本資料はSatAI.challengeのサーベイメンバーと共に作成したものです。
SatAI.challengeは、リモートセンシング技術にAIを適用した論文の調査や、より俯瞰した技術トレンドの調査や国際学会のメタサーベイを行う研究グループです。speakerdeckではSatAI.challenge内での勉強会で使用した資料をWeb上で共有しています。
https://x.com/sataichallenge
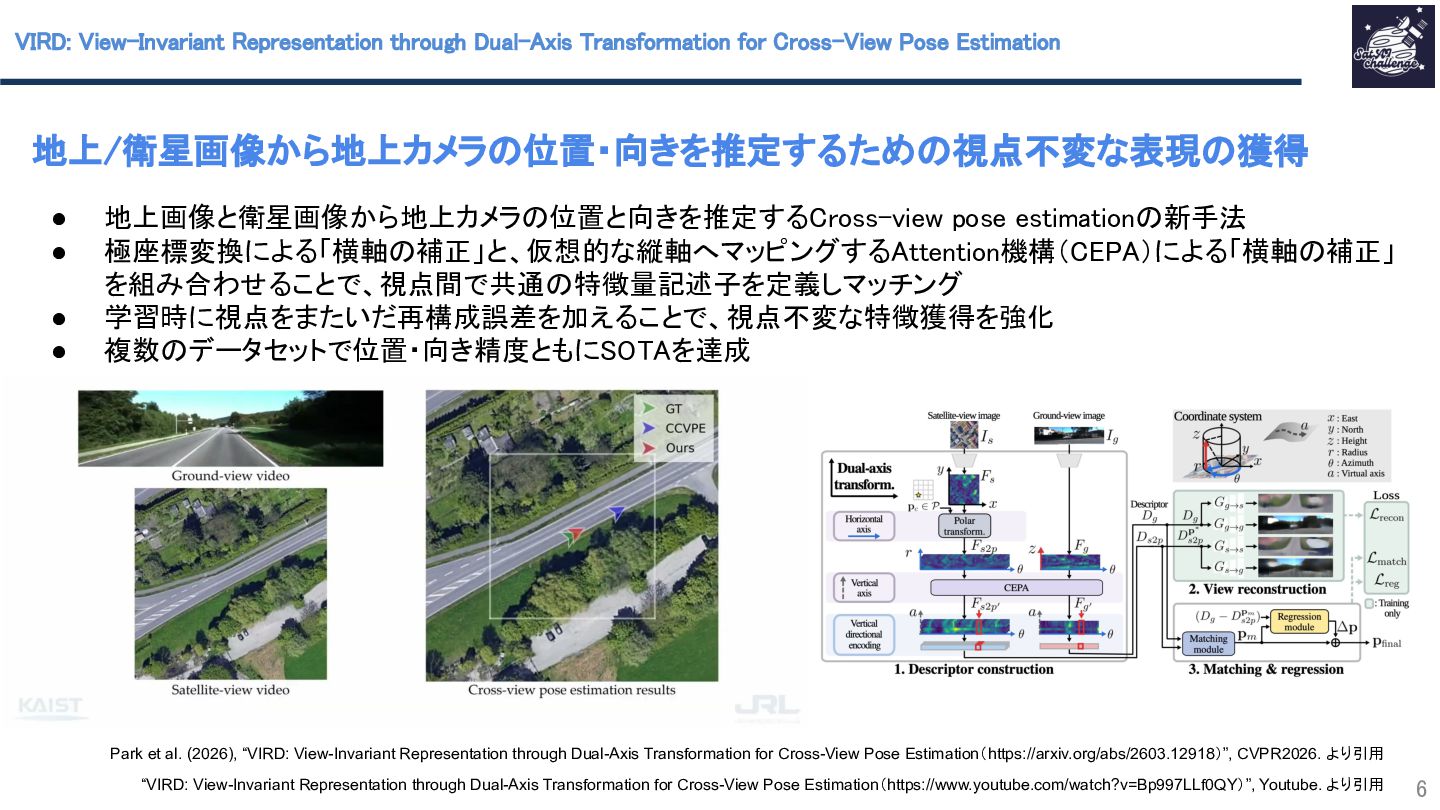
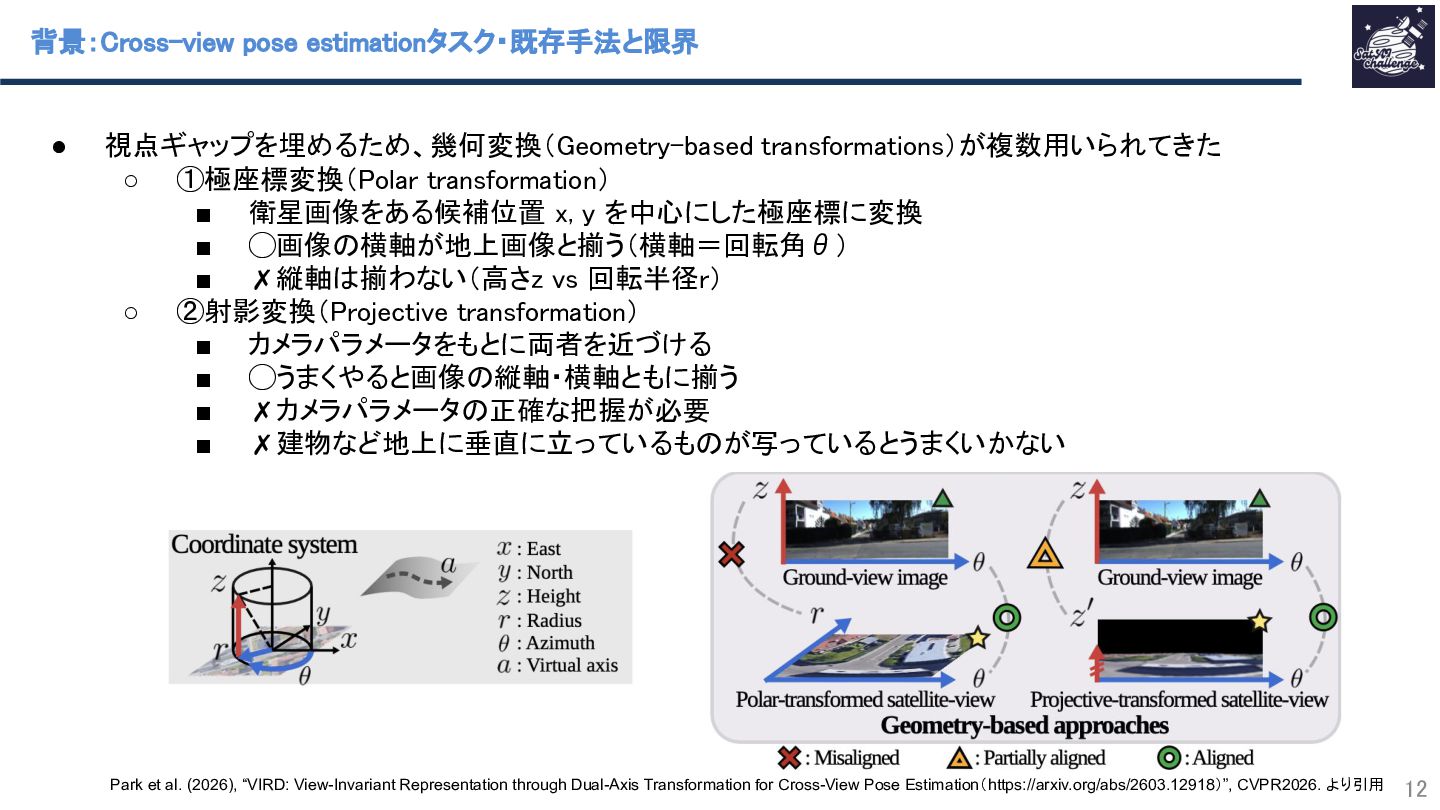
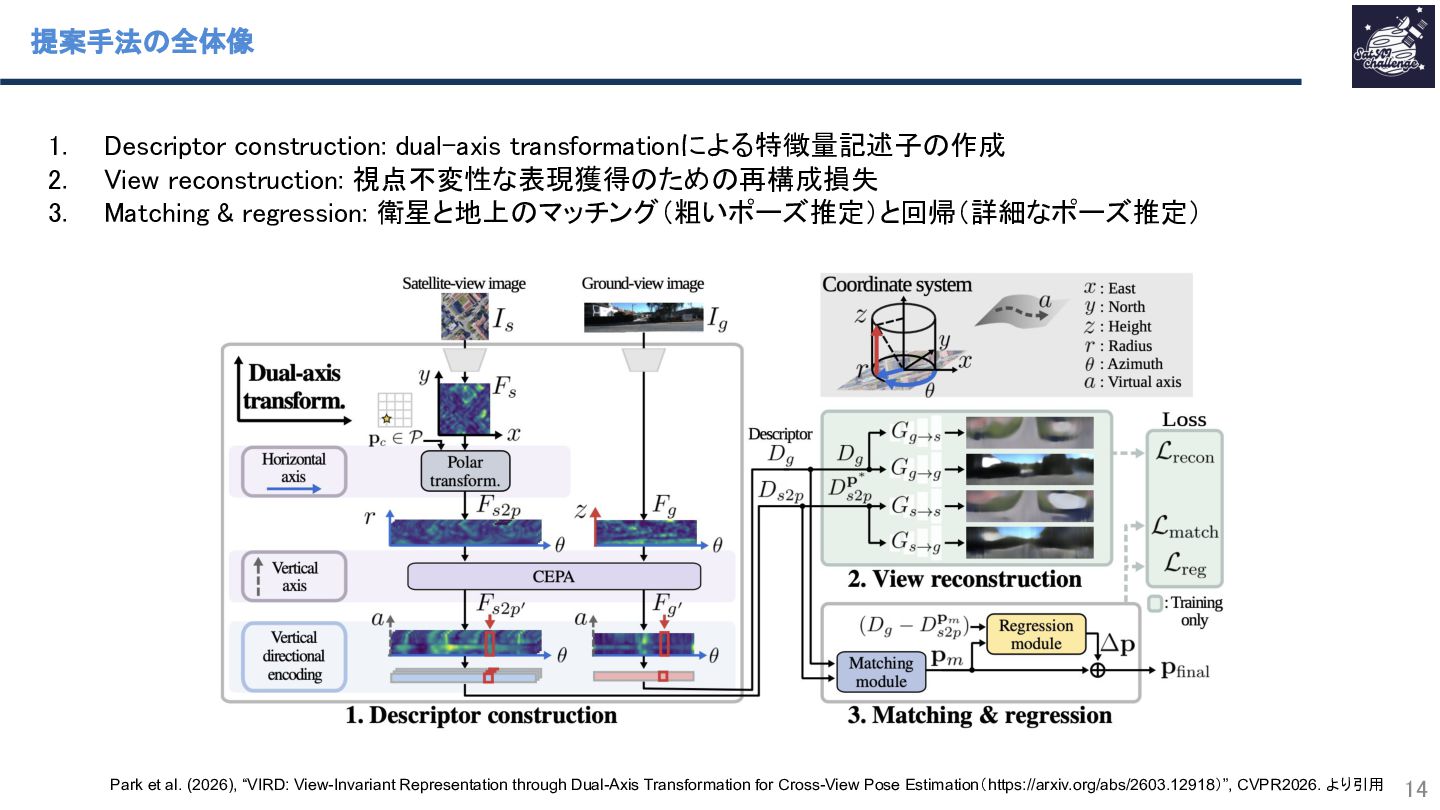
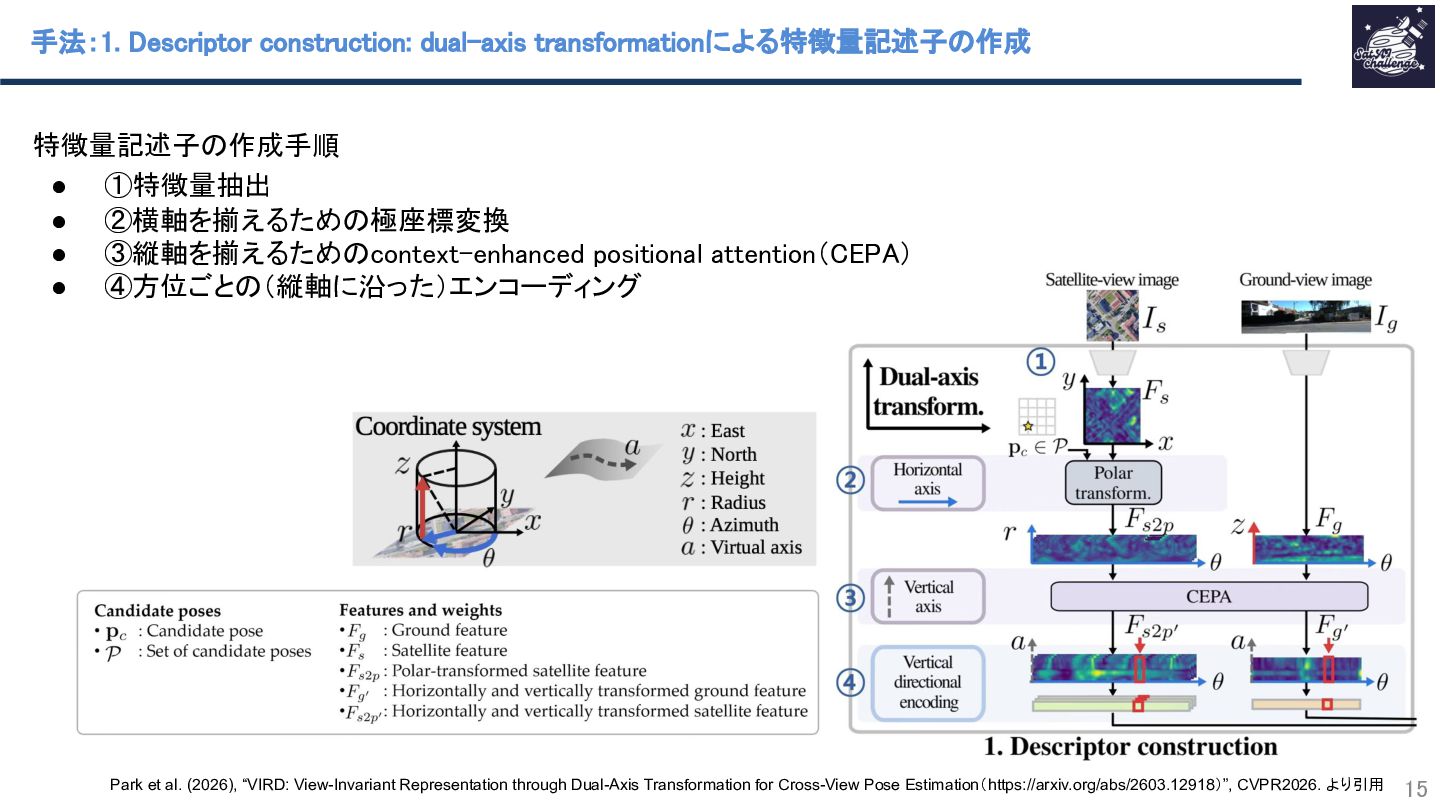
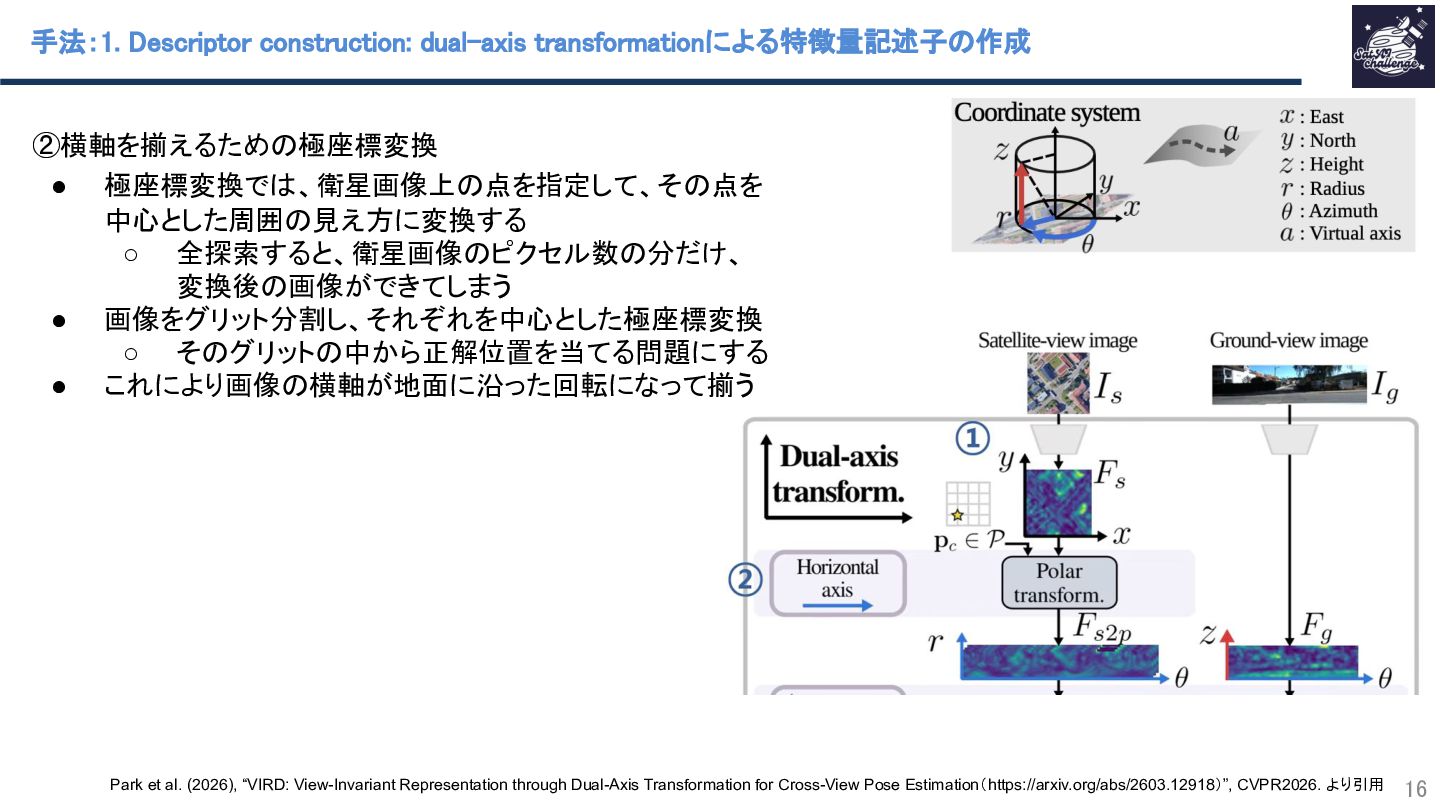
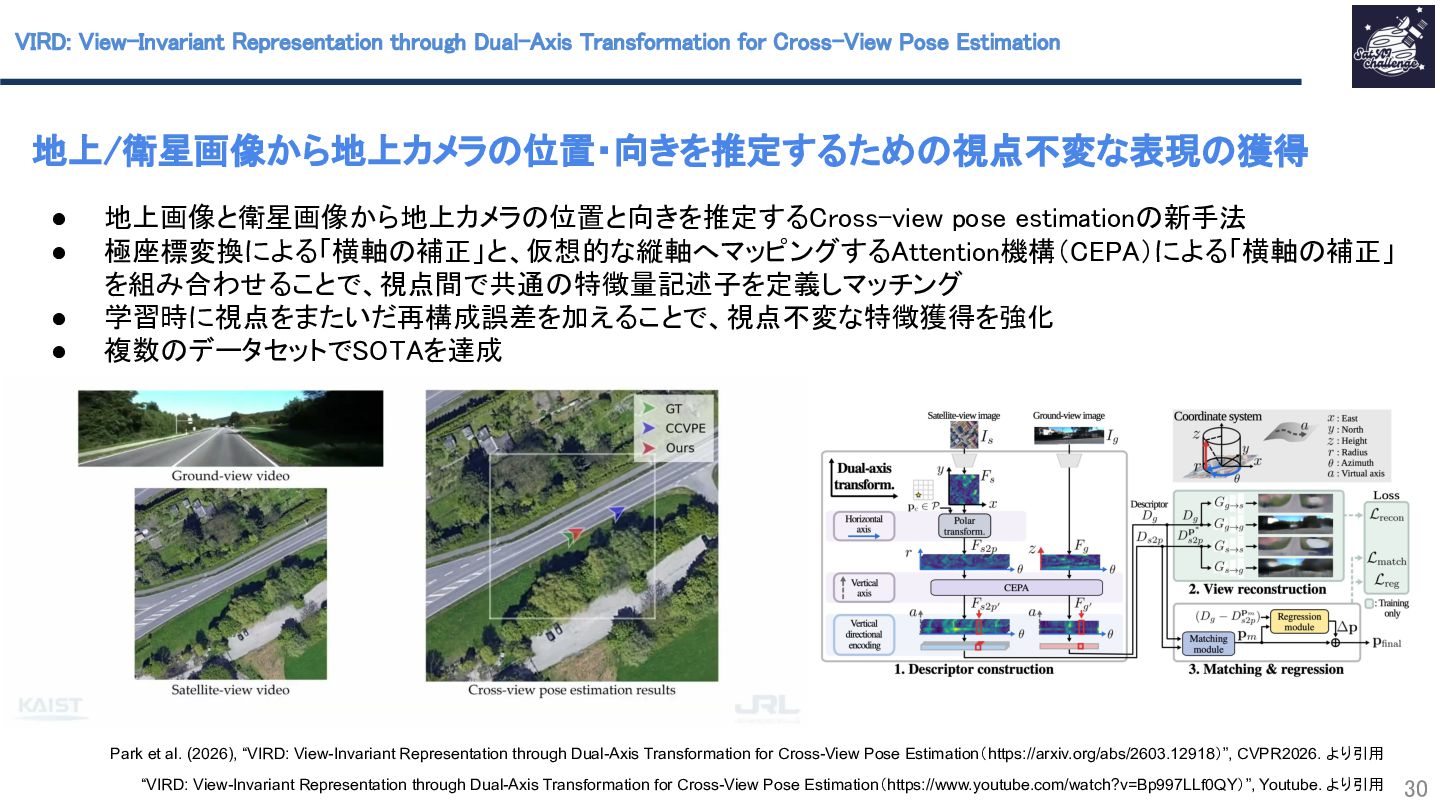
本研究では、地上画像と衛星画像から地上カメラ位置と向きを推定するCross-view pose estimationと呼ばれる問題の新手法を提案しています。従来の手法では地上画像と衛星画像の視点のギャップを適切な座標変換により埋める点に難しさがありました。極座標変換による横軸補正と、仮想的な縦軸へマッピングするAttention機構(CEPA)による縦軸補正を組み合わせることで、視点間で共通特徴量記述子を定義しマッチングすることでこの課題を克服しました。また、学習時に視点をまたいだ再構成誤差を加えることで、視点不変な特徴獲得を強化しています。複数データセットで位置・向き精度ともにSOTAを達成しました。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
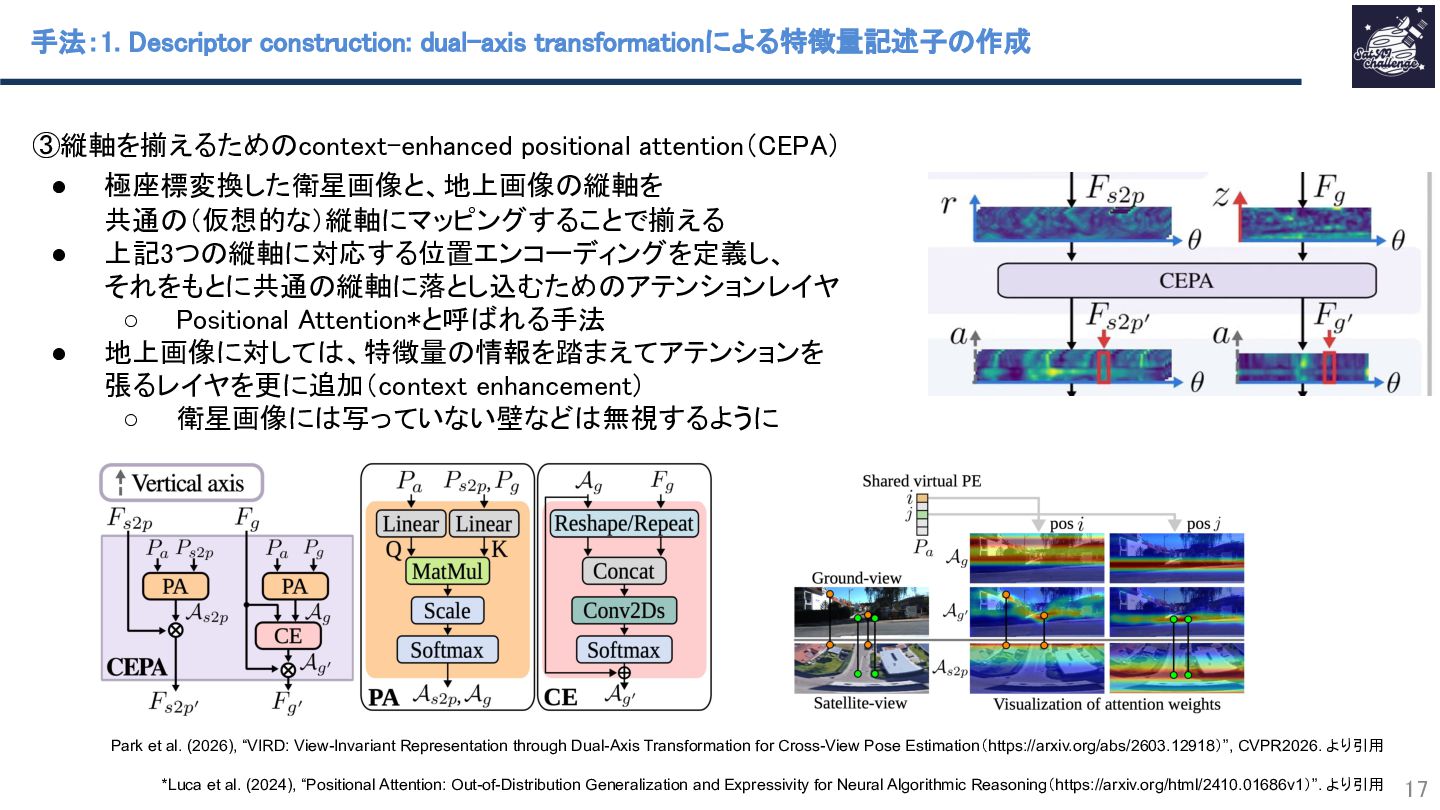{kind=link}
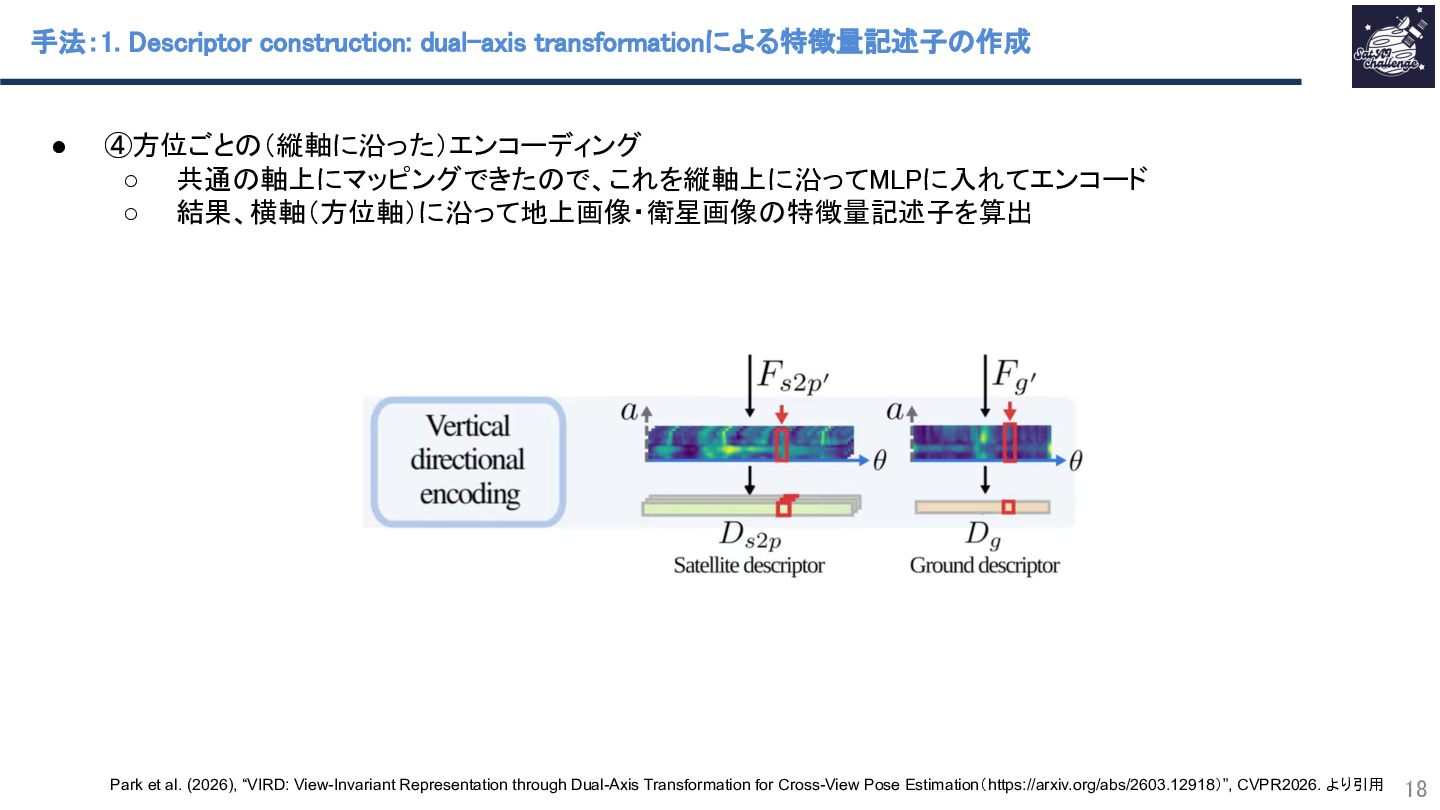{kind=link}
{kind=link}
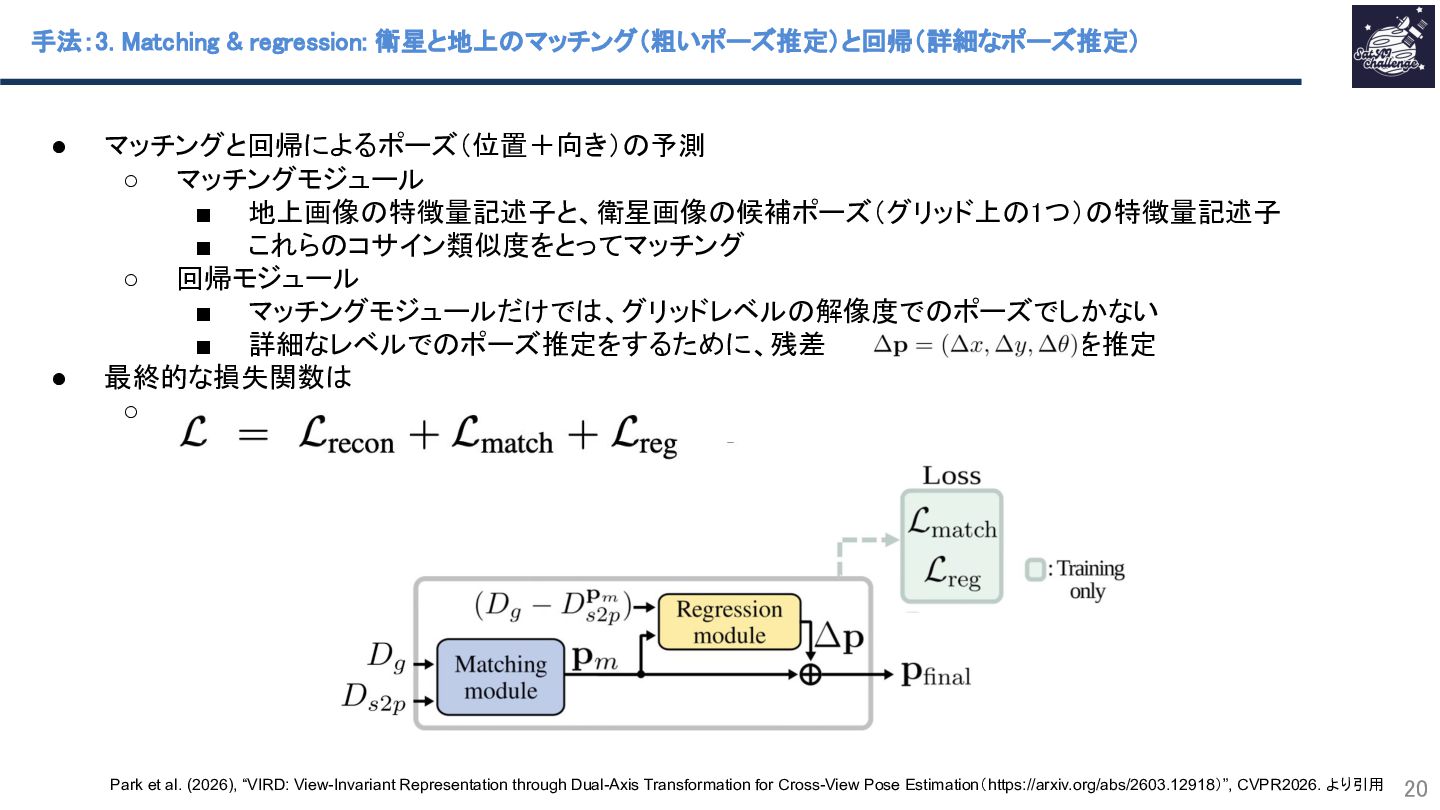{kind=link}
{kind=link}
{kind=link}
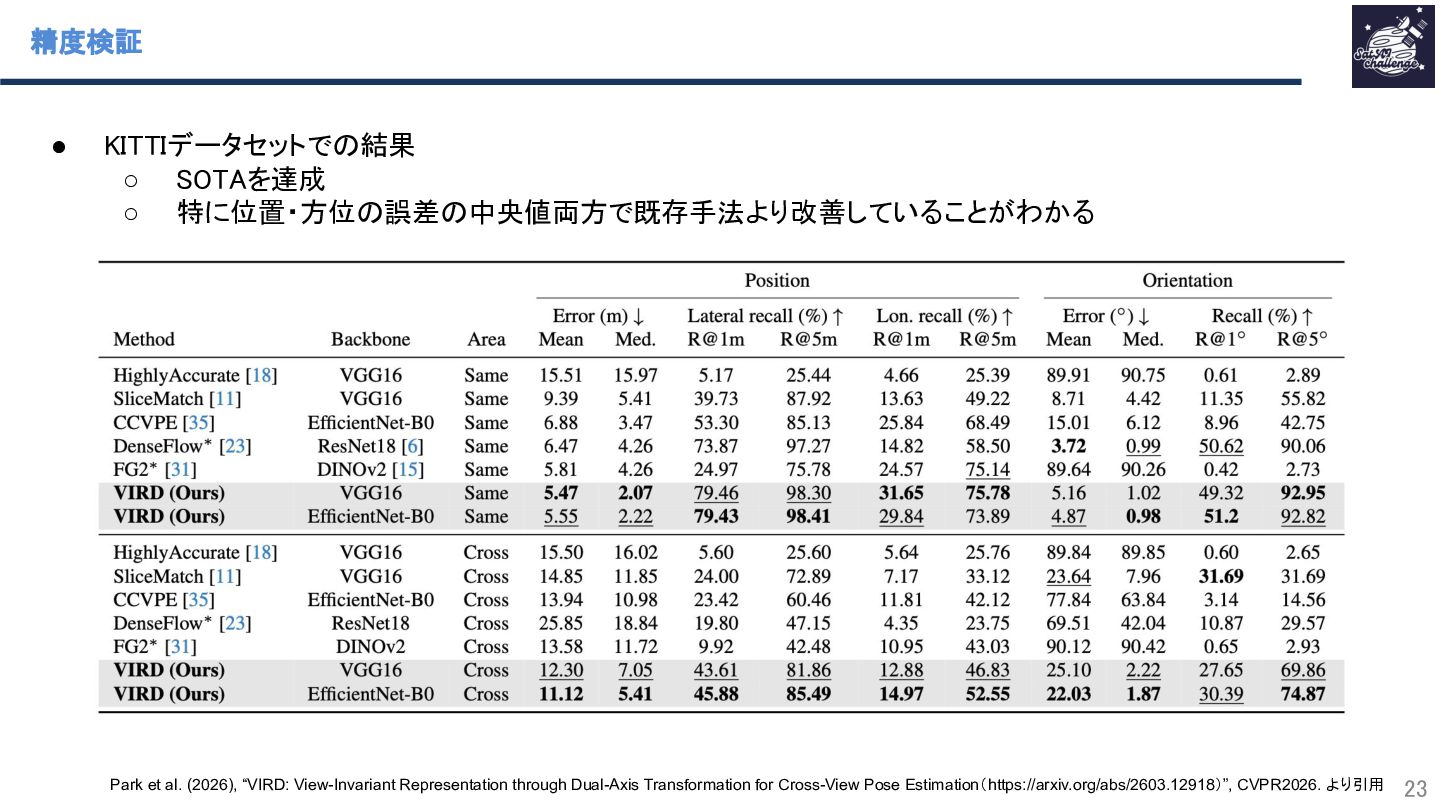{kind=link}
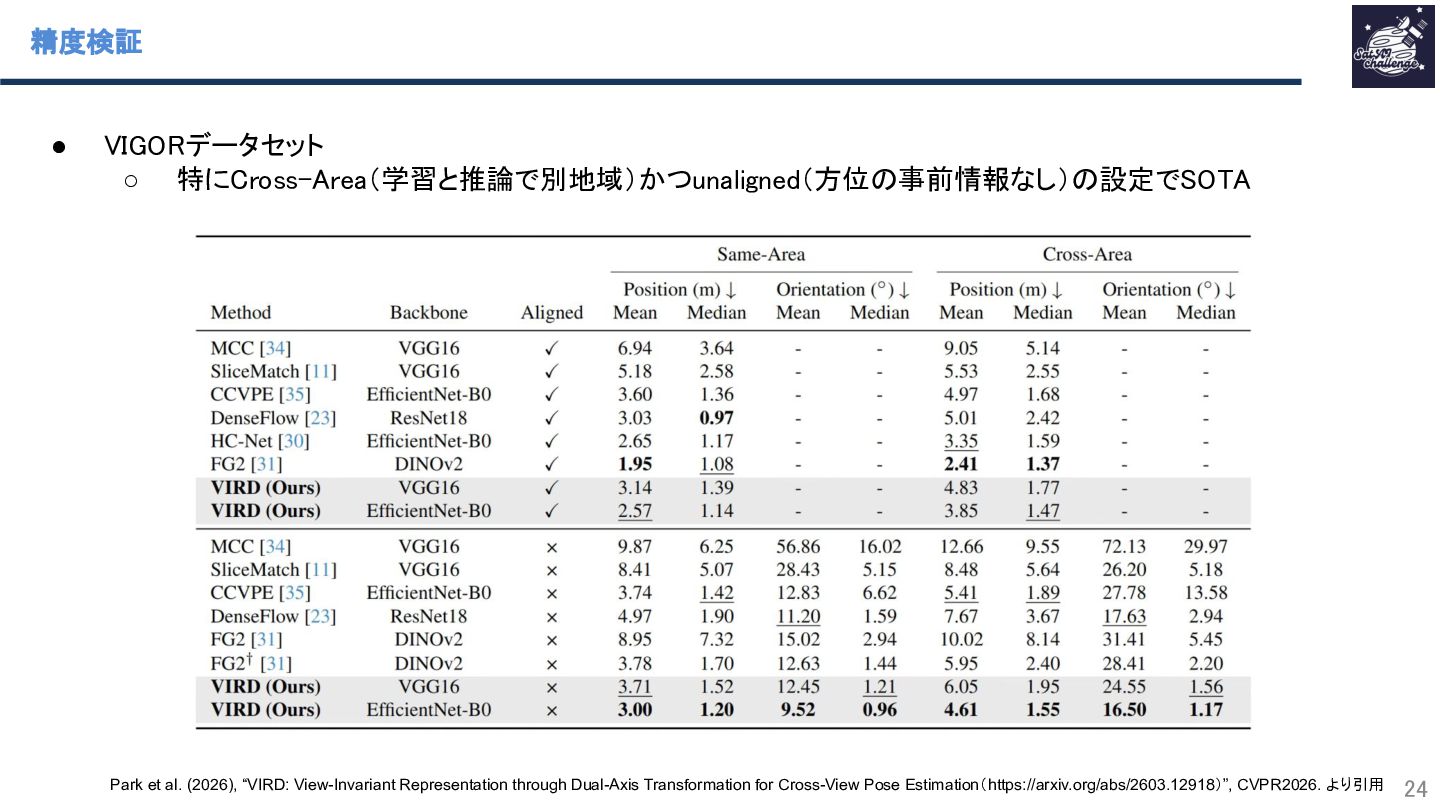{kind=link}
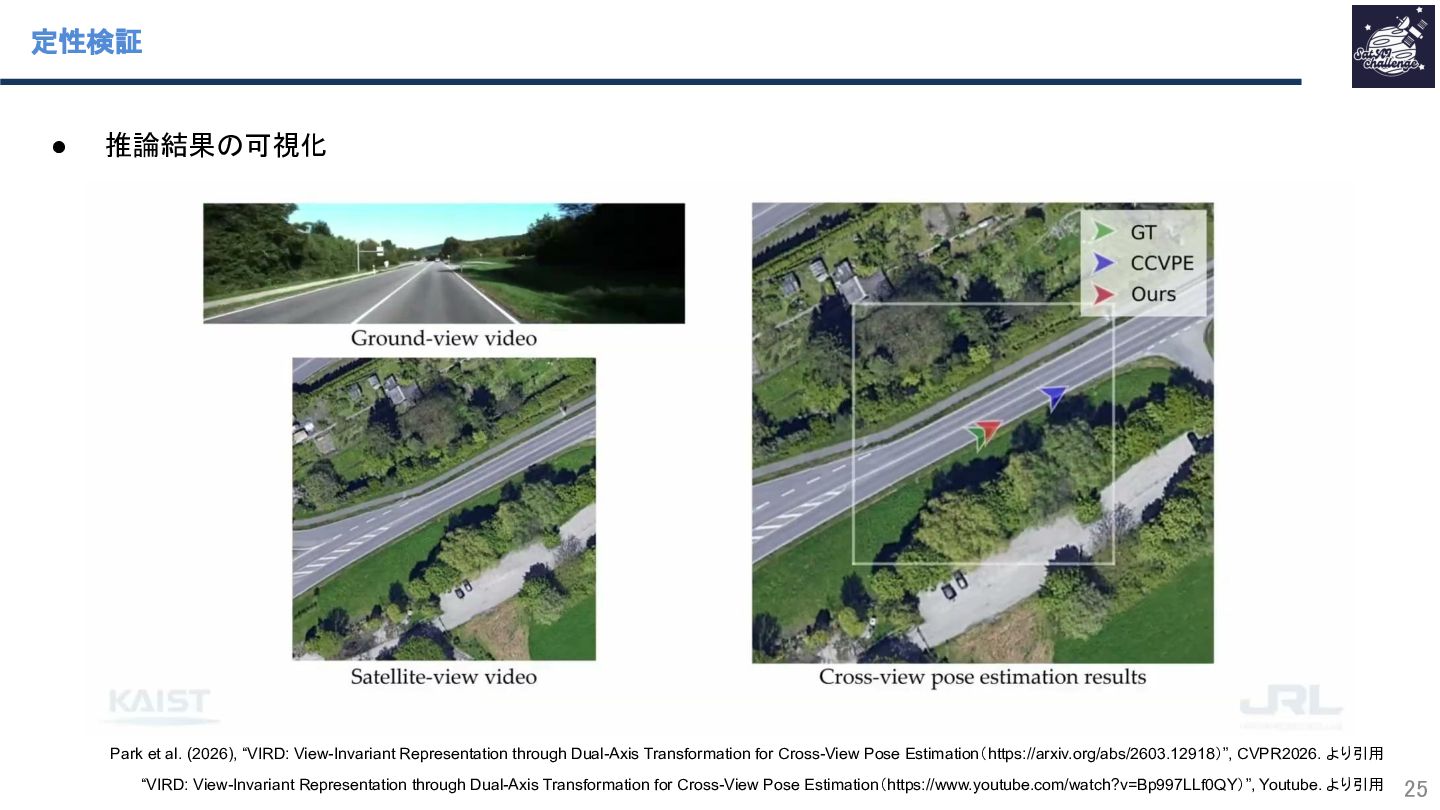{kind=link}
{kind=link}
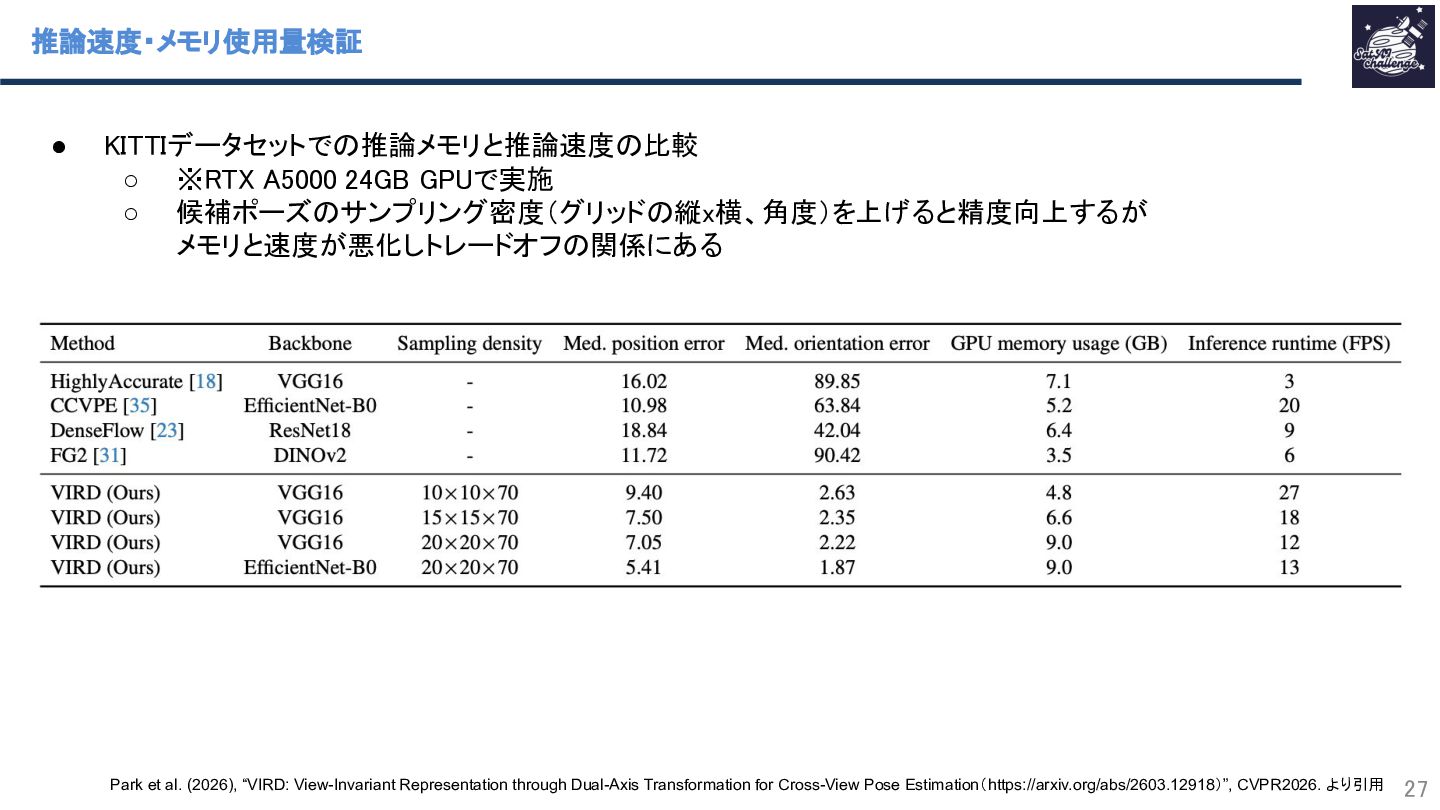{kind=link}
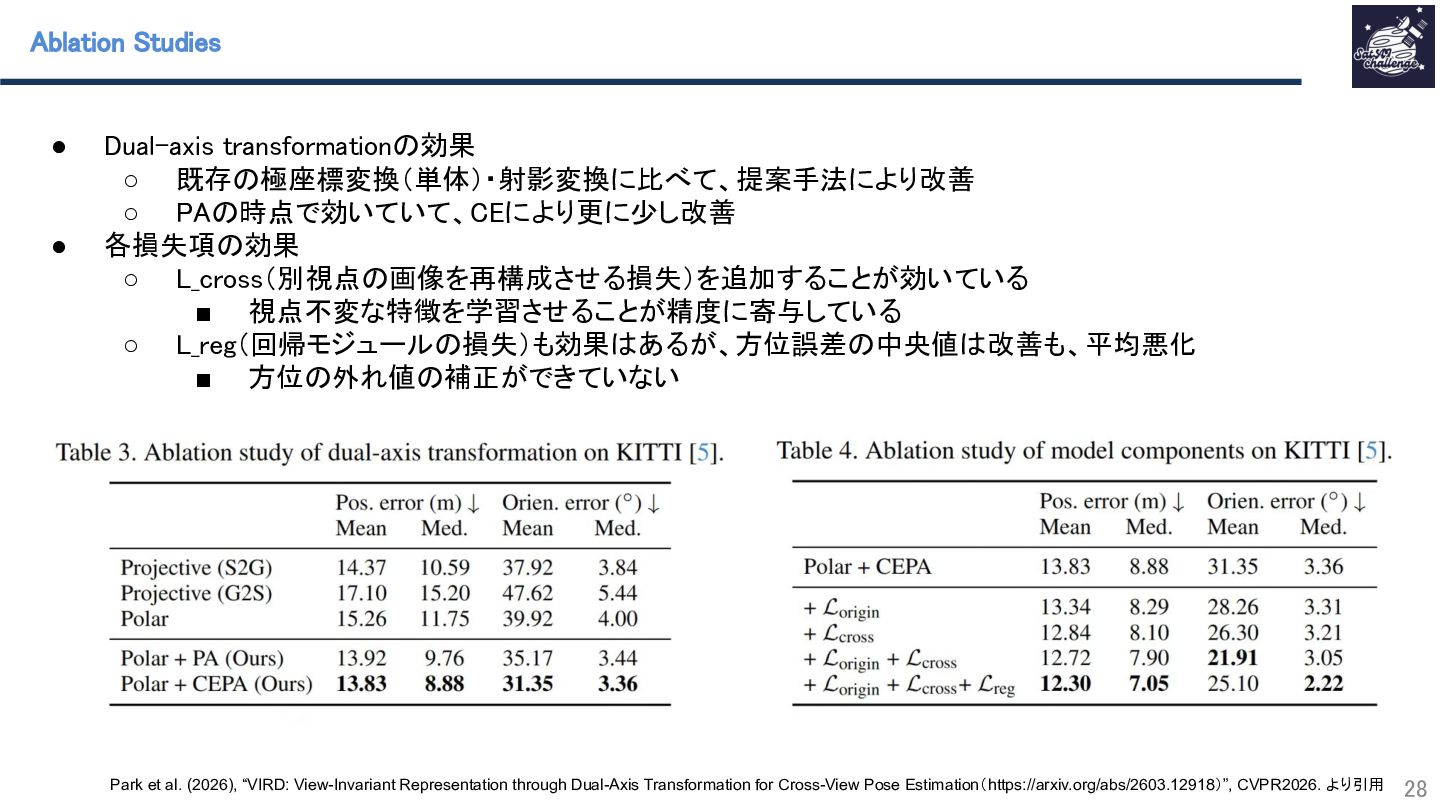{kind=link}
{kind=link}
{kind=link}