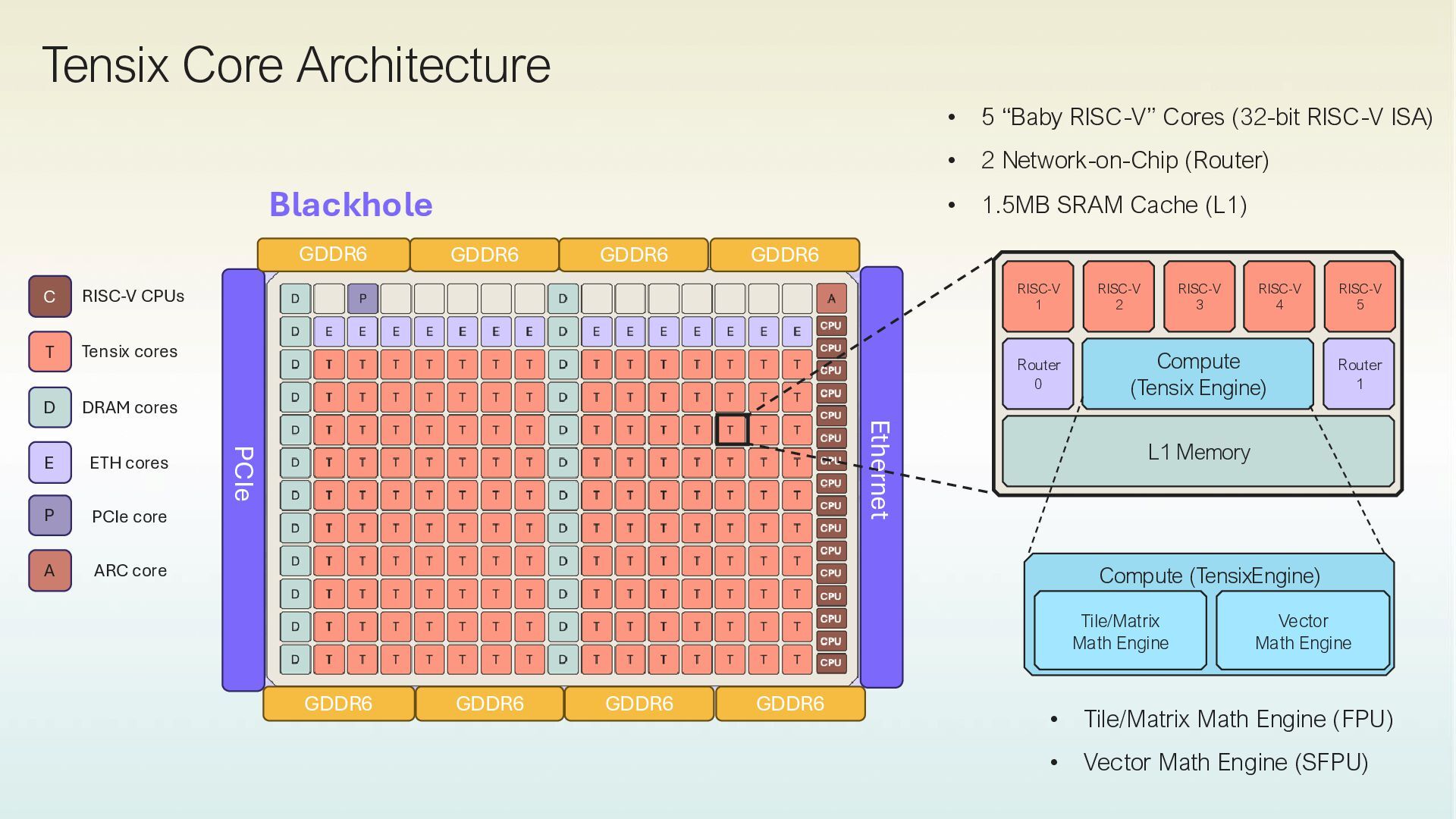
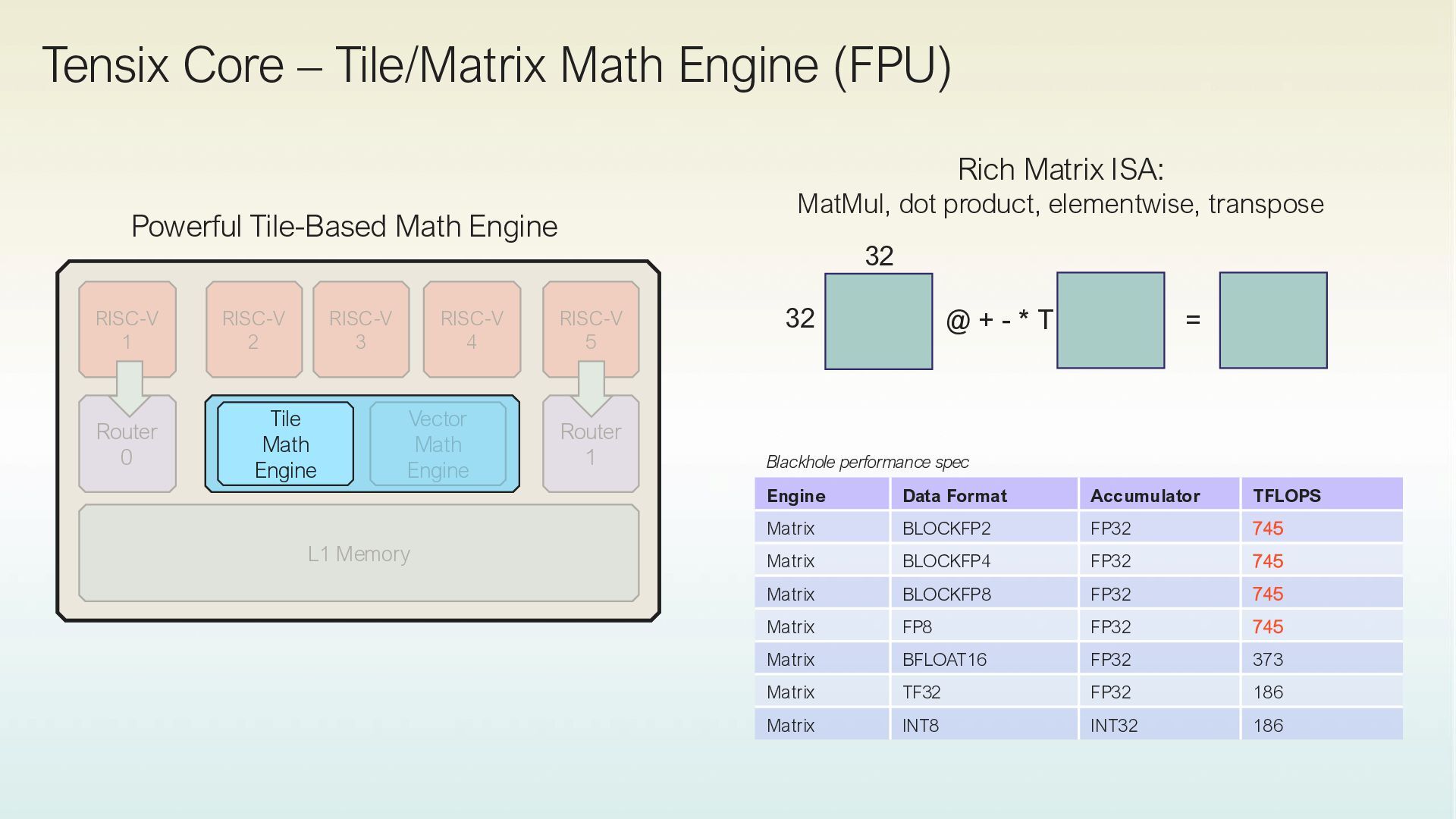
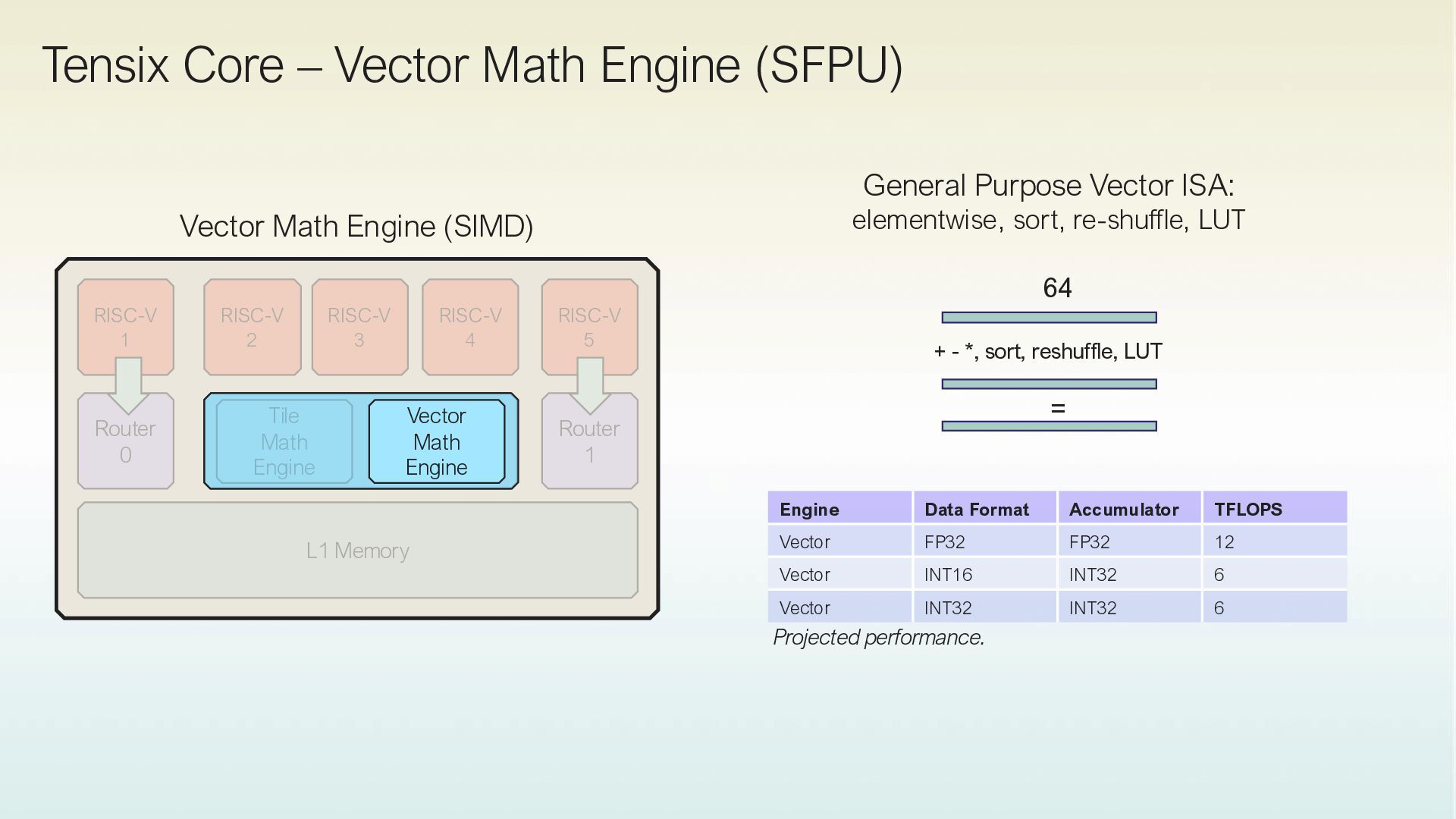
High bandwidth, large capacity SRAM in each Tensix core. • Achives “sillicon peak” performance. • Single-level SRAM as primary Tensor storage. • Minimizes reliance on HBM. Native Tile-Based Compute • Operates on 32x32 matrix tiles. • Uses single-threaded RISC-V processors. • Supports concurrent data movement and compute. Distributed Shared Memory & In-Place Compute • Efficiently implements distributed shared memory. • Optimizes data layout and movement. • Allows in-place compute on local SRAM data. • Reduces unnecessary data movement. Explicit Data Movement • Data movement is decoupled from compute. • Kernels manage data transfer to local SRAM. • Pre-planned, optimized data movement. • No caches or global crossbars involved.
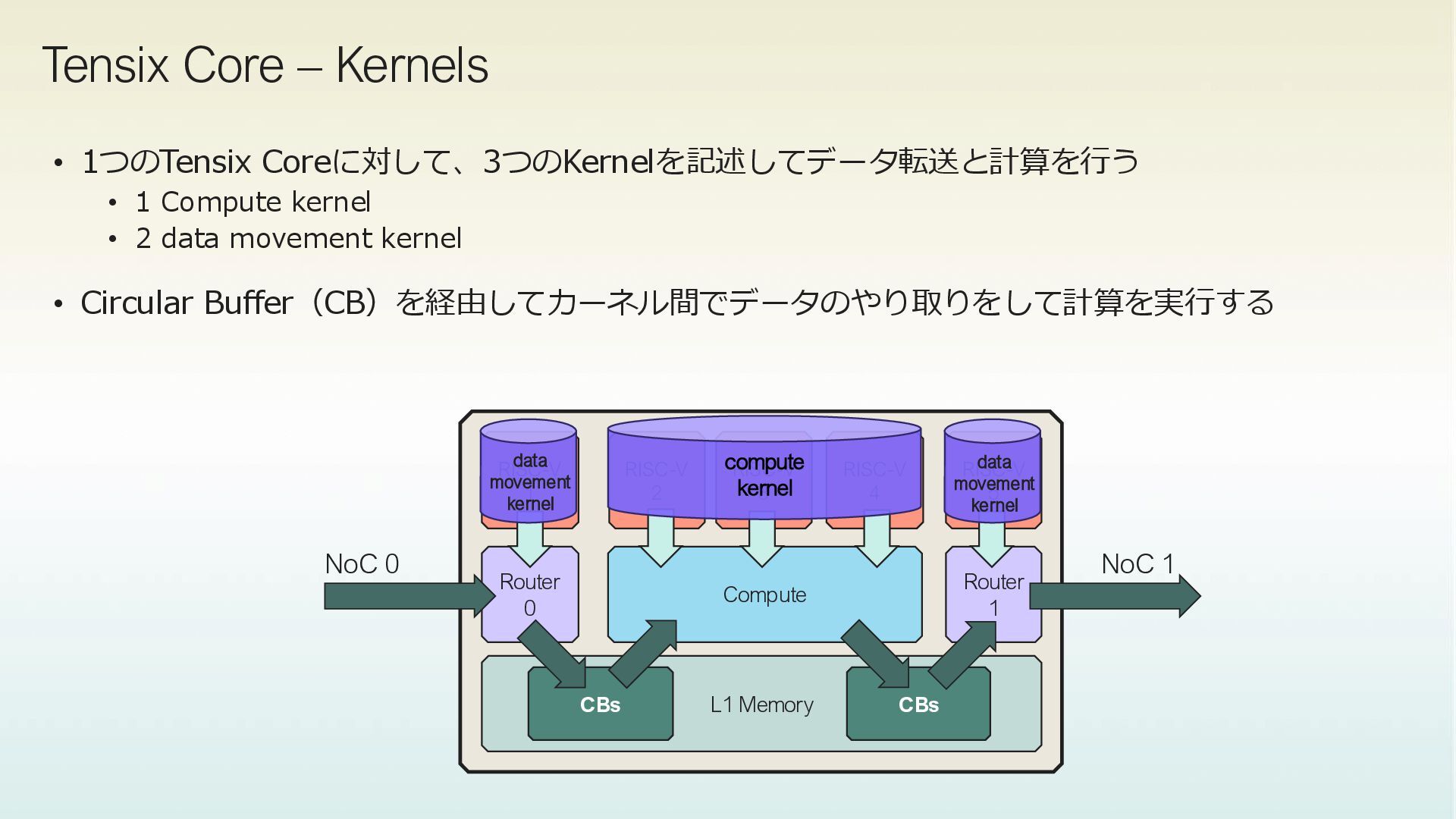
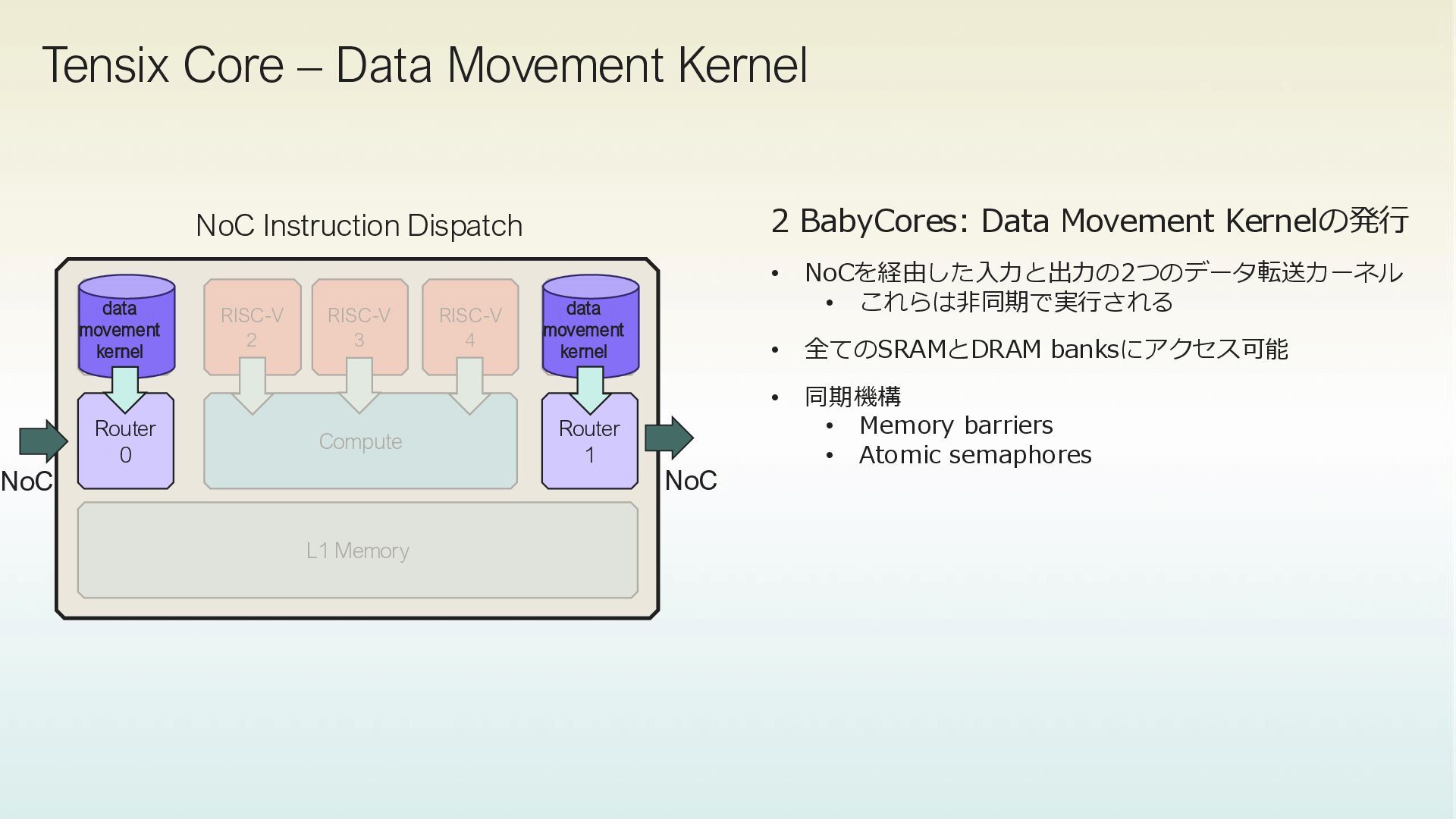
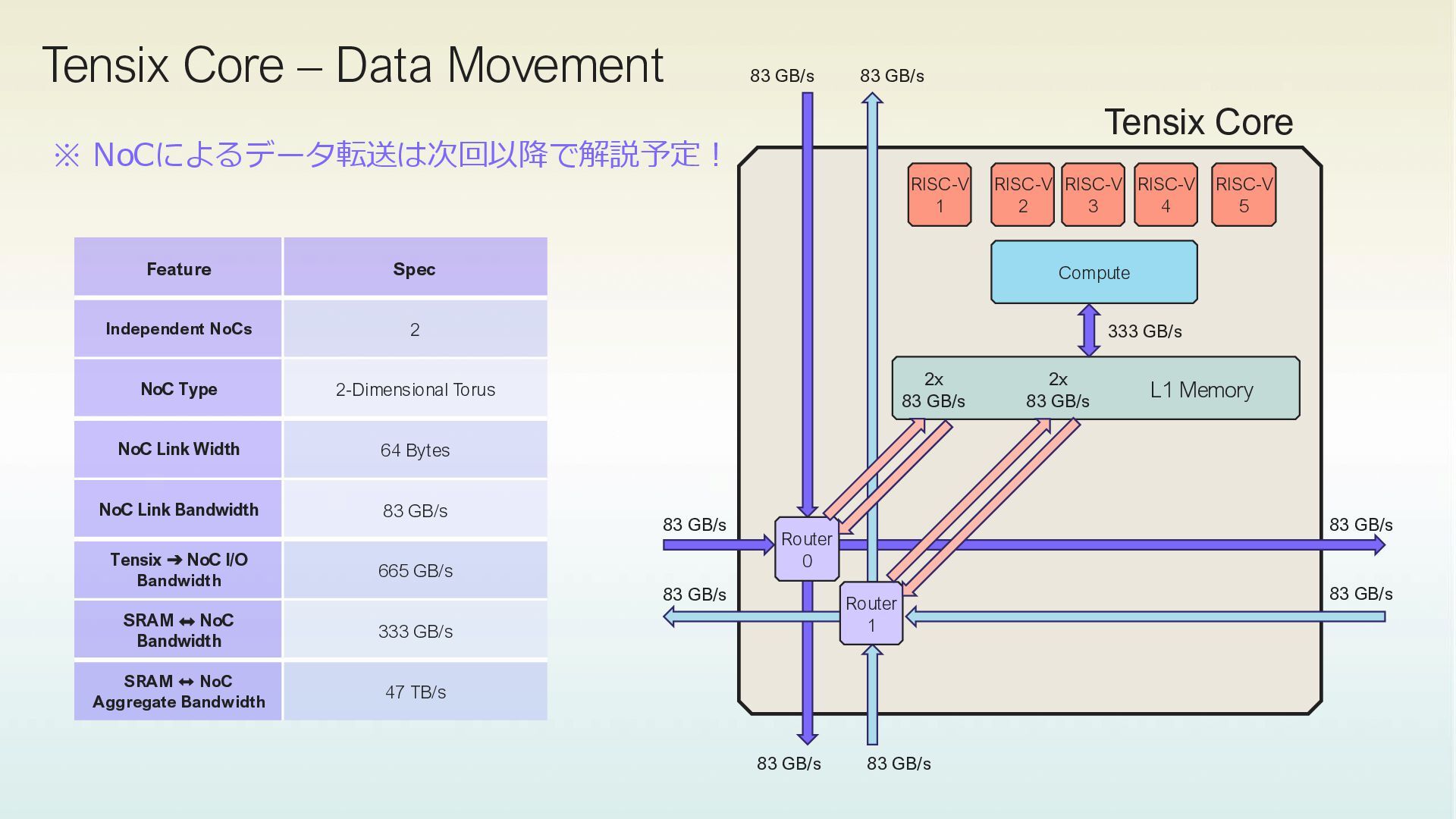
4 RISC-V 5 RISC-V 1 Router 1 Router 0 L1 Memory NoC 0 data movement kernel data movement kernel compute kernel NoC 1 CBs CBs • 1つのTensix Coreに対して、3つのKernelを記述してデータ転送と計算を行う • 1 Compute kernel • 2 data movement kernel • Circular Buffer(CB)を経由してカーネル間でデータのやり取りをして計算を実行する
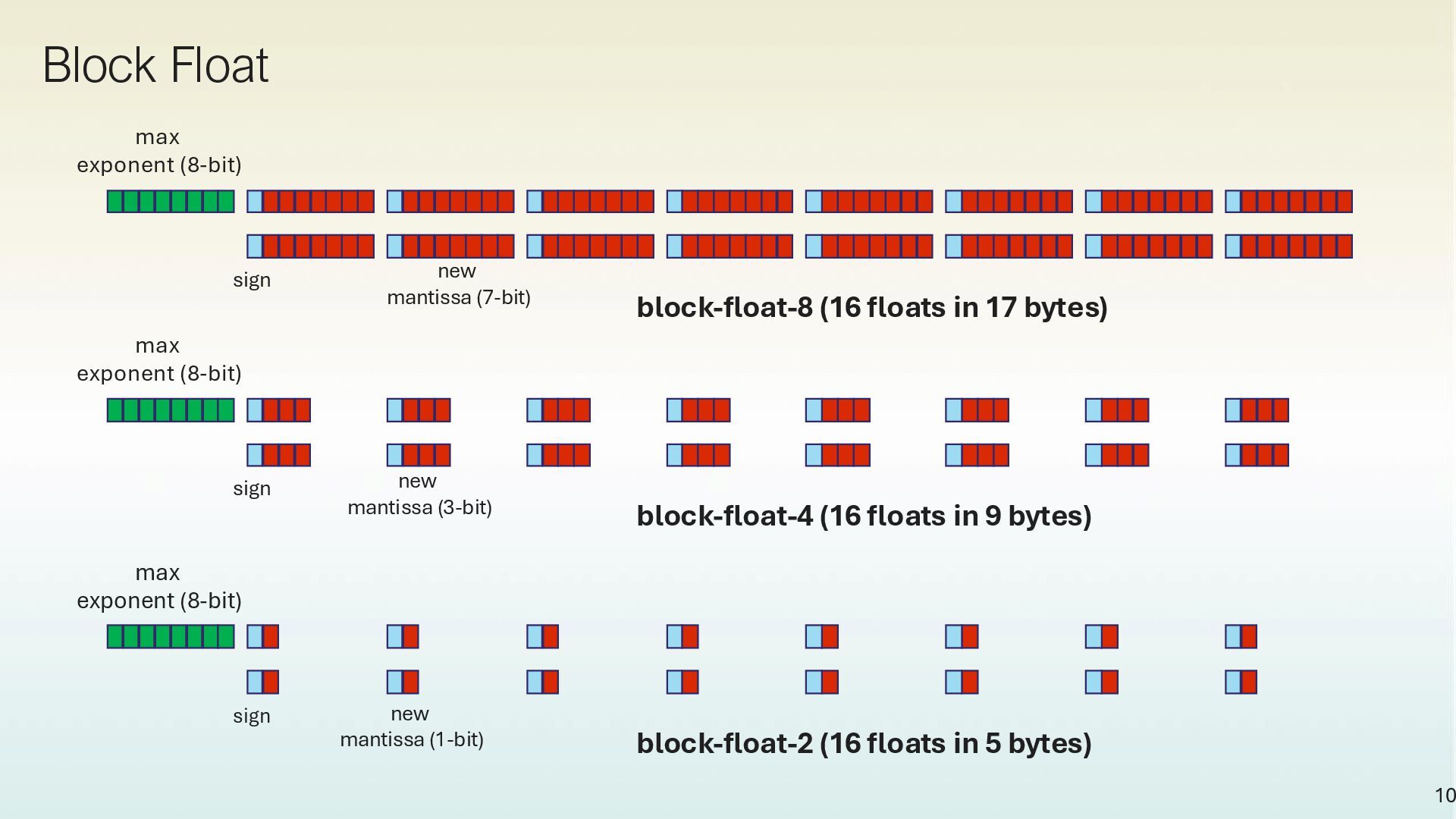
block-float-8 (16 floats in 17 bytes) max exponent (8-bit) sign new mantissa (3-bit) block-float-4 (16 floats in 9 bytes) max exponent (8-bit) sign new mantissa (1-bit) block-float-2 (16 floats in 5 bytes)
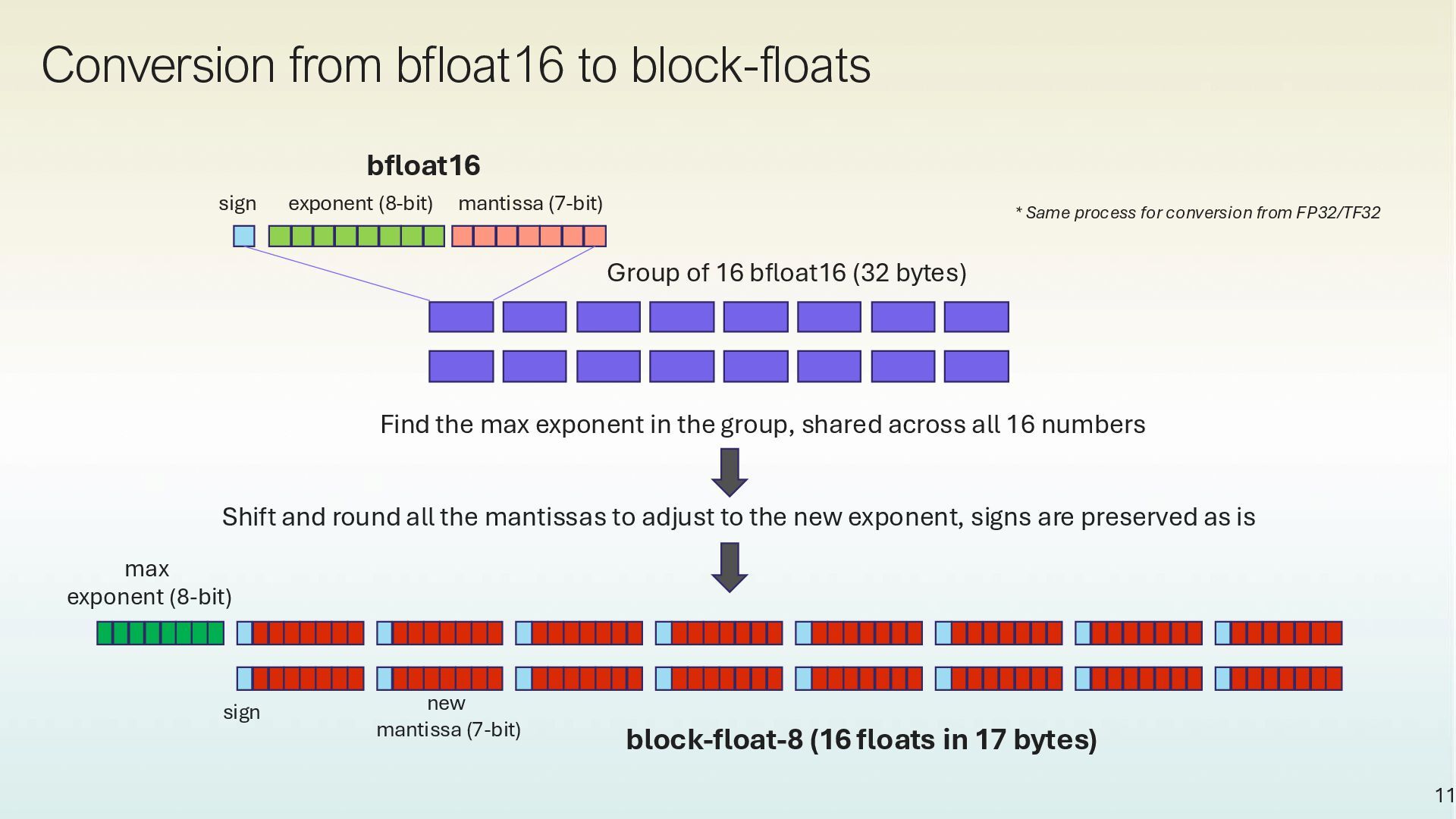
mantissa (7-bit) Group of 16 bfloat16 (32 bytes) Find the max exponent in the group, shared across all 16 numbers max exponent (8-bit) Shift and round all the mantissas to adjust to the new exponent, signs are preserved as is * Same process for conversion from FP32/TF32 sign new mantissa (7-bit) block-float-8 (16 floats in 17 bytes)
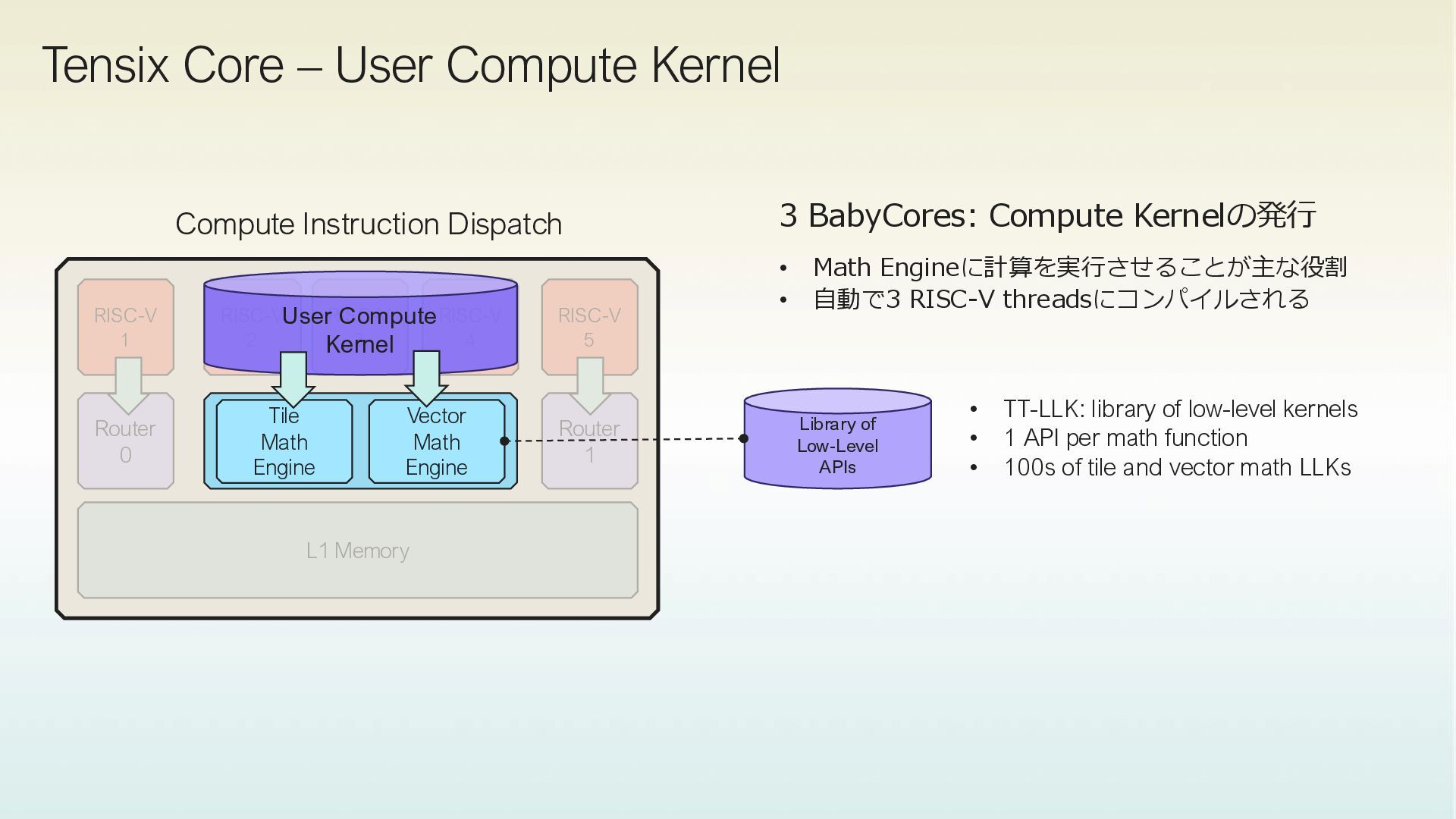
RISC-V 4 RISC-V 5 RISC-V 1 Router 1 Router 0 L1 Memory Tile Math Engine Vector Math Engine User Compute Kernel Library of Low-Level APIs • TT-LLK: library of low-level kernels • 1 API per math function • 100s of tile and vector math LLKs 3 BabyCores: Compute Kernelの発行 • Math Engineに計算を実行させることが主な役割 • 自動で3 RISC-V threadsにコンパイルされる Compute Instruction Dispatch
(phase4) Fidelityを変えることで精度と性能のトレードオフを制御する • WormholeとBlackholeのmultipliersは5bits x 7bits • matntissa bitsを1 cycleで計算できる • 小さいDataFormat(BFP4/2, etc)はこの1cycleで全て計算できる が、大きいDataFormatの場合にはMath Fidelityを使う • Math FidelityはDataFormatごとに4 fidelity phasesに分けられる • Mantissaの計算を複数Phaseにすることで性能と精度をコントロールする • 例: BFP16の場合 • LoFi : minimal precision, high performance • LoFi+HiFi2 : “reasonable” precision • Lofi~HiFi4 : full precision, low performance I I SrcA SrcB I I SrcA SrcB I I SrcA SrcB I I SrcA SrcB
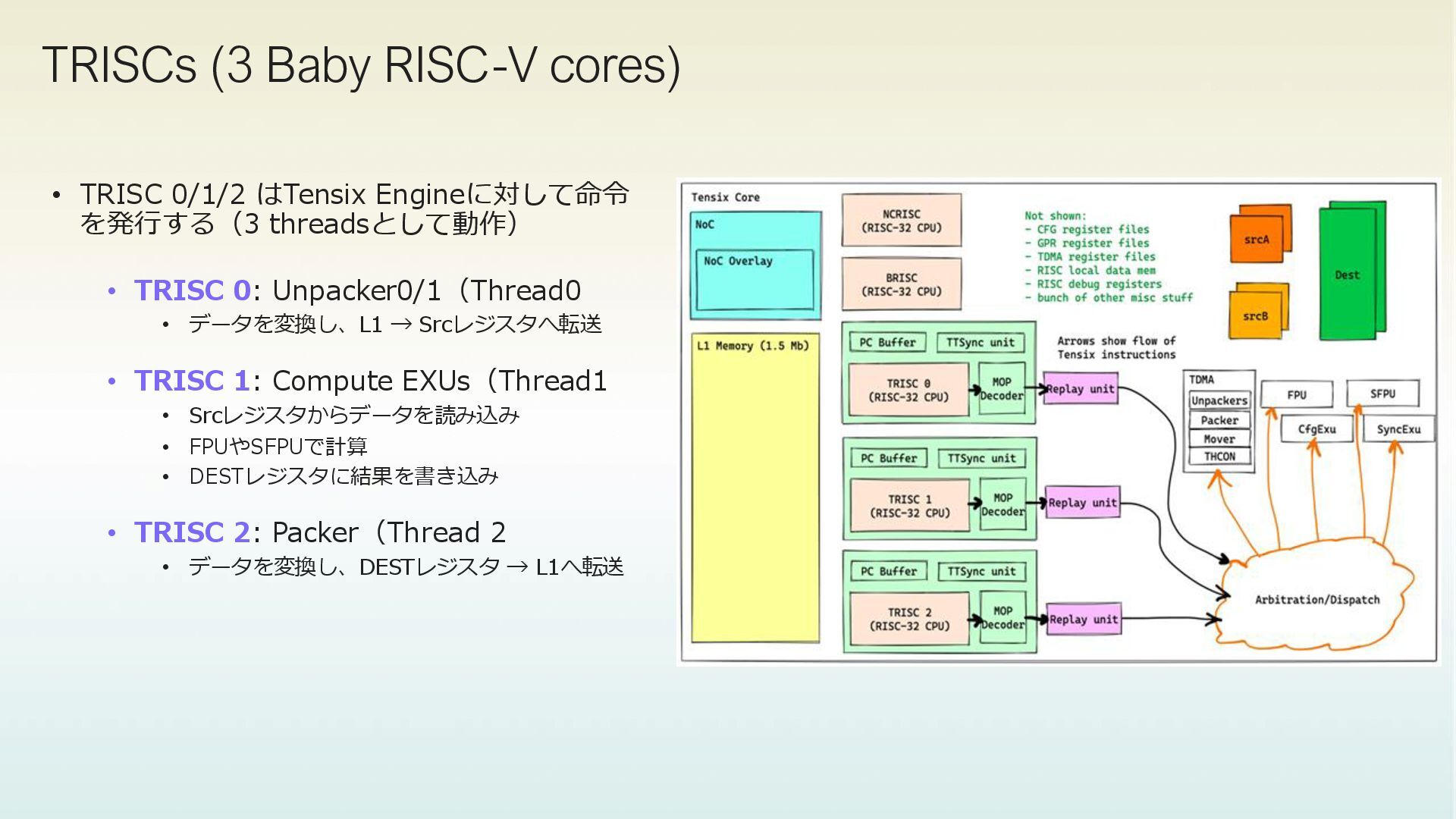
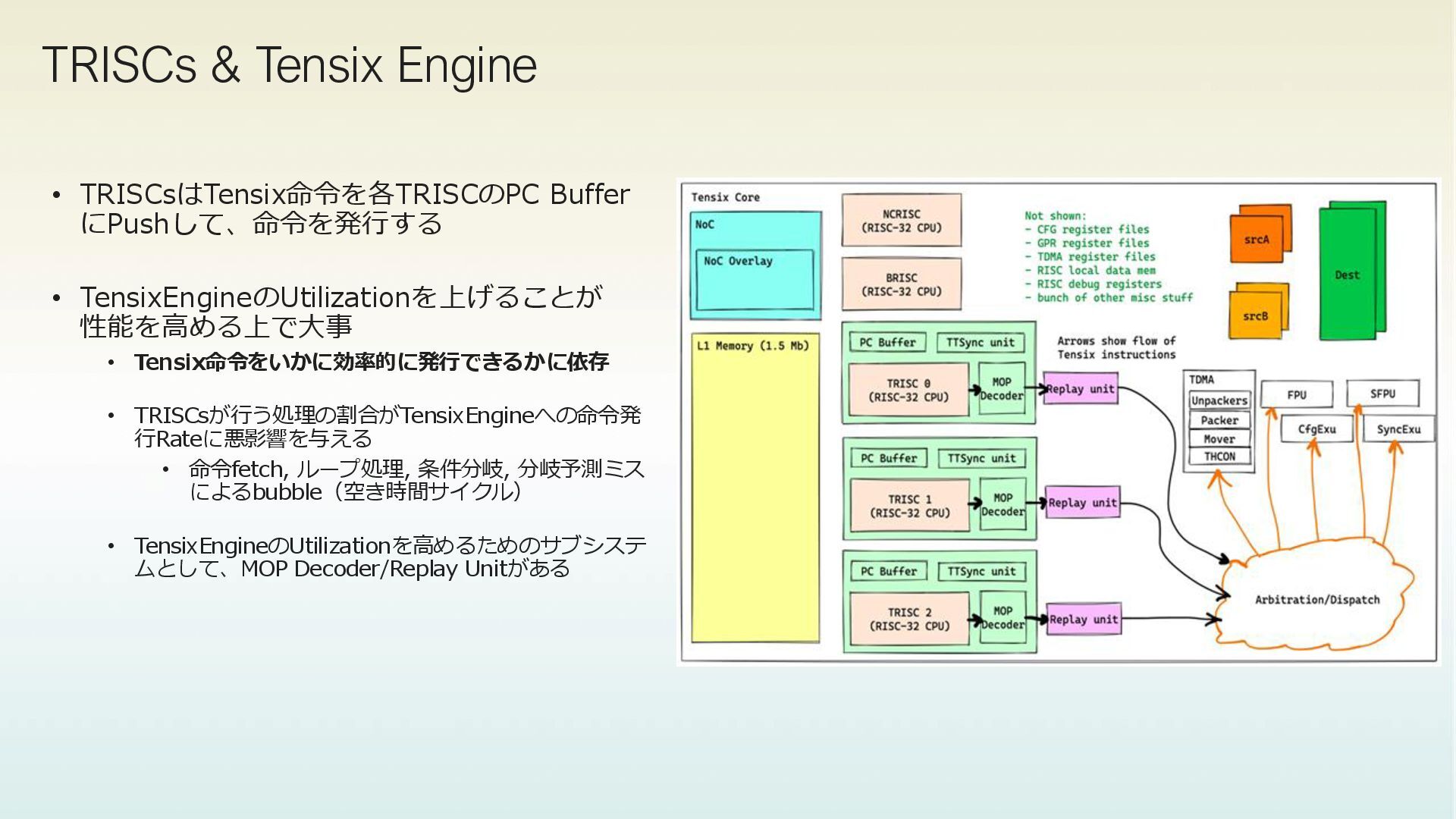
GPRsは192個あり、3 Tensix Threadsそれぞれが64GPRsを持つ Atomic Load/Store Bit Ops Add/Sub/Mul/Comp Other https://github.com/tenstorrent/tt-isa-documentation/blob/46e2c636ac41d6c4929e45ebd36f05679d12570d/WormholeB0/TensixTile/TensixCoprocessor/ScalarUnit.md
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}