辻 栄翔(京都大学) Spatial AI Network勉強会, 2025.4.22 https://www.robots.ox.ac.uk/~vgg/research/dynamic-point-maps/ Edgar Sucar, Zihang Lai, Eldar Insafutdinov, Andrea Vedaldi
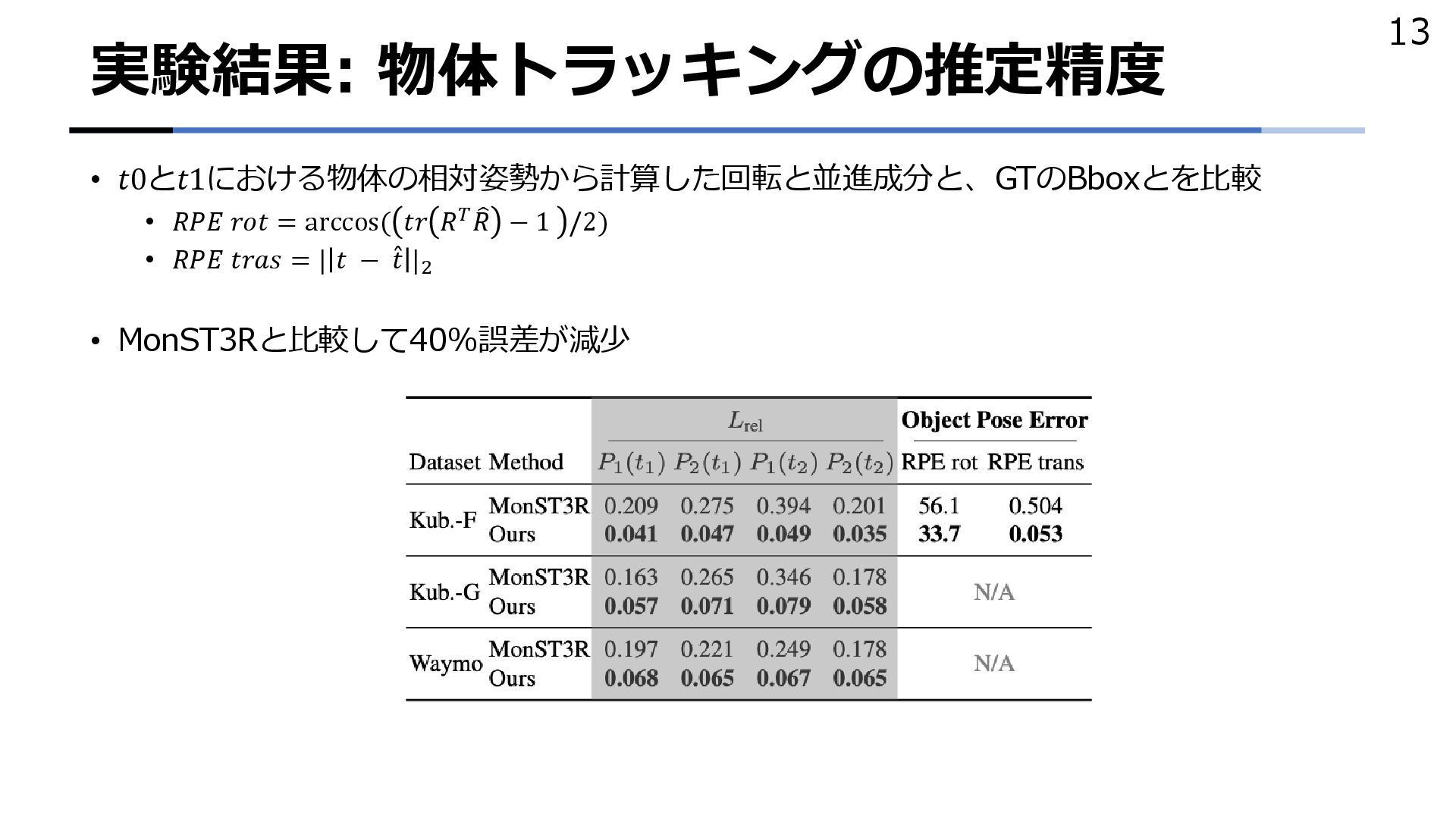
DUSt3Rで推定した点マップにRAFTを適用するため、途中でカメラ姿勢を推定 • 時間的な一貫性を保つために複数フレームの統合処理 5 Zhang et al., MonST3R: A Simple Approach for Estimating Geometry in the Presence of Motion, ICLR, 2025
{kind=link}
{kind=link}
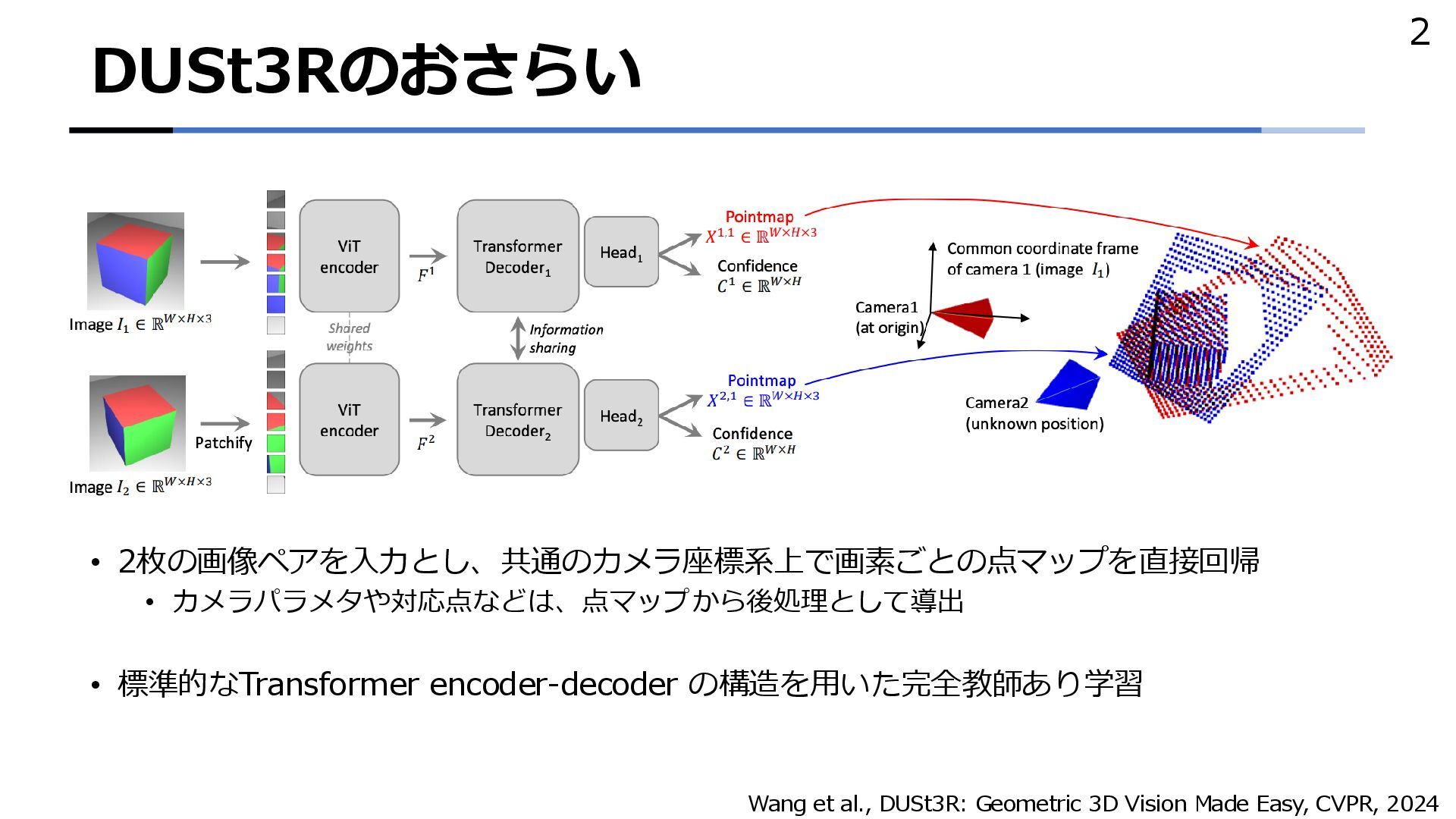{kind=link}
{kind=link}
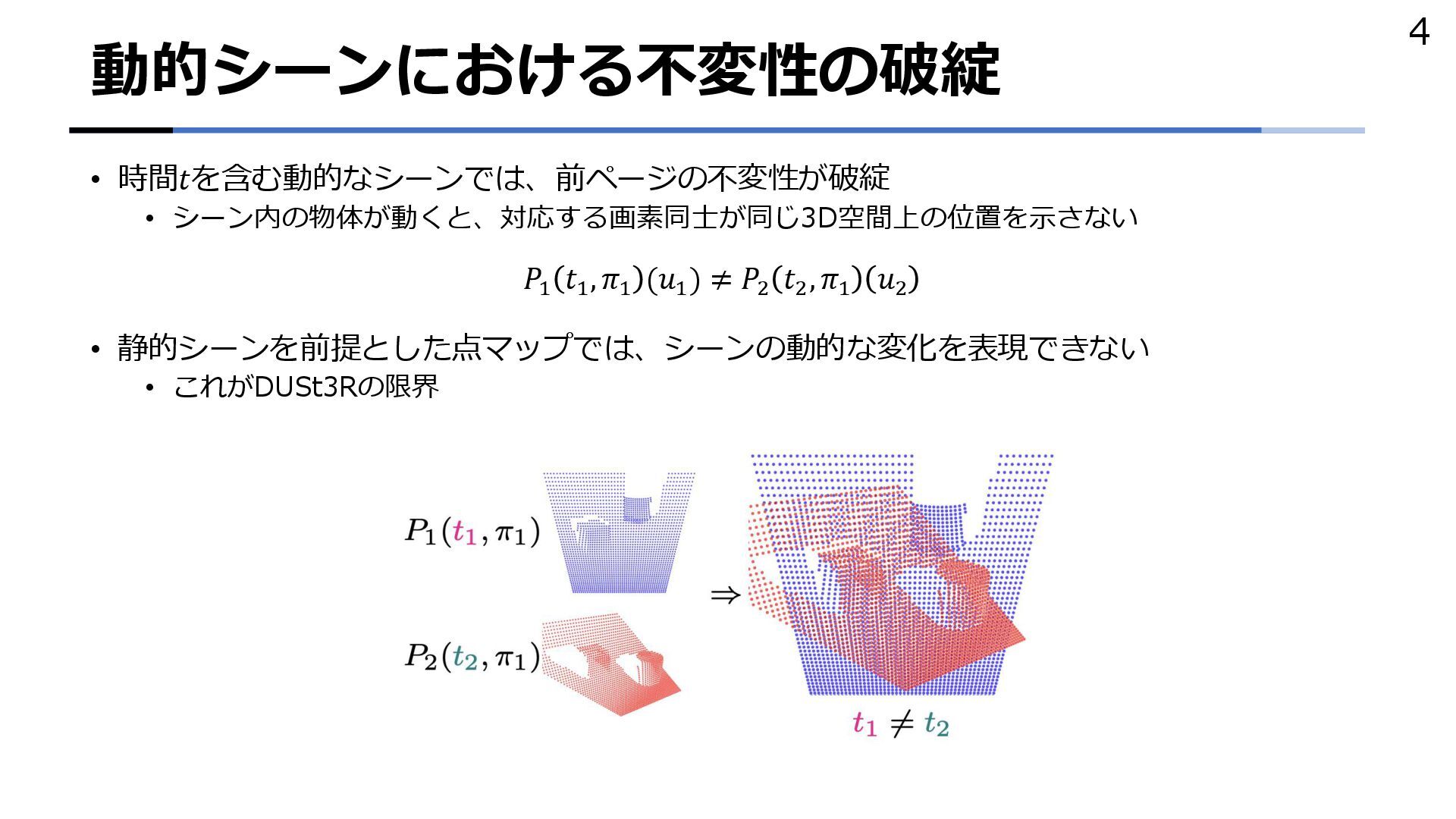{kind=link}
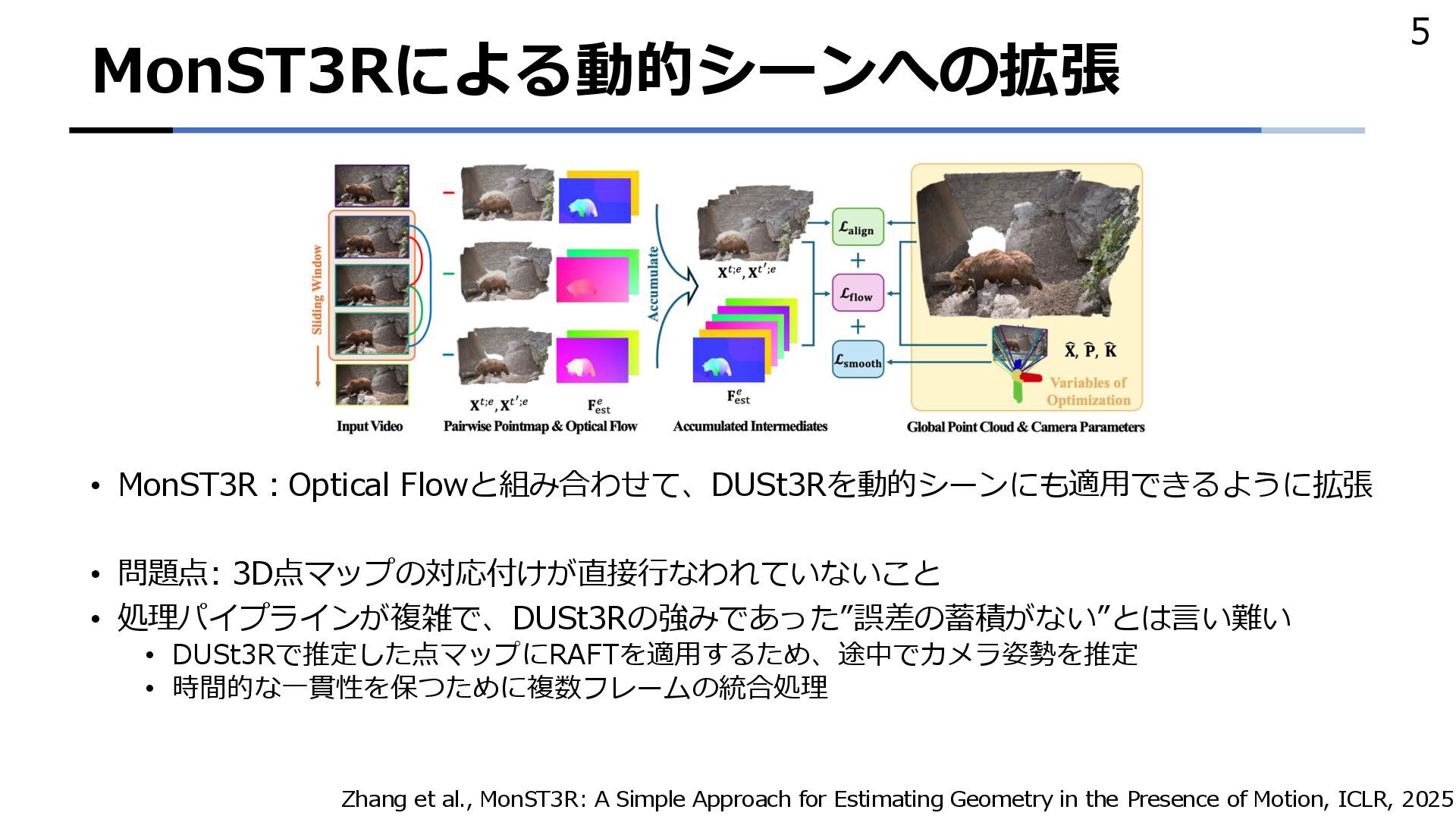{kind=link}
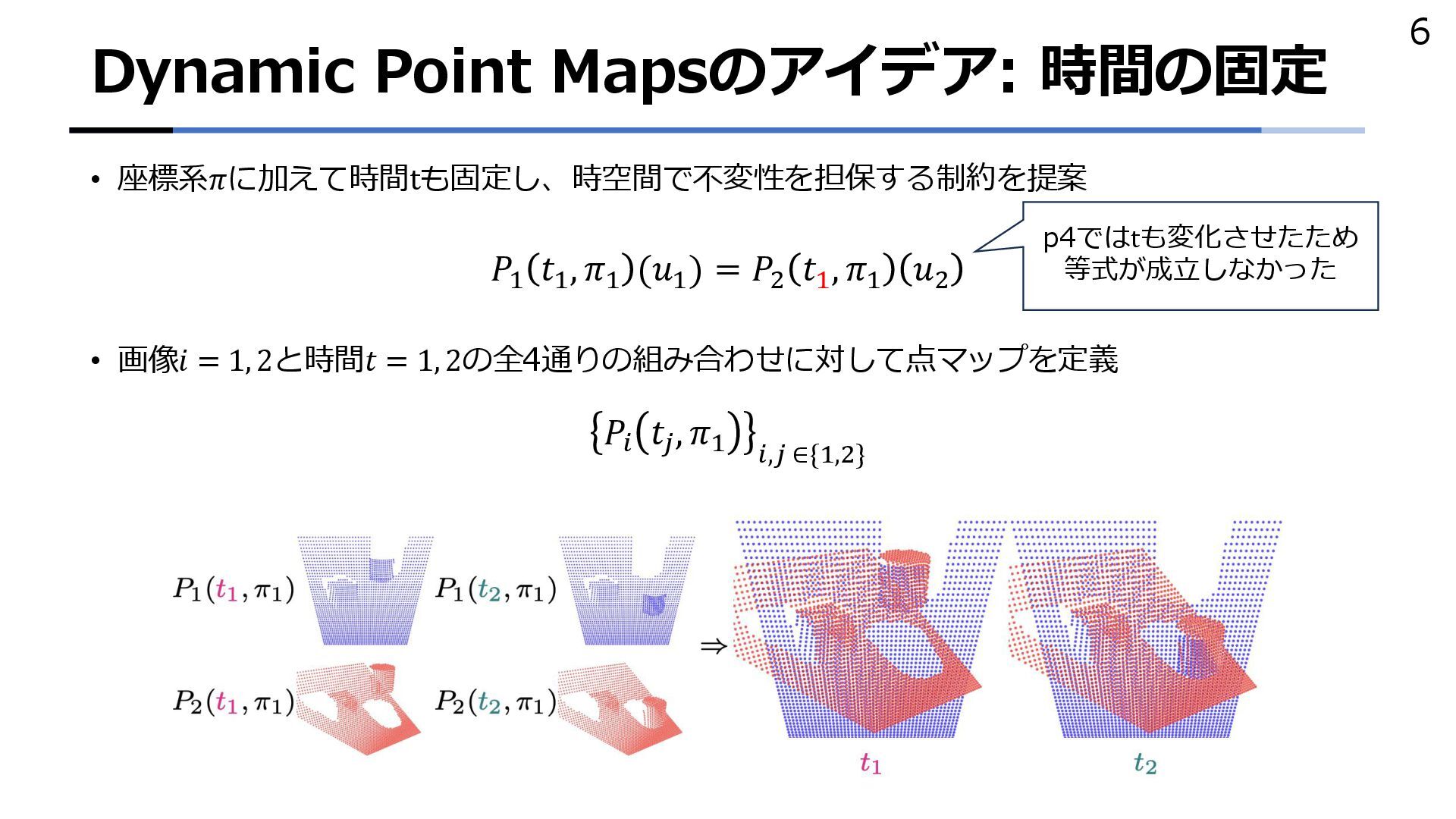{kind=link}
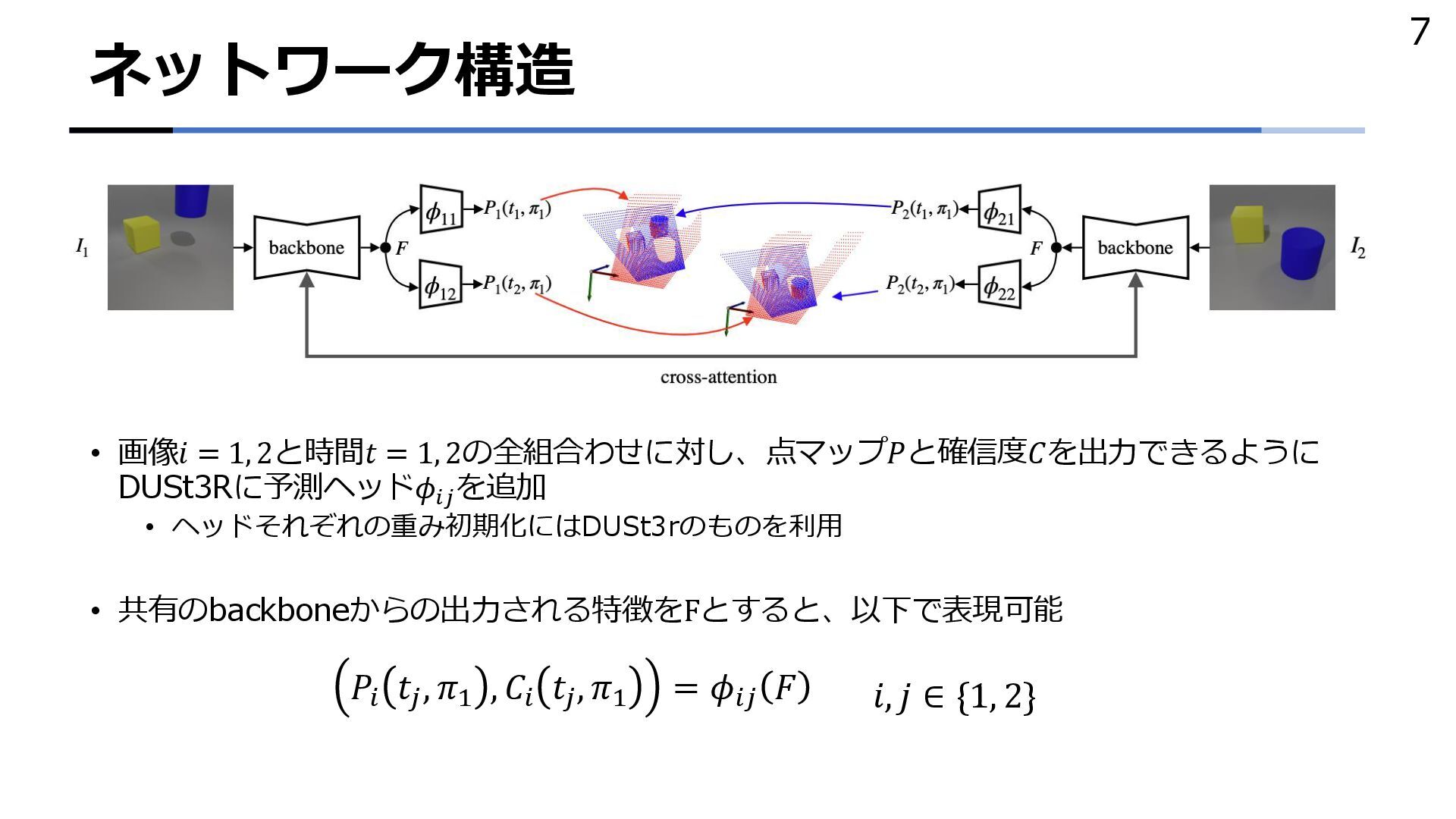{kind=link}
{kind=link}
{kind=link}
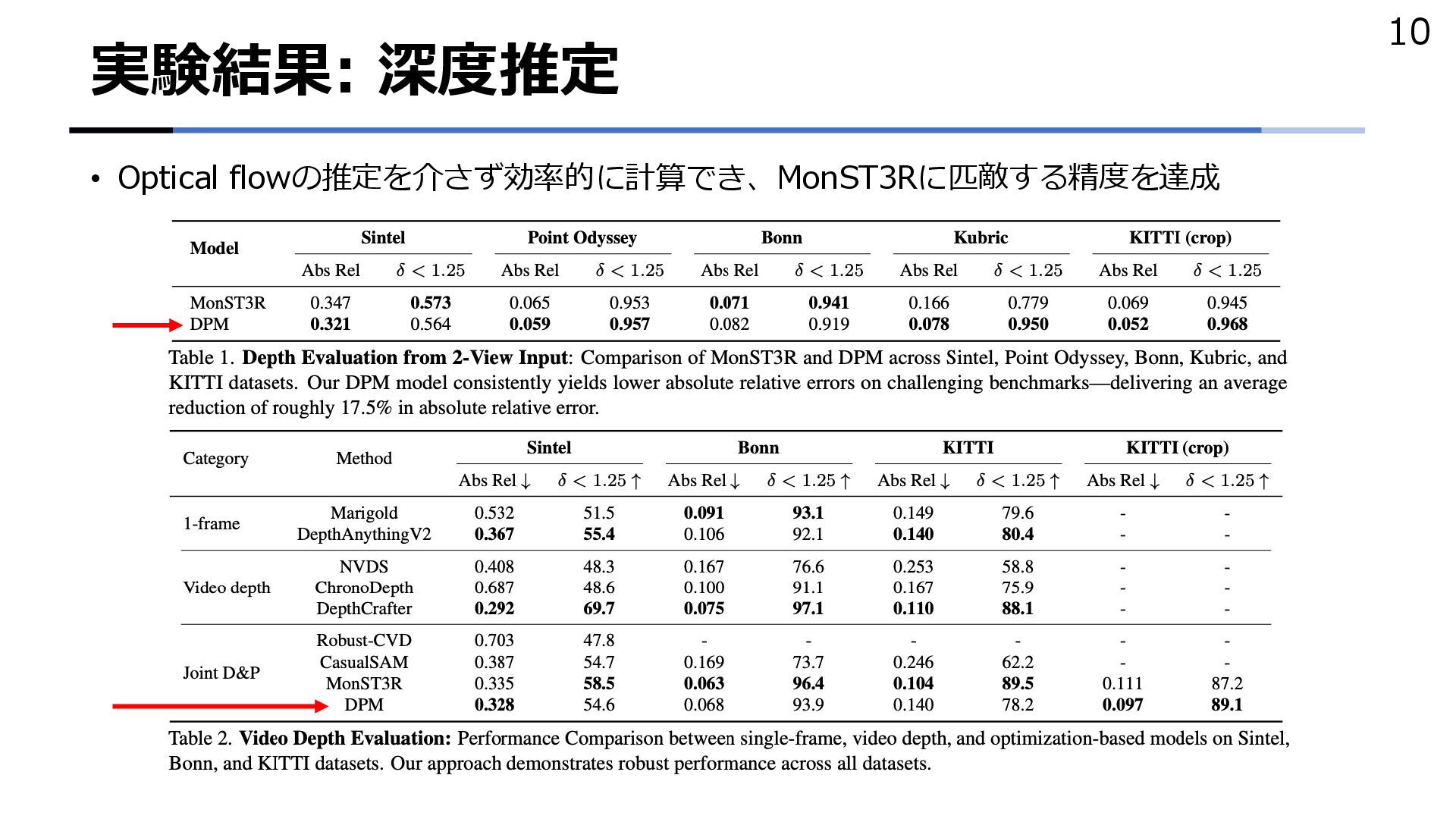{kind=link}
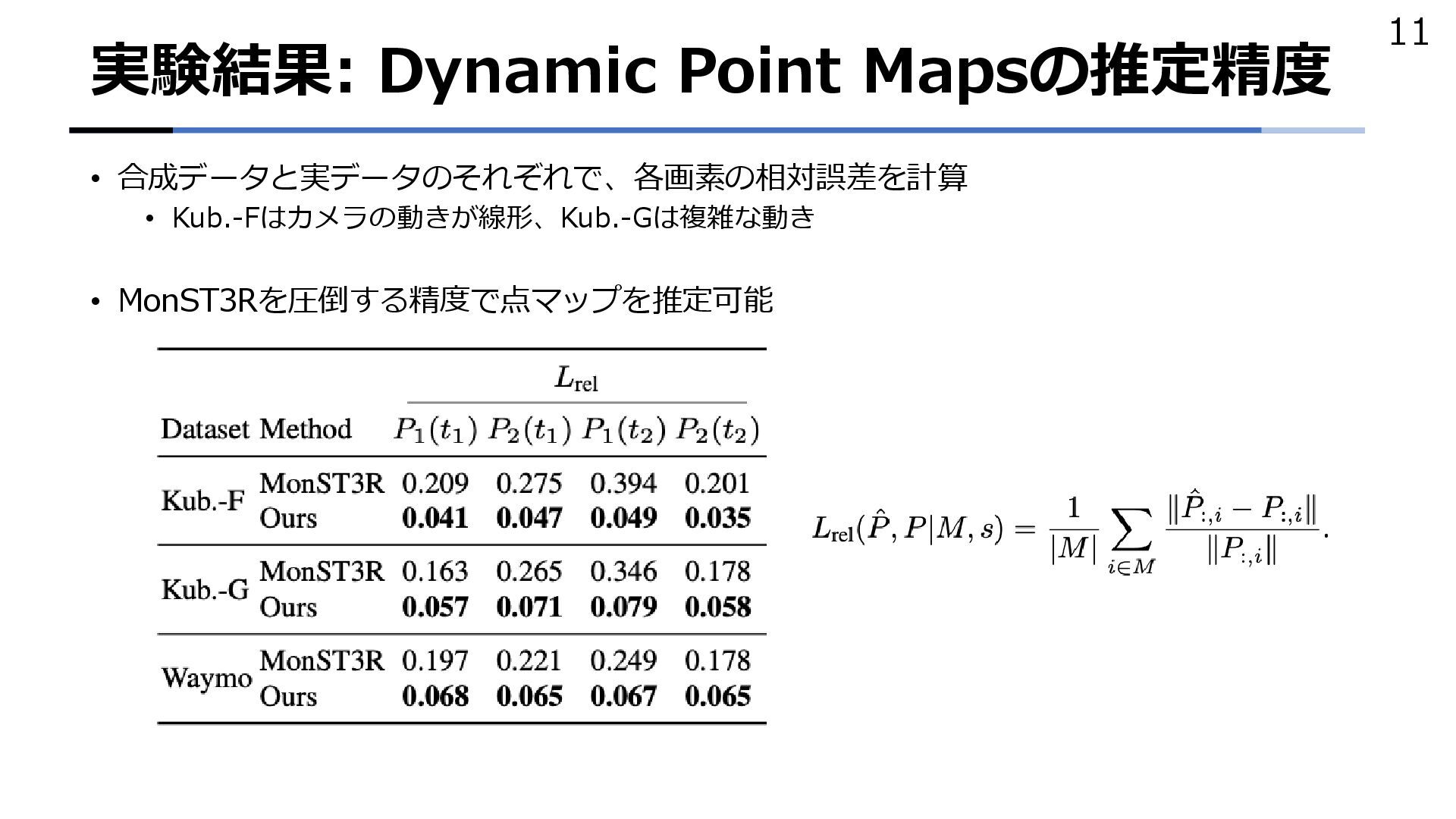{kind=link}
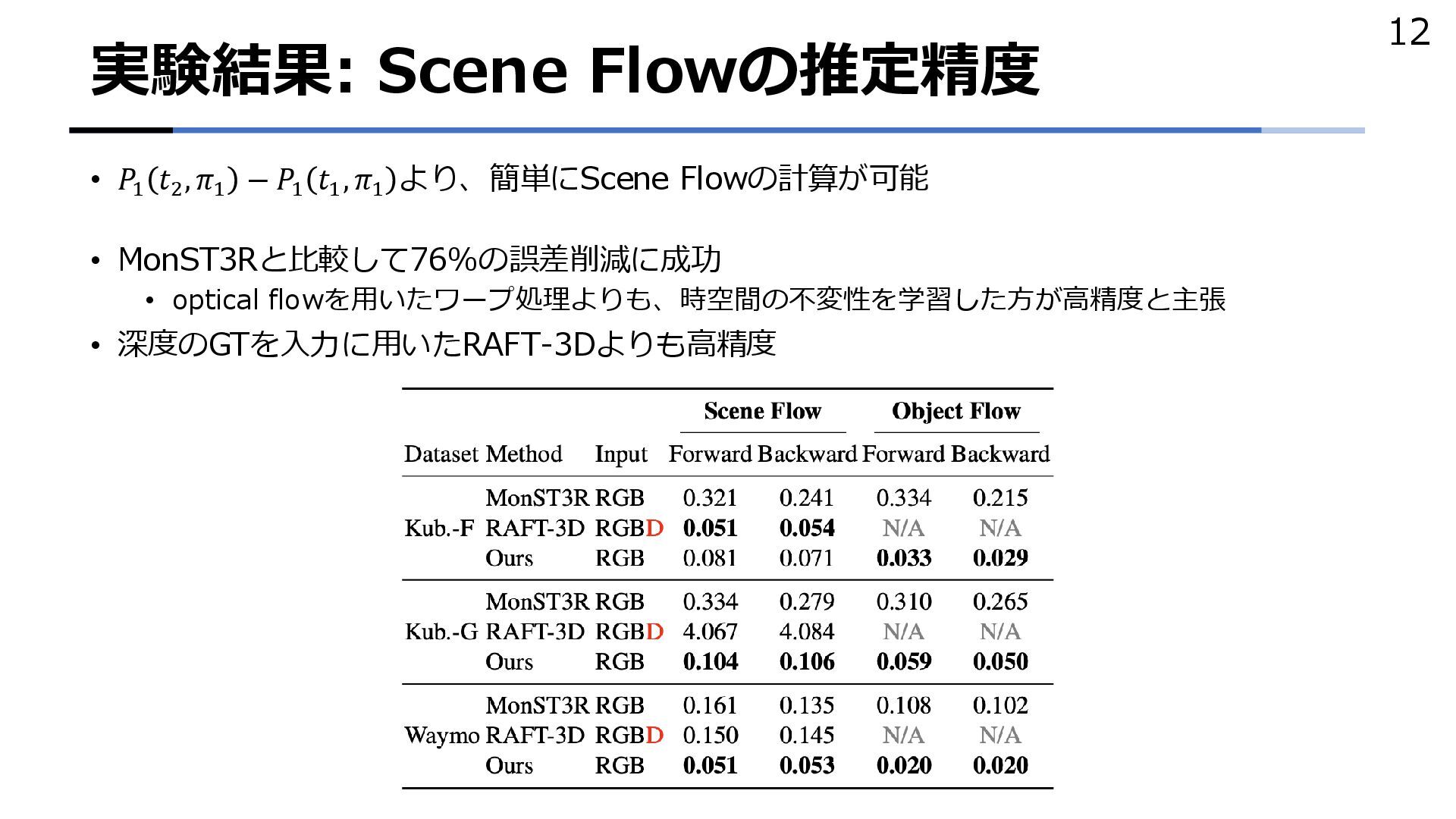{kind=link}
{kind=link}
{kind=link}
{kind=link}