Александр Сербул
руководитель направления контроля качества и интеграции внедрений, 1С-Битрикс
SECR 2019
В докладе расскажем, как мы делали скоринг Лидов и других сущностей в массовой облачной CRM Битрикс24: от прототипа до “боевого” высоконагруженного веб-сервиса. Доклад будет полезен разработчикам, аналитикам, менеджерам, интересующимся вопросами скоринга, классификации в CRM и эффективного применения алгоритмов машинного обучения для решения бизнес-задач. Специально для SECR сделаем дополнительное техническое описание подробностей прототипа, алгоритмов и пр. Дополнительно готовы рассказать также о голосовом управлении в Битрикс24 и возможностях библиотеки DeepPavlov.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
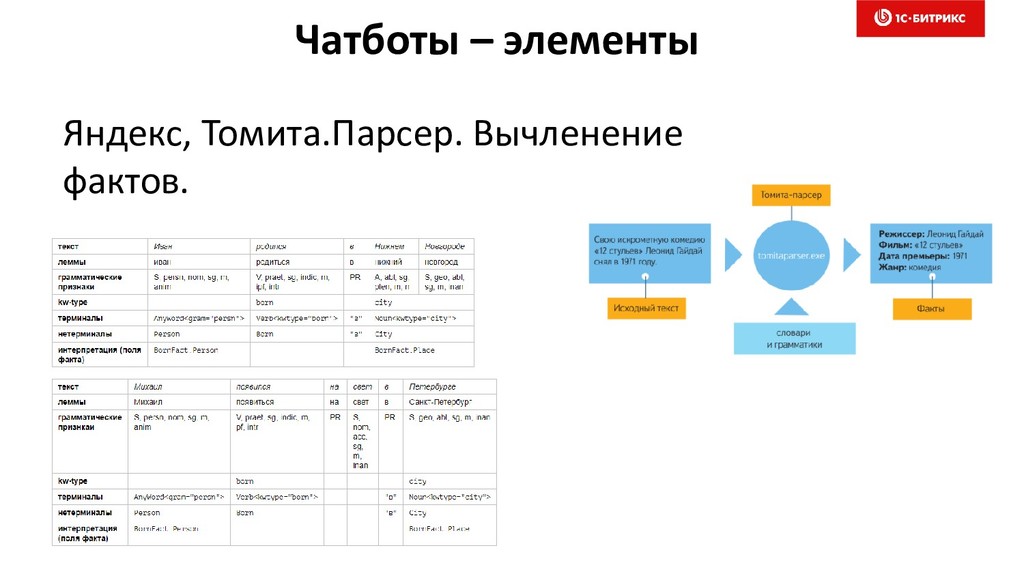{kind=link}
{kind=link}
{kind=link}
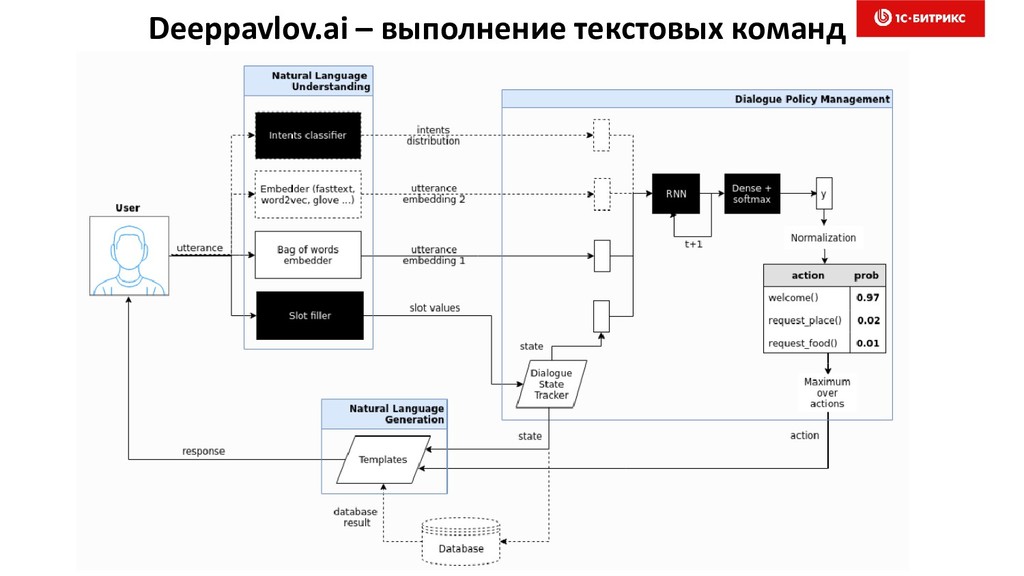{kind=link}
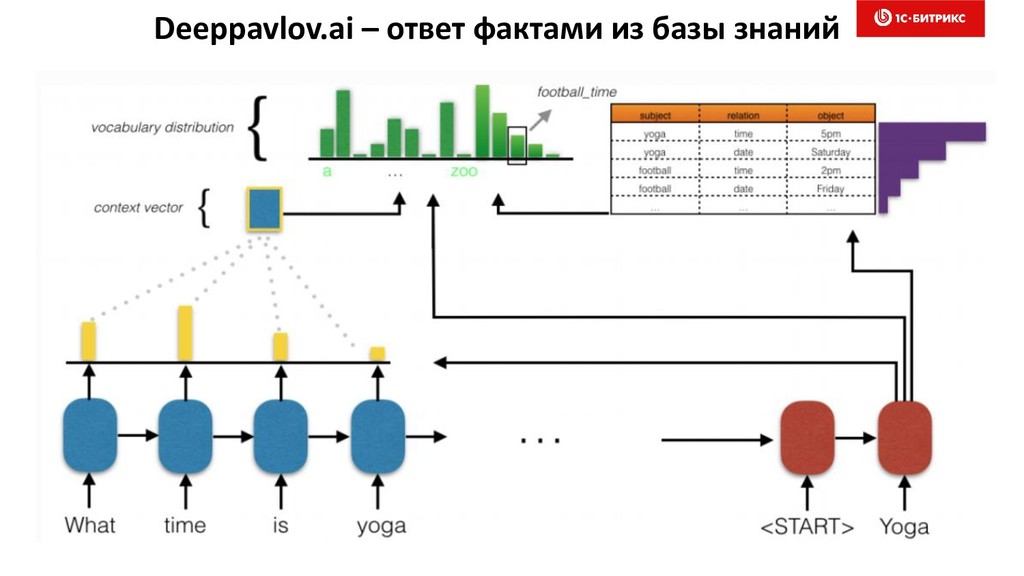{kind=link}
{kind=link}
{kind=link}
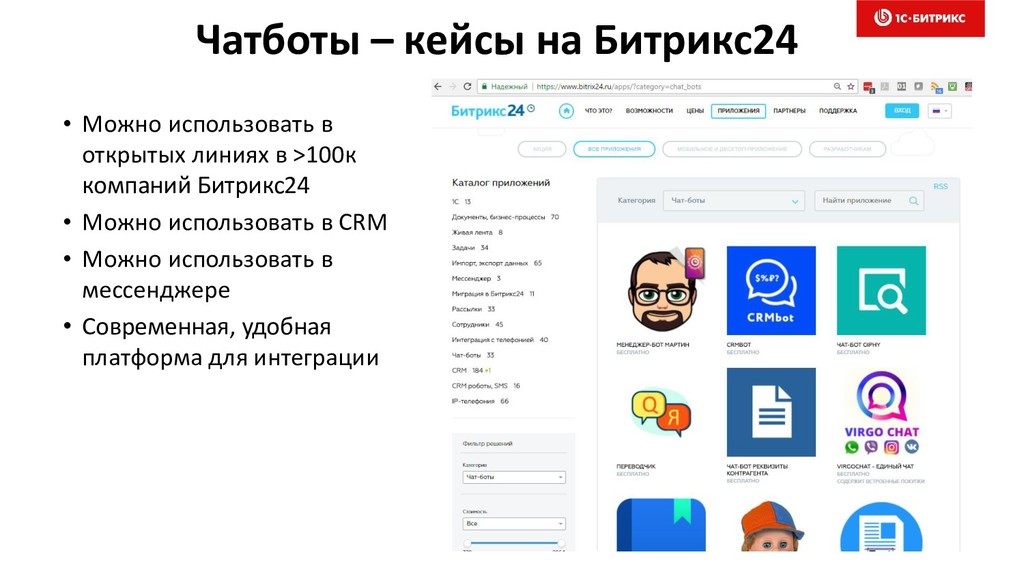{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Спасибо за внимание! Вопросы? Александр Сербул @AlexSerbul Alexandr Serbul [email protected]](https://files.speakerdeck.com/presentations/e8e3abc75b49437c88eb1b3e18864bfc/slide_68.jpg){kind=link}