DE CONTEXTE ▸ Qui sommes nous ? ▸ eTF1 : entité de TF1 qui crée/gère les sites web du groupe TF1 ▸ tf1.fr, lci.fr, etc... : sites avec un peu de trafics (120kh/s) et surtout on délivre un peu de vidéos ▸ peak 180Gbit/s depuis notre plateforme (vod), 700Gbit/s via CDN (live) ▸ métiers : faire du web et produire de la vidéo (comparable m6web/molotov/dailymotion)
DE CONTEXTE ▸ 2 ans en arrière : stack un peu legacy/old school ▸ infra classique : 300 serveurs OP, Vmware + SAN/NAS, 99% Centos (puppet/ansible) =~ 1200 vm(s) ▸ 50aines d'applis diverses (php legacy, nodejs, go) avec méthode de déploiement diverses et variées (capistrano, puppet, shell scripts ...) ▸ quelque grosse application monolithique : la plus representative "mytf1" : déploiement de ~1G qui fait tout (front/back/jobs/café) ▸ problèmes biens connus : déploiement long, maintenance infernale, release difficile, bref... ▸ ===> BREAK THE MONOLITH => GO TO MICRO SERVICES
MONOLITH : MOVE TO MICRO SERVICES ▸ (qui dit micro service, dit container, dit docker) ▸ double move docker / micro services ▸ 1er essai sans k8s, build docker dev puis flatten et export sur des vm(s) ?! ▸ résultat : 150 vm(s) pour une application avec de la configuration spaghetti dans tous les sens ▸ => incompréhensibles, un-maintenable, gouffre à performance ▸ => BIG FAIL
MICRO SERVICES ▸ /!\ STOP : wait a little, think a bit ▸ Besoin : orchestrateur de containers (test mesos, marathon, etc...) ▸ Found K8S début 2016 ▸ POC, test ▸ Success => GO PROD
▸ les clusters k8s ▸ 5 clusters ▸ cluster On Premise sur vm(s) centos 7.3 k8s 1.7.3 ▸ integration : 1 master, 20 nodes (80 vcpu, 640Gb ram) : ~ 100pods , 400 containers ▸ validation : pareil que l'intégration ▸ production old (k8s 1.4.2) : 3masters, 80 nodes (640 vcpu, 2.6To ram) : 400pods, 4000 containers (on eat large) ▸ nouveau cluster de prod en cours de définition/déploiement ▸ cluster PRA sur Aws (k8s 1.4.2): 1 master, 2 nodes <> autoscale à 80 pour reprendre la production à l'identique
▸ méthode de déploiement ▸ Il existe plein de scripts tout fait (kubeadm, kops, kubernetes- everywhere, etc... ) ▸ Cool pour bootstrap un petit cluster mais pas adapté pour le HA/ gros workload ▸ Scripts opaques/magique : nous n'aimons pas la magie ▸ Besoin de comprendre ▸ besoin de tuning des composants standards ▸ => READ K8S the hard way
▸ méthode de déploiement ▸ On Premise ▸ foreman : ansible => déploiement masters/nodes auto centos car on connait bien et que ca pose aucun problème, et déploiement des applis ▸ AWS ▸ ansible fait tout => déploiement/terraforming instance/ elb + master/nodes/applicatifs ▸ mutualisation du code ansible :)
▸ quelques détails/choix ▸ cluster etcd 3 hosts (lancé hors docker mais discuté encore) ▸ tout le reste est lancé en container via kubelet (api/ scheduler/container) en mode non connecté à api-server ▸ networking : ▸ flannel en host gateway (le plus simple/compréhensible) ▸ kube-router très fortement étudié pour le futur cluster
▸ les applications déployés sur k8s ▸ lci.fr : 10 micros-services en prod depuis 10/2016 ▸ 30 micros services cores/videos (delivery, dvr, etc...) ▸ svod (mytf1vod.fr) : 20 micro services sortie prévu fin de mois ▸ tf1.fr : refonte du monolithe / éclaté 10aines de micro services => fin de l'année ▸ Objectif : 90% de la production sur K8S fin 2017
▸ les applications déployés sur k8s ▸ On déploie tout les nouveaux applicatifs sur k8s, les anciens monolithes sont brisés en micro services ▸ les middleware type rabbitmq aussi sur k8s ▸ les caches web (nginx) simples sur k8s ▸ pour le moment on garde l'offload ssl en dehors (parité nginx/elb) ▸ accès au data persistentes via interface s3 (assets), et encore un peu de nfs legacy :( ▸ les datastores not on k8S (persistent volumes) : postgres ▸ ES en grande discussion
THE GOOD ▸ PROS ▸ orchestration facilités des containers/gestion des lifecycles ▸ gestion des restarts auto/auto-monitoring ▸ scaling facile !! ▸ api k8s simple et pratique (possibilité infinie d'integration) ▸ labeling (possibilité infinie)
THE GOOD ▸ PROS ▸ création facile de nouveau environnements et cloisonnements (via les namespaces) ▸ Enormément de fonctionnalités/possibilités (DaemonSets, Jobs, PetSets, Ingress) ▸ Abstraction "clean" entre les services et les instances d'applications fournissants ces services ▸ Services discovery par défaut via kubedns (et c'est fantastique) ▸ Intégration parfaite dans notre cycle de CI/CD (Jenkins) ▸ Blue/Green deployment
THE GOOD ▸ SECRET^W^W SUCCESS STORY ▸ Une des grosse réussite aura été le déploiement quasi à l'identique du cluster/applications OP / AWS ▸ Couplage à la refonte de notre chaîne de CI/CD (Docker/Github/Jenkins/Scripts) ▸ BIG WIN
THE BAD ▸ CONS (ou les choses à adapter) ▸ formation à la technologie k8s / niveau minimum requis assez élevé / plein de concept à appréhender ▸ problème interne : les dev utilisent docker-compose... et non k8s ▸ écosystème mouvant et très actif ▸ gestion des configurations applicatives (envvars/configmap/etcd/consul ?) ▸ Monitoring : services distribués donc complexe ▸ manque de visibilité / debug ▸ l'auto-recovery de k8s marche si bien que nous avons des situations où les containers peuvent crasher plusieurs fois par heures (memory leak nodejs ?) sans que personne ne le remarque (y compris l'équipe ops)
THE BAD ▸ Monitoring ▸ Définition de ce que l'on doit monitorer et comment ▸ état des déploiements/pods/containers (nb de restart, état du démarrage, etc...) ▸ état des services/endpoints ▸ état des routes /readiness et /liveness ▸ état des composants cluster (etcd/api/scheduler/controller/registry/etc...) ▸ conformité des pods (selon des règles maisons) ▸ limites mem/cpu, host-selector, labels, etc... ▸ heapster/grafana + plein de petits scripts homemade en python pour zabbix
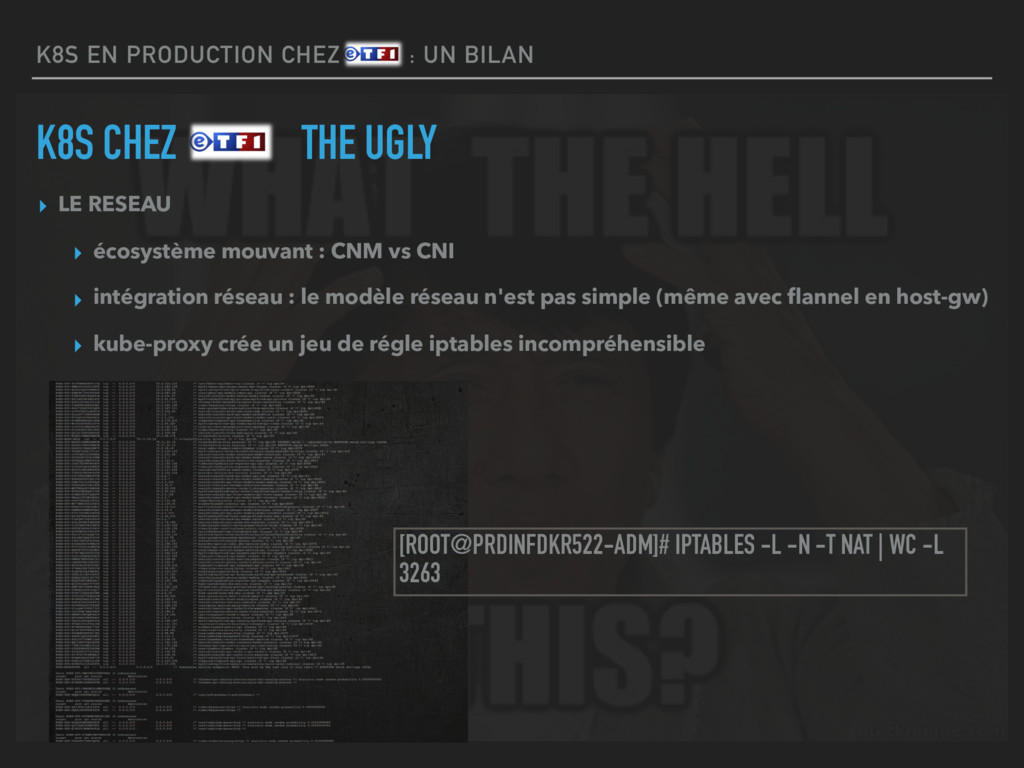
THE UGLY ▸ LE RESEAU ▸ écosystème mouvant : CNM vs CNI ▸ intégration réseau : le modèle réseau n'est pas simple (même avec flannel en host-gw) ▸ kube-proxy crée un jeu de régle iptables incompréhensible [ROOT@PRDINFDKR522-ADM]# IPTABLES -L -N -T NAT | WC -L 3263
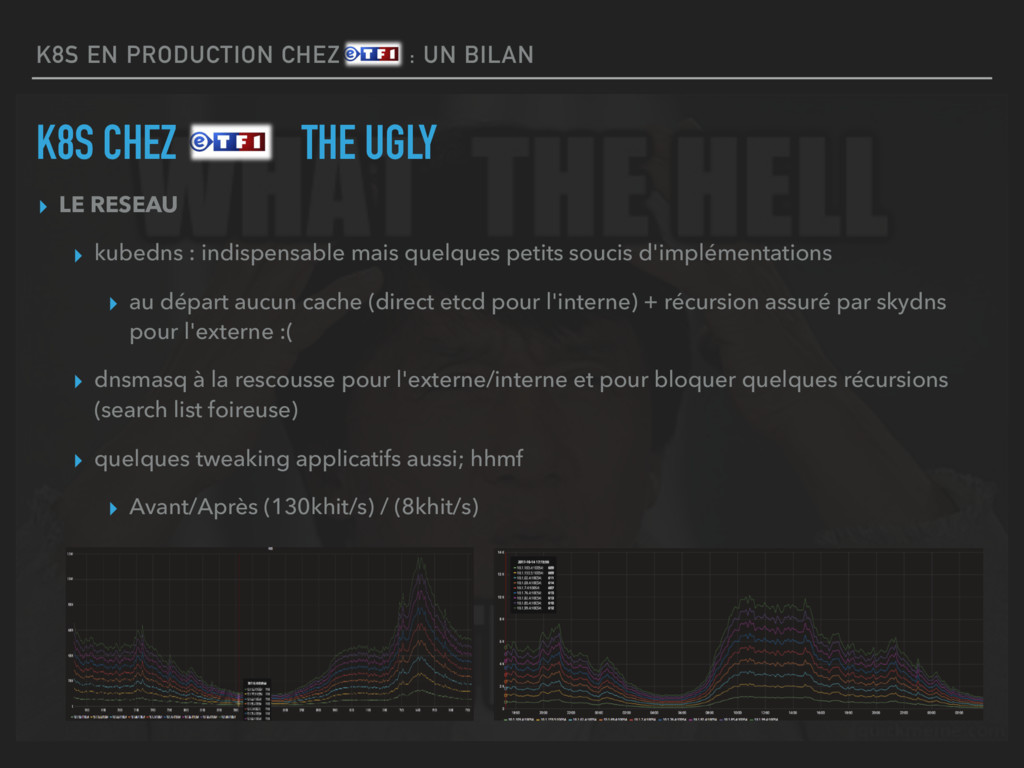
THE UGLY ▸ LE RESEAU ▸ kubedns : indispensable mais quelques petits soucis d'implémentations ▸ au départ aucun cache (direct etcd pour l'interne) + récursion assuré par skydns pour l'externe :( ▸ dnsmasq à la rescousse pour l'externe/interne et pour bloquer quelques récursions (search list foireuse) ▸ quelques tweaking applicatifs aussi; hhmf ▸ Avant/Après (130khit/s) / (8khit/s)
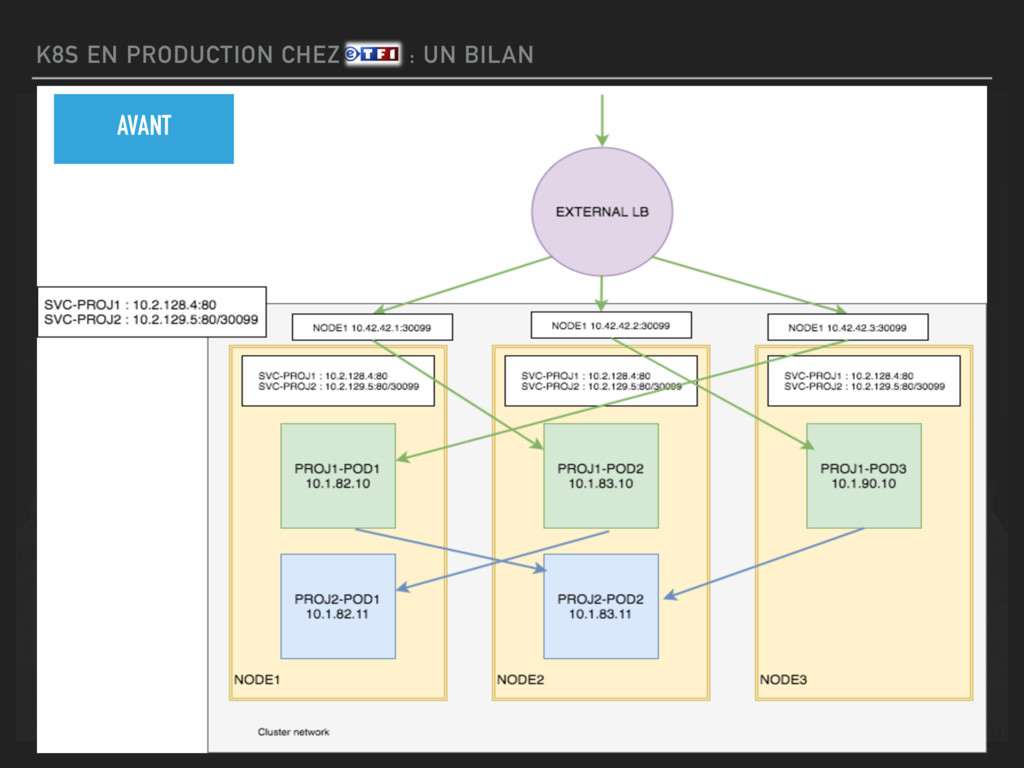
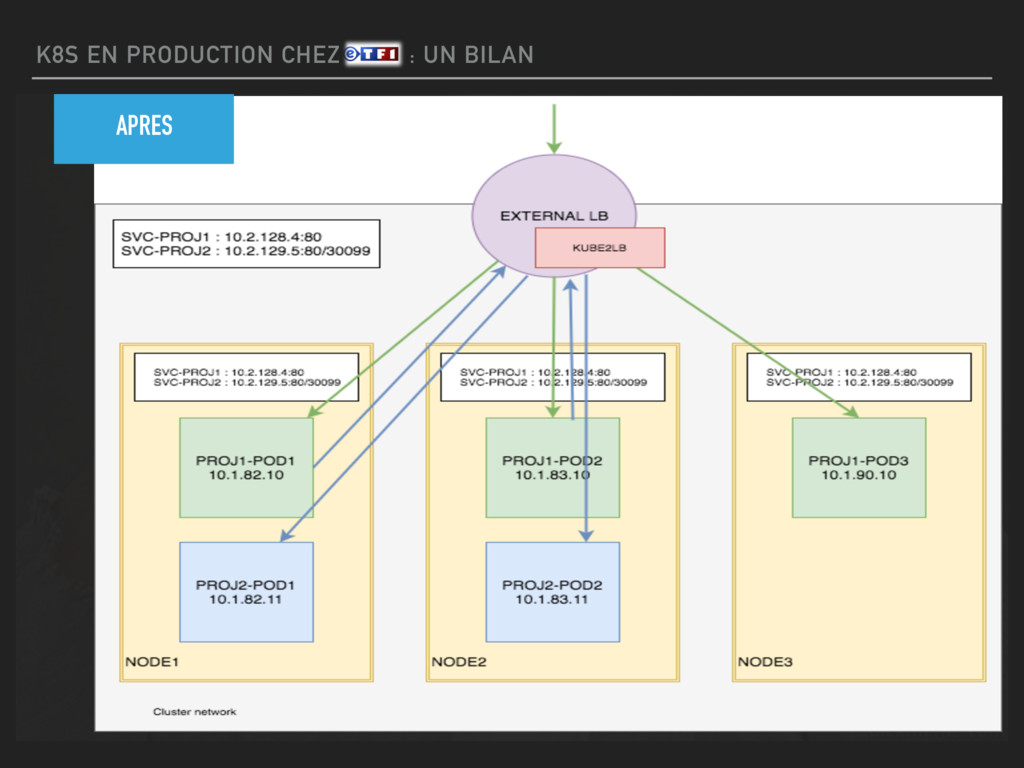
THE UGLY ▸ LE RESEAU ▸ Kube-proxy crée des règles stateless (load balancing probabiliste) ▸ acceptable pour le trafic intracluster ▸ problème quand on doit load balancer un service exposé extérieur (pour le moment via NodePort) ▸ Solution : mettre les LBs dans le réseau cluster (flannel) et dev custom qui watch l'api k8s pour reload dynamiquement le lb (hapee/nginx) ▸ Note : on pourrait passer en ingress sur les LBs. (pour le moment on utilise le mécanisme External LB)
REPARLONS UN PEU APPLI ▸ pour vraiment utiliser correctement k8s il faut des applications/micro services prévu/pensé pour ! ▸ cela ne sert à rien de faire rentrer une grosse appli existante dans ce modèle ▸ Monolithe => Micro Service ▸ le plus stateless possible ▸ Application instrumentalisé ▸ Application "cloud ready" ▸ 12 factors apps
REPARLONS UN PEU APPLI ▸ règles chez eTF1 : ▸ utilisation d'image docker light (alpine) ▸ log formaté GELF (graylog), utilisation du x-request-id (et du fluentd pour les logs nginx) ▸ configuration : default.json/env.json + ENV_VARS + etcd ▸ /metrics (prometheus) et dashboard ▸ /liveness, /readiness ▸ circuit breaker ▸ gestion des limites cpu/mem ▸ applicatif qui a conscience que tout est éphémère (retry, ou soft kill) ▸ le dev(devops) est responsable de créer/gérer tout ceci et son pipeline Jenkins
EVOLUTIONS / FUTUR ▸ rester bleeding edge (et c'est pas facile) ▸ réseau : kube-router/bgp en cours ▸ coreos pour les os ? ▸ service mesher : envoy / istio / linkerd (grpc /rest ?) ▸ encore plus de monitoring / autodiscover ▸ Serverless / FAAS ▸ migrer toutes les applis sur k8s ▸ migrer sur une archi hybride OP/Cloud ▸ kill le legacy/ kill le lecacy / kill le legacy
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}