CRuby committer, mainly develop parser generator and parser ✦ Lrama LALR (1) parser generator (2023, Ruby 3.3) ✦ The Bison Slayer ✦ The parser monster ✦ The dawn bringer of the parser world ✦ Ripper Rearchitecture (2024, Ruby 3.4) ✦ Code positions to RNode (2018, Ruby 2.6) ✦ RubyVM::AbstractSyntaxTree (2018, Ruby 2.6) About me
codes ✦ #1: Due to the line break, the fi rst and second lines are interpreted as distinct method calls ✦ #2: The two lines are combined into a single line of code ✦ In other words, the second code behaves as if the line break is ignored Line Breaks are the question
complete statement as a method call without arguments ✦ Therefore this code is two method calls, not a single method call with an argument ✦ The principle holds true #1: method call w/o args !=
complete statement because syntax error is raised ✦ Therefore this code is one method call with two arguments ✦ The principle holds true #2: method call w/ args == Syntax Error
Hypothesis: In principle, a statement terminates if a line break is present at a point where a statement can be complete ✦ However, are there truly no counterexamples in every part of Ruby's grammar …? No counterexamples exist …?
(TRICK), they belong to Ruby language. Ruby https://github.com/tric/trick2022/blob/master/01-tompng/entry.rb https://github.com/tric/trick2022/blob/master/06-mame/entry.rb
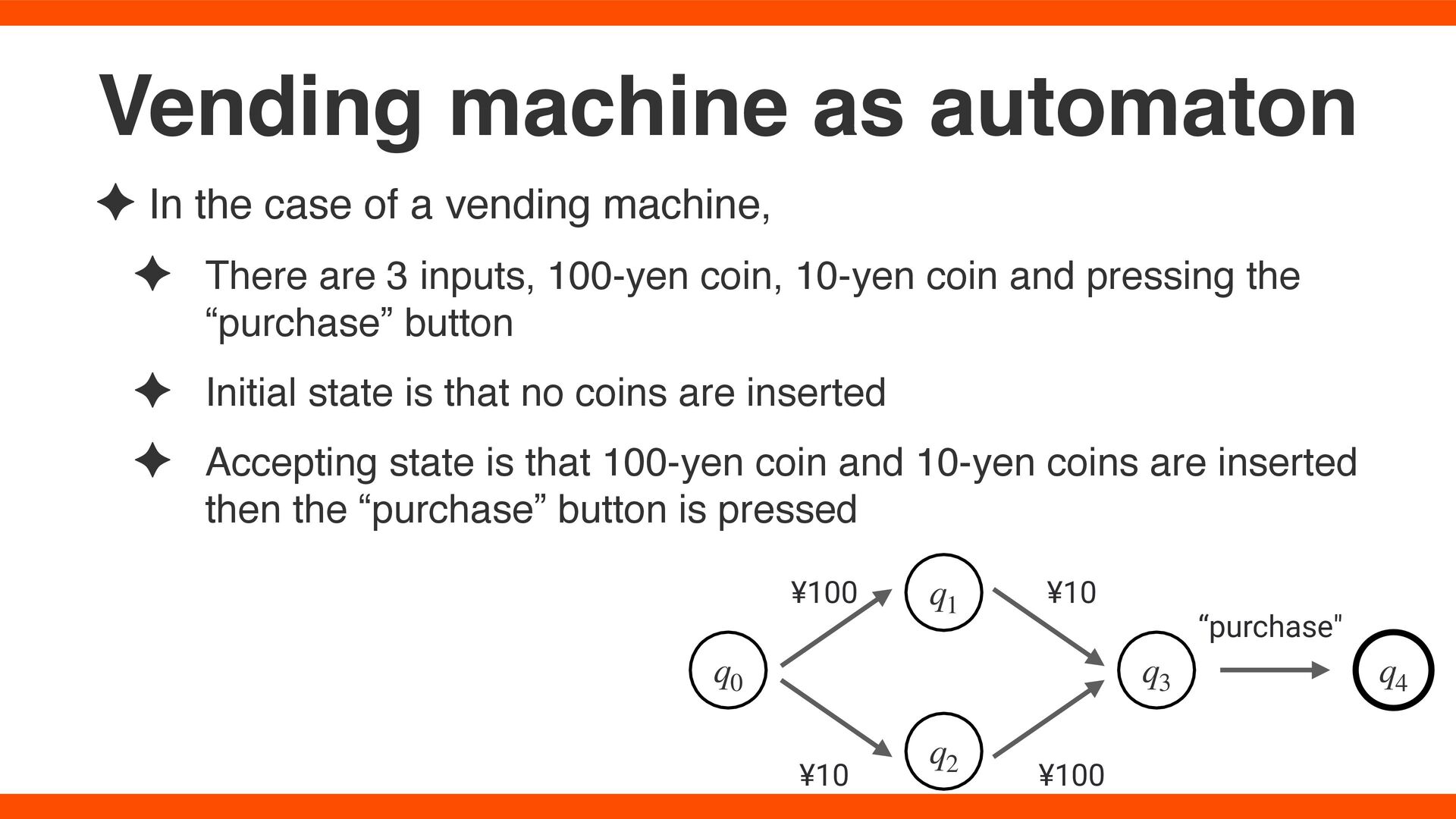
set of states ✦ is a fi nite set of input symbols ✦ is a transition function, from state to state by input symbol ✦ is an initial state ✦ is a set of accepting states (Q, Σ, δ, q0 , F) Q Σ δ q0 F What is Automaton?
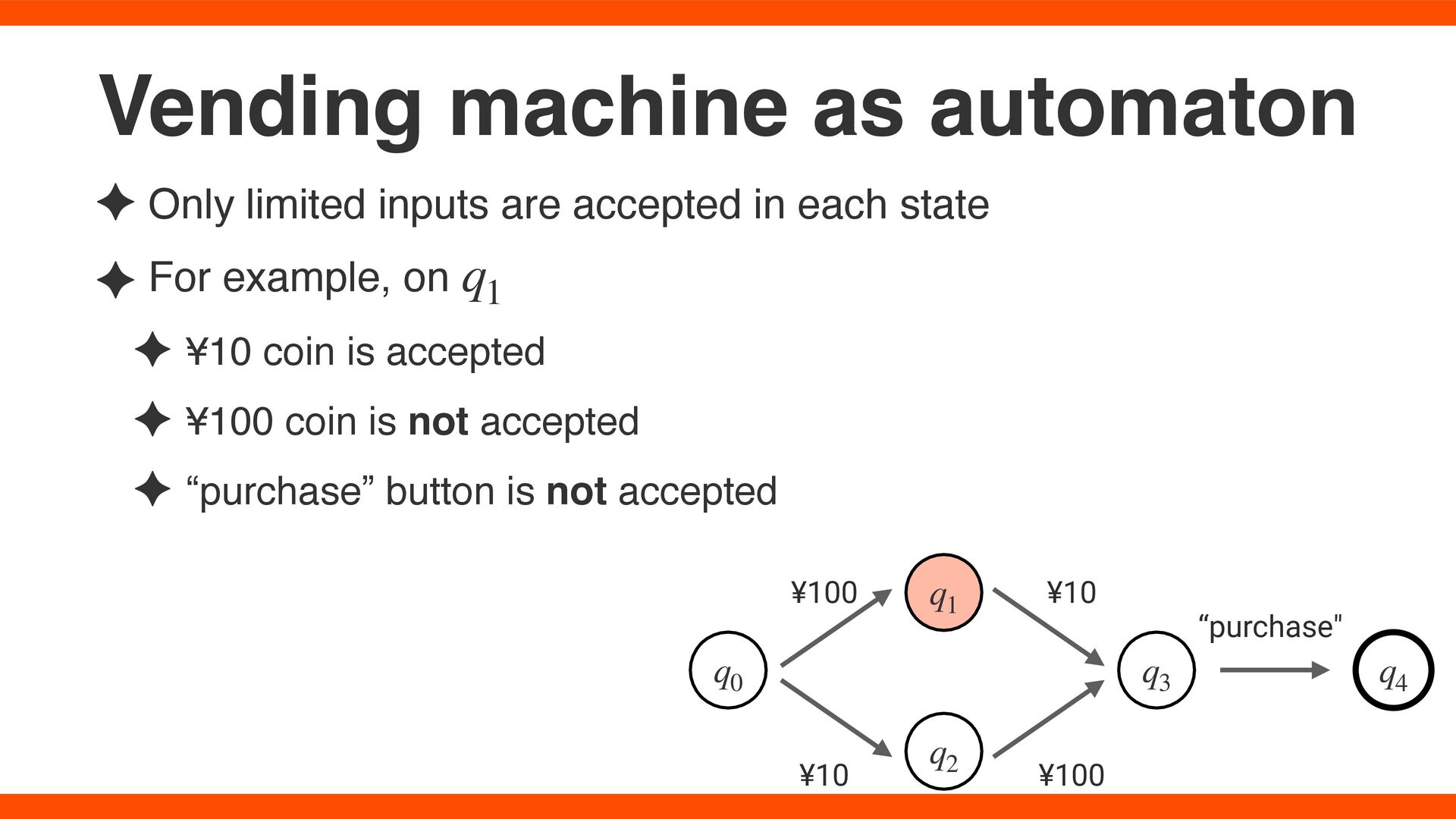
are 3 inputs, 100-yen coin, 10-yen coin and pressing the “purchase” button ✦ Initial state is that no coins are inserted ✦ Accepting state is that 100-yen coin and 10-yen coins are inserted then the “purchase” button is pressed Vending machine as automaton q0 ¥100 q1 q2 ¥10 q3 q4 ¥100 ¥10 “purchase"
For example, on ✦ ¥10 coin is accepted ✦ ¥100 coin is not accepted ✦ “purchase” button is not accepted q1 Vending machine as automaton q0 ¥100 q1 q2 ¥10 q3 q4 ¥100 ¥10 “purchase"
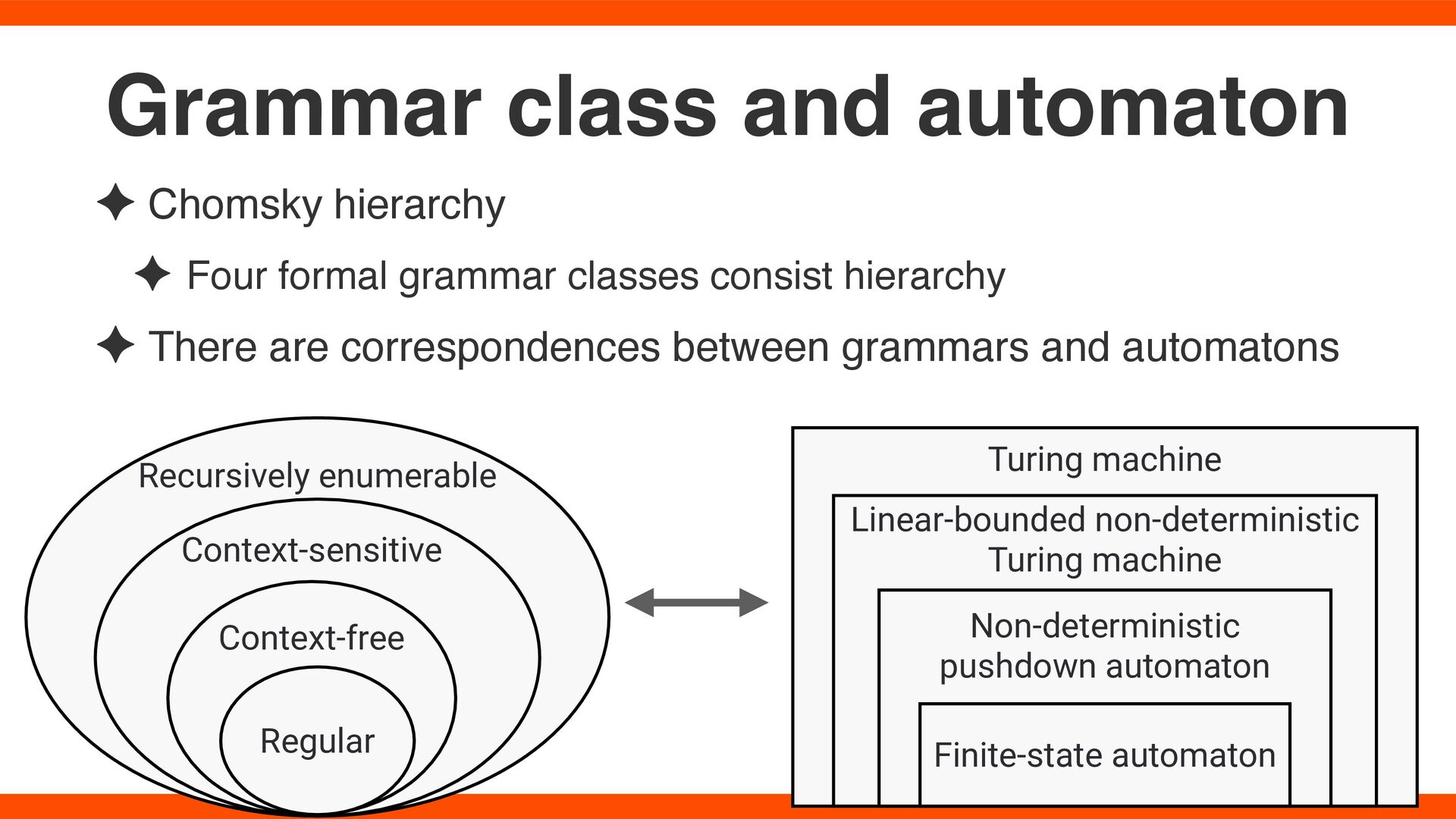
Automaton (NFA) to a Deterministic Finite Automaton (DFA) ✦ It is known that the minimum DFA is unique ✦ It's possible to combine two automata into a single automaton Theory of Automaton
class de fi nition ✦ “class”, identi fi er (id) then “end” ✦ This can be represented as an automaton with four states, taking “class” id and “end” as inputs Parser for very simple grammar class A end program : "class" id "end" P1 P2 P3 P4 class id end Grammar Language Automaton
goes to state P2 ✦ id is not accepted then syntax error ✦ “end” is not accepted then syntax error How the parser works program : "class" id "end" P1 P2 P3 P4 class id end Grammar Automaton
then syntax error ✦ id is accepted then goes to state P3 ✦ “end” is not accepted then syntax error How the parser works program : "class" id "end" P1 P2 P3 P4 class id end Grammar Automaton
then syntax error ✦ id is not accepted then syntax error ✦ “end” is not accepted then syntax error ✦ End of Input is accepted then the parsing process completed without errors How the parser works program : "class" id "end" P1 P2 P3 P4 class id end Grammar Automaton
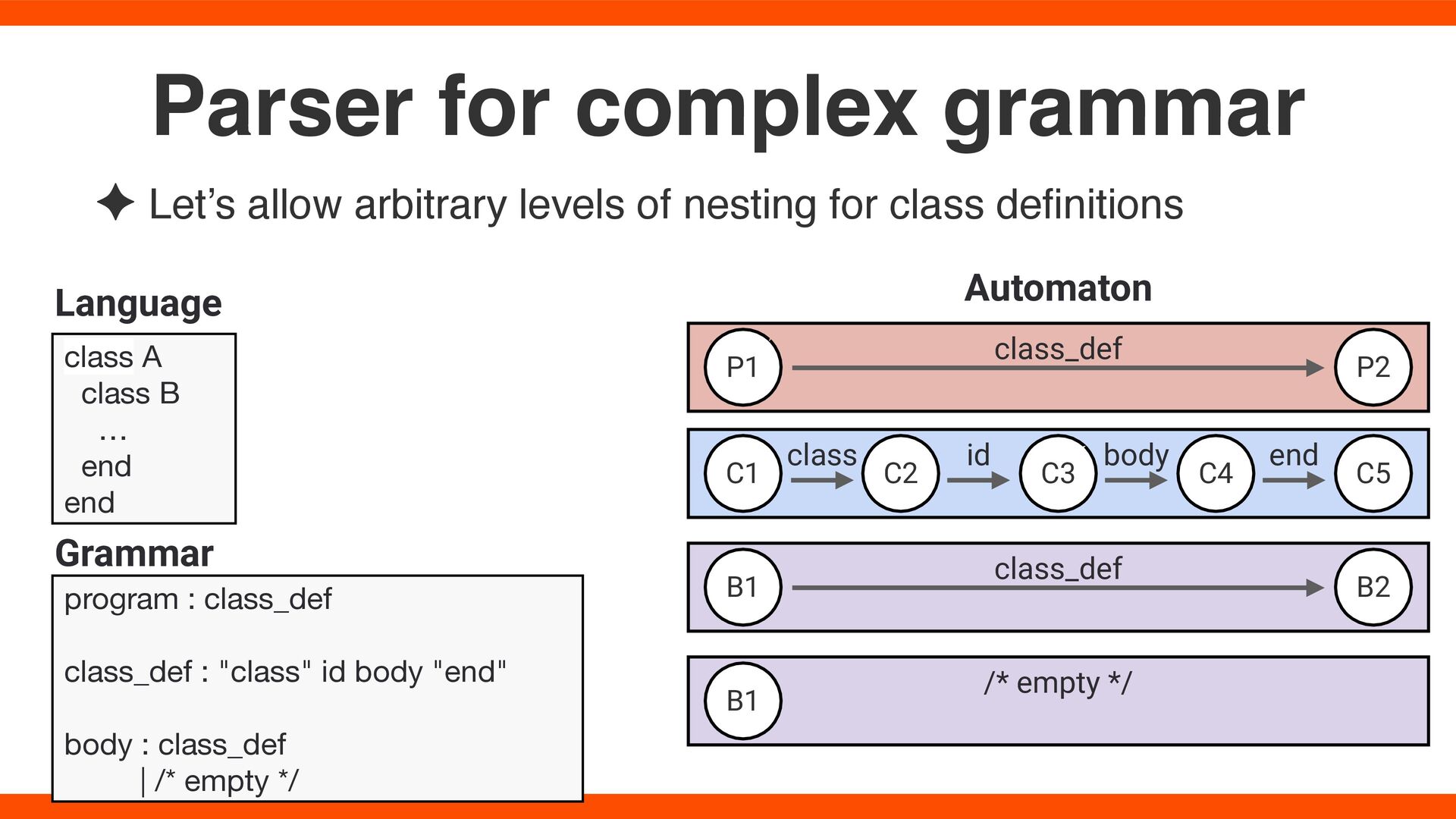
fi nitions Parser for complex grammar class A class B … end end program : class_def class_def : "class" id body "end" body : class_def | /* empty */ Grammar Language Automaton B1 B2 C1 C2 C3 C5 P1 P2 class_def class_def C4 class id body end B1 /* empty */
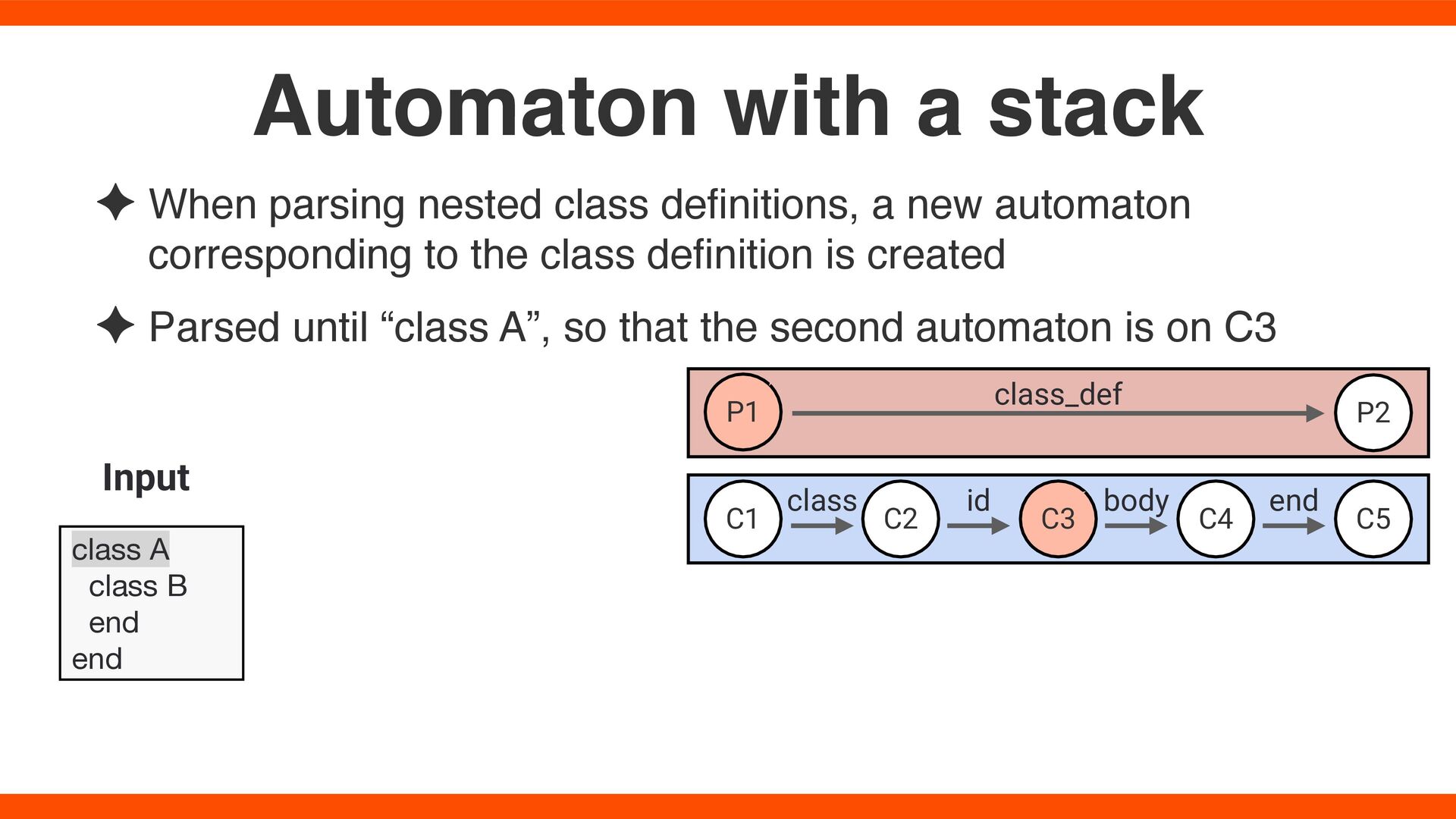
automaton corresponding to the class de fi nition is created ✦ Parsed until “class A”, so that the second automaton is on C3 Automaton with a stack class A class B end end Input C1 C2 C3 C5 P1 P2 class_def C4 class id body end
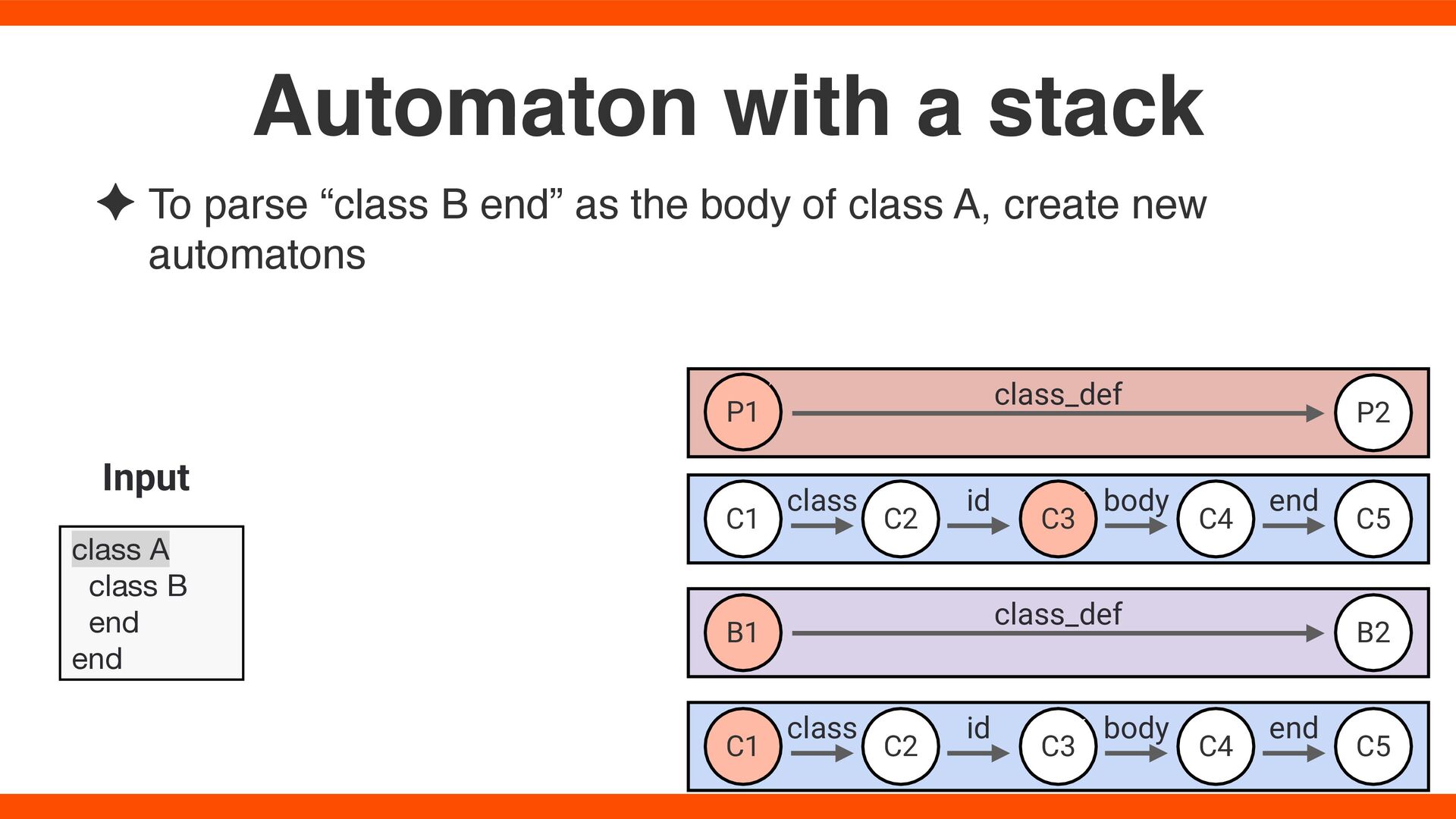
class A, create new automatons Automaton with a stack class A class B end end Input B1 B2 C1 C2 C3 C5 P1 P2 class_def class_def C4 class id body end C1 C2 C3 C5 C4 class id body end
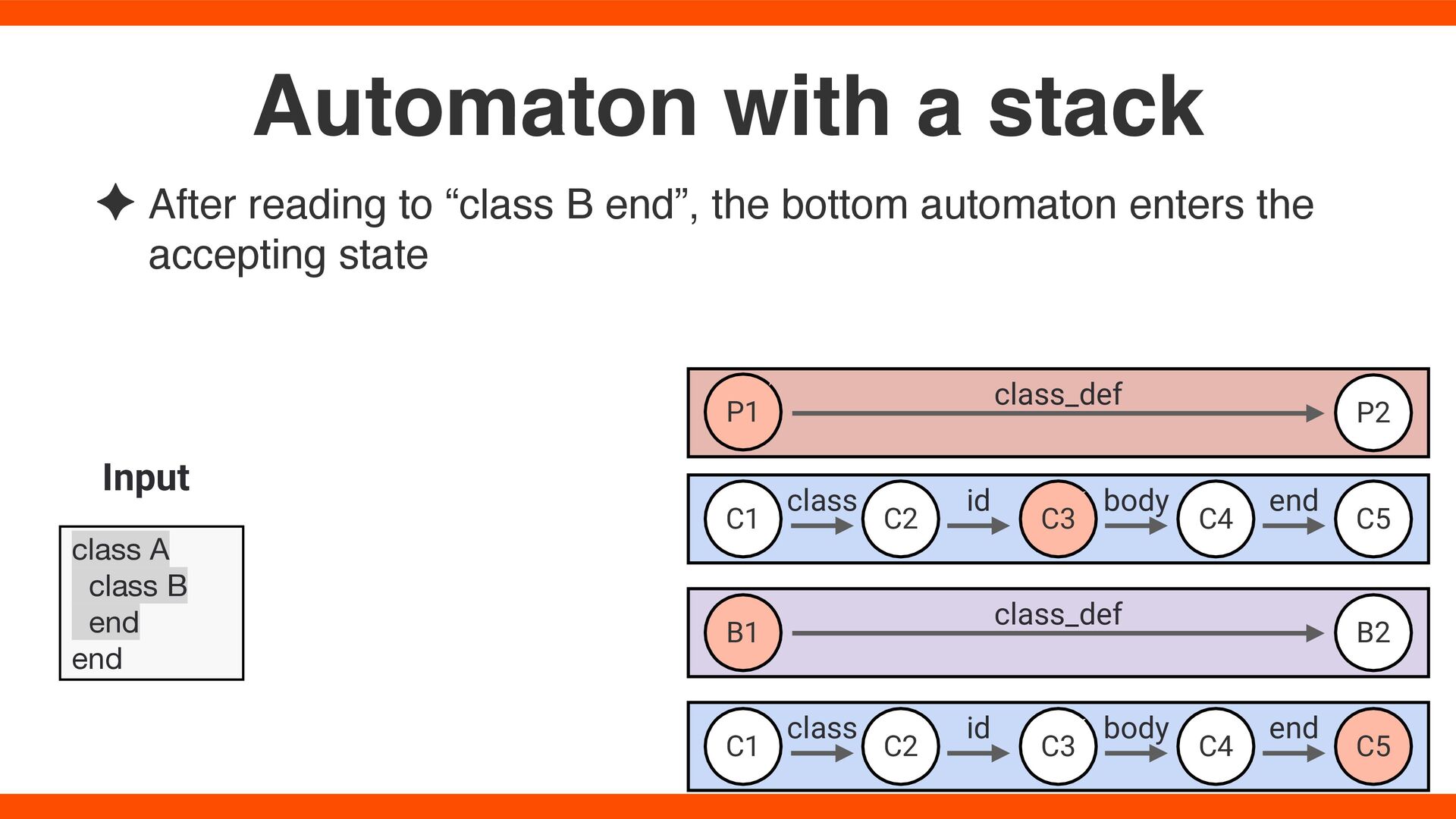
enters the accepting state Automaton with a stack class A class B end end Input B1 B2 C1 C2 C3 C5 P1 P2 class_def class_def C4 class id body end C1 C2 C3 C5 C4 class id body end
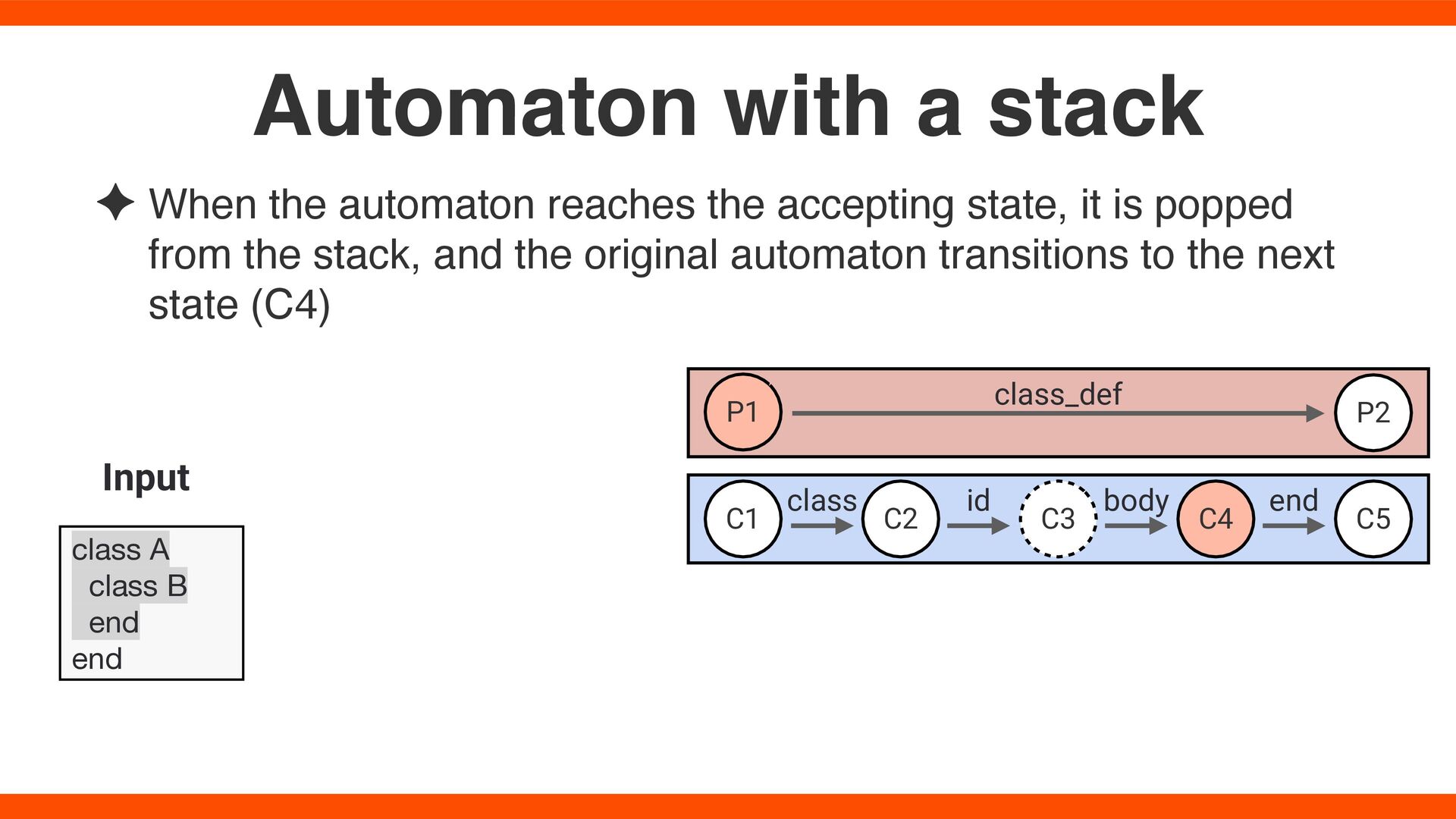
popped from the stack, and the original automaton transitions to the next state (C4) Automaton with a stack class A class B end end Input C1 C2 C3 C5 P1 P2 class_def C4 class id body end
“class”, id, and “end” as input ✦ A fi nite automaton with a stack is called a pushdown automaton ✦ By using a stack, pushdown automaton can handle languages with in fi nite nesting ✦ Implementation of LR parser is pushdown automaton LR Parser as pushdown automaton
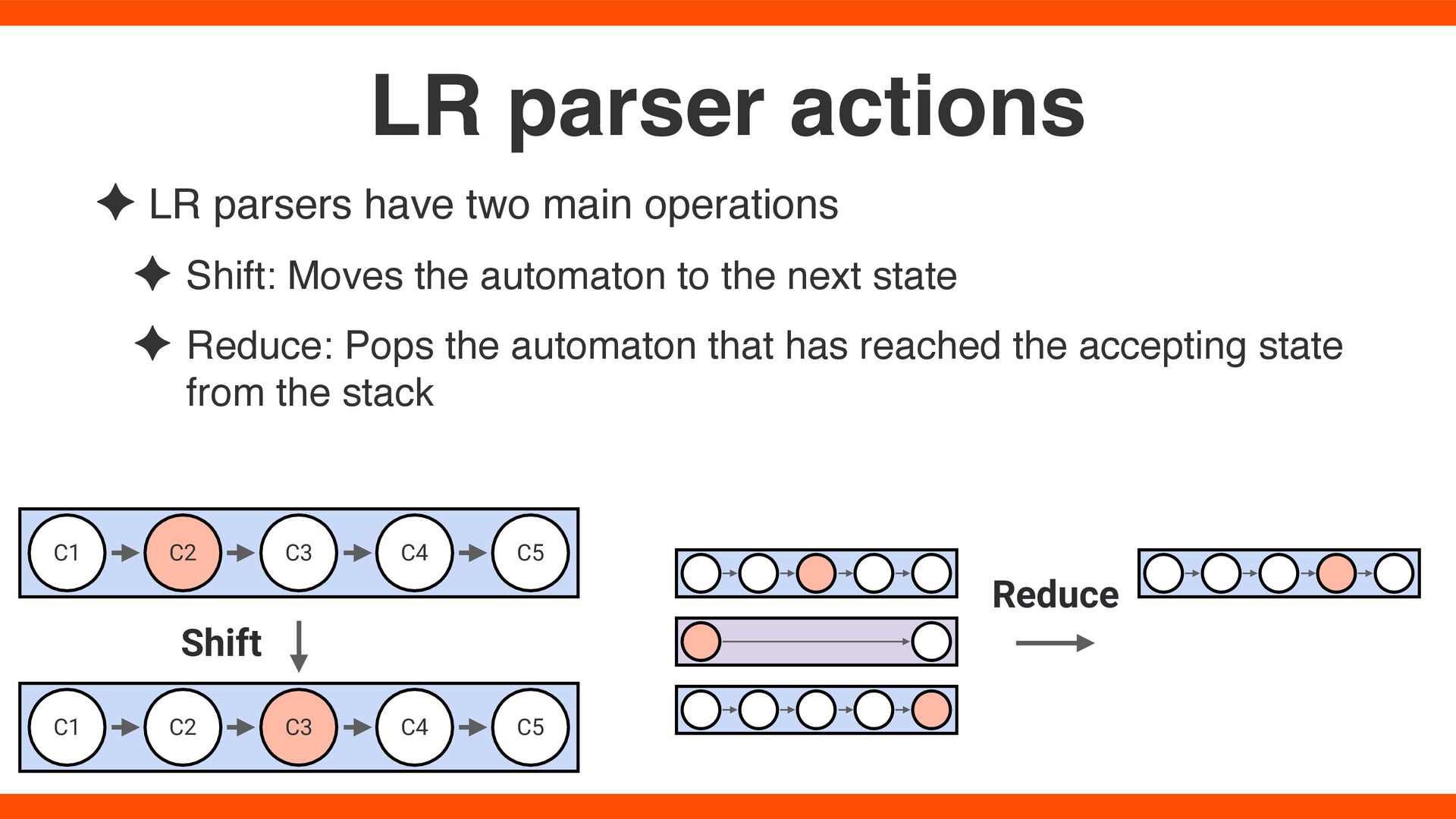
the automaton to the next state ✦ Reduce: Pops the automaton that has reached the accepting state from the stack LR parser actions C1 C2 C3 C5 C4 C1 C2 C3 C5 C4 Shift Reduce
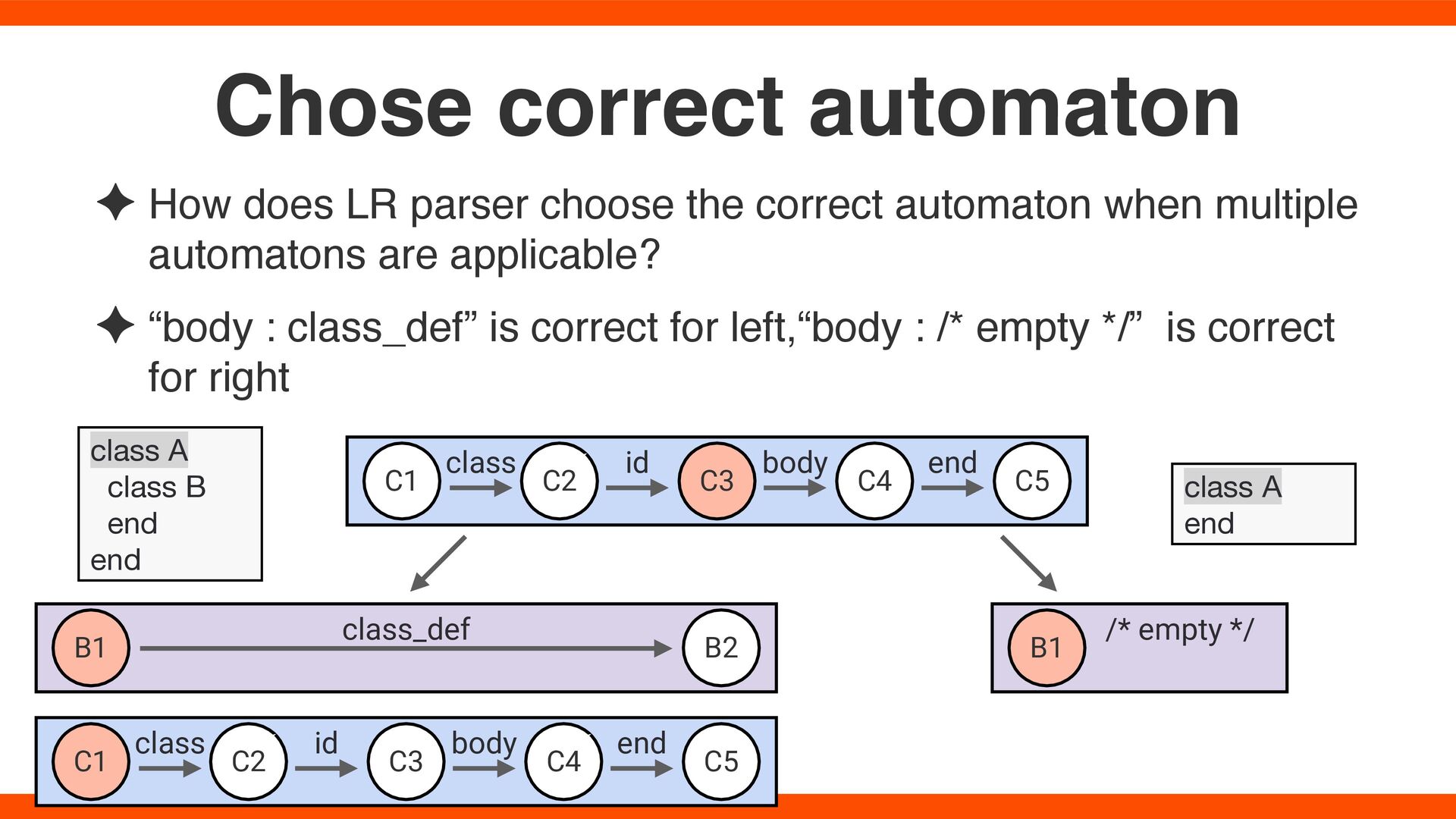
multiple automatons are applicable? ✦ “body : class_def” is correct for left,“body : /* empty */” is correct for right Chose correct automaton class A end B1 B2 C1 C2 C3 C5 class_def C4 class id body end C1 C2 C3 C5 C4 class id body end class A class B end end B1 /* empty */
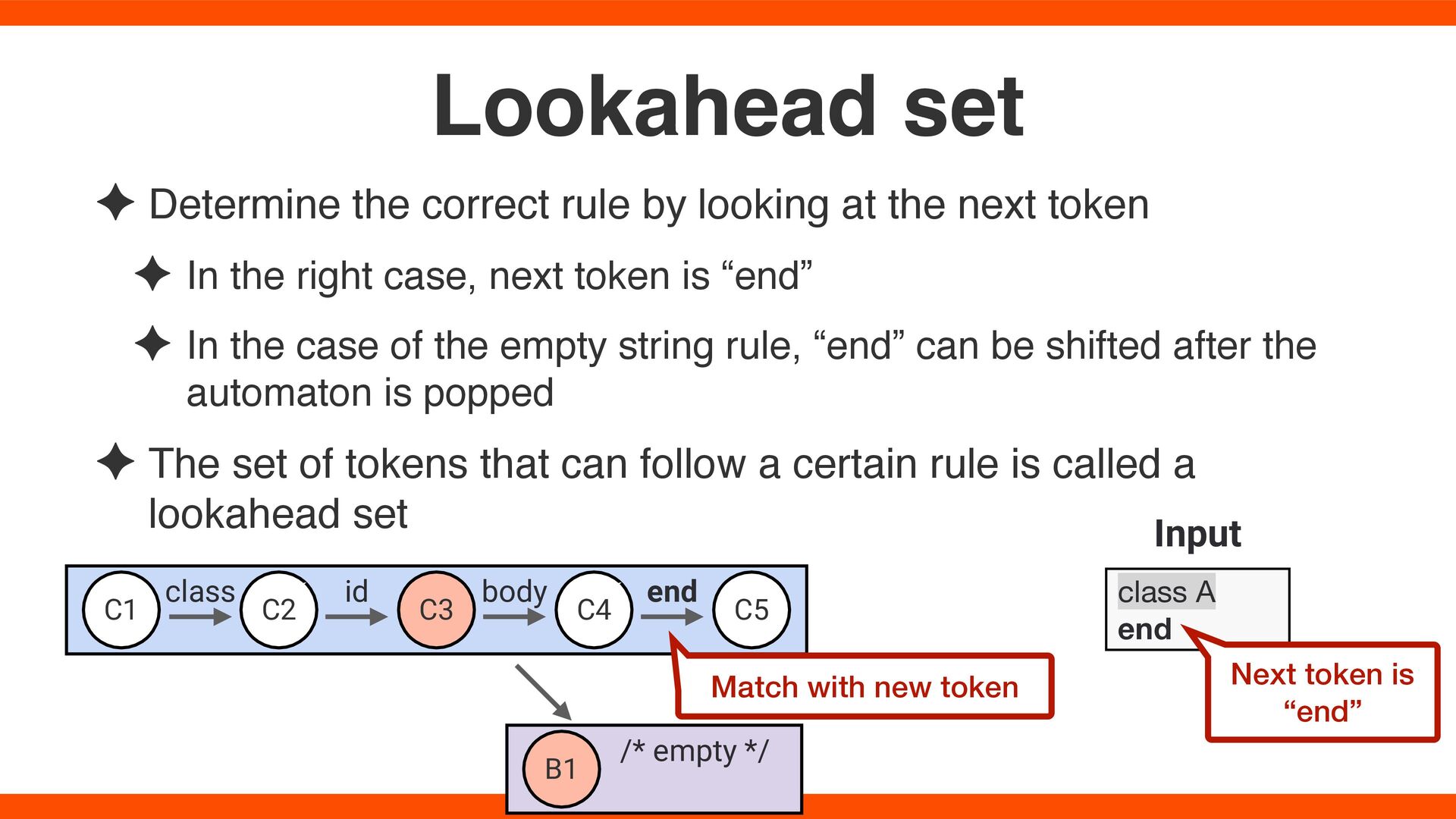
token ✦ In the right case, next token is “end” ✦ In the case of the empty string rule, “end” can be shifted after the automaton is popped ✦ The set of tokens that can follow a certain rule is called a lookahead set Lookahead set class A end C1 C2 C3 C5 C4 class id body end B1 /* empty */ Next token is “end” Match with new token Input
✦ There are correspondences between grammars and automatons Grammar class and automaton Regular Context-free Context-sensitive Recursively enumerable Linear-bounded non-deterministic Turing machine Non-deterministic pushdown automaton Finite-state automaton Turing machine
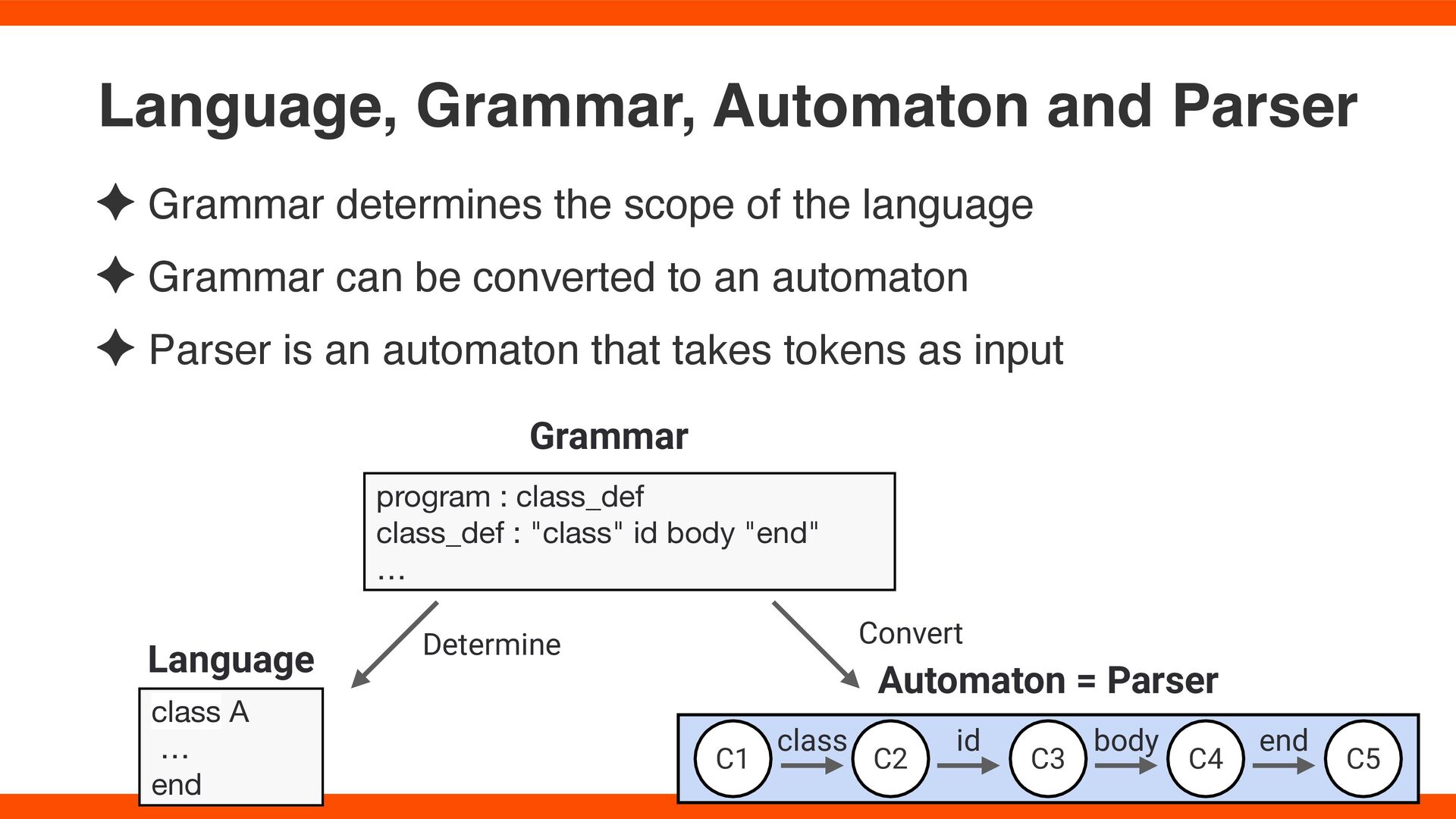
can be converted to an automaton ✦ Parser is an automaton that takes tokens as input Language, Grammar, Automaton and Parser class A … end program : class_def class_def : "class" id body "end" … Grammar Language Automaton = Parser C1 C2 C3 C5 C4 class id body end Determine Convert
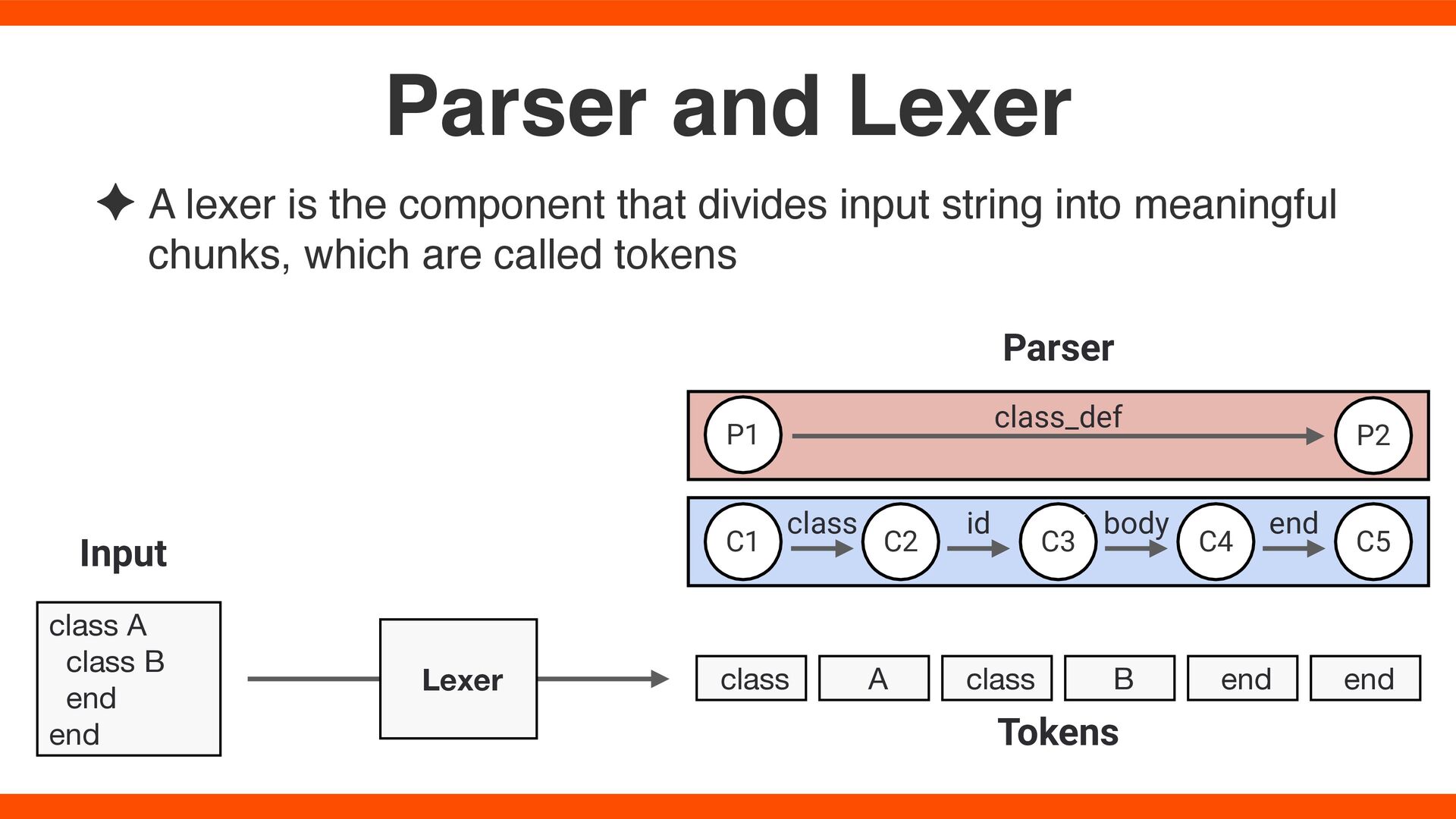
into meaningful chunks, which are called tokens Parser and Lexer C1 C2 C3 C5 P1 P2 class_def C4 class id body end class A class B end end Input class A class B end end Tokens Parser Lexer
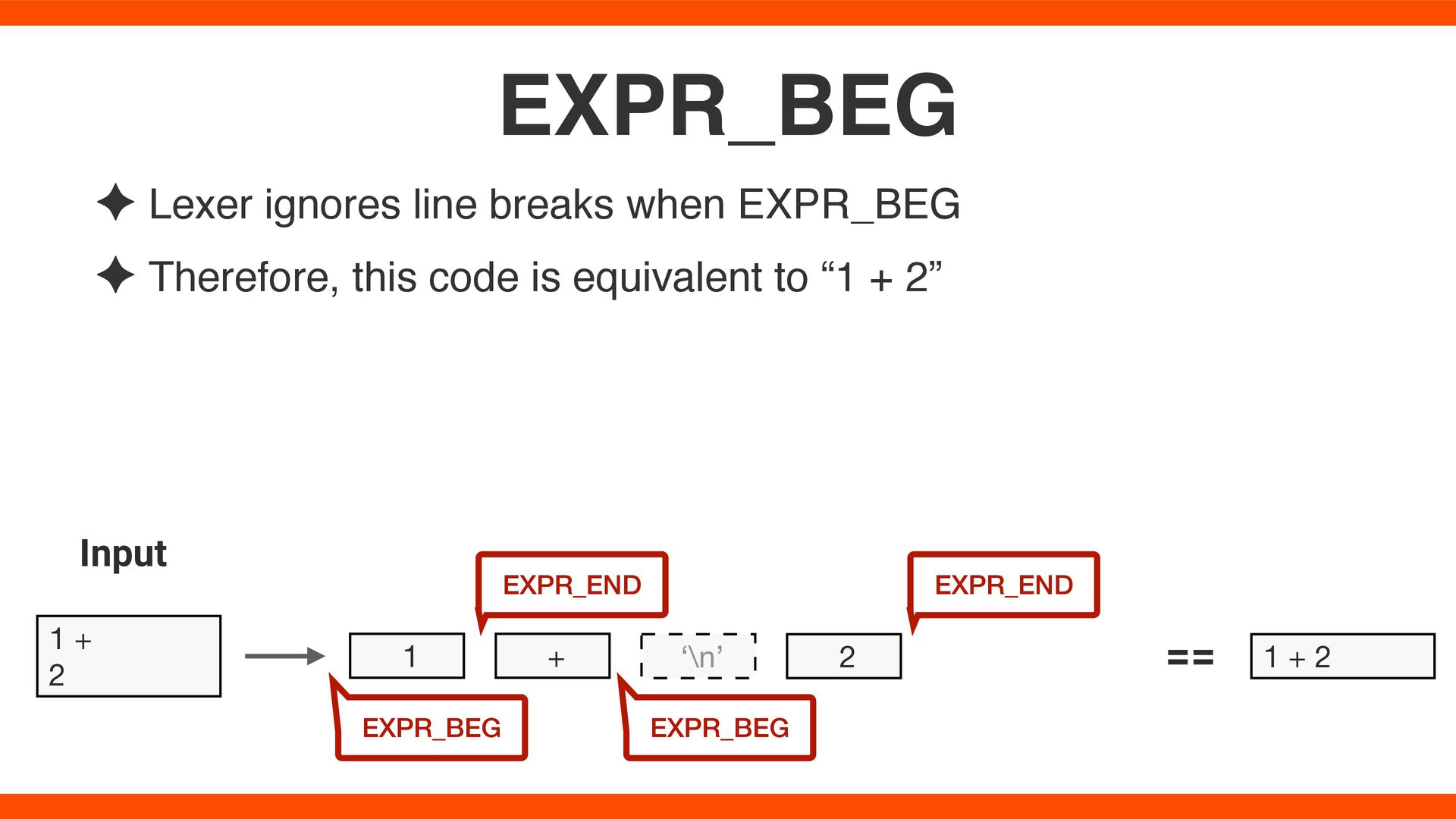
line breaks, sometimes ignoring them and sometimes not #1: Lexer ignores Line Breaks method_1 arg 1 + 2 Input method_1 ‘\n’ arg 1 + 2 Tokens Not ignored Ignored
of expression ✦ EXPR_END: END of expression ✦ EXPR_ENDARG: END of ARGument ✦ EXPR_ENDFN: END of Function NAME ✦ EXPR_ARG: ARGument ✦ EXPR_CMDARG: CoMmanD ARGument ✦ EXPR_MID: MIDdle of expression ✦ EXPR_FNAME: immediate after “def” keyword, might be Function NAME ✦ EXPR_DOT: immediate after DOT (dot includes ‘.’ ‘&.’ ‘::’) ✦ EXPR_CLASS: immediate after “class” keyword ✦ EXPR_LABEL: label is possible, label is `a:` ✦ EXPR_LABELED: immediate after label ✦ EXPR_FITEM: just before fi tem. fi tem is token after undef or alias ✦ Only written the typical meanings, there are also exceptions They are lex state fl ags !
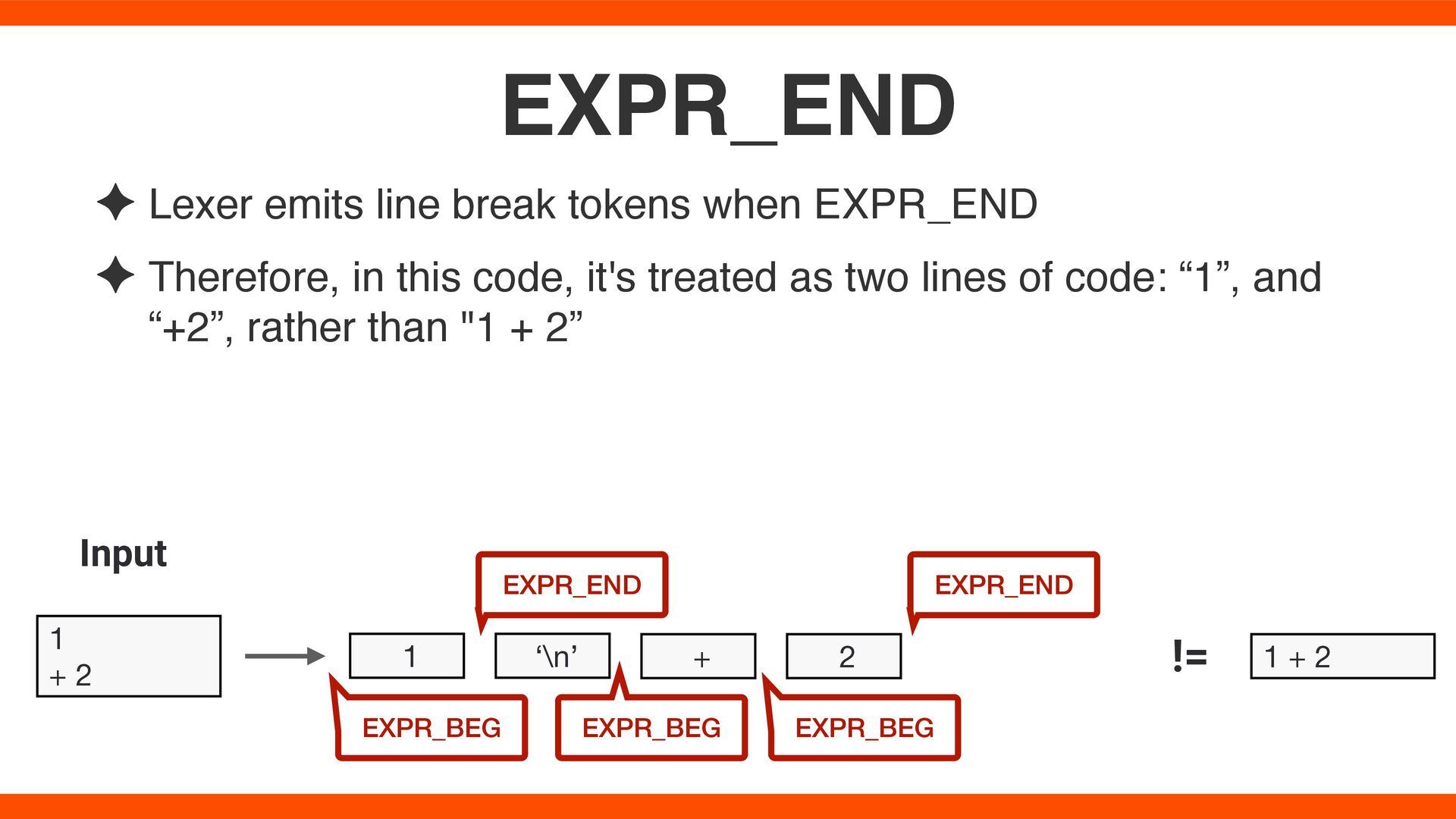
in this code, it's treated as two lines of code: “1”, and “+2”, rather than "1 + 2” EXPR_END 1 + 2 Input 1 ‘\n’ 2 EXPR_BEG EXPR_END EXPR_BEG EXPR_END 1 + 2 != + EXPR_BEG
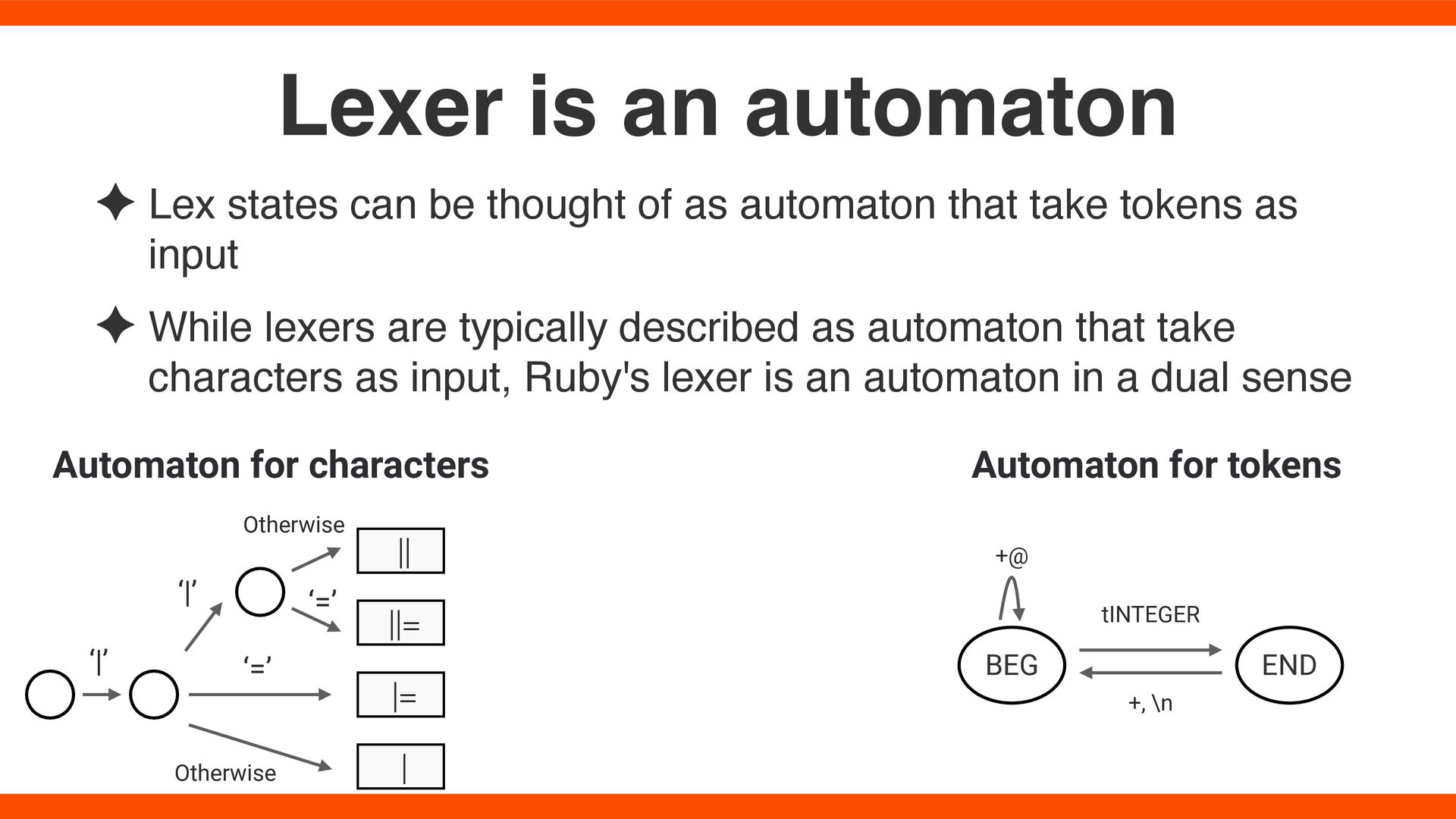
take tokens as input ✦ While lexers are typically described as automaton that take characters as input, Ruby's lexer is an automaton in a dual sense Lexer is an automaton Automaton for characters ‘|’ ‘|’ ‘=’ |= || | ||= Otherwise ‘=’ Otherwise Automaton for tokens BEG END tINTEGER +, \n +@
are situations where that doesn't work ✦ Lex state is EXPR_END after “arg” then lexer emits line breaks ✦ For example, “1+ 2” is “arg” ✦ In such cases, need to write line break token in the grammar #2: Grammar allows Line Breaks ‘\n’ is needed in grammar rules EXPR_END EXPR_END
we can maintain this… ✦ Then I asked other committers what they think about lex state ✦ “This is impossible to understand, isn't it?” by usa ✦ “I'm keeping my distance because it's scary” by ko1 ✦ “It's hard to believe anyone could completely understand and work with all of lex state” by akr Monstrous Lex state
on the script's reading position that it seems beyond human comprehension. How could we describe this poetically or in a literary sense? Q&A session with Gemini
fl ow of Qi within the code” ✦ Reason: An unseen force that forms the semantic fl ow and structure of the code, directing its interpretation, with a touch of Eastern mysticism Lex state is Qi
state transition that erodes the developer's sanity” ✦ Nuance: A madness that transcends human comprehension, a forbidden insanity that drains the mind upon close inspection. (With a Cthulhu Mythos vibe.) An indescribable state transition
to chaos lurking in the parser's abyss” ✦ Nuance: The unfathomable eeriness of its intricate mechanism, which leads to the deepest, incomprehensible realms of language interpretation (abyss and chaos). A doorway to chaos
binary plus operator to be EXPR_END ✦ Grammar rule for the binary plus operator expression is “arg : arg + arg” ✦ Therefore, lex state should be EXPR_END when it comes to the end of arg Where should be EXPR_END? 1 + 2 EXPR_BEG EXPR_END EXPR_BEG EXPR_END arg + arg EXPR_BEG EXPR_END EXPR_BEG EXPR_END
EXPR_END for all the tokens that come at the end of the 'arg' rule ✦ In relation to the First set, could we refer to them as the Last set? ✦ These tokens can be the last token of arg ✦ tINTEGER ✦ tSTRING_END ✦ “end” Last set of rules
its fi nal symbol is a token ✦ “arg” includes “primary” ✦ “primary” can be expanded to tINTEGER and so on ✦ “primary” ends with ‘]’, “end” and so on ✦ Need to set the state to EXPR_END immediately after all the tokens obtained in this way How to know Last set arg : arg ‘+’ arg | arg '-' arg | … | primary primary : literal | tLBRACK aref_args ‘]' | k_if … k_end | … simple_numeric : tINTEGER | tFLOAT | tRATIONAL | tIMAGINARY literal : numeric | symbol
example, ‘^’ (caret) ✦ This is a binary operator used to calculate the exclusive OR for integers ✦ As it's a binary operator, similar to ‘+’, it should transition to EXPR_BEG immediately after ‘^’ The context of the token
binary operator but also as a unary operator, speci fi cally as a pin operator in pattern matching ✦ For now, even in the unary operator case, simply transitioning to EXPR_BEG works well ✦ However, if we change the lex state transition for the caret in the future, we'll need to consider both cases ✦ Lex state management is also dif fi cult because a single token can be used in grammatically very different places ‘^’ is not always binary operator
cult is that a state is used for various purposes ✦ For example, EXPR_BEG is not only used to determine whether to ignore or emit line break but also whether to treat two bars as a set or as separate bars Lex state overloading This is “||” (!EXPR_BEG) This is ‘|’ and ‘|’ (EXPR_BEG)
decide whether to ignore or emit it, depending on the context ✦ This context-dependent behavior is managed by something called lex state ✦ It’s clear that lex state is incredibly hard to manage, and it can be described as “a doorway to chaos” A doorway to chaos lurking in the parser's abyss
can be written in Ruby? ✦ Yes, it's clear from the grammar ✦ Not only subtraction but also all binary operators can be checked by the grammar Grammar as Order arg : arg '+' arg | arg '-' arg | arg '*' arg | arg '/' arg | arg '^' arg | arg tCMP arg ... Grammar
both the default value of a formal argument (“expr1”) and the actual argument (“expr2”)? ✦ Yes, it's also clear from the grammar that both of them allow “arg_value” Grammar as Order f_args : f_arg ',' f_optarg(arg_value) ',' … call_args : args opt_block_arg args : arg_value Grammar
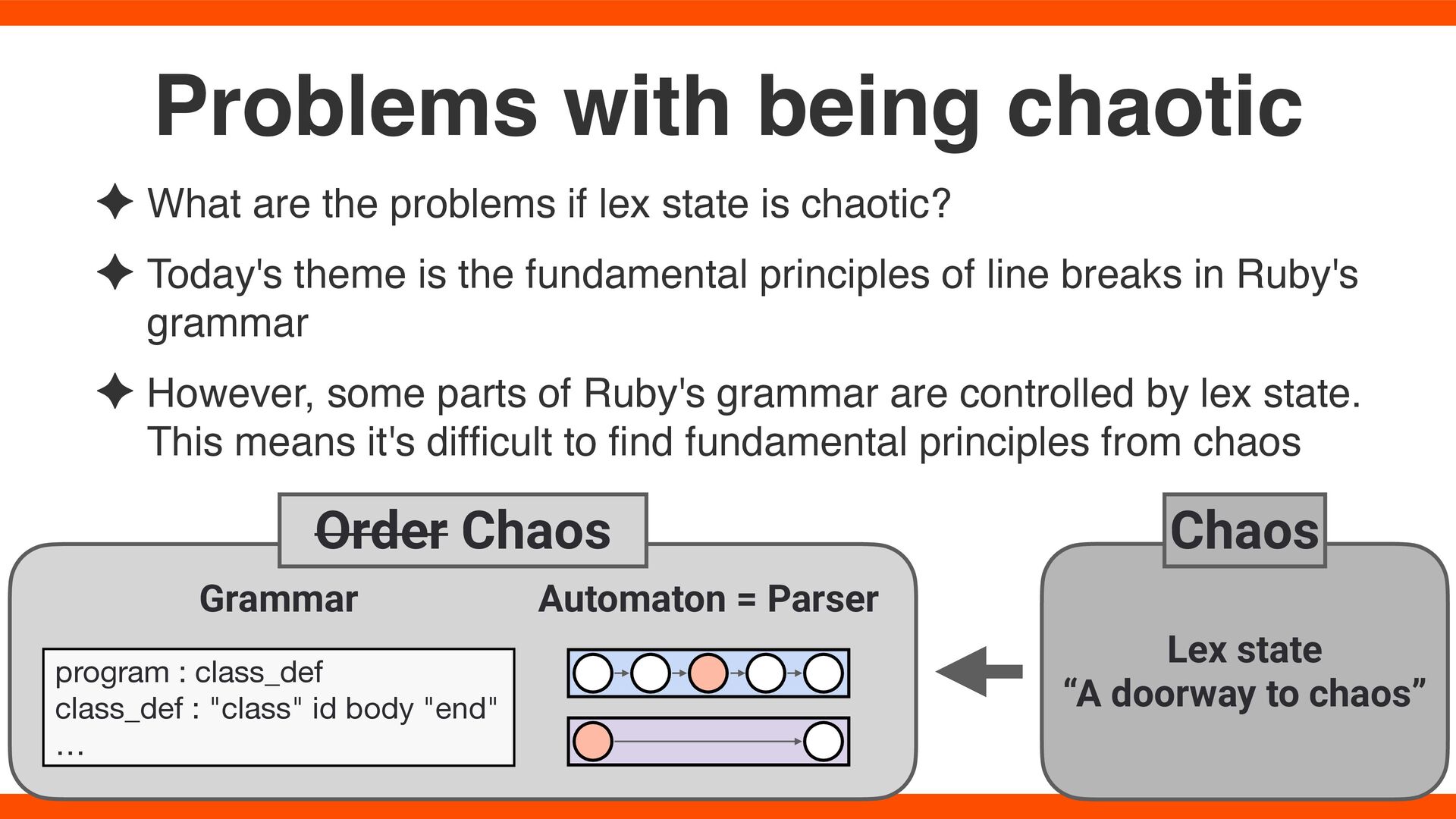
✦ Today's theme is the fundamental principles of line breaks in Ruby's grammar ✦ However, some parts of Ruby's grammar are controlled by lex state. This means it's dif fi cult to fi nd fundamental principles from chaos Problems with being chaotic program : class_def class_def : "class" id body "end" … Grammar Automaton = Parser Lex state “A doorway to chaos” Order Chaos Chaos
simplifying an object by focusing on its important properties to make it easier to comprehensively understand the structure of the object What’s modeling and why
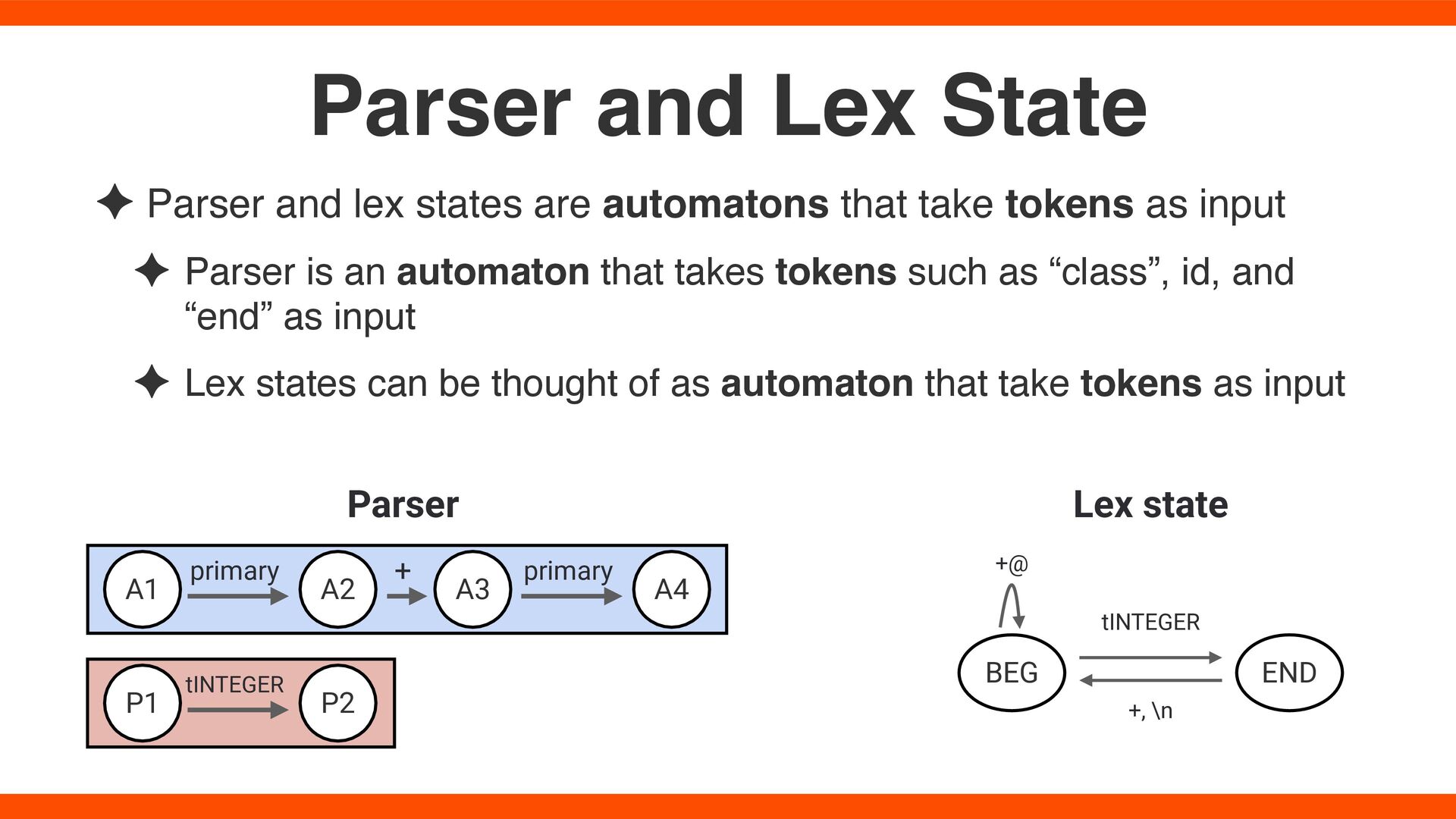
as input ✦ Parser is an automaton that takes tokens such as “class”, id, and “end” as input ✦ Lex states can be thought of as automaton that take tokens as input Parser and Lex State Parser Lex state BEG END tINTEGER +, \n +@ A1 A2 A3 primary + A4 primary P1 P2 tINTEGER
automaton ✦ Therefore, it's possible to build a new automaton from these two ✦ For example, the state after reading '+' is the A3 state in the parser, and the lex state is EXPR BEG Combine automatons Parser BEG END tINTEGER +, \n +@ A1 A2 A3 primary + A4 primary BEG END BEG END Lex state
implementation, simply focus on the tokens the lexer returns How to extract lex state transition EXPR_ARG if IS_AFTER_OPERATOR EXPR_BEG if ! IS_AFTER_OPERATOR
Lex state transitions for each token is shown ✦ For example, “end” token has two transitions ✦ If “end” is method name, transits to EXPR_ENDFN ✦ Otherwise transits to EXPR_END Lex state for tokens EXPR_ENDFN EXPR_END
✦ Method de fi nitions always result in the EXPR_END state ✦ Even so lex state after “end” token can be EXPR_ENDFN or EXPR_END Lex state for rules EXPR_END
each rule, the lex state transitions for each parser state becomes clear ✦ For example, the parser immediately after reading the binary operator ‘+’ is always in the EXPR_BEG state Lex state for parser state EXPR_END
for counterexamples ✦ Hypothesis: In principle, a statement terminates if a line break is present at a point where a statement can be completed Verify the hypothesis https://x.com/tanaka_akr/status/1870679443376947467
EXPR_BEG, and the following line break is ignored ✦ Therefore the code below is not an endless range and “b” but an normal range Endless range == != Based on the principles
the following line break is ignored ✦ Therefore the code below is not anonymous arguments ✦ “**” and “&” are same Anonymous arguments == != Based on the principles
EXPR_LABEL, and the following line break is ignored ✦ Because this ‘\n’ is optional, it doesn't cause any problems if the lexer ignores it Line Breaks before ‘)’ '\n'? ')' ==
The state can’t be EXPR_BEG ✦ Then ‘\n’ is emitted ✦ The state’s lookahead set doesn’t include ‘\n’ token nor shirt ‘\n’ token #3. Unexpectedly emits ‘\n’
line break is placed between global variables within the alias de fi nition ✦ ‘\n’ is ignored when EXPR_FNAME but emitted when EXPR_END Line Breaks in “alias” Syntax Error unexpected '\n' Ignore ‘\n’ Emit ‘\n’
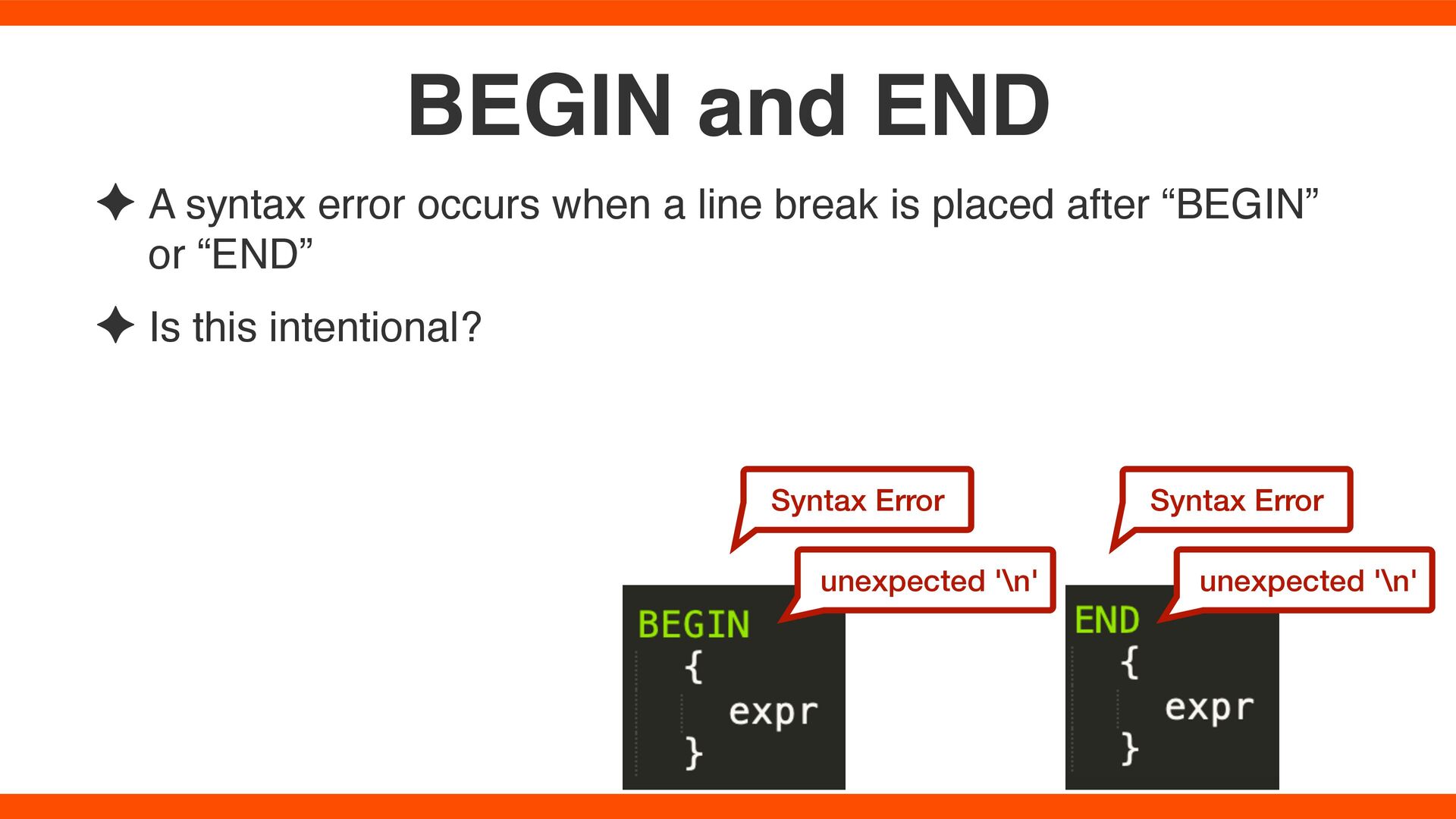
break is present at a point where a statement can be completed ✦ Exception: A statement doesn’t terminate for endless range and anonymous arguments (#1) ✦ Hypothesis: Ignoring line breaks where expressions cannot end ✦ Exception: A line break is emitted for global variable alias, BEGIN and END (#3) Verify the hypothesis
of grammar with the chaos of lex state ✦ The order of grammar is necessary to face chaos ✦ Using the fact that both the parser and lex state are automata that take tokens as input, and that we can create a new automaton by combining two automata ✦ To validate the principles regarding line breaks in Ruby grammar, search for exceptions, and fi nd some exceptions ✦ However, for the most part,the hypothesis seems to be correct Chaos and Order
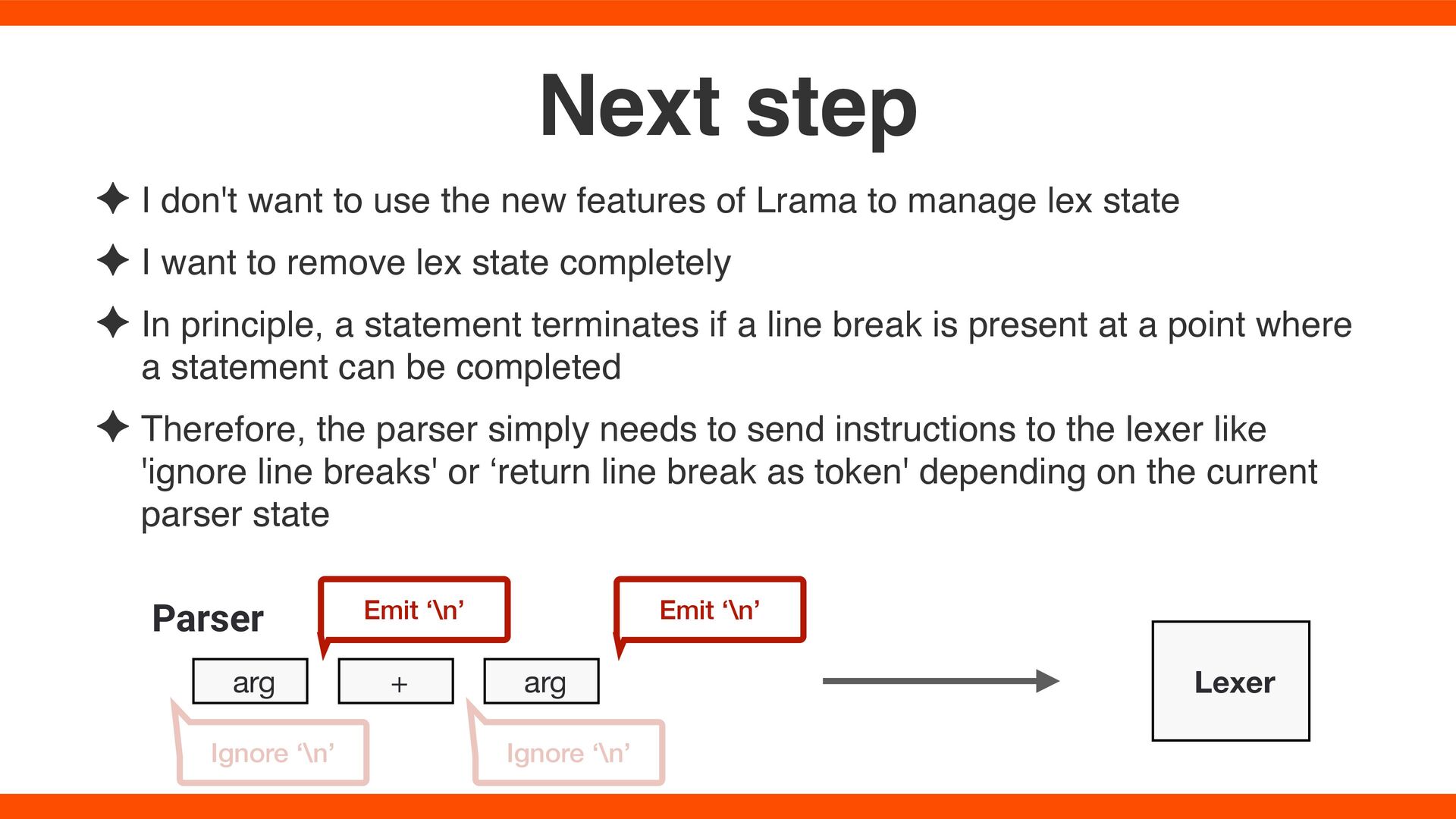
Lrama to manage lex state ✦ I want to remove lex state completely ✦ In principle, a statement terminates if a line break is present at a point where a statement can be completed ✦ Therefore, the parser simply needs to send instructions to the lexer like 'ignore line breaks' or ‘return line break as token' depending on the current parser state Next step arg + arg Ignore ‘\n’ Emit ‘\n’ Ignore ‘\n’ Lexer Emit ‘\n’ Parser
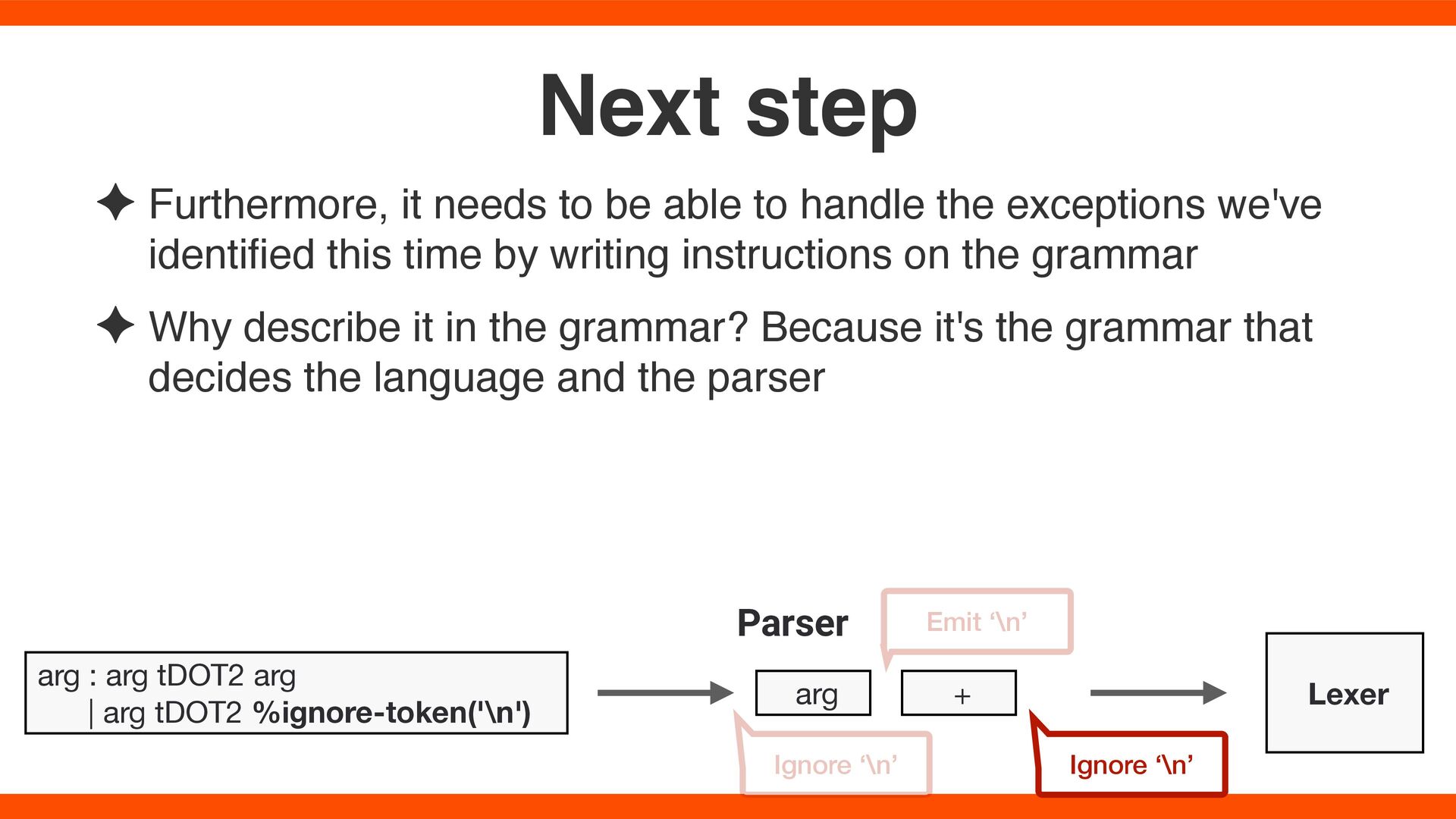
exceptions we've identi fi ed this time by writing instructions on the grammar ✦ Why describe it in the grammar? Because it's the grammar that decides the language and the parser Next step arg : arg tDOT2 arg | arg tDOT2 %ignore-token('\n') arg + Ignore ‘\n’ Emit ‘\n’ Ignore ‘\n’ Lexer Parser
that's surprisingly interesting when you consider it ✦ To understand how line breaks are treated in current Ruby, it is necessary to understand the behavior of lex state, which is a doorway to chaos ✦ Bringing lex state into the ordered systems of grammar and automata makes it possible to understand lex state behavior Ruby's Line Breaks
is present at a point where a statement can be completed ✦ Exception ✦ A statement doesn’t terminate for endless range and anonymous arguments ✦ A line break is emitted for global variable alias, BEGIN and END Principle and exceptions
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![✦ @.bookstore at RubyKaigi 2025 ✦ “ܭࢉཧͷجૅɹ[ݪஶୈ3൛] 1.ΦʔτϚτϯͱݴޠ” ✦ “നͱࠇͷͱͼΒ:](https://files.speakerdeck.com/presentations/feb4bd940cc2424ba26a8b66721d6ea1/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![✦ Fixing [Bug #10653] caused [Bug #11456] and [Bug #11849]](https://files.speakerdeck.com/presentations/feb4bd940cc2424ba26a8b66721d6ea1/slide_77.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}