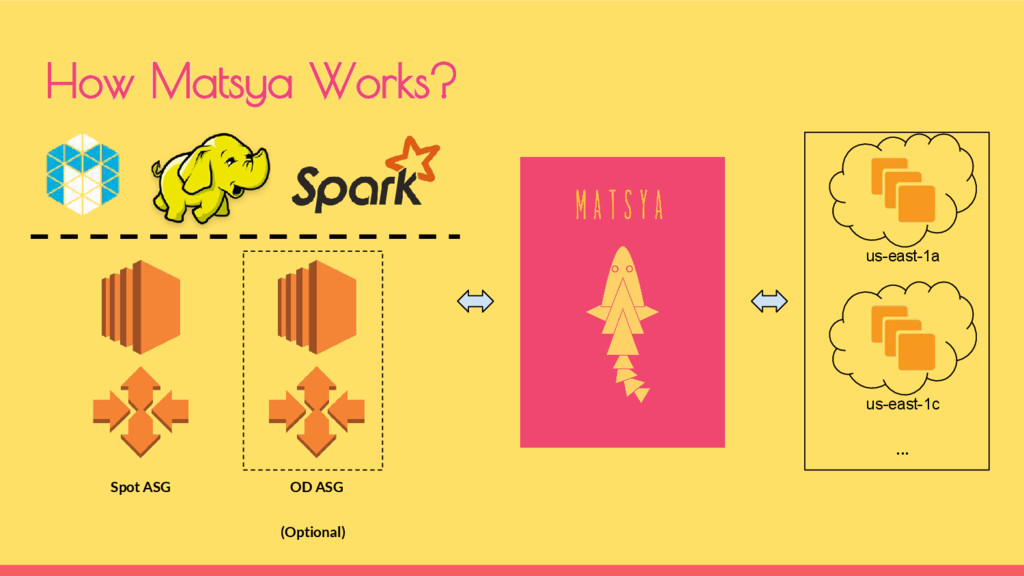
(ASG) based, set of instances running TaskTrackers and DataNodes Scaling up or down is as easy as updating the Desired value (or) You can also do Auto scaling based on specific metrics from CloudWatch
instances Spot Prices are highly volatile But, highly cost effective if used right Spot’s “Demand vs Supply” is local to it’s Spot Market AWS Spot Primer
risk and high reward game While you get the best value in terms of cost of the same compute, there’s no guarantee on when the machines are going to be taken away There’s Spot Termination Notice, but unfortunately not all applications are AWS- aware like Hadoop in our case
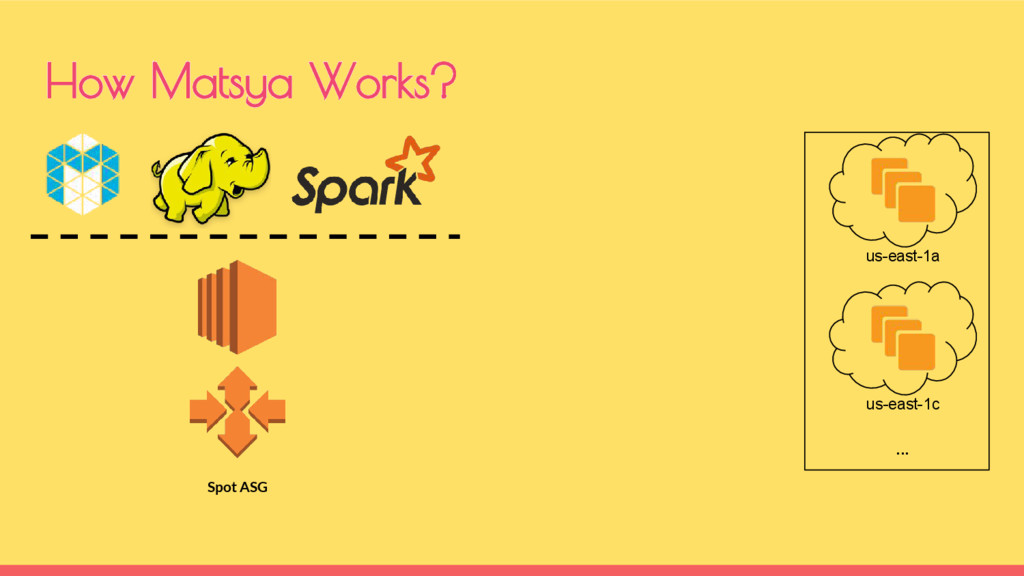
the following dimensions • # of Instance Types, Regions and Availability Zones The number of spot markets is a cartesian product of all the above numbers. Example - Requirement for 36 CPUs per instance • Instance Types - [d2.8xlarge, c4.8xlarge] • AZs - [us-east-1a, us-east-1b, us-east-1c, …] • Region - [us-east, us-west, …] - 10 regions • Total in US-EAST (alone) => 2 * 1 * 5 = 10 spot markets AWS Spot Markets
We saw our AWS bill was gradually increasing on “Data Transfer” section Because HDFS write pipeline is not very AWS-Cross-AZ-Data-Transfer-Cost aware With HDFS on Spot, each machine going down meant replication will kick in from start Not only HDFS but in a MR job, reducers download data from each mappers Problem 3 - Cost of Data Transfer
with Vamana, enabled us to achieve • ~40% reduction in monthly AWS bill • ~50% of AWS Infrastructure is on Spot • 100% of Hadoop MR workloads are on Spot Matsya at Indix
Blocks More notification systems Multiple Region support Multiple Product support Minimum number of OD instances Work In Progress Questions? github.com/ind9/matsya
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}