[論文サーベイ] Survey on Pokemon AI
PDFファイルをダウンロードすると,スライド内のリンクを見ることができます.
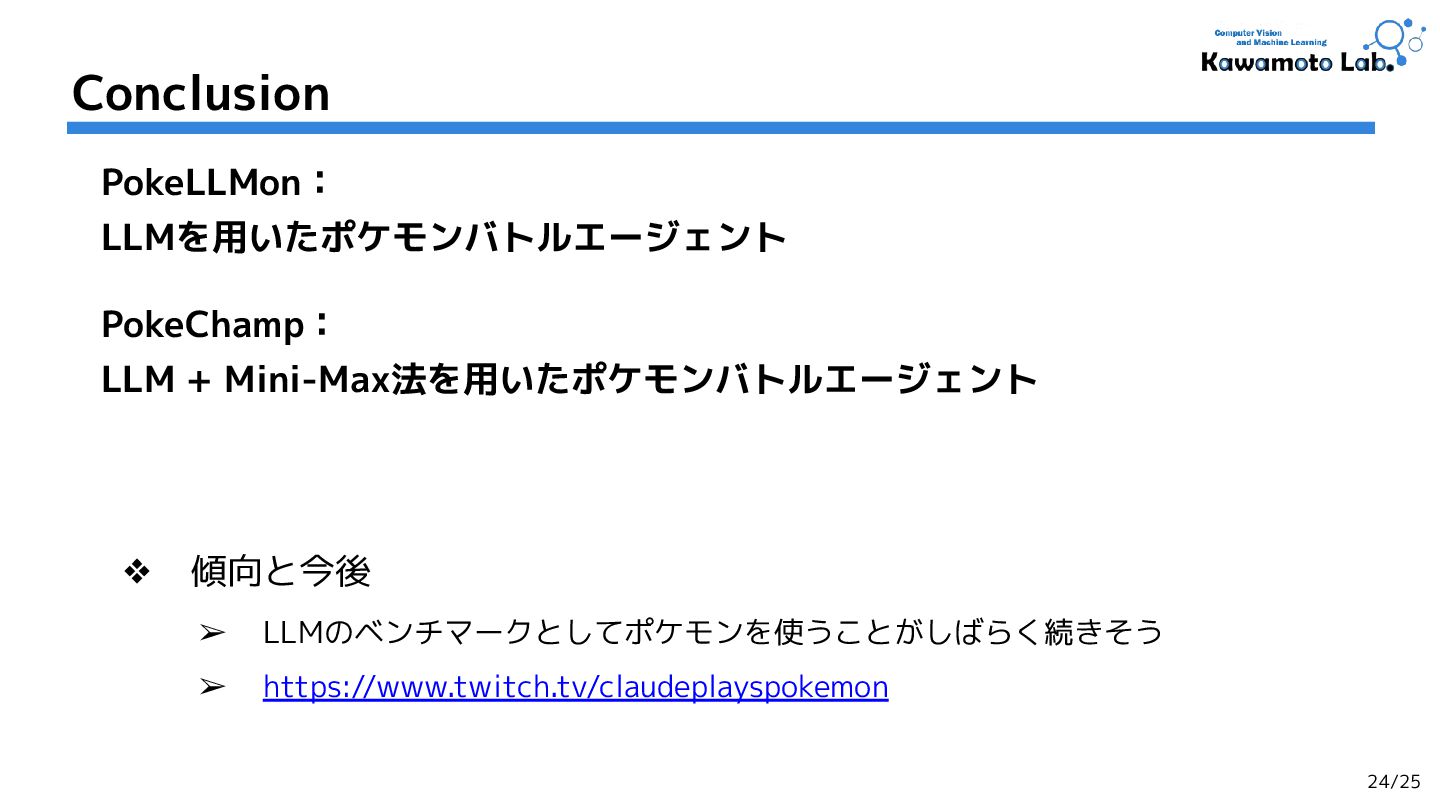
1.PokeLLMon: A Human-Parity Agent for Pokemon Battles with Large Language Models,
Sihao Hu et al. (Georgia Institute of Technology.)
ICLR'25 [Withdrawal] (Cited by: 21 )
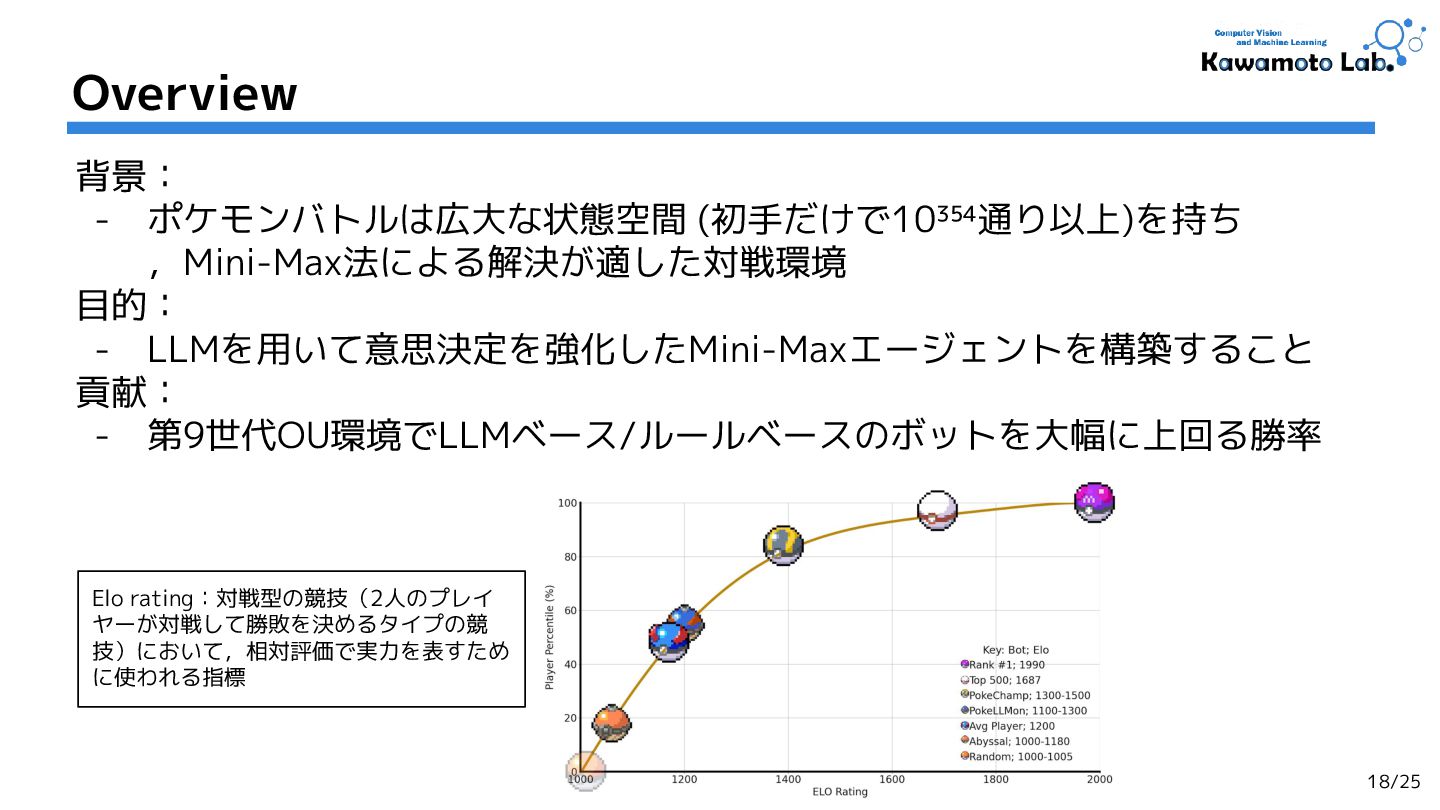
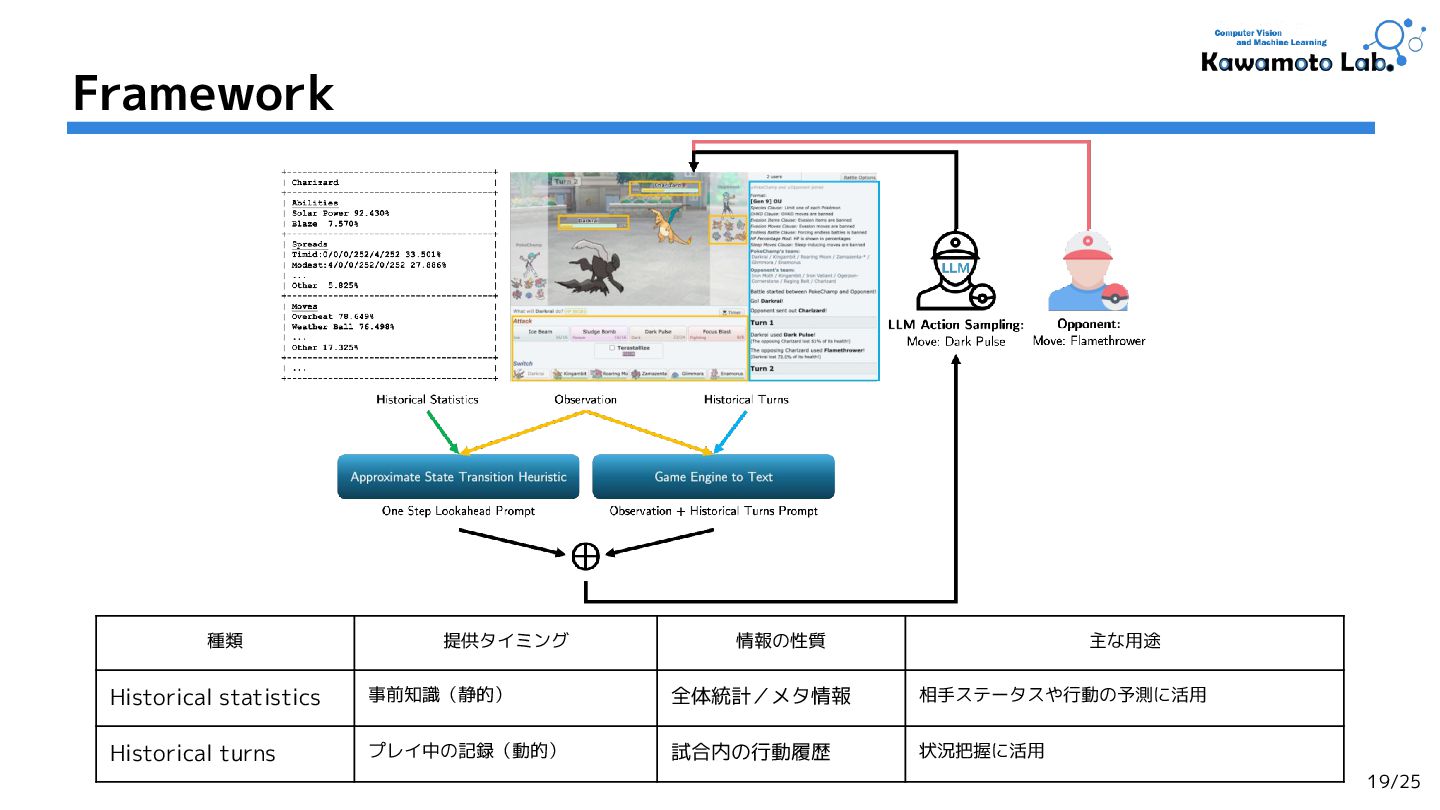
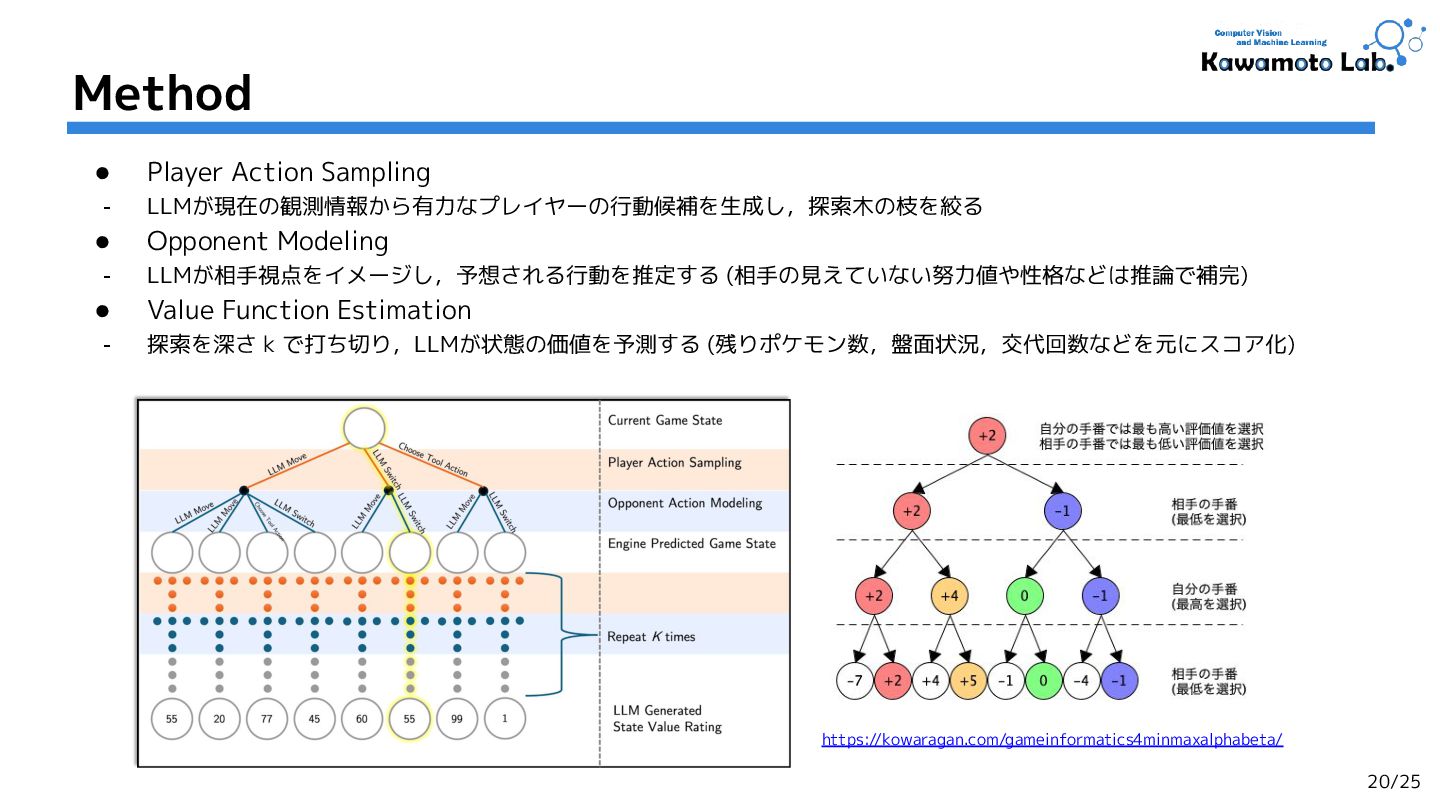
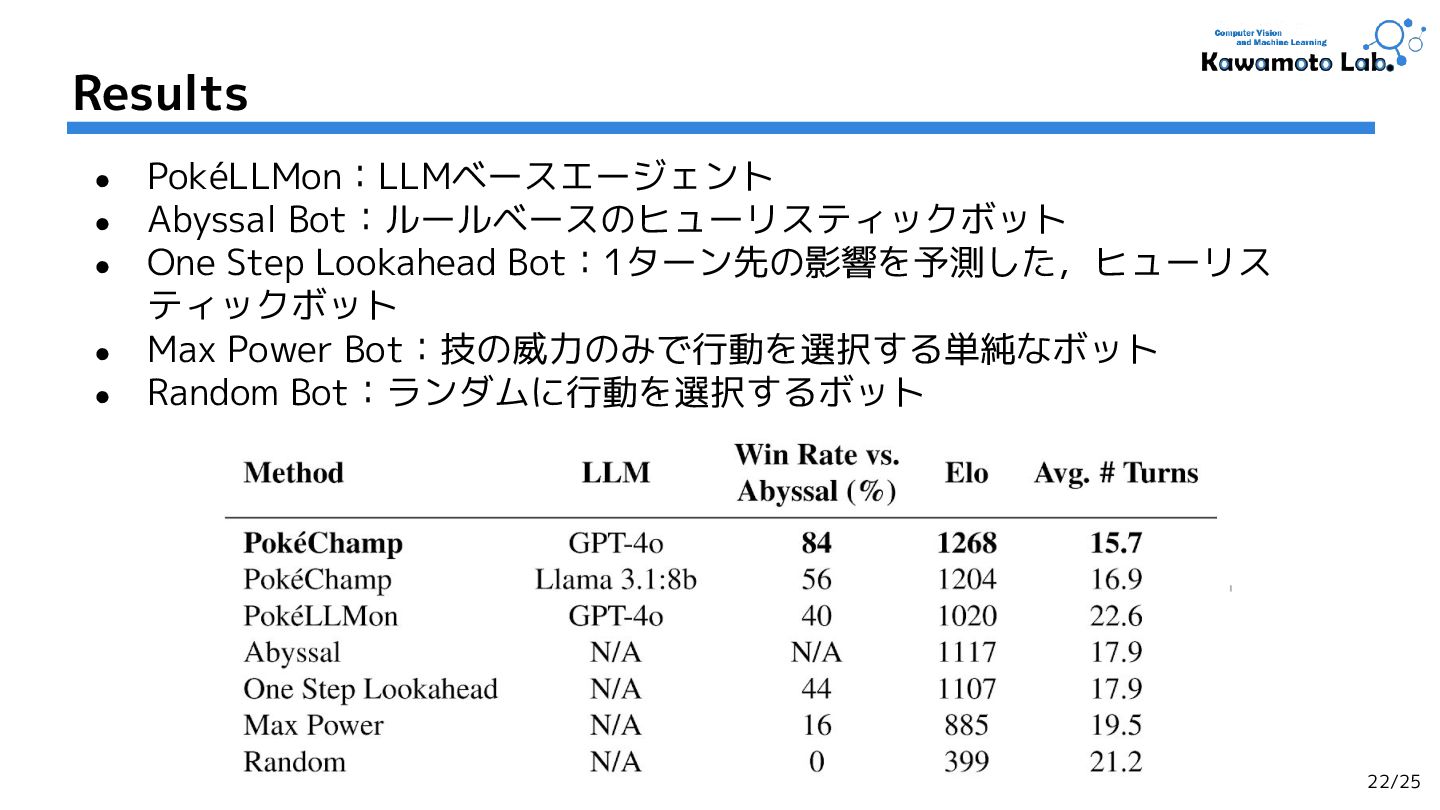
2.PokeChamp: an Expert-level Minimax Language Agent for Competitive Pokemon,
Seth Karten et al. (Princeton University.)
NeurIPS'24 [Workshop] (Cited by: 1 )
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
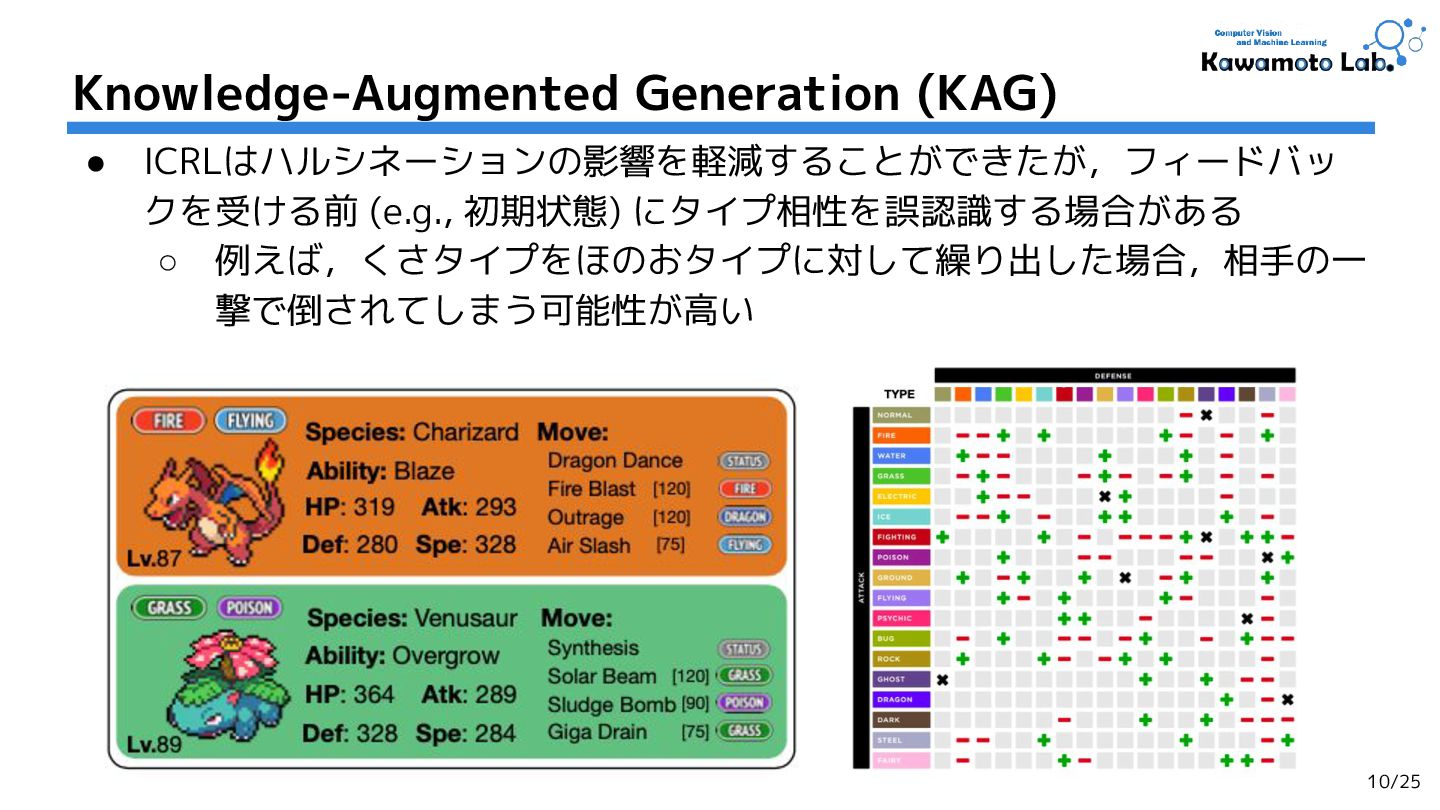
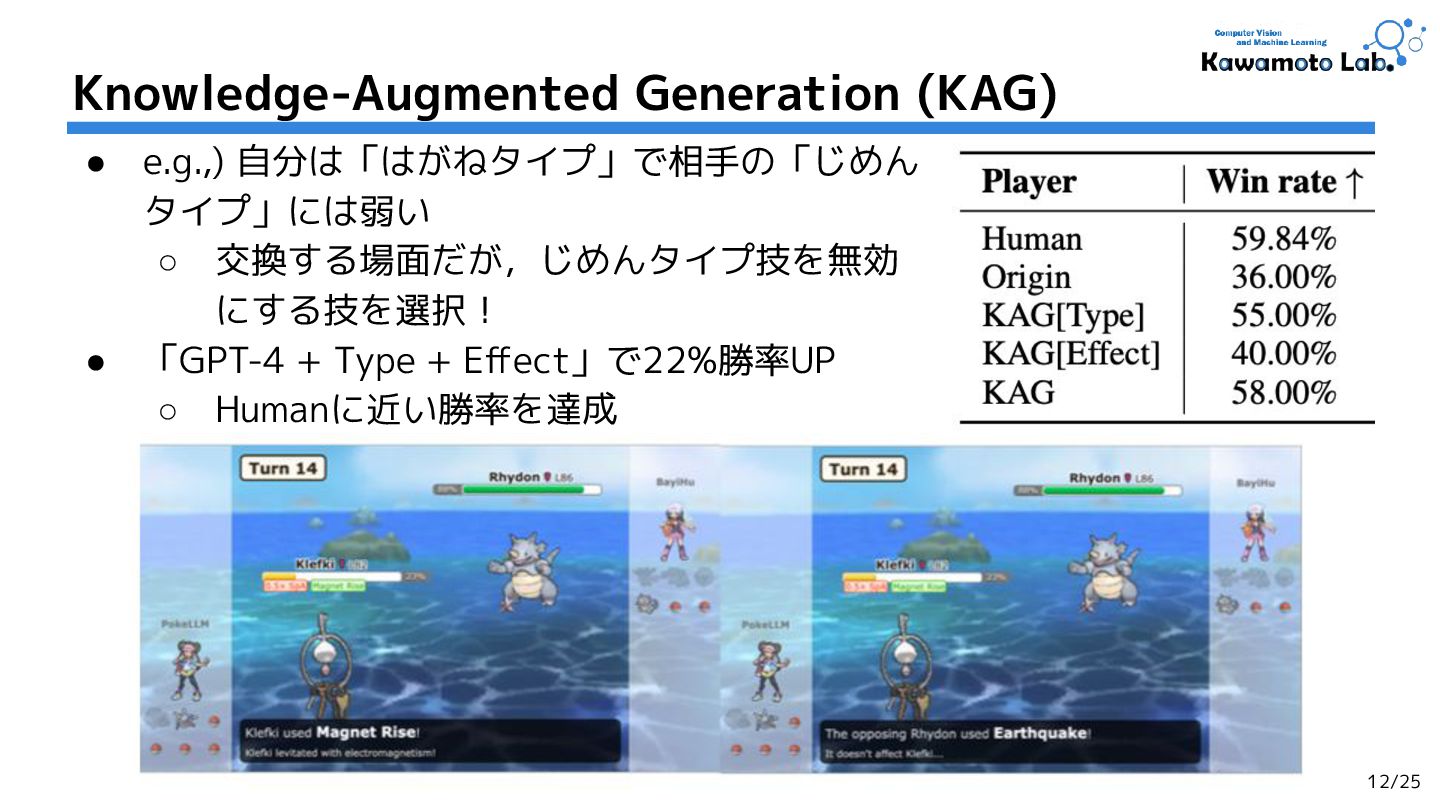
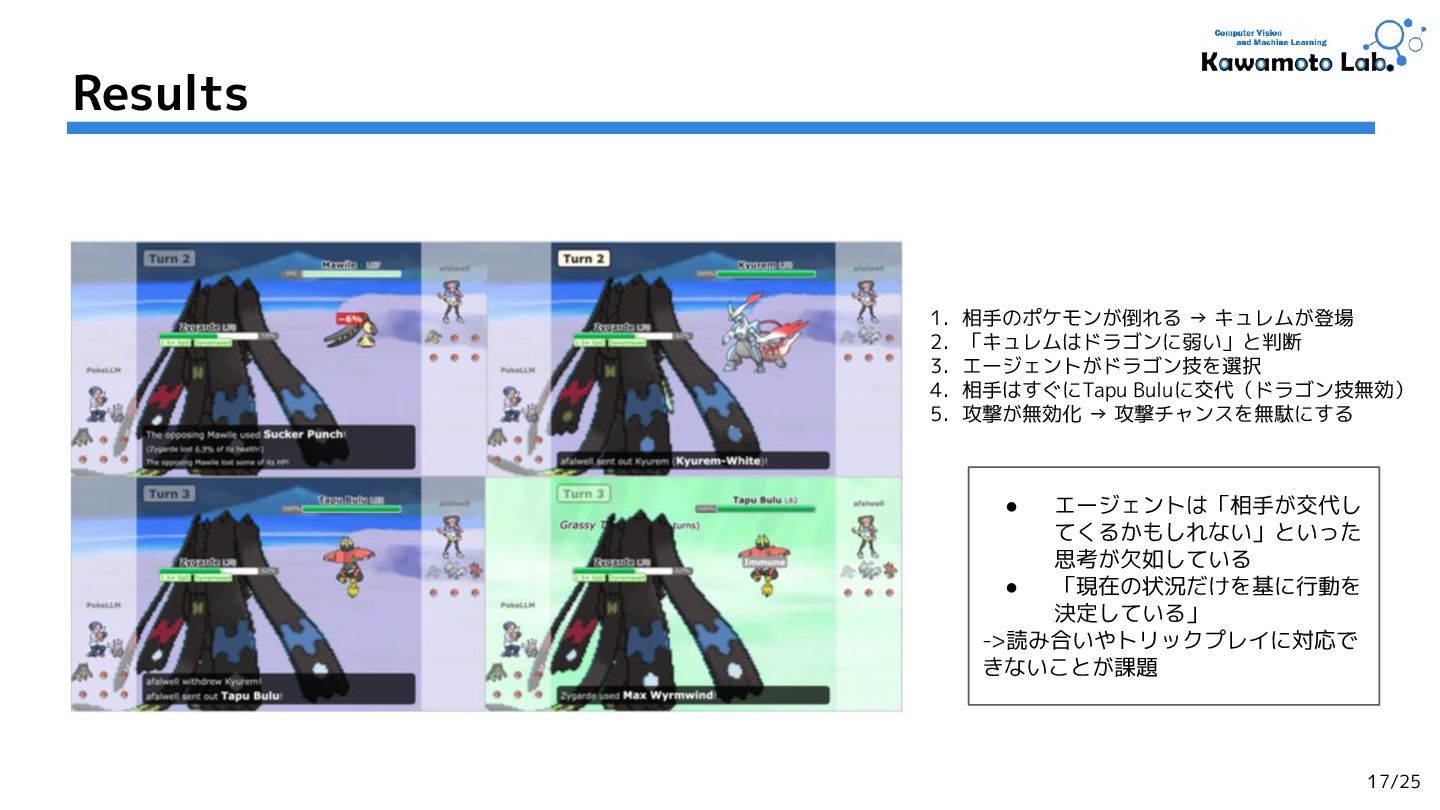
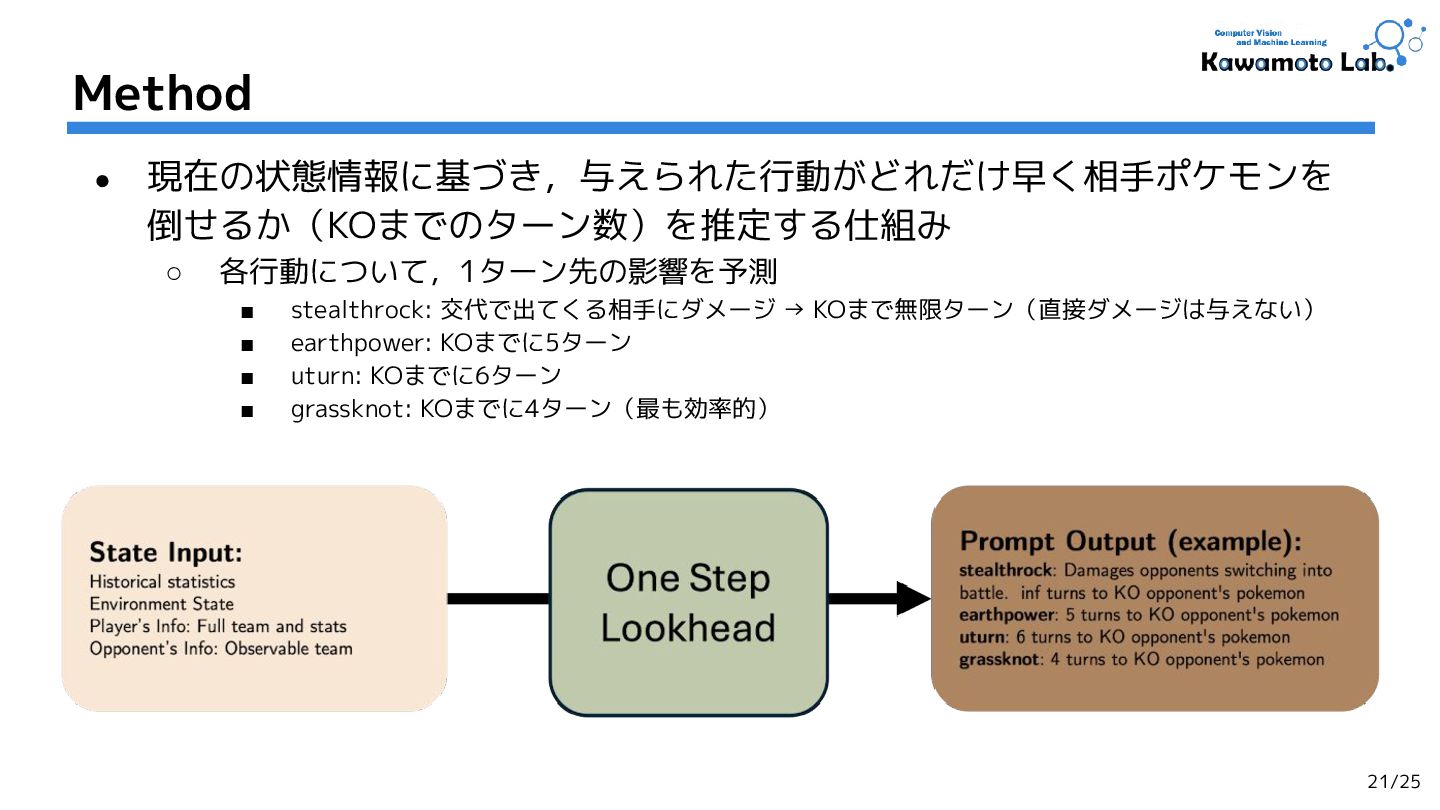
![• タイプ相性(有利・不利)の関係:[Type] ◦ 相手ポケモンと自分のポケモンの有利・不利 関係を明示的に記述 ◦ e.g.,) リザードンは「くさタイプ」につよい • 技・特性の効果:](https://files.speakerdeck.com/presentations/324358337cab4826856c43a6a35989d5/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}