Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
理系ナビ_日本におけるAI活用の状況と注目トピック
Search
takumamitarai
September 29, 2021
Technology
2.6k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
理系ナビ_日本におけるAI活用の状況と注目トピック
2021/09/29の理系ナビ プログラムにおける発表資料です。
takumamitarai
September 29, 2021
More Decks by takumamitarai
See All by takumamitarai
ホテルニューグランドを読み解く~横浜復興と文化融合~
takumamitarai
0
290
Other Decks in Technology
See All in Technology
スタートアップにAmazon EKSは早すぎる? マルチプロダクト戦略を加速する Platform Engineeringの実践 / Is Amazon EKS Too Soon for Startups? Practical Platform Engineering to Accelerate a Multi-Product Strategy
elmodev09
1
460
現地で盛り上がった WWDC26 Keynote
zozotech
PRO
1
270
アジャイルな経理と Claude Code と 経営の未来
kawaguti
PRO
3
160
SONiCのLinuxベースを活かしたZabbix監視
sonic
0
230
FPGAの開発コンペでZephyrを使ってみた
iotengineer22
0
150
人材育成分科会.pdf
_awache
4
300
Oracle AI Database@Google Cloud:サービス概要のご紹介
oracle4engineer
PRO
6
1.6k
2026TECHFRESH畢業分享會 - 原生還是跨平台? App 開發踩坑實錄
line_developers_tw
PRO
0
1.3k
【セミナー資料】Claude Code をセキュアに使うための考え方と設定の勘どころ / Claude Code Webinar 20260616
masahirokawahara
2
420
あなたの知らないPDFのアクセシビリティ
lycorptech_jp
PRO
0
220
自分が詳しくない領域でAIを使う #プロヒス2026
konifar
16
5.5k
生成 AI 実践ガイド (概略版) AIガバナンス編
asei
0
130
Featured
See All Featured
RailsConf 2023
tenderlove
30
1.5k
Leo the Paperboy
mayatellez
7
1.8k
HDC tutorial
michielstock
2
720
How to Ace a Technical Interview
jacobian
281
24k
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
950
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
Un-Boring Meetings
codingconduct
0
320
Writing Fast Ruby
sferik
630
63k
Raft: Consensus for Rubyists
vanstee
141
7.5k
Rails Girls Zürich Keynote
gr2m
96
14k
The Art of Programming - Codeland 2020
erikaheidi
57
14k
Transcript
日本におけるAI活用と注目トピック 電通国際情報サービス(ISID) X(クロス)イノベーション本部 AIテクノロジー部 AIトランスフォーメーションセンター 御手洗 拓真
2 アジェンダ 1: 自己紹介&はじめに 2: AI・機械学習とは? 3:日本におけるAI活用とAIの民主化 4:MLOpsと注目キーワード 5:さいごに
3 自己紹介&はじめに 01
4 御手洗拓真 所属: 電通国際情報サービス クロスイノベーション本部 AIトランスフォーメーションセンター 経歴: 2015年3月:慶應義塾大学総合政策学部卒(近代史・社会学専攻) 2015年4月:新卒でとあるSIerへ入社し、 Azureベースの機械学習システム導入案件を推進
2020年2月:ISIDへ中途入社 現在は、顧客支援と並行してAIを使った自社サービス開発に尽力中 業務: 機械学習システム開発・導入、自社のAIソフトウェアの開発、主にAzureによる アーキテクチャ設計 ディープラーニング検定との関わり: 2019年10月に、エンジニア資格を取得しました。 Qiita : https://qiita.com/tamitarai 趣味: コーヒー、ウィスキーなど 自己紹介
5 はじめに ⚫ お話すること ⚫ 皆さんが就職した後や、就活の面接で喋るのに使えるようなAI・機械学習の説明 ⚫ 日本企業におけるAI導入の状況 ⚫ 「AI活用の課題」におけるの注目キーワード
⚫ お話しないこと ⚫ 数学的な機械学習の仕組みについてのお話 ⚫ 皆様に理解してもらうための「機械学習とは?」というお話 ⚫ 個別のドメインにおけるコアな最新技術のお話
6 AI・機械学習とは? 02
7 AI・機械学習とは? 皆様は、すでに「機械学習とは何か」について多かれ少なかれ知っていると思います。 では、機械学習システムの導入を検討しているお客様に 「機械学習ってなに?」と聞かれたら、なんと答えますか? 私(たち)は、「従来システムとの違い」という観点でご説明をすることが多いです。 (理由はあとで説明します)
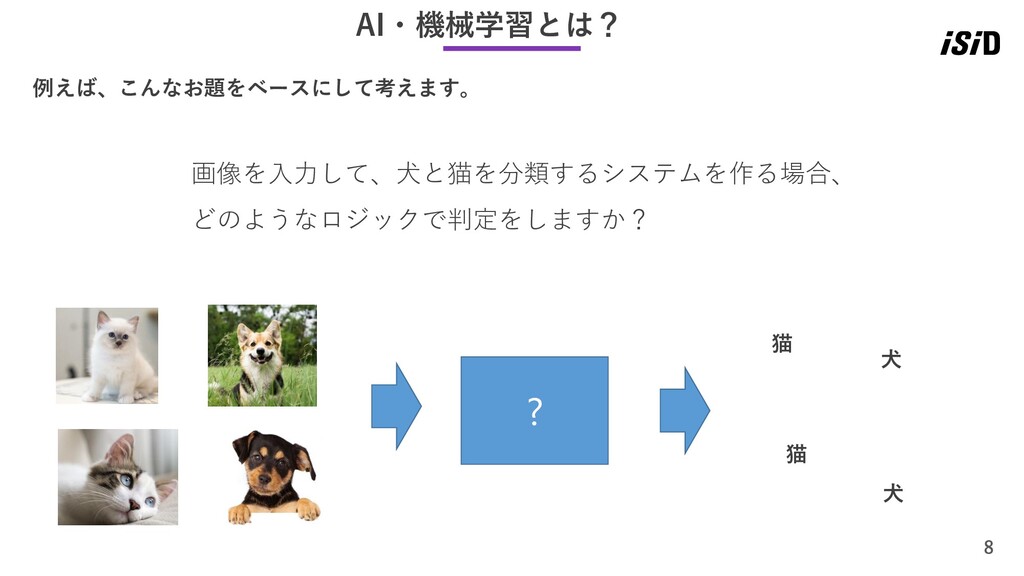
8 AI・機械学習とは? 例えば、こんなお題をベースにして考えます。 画像を入力して、犬と猫を分類するシステムを作る場合、 どのようなロジックで判定をしますか? ? 猫 猫 犬 犬
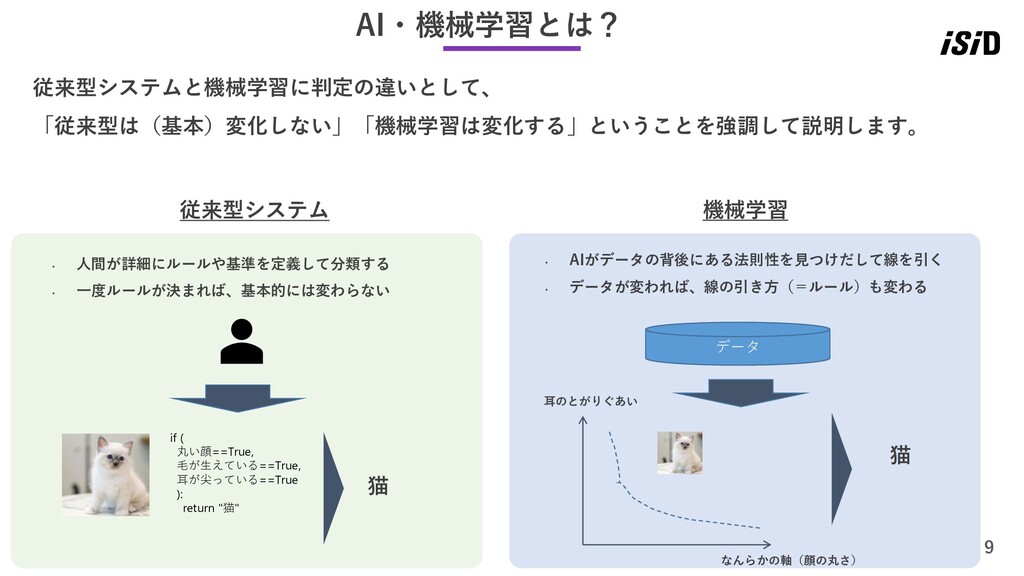
9 AI・機械学習とは? 従来型システムと機械学習に判定の違いとして、 「従来型は(基本)変化しない」「機械学習は変化する」ということを強調して説明します。 if ( 丸い顔==True, 毛が生えている==True, 耳が尖っている==True ):
return "猫" 猫 従来型システム • 人間が詳細にルールや基準を定義して分類する • 一度ルールが決まれば、基本的には変わらない • AIがデータの背後にある法則性を見つけだして線を引く • データが変われば、線の引き方(=ルール)も変わる 機械学習 データ なんらかの軸(顔の丸さ) 耳のとがりぐあい 猫
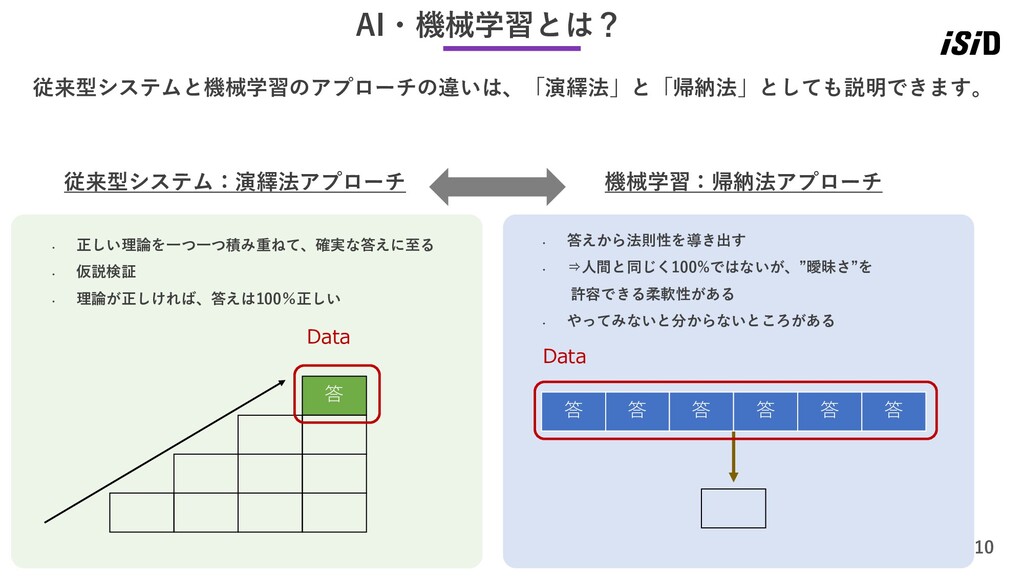
10 従来型システムと機械学習のアプローチの違いは、「演繹法」と「帰納法」としても説明できます。 AI・機械学習とは? 答 Data • 正しい理論を一つ一つ積み重ねて、確実な答えに至る • 仮説検証 •
理論が正しければ、答えは100%正しい 従来型システム:演繹法アプローチ 機械学習:帰納法アプローチ Data 答 答 答 答 答 答 • 答えから法則性を導き出す • ⇒人間と同じく100%ではないが、”曖昧さ”を 許容できる柔軟性がある • やってみないと分からないところがある
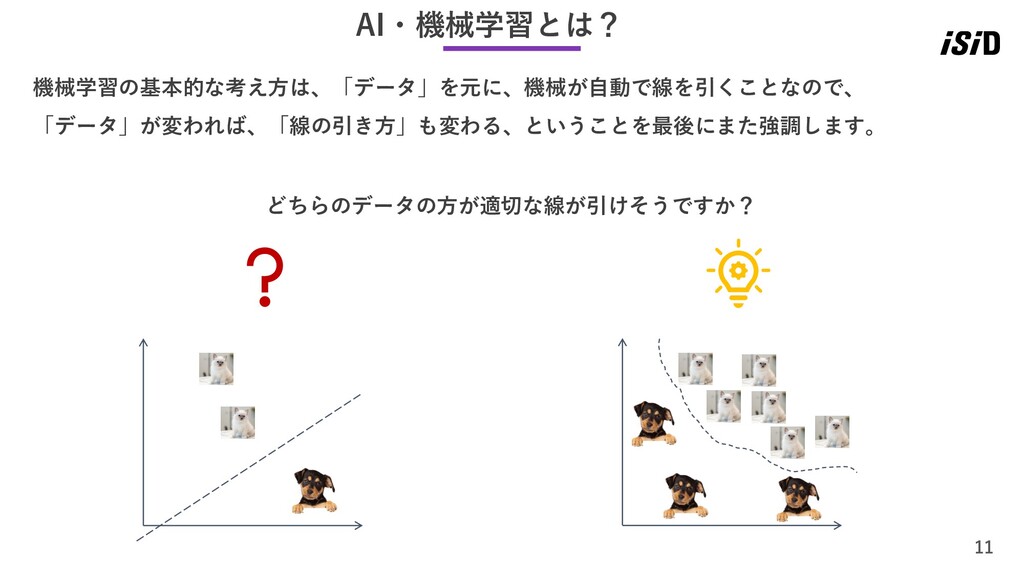
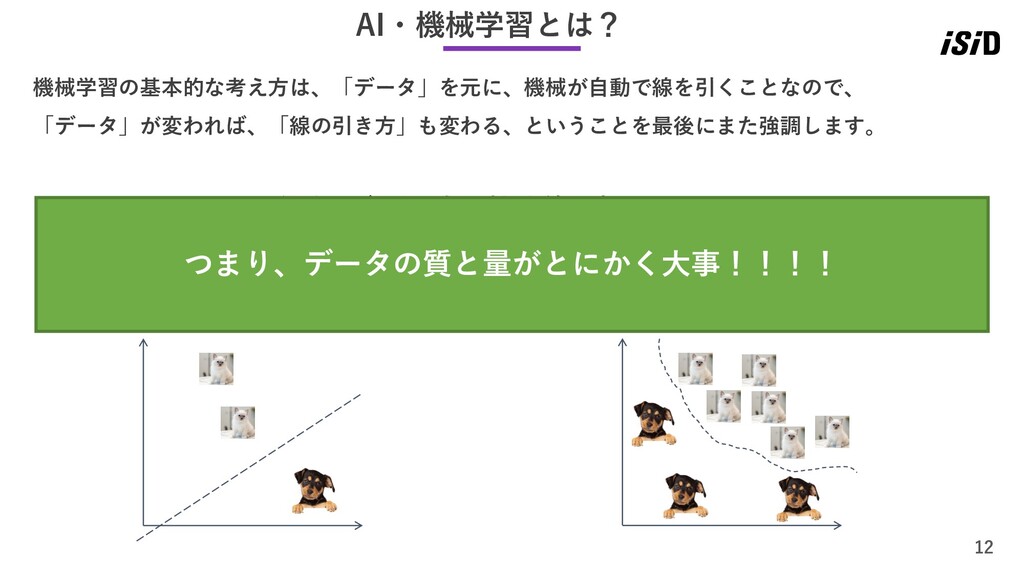
11 AI・機械学習とは? 機械学習の基本的な考え方は、「データ」を元に、機械が自動で線を引くことなので、 「データ」が変われば、「線の引き方」も変わる、ということを最後にまた強調します。 どちらのデータの方が適切な線が引けそうですか?
12 AI・機械学習とは? どちらのデータの方が適切な線が引けますか? つまり、データの質と量がとにかく大事!!!! 機械学習の基本的な考え方は、「データ」を元に、機械が自動で線を引くことなので、 「データ」が変われば、「線の引き方」も変わる、ということを最後にまた強調します。
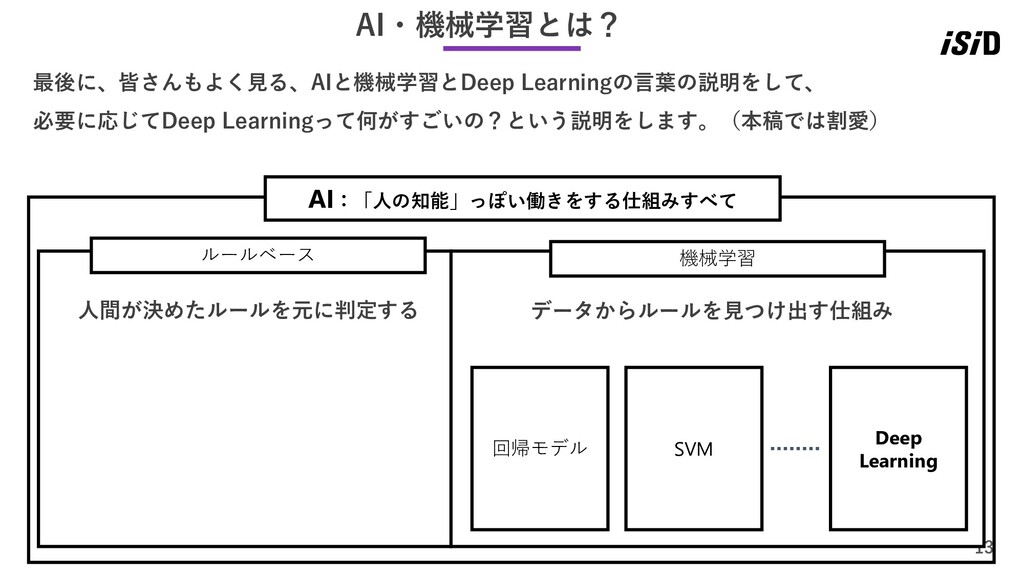
13 AI・機械学習とは? 最後に、皆さんもよく見る、AIと機械学習とDeep Learningの言葉の説明をして、 必要に応じてDeep Learningって何がすごいの?という説明をします。(本稿では割愛) AI:「人の知能」っぽい働きをする仕組みすべて 機械学習 ルールベース 回帰モデル
SVM Deep Learning 人間が決めたルールを元に判定する データからルールを見つけ出す仕組み
14 日本におけるAI活用とAIの民主化 03
15 なぜ従来システムとの違いを強調して説明するのか? それは、日本では「システムは外部に発注して作らせて終わり」とする商習慣がまだまだ強く、 従来型システムと同じように考えられてしまうと、 「結局活用されない」とか「トラブルのタネになる」などの悲しい結果に繋がるためです。 従来システムのイメージ 機械学習システム 認識ズレによる問題 作ったら終わり、運用は外部任せでOK 一度作った後、定期的に再学習が必
要なので自分たちで運用する必要が ある 「え?再学習?運用する 人なんかいないし、運用 方法もわからない よ。。。」 設計時に決めたとおりに動き続ける モデルの挙動は再学習するびに変 わってしまう 「確実に精度保証ができ ないならお金は払えな い!!!!」
16 なぜ「システムは外部発注して終わり」になるのか? 余談ですが、「システムは外部に発注して作って終わり」という商習慣の背景としては 以下のように「雇用の流動性の低さ」が挙げられることが多いです。 アメリカ 日本 雇用の流動性が高い 雇用の流動性が低い 最悪、解雇できるので、 社内にIT人材を抱えるリスクが取れる
解雇にしづらいので IT人材を社内に抱えるリスクが取りづらい 自社でシステムの開発から運用までをする システムごとに外部(=Sier)に IT人材をアウトソースして開発・運用をする ※ちなみに「それなら雇用の流動性を上げればいいんだ!解雇規制を緩和だ!」みたいな雑な議論を時々見ますが、 そんなに単純なら苦労しないのです。皆さんは、「ではなぜ雇用流動性が低い労働法制になっているのか?」というところまで 考えて頂けるとうれしいです。
17 いろいろ書きましたが、要するに何が言いたかったかというと、 日本には、"自分たちで改善し続ける必要がある"AI活用が難しい構造的な背景がある、 ということです それでは続いて、日本におけるAI導入の状況を見てみましょう
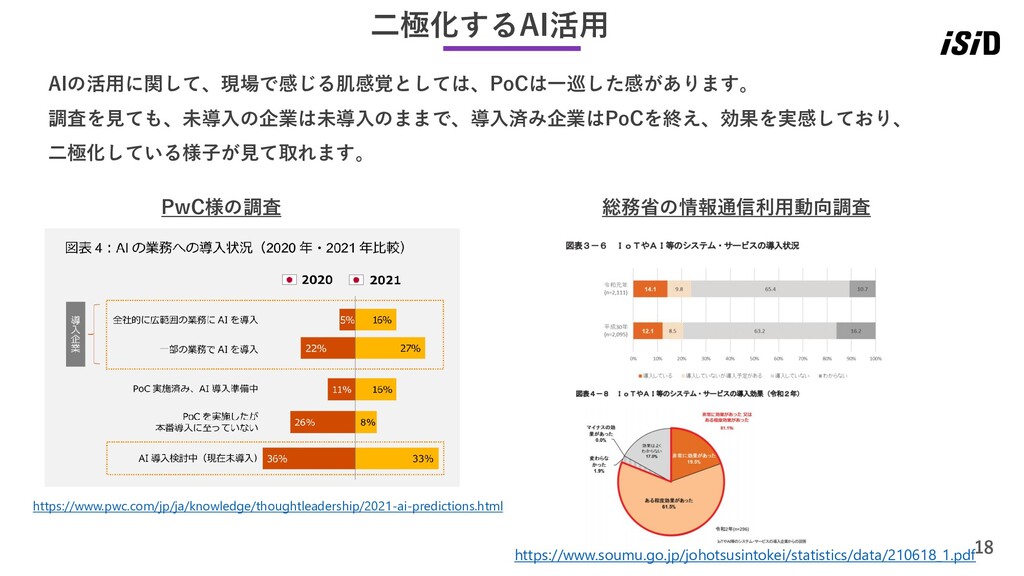
18 二極化するAI活用 https://www.pwc.com/jp/ja/knowledge/thoughtleadership/2021-ai-predictions.html AIの活用に関して、現場で感じる肌感覚としては、PoCは一巡した感があります。 調査を見ても、未導入の企業は未導入のままで、導入済み企業はPoCを終え、効果を実感しており、 二極化している様子が見て取れます。 PwC様の調査 https://www.soumu.go.jp/johotsusintokei/statistics/data/210618_1.pdf 総務省の情報通信利用動向調査
19 このように、現状はAI活用は二極化していますが、 個人的には「AIを使ってみた」はなんだかんだ増えると思っています。(ただし「活用」はまだ別) 理由は、いわゆる「AIの民主化」の勢いがすごいためです。 「AIの民主化」に関連して、ここで触れたいキーワードは、以下の4つです 「AIの民主化」 ✓ Auto ML ✓
学習済みモデルのAPI化 ✓ 学習済みモデルの公開 ✓ GoogleのAutoML Zero
20 Auto ML ⚫ インプットされたデータに対して最適な前処理、アルゴリズム、ハイパーパラメータを探索し、簡単に高精度 なモデルを作成する技術 ⚫ 一般的なタスクであれば、データ作成までできれば投入するだけでコンペ上位レベルのモデルができる ⚫ 各社、いろいろなサービスを出しており、ISIDもOpTApfというサービスをリリース
OpTApfの製品ページ→https://isid-ai.jp/products/optapf.html https://youtu.be/0nGdTPJvjDI 具体的なサービスイメージ サービスによって異なるが、 例えばMicrosoftのAuto MatedMLは、協調フィルタリ ングとベイズ最適化問題を組み 合わせることで、上記の探索を 効率化している 以下のAzure Machine Learningの動画がわかりやすいです しくみ https://arxiv.org/pdf/1705.05355.pdf
21 学習済みモデルのAPI提供 ⚫ 画像、音声、自然言語、動画、etcとかなり色々なデータ・タスクが既にAPIとして提供されている ⚫ これらの多くは有料だが、すぐにAIを使って課題を解決できる Microsoftが提供するAPI Microsoft Azureは、APIとして例えば以下のようなAIを提供しています。 (以下は一例です。実際にはもっとあります。)
以下は、Azure Compute Visionの利用イメージです。 画像に写り込んだオブジェクトの位置を検出し、 それが「自転車」であることを特定しています MicrosoftのAPI利用画面例 https://docs.microsoft.com/ja-jp/azure/cognitive-services/what-are-cognitive-services https://azure.microsoft.com/ja-jp/services/cognitive-services/computer-vision/#featu
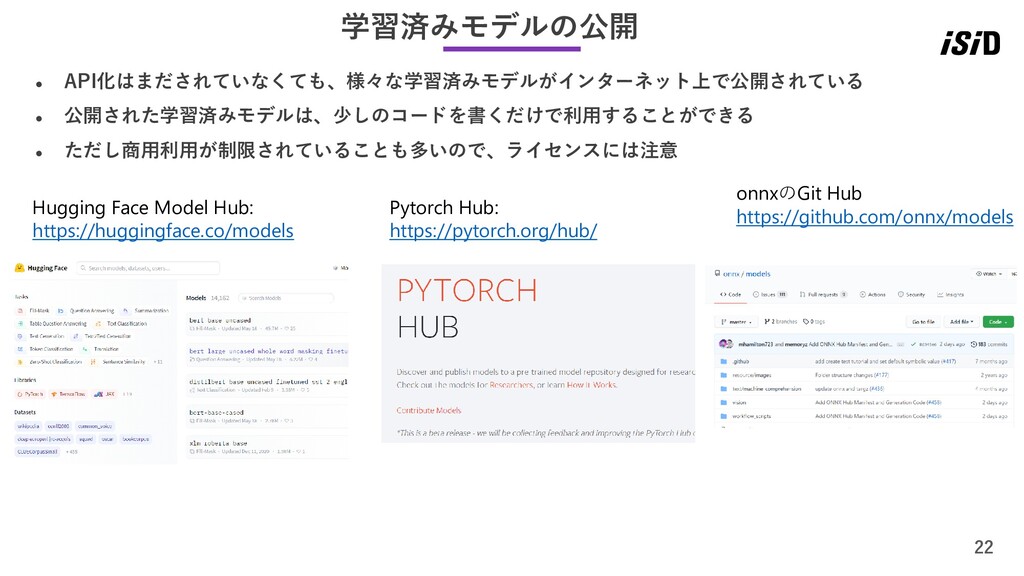
22 学習済みモデルの公開 ⚫ API化はまだされていなくても、様々な学習済みモデルがインターネット上で公開されている ⚫ 公開された学習済みモデルは、少しのコードを書くだけで利用することができる ⚫ ただし商用利用が制限されていることも多いので、ライセンスには注意 Hugging Face
Model Hub: https://huggingface.co/models Pytorch Hub: https://pytorch.org/hub/ onnxのGit Hub https://github.com/onnx/models
23 AutoML-Zero ⚫ Googleが開発したアルゴリズム ⚫ 進化的アルゴリズムによって、ゼロから今まで人類が発見してきた手法をAIが自分で発見する ⚫ ReLUや、誤差逆伝播法などを用いた二層ニューラルネットワークを自力で発見 ⚫ まだ安定的に高精度なアルゴリズムを作成はできず、実用段階ではないとのこと
https://ai.googleblog.com/2020/07/automl-zero-evolving-code-that-learns.html AutoML-Zeroの進化の過 程
24 このような「AIの民主化」が進むとAIのハードルはどんどん低くなり、 「使ってみた」自体は増えていくと考えています。 すると、次の課題は、「導入したAIをいかにして活用するか」です。 外部ベンダーにシステム構築を発注する文化がある日本では、 特に重要なテーマなのかなと思っています
25 MLOpsと注目キーワード 04
26 MLOps ご存知の方が多いかもですが、「AIの運用」を表す「MLOps」というキーワードが注目されています。 が、「MLOps」とは具体的に何をさすのでしょうか? [引用] Azureアーキテクチャセンター https://docs.microsoft.com/ja-jp/azure/architecture/example-scenario/mlops/media/basic-ml-process-flow.png
27 MLOps = AI活用に必要な要素ぜんぶ MLOpsの定義はいろいろありますが、私は、「AI活用に必要な要素ぜんぶ」だと思っています。 例えば、以下は、MLOpsに関して言及された要素として紹介されている図です。 私も、MLOpsとしてこれくらいまで含まれる気がします。 [引用] 渡部 徹太郎「MLOpsはバズワード」https://www.slideshare.net/tetsutarowatanabe/mlops-
249382186
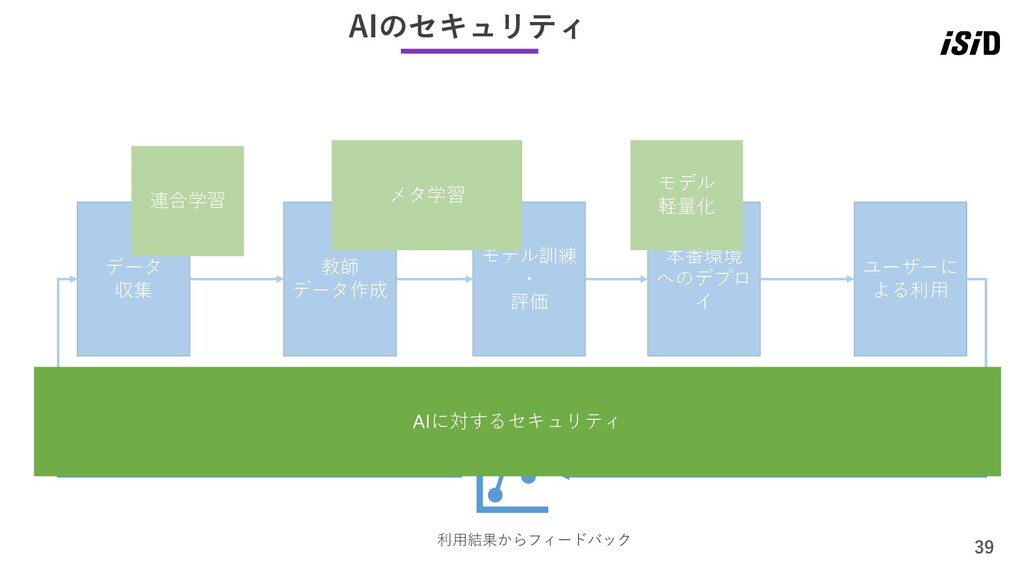
28 MLOps = AI活用に必要な要素ぜんぶ つまり、AIの実運用・活用するにあたっては、 AI自体はほんの一部で、AI以外の仕組みが大部分を占めることになります そこで、ここでは「MLOps」という観点から以下のキーワードについてご紹介します ✓ 連合学習(Federated Learning)
✓ メタ学習 ✓ モデルの軽量化 ✓ AIに対するセキュリティ
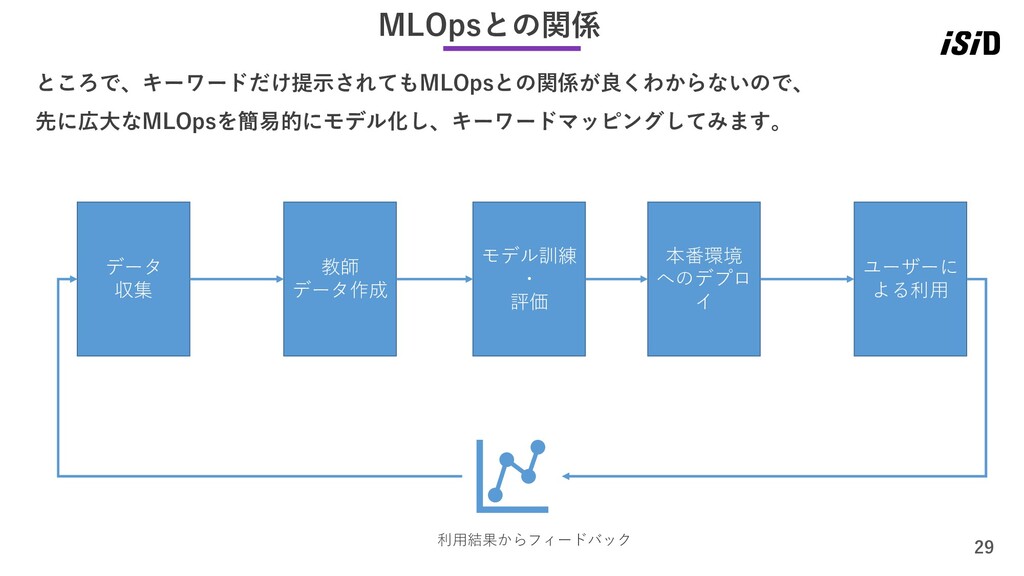
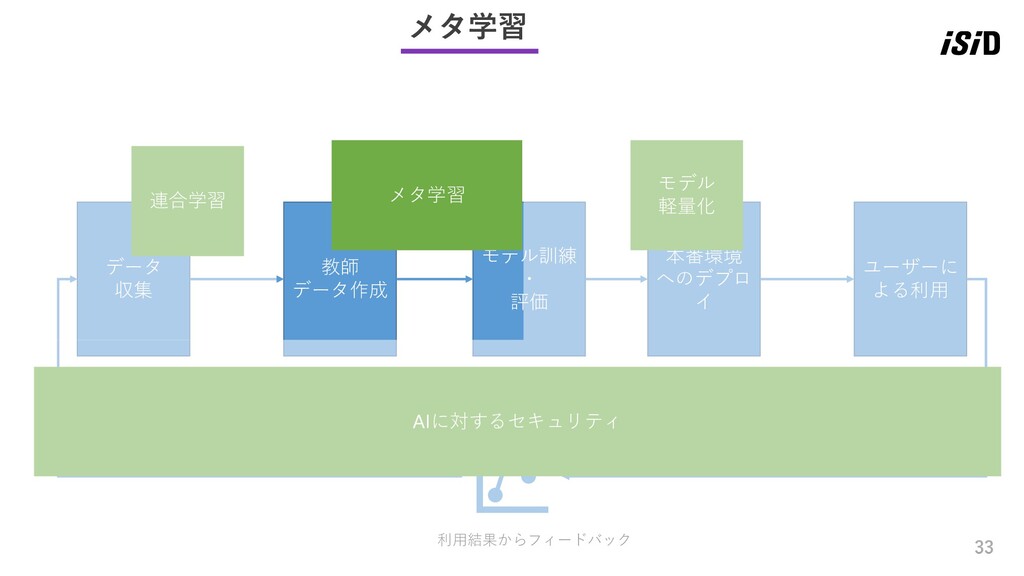
29 MLOpsとの関係 ところで、キーワードだけ提示されてもMLOpsとの関係が良くわからないので、 先に広大なMLOpsを簡易的にモデル化し、キーワードマッピングしてみます。 データ 収集 教師 データ作成 モデル訓練 ・
評価 本番環境 へのデプロ イ ユーザーに よる利用 利用結果からフィードバック
30 データ 収集 教師 データ作成 モデル訓練 ・ 評価 本番環境 へのデプロ
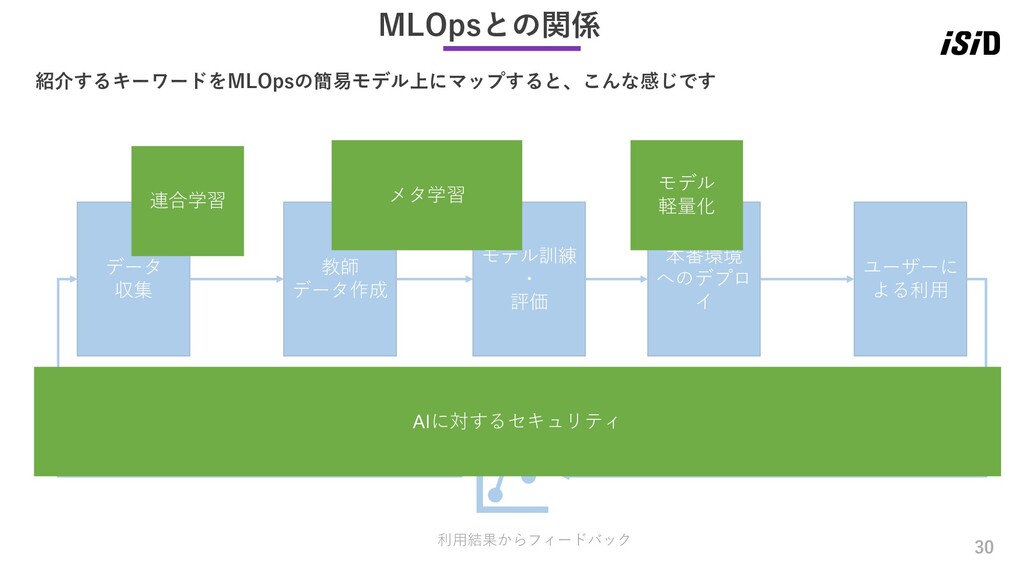
イ ユーザーに よる利用 利用結果からフィードバック MLOpsとの関係 紹介するキーワードをMLOpsの簡易モデル上にマップすると、こんな感じです 収集 連合学習 メタ学習 モデル 軽量化 AIに対するセキュリティ
31 データ 収集 教師 データ作成 モデル訓練 ・ 評価 本番環境 へのデプロ
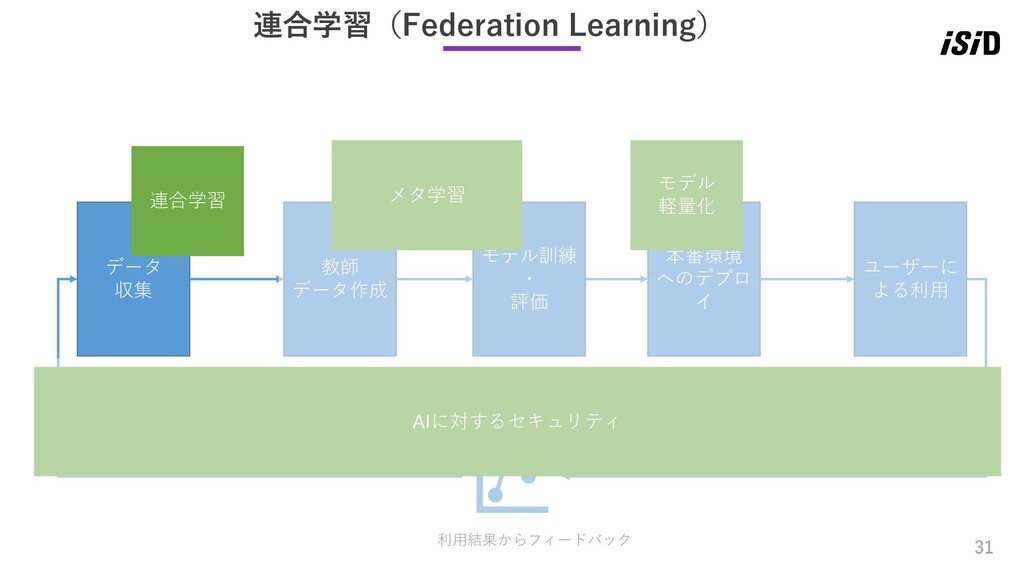
イ ユーザーに よる利用 利用結果からフィードバック 連合学習(Federation Learning) 連合学習 AIに対するセキュリティ メタ学習 モデル 軽量化
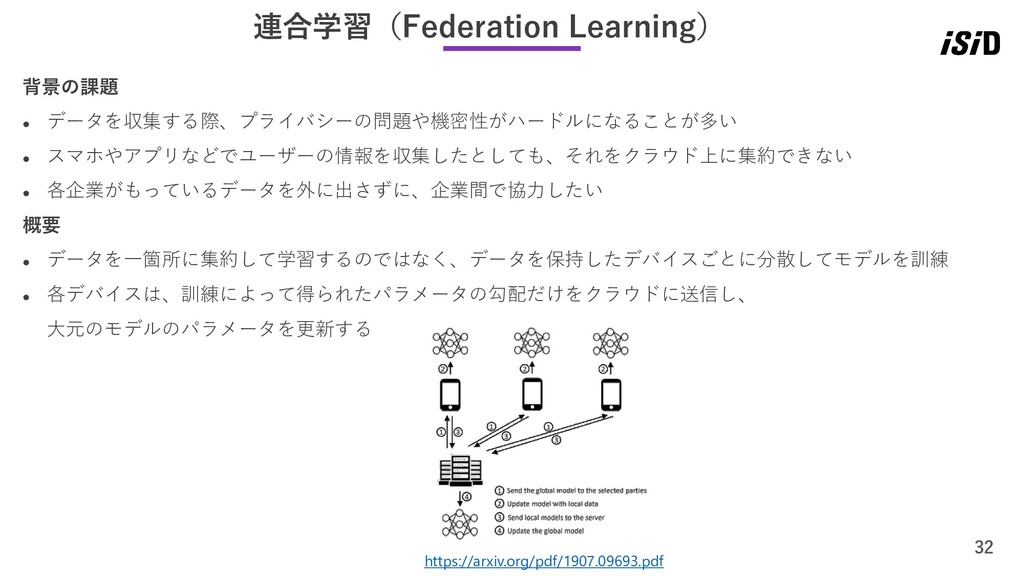
32 連合学習(Federation Learning) 背景の課題 ⚫ データを収集する際、プライバシーの問題や機密性がハードルになることが多い ⚫ スマホやアプリなどでユーザーの情報を収集したとしても、それをクラウド上に集約できない ⚫ 各企業がもっているデータを外に出さずに、企業間で協力したい
概要 ⚫ データを一箇所に集約して学習するのではなく、データを保持したデバイスごとに分散してモデルを訓練 ⚫ 各デバイスは、訓練によって得られたパラメータの勾配だけをクラウドに送信し、 大元のモデルのパラメータを更新する https://arxiv.org/pdf/1907.09693.pdf
33 データ 収集 教師 データ作成 モデル訓練 ・ 評価 本番環境 へのデプロ
イ ユーザーに よる利用 利用結果からフィードバック 連合学習 AIに対するセキュリティ メタ学習 メタ学習 モデル 軽量化
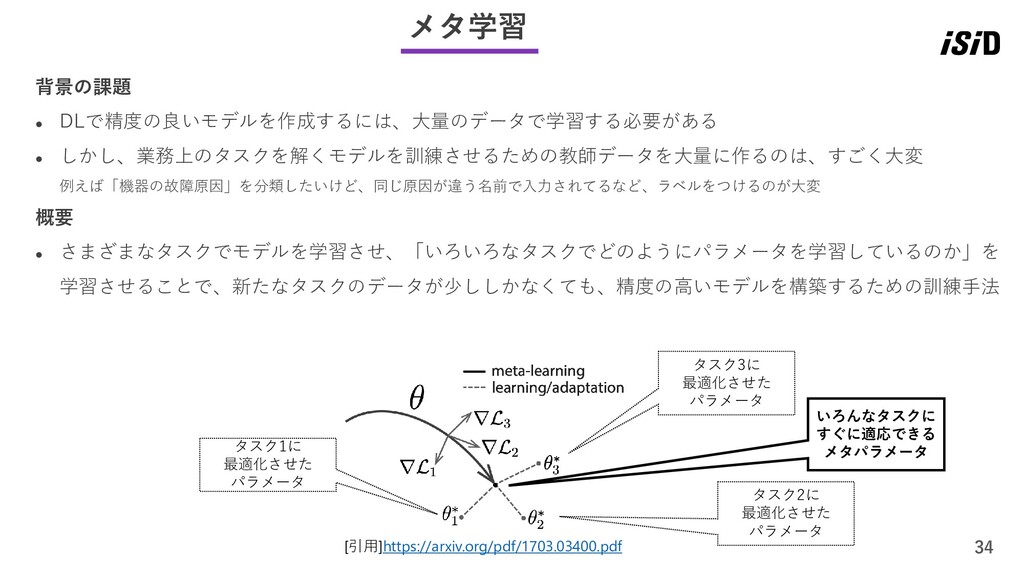
34 メタ学習 背景の課題 ⚫ DLで精度の良いモデルを作成するには、大量のデータで学習する必要がある ⚫ しかし、業務上のタスクを解くモデルを訓練させるための教師データを大量に作るのは、すごく大変 例えば「機器の故障原因」を分類したいけど、同じ原因が違う名前で入力されてるなど、ラベルをつけるのが大変 概要 ⚫
さまざまなタスクでモデルを学習させ、「いろいろなタスクでどのようにパラメータを学習しているのか」を 学習させることで、新たなタスクのデータが少ししかなくても、精度の高いモデルを構築するための訓練手法 [引用]https://arxiv.org/pdf/1703.03400.pdf タスク1に 最適化させた パラメータ タスク3に 最適化させた パラメータ タスク2に 最適化させた パラメータ いろんなタスクに すぐに適応できる メタパラメータ
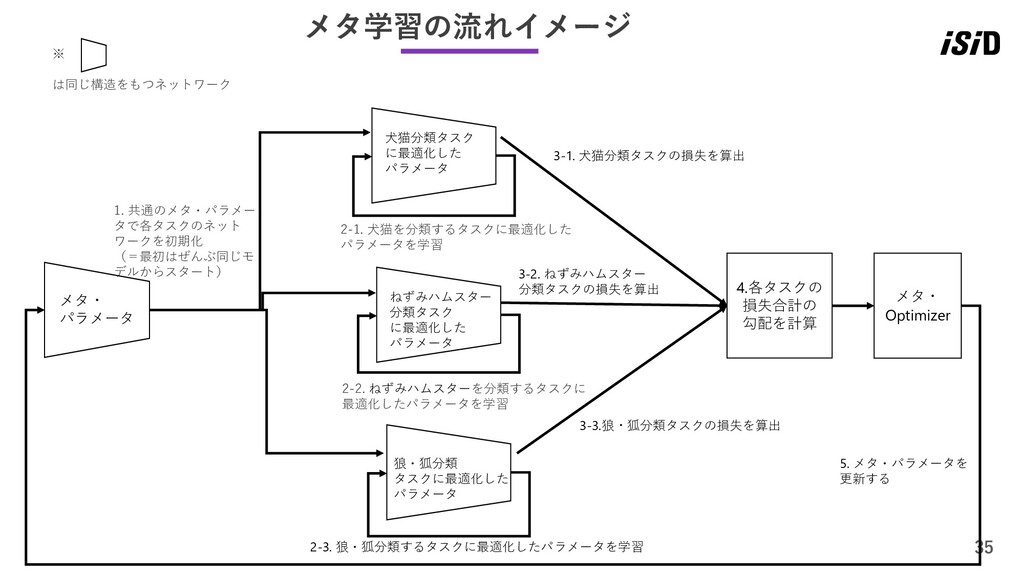
35 ※ は同じ構造をもつネットワーク 2-2. ねずみハムスターを分類するタスクに 最適化したパラメータを学習 2-3. 狼・狐分類するタスクに最適化したパラメータを学習 1. 共通のメタ・パラメー
タで各タスクのネット ワークを初期化 (=最初はぜんぶ同じモ デルからスタート) 5. メタ・パラメータを 更新する 3-2. ねずみハムスター 分類タスクの損失を算出 3-3.狼・狐分類タスクの損失を算出 4.各タスクの 損失合計の 勾配を計算 メタ・ Optimizer 2-1. 犬猫を分類するタスクに最適化した パラメータを学習 犬猫分類タスク に最適化した パラメータ ねずみハムスター 分類タスク に最適化した パラメータ 狼・狐分類 タスクに最適化した パラメータ メタ・ パラメータ メタ学習の流れイメージ 3-1. 犬猫分類タスクの損失を算出
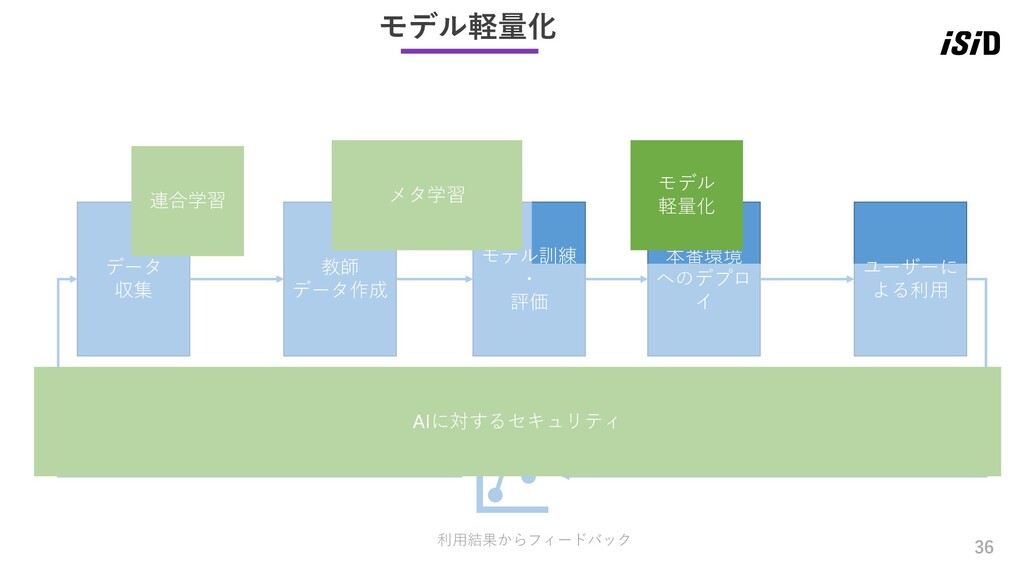
36 データ 収集 教師 データ作成 モデル訓練 ・ 評価 本番環境 へのデプロ
イ ユーザーに よる利用 利用結果からフィードバック 連合学習 AIに対するセキュリティ メタ学習 モデル軽量化 モデル 軽量化
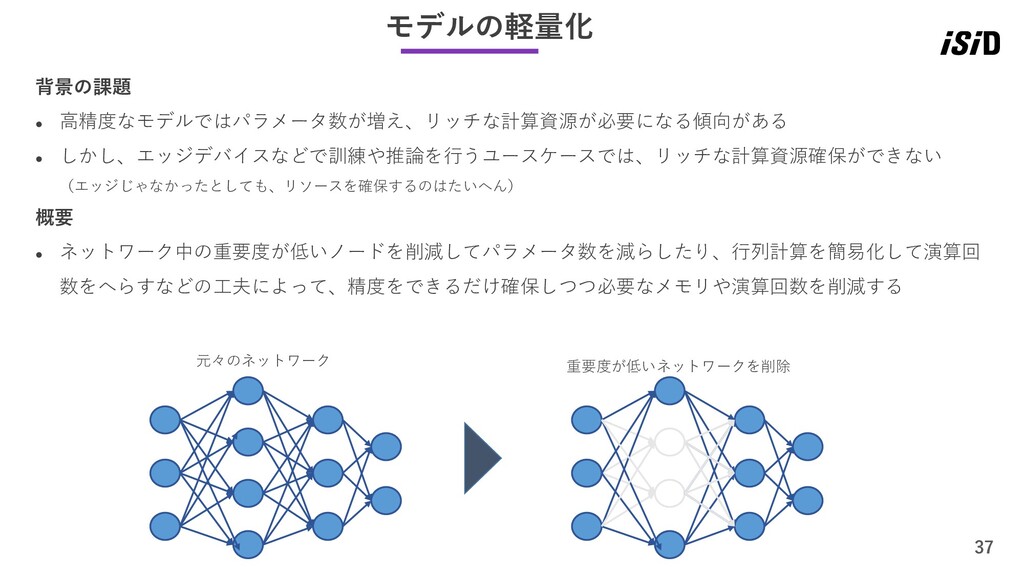
37 モデルの軽量化 背景の課題 ⚫ 高精度なモデルではパラメータ数が増え、リッチな計算資源が必要になる傾向がある ⚫ しかし、エッジデバイスなどで訓練や推論を行うユースケースでは、リッチな計算資源確保ができない (エッジじゃなかったとしても、リソースを確保するのはたいへん) 概要 ⚫
ネットワーク中の重要度が低いノードを削減してパラメータ数を減らしたり、行列計算を簡易化して演算回 数をへらすなどの工夫によって、精度をできるだけ確保しつつ必要なメモリや演算回数を削減する 元々のネットワーク 重要度が低いネットワークを削除
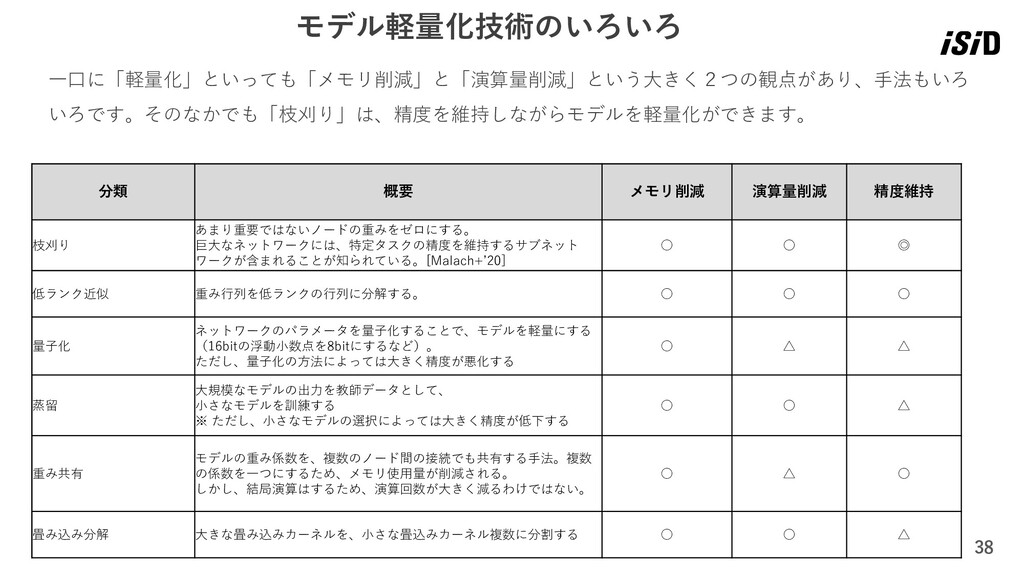
38 モデル軽量化技術のいろいろ 分類 概要 メモリ削減 演算量削減 精度維持 枝刈り あまり重要ではないノードの重みをゼロにする。 巨大なネットワークには、特定タスクの精度を維持するサブネット
ワークが含まれることが知られている。[Malach+’20] ◦ ◦ ◎ 低ランク近似 重み行列を低ランクの行列に分解する。 ◦ ◦ ◦ 量子化 ネットワークのパラメータを量子化することで、モデルを軽量にする (16bitの浮動小数点を8bitにするなど)。 ただし、量子化の方法によっては大きく精度が悪化する ◦ △ △ 蒸留 大規模なモデルの出力を教師データとして、 小さなモデルを訓練する ※ ただし、小さなモデルの選択によっては大きく精度が低下する ◦ ◦ △ 重み共有 モデルの重み係数を、複数のノード間の接続でも共有する手法。複数 の係数を一つにするため、メモリ使用量が削減される。 しかし、結局演算はするため、演算回数が大きく減るわけではない。 ◦ △ ◦ 畳み込み分解 大きな畳み込みカーネルを、小さな畳込みカーネル複数に分割する ◦ ◦ △ 一口に「軽量化」といっても「メモリ削減」と「演算量削減」という大きく2つの観点があり、手法もいろ いろです。そのなかでも「枝刈り」は、精度を維持しながらモデルを軽量化ができます。
39 データ 収集 教師 データ作成 モデル訓練 ・ 評価 本番環境 へのデプロ
イ ユーザーに よる利用 利用結果からフィードバック 連合学習 AIに対するセキュリティ メタ学習 AIのセキュリティ モデル 軽量化
40 AIのセキュリティ 背景にある課題 ⚫ AIを実運用に乗せるにあたって、AIシステム特有のリスクに備える必要が生じている 概要 ⚫ 大きく分けて、以下の二つのタイプの攻撃に対する防御策を講じることとなる 参考:宇根 正志「機械学習のセキュリティの研究動向:金融サービスでの活用を展望して」
https://drive.google.com/file/d/1P_VXPYDkt6l5KuxsjAaty0M4i_0wTBCF/view 1. データの完全性に対する攻撃 (データを改善したり、おかしな出力をさせたりする) 2. データの機密性に対する攻撃 (秘密にしておきたい情報を漏洩させる) 例:有名な、パンダの画像にノイズを加えて手長ザルと認識させる攻撃 https://arxiv.org/pdf/1412.6572.pdf 例:モデルが出力する確信度などから訓練データを生成する https://dl.acm.org/doi/pdf/10.1145/2810103.2813677 生成画像 訓練画像
41 AIのセキュリティ AIのセキュリティに関しても、いろいろな攻撃とそれへの対策があります。 このあたりはガイドライン化が進んでおり、いずれ、一般的な基準として標準化されると思います。 ビジネス側では、標準化されたときに対応できるようにウォッチしておく必要があります。 https://www.digiarc.aist.go.jp/publication/aiqm/AIQM- Guideline-2.1.0.pdf 国立研究開発法人産業技術総合研究所 「機械学習品質マネジメントガイドライン」
42 最後に 05
43 さいごに いろいろと変化のはやい世の中で、わかりやすい成果に飛びつきたくなることが多いと思います。 私もすごーーーーく、飛びつきがちです。 なぜなら、目の前の成果を出す方が、着実に土台を築いて進むよりもはるかに楽だからです。 ですが、5年経ってみると、分かりやすい目の前の成果に飛びつき続けた人よりも、 着実に土台を築きながら進み続けた人の方が、モノになっていることがよくあります。 特に、エンジニアというのはそういう職業だと思います。 お互い、焦らず、着実に、やっていきましょう。
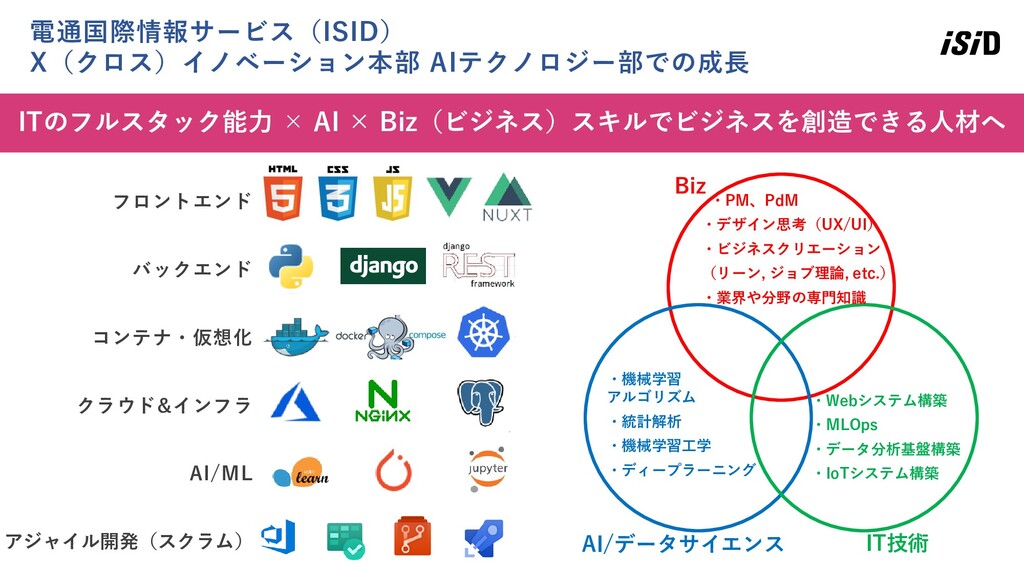
44 ITのフルスタック能力 × AI × Biz(ビジネス)スキルでビジネスを創造できる人材へ 電通国際情報サービス(ISID) X(クロス)イノベーション本部 AIテクノロジー部での成長 UVP
・機械学習 アルゴリズム ・統計解析 ・機械学習工学 ・ディープラーニング ・Webシステム構築 ・MLOps ・データ分析基盤構築 ・IoTシステム構築 ・PM、PdM ・デザイン思考(UX/UI) ・ビジネスクリエーション (リーン, ジョブ理論, etc.) ・業界や分野の専門知識 IT技術 Biz AI/データサイエンス フロントエンド バックエンド コンテナ・仮想化 クラウド&インフラ AI/ML アジャイル開発(スクラム)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![26 MLOps ご存知の方が多いかもですが、「AIの運用」を表す「MLOps」というキーワードが注目されています。 が、「MLOps」とは具体的に何をさすのでしょうか? [引用] Azureアーキテクチャセンター https://docs.microsoft.com/ja-jp/azure/architecture/example-scenario/mlops/media/basic-ml-process-flow.png](https://files.speakerdeck.com/presentations/3fd830c378044cbebd84f5849ab286f0/slide_25.jpg){kind=link}
![27 MLOps = AI活用に必要な要素ぜんぶ MLOpsの定義はいろいろありますが、私は、「AI活用に必要な要素ぜんぶ」だと思っています。 例えば、以下は、MLOpsに関して言及された要素として紹介されている図です。 私も、MLOpsとしてこれくらいまで含まれる気がします。 [引用] 渡部 徹太郎「MLOpsはバズワード」https://www.slideshare.net/tetsutarowatanabe/mlops-](https://files.speakerdeck.com/presentations/3fd830c378044cbebd84f5849ab286f0/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}