(In German) Presentation held at the Parallel Conference in Karlsruhe, Germany, on May 15, 2013. Apart from the slides, the presentation featured a demo of Java Concurrent Animated.
zwischen Threads ist leichtgewichtig − Effizienz ist begrenzt durch die Nutzung gemeinsamer Ressourcen – Kosten von Context Switching – Zustand von Caches − Tatsächlich parallele Abarbeitung bei geeigneter Hardware – Multicore- bzw. Multiprozessor-Systeme – „Simultaneous Multithreading“-Techniken wie Hyperthreading
auf native Betriebssystem-Threads – Hohe Skalierbarkeit durch Nutzung von Betriebssystem-Ressourcen – Mechanismen zur Sichtbarkeit notwendig (Java Memory Model) − Verschiedene Arten von Threads – Java-Threads (Programmiermodell) – Native Threads (Anbindung durch JNI) – JVM-interne Threads − Java-Thread-Instanzen -> C++ Thread-Objekte -> native Threads
gestartet − RUNNABLE – Lauffähig, wartet aber auf Betriebssystem-Ressourcen (z.B. Prozessor) − BLOCKED – Wartet auf ein Monitor-Lock (z.B. Aufruf eines synchronized-Block) − WAITING – Wartet auf eine Aktion eines anderen Threads (z.B. notify()) − TIMED_WAITING – Wie WAITING, nur mit Timeout bei zu langer Wartezeit − TERMINATED – Hat seine Ausführung beendet
mit Keywords – Explizites Erzeugen und Starten von Threads – synchronized, volatile – wait(), notify(), etc. − Dann: Abstraktion von den Low-Level-Konstrukten durch java.util.concurrent – Runnable-/Task-Ausführung, z.B. mit ExecutorService – Nebenläufige Datenstrukturen, z.B. ConcurrentHashMap – Thread-Synchronisation, z.B. mit Semaphore – Atomare Variablen basierend auf CAS − Aktuell: Noch höhere Abstraktion wird angestrebt – Externe Bibliotheken – Für Java 8 geplante Neuerungen
Wann werden Änderungen an Variablen für andere Threads sichtbar? – Schwierig wegen Compiler-Optimierungen (Reordering) und Caches − Das Java Memory Model definiert einen klaren Rahmen – Zentraler Begriff: „happens-before“ – Regeln, unter welchen Umständen „happens-before“ gilt
Regeln − Verlässt ein Thread A einen synchronized-Block, – und betritt ein anderer Thread B anschließend einen synchronized-Block desselben Monitors, – so sieht B alle Werte von Variablen, die A beim Verlassen gesehen hat − Schreibt ein Thread A eine volatile-Variable, – und liest ein anderer Thread B anschließend dieselbe volatile-Variable, – so sieht B alle Werte von Variablen, die A beim Schreibzugriff gesehen hat
hinreichend geschützter Zugriff von Threads auf gemeinsame Daten – Ergebnis hängt vom Thread-Scheduling ab und wird nichtdeterministisch – Sind oft nur sehr schwierig zu identifizieren – Unter dem Java Memory Model können Race Conditions dann auftreten, wenn Schreib- und Lesezugriffe mehrerer Threads auf eine Variable nicht durch “happens-before” geordnet sind (z.B. fehlendes synchronized) − Deadlocks und Livelocks – Threads warten ewig auf Ressourcen des/der anderen Threads – Threads befinden sich in einer (ggf. komplexen) Endlosschleife − Die Ursachen sind in der Regel Programmierfehler
void main(String[] args) { MyThread myThread = new MyThread(); myThread.start(); // ... do some work ... myThread.shutdown = true; } static class MyThread extends Thread { boolean shutdown = false; @Override public void run() { while (!shutdown) { // ... do some work ... } } } }
public static void main(String[] args) { MyThread myThread = new MyThread(); myThread.start(); // ... do some work ... myThread.shutdown = true; } static class MyThread extends Thread { volatile boolean shutdown = false; @Override public void run() { while (!shutdown) { // ... do some work ... } } } }
volatile boolean initialized = false; public void init() { a = 1; b = 2; initialized = true; } public void check() { while (!initialized) { // just wait } // a == 1 && b == 2 }
counter = new BrokenCounter(); public static void main(String[] args) { new MyThread().start(); new MyThread().start(); } static class MyThread extends Thread { @Override public void run() { for (int i = 0; i < 10; i++) { int next = counter.getNext(); System.out.println(getName() + " " + next); } } } }
tauchen manchmal versteckt auf: – Vector vs. ArrayList – Hashtable vs. HashMap – StringBuffer vs. StringBuilder − Empfehlungen: – Verwende nicht-synchronisierte Klassen, wenn nur ein Thread zugreift – Verwende nebenläufige Datenstrukturen für bessere Performance
Overhead – Prinzipiell kann jedes Objekt als Lock-Monitor verwendet werden – Zusätzlicher Zustand im Objekt-Header: Wird das Objekt momentan als Lock verwendet, welche Art von Lock ist es, etc. – Der Zugriff auf diesen Zustand muss exklusiv bzw. atomar erfolgen – Höhere Anforderungen an interne Synchronisationsmechanismen der JVM − Dynamische Optimierung von Locks – Umformung von „Thin Locks“ in „Fat Locks“ und umgekehrt – Eliminieren von unnötigen Locks (deaktivierbar mit -XX:-EliminateLocks) – Spekulative Optimierung von Lock- und Unlock-Operationen auf einen bestimmten Thread (deaktivierbar mit -XX:-UseBiasedLocking)
Syntax aus der funktionalen Programmierung − Parallelisierung „frei Haus“ − Interne Implementierung von parallel() mit Hilfe von ForkJoin − Performance durch Nutzung von InvokeDynamic int sum = blocks.filter(b -> b.getColor() == BLUE) .map(b -> b.getWeight()) .sum(); int sum = blocks.parallel() .filter(b -> b.getColor() == BLUE) .map(b -> b.getWeight()) .sum();
und asynchrone Nachrichten − Lose Kopplung – Actor-Instanzen können überwacht und bei Bedarf ersetzt werden – Sehr robustes Programmiermodell − Parallele Ausführung von Actors – Scheduling mit Executors oder ForkJoin – Threads sind nicht an einzelne Actors gebunden − Kleine Beispiel-Implementierung für Einsteiger: – http://github.com/peschlowp/ForkJoin
wir hohe (parallele) Effizienz – z.B. wissenschaftliche Anwendungen, Batch-Anwendungen, HPC – Hier kann sich eine eigene Implementierung lohnen – „Active waiting“ ist ein möglicher Ansatz bei exklusiver Nutzung der Hardware − Beispiel: CyclicBarrier (JDK) vs. CentralBarrier – Gleicher Algorithmus, eigene Implementierung – Bestandteil des „jbarrier“-Pakets
ein „Hinweis“ für die JVM − Mapping auf native Prioritäten des Betriebssystems ist möglich – (De-)aktivierbar mit -XX:+UseThreadPriorities – Beachte: Der Default-Wert für dieses Flag kann sich ändern − Unterschiedliche Auswirkungen je nach Betriebssystem – Z.B. sind unter Linux root-Rechte nötig − Empfehlung: Thread-Prioritäten in Java nicht verwenden – Kann Performance negativ beeinflussen – Gefährdet Plattformunabhängigkeit
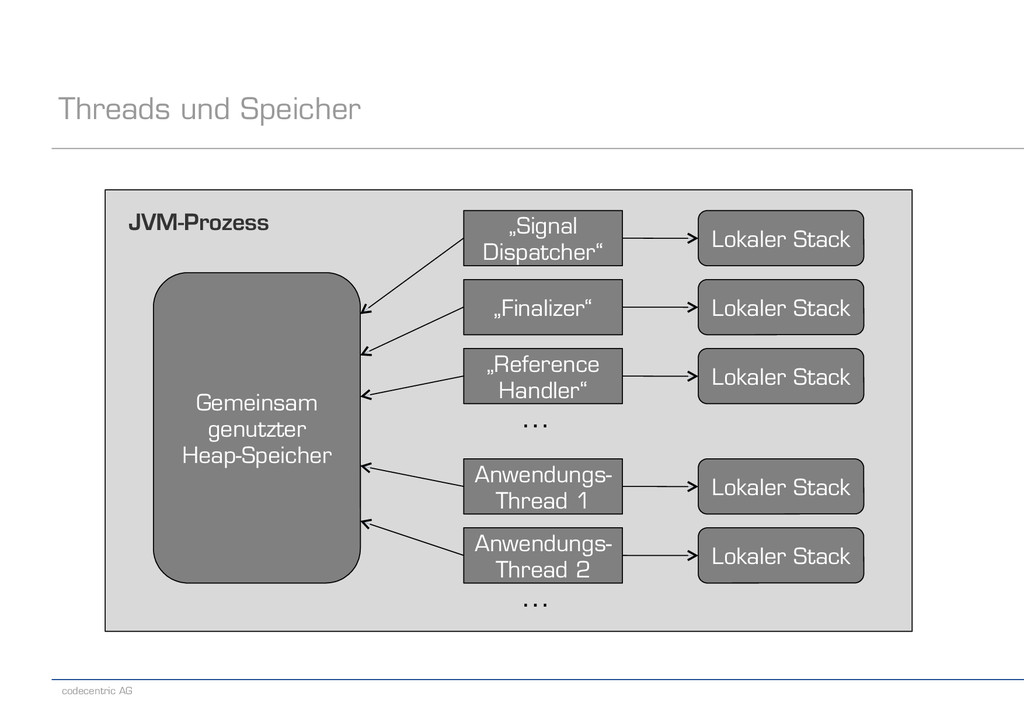
für interne Aufgaben − Beispiel: HotSpot – VM Thread – VM Periodic Task Thread – Signal Dispatcher – Finalizer – Reference Handler – Low Memory Detector – Attach Listener – Ein oder mehrere Compiler Threads – Je nach Konfiguration noch ein oder mehrere GC-Threads – Ggf. noch Threads für JMX-Server, Connection-Handler, etc.
startet die JVM zunächst nur einen einzigen Thread – Dieser führt die main-Methode der Starter-Klasse aus – Im weiteren Verlauf kann die Anwendung prinzipiell beliebig viele weitere Threads erzeugen (und beenden lassen) – Die Anwendungs-Threads leben für die gesamte Laufzeit der Anwendung gemeinsam mit den Daemon-Threads in der JVM − Der Zeitpunkt der Beendigung der JVM wird durch die Anwendungs-Threads bestimmt – Sobald der letzte Anwendungs-Thread beendet ist (durch Verlassen seiner run-Methode), wird auch die JVM beendet – Einzige Ausnahme: Ein Anwendungs-Thread ruft explizit die Methode System.exit bzw. Runtime.exit auf
Thread Stacks konfiguriert werden – -Xss<size> legt die Größe für einen Thread Stack fest − Beispiel: -Xss512k legt die Stack-Größe auf 512 KB fest − Default-Werte für x86 Solaris/Linux/Windows – 320 KB bei der 32-bit JVM – 1024 KB bei der 64-bit JVM − Verwendet die Applikation sehr viele Threads, kann es sinnvoll sein, eine kleinere Stack-Größe als den Default-Wert zu verwenden
– Mehrere Threads können gleichzeitig versuchen ein neues Objekt zu erzeugen – Konflikte beim Zugriff auf gemeinsamen Speicher sind teuer − Lösung: TLABs – Jeder Thread erhält einen kleinen exklusiven Teil des gemeinsamen Speichers – Neue Objekte werden dort angelegt – Erst wenn ein TLAB voll wird, werden die Objekte in den gemeinsam genutzten Bereich migriert (und nur dann muss Synchronisation verwendet werden) – Detail-Ausgaben mit -XX:+PrintTLAB
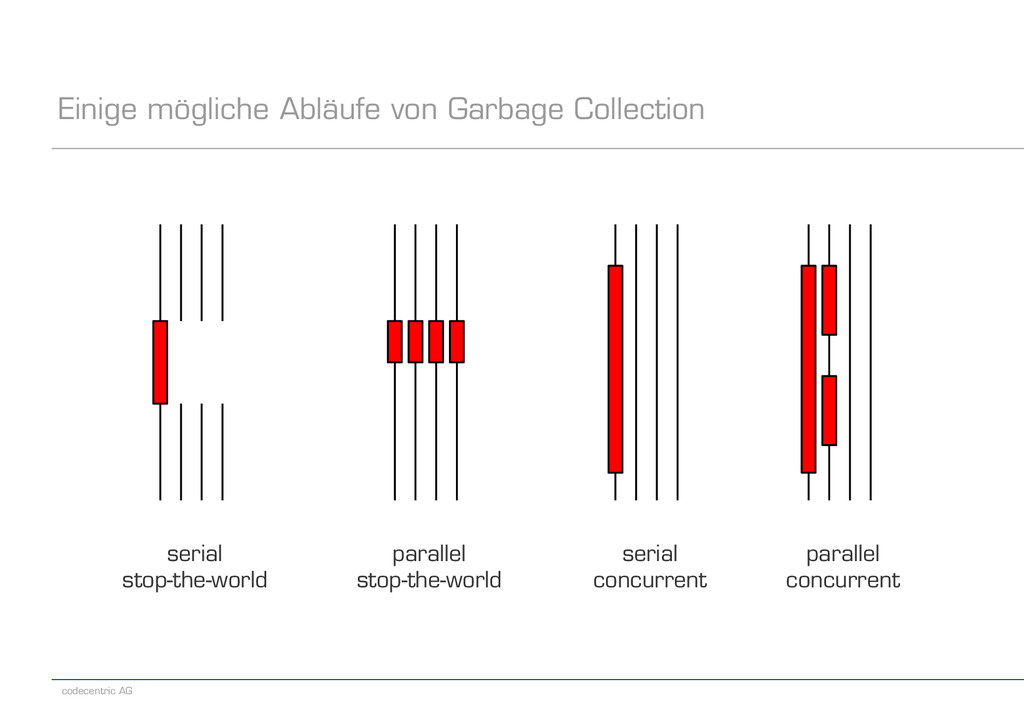
Anzahl Threads für Stop-the-World-Phasen – Default ist 3+5N/8 mit N der Anzahl virtueller Prozessoren -XX:ConcGCThreads=<value> – Setzt die Anzahl Threads für nebenläufige Phasen – Default ist (ParallelGCThreads + 3)/4
Möglichkeiten für nebenläufige Programmierung – synchronized ist einfach, aber oft unnötig teuer – volatile ist eine gute Alternative bei nur einem schreibenden Thread – java.util.concurrent enthält viele robuste und performante Klassen – Trend zu Einfachheit durch zusätzliche Abstraktion (Lambdas, Actors, DataFlow, …) – Die JVM verwendet eigene Threads für Kompilierung, GC, etc. – Die JVM bietet diverse Optimierungen für Multithreading und Locking − Für weitergehend Interessierte: – Joshua Bloch: „Effective Java“ 2nd edition – Brian Goetz et al.: „Java Concurrency in Practice“ – Charlie Hunt, Binu John: „Java Performance“
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}