evaluate extractors with the metric of the new task, such as validation accuracy. • There are two common training strategies on the new task: • Frozen: train only a simple predictor on extracted features by . • Fine-tune: train too on the new task. • Note: Model and data sizes of pre-training correlate with the performance (Scaling-law [Kaplan et al., 2020]). ̂ f ̂ f ̂ f
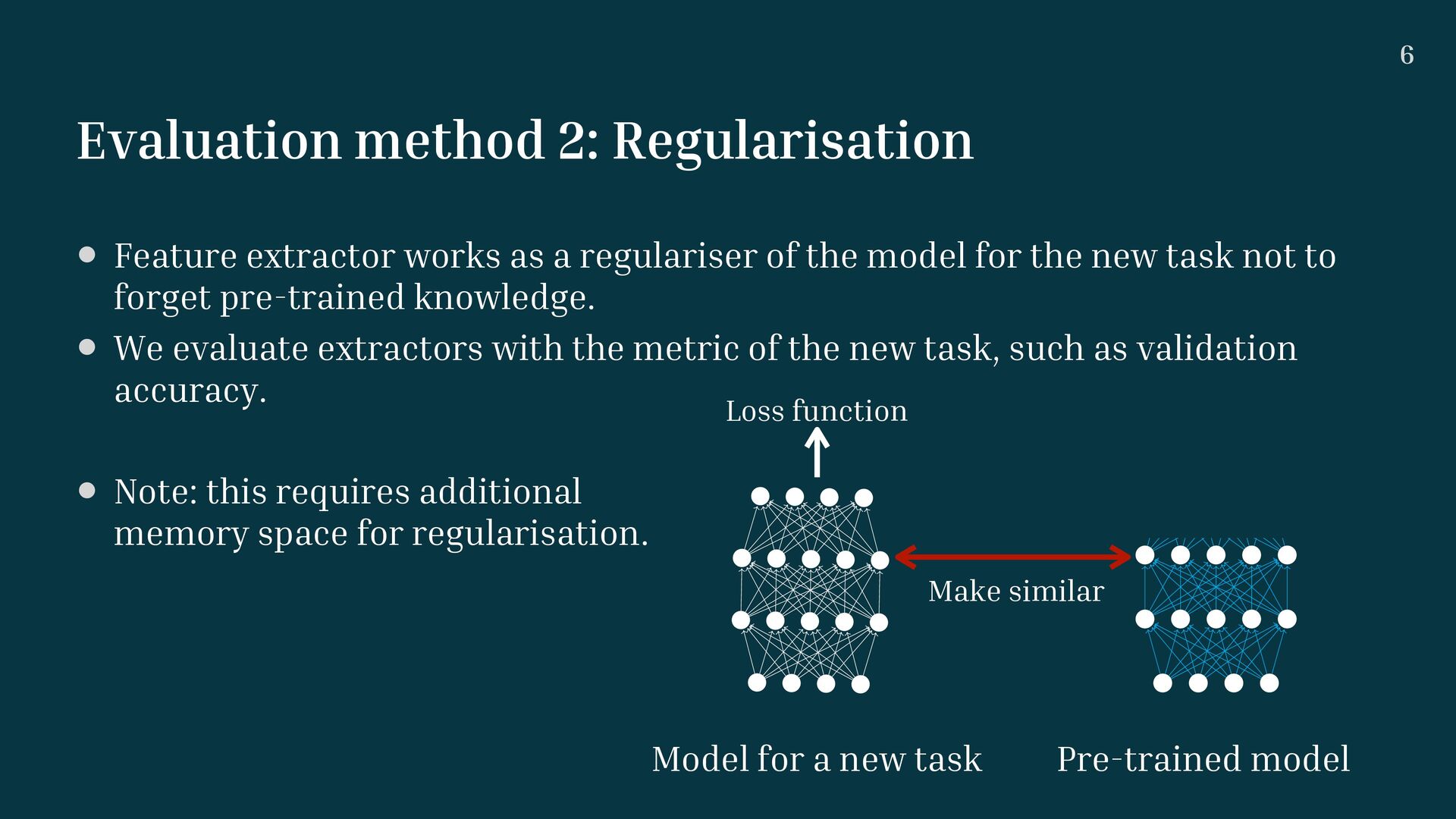
a regulariser of the model for the new task not to forget pre-trained knowledge. • We evaluate extractors with the metric of the new task, such as validation accuracy. • Note: this requires additional memory space for regularisation. Pre-trained model Model for a new task Make similar Loss function
be seen as dimensionality reduction when the extracted feature’s dimensionality is smaller than the original one. • Evaluation: how perform well as dimensionality reduction. • Related evaluation: visualisation (directly learn 2d features or apply T-SNE [van der Maaten and Hinton, 2008]). • Evaluation: compare the scatter plots visually. Classes 0 1 2 3 4 5 6 7 8 9
representation learning algorithms, we would like to select one of them that improves main task’s performance. • Ex: cross-entropy loss for image classi fi cation (main task) and self- supervised contrastive loss (auxiliary task). • We evaluate them with the metric of the main task, ex. validation accuracy. • Note: unlike the other methods, we can directly search the hyper-parameters of representation learning part. Main task’s loss auxiliary loss
representation learning: 1. Pre-training 2. Regularisation 3. Dimensionality reduction (and visualisation) 4. Auxiliary task • Discussion: • Existing evaluation methods focus on a single task’s performance. • Can we develop an evaluation method for universal representation learning? More discussion and theoretical survey are available in the extended version!
{kind=link}
![Representation learning [Bengio et al., 2013] 2 Goal: learning a](https://files.speakerdeck.com/presentations/69ed4a34c9ff44daa0e45bdf10471282/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}