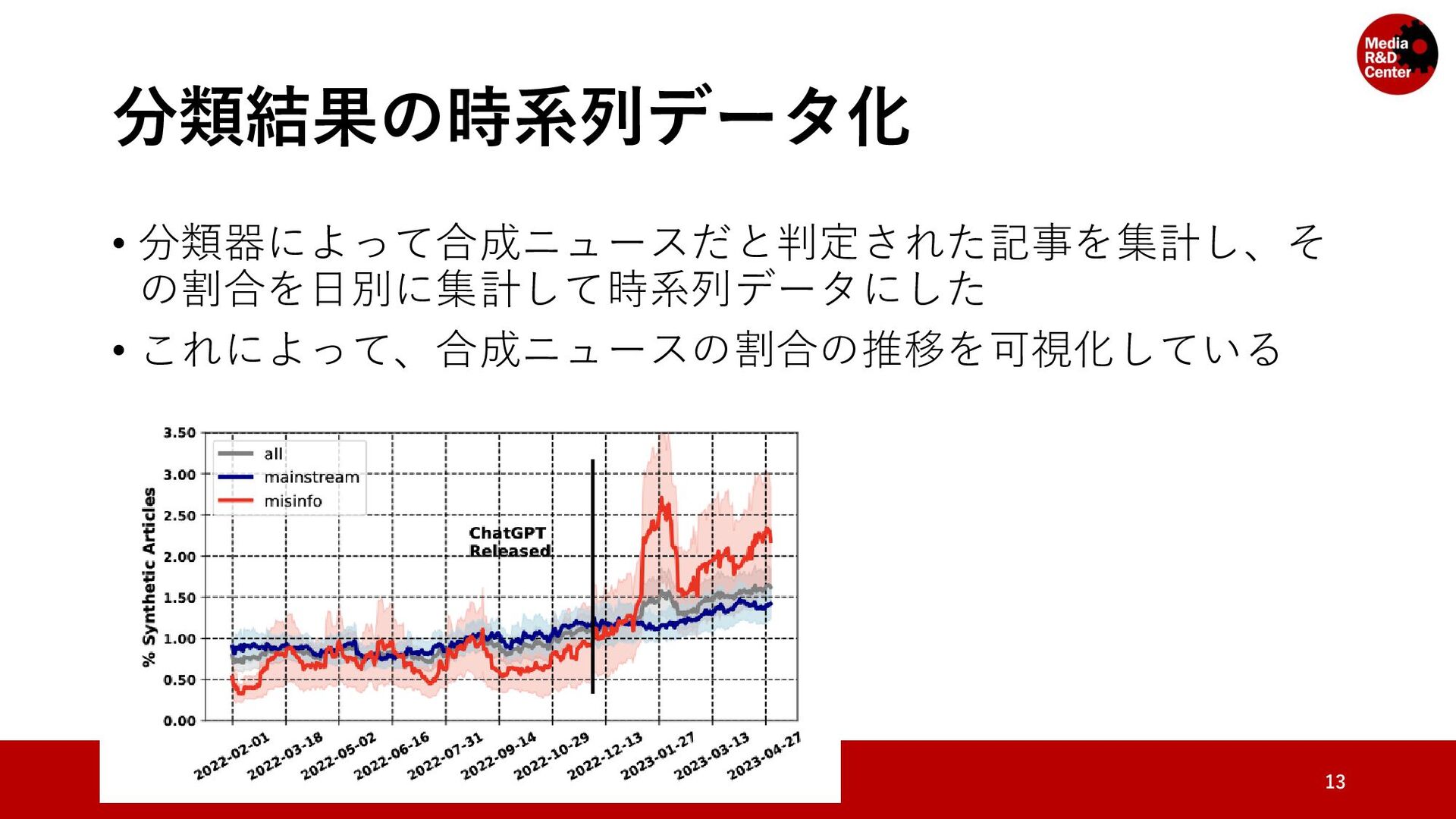
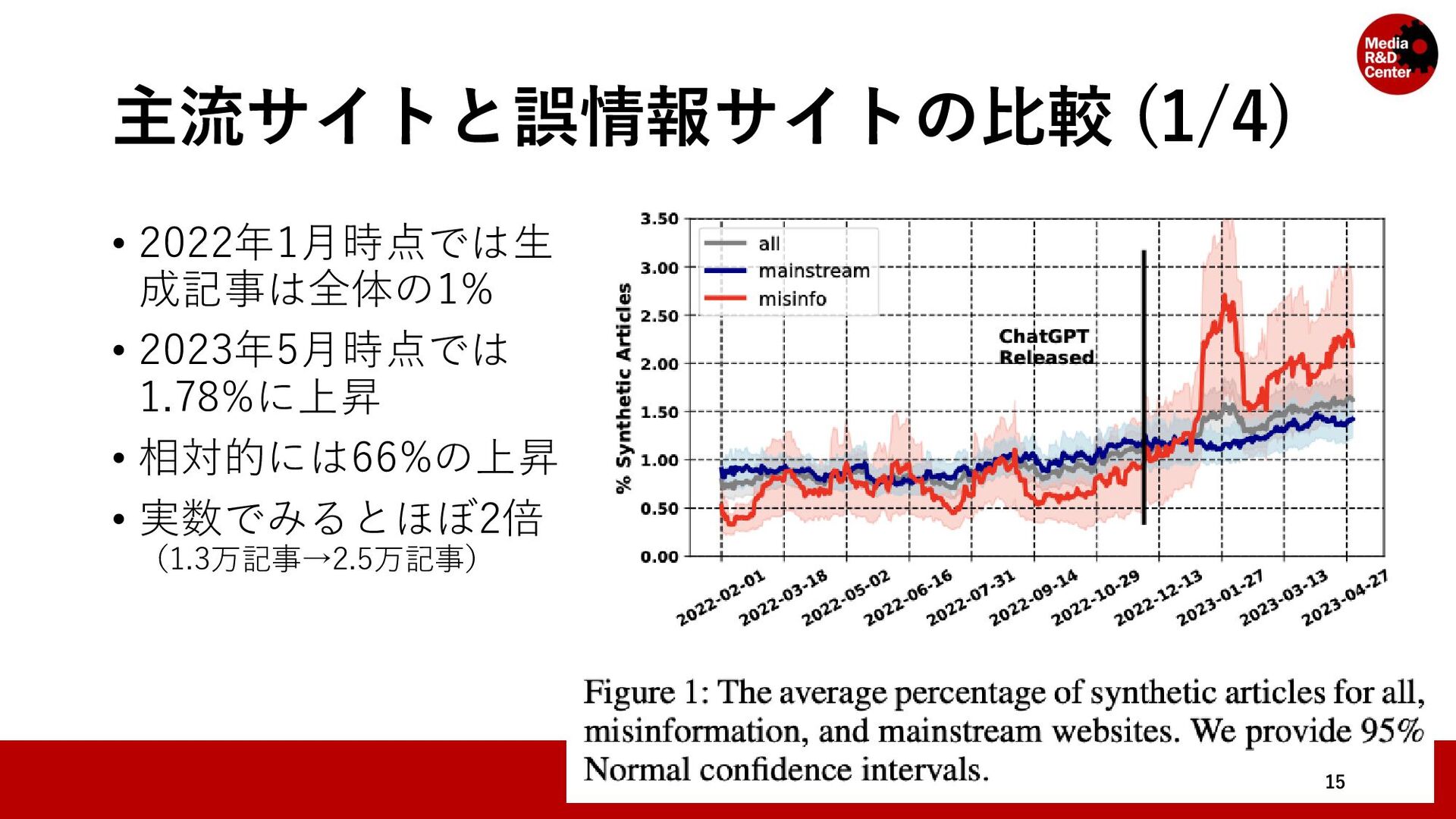
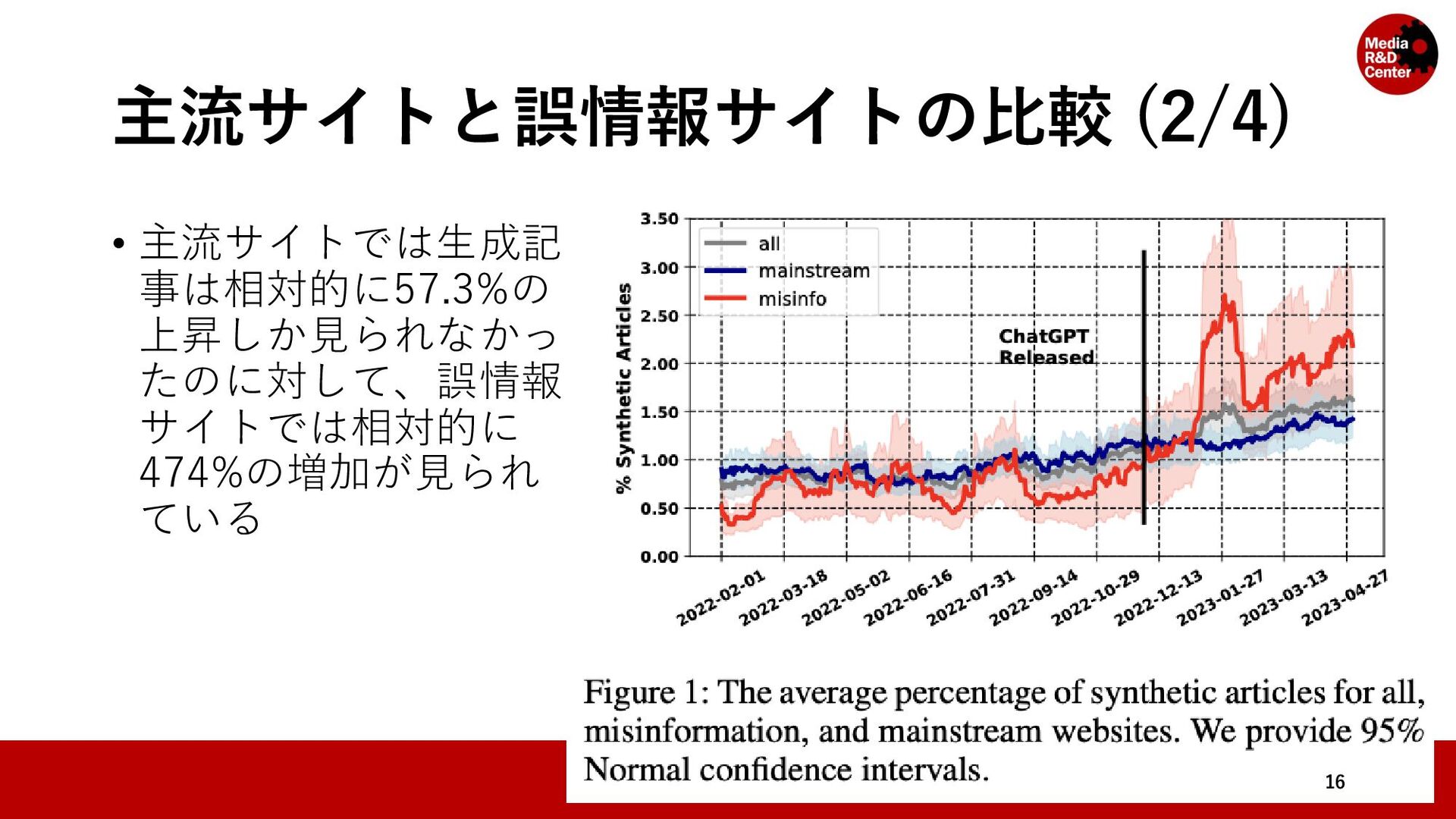
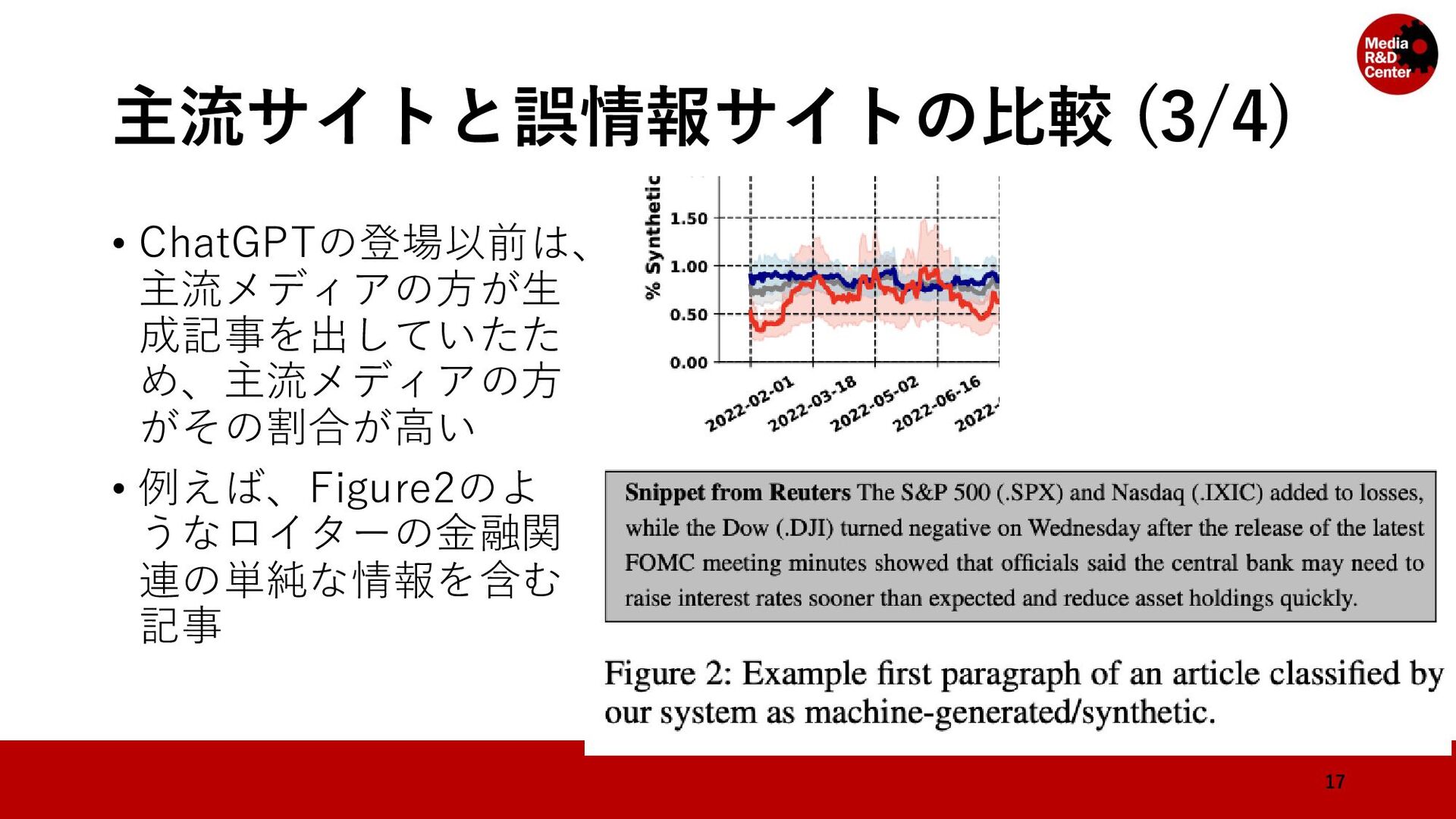
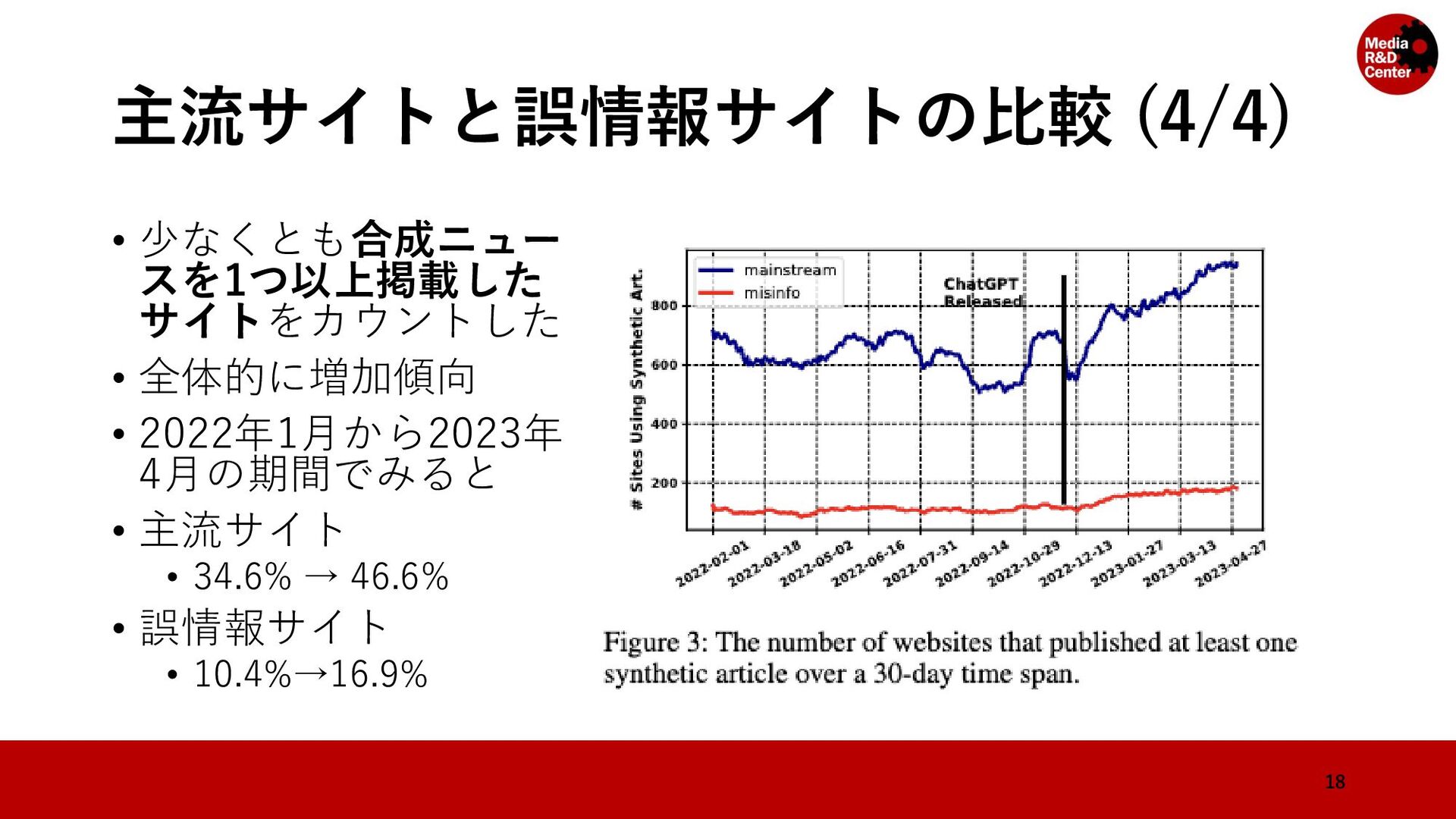
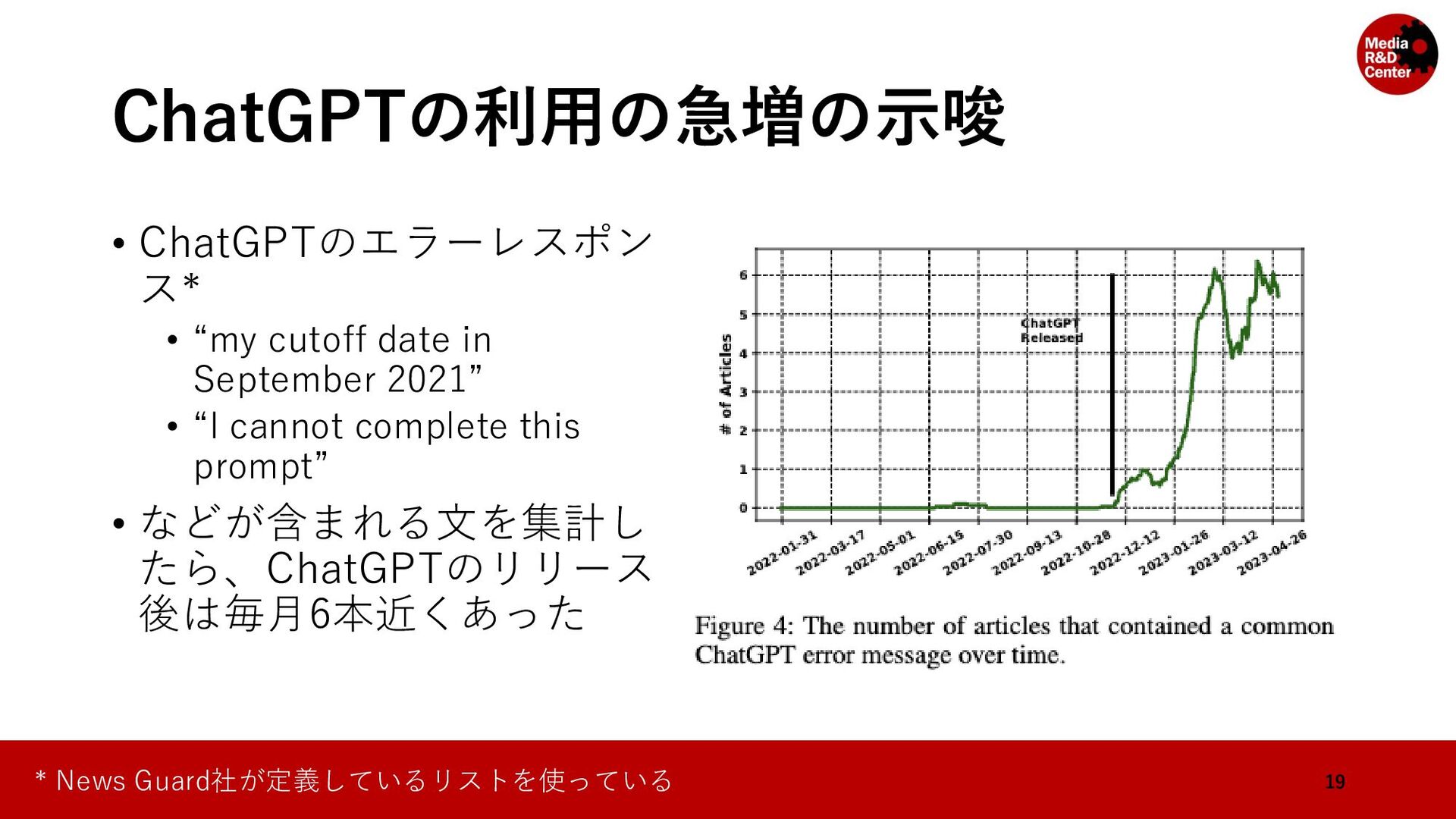
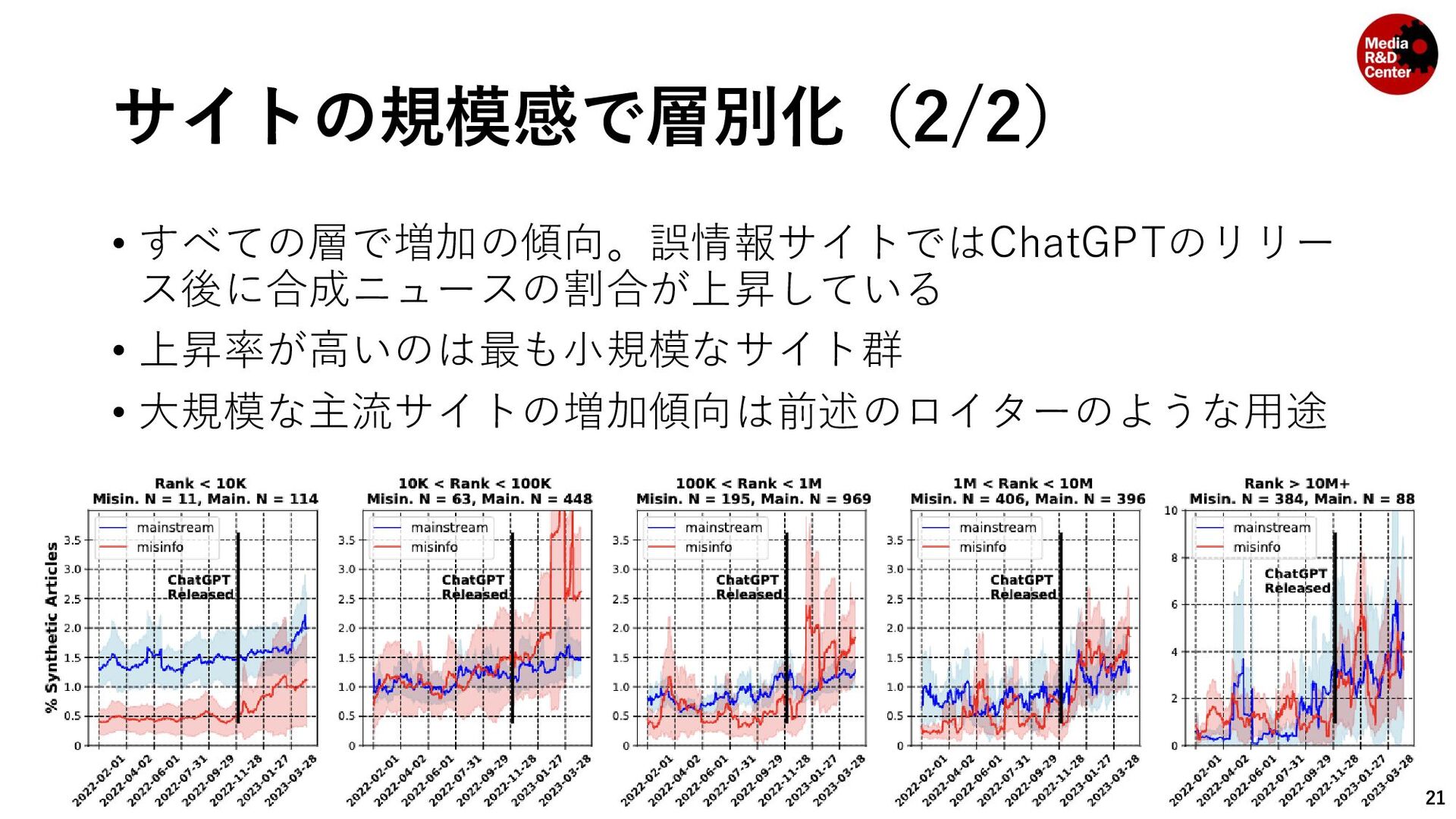
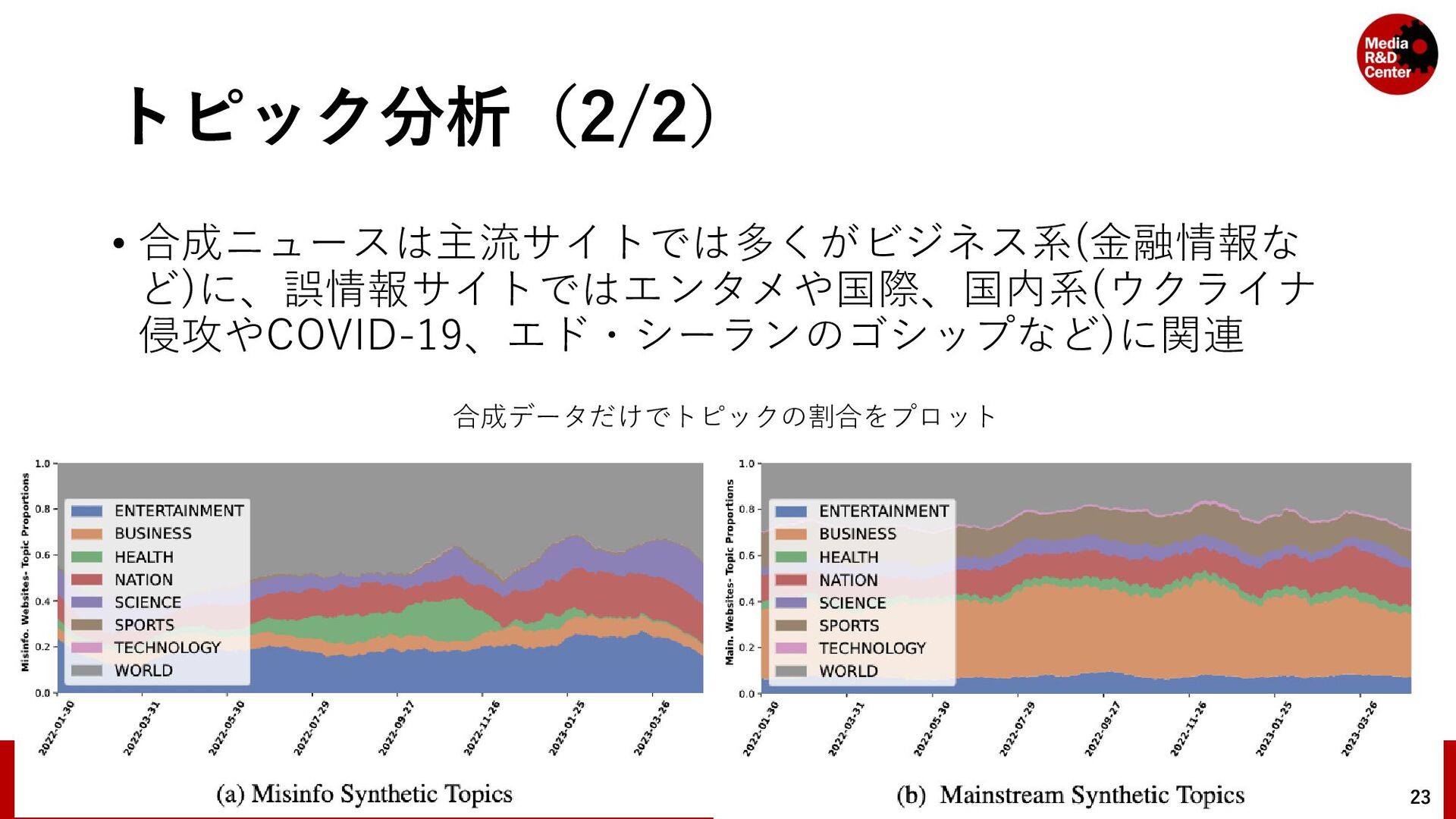
• 対象のウェブサイトのリストをMedia Bias/Fact Check*と先行研究 (Hanley, Kumar and Durumeric, 2023)**によって「ニュース」とラベ ル付けされているドメインを集めて構成されている • メディアの規模や信頼性を問わず集めている 7 * https://mediabiasfactcheck.com/ ** A Golden Age: Conspiracy Theories' Relationship with Misinformation Outlets, News Media, and the Wider Internet
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}