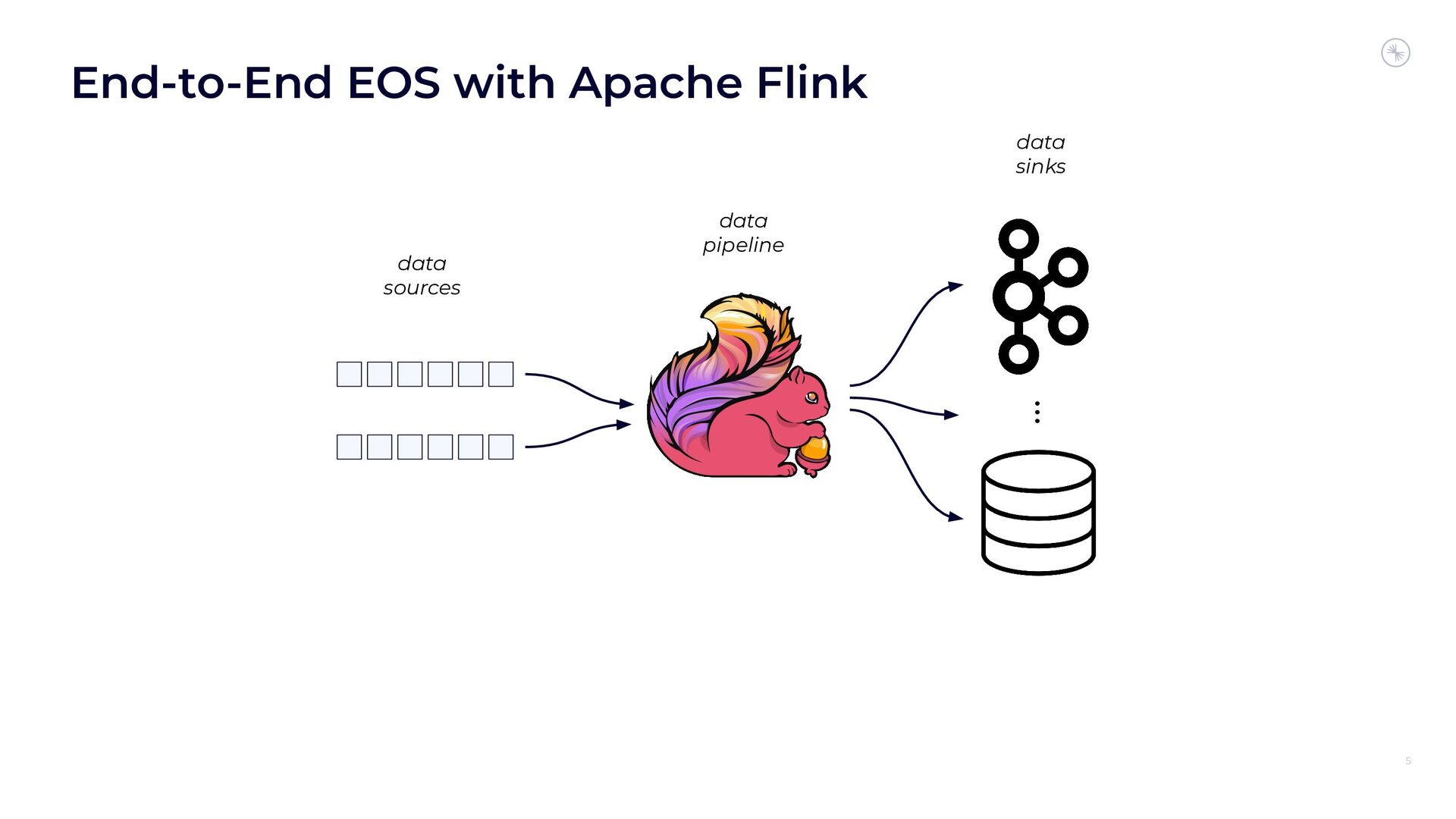
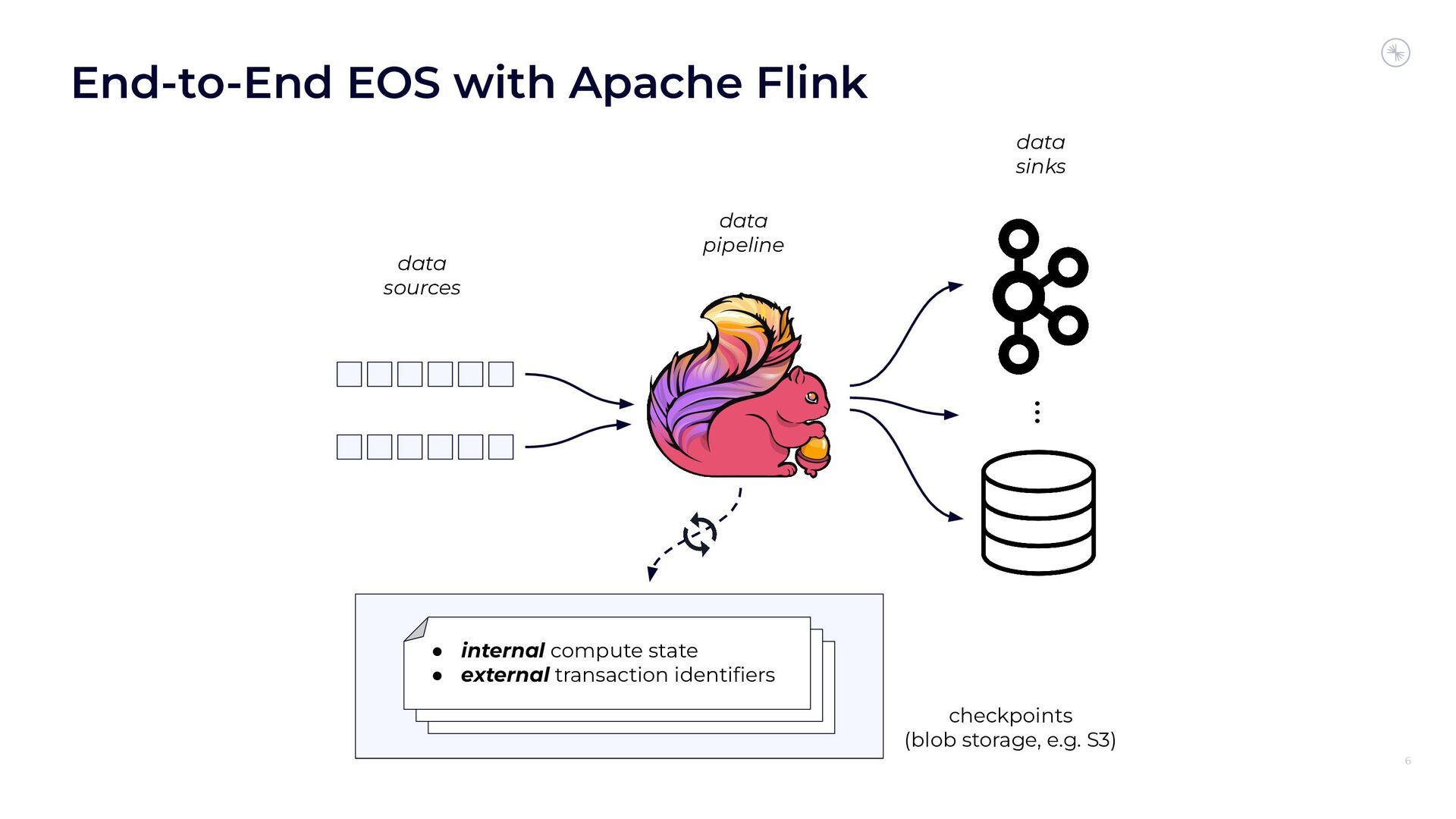
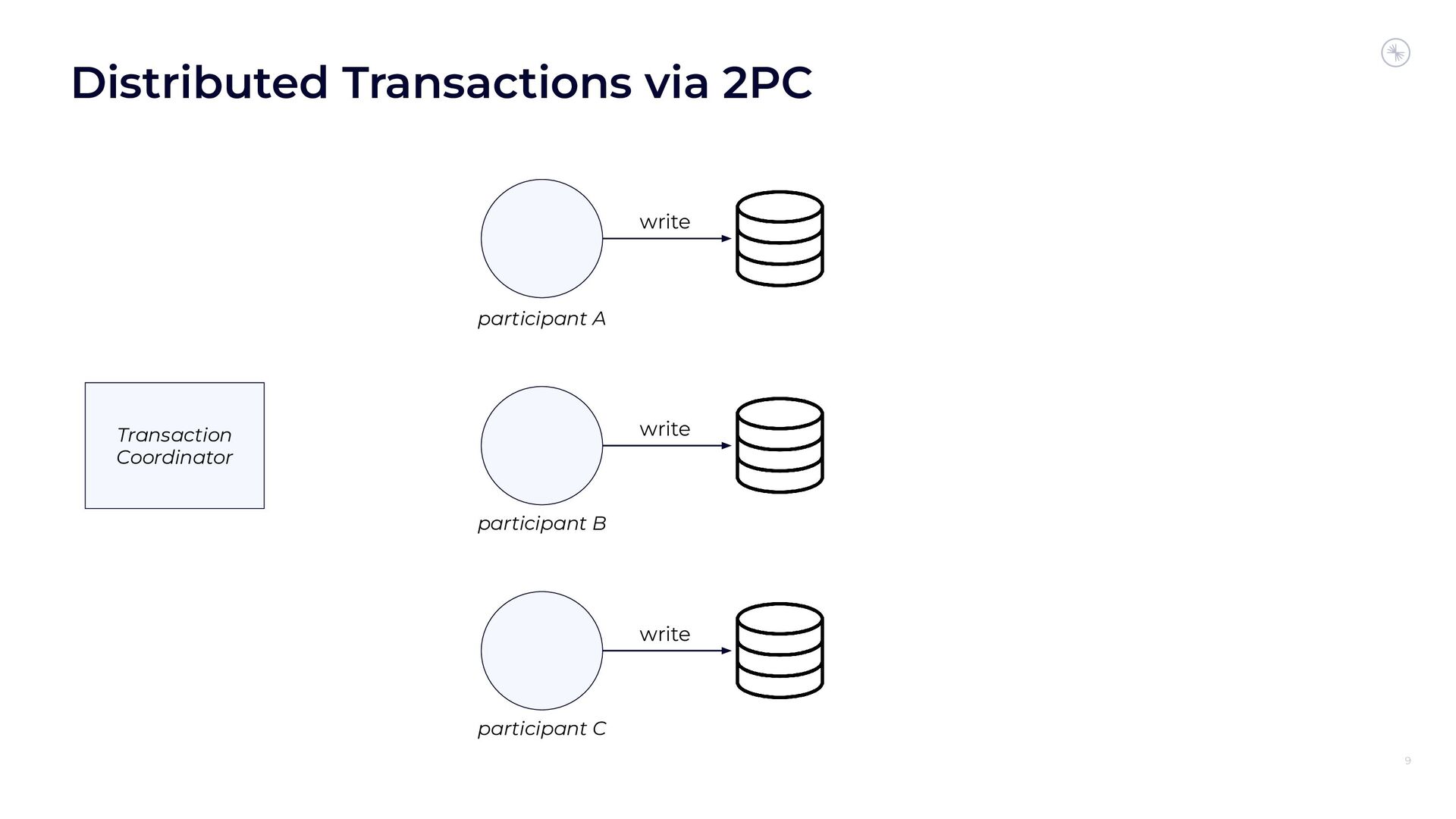
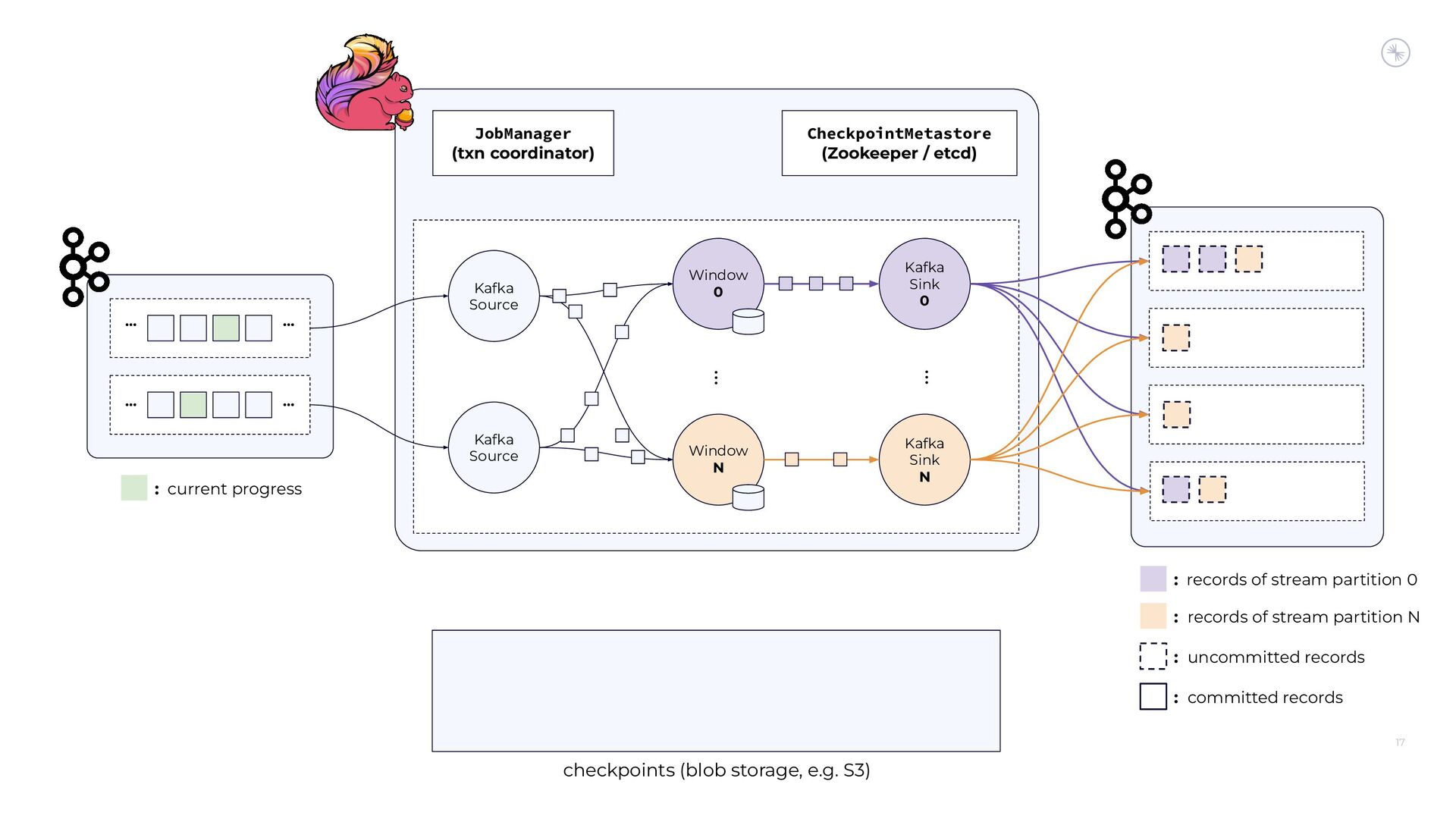
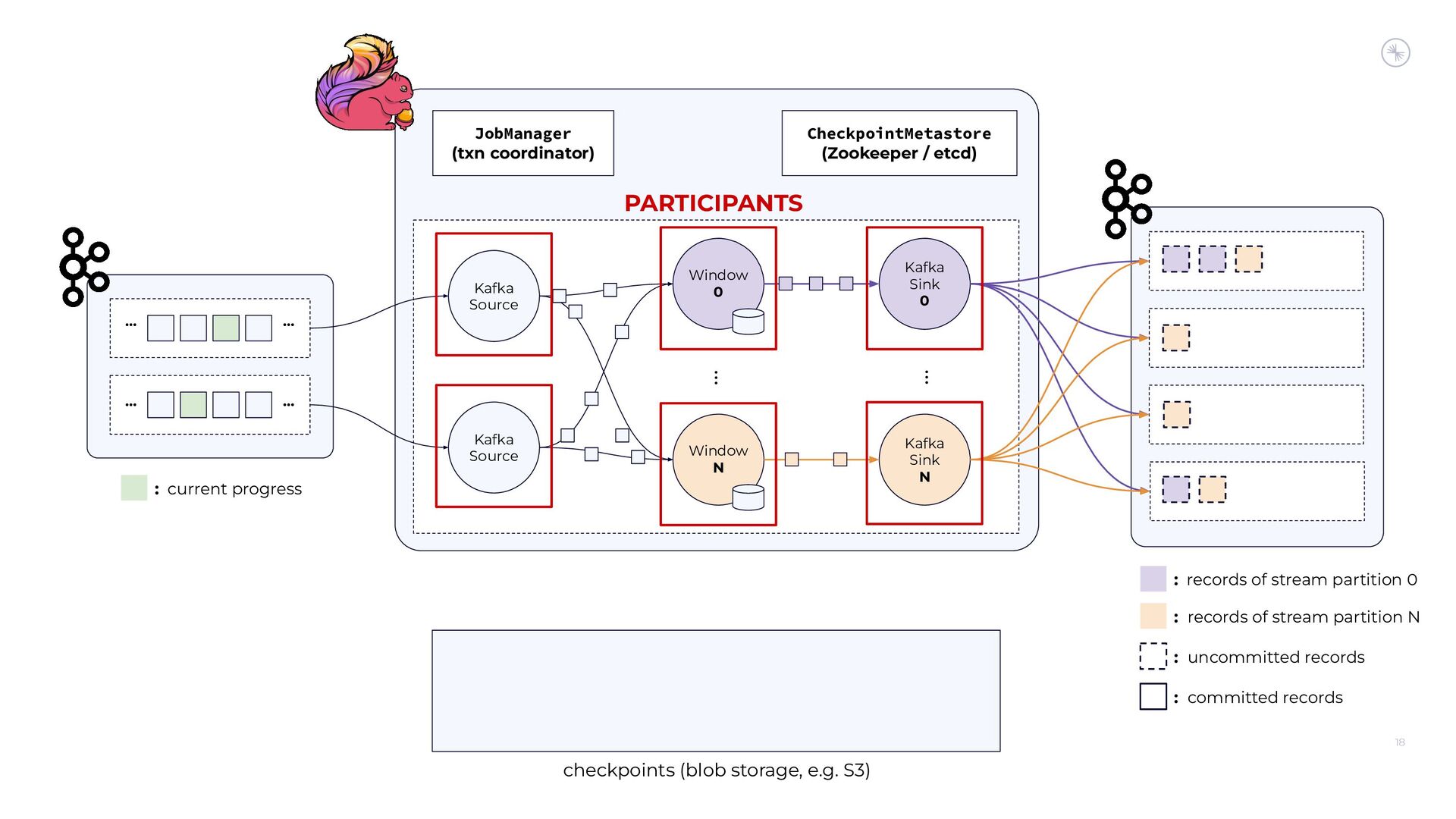
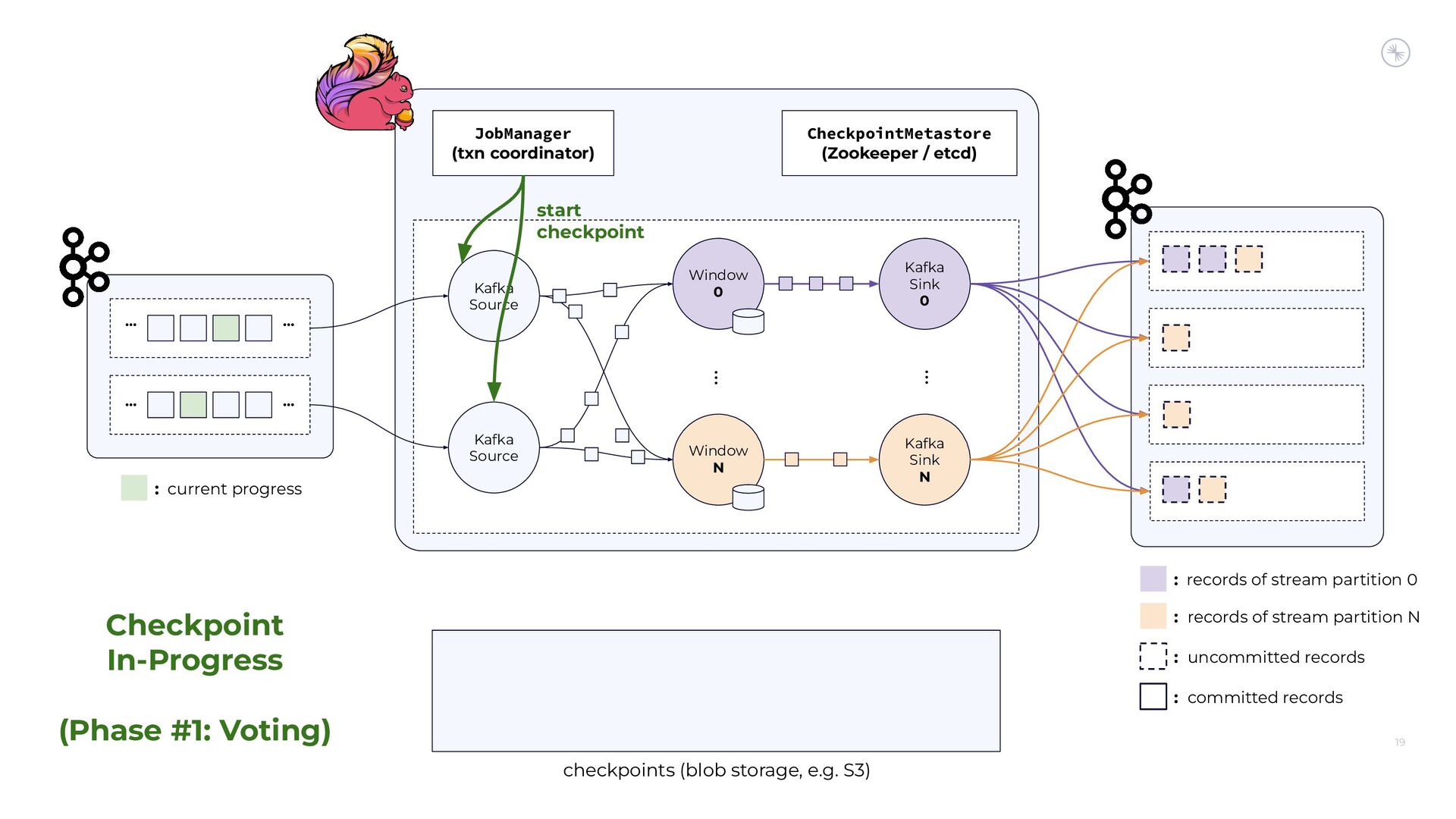
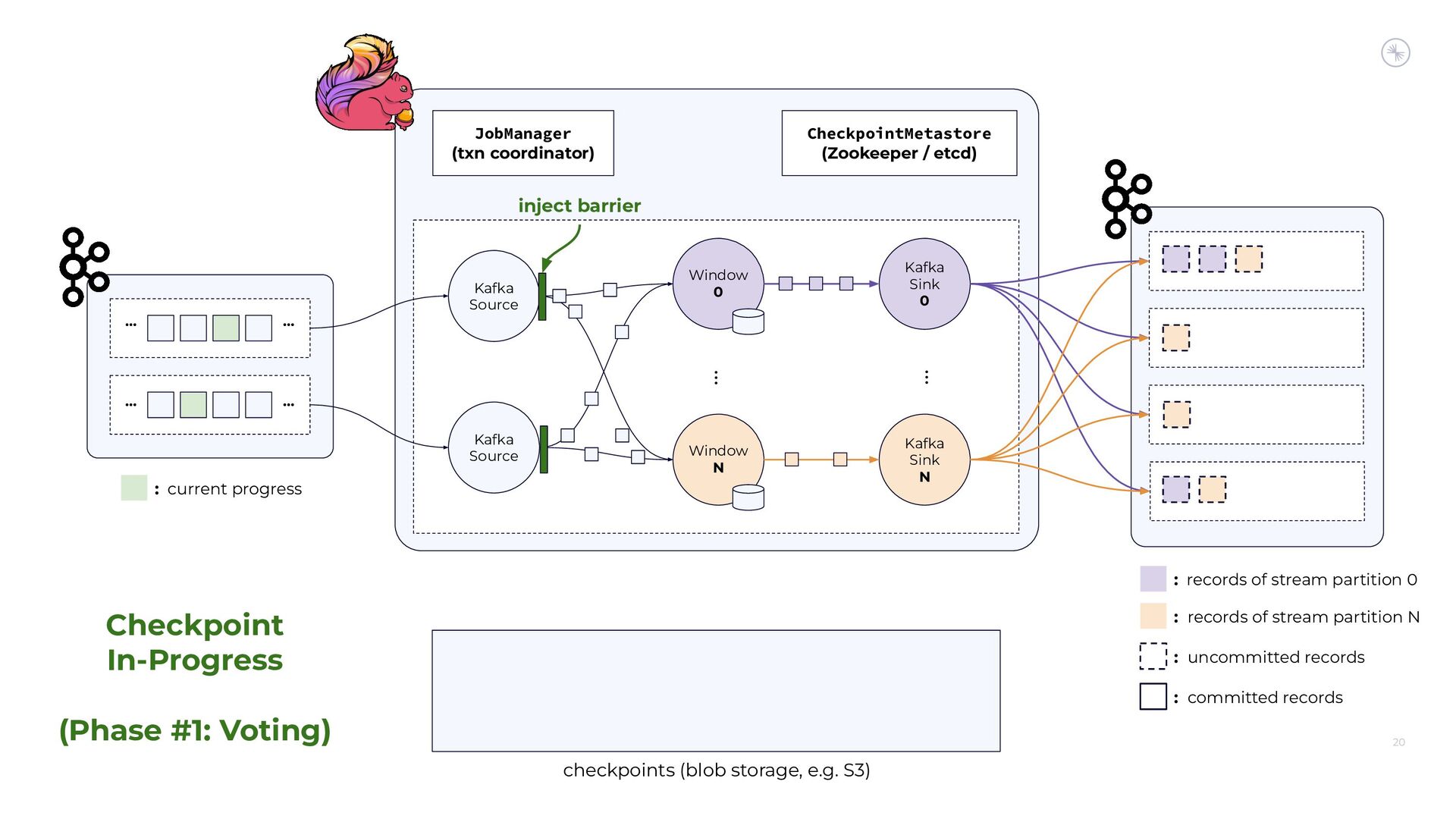
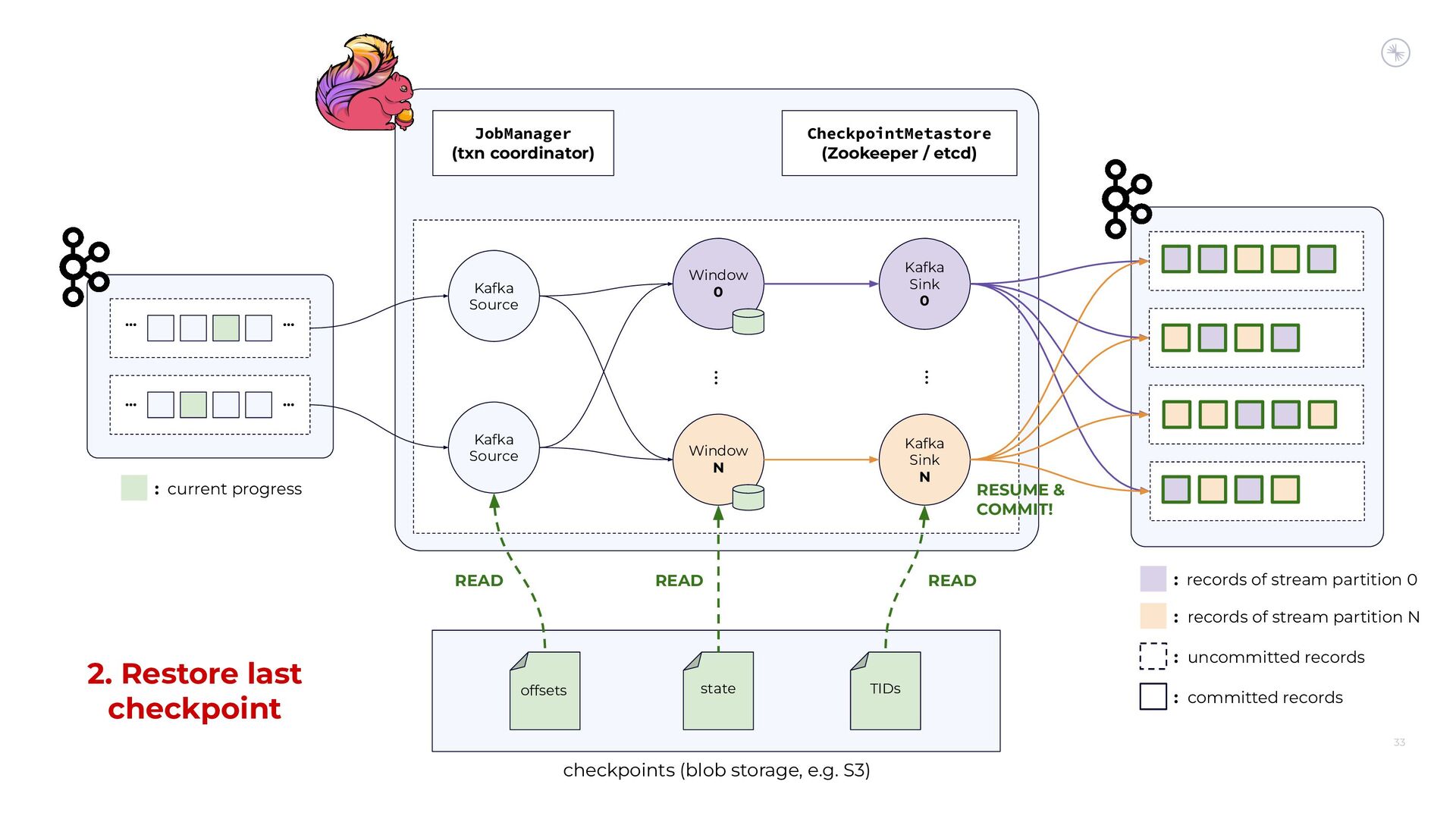
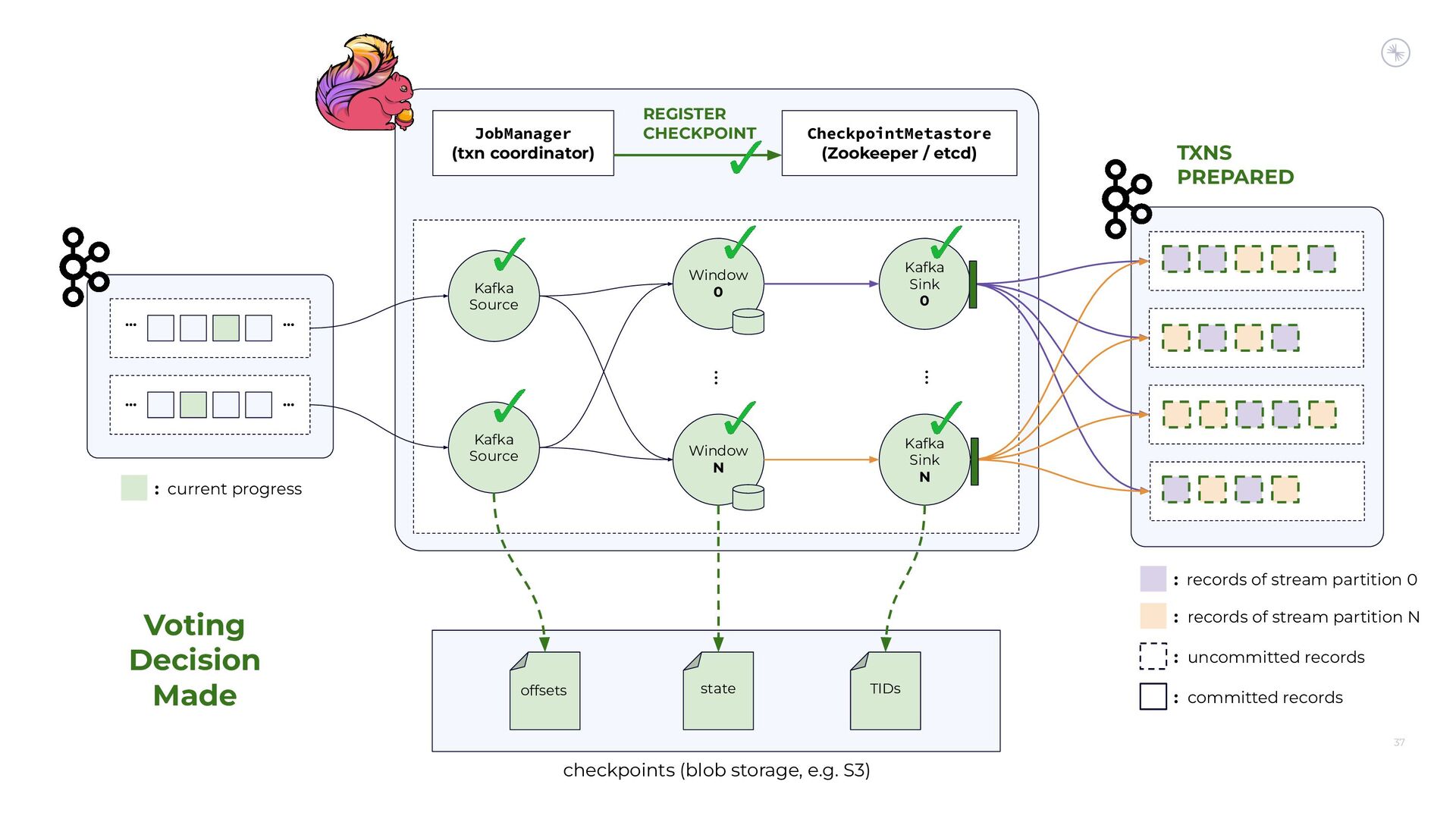
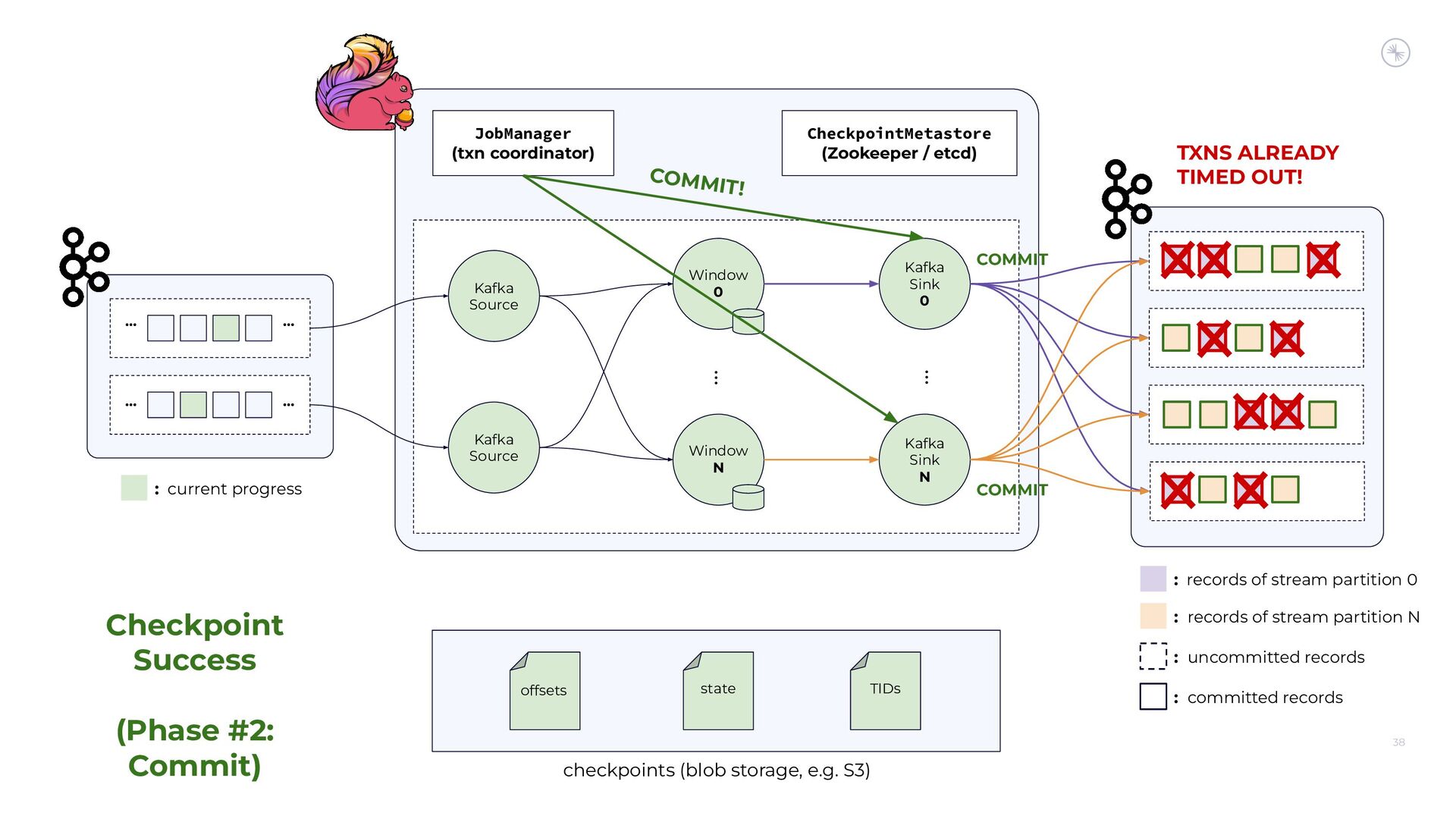
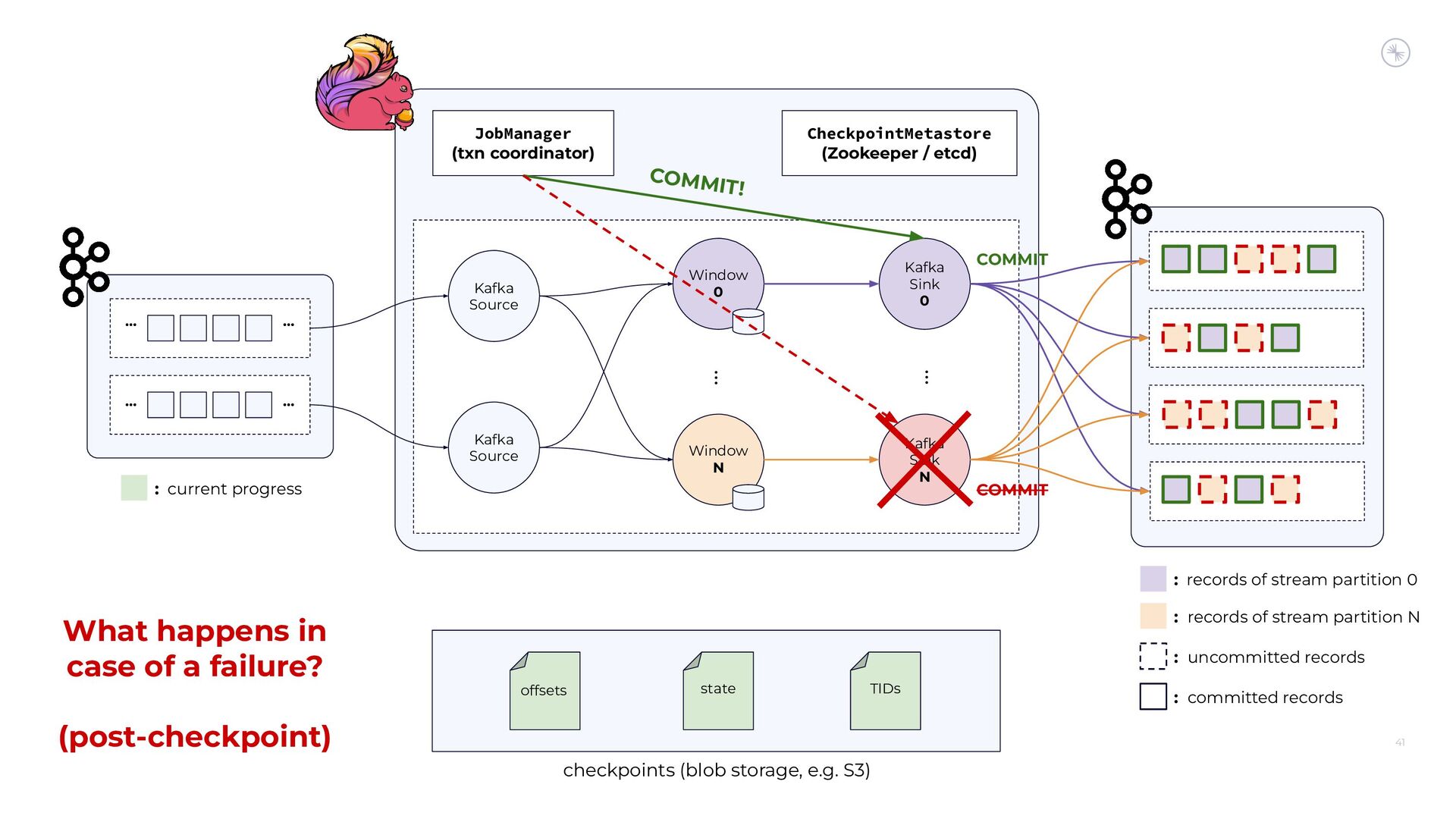
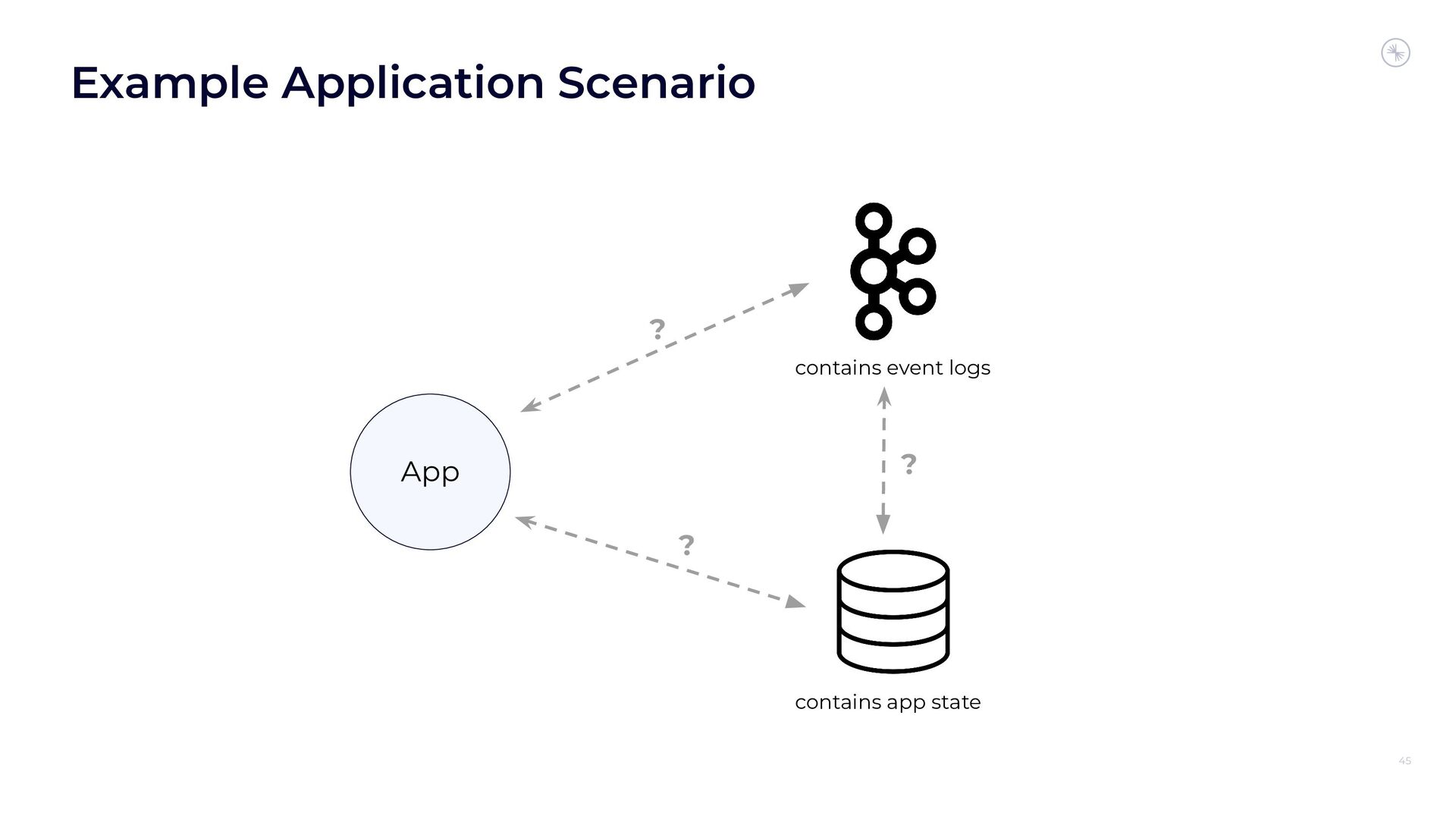
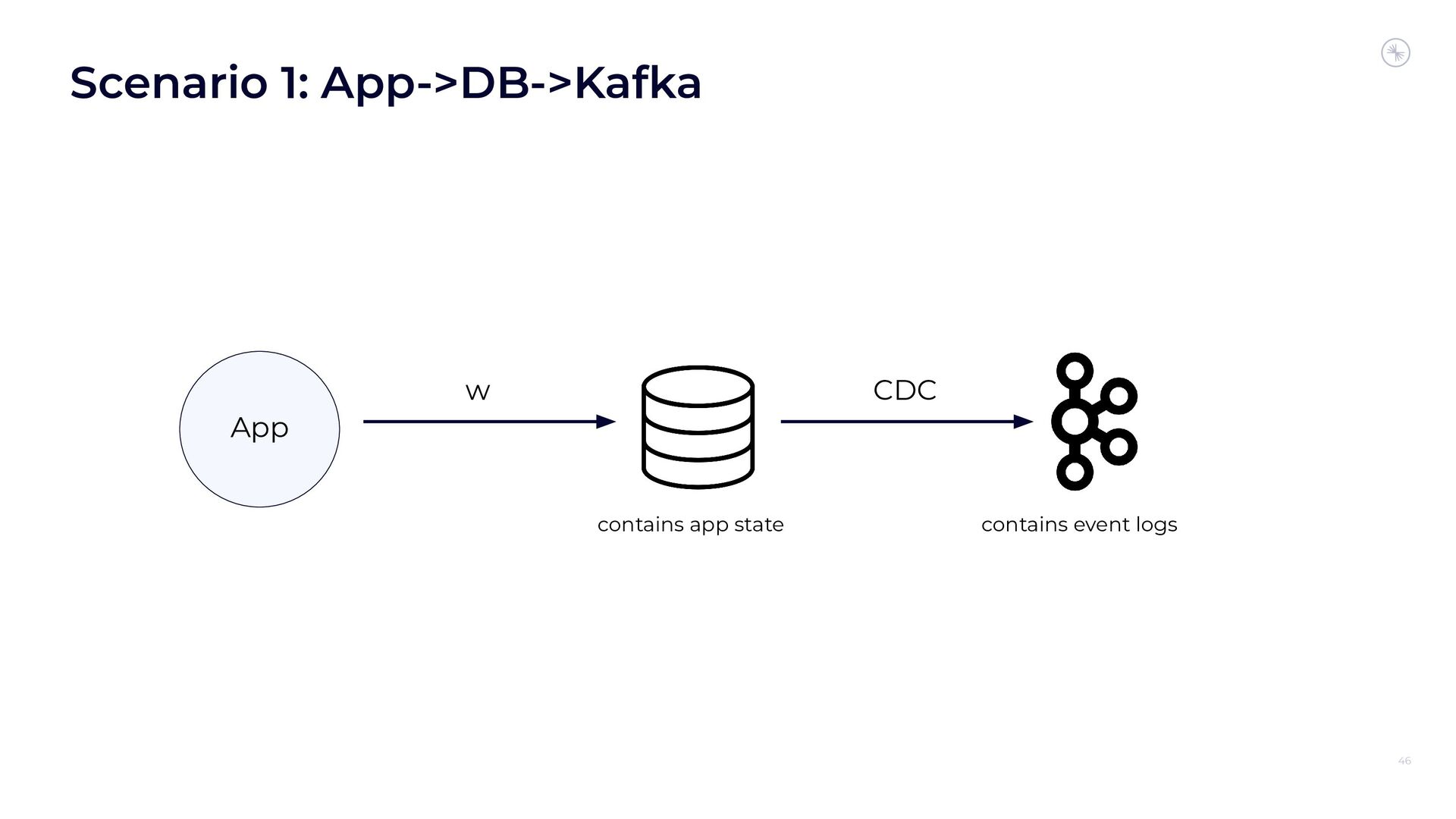
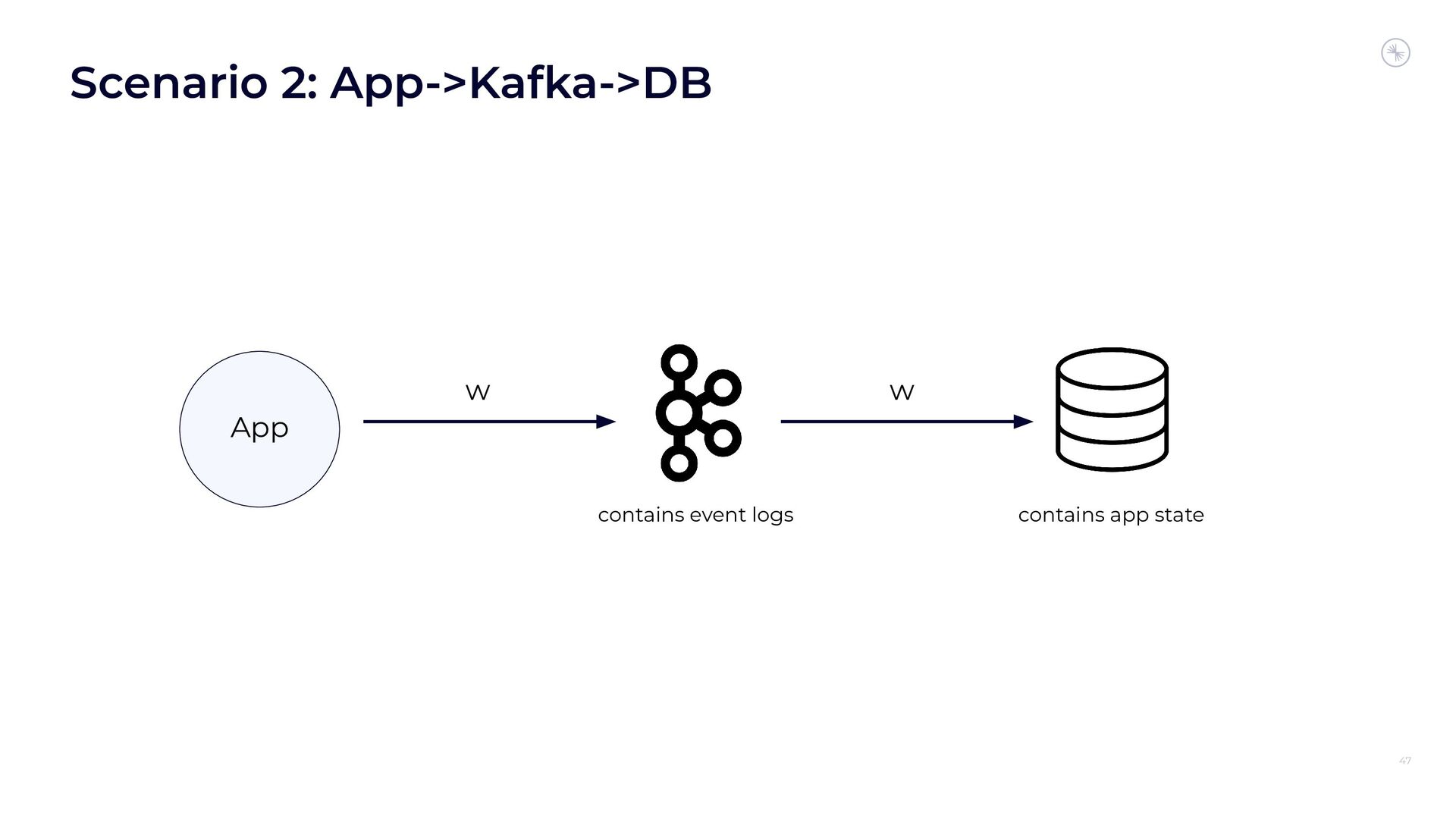
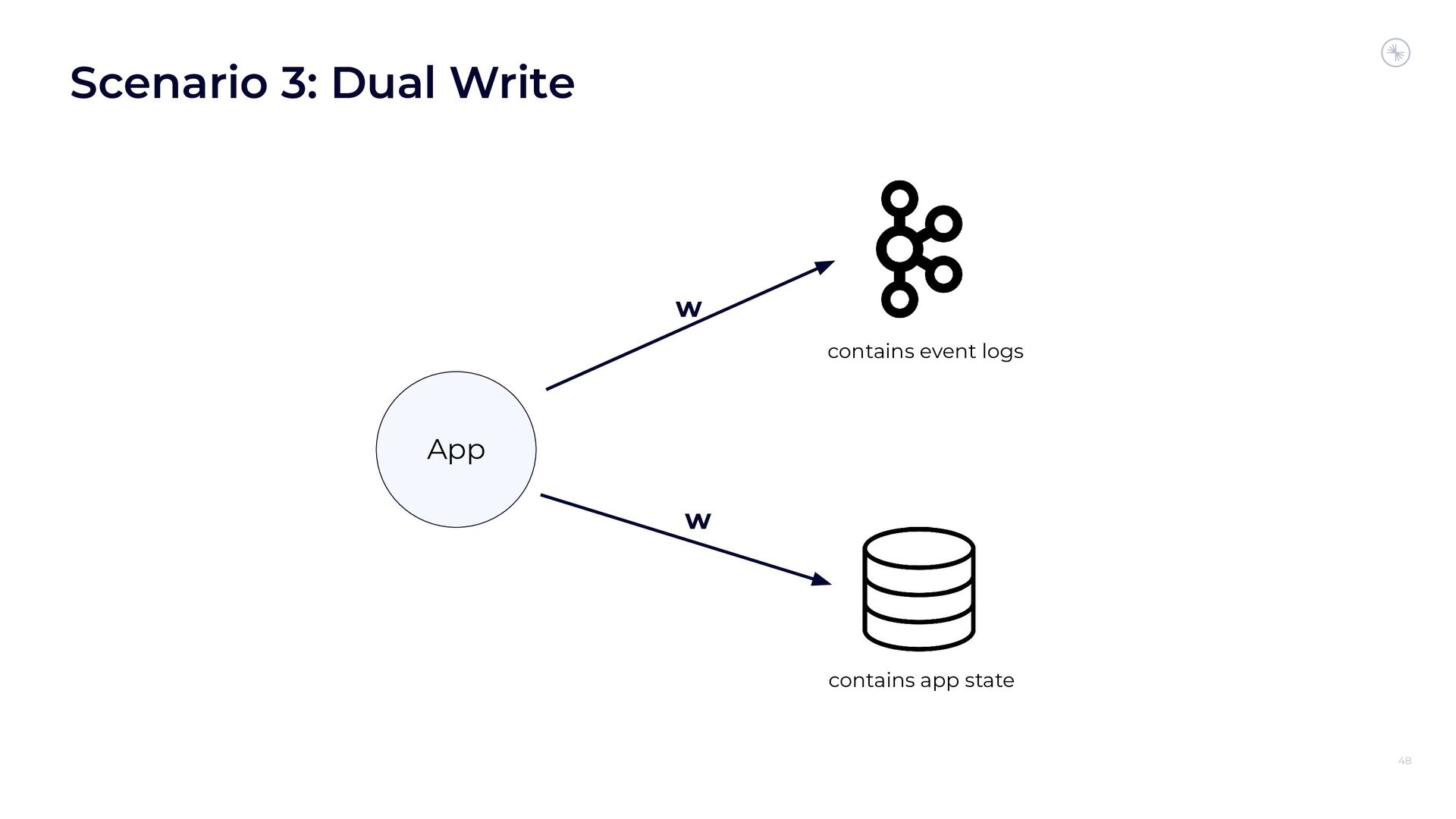
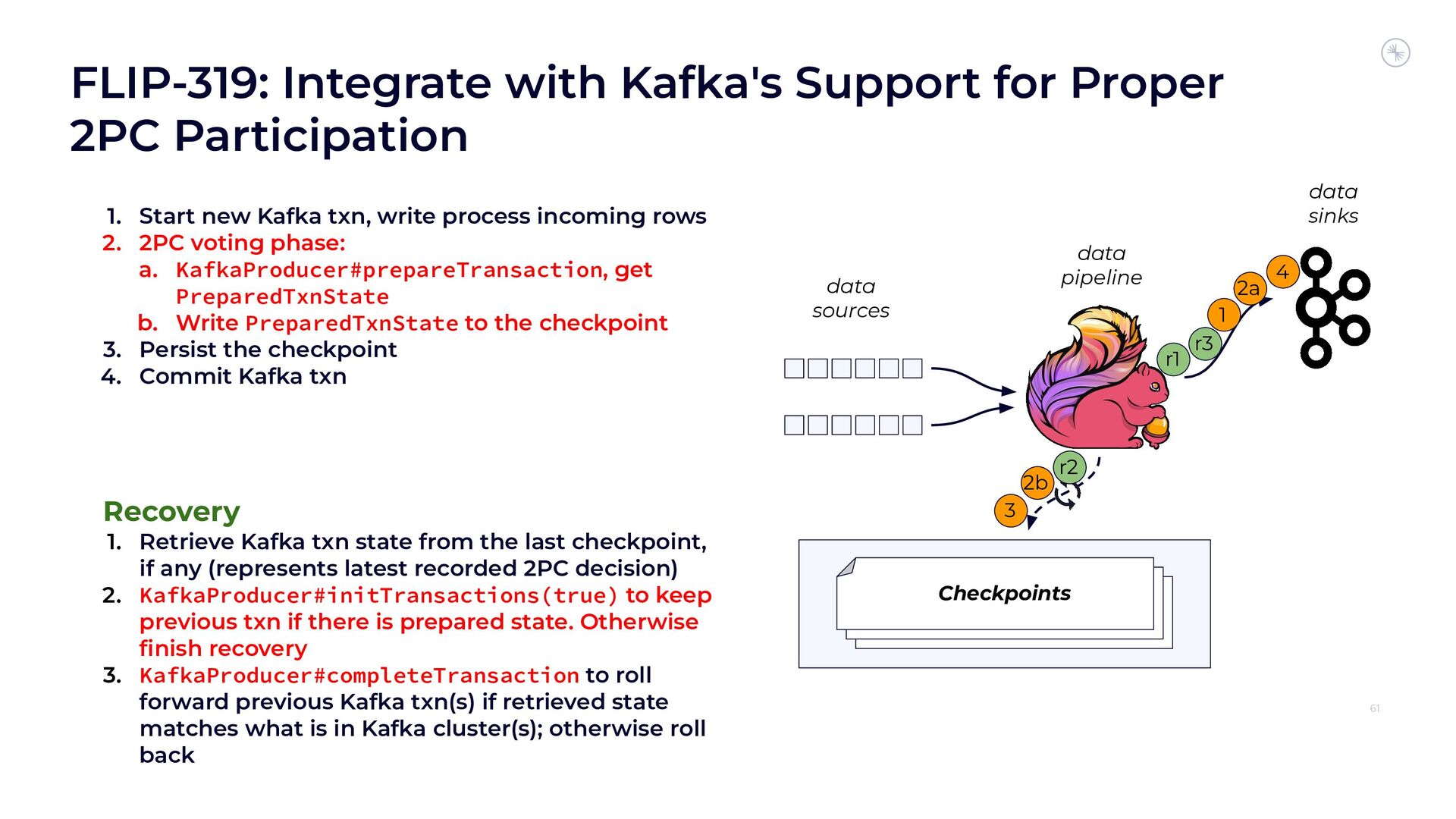
Apache Flink’s Exactly-Once Semantics (EOS) integration for writing to Apache Kafka has several pitfalls, due mostly to the fact that the Kafka transaction protocol was not originally designed with distributed transactions in mind. The integration uses Java reflection hacks as a workaround, and the solution can still result in inconsistencies under certain scenarios. Can we do better?
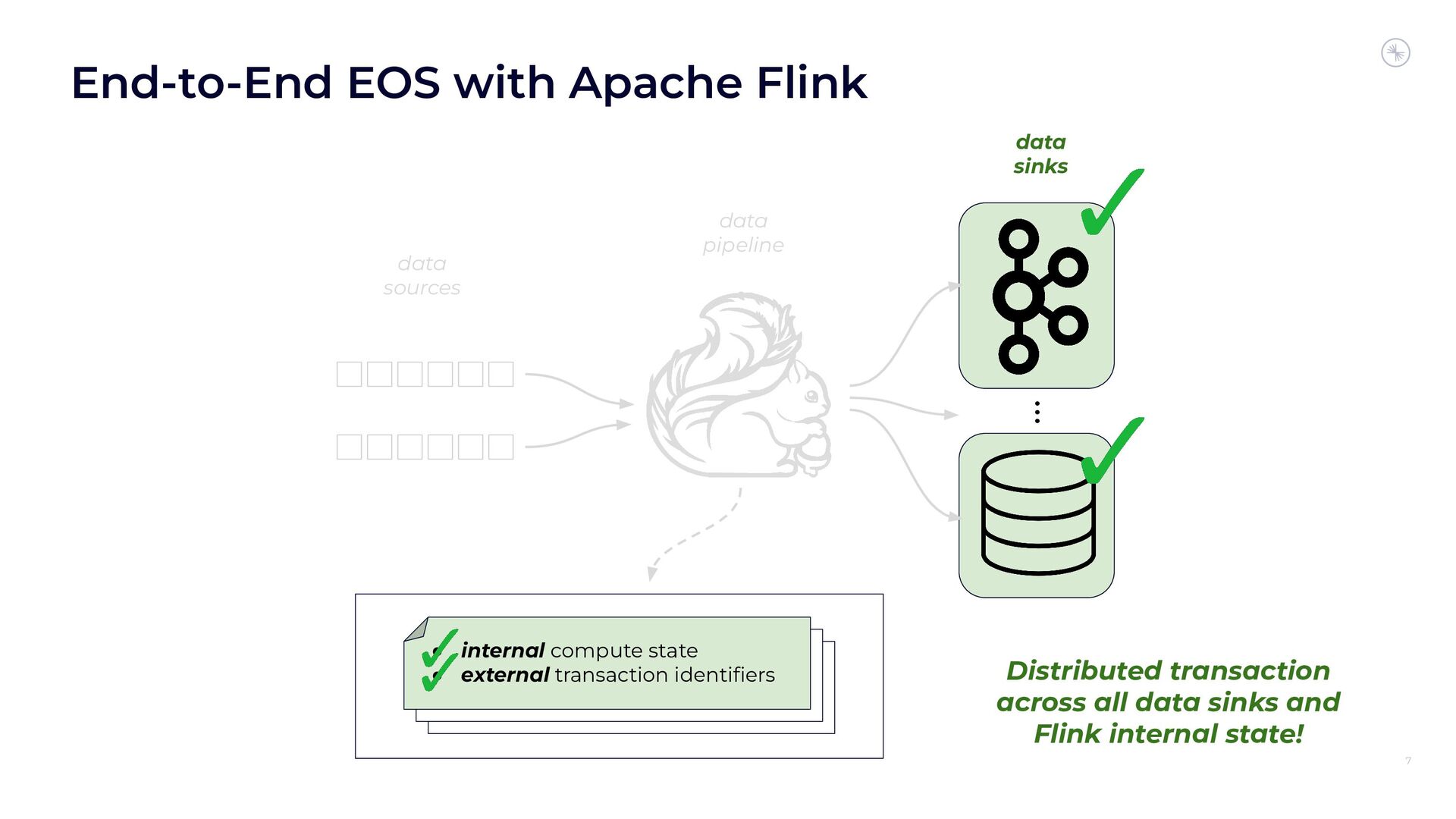
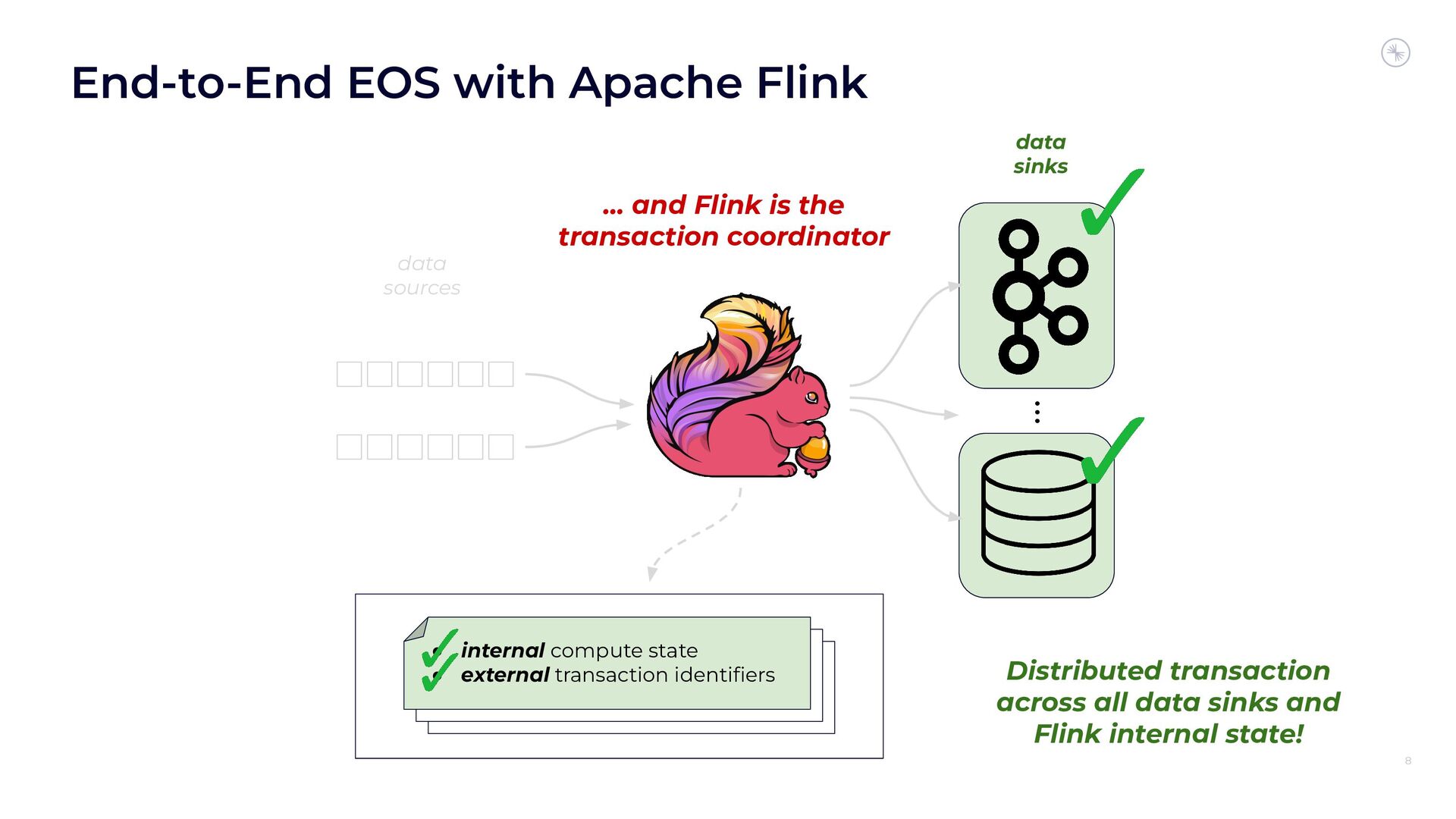
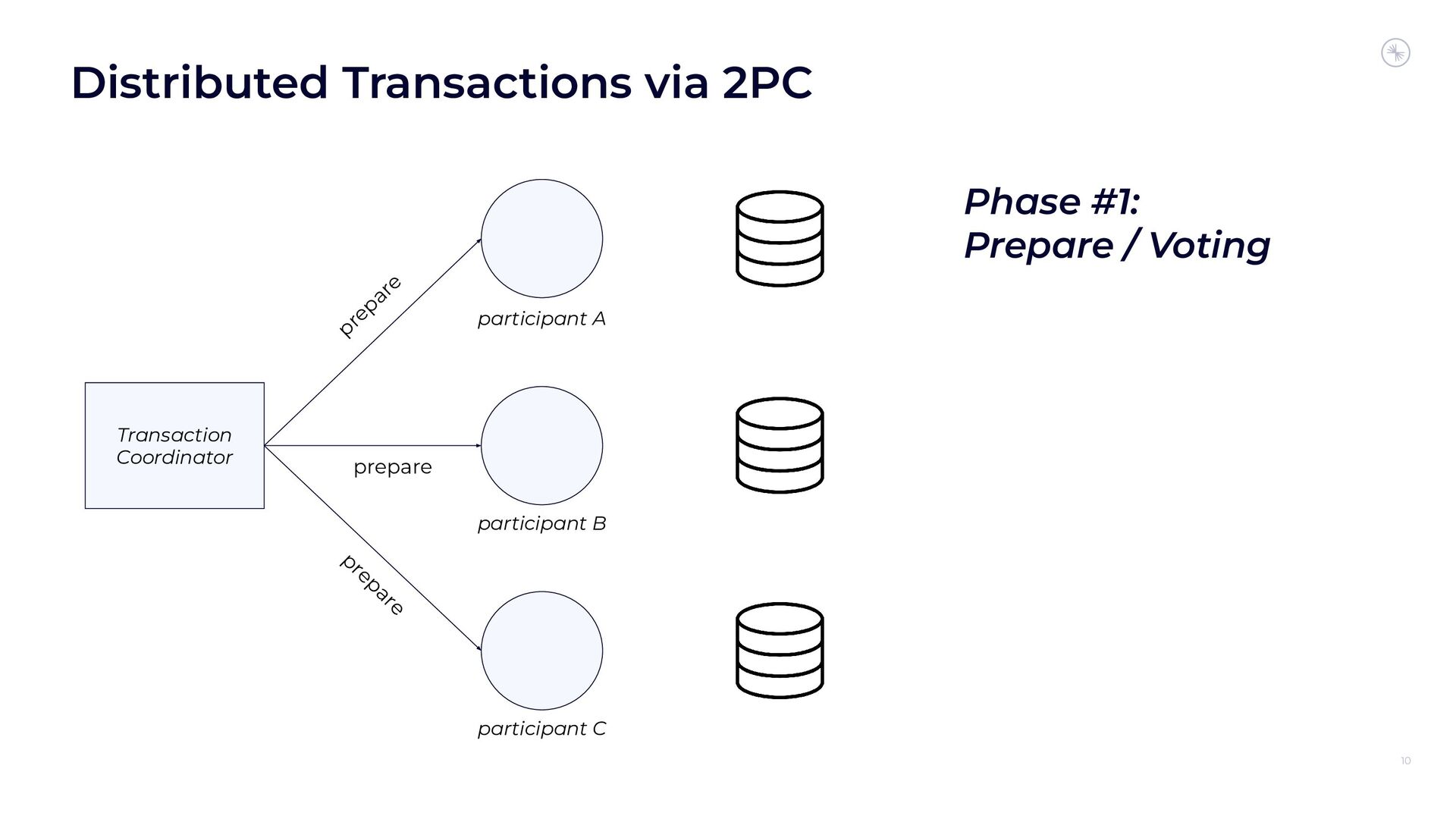
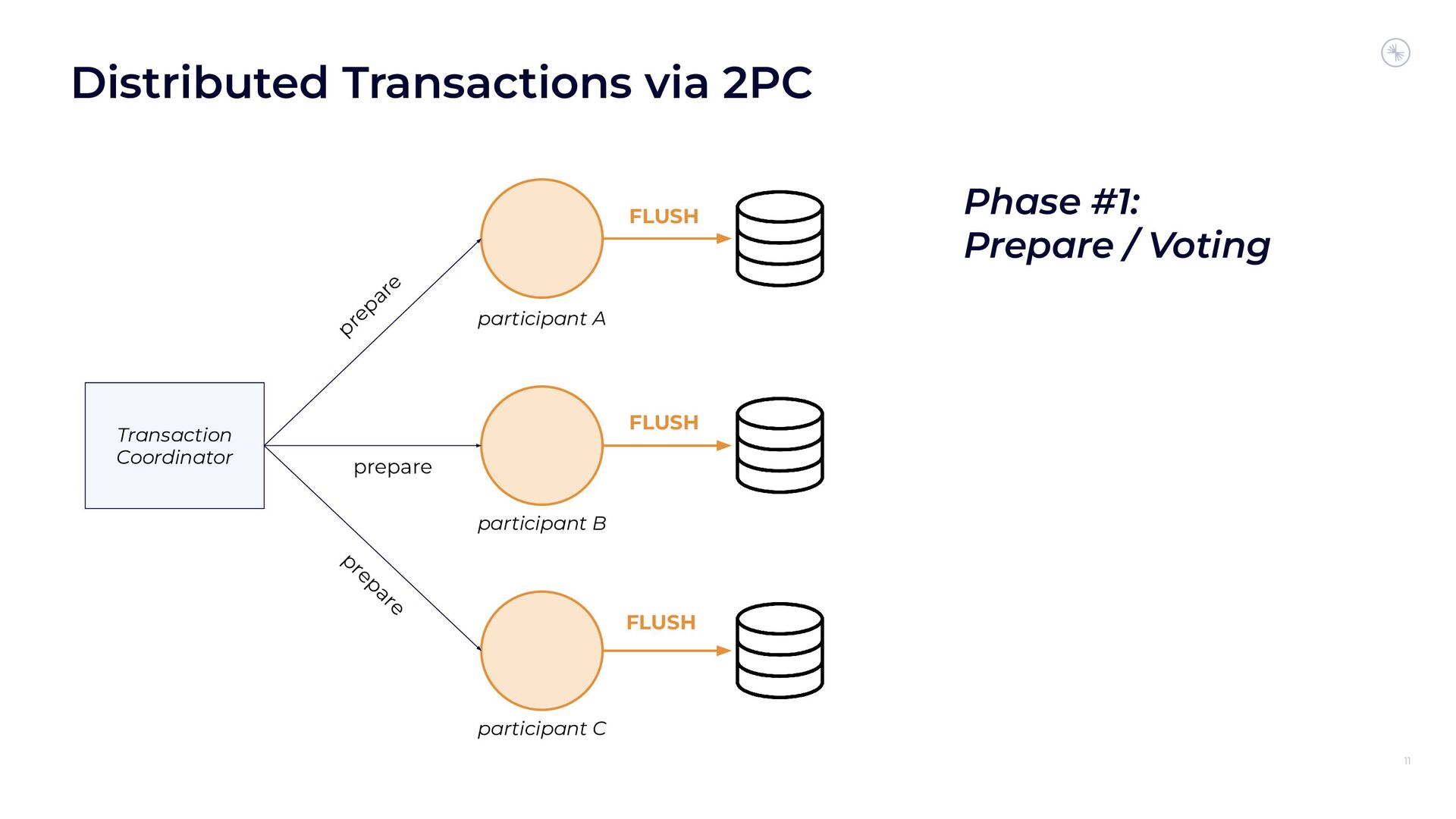
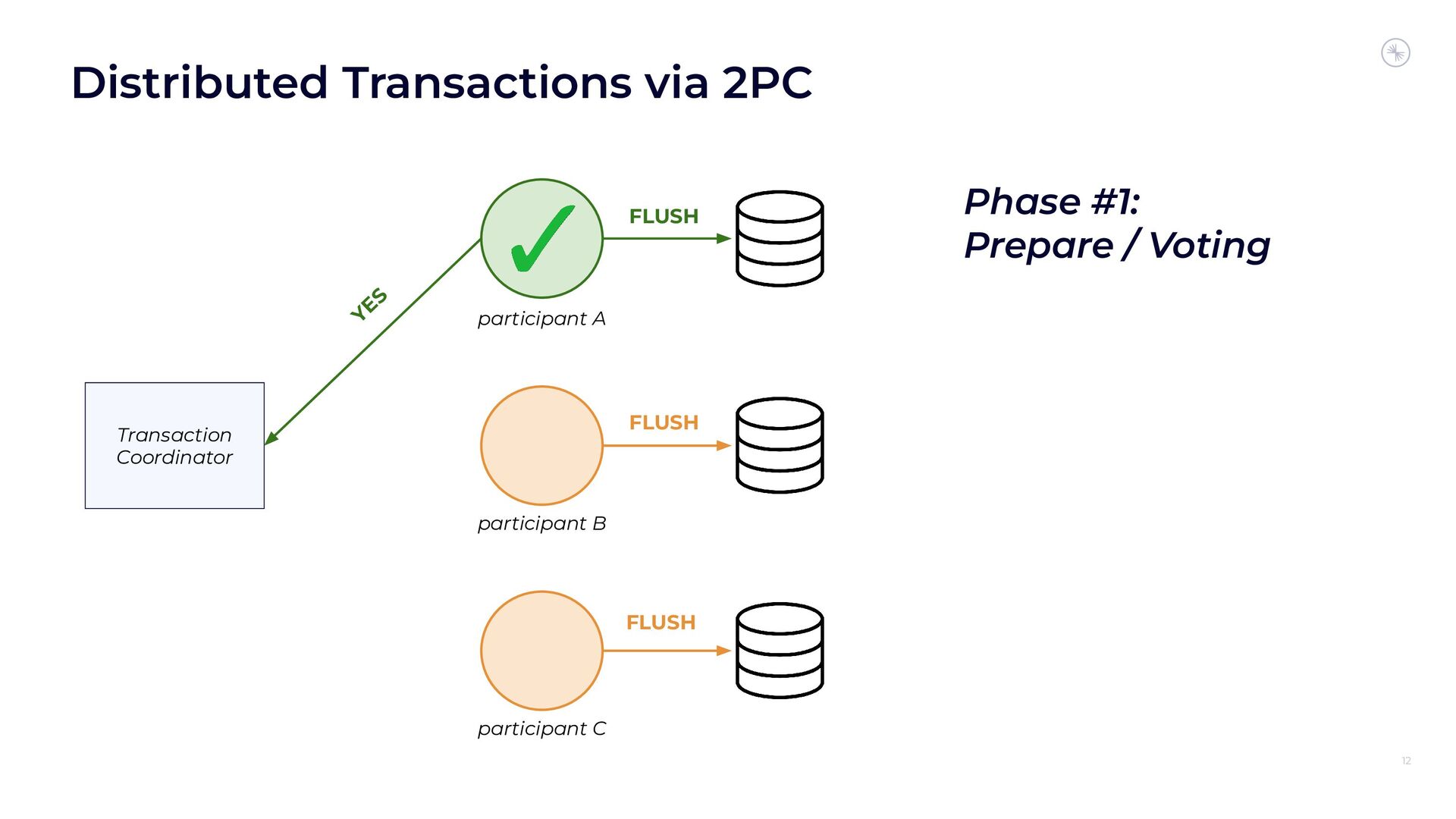
In this session, you’ll see how the Flink and Kafka communities are uniting to tackle these long-standing technical debts. We’ll introduce the basics of how Flink achieves EOS with external systems and explore the common hurdles that are encountered when implementing distributed transactions. Then we’ll dive into the details of the proposed changes to both the Kafka transaction protocol and Flink transaction coordination that seek to provide a more robust integration.
By the end of the talk, you’ll know the unique challenges of EOS with Flink and Kafka and the improvements you can expect across both projects.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
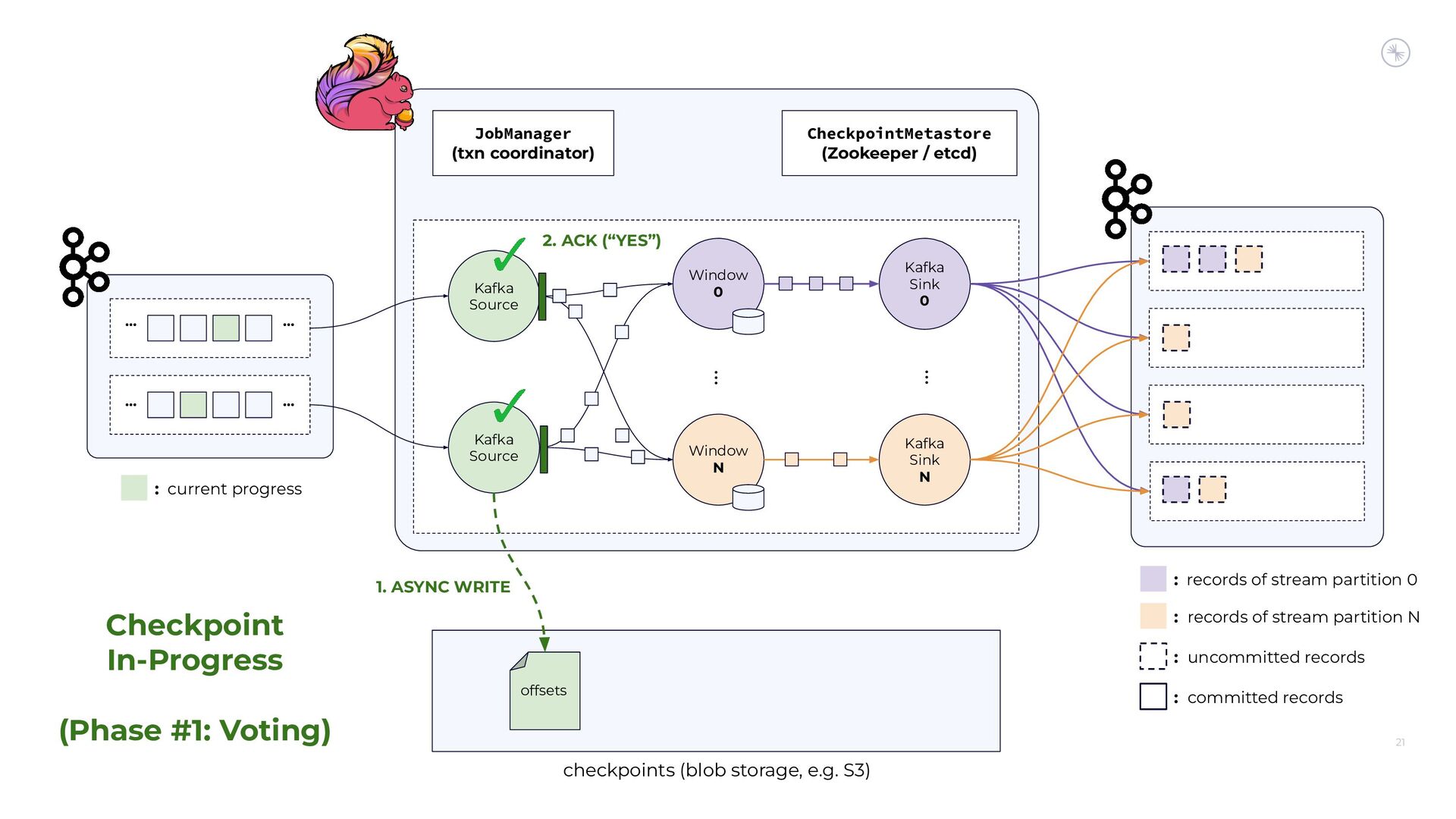{kind=link}
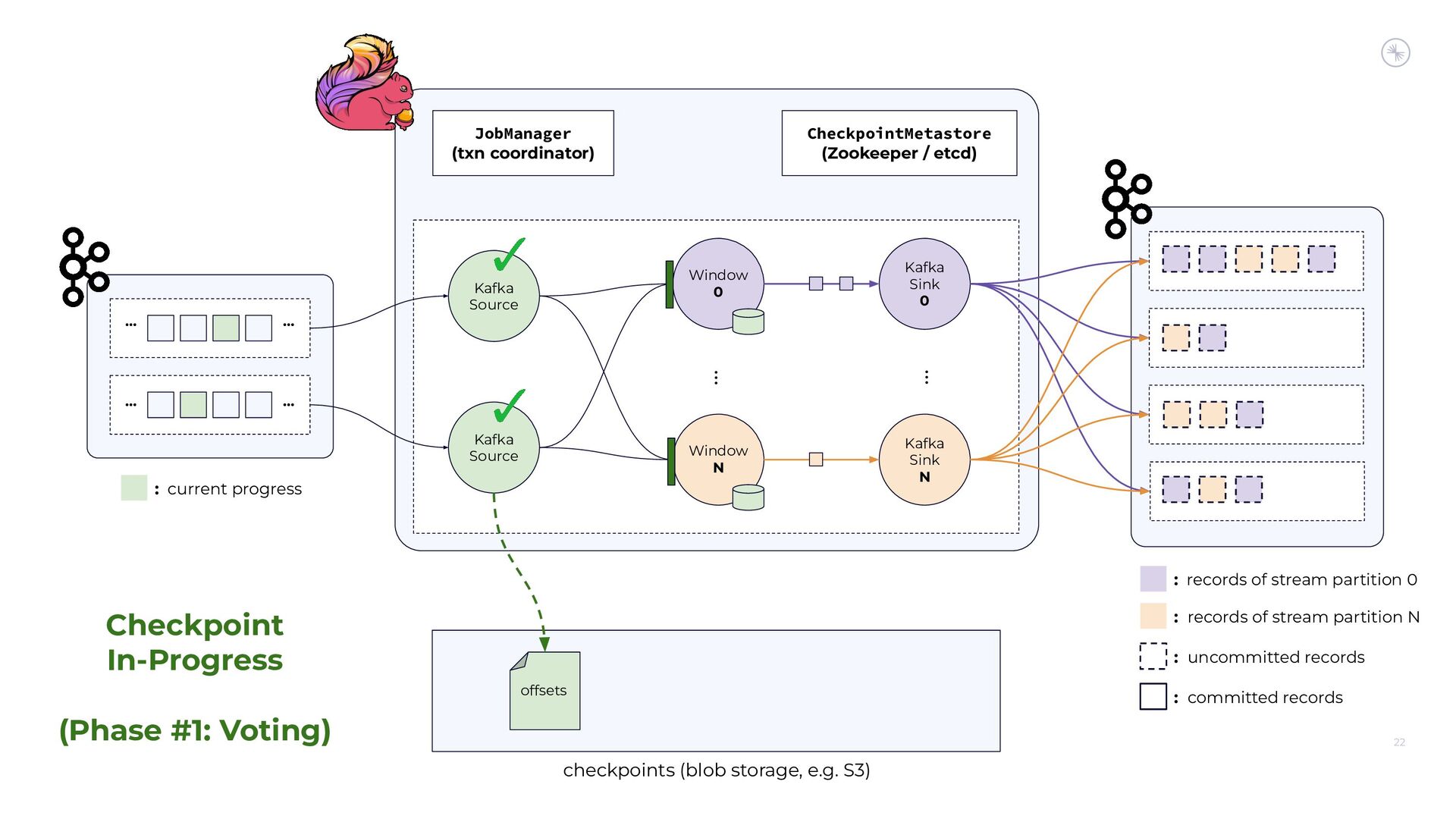{kind=link}
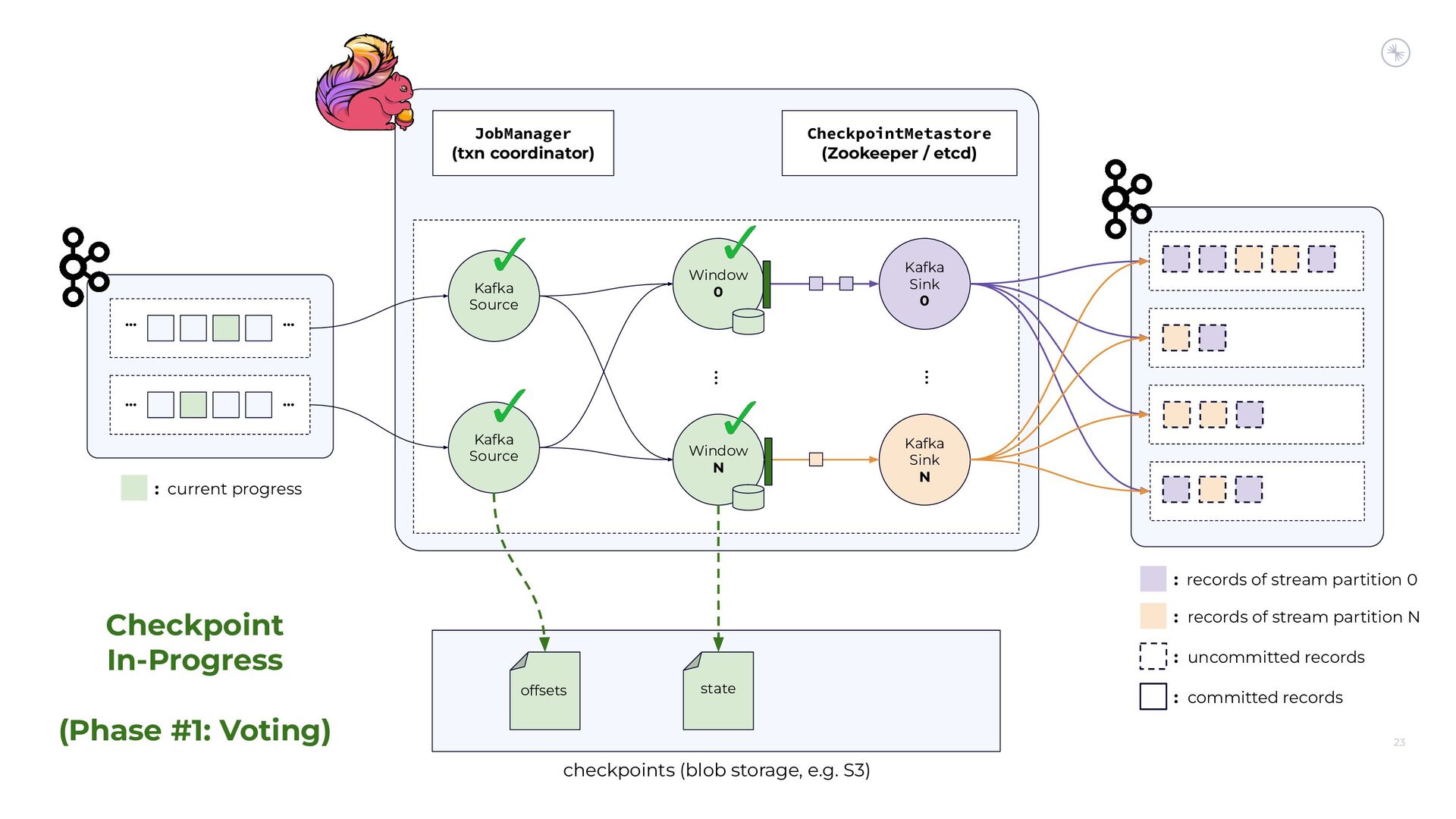{kind=link}
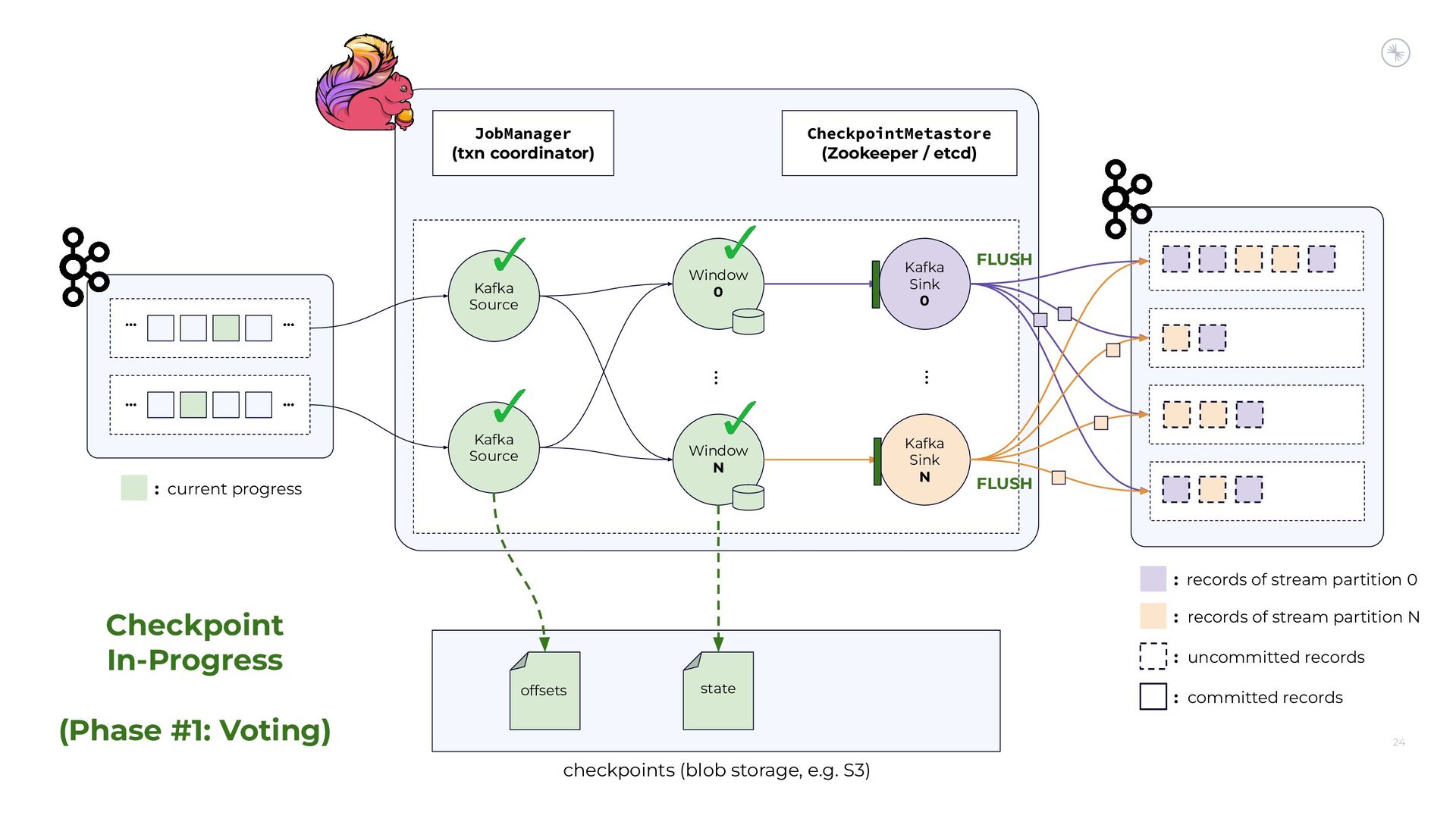{kind=link}
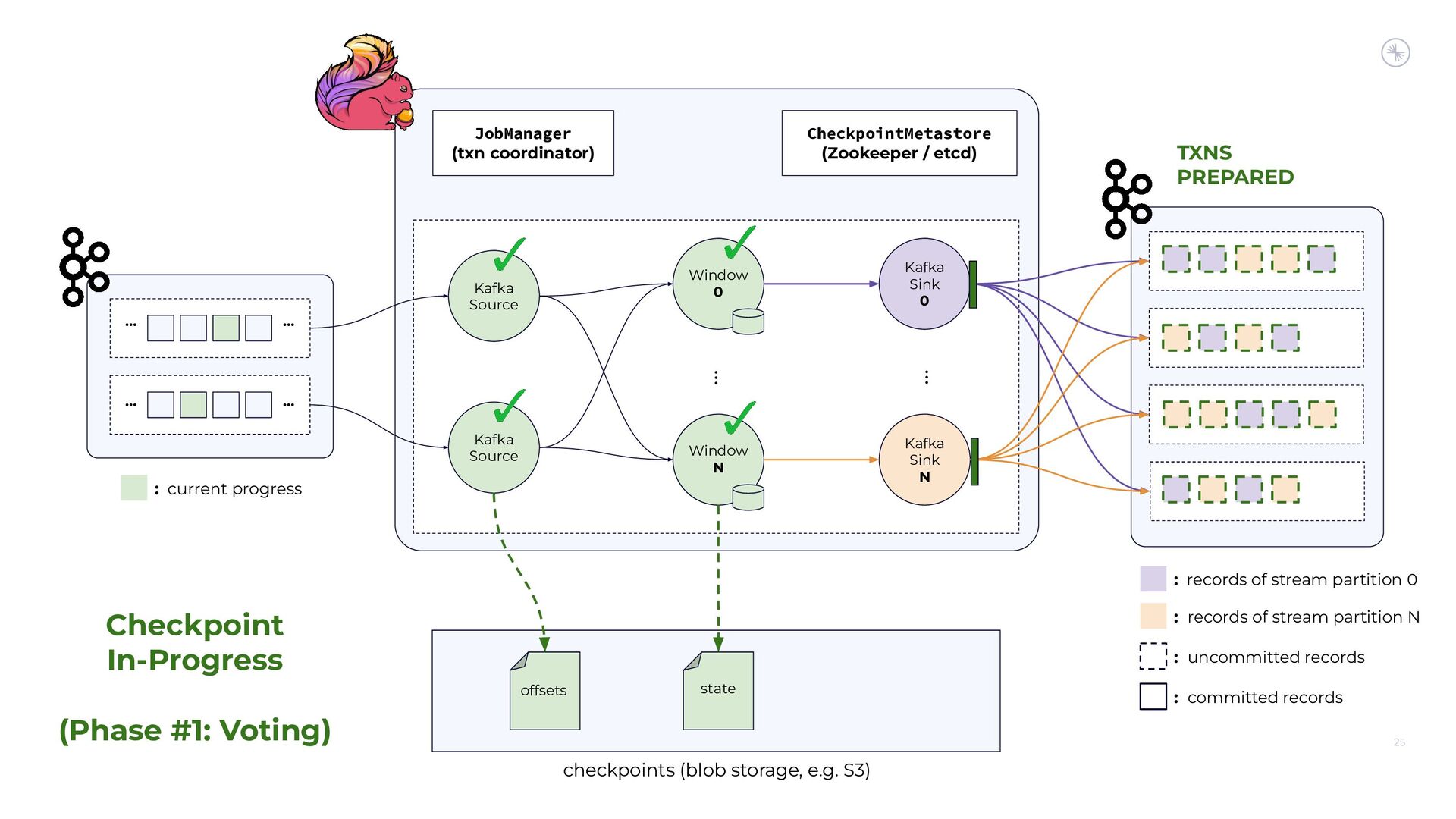{kind=link}
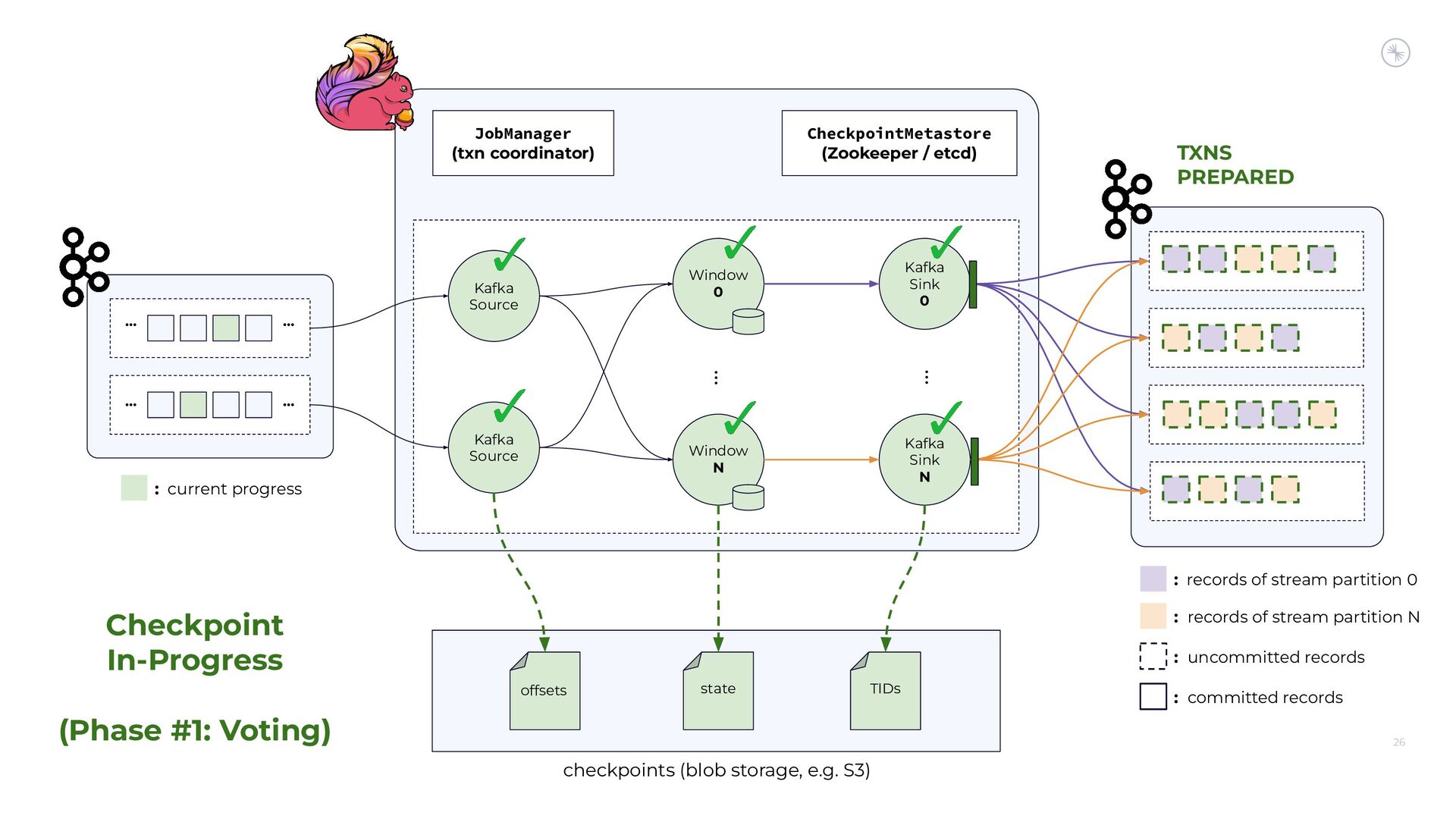{kind=link}
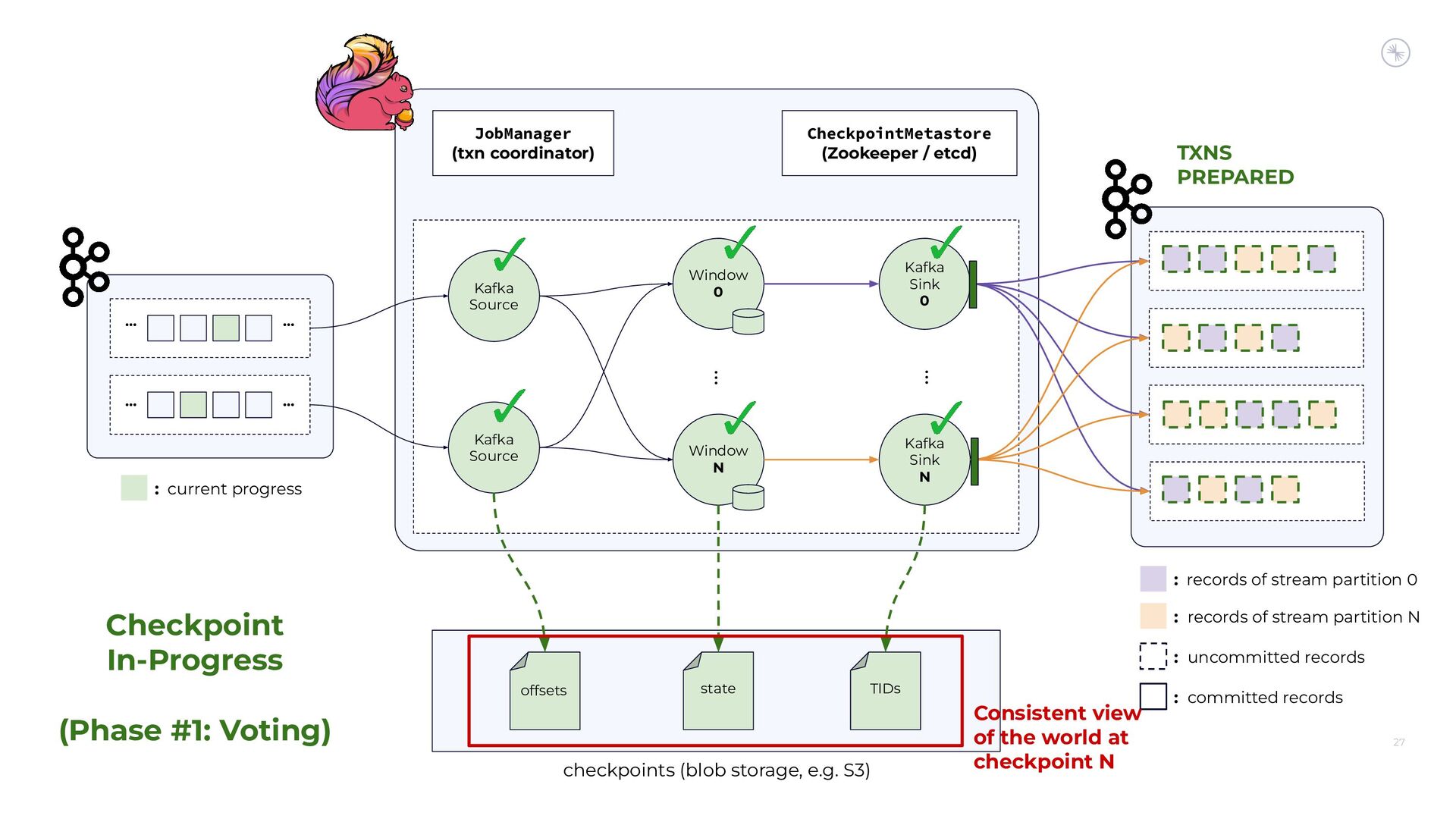{kind=link}
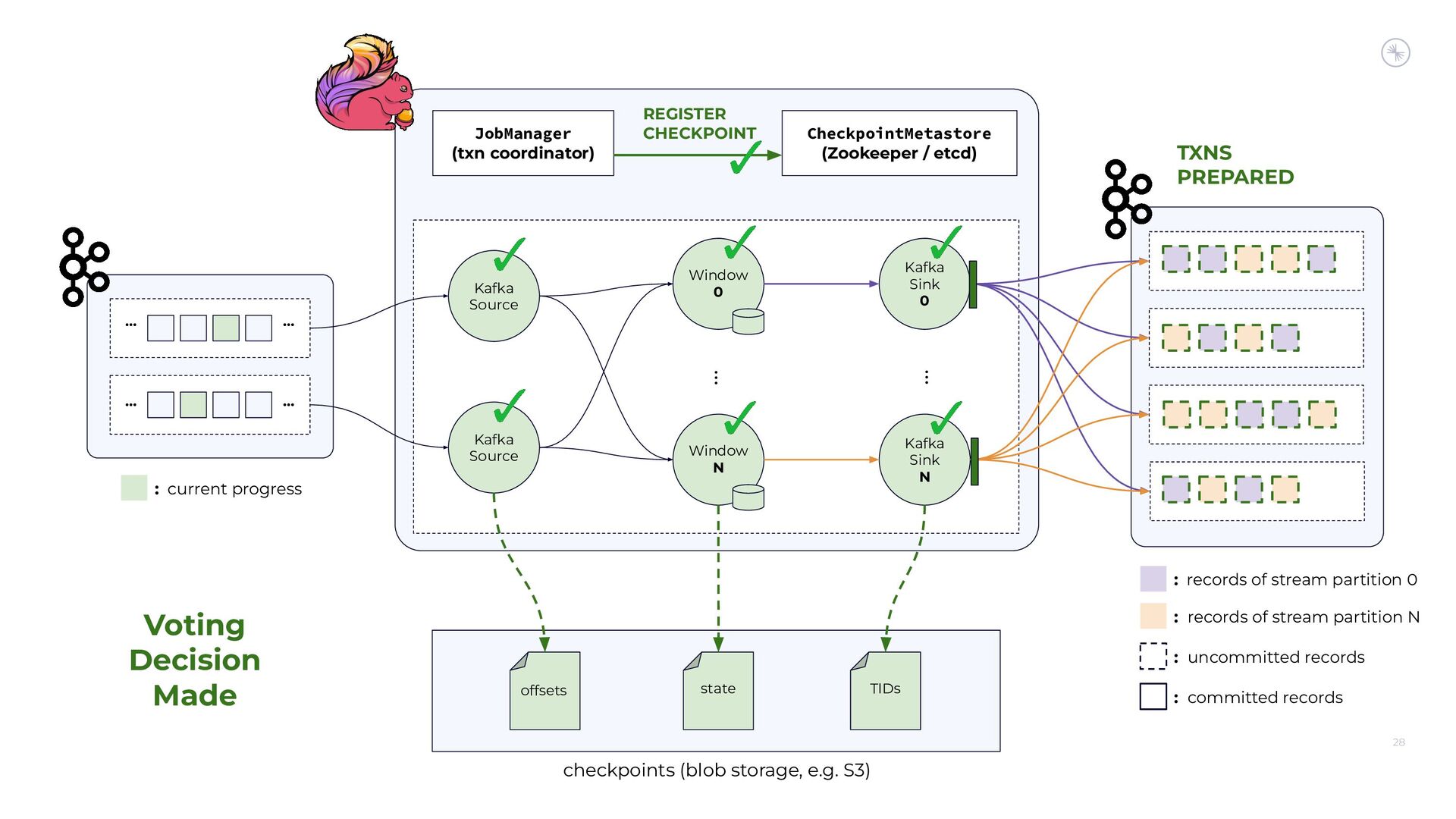{kind=link}
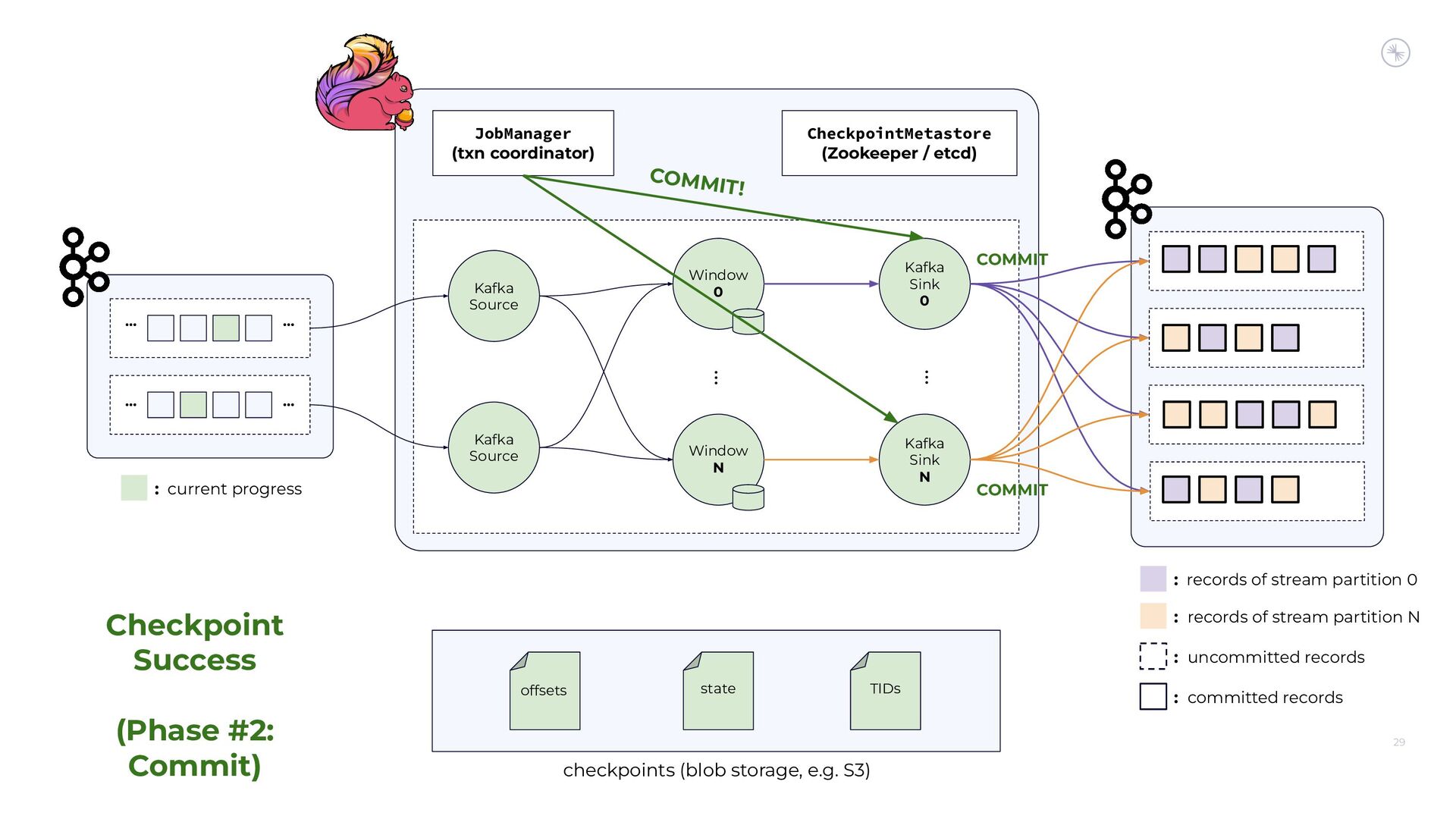{kind=link}
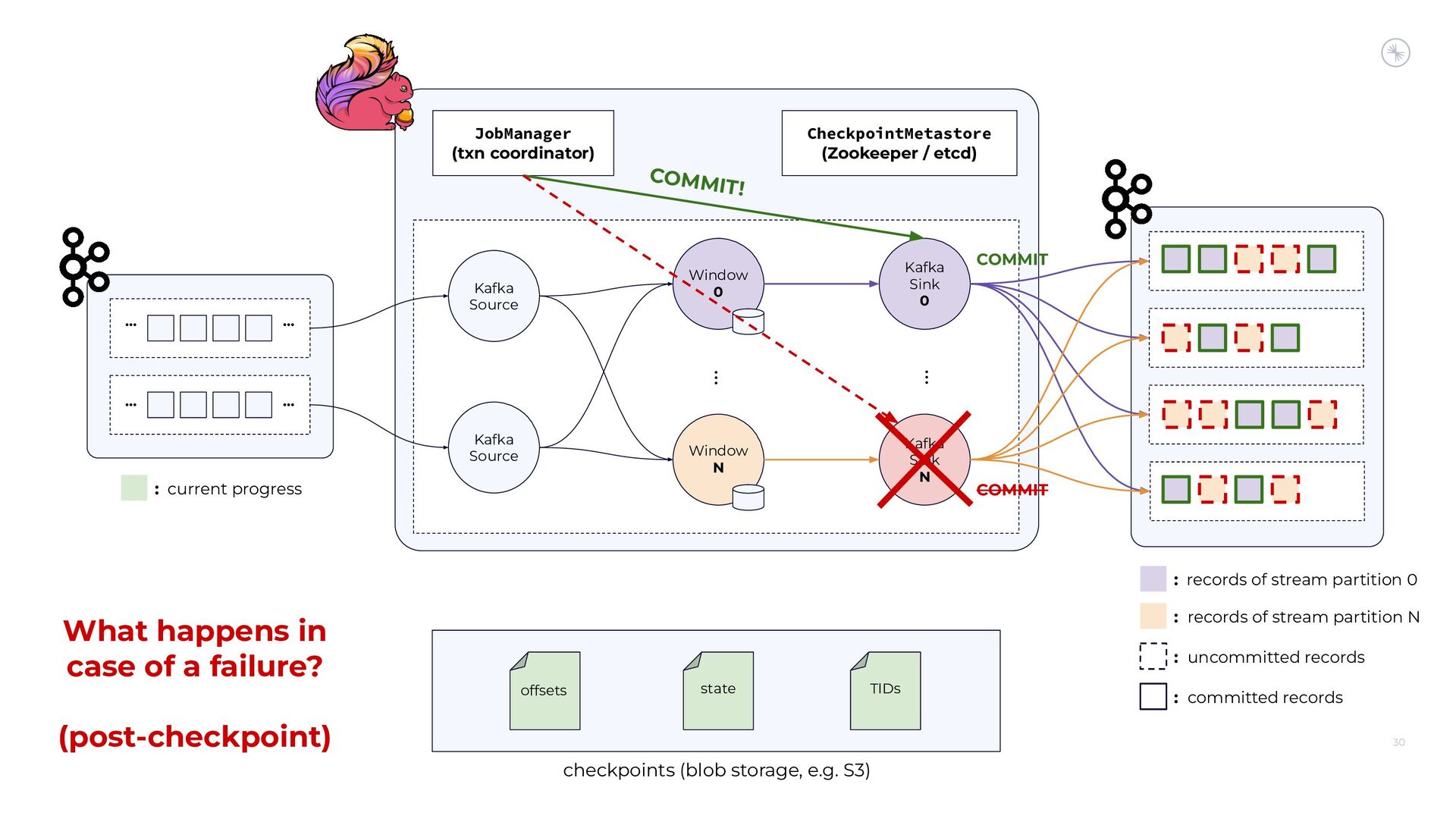{kind=link}
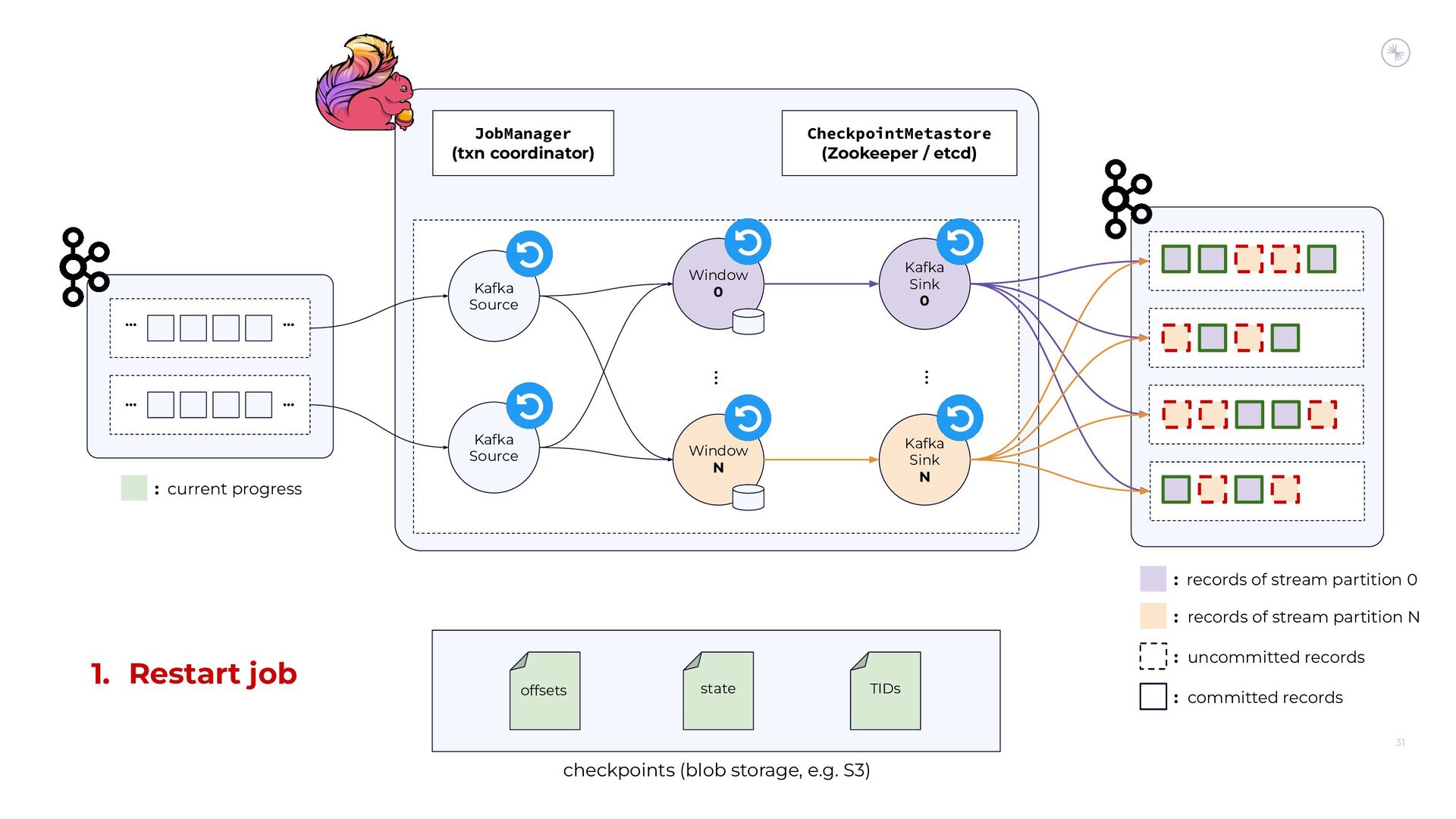{kind=link}
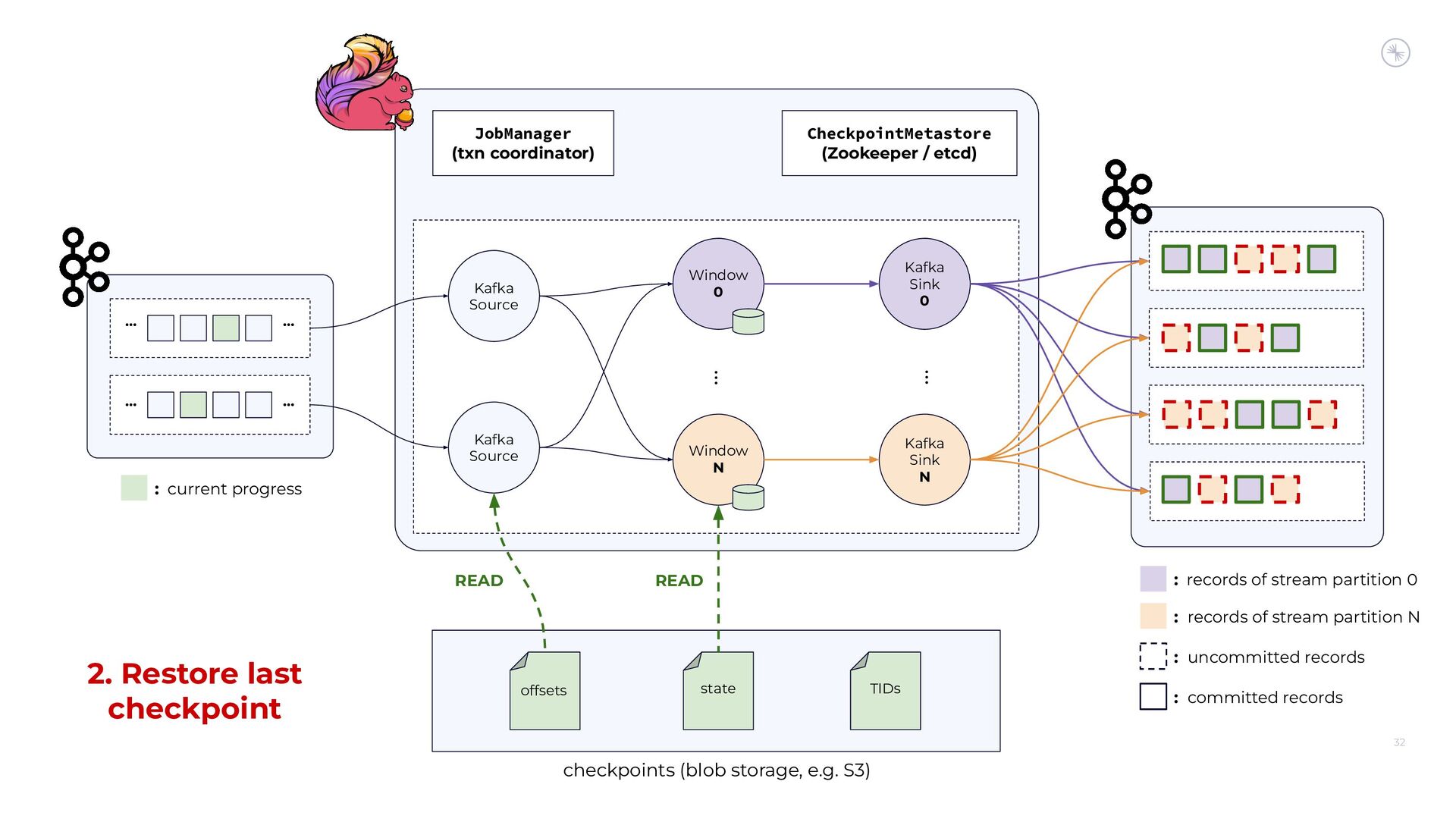{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
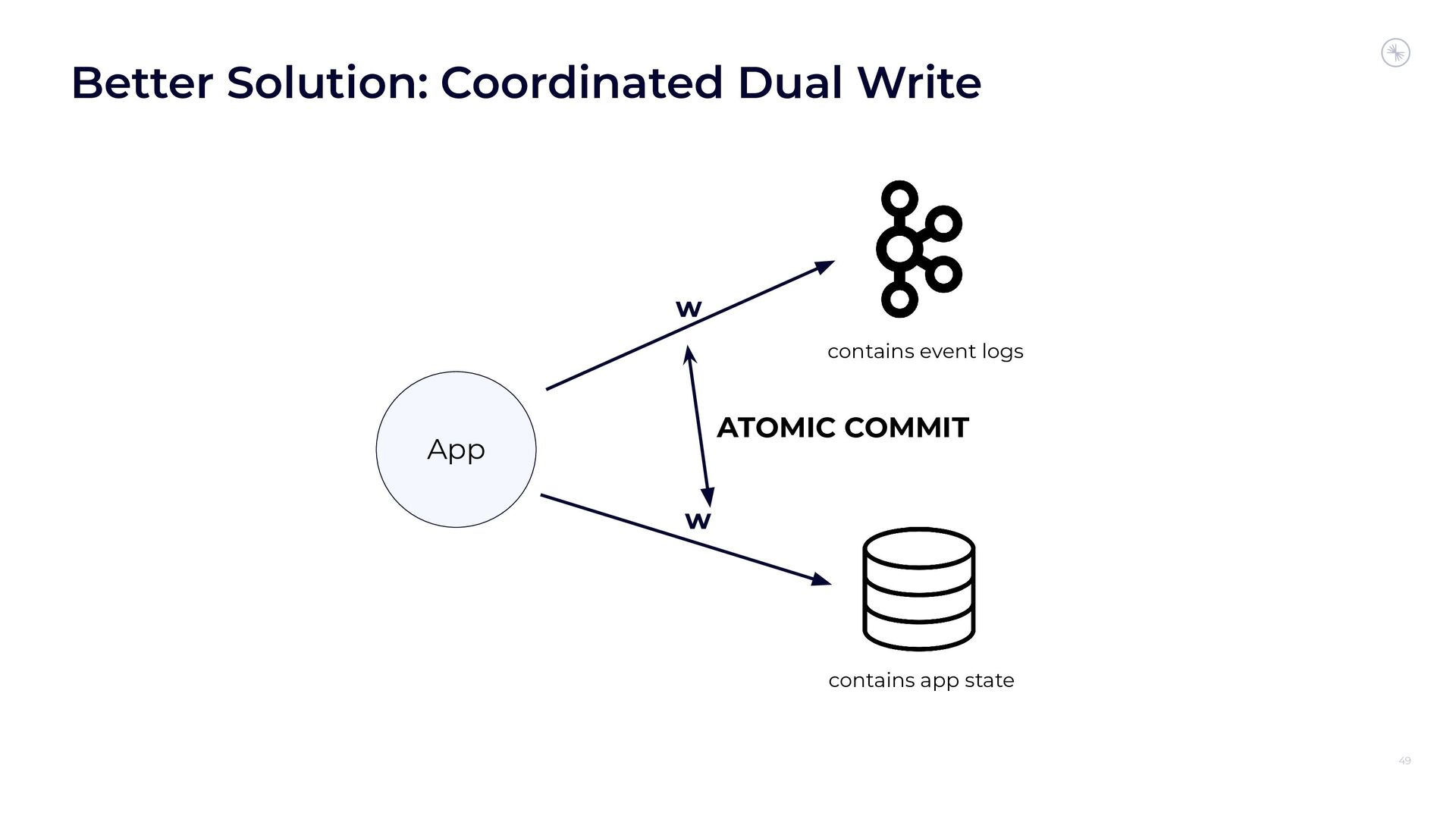{kind=link}
{kind=link}
{kind=link}
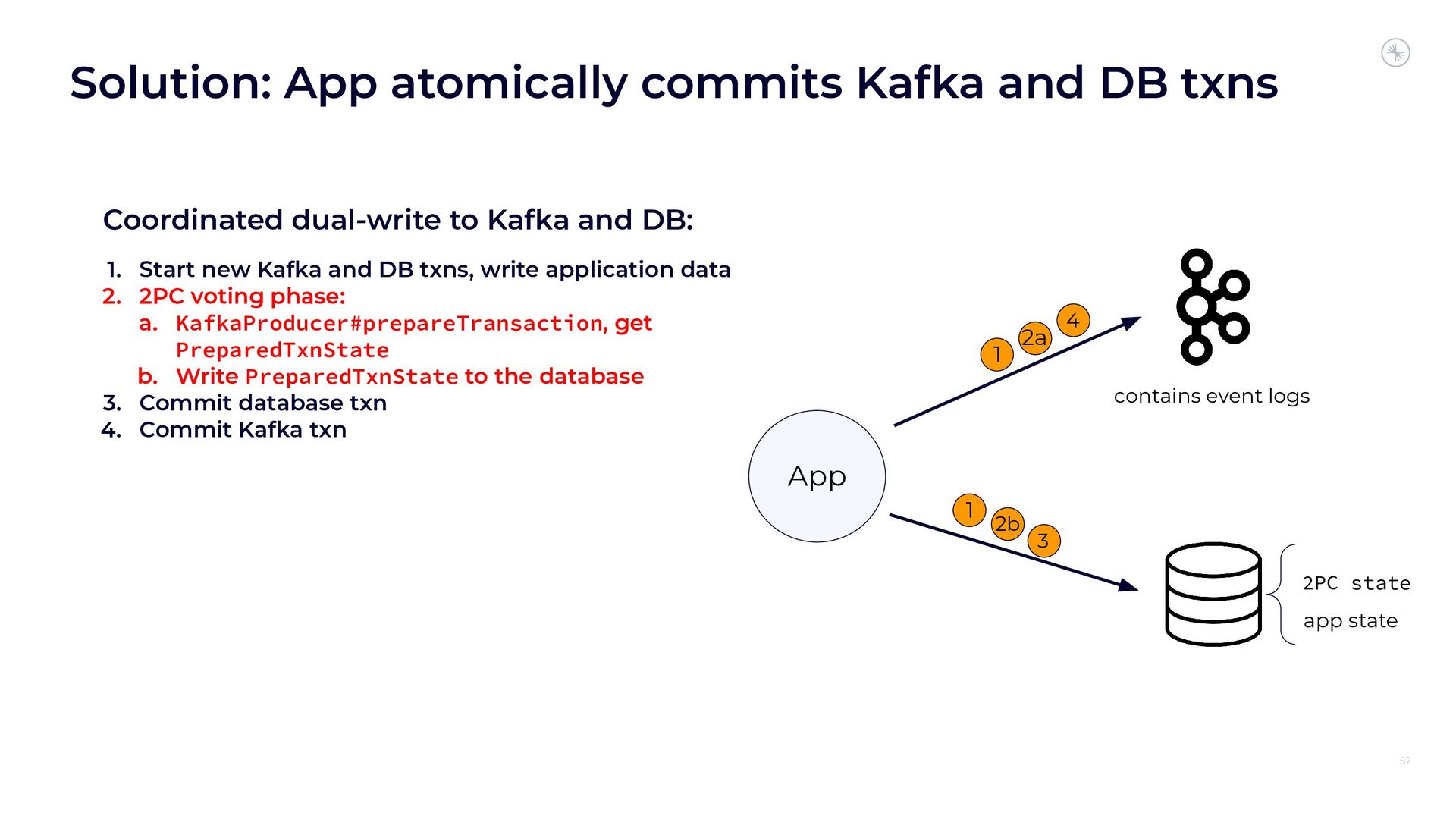{kind=link}
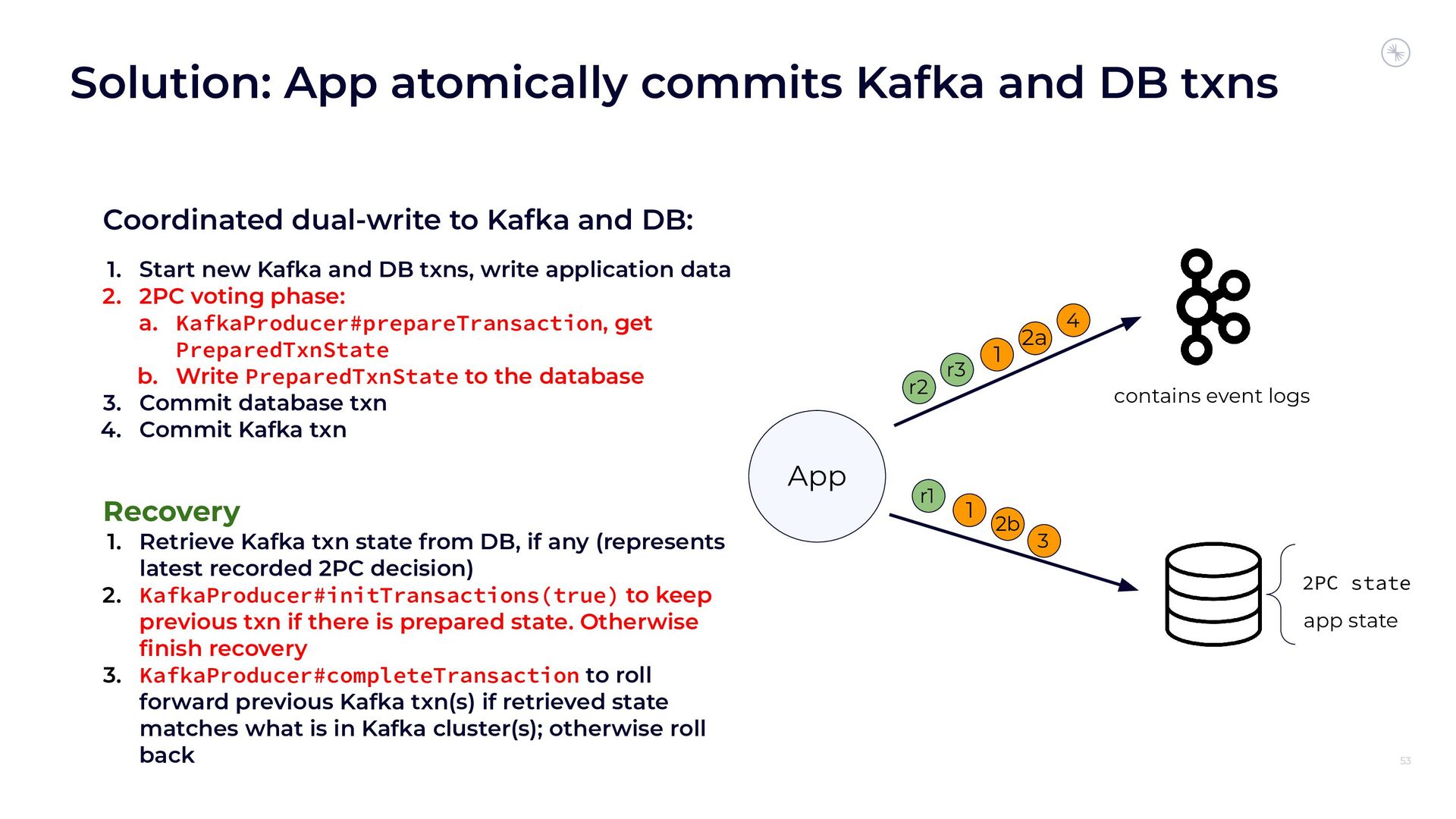{kind=link}
{kind=link}
{kind=link}
{kind=link}
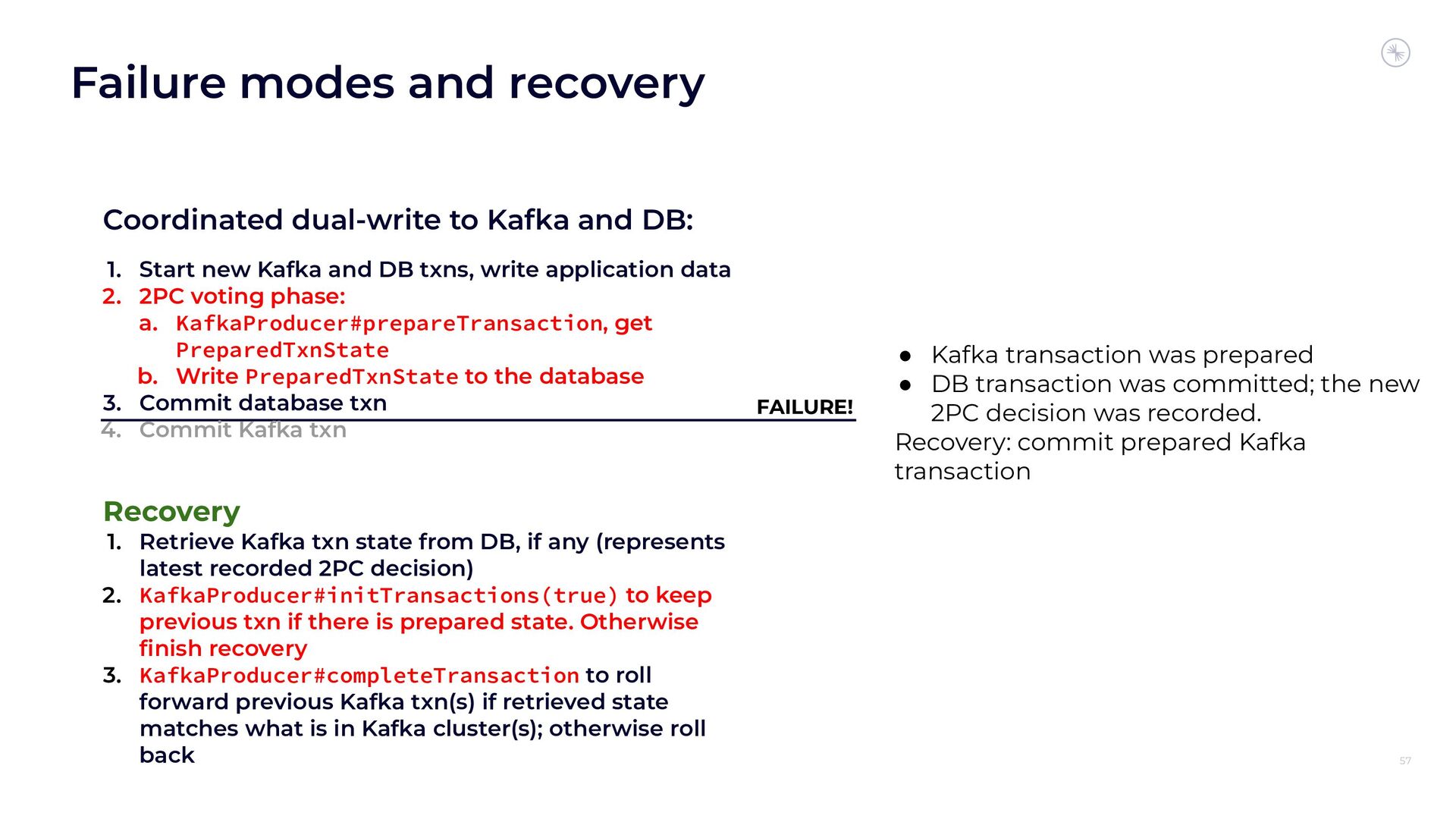{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}