[論文サーベイ] Survey on Google DeepMind’s Game AI
PDFファイルをダウンロードすると,スライド内のリンクを見ることができます.
1.Genie: Generative Interactive Environments,
Jake Bruce et al. (Google DeepMind et al.)
[ICML'24 Best paper] (Cited by: 344 )
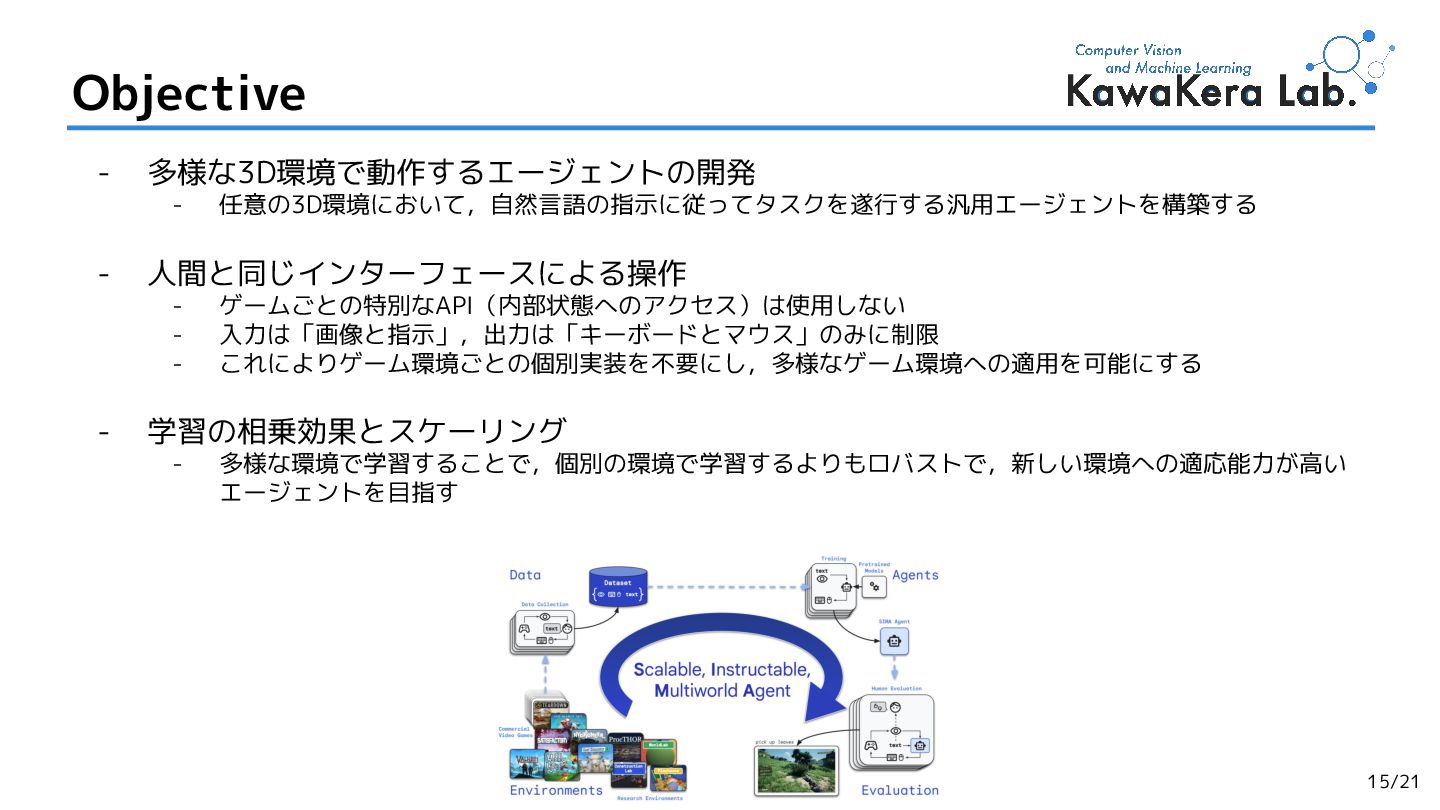
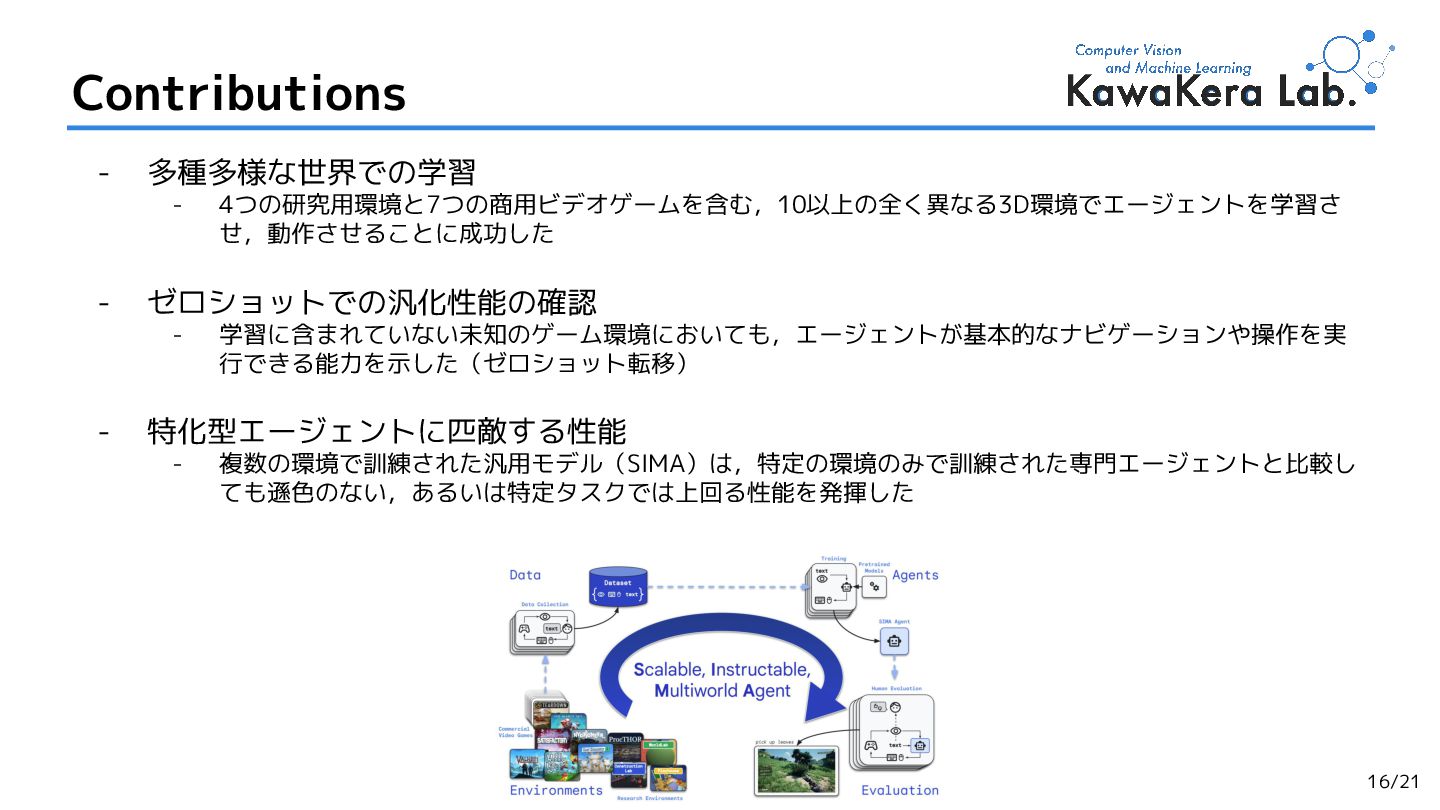
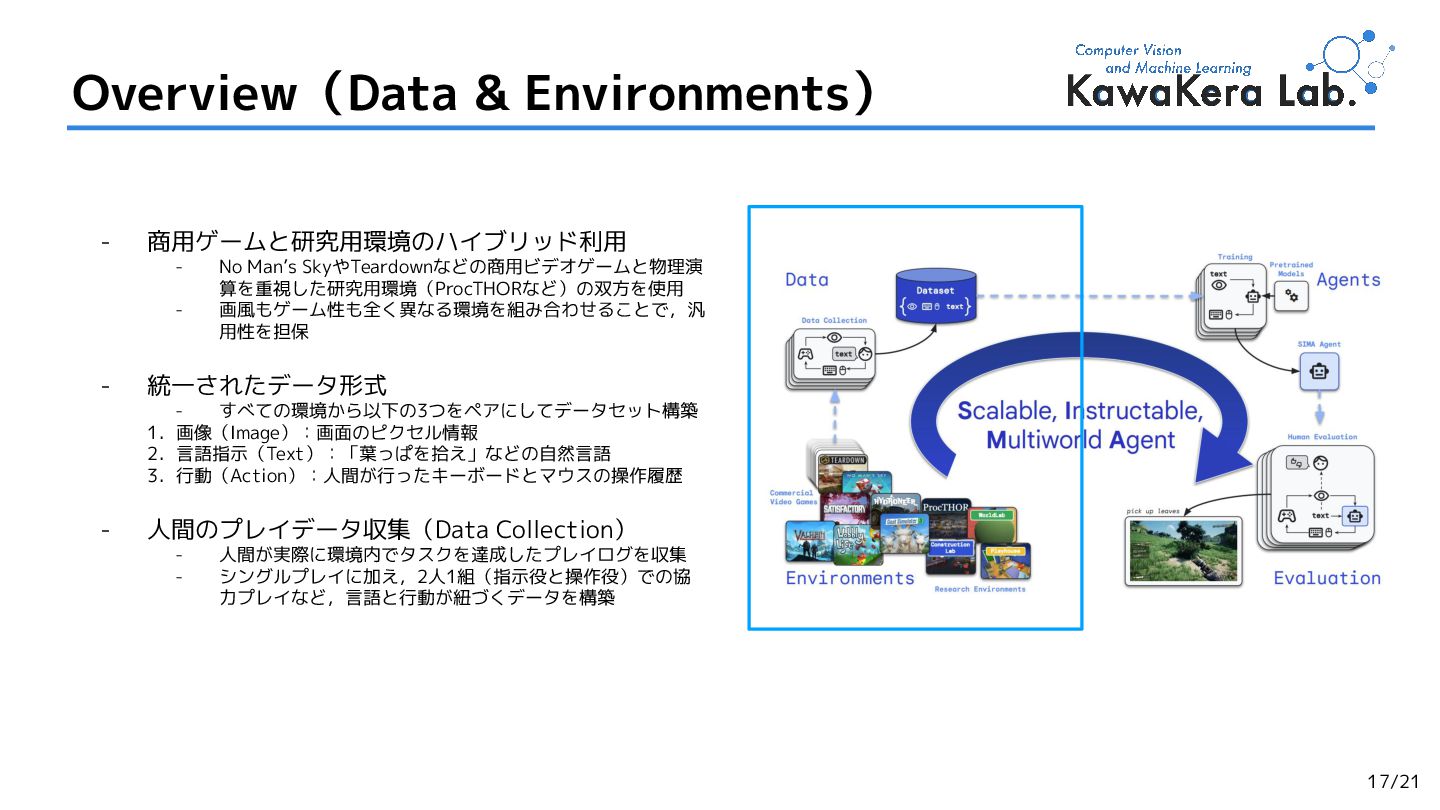
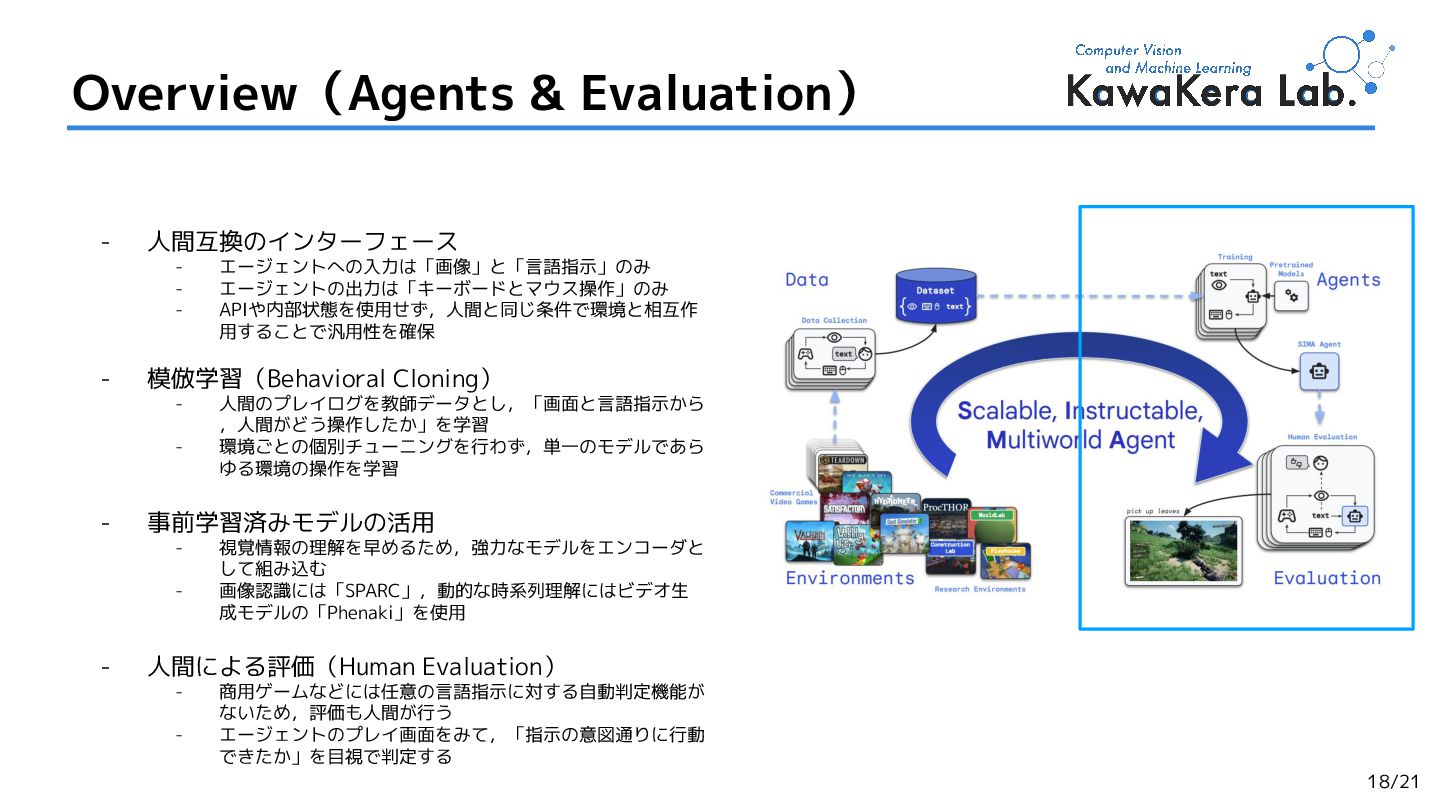
2.Scaling Instructable Agents Across Many Simulated Worlds,
Maria Abi Raad et al. (Google DeepMind et al.)
[arXiv'2404] (Cited by: 52 )
{kind=link}
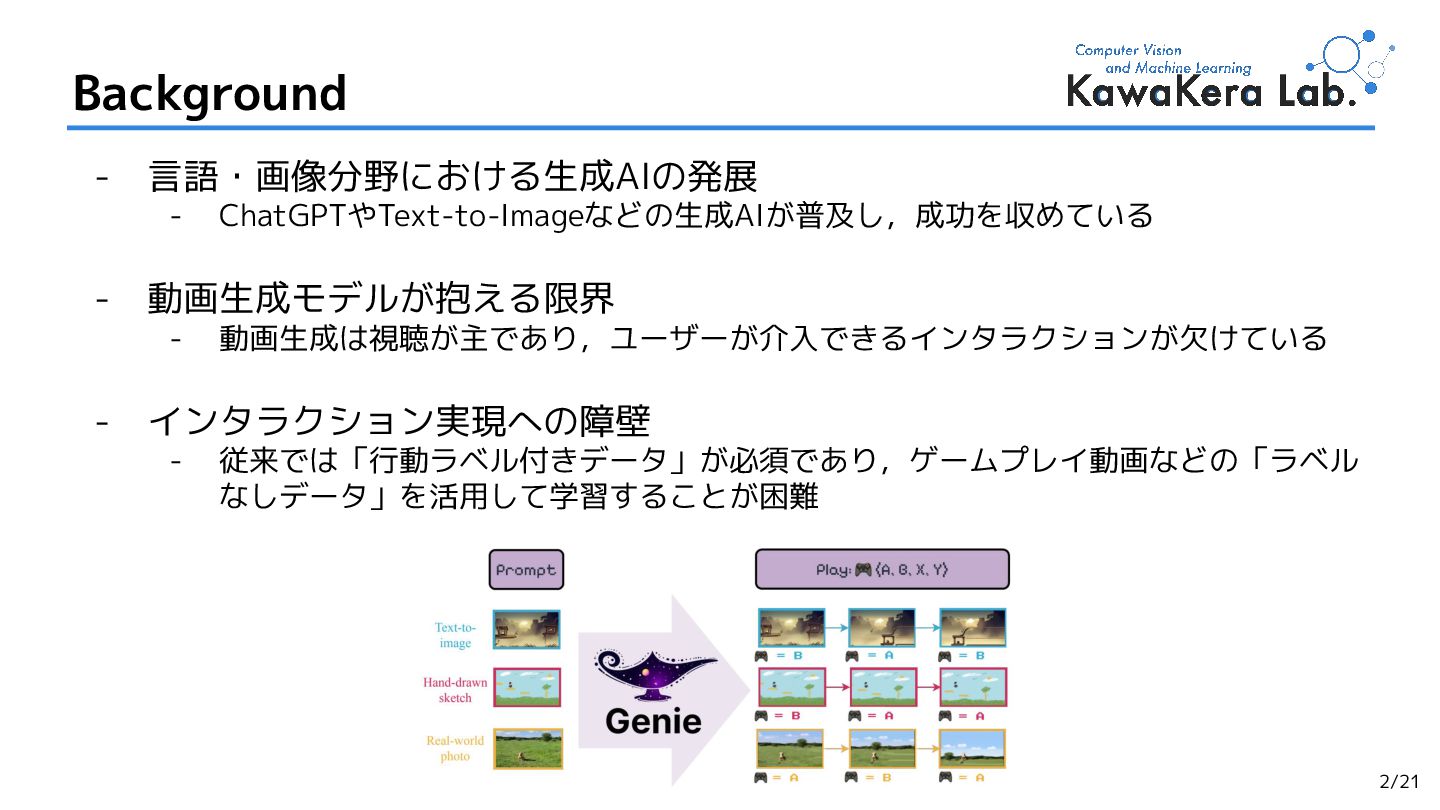{kind=link}
{kind=link}
{kind=link}
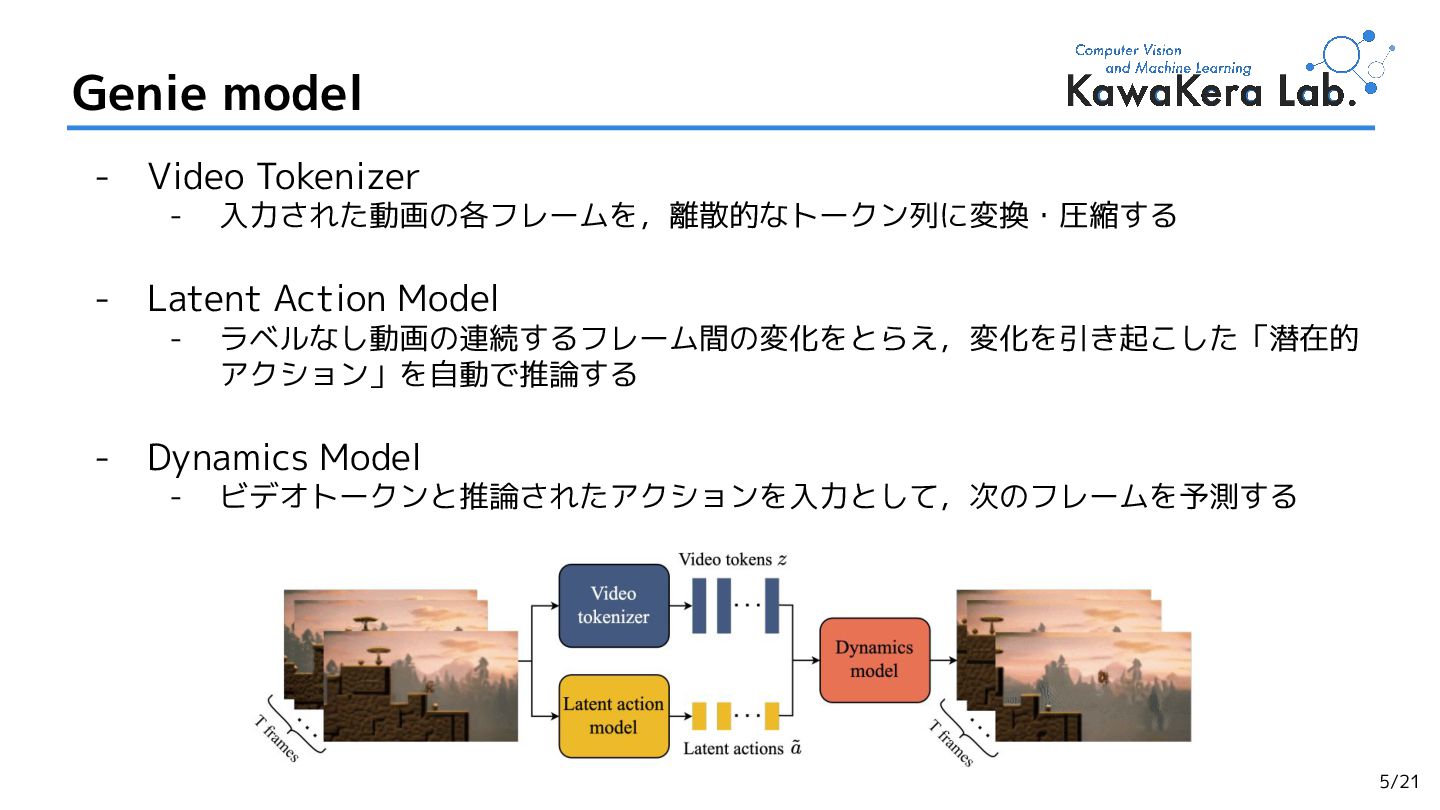{kind=link}
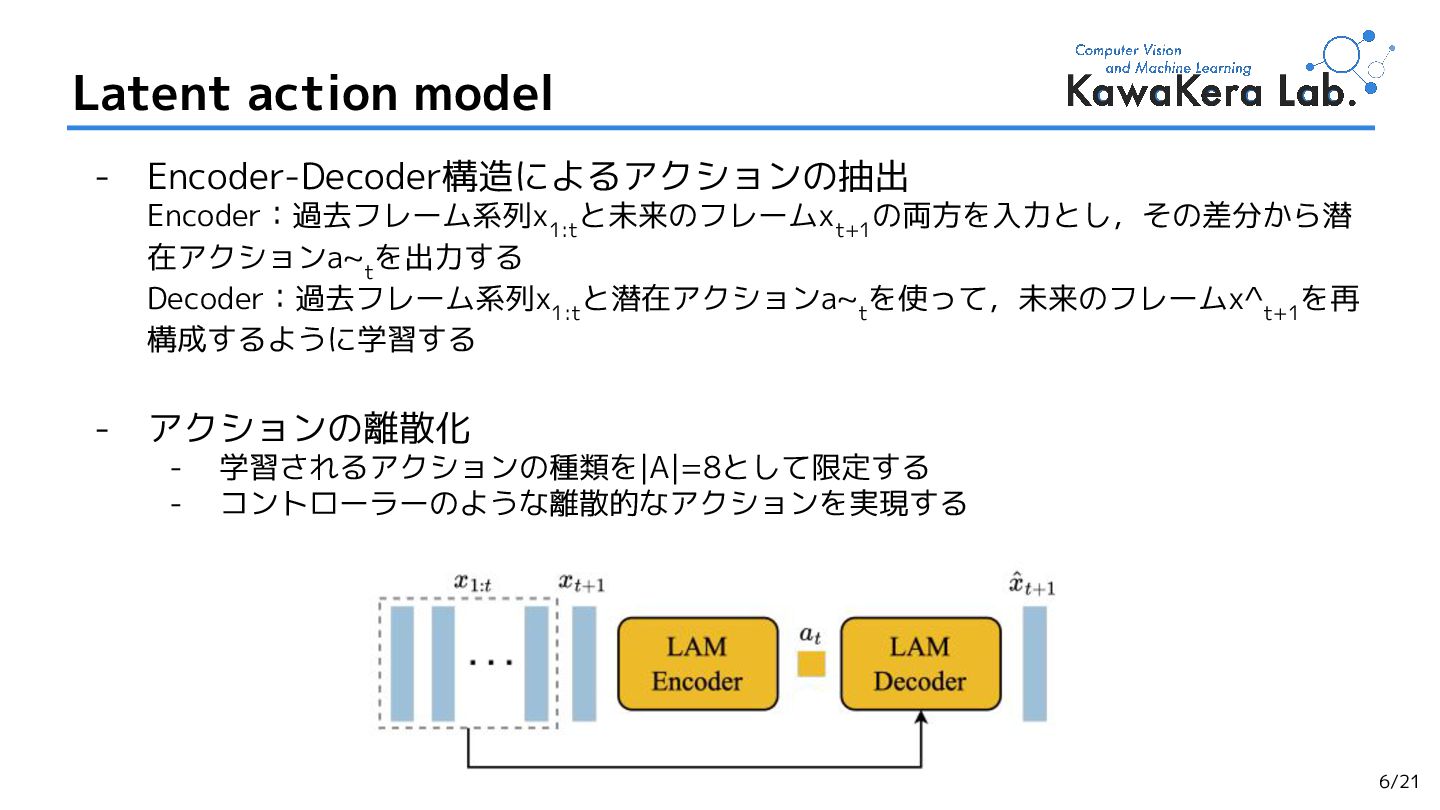{kind=link}
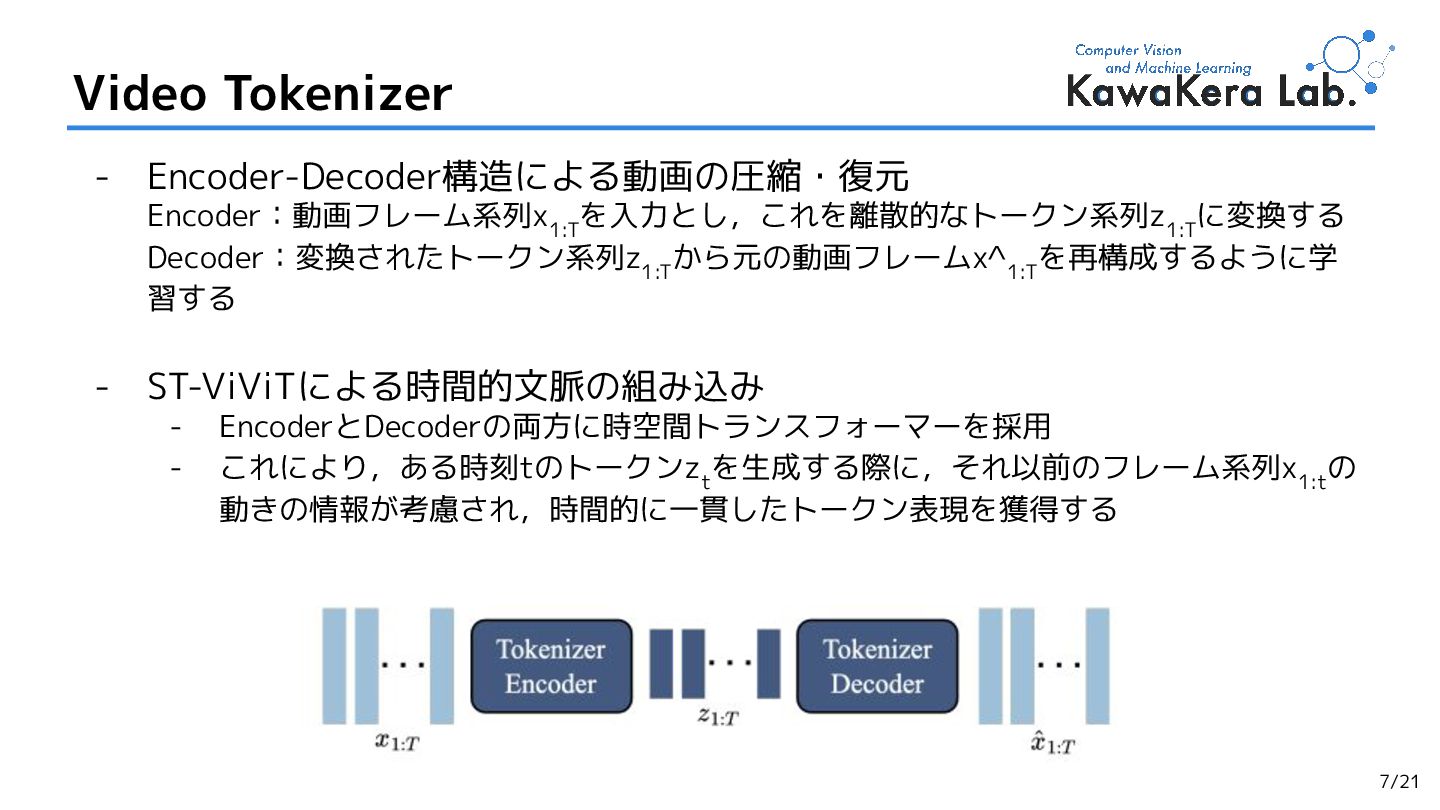{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}