1 Z ( ✓ ) ˜ p ( x ; ✓ ) Z ˜ p ( x ) dx X x ˜ p ( x ) or Z(✓) is An integral or sum is intractable over unnormalized probability distribution for many models. We sometimes face the probability distribution below: Unnormalized distribution Partition function
with tractable normalizing constant 2. To design a model that does not have involve computing p(x) 3. To confront a model with intractable normalizing constant • This chapter!
Z = X x p (x) r✓ log ˜ p (x) = E x ⇠p( x ) r✓ log ˜ p (x) For discrete data r✓ log Z = r✓ Z ˜ p (x) d x = Z r✓ ˜ p (x) d x = E x ⇠p( x ) r✓ log ˜ p (x) For continuous data NOTE: Under certain regularity conditions
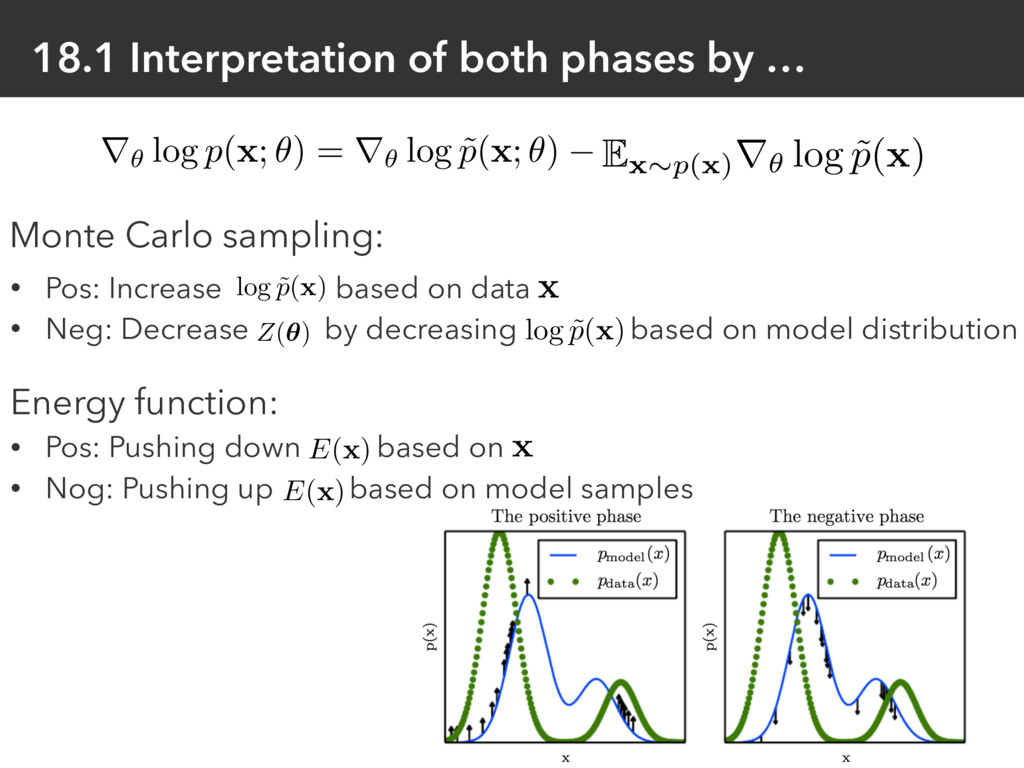
r✓ log Z = E x ⇠p( x ) r✓ log ˜ p (x) r✓ log p (x; ✓ ) = r✓ log ˜ p (x; ✓ ) r✓ log Z ( ✓ ) • Pos: Increase based on data • Neg: Decrease by decreasing based on model distribution log ˜ p (x) x log ˜ p (x) Z(✓) Energy function: • Pos: Pushing down based on • Nog: Pushing up based on model samples E( x ) x E( x )
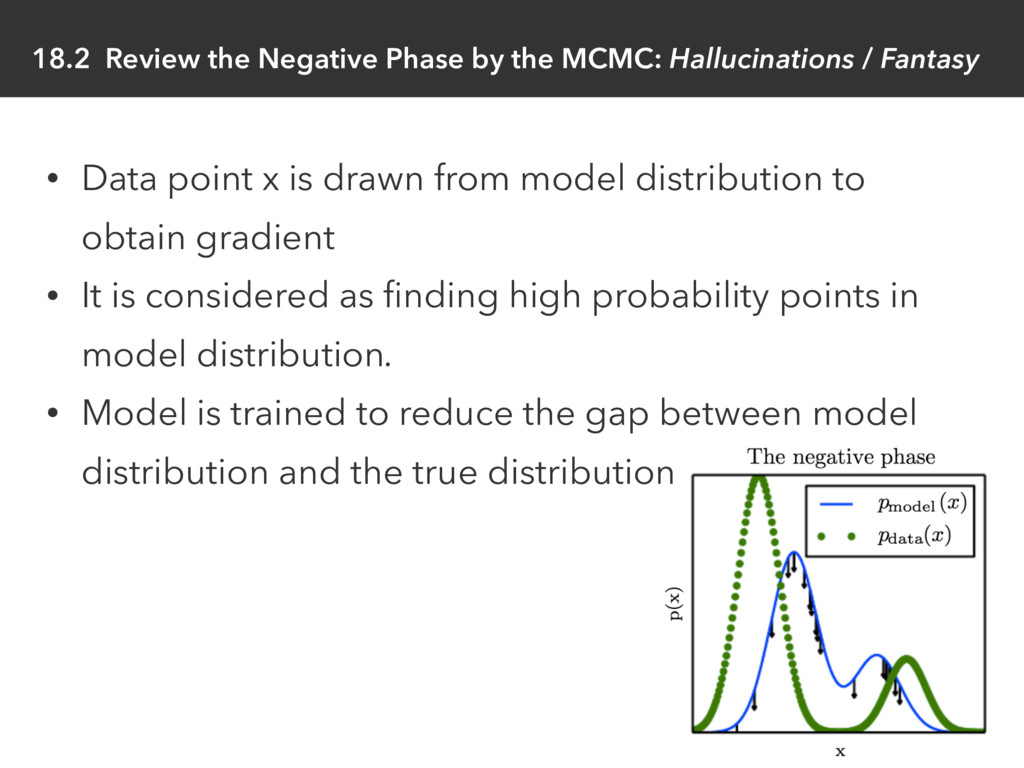
Fantasy • Data point x is drawn from model distribution to obtain gradient • It is considered as finding high probability points in model distribution. • Model is trained to reduce the gap between model distribution and the true distribution
Obtain the gradient based on real events: Awake • Neg: Obtain the gradient based on samples from model dist.: Asleep Note: • In ML, two phases are simultaneous, rather than separate; wakefulness and REM sleep
MCMC is burning in the Markov chain from random initialization • To reduce too many burning in, a solution is to initialize Markov chain from a distribution that is a similar to model distribution • Contrastive Divergence is a algorithm to do that • Short forms: CD, CD-k (CD with k Gibbs steps)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}