Task Danqi Chen and Jason Bolton and Christopher D. Manning https://arxiv.org/pdf/1606.02858v2.pdf ACL2016 ఏग़൛͔Βਫ਼্͕͍ͯ͠ΔʢACL ൃදͦͷ ༰ʣ http://cs.stanford.edu/people/danqi/ bib/paper/slide https://github.com/danqi/rc-cnn-dailymail only README??? Figs are quoted from the original paper or the slides 3 / 26
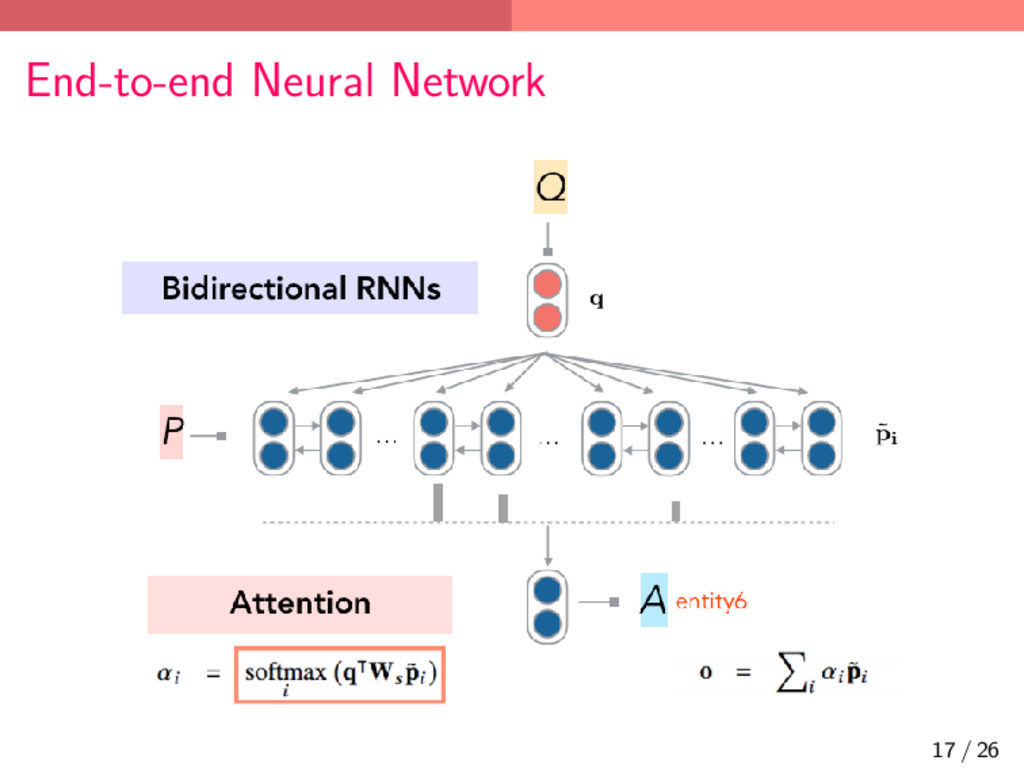
൛Ͱ LSTM ͕ͩͬͨվగ൛ (v2) Ͱ RNN+GRU ʹมߋ 1. hR i = RNN(hR i−1 , w(pi)), hL i = RNN(hL i+1 , w(pi)) 2. pi = concat(hR i , hL i ) 2. Attention 1. αi = softmaxi q⊤Wspi 2. o = ∑ i αipi α: prob. distribution (=attention), q: question embedding, pi: contextual embedding for pi (i-th word in the passage), Ws: weight matrix used for a bilinear term (it frexibly computes a similarity between q and pi), o: output vector 3. Prediction a = argmaxa∈p W⊤ a o 18 / 26
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
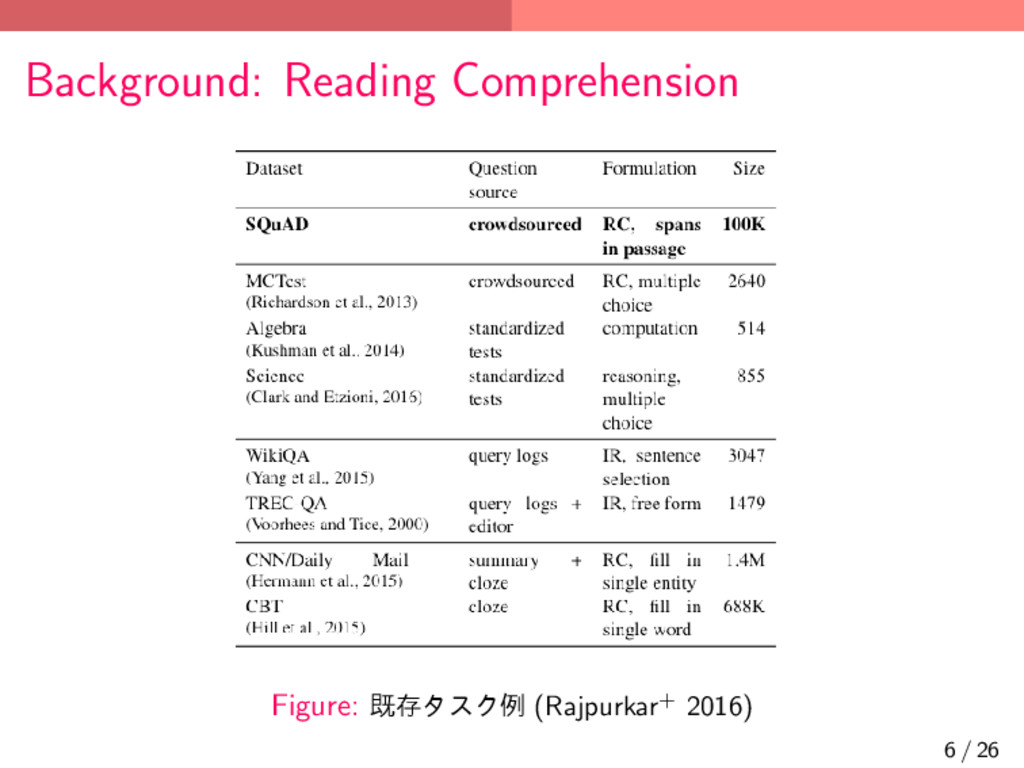{kind=link}
![Background: Big Data vs. Realistic ਓखͰσʔλΛ࡞Ζ͏ͱ͢ΔͱͲ͏ͯ͠খ͘͞ͳΔ MCTest (Richardson+ 2013) [web]:](https://files.speakerdeck.com/presentations/3a3432c10dcc4accb2d8cab464b385a2/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
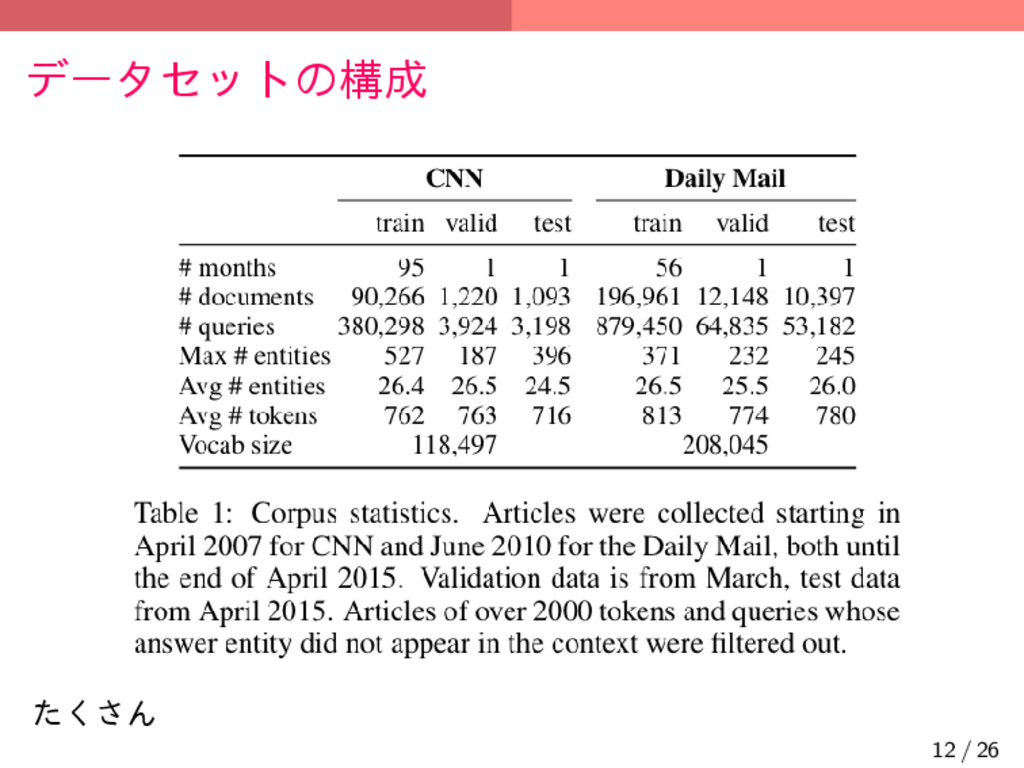{kind=link}
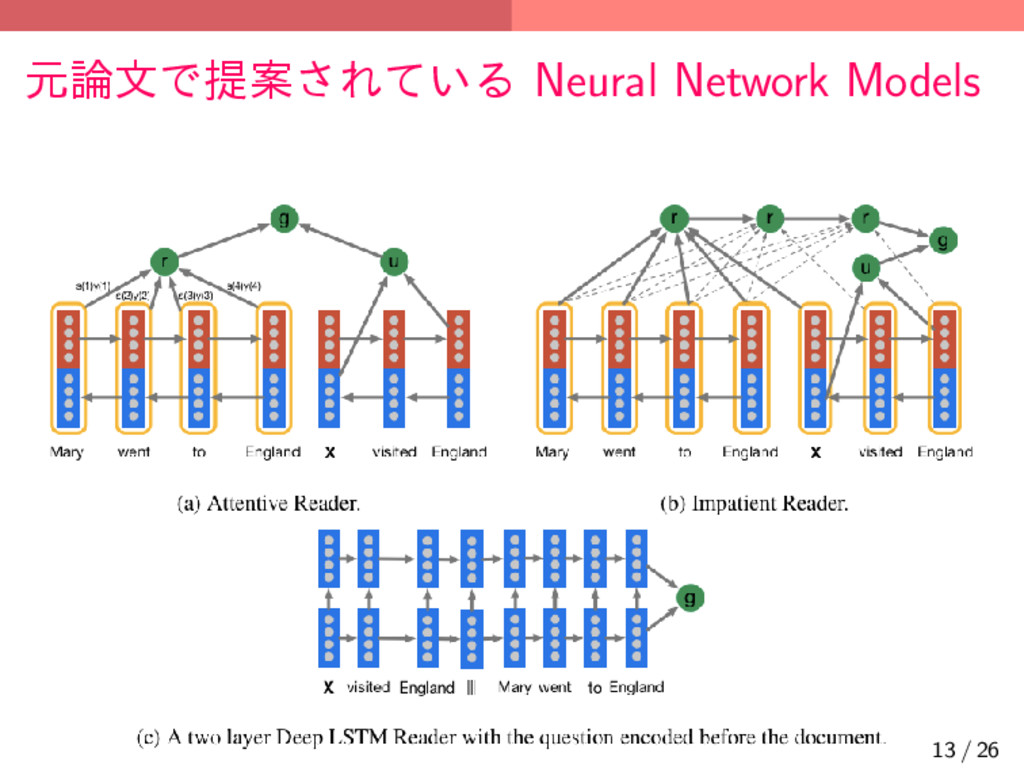{kind=link}
{kind=link}
{kind=link}
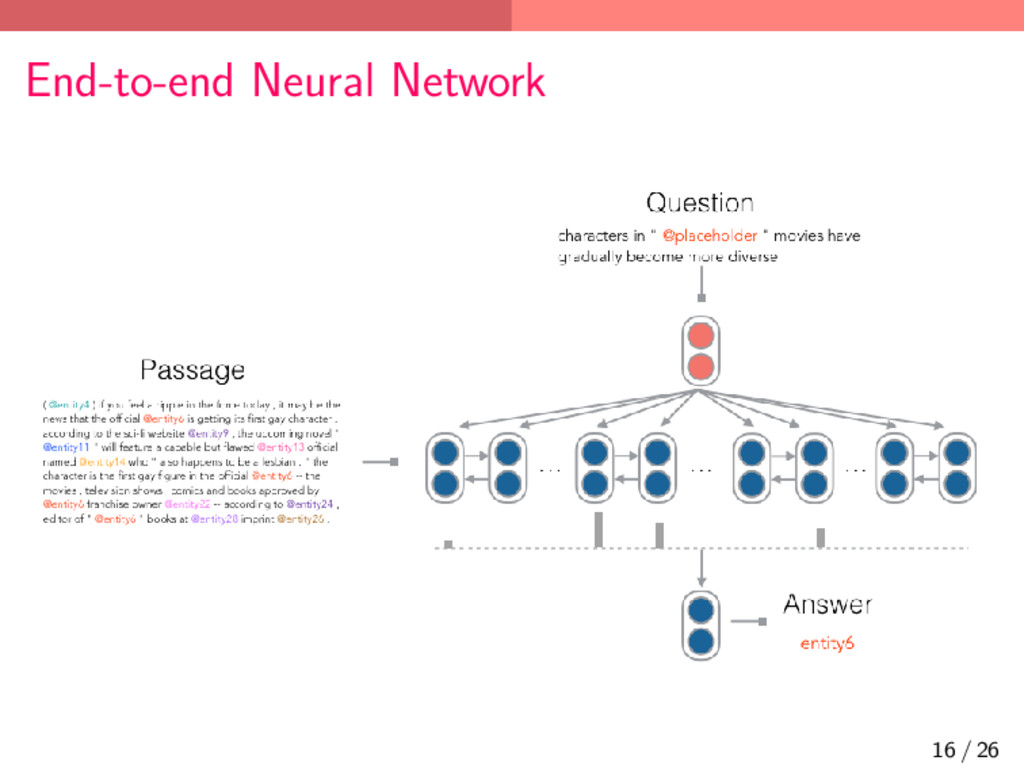{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}