Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
機械学習 - 授業概要
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Y. Yamamoto
PRO
April 13, 2026
Science
560
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
機械学習 - 授業概要
Y. Yamamoto
PRO
April 13, 2026
More Decks by Y. Yamamoto
See All by Y. Yamamoto
データベース15: ビッグデータ時代のデータベース
trycycle
PRO
1
490
データベース14: B+木 & ハッシュ索引
trycycle
PRO
0
770
データベース12: 正規化(2/2) - データ従属性に基づく正規化
trycycle
PRO
0
1.5k
データベース11: 正規化(1/2) - 望ましくない関係スキーマ
trycycle
PRO
0
1.5k
データベース10: 拡張実体関連モデル
trycycle
PRO
0
1.4k
データベース09: 実体関連モデル上の一貫性制約
trycycle
PRO
0
1.6k
機械学習 - ニューラルネットワーク入門
trycycle
PRO
0
1.1k
データベース08: 実体関連モデルとは?
trycycle
PRO
0
1.5k
機械学習 - SVM
trycycle
PRO
2
1.2k
Other Decks in Science
See All in Science
プロジェクト「Azayaka」のSARの数式とジオメトリ
syuchimu
0
390
生成AIが科学とRAにもたらしていること:メタサイエンスの視点から
rmaruy
0
110
YouTubeにおける撤回論文の参照実態 / metascience-meetup2026
corgies
3
310
J-STAGE全文XML登載必須化について
xspa2012
0
1.2k
AkarengaLT vol.40
hashimoto_kei
0
120
1. CPC理論の展開と集合的知能モデル(JSAI2026 KS-27 集合的予測符号化と新たな知性の時代)
hayashiyus884
1
310
Cross-Media Technologies, Information Science and Human-Information Interaction
signer
PRO
3
32k
力学系から見た現代的な機械学習
hanbao
4
4.3k
Understanding CVP Waveforms: Interpretation and Clinical Implications in Anesthesiology
taka88
0
690
[NLP2026 参加報告会] AI for Science まとめ / NLP2026
lychee1223
0
1.9k
人生を変えた一冊「独学大全」のはなし / Self-study ENCYCLOPEDIA: The Book Which Change My Life #独学大全 #EM推し本
expajp
0
180
Bリーグのショットデータを活用した得点期待値モデルの構築 / Construction of expected points model using shot data of B.LEAGUE
konakalab
0
170
Featured
See All Featured
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
420
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
310
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
Ethics towards AI in product and experience design
skipperchong
2
330
Balancing Empowerment & Direction
lara
6
1.2k
Google's AI Overviews - The New Search
badams
0
1.1k
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
230
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
270
Paper Plane
katiecoart
PRO
2
52k
Darren the Foodie - Storyboard
khoart
PRO
3
3.5k
Transcript
授業概要 ⼭本 祐輔 名古屋市⽴⼤学 データサイエンス研究科
[email protected]
第1回 機械学習発展 (前半パート)
シラバス情報 科目名 機械学習発展 2 開講学期 3年次 前期 科目区分 選択 担当教員
山本祐輔・小山先生
初回授業のメニュー 1. 機械学習の概要 3. はじめての機械学習 2. 講義の進め方 今のAIは何ができる? 「決定木」を 体験してみよう
何をどうやって学ぶのか? 13
機械学習の概要 1 今のAIは何ができるのか? 14
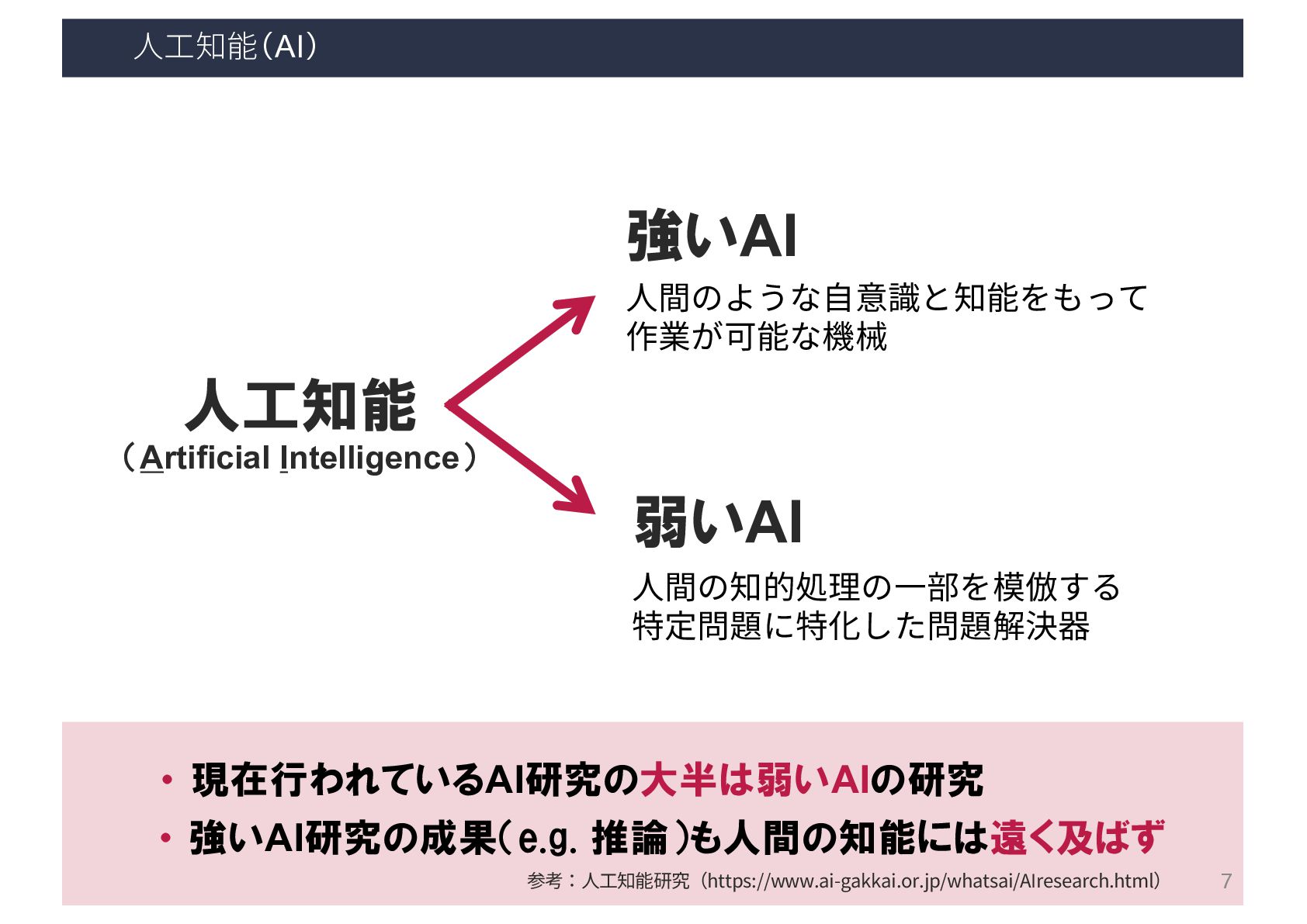
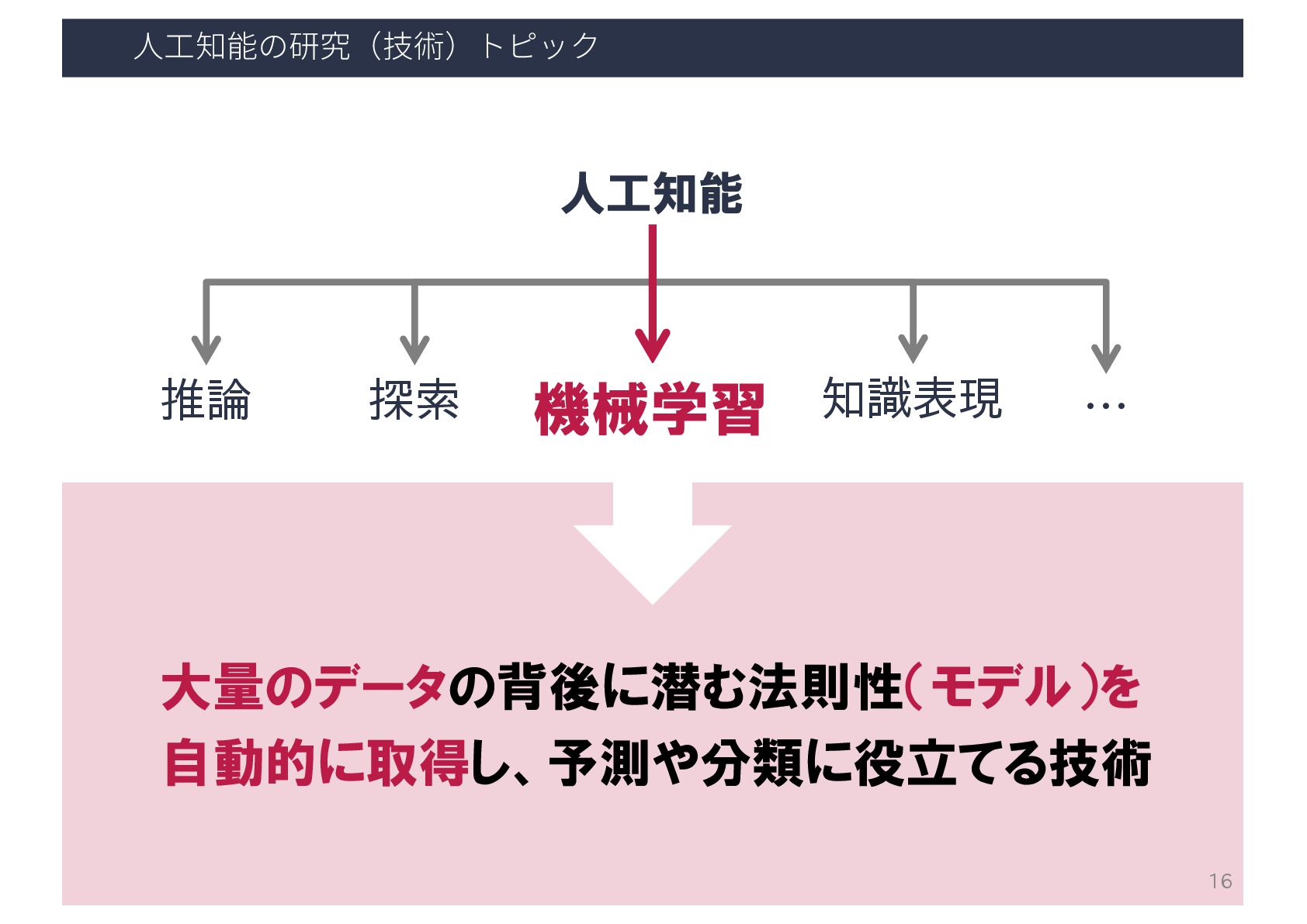
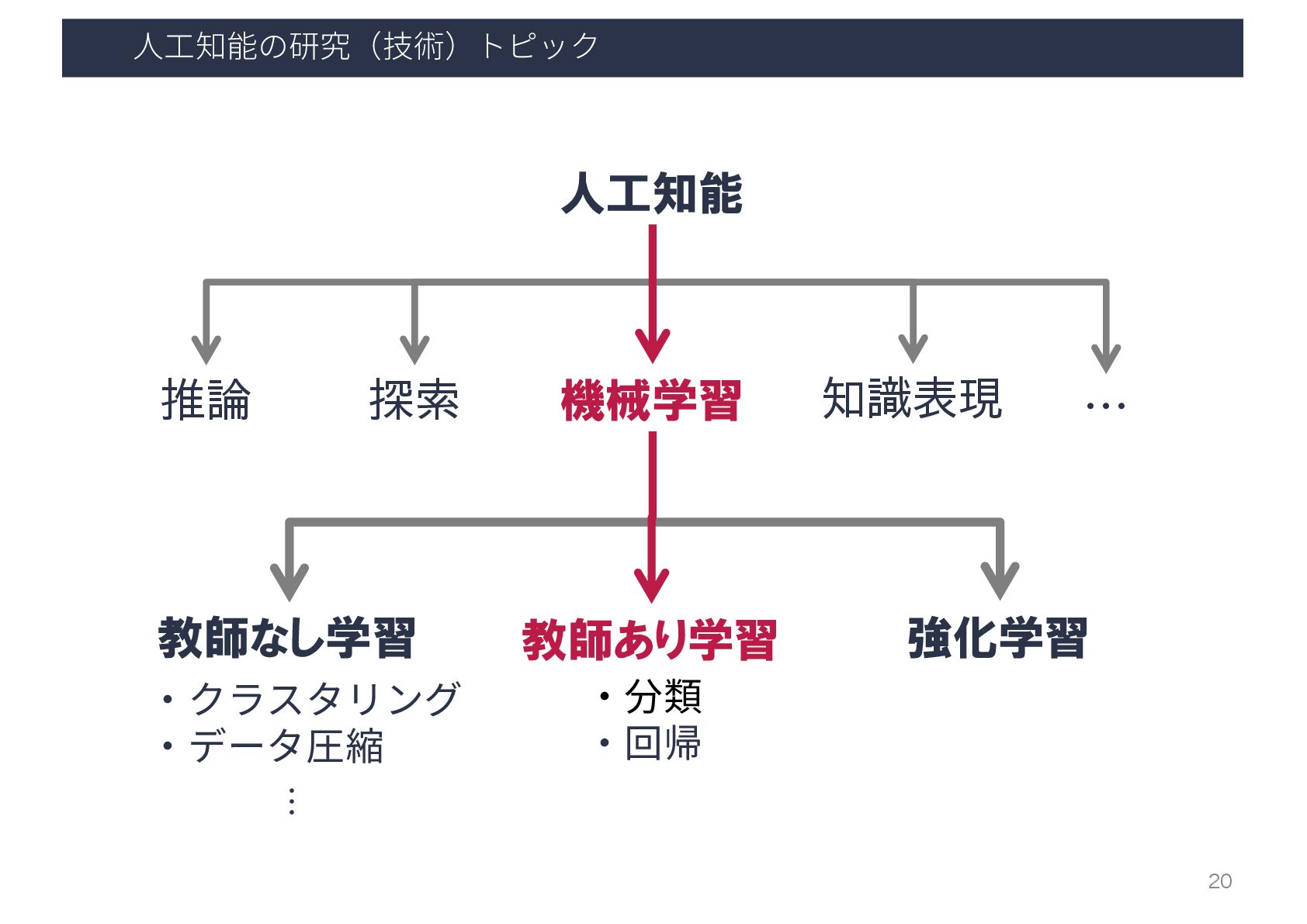
⼈⼯知能の研究(技術)トピック 人工知能 推論 探索 機械学習 知識表現 … 15
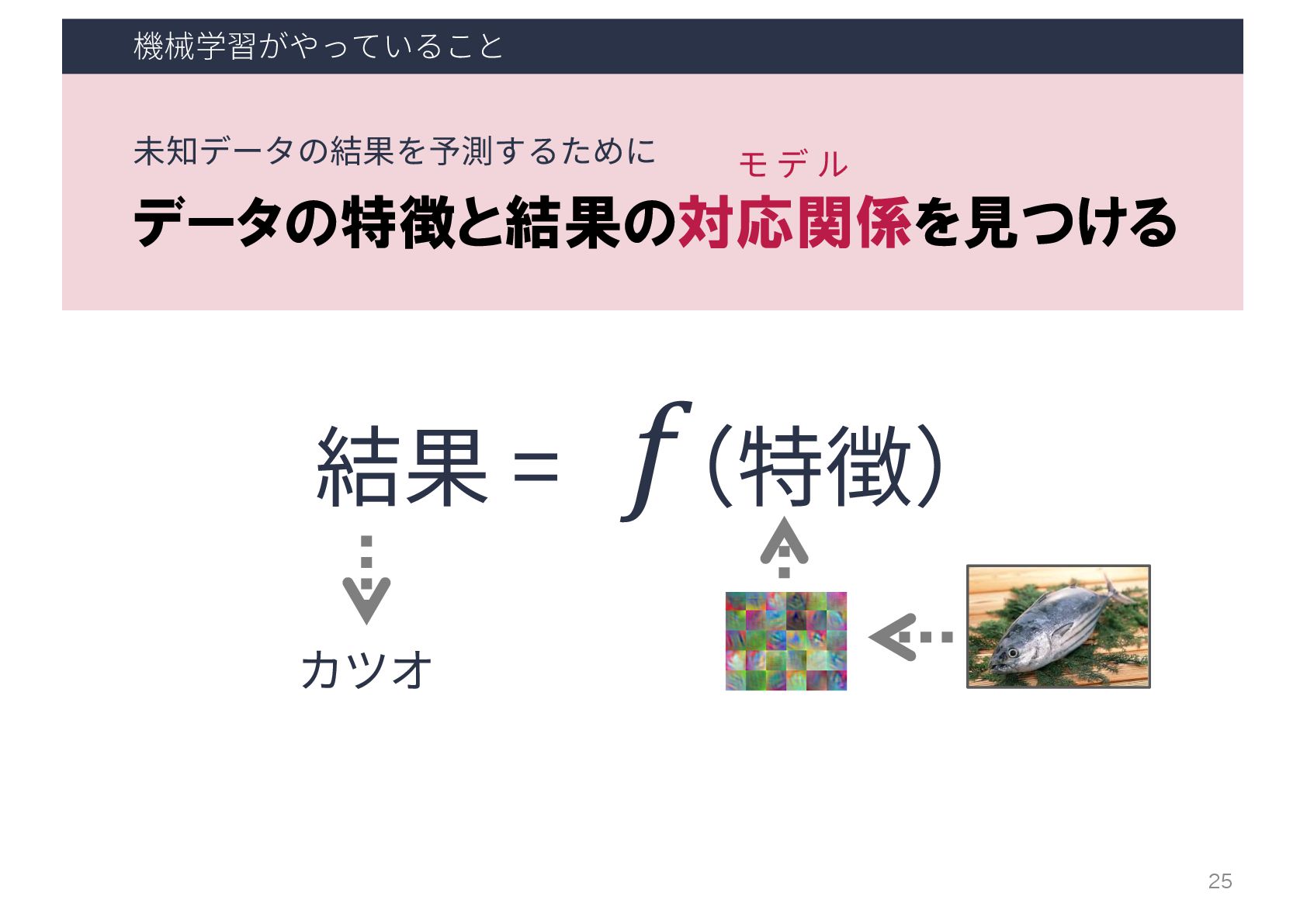
⼈⼯知能の研究(技術)トピック 人工知能 推論 探索 機械学習 知識表現 … 機械学習 大量のデータの背後に潜む法則性(モデル)を 自動的に取得し、予測や分類に役立てる技術
16
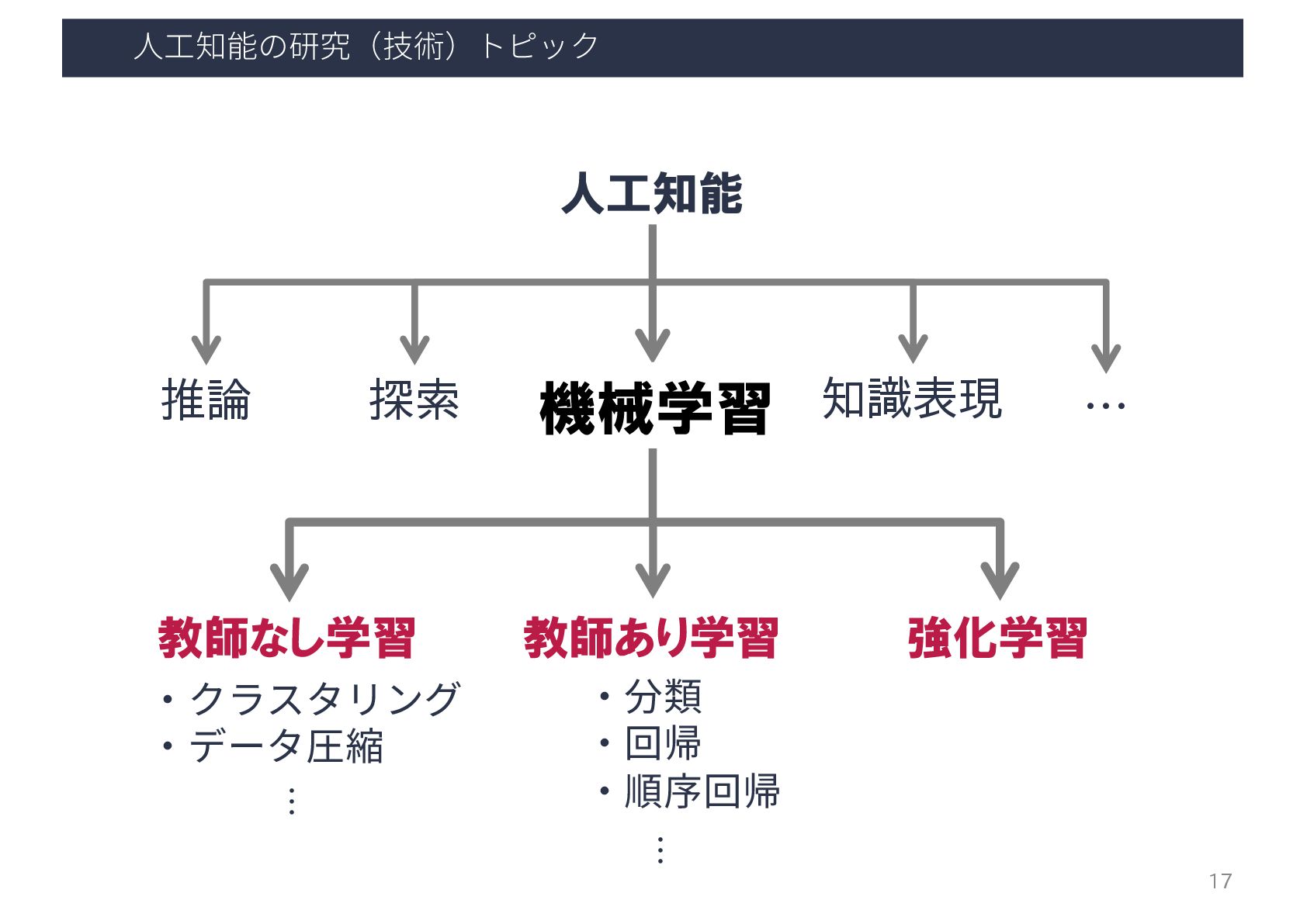
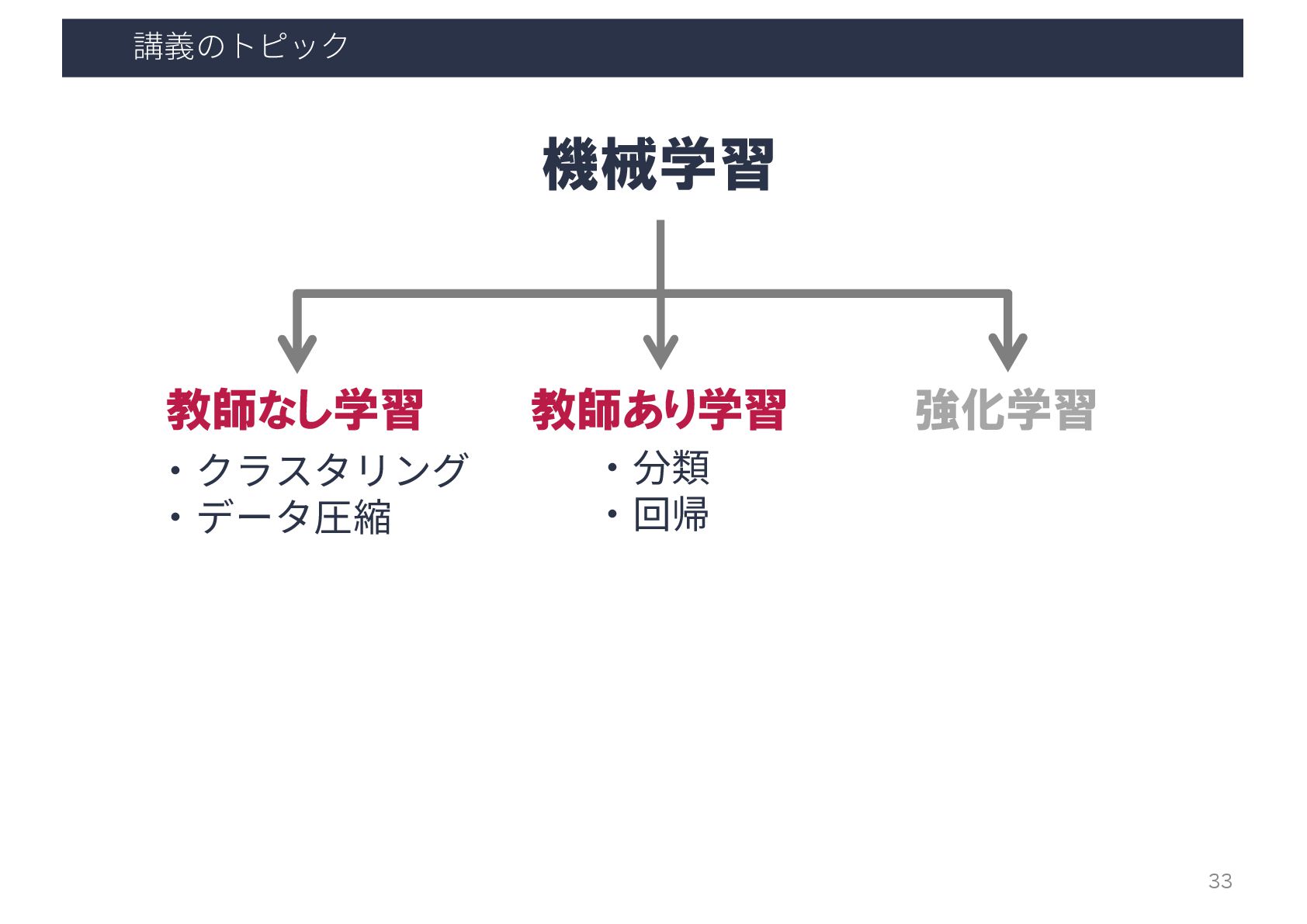
⼈⼯知能の研究(技術)トピック 人工知能 推論 探索 機械学習 知識表現 … 教師あり学習 教師なし学習 強化学習
・クラスタリング ・データ圧縮 ・分類 ・回帰 ・順序回帰 … 機械学習 17 …
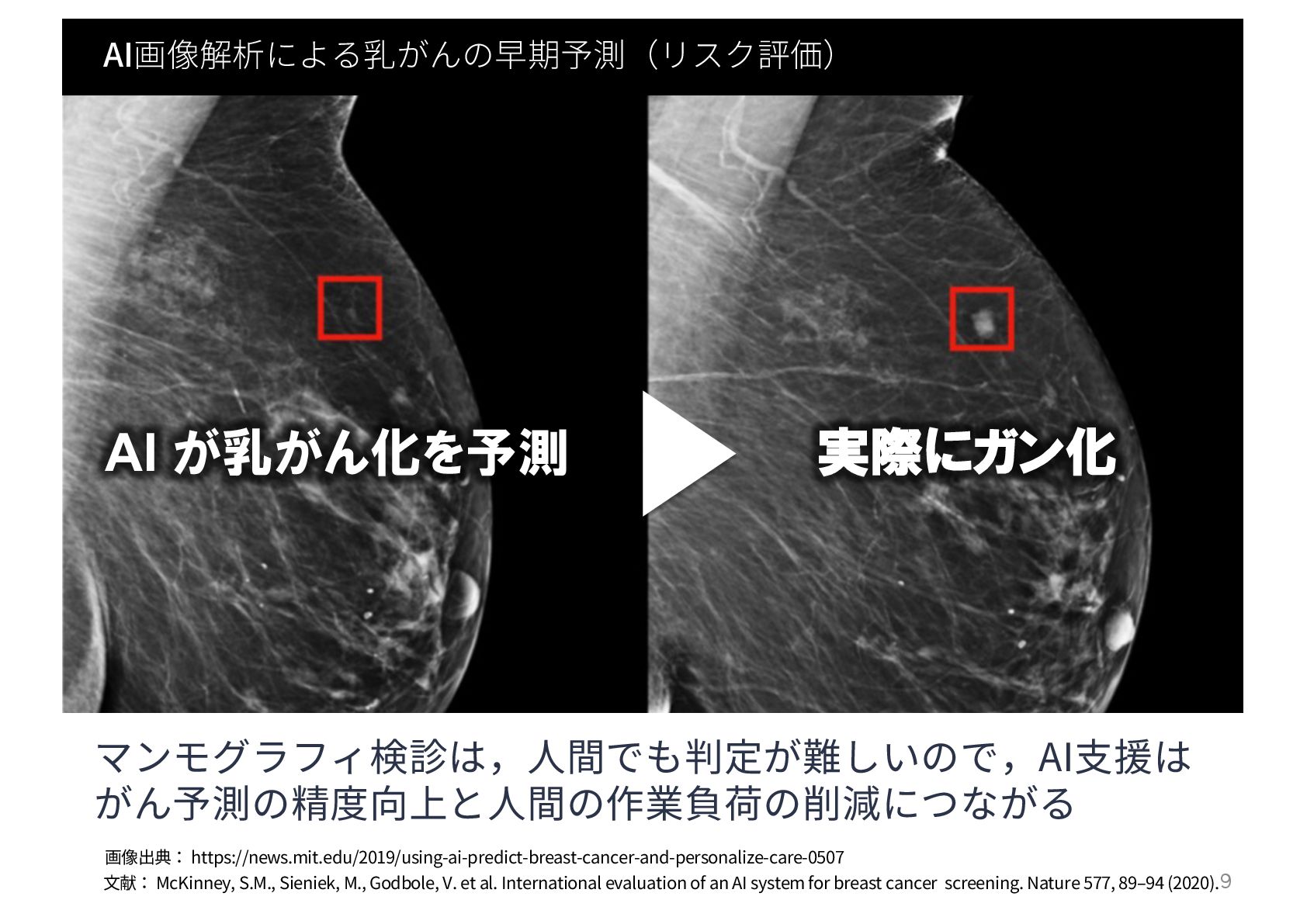
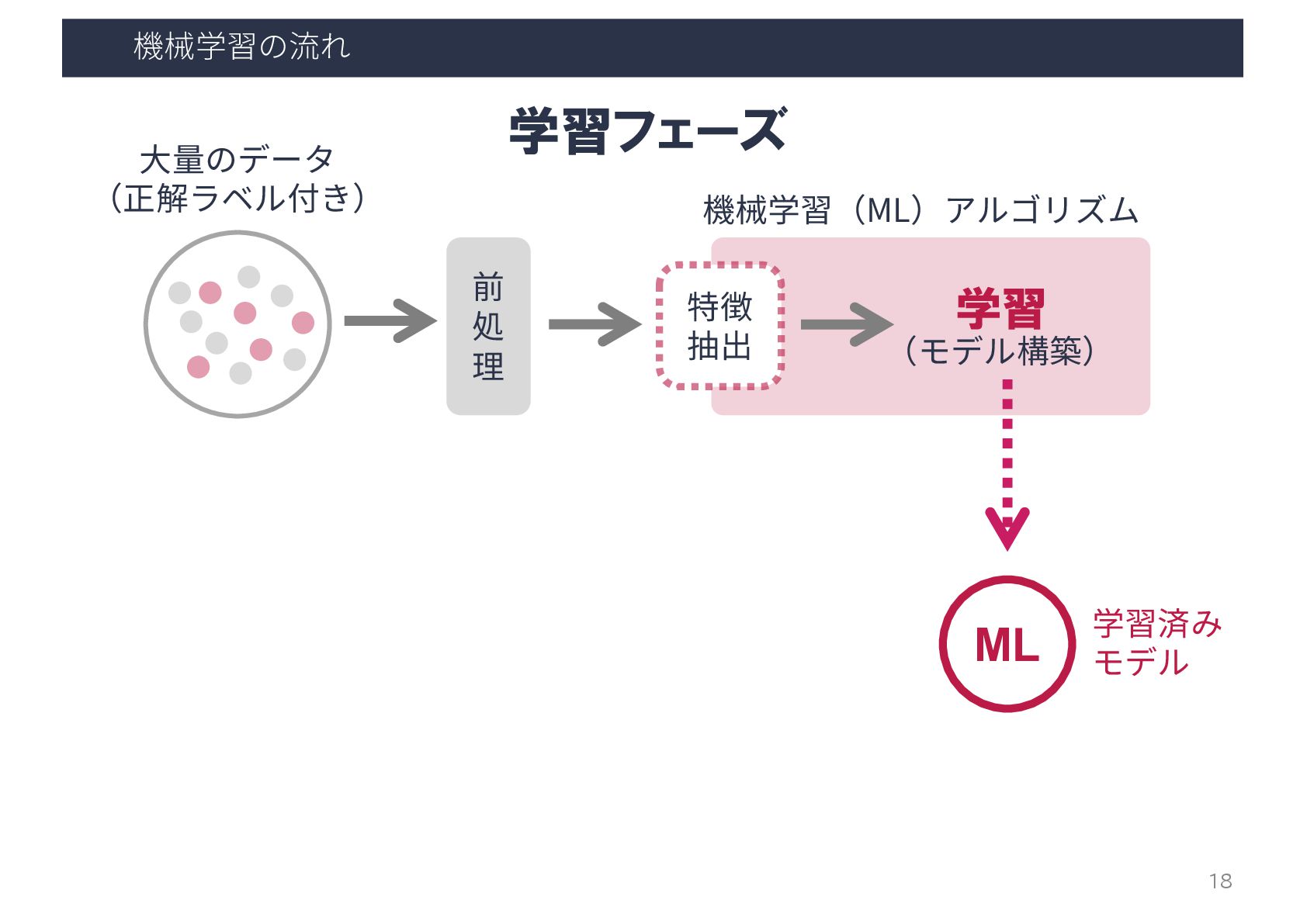
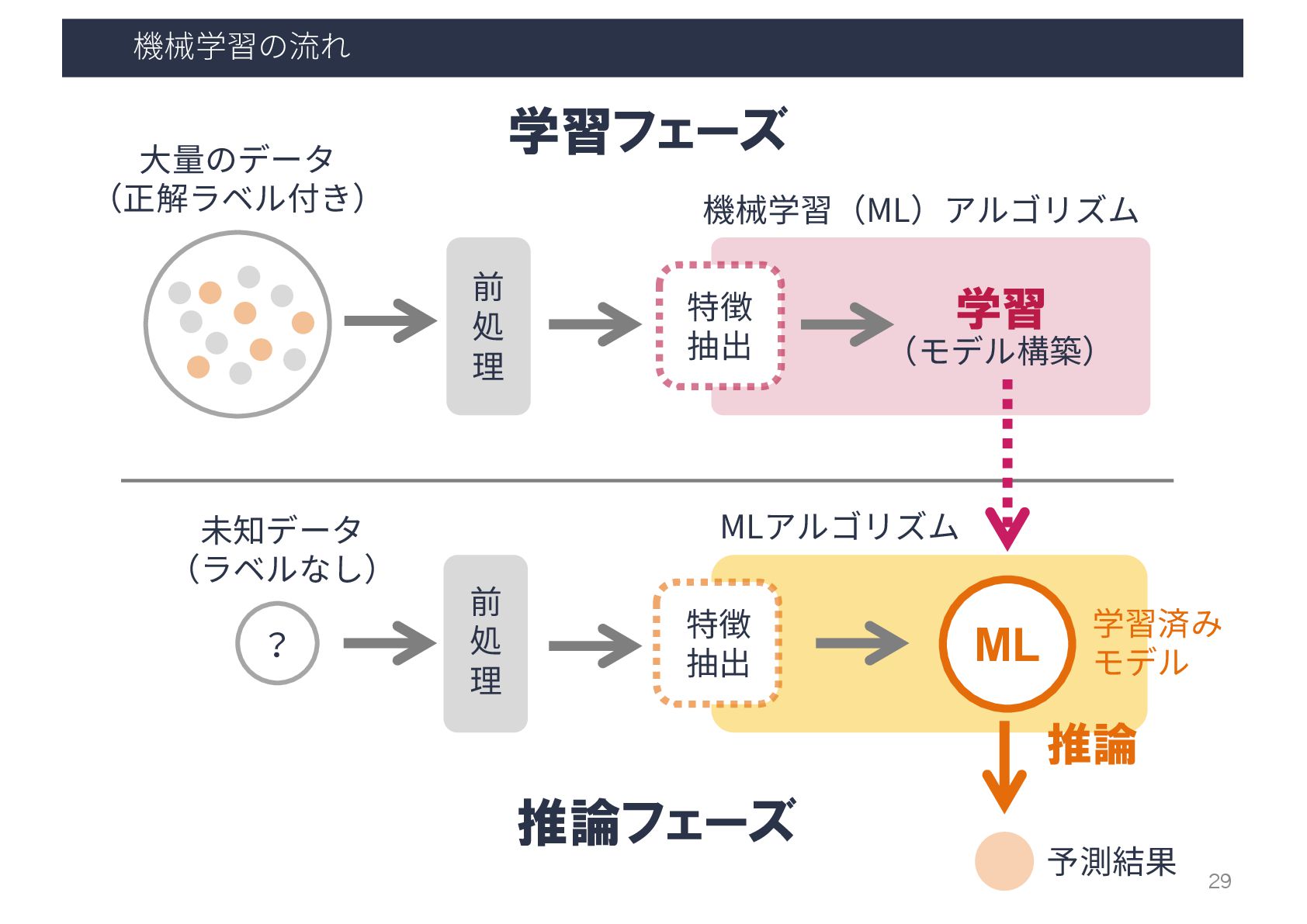
機械学習の流れ ⼤量のデータ (正解ラベル付き) 前 処 理 特徴 抽出 学習 (モデル構築)
機械学習(ML)アルゴリズム 学習済み モデル ML 学習フェーズ 18
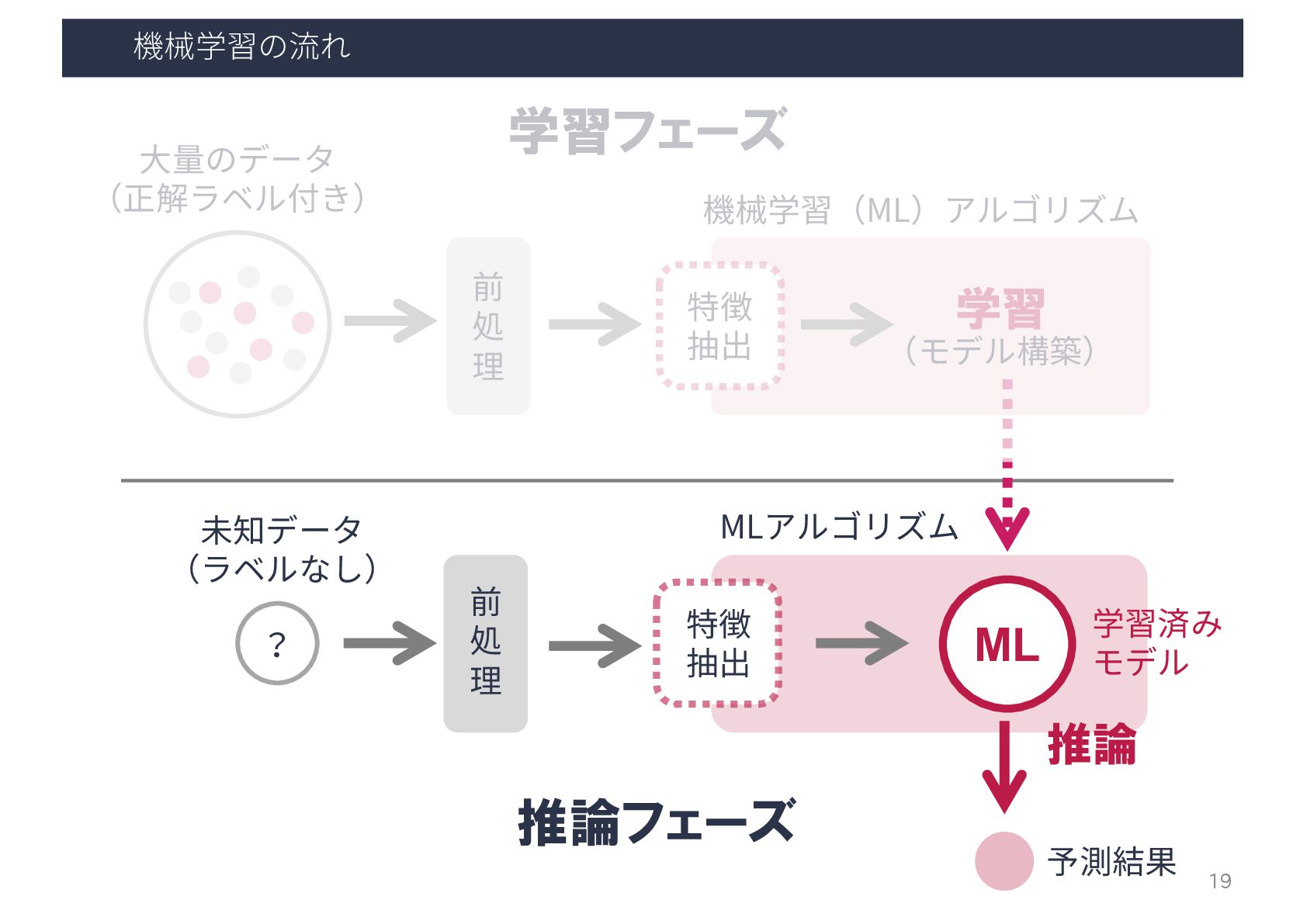
機械学習の流れ ⼤量のデータ (正解ラベル付き) 前 処 理 特徴 抽出 学習 (モデル構築)
機械学習(ML)アルゴリズム 学習済み モデル ML 推論 特徴 抽出 ? 前 処 理 未知データ (ラベルなし) 予測結果 推論フェーズ MLアルゴリズム 学習フェーズ 19
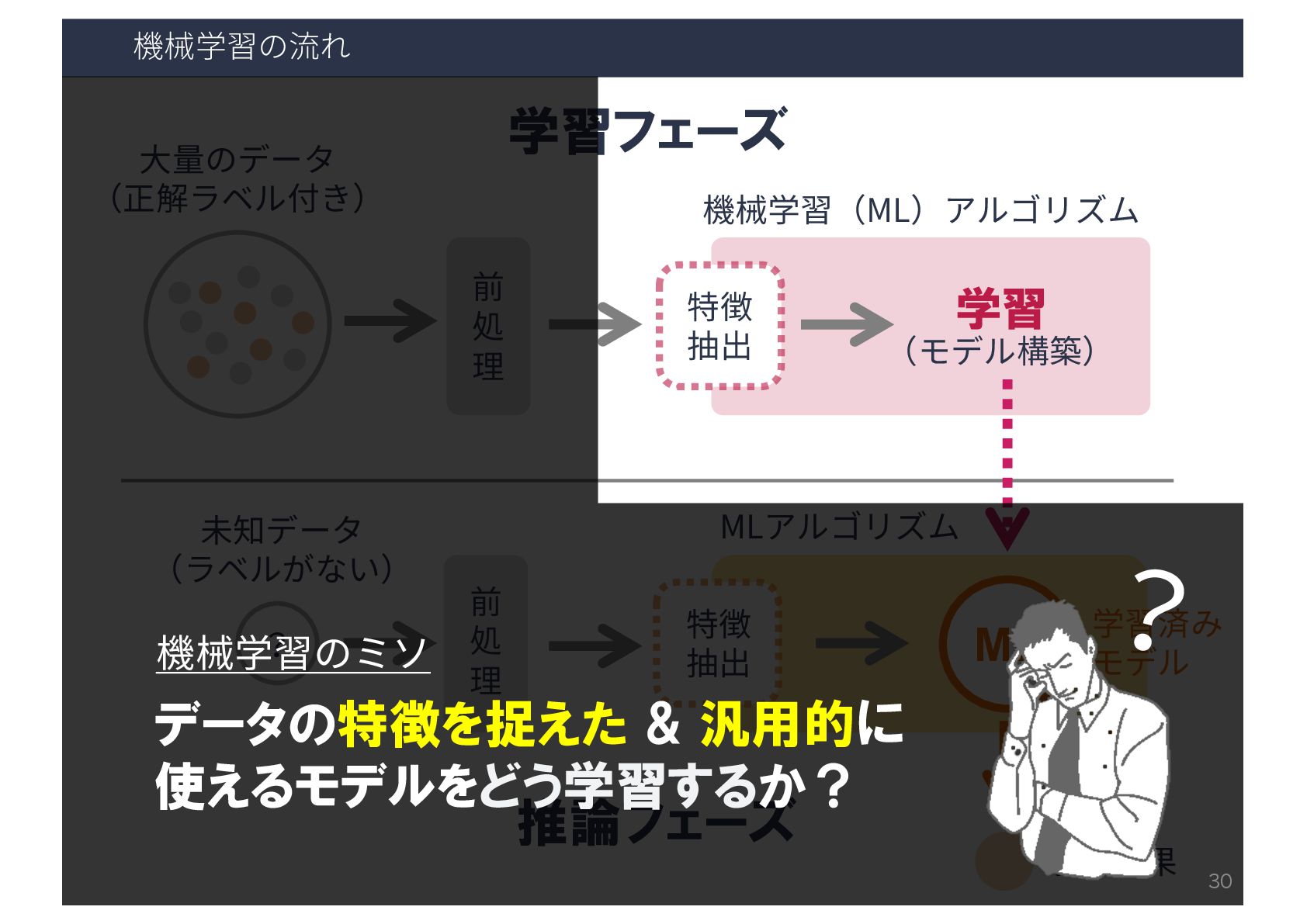
機械学習の流れ ⼤量のデータ (正解ラベル付き) 前 処 理 特徴 抽出 学習 (モデル構築)
機械学習(ML)アルゴリズム 学習済み モデル ML 推論 特徴 抽出 ? 前 処 理 未知データ (ラベルなし) 予測結果 推論フェーズ MLアルゴリズム 学習フェーズ 29
機械学習の流れ ⼤量のデータ (正解ラベル付き) 前 処 理 特徴 抽出 学習 (モデル構築)
機械学習(ML)アルゴリズム 学習済み モデル ML 推論 特徴 抽出 ? 前 処 理 未知データ (ラベルがない) 予測結果 推論フェーズ MLアルゴリズム 学習フェーズ ? 機械学習のミソ データの特徴を捉えた & 汎用的に 使えるモデルをどう学習するか? 30
講義の進め方 2 何をどうやって学ぶのか? 31
講師の紹介 32 ⼭本祐輔(me) ⼩⼭先⽣
[email protected]
[email protected]
講義のトピック 機械学習 教師あり学習 教師なし学習 強化学習 ・クラスタリング ・データ圧縮 ・分類 ・回帰 33
講義のトピック 機械学習 教師あり学習 教師なし学習 強化学習 ・クラスタリング ・データ圧縮 ・分類 ・回帰 …
… 34 発展的内容 ・⼀般化線形モデル ・カーネル法 ・ガウス回帰 ・ニューラルネットワーク ⼭本担当 ⼩⼭先⽣担当 …
機械学習技術のコアは数学であるが˟ 数理的内容の学習は,初学者にはハードルが高い 35
最近のツール事情 # Python 1 import sklearn.ensemble.GradientBoostingClassifier as GBDT 2 data
= pd.read_csv(“data.csv”) 3 model = GBDT() 4 model.fit(data) ほとんど何も書かなくても動くので便利 中身も理解せず,正しく動かせているか分からず 利用しているユーザ(学生)が多い 36
授業の⽬的(⼭本担当パート) 「機械学習」の仕組みを直感的に理解し, 実問題に応用するための足掛かりを得る 37
講義の⽬標(⼭本担当パート) 機械学習 教師あり学習 教師なし学習 強化学習 ・クラスタリング ・データ圧縮 ・分類 ・回帰 …
本講義の学習目標 • 代表的な機械学習がどのように動くかを直感的に理解する • 既存ライブラリを使い例題に対して機械学習を適用できる … 38 (山本担当パート)
講義計画 39 回 トピック 1 ガイダンス 2 pandas⼊⾨ 3 決定⽊からはじめる機械学習
4 クラスタリング1:k-means & 階層的クラスタリング 5 クラスタリング2:密度ベースクラスタリング 6 分類1:K近傍法 & 教師あり機械学習のお作法 7 分類2:サポートベクターマシン 8 分類3:ニューラルネットワーク⼊⾨
講義計画(⼩⼭先⽣担当会) 40 回 トピック 9 ⼀般化線形モデル 10 半正定値カーネル 11 ⾮線形サポートベクトルマシン
(オンデマンド遠隔講義) 12 ガウス過程回帰 13 多層ニューラルネットワーク (オンデマンド遠隔講義) 14 誤差逆伝搬法 (オンデマンド遠隔講義) 15 最近の機械学習の話題
この授業でやらないこと(⼭本担当パート) lドメインに特化した機械学習手法 (画像処理,自然言語処理,情報検索,etc.) l前提知識の復習(線形代数,微積,確率etc) lディープラーニングの詳細解説 41
講義スタイル(⼭本担当パート) Hands-onデモ with Python 0:00 1:30 0:50 座学 機械学習技術の 適⽤体験
機械学習の理論や ⼿法の直感的理解 (数学的にもフォローする) (⾼度なプログラミングスキルは不要) 42
⼭本パートで使⽤するもの 配布スライド(座学用) Google Colaboratory (プログラミング環境を 構築する必要はない) 43
授業資料 44 https://mlnote.hontolab.org/
成績評価 レポート: 100% ・実際にコードを⾛らせて機械学習の動作や結果を考察 ・アルゴリズムの動作⼿順を頭で追う練習など 45
成績評価 46 ⼭本担当回 50% ⼩⼭先⽣担当回 50% + (レポート課題) (レポート課題)
参考図書(初学者向け) 画像出典2: https://www.amazon.co.jp/dp/B07GYS3RG7/ 画像出典1: https://www.amazon.co.jp/dp/B00MWODXX8 47
参考図書(こってり学ぶ) 画像出典: https://www.amazon.co.jp/dp/432012362X 画像出典: https://www.amazon.co.jp/dp/4621061224 48
すばらしいコンテンツ 49 https://chokkan.github.io/mlnote/index.html http://codh.rois.ac.jp/ 機械学習帳 ROISデータセット
今後の予定 50 回 実施⽇ トピック 1 04/13 ガイダンス 2 04/20
pandas⼊⾨ 3 04/27 決定⽊からはじめる機械学習 4 05/11 クラスタリング1:k-means & 階層的クラスタリング 5 05/18 クラスタリング2:密度ベースクラスタリング 6 05/25 分類1:K近傍法 & 教師あり機械学習のお作法 7 06/01 分類2:サポートベクターマシン 8 06/08 分類3:ニューラルネットワーク⼊⾨
![授業概要 ⼭本 祐輔 名古屋市⽴⼤学 データサイエンス研究科 [email protected] 第1回 機械学習発展 (前半パート)](https://files.speakerdeck.com/presentations/732b5f47d80b4287b087973aa3e93abc/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![講師の紹介 32 ⼭本祐輔(me) ⼩⼭先⽣ [email protected] [email protected]](https://files.speakerdeck.com/presentations/732b5f47d80b4287b087973aa3e93abc/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}