[論文サーベイ] Survey on Pokemon AI 2
PDFファイルをダウンロードすると,スライド内のリンクを見ることができます.
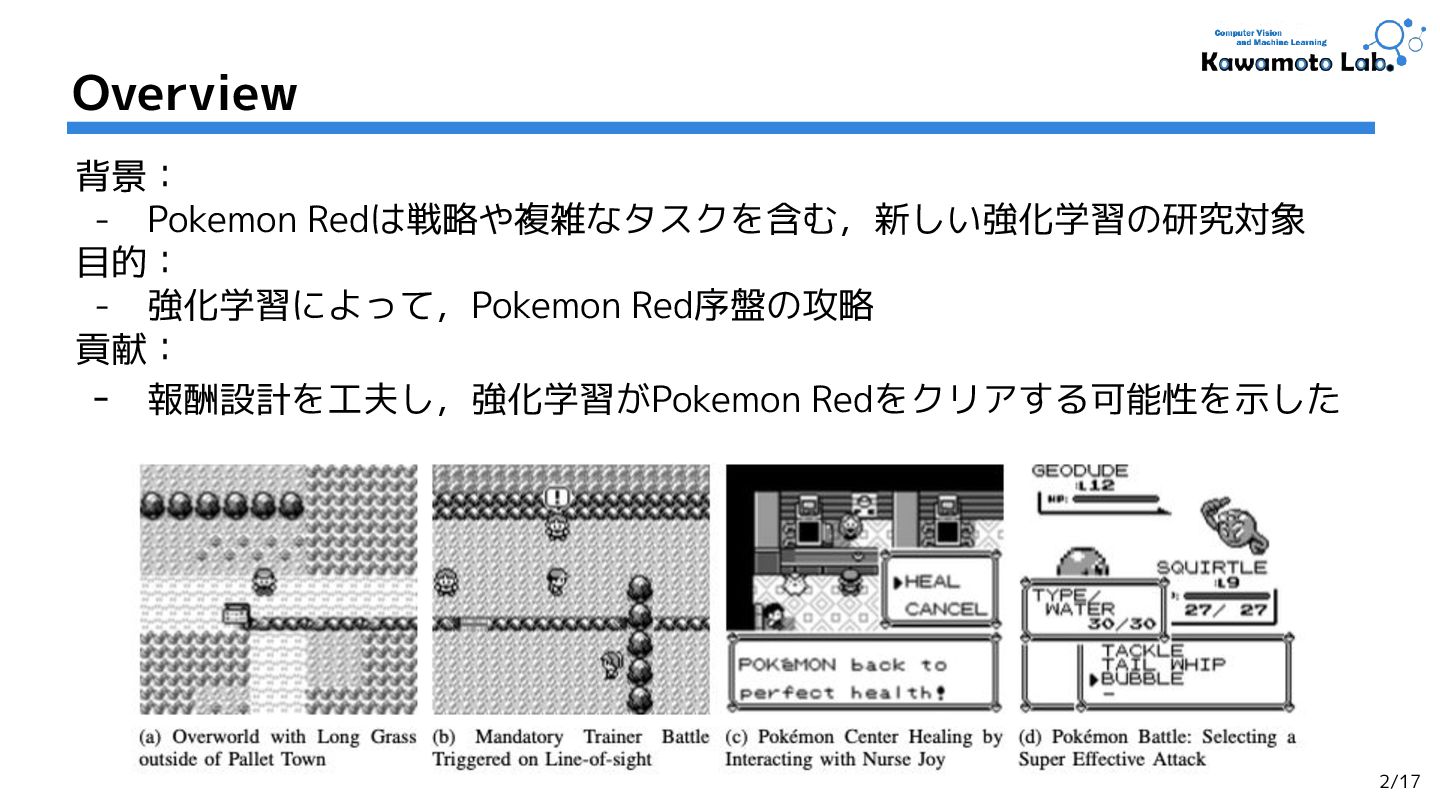
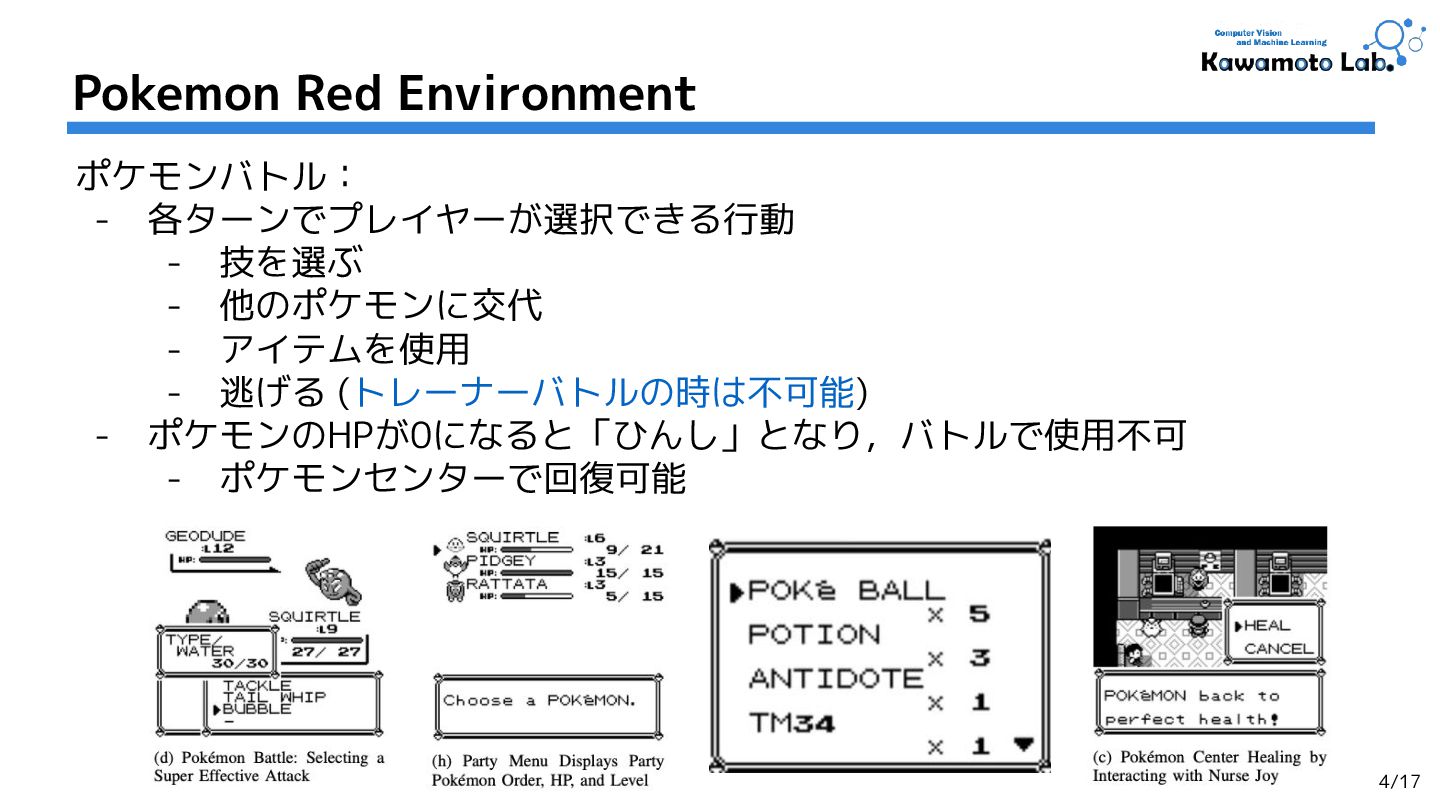
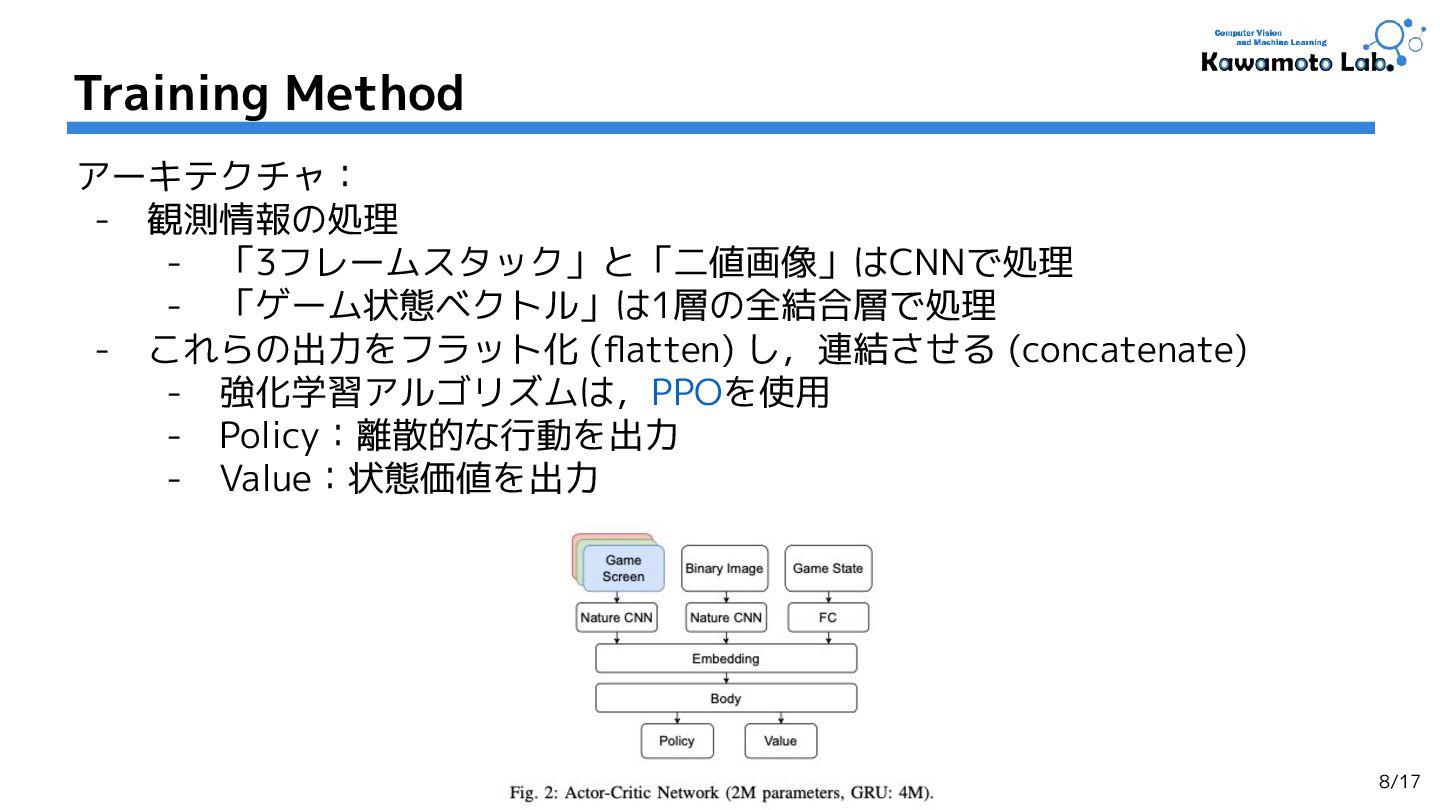
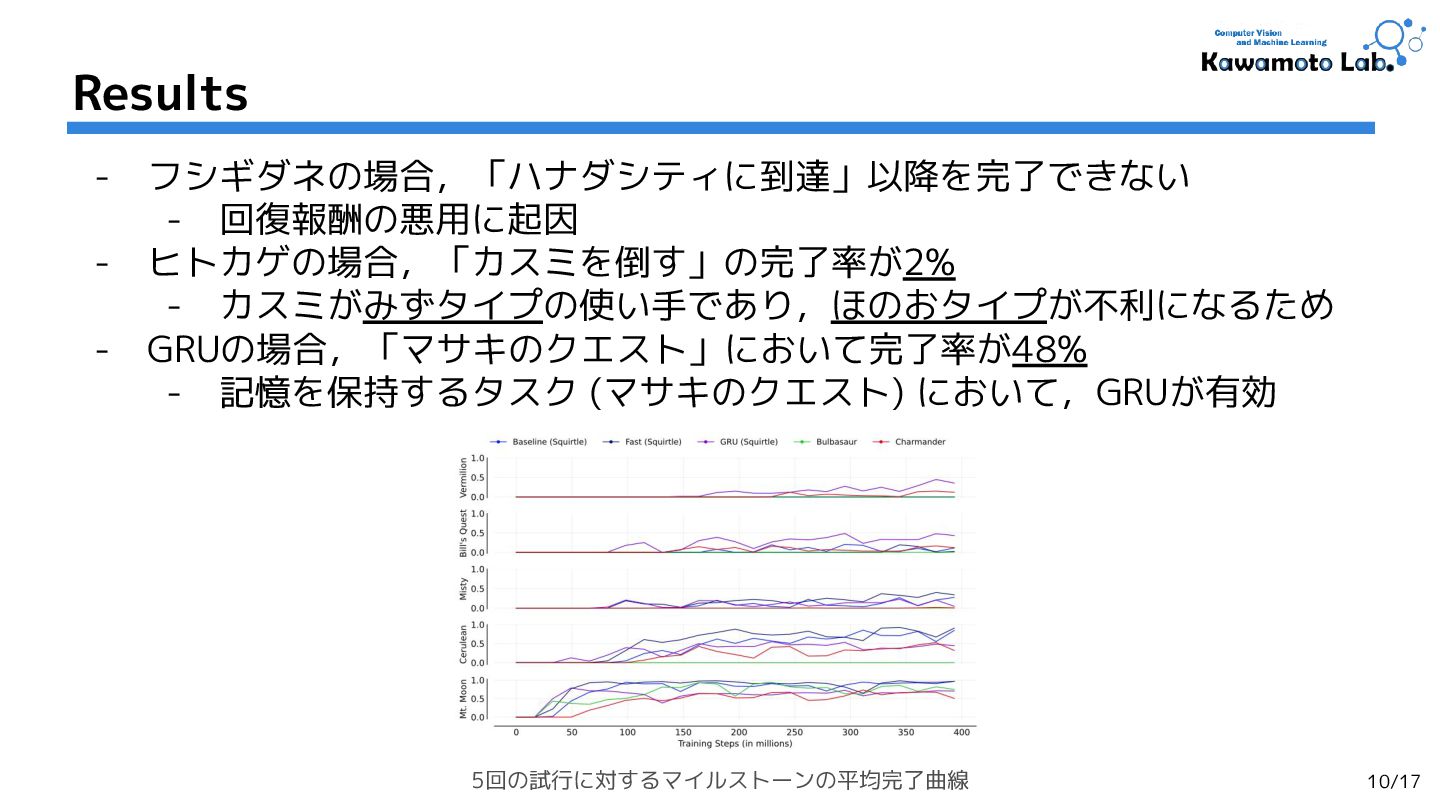
1.Pokemon Red via Reinforcement Learning,
Marco Pleines et al. (TU Dortmund University et al.)
[CoG'25] (Cited by: - )
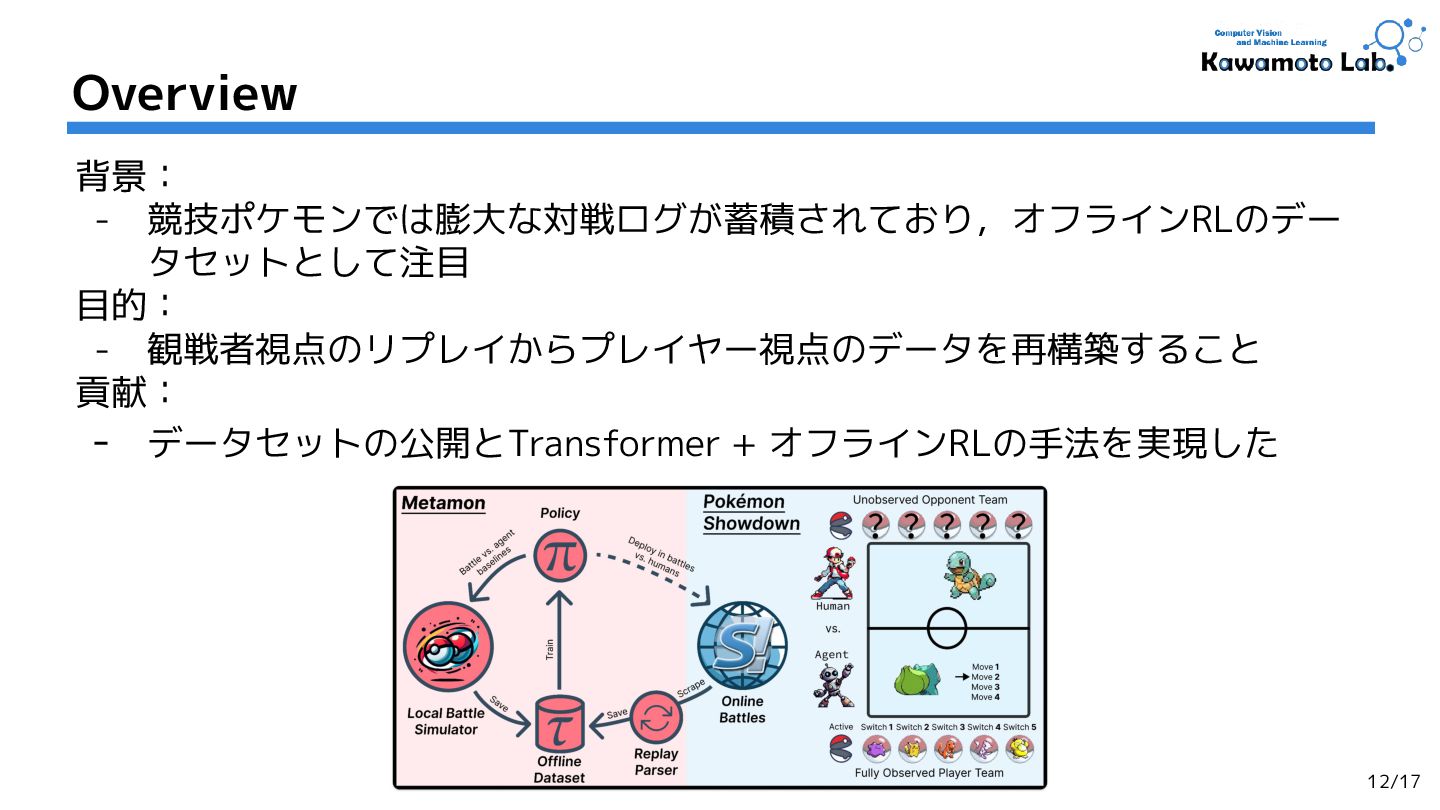
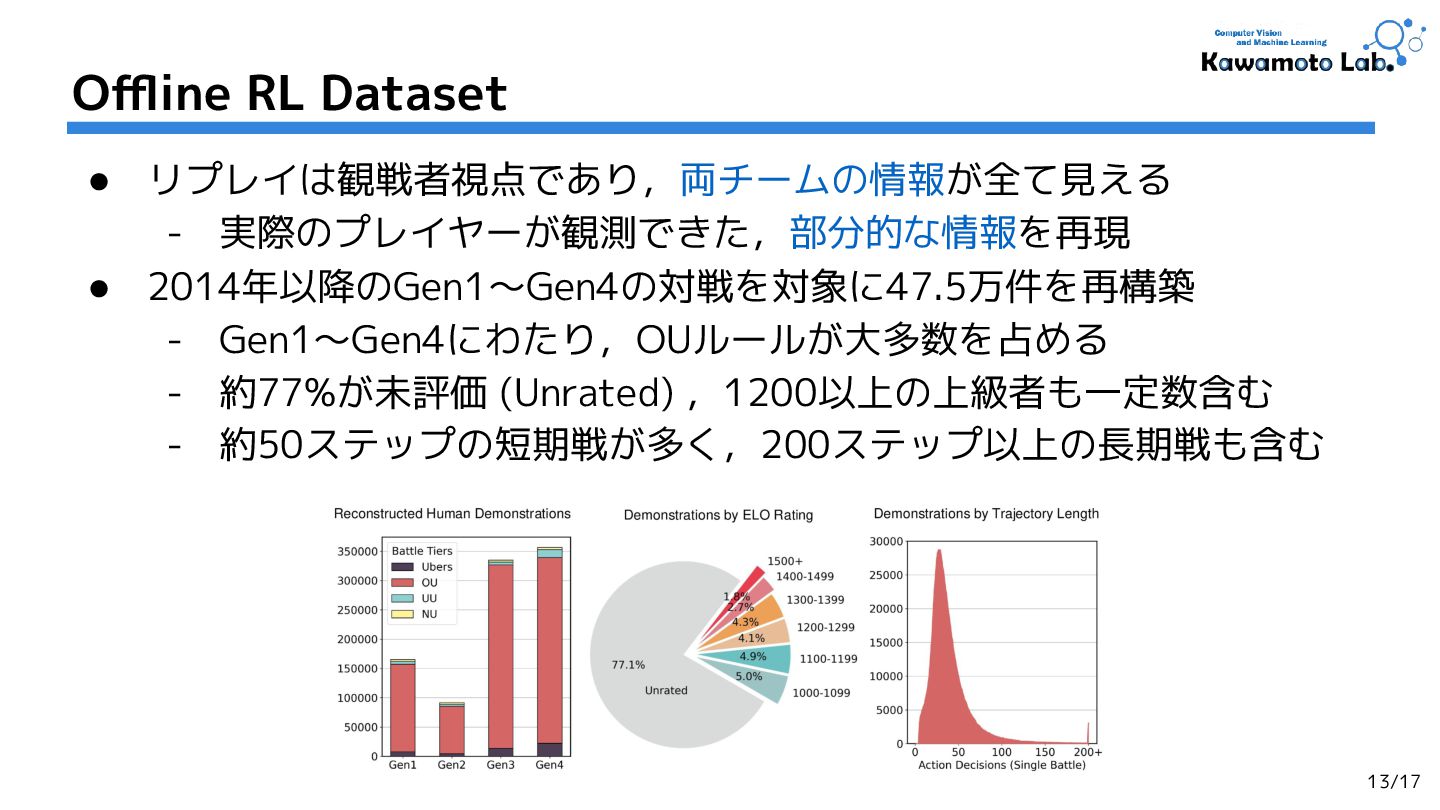
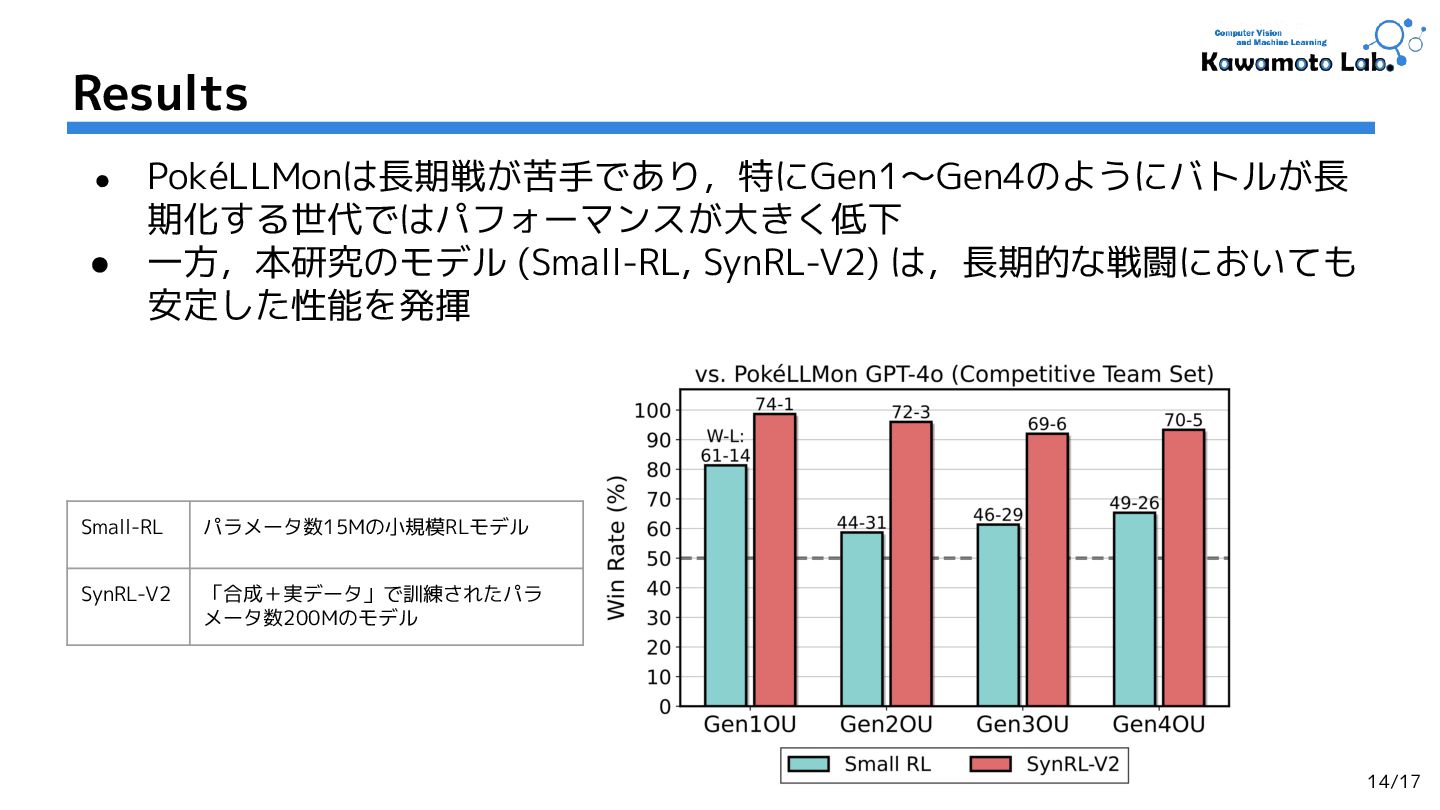
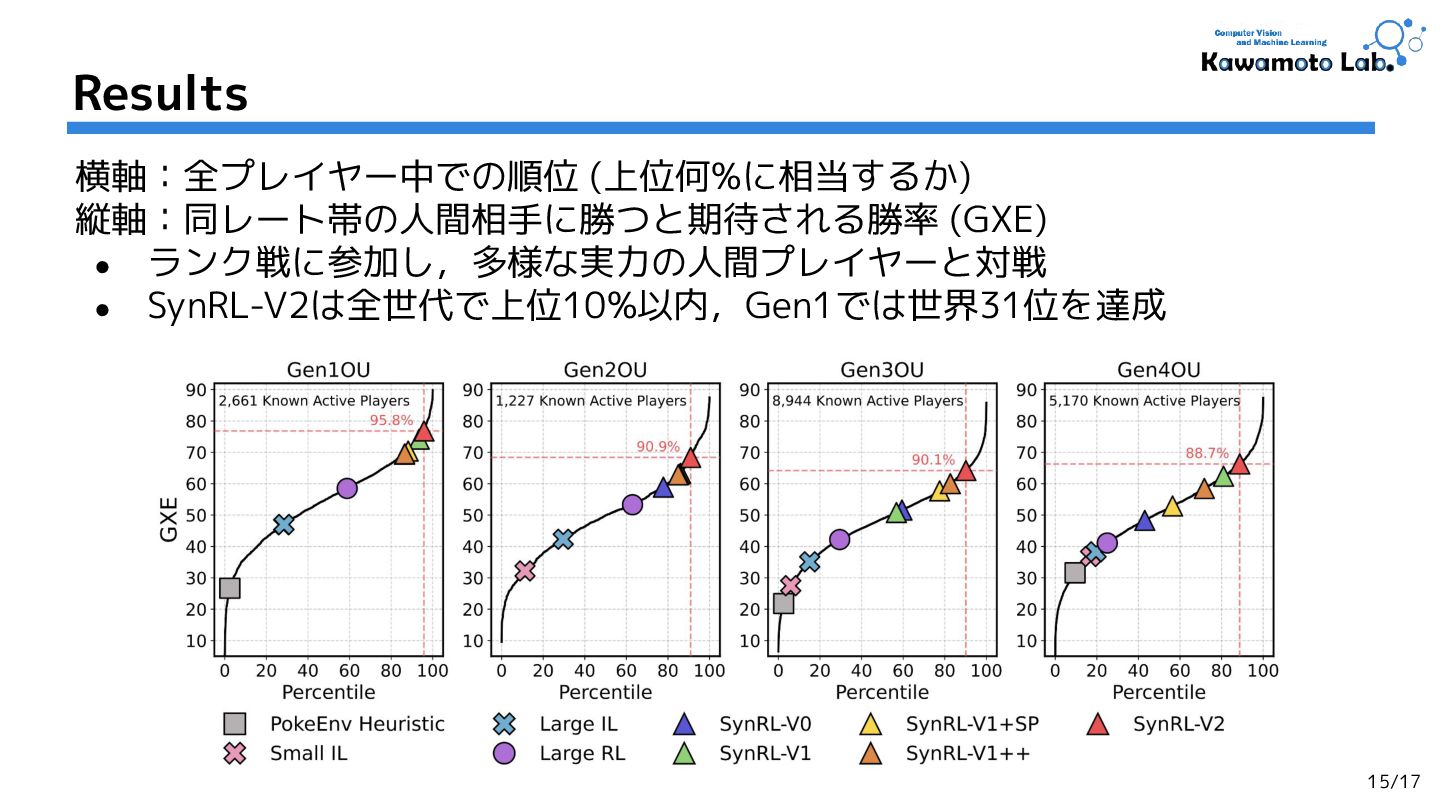
2.Human-Level Competitive Pokémon via Scalable Offline Reinforcement Learning with Transformers,
Jake Grigsby et al. (The University of Texas at Austin.)
RLC'25 [OpenReview] (Cited by: - )
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}