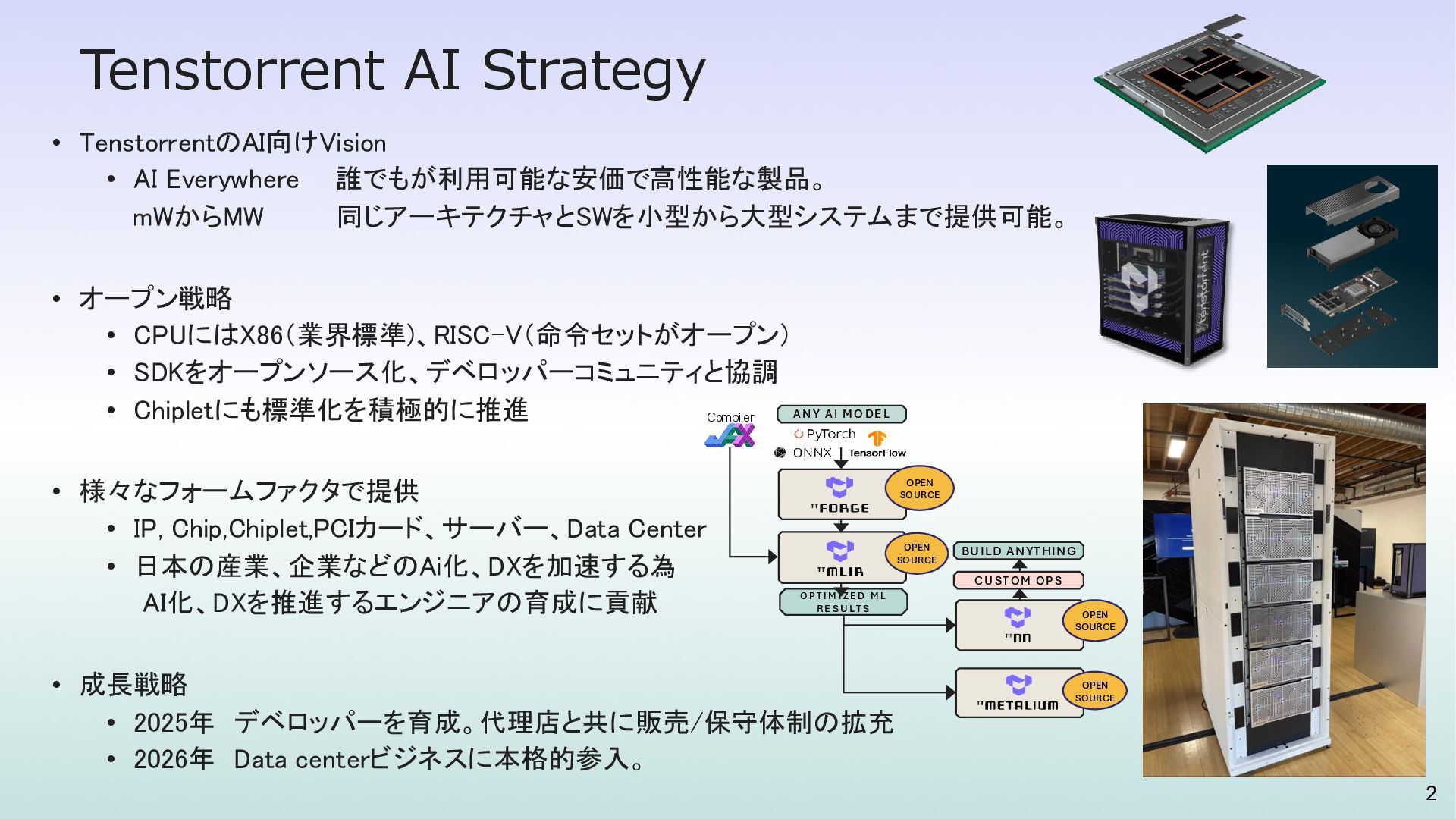
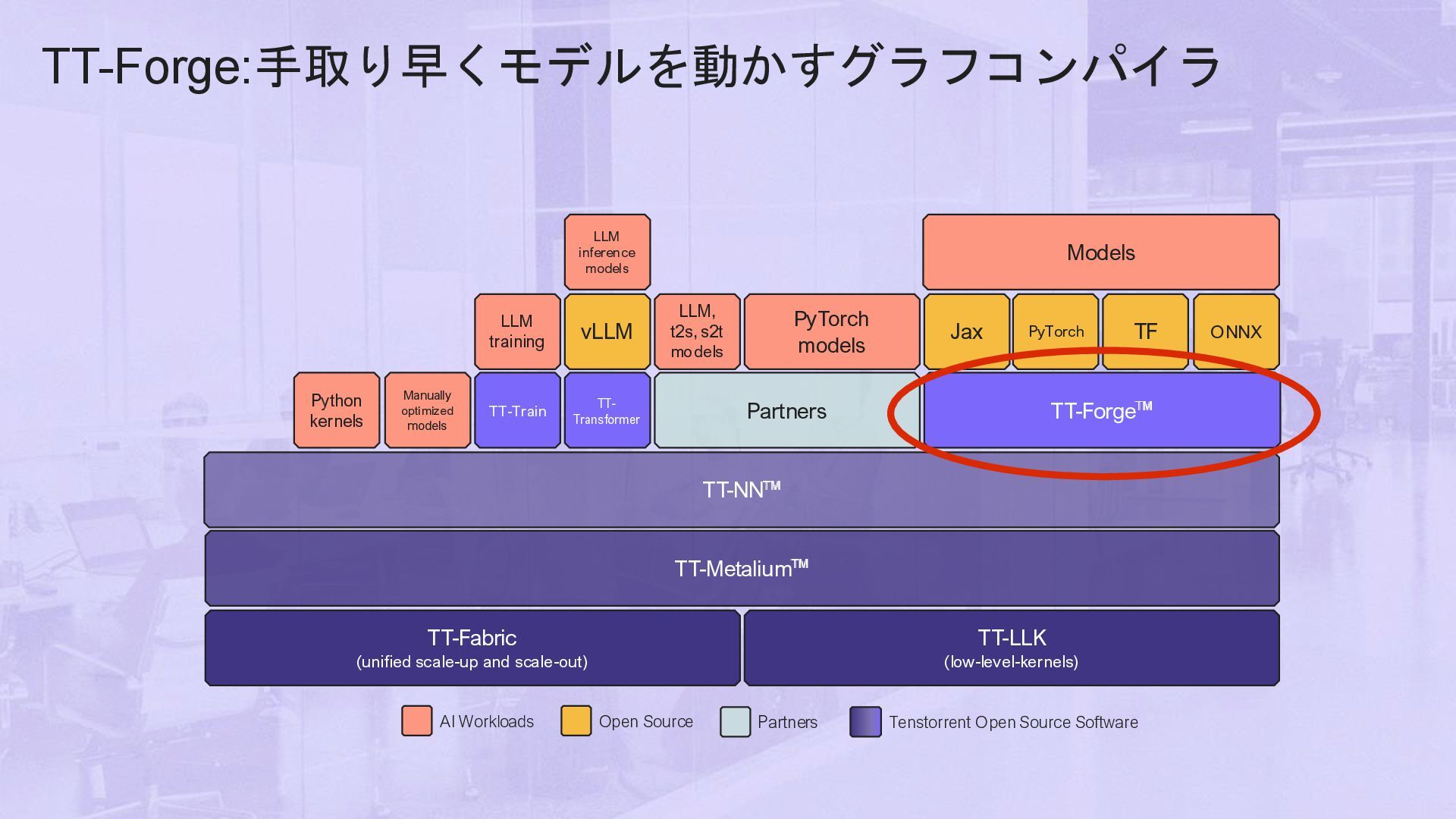
mWからMW 同じアーキテクチャとSWを小型から大型システムまで提供可能。 • オープン戦略 • CPUにはX86(業界標準)、RISC-V(命令セットがオープン) • SDKをオープンソース化、デベロッパーコミュニティと協調 • Chipletにも標準化を積極的に推進 • 様々なフォームファクタで提供 • IP, Chip,Chiplet,PCIカード、サーバー、Data Center • 日本の産業、企業などのAi化、DXを加速する為 AI化、DXを推進するエンジニアの育成に貢献 • 成長戦略 • 2025年 デベロッパーを育成。代理店と共に販売/保守体制の拡充 • 2026年 Data centerビジネスに本格的参入。 ANY AI MO DE L OPEN SOURCE OPEN SOURCE O P T I M I ZE D M L R E S U L T S CUSTOM OPS BUILD ANYTHING OPEN SOURCE OPEN SOURCE Compiler
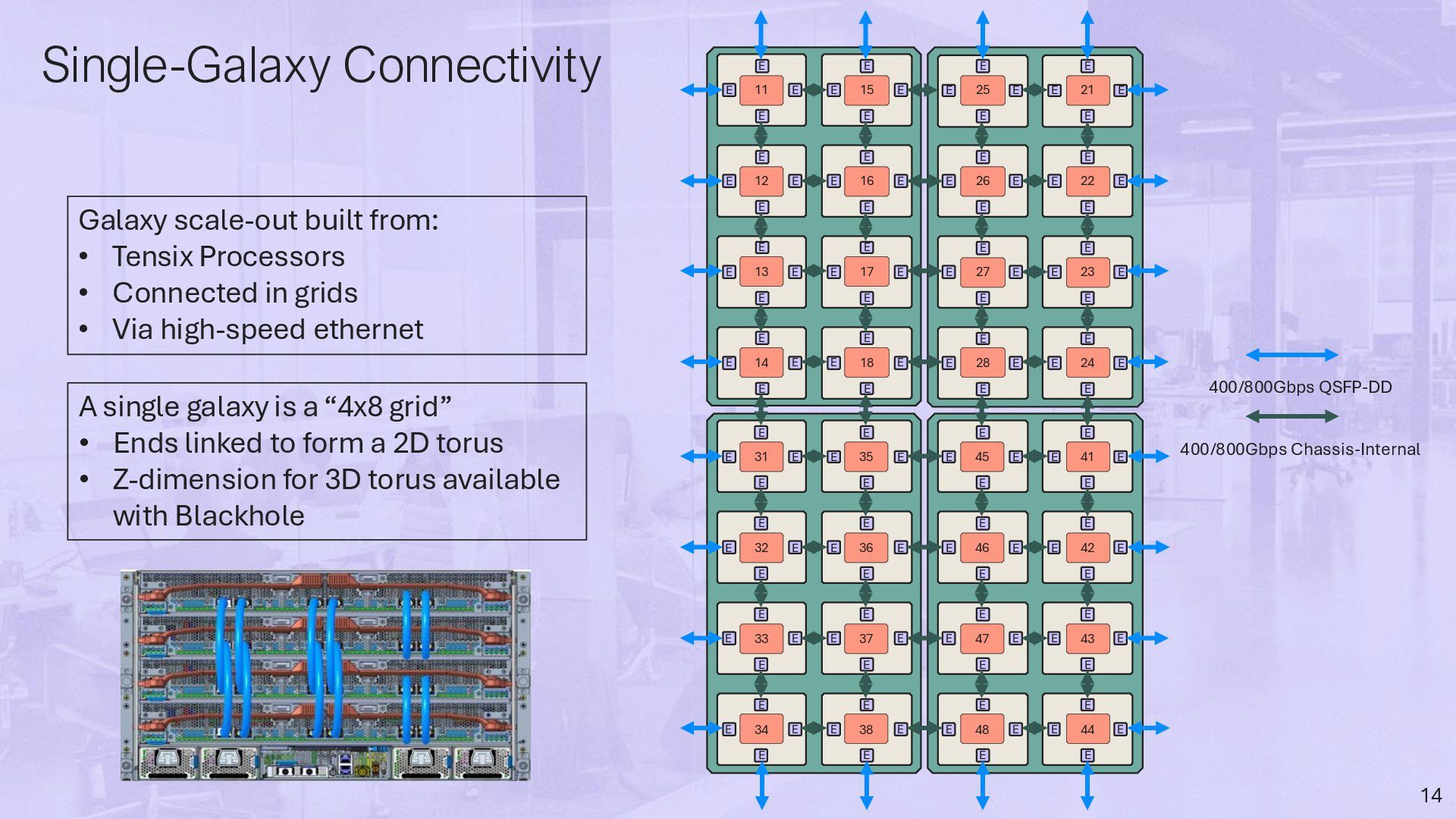
E E E 13 E E E E 14 E E E E 15 E E E E 16 E E E E 17 E E E E 18 E E E E 21 E E E E 22 E E E E 23 E E E E 24 E E E E 25 E E E E 26 E E E E 27 E E E E 28 E E E E 31 E E E E 32 E E E E 33 E E E E 34 E E E E 35 E E E E 36 E E E E 37 E E E E 38 E E E E 41 E E E E 42 E E E E 43 E E E E 44 E E E E 45 E E E E 46 E E E E 47 E E E E 48 E E E E 400/800Gbps QSFP-DD 400/800Gbps Chassis-Internal Galaxy scale-out built from: • Tensix Processors • Connected in grids • Via high-speed ethernet A single galaxy is a “4x8 grid” • Ends linked to form a 2D torus • Z-dimension for 3D torus available with Blackhole
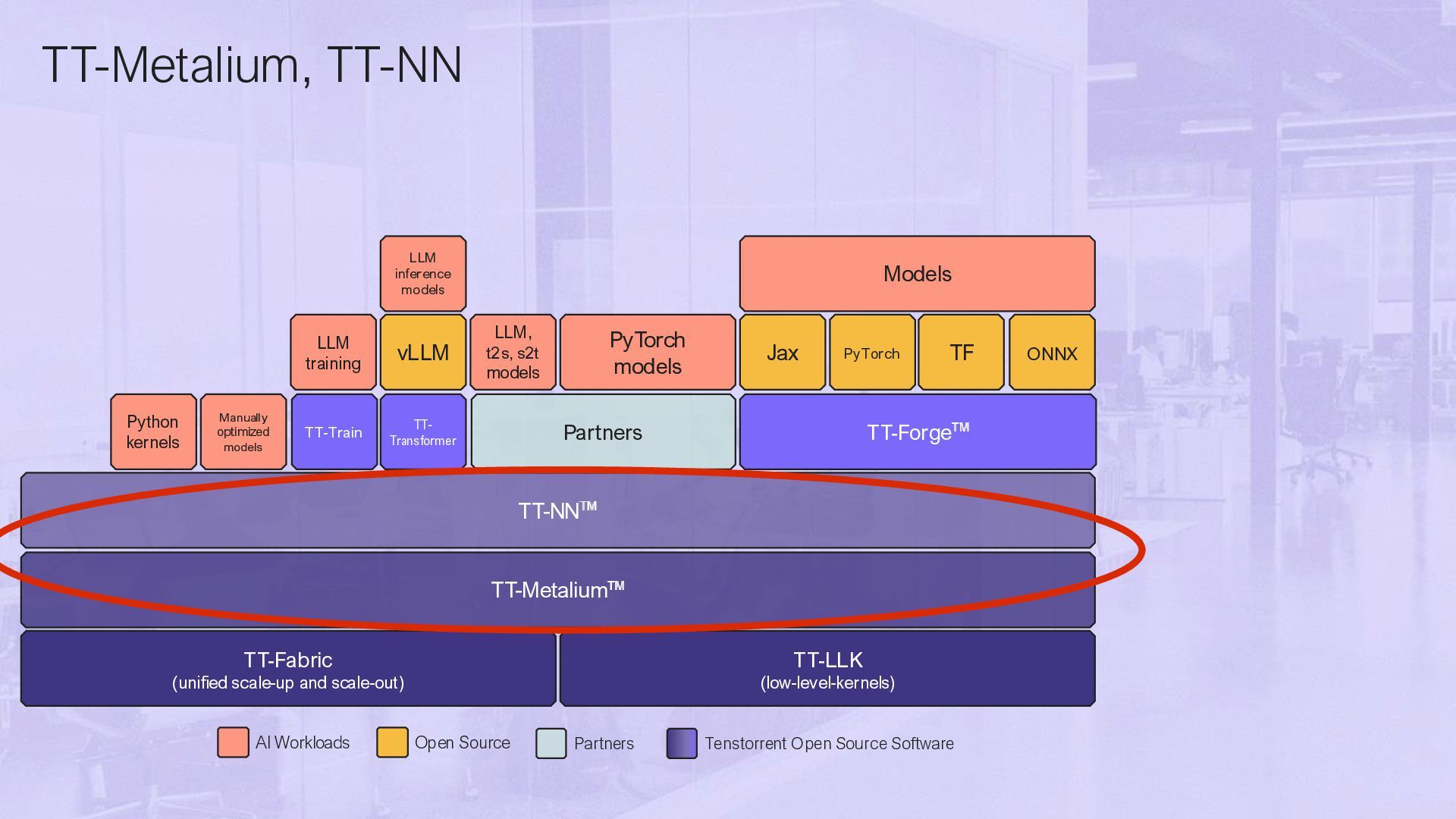
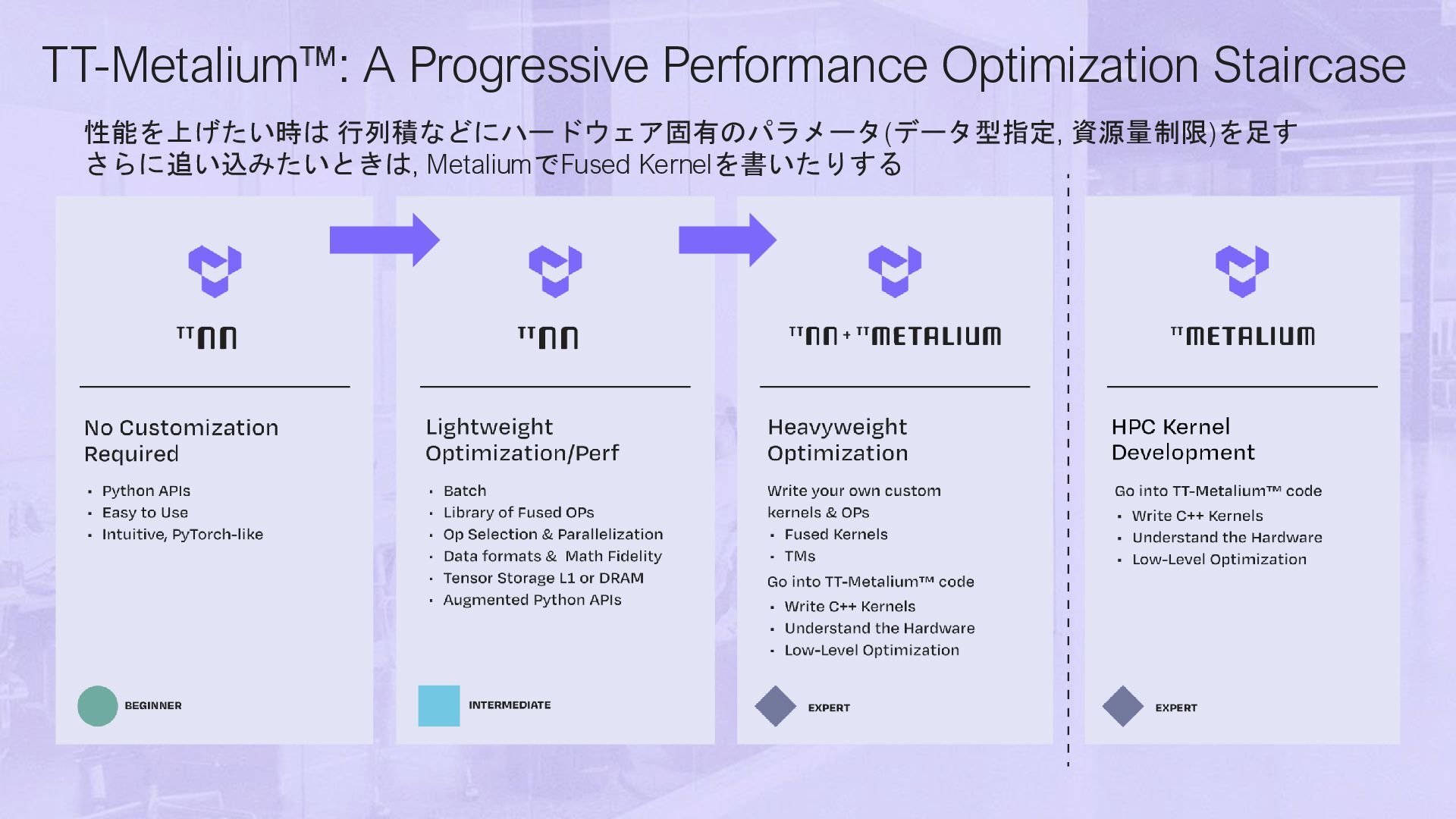
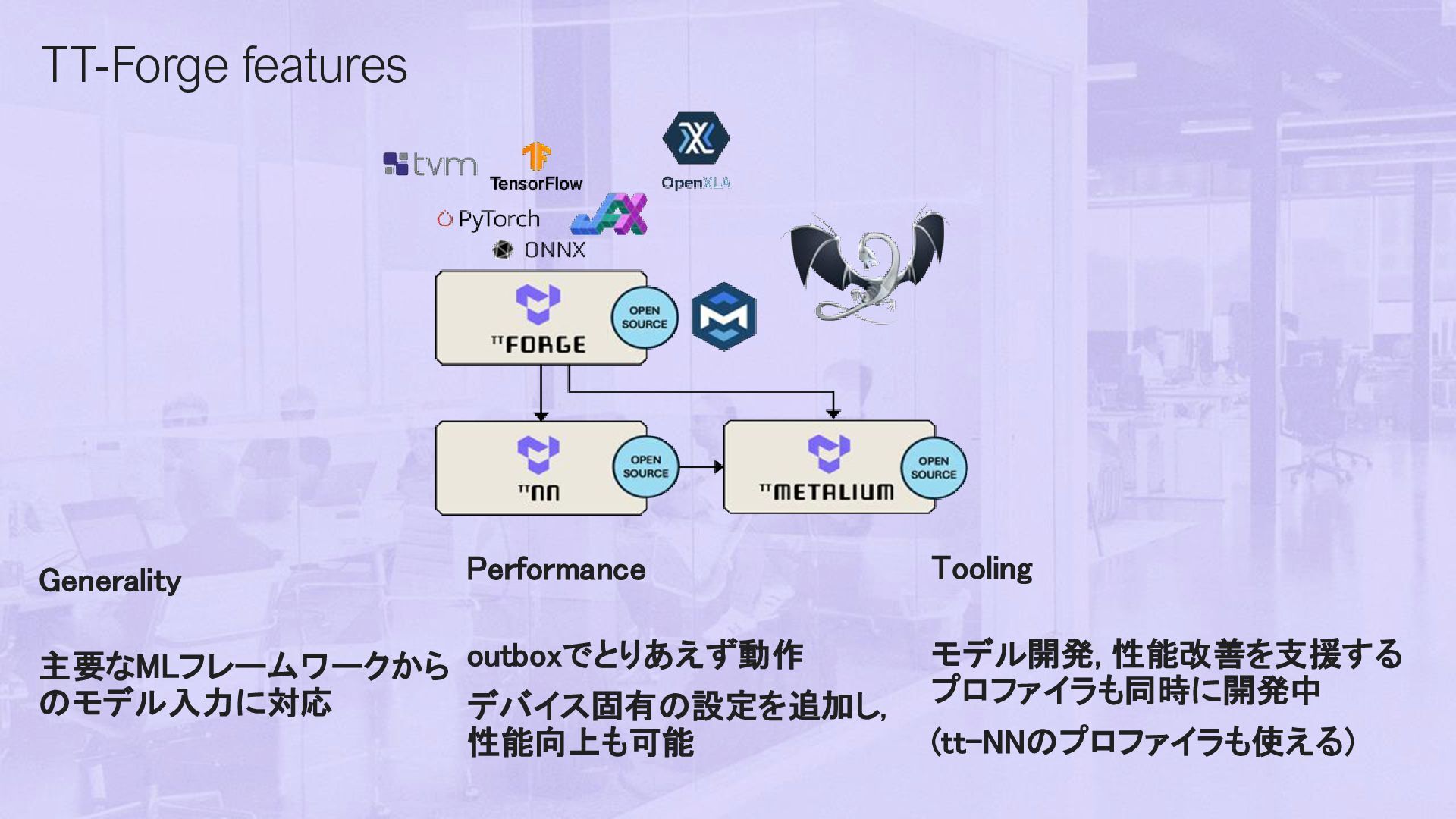
and Ops TT-Metalium GPU Programming (詳細は第二回あたりで特集します) • Tensixコア毎に, データ出し入れ/計算の3つのKernel • 普通の?C++で書ける • SRAM/DRAM/別チップへのアクセスも自由 裏を返すと 最も低水準なところではTensixへのタスク割当て, メモリの管理も手動. それは流石にしんどいので TT-NNなどのライブラリは, 上記を自動でやってく れるものの上に実装. Deep Learning Ops Collective Comms Ops VS. TT-Metalium C++ Host API TT-Metalium C++ Kernel API TT-NN C++ Host API GPU Kernel Language DNN CCL
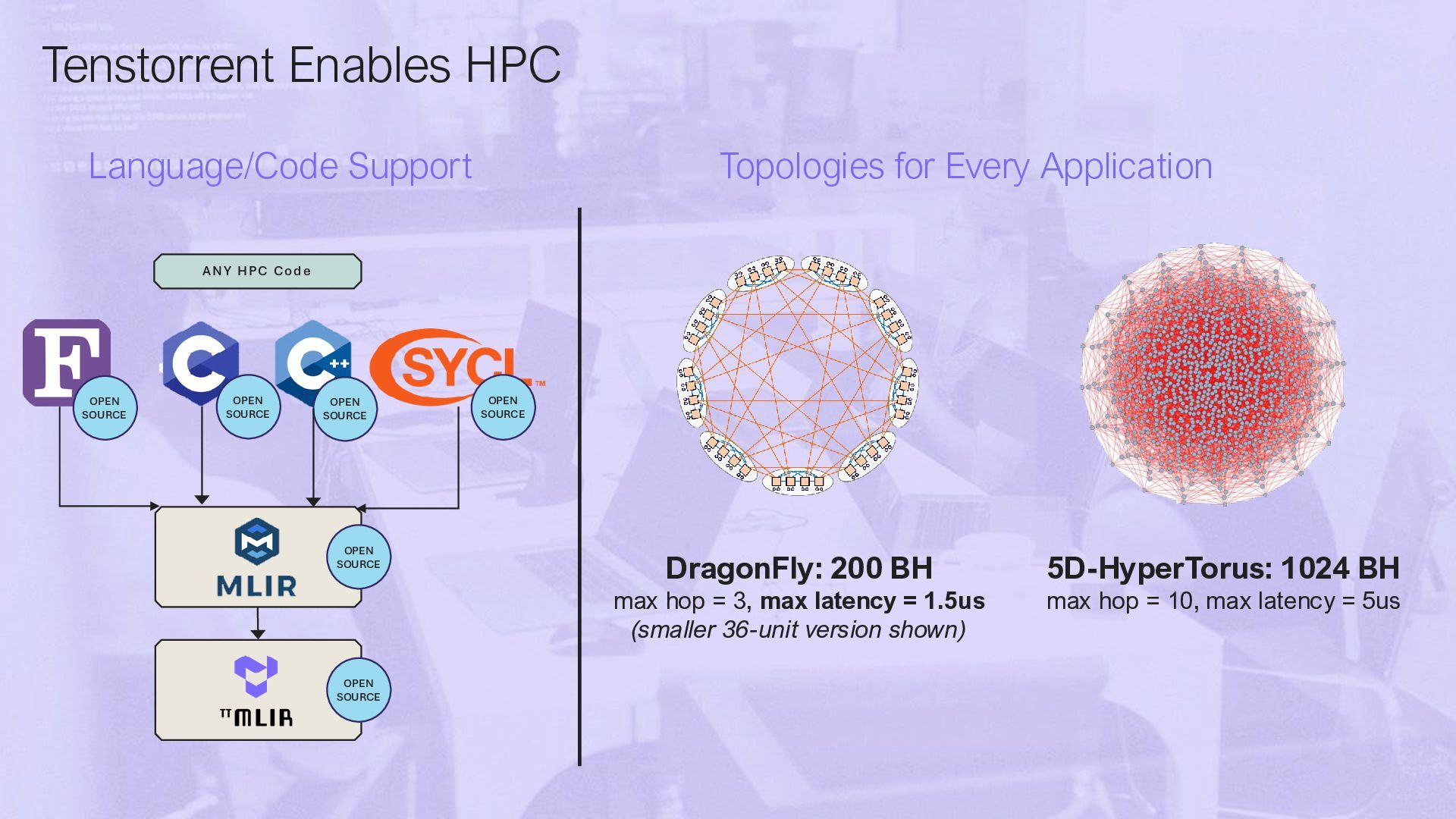
HPC Cod e OPEN SOURCE OPEN SOURCE OPEN SOURCE OPEN SOURCE OPEN SOURCE OPEN SOURCE DragonFly: 200 BH max hop = 3, max latency = 1.5us (smaller 36-unit version shown) 5D-HyperTorus: 1024 BH max hop = 10, max latency = 5us
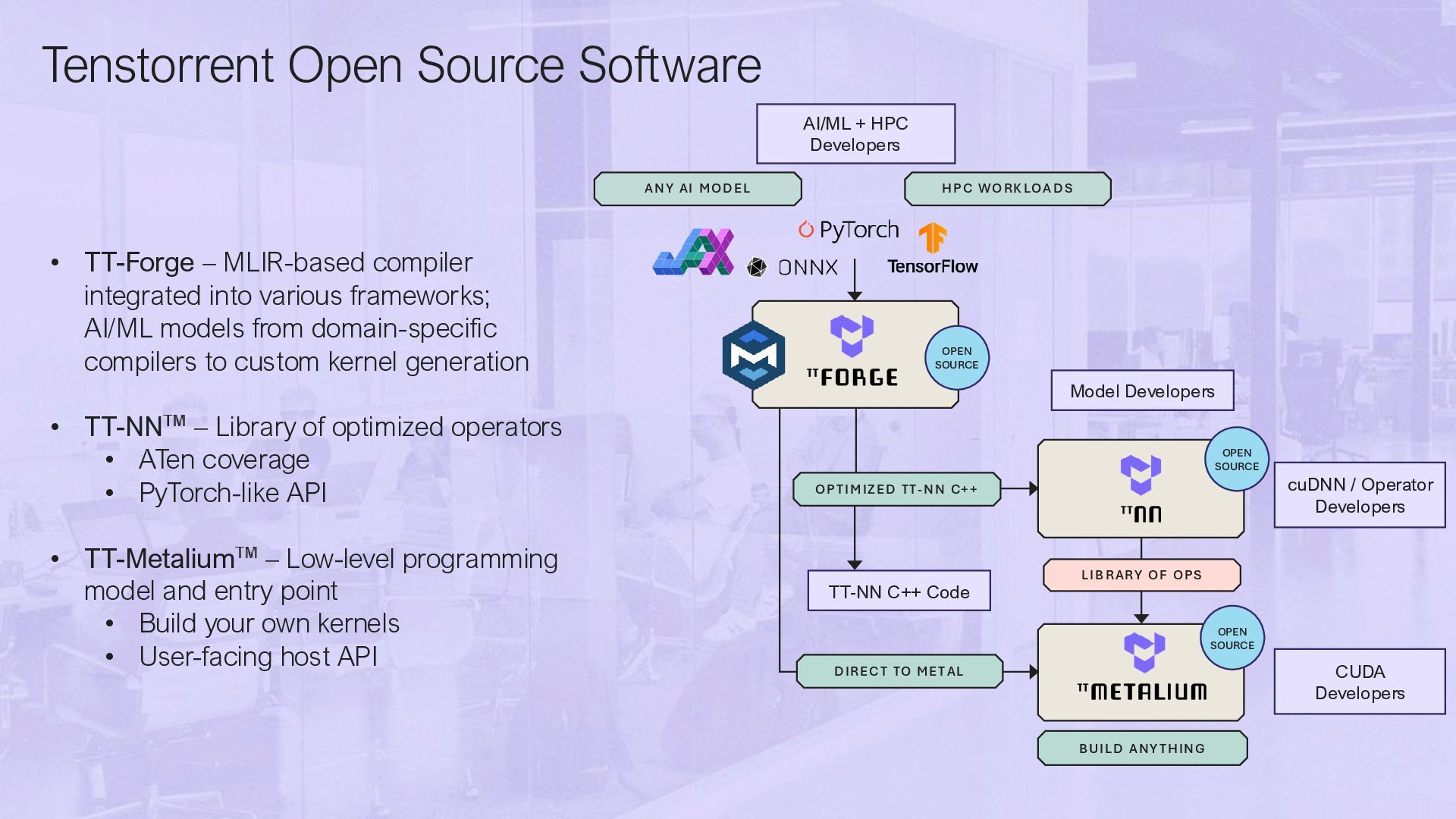
into various frameworks; AI/ML models from domain-specific compilers to custom kernel generation • TT-NN – Library of optimized operators • ATen coverage • PyTorch-like API • TT-Metalium – Low-level programming model and entry point • Build your own kernels • User-facing host API ANY AI MODEL OPEN SOURCE OPEN SOURCE AI/ML + HPC Developers Model Developers cuDNN / Operator Developers CUDA Developers DIRECT TO MET AL OP TIMIZED TT-NN C++ BUILD ANY THING LIBRARY OF OPS OPEN SOURCE TT-NN C++ Code HP C WO RK LOADS
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
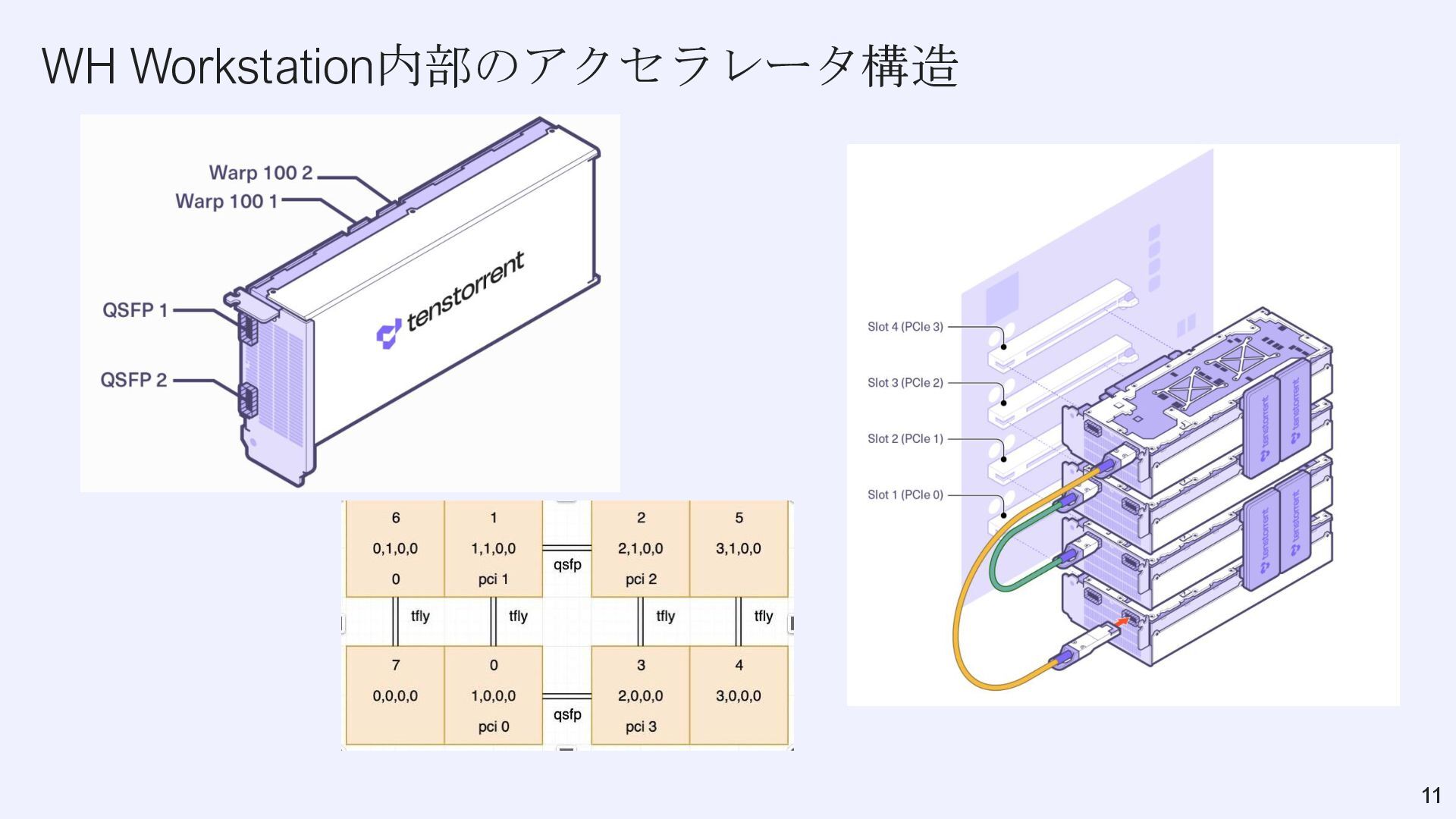{kind=link}
{kind=link}
{kind=link}
{kind=link}
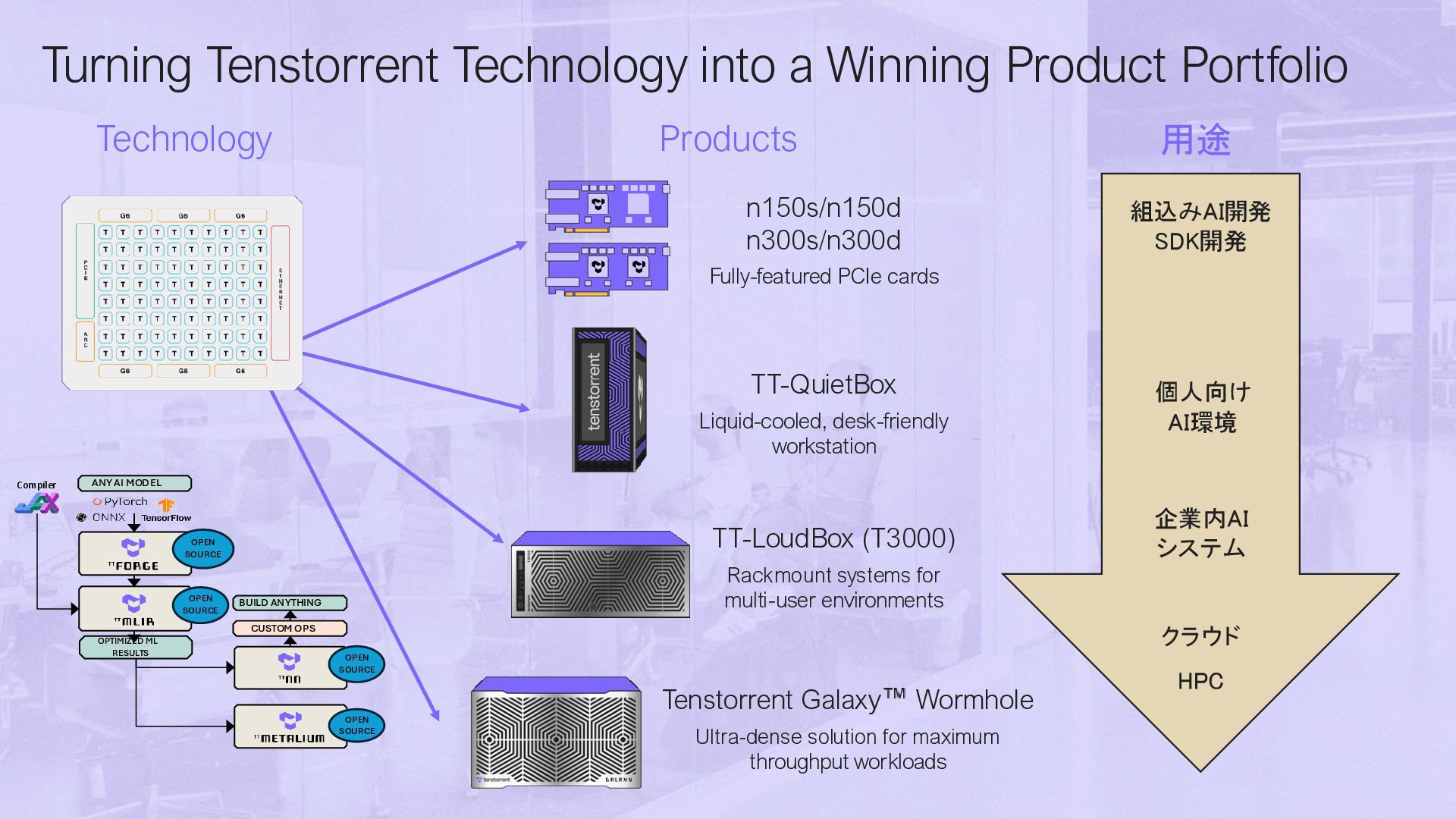{kind=link}
{kind=link}
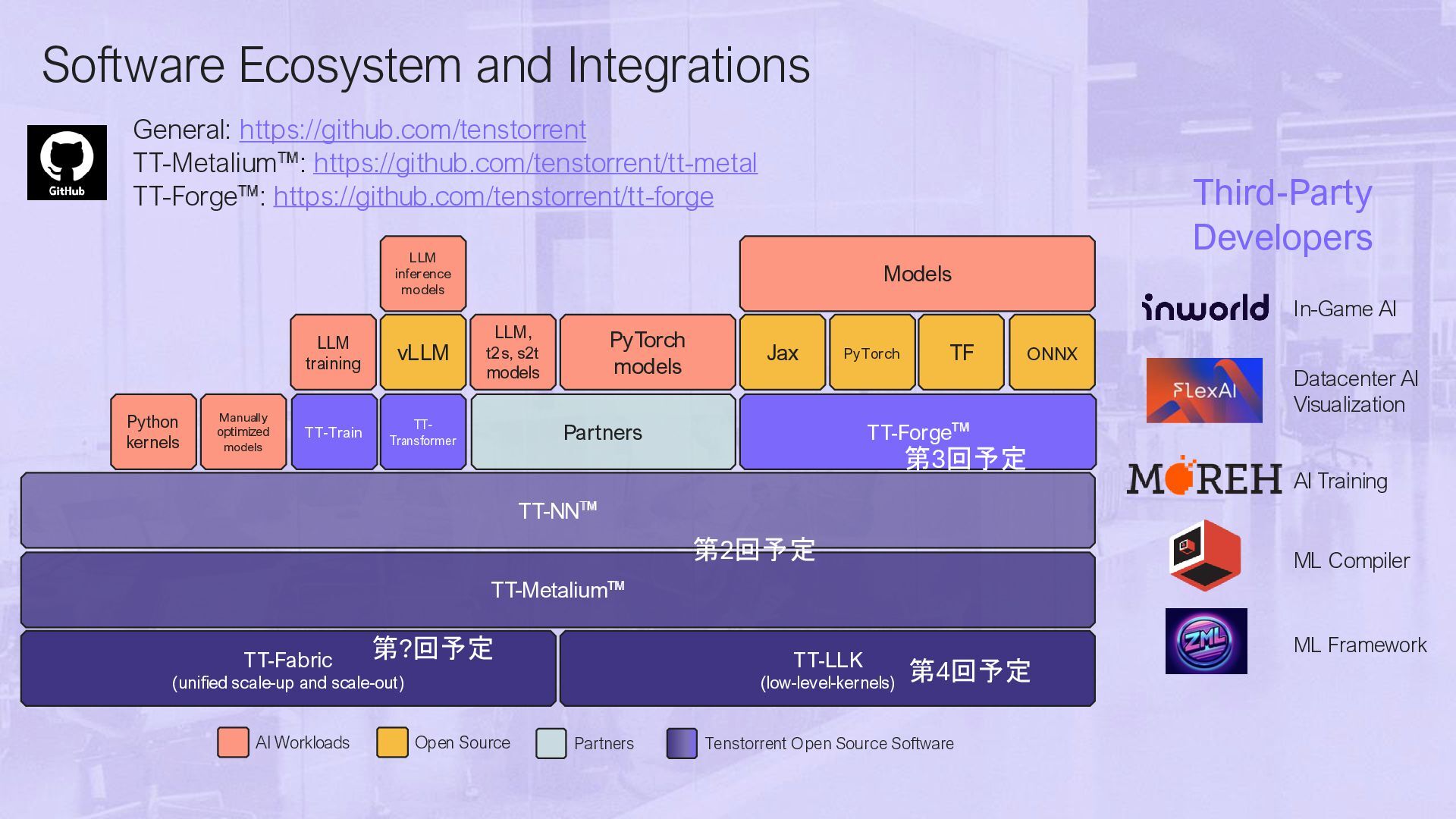{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}