Observabilityチームは2022年に発足し、現在まで活動してきました。
限られたコストの中、どうやって運用を最適化していくか?
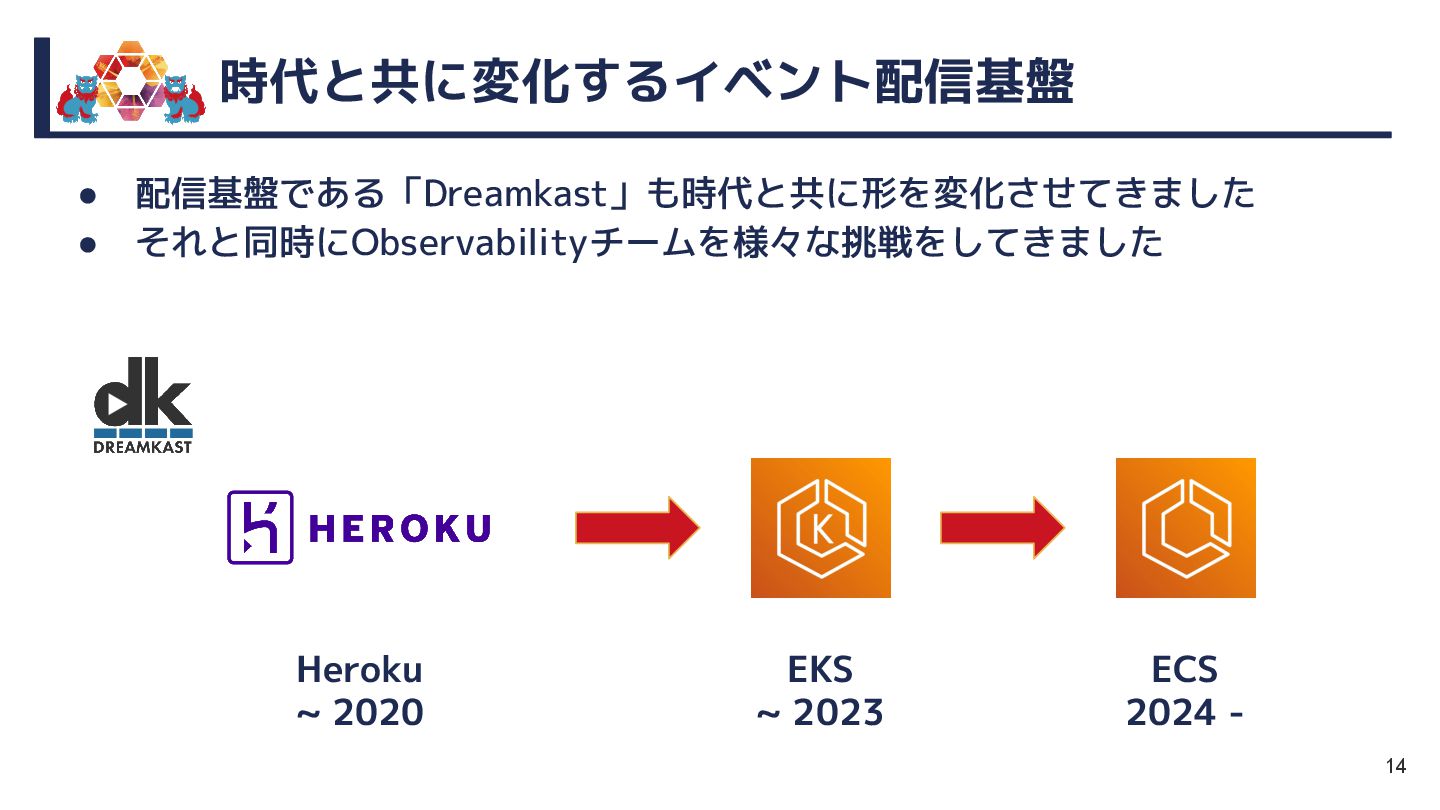
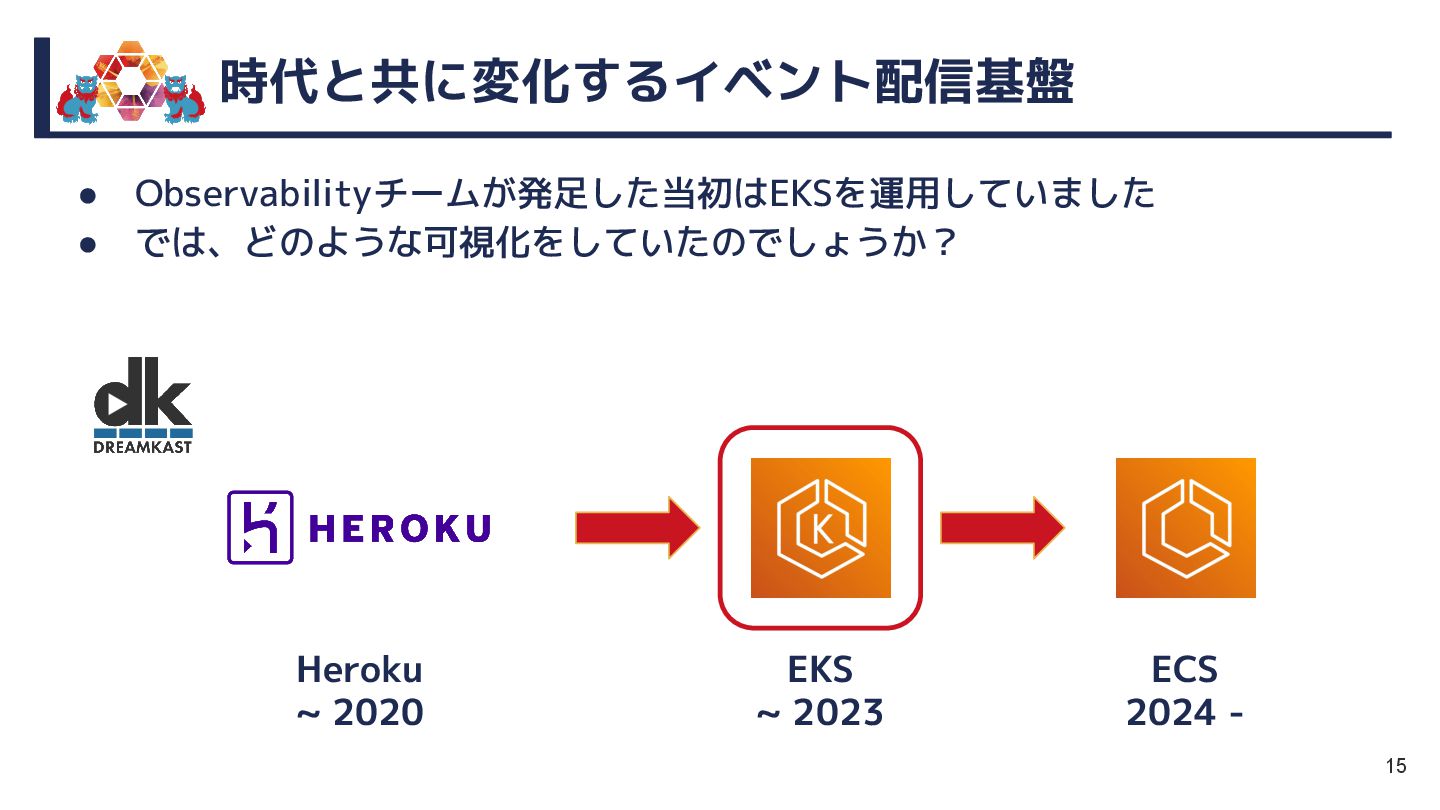
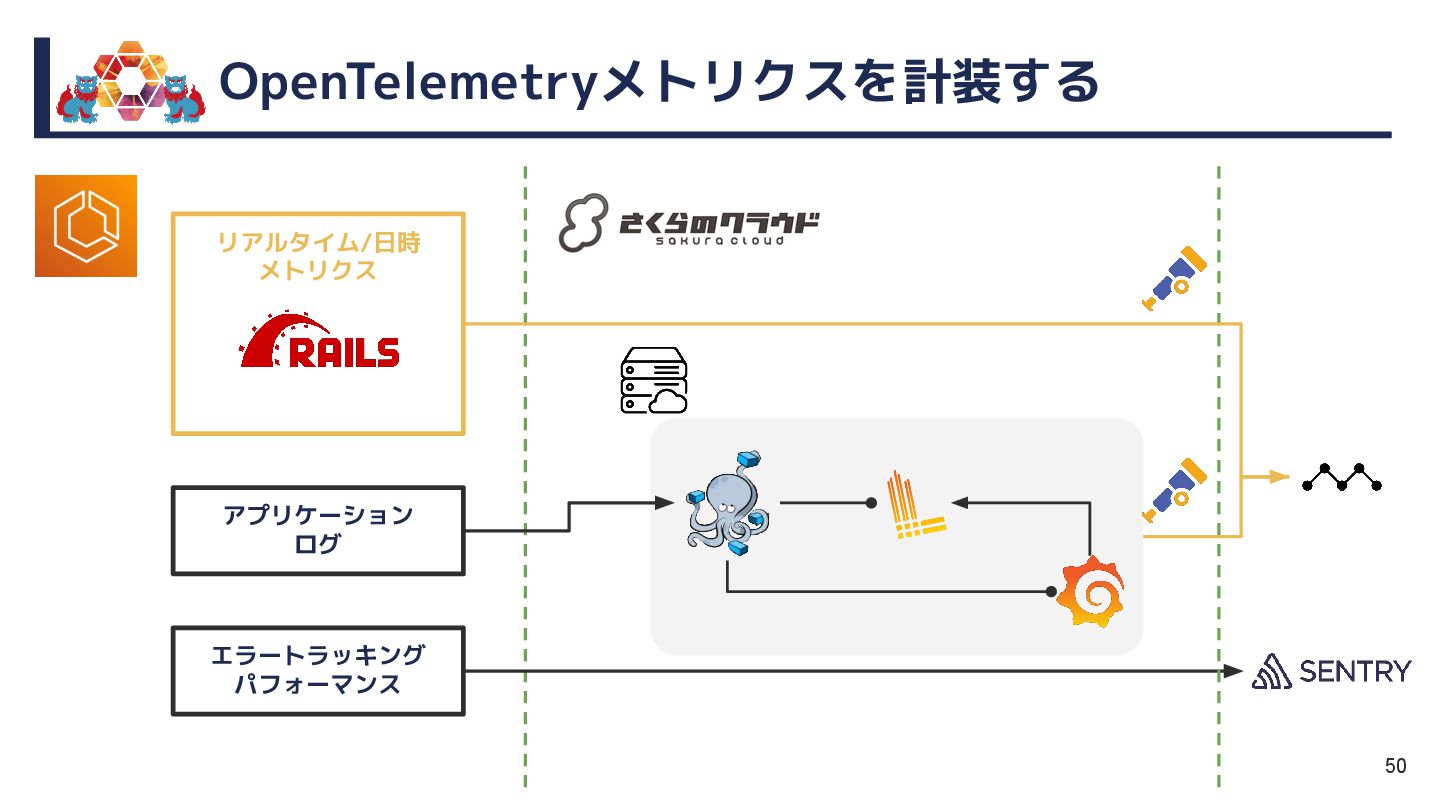
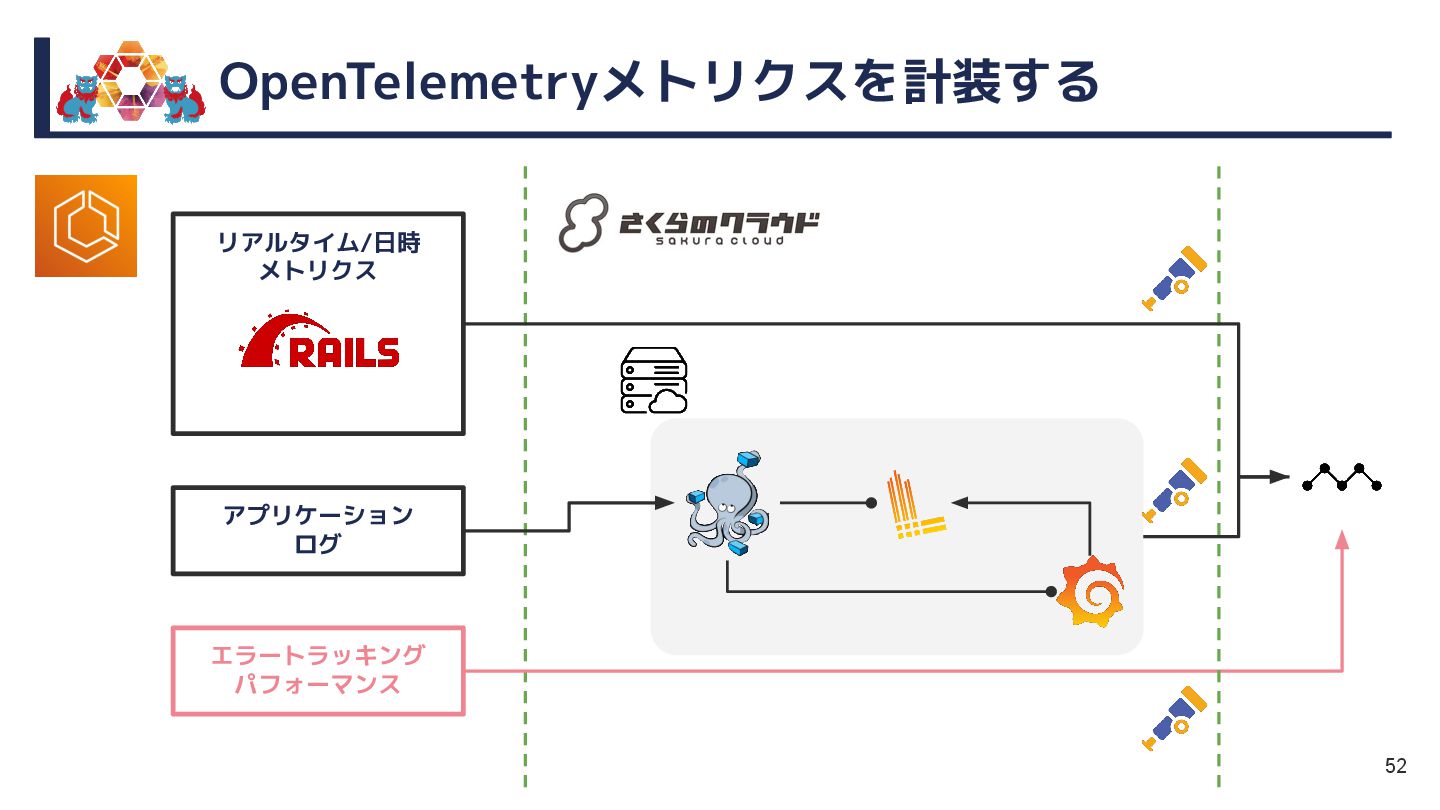
本セッションでは、EKS→さくら→Mackerelと移り変わる監視・運用の変遷を軸に、情熱とともに走り抜けてきた現場のリアルをお届けします。
Sentryの自前運用で直面した苦悩や、実際のイベント運用時のトラブル体験談も紹介。
インフラに求める『本質的なオブザーバビリティ』とは?
今後見据えるSLO運用やOpenTelemetryトレーシングの導入も含め、実践者の視点で情熱的に語ります。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
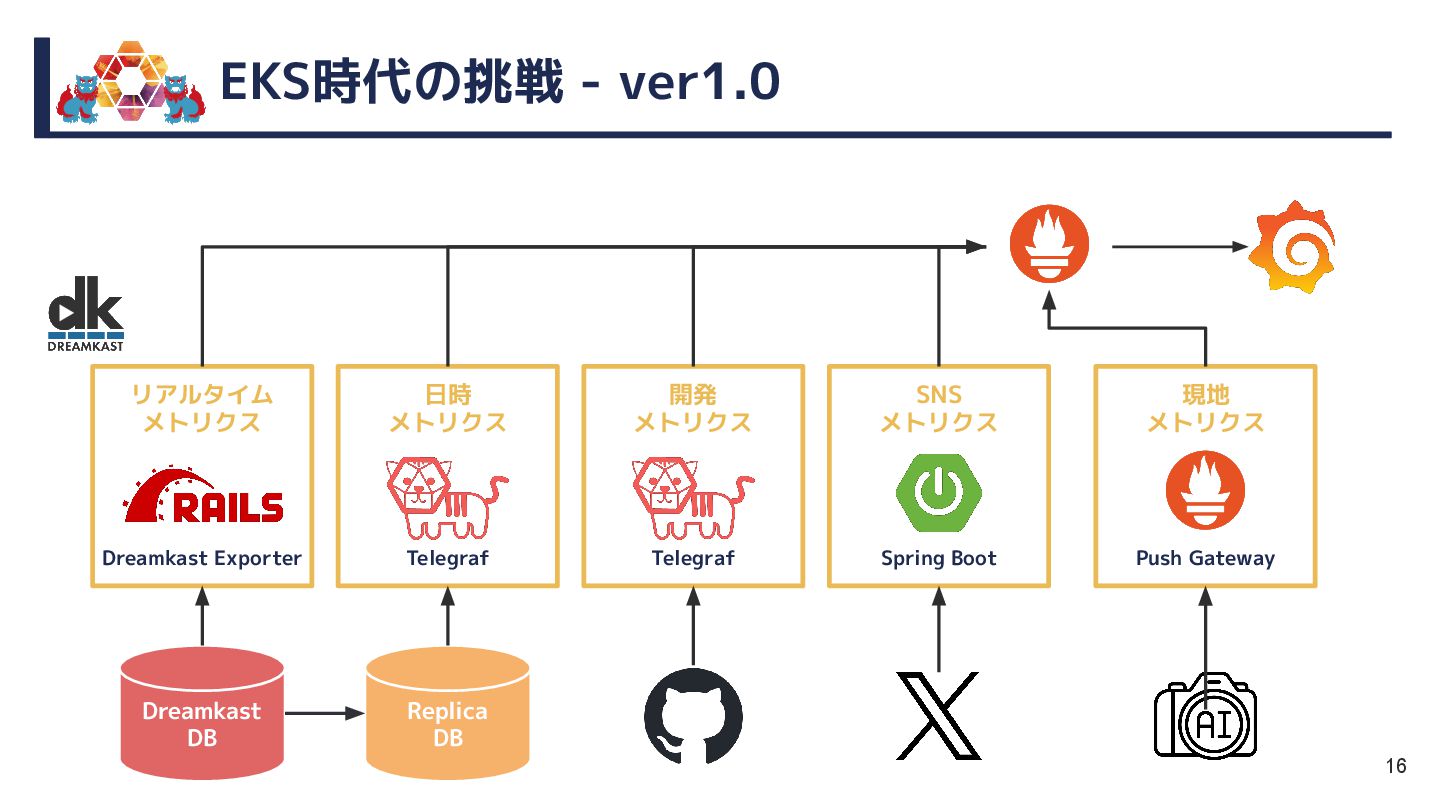{kind=link}
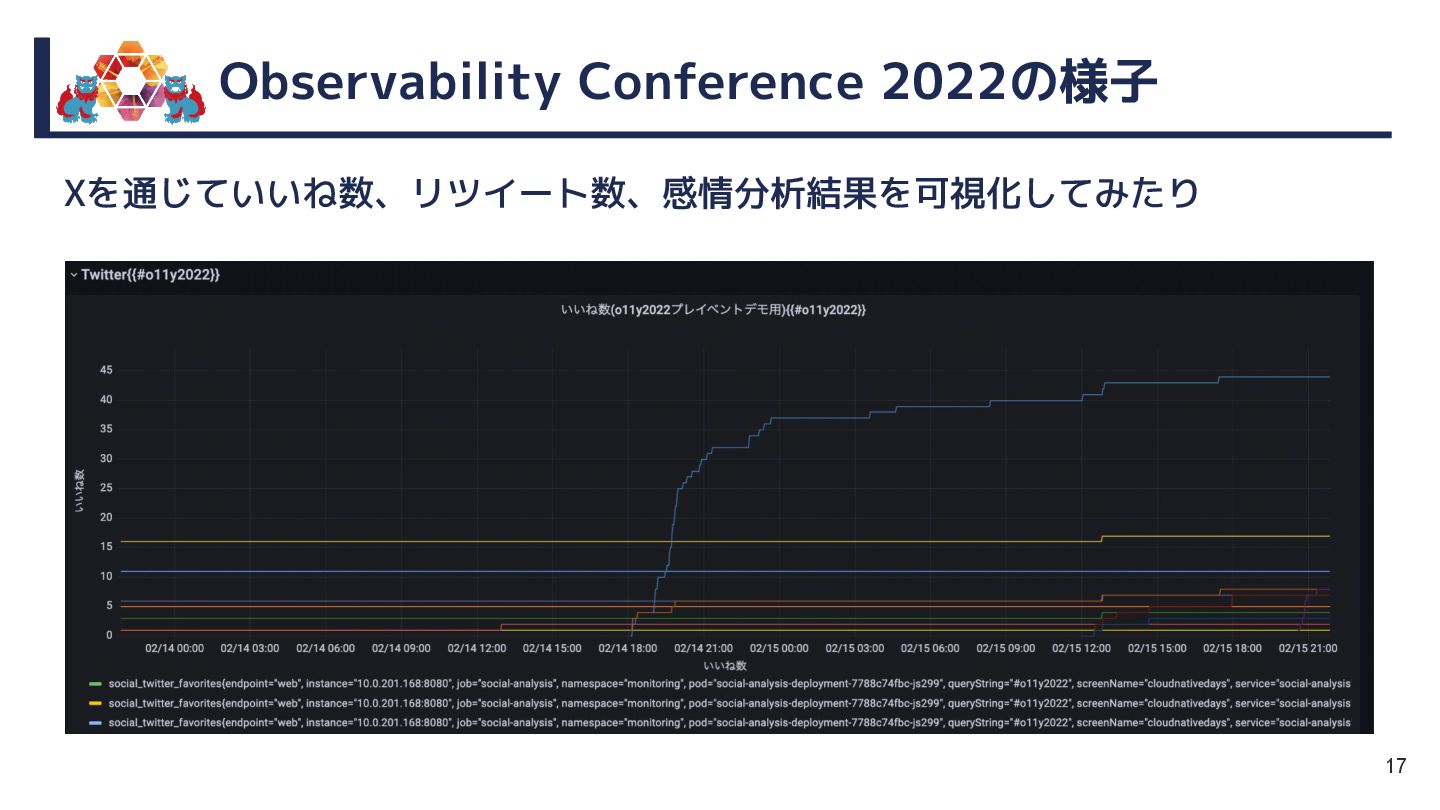{kind=link}
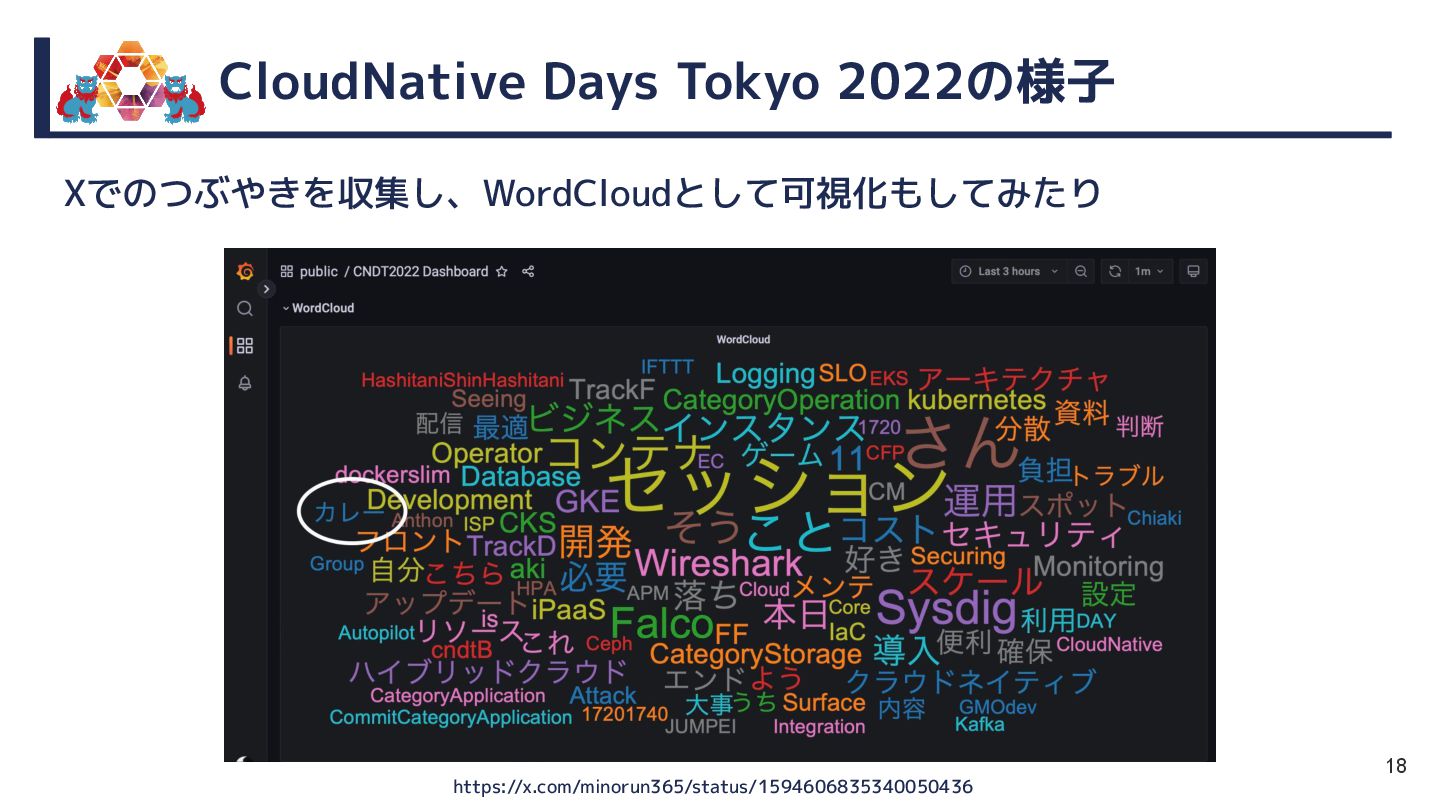{kind=link}
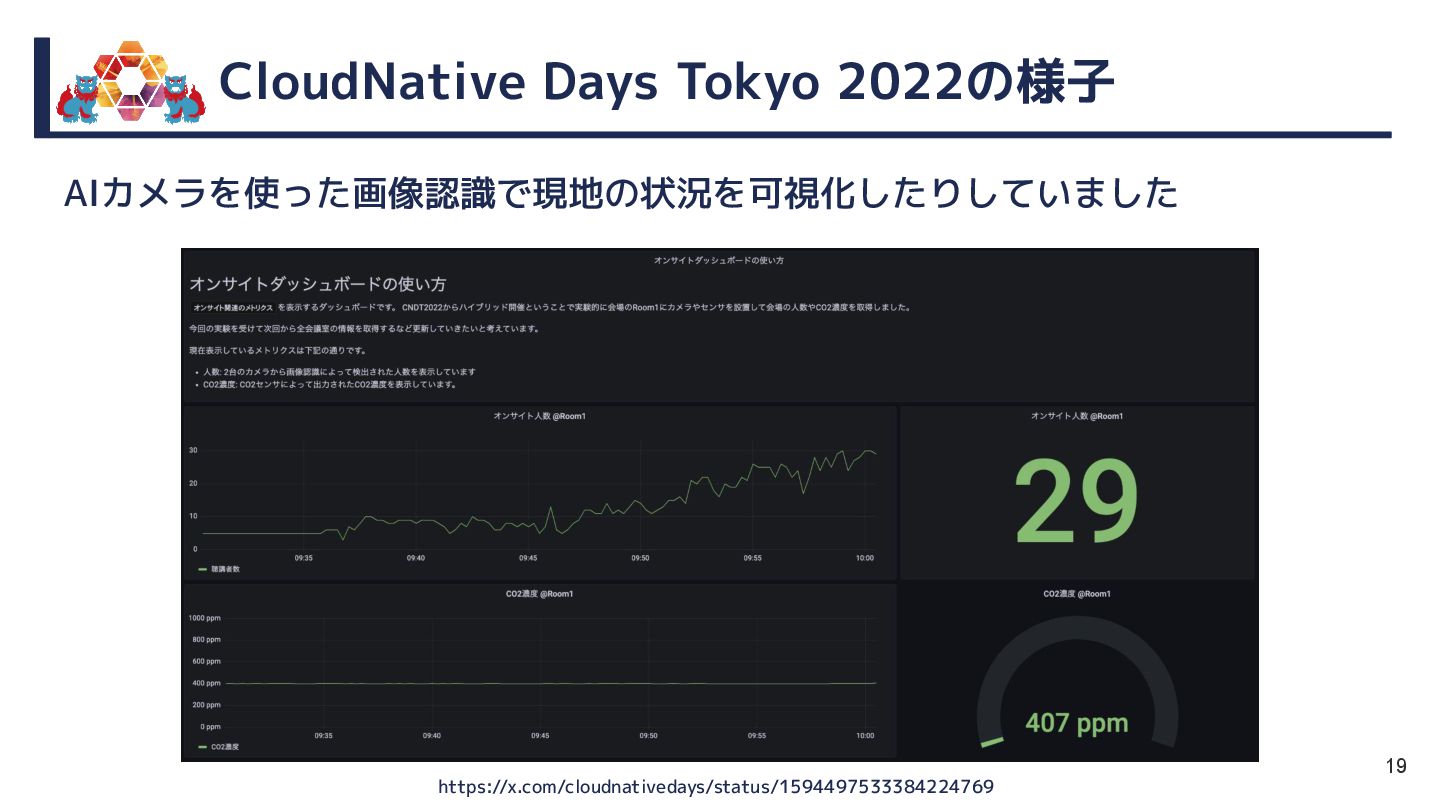{kind=link}
{kind=link}
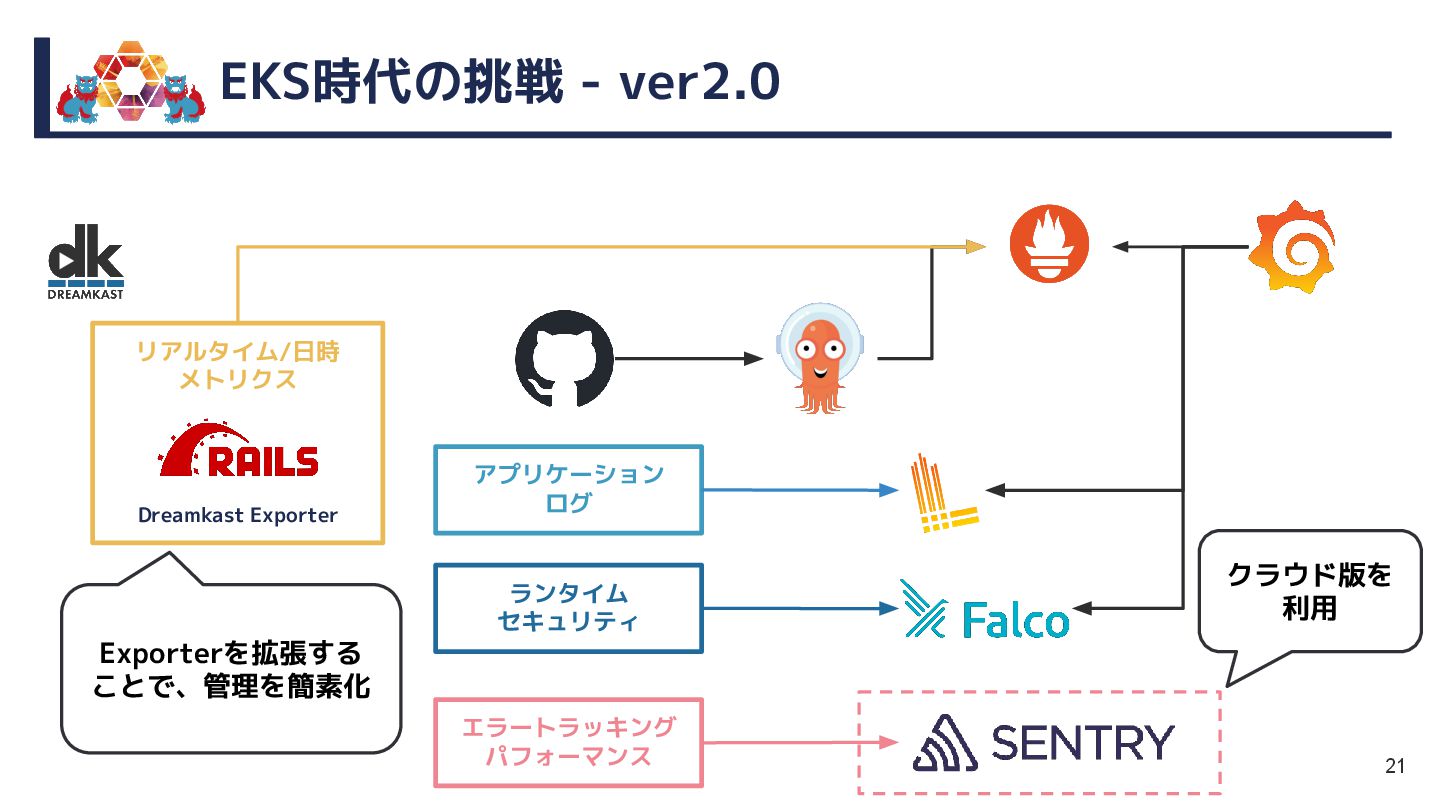{kind=link}
{kind=link}
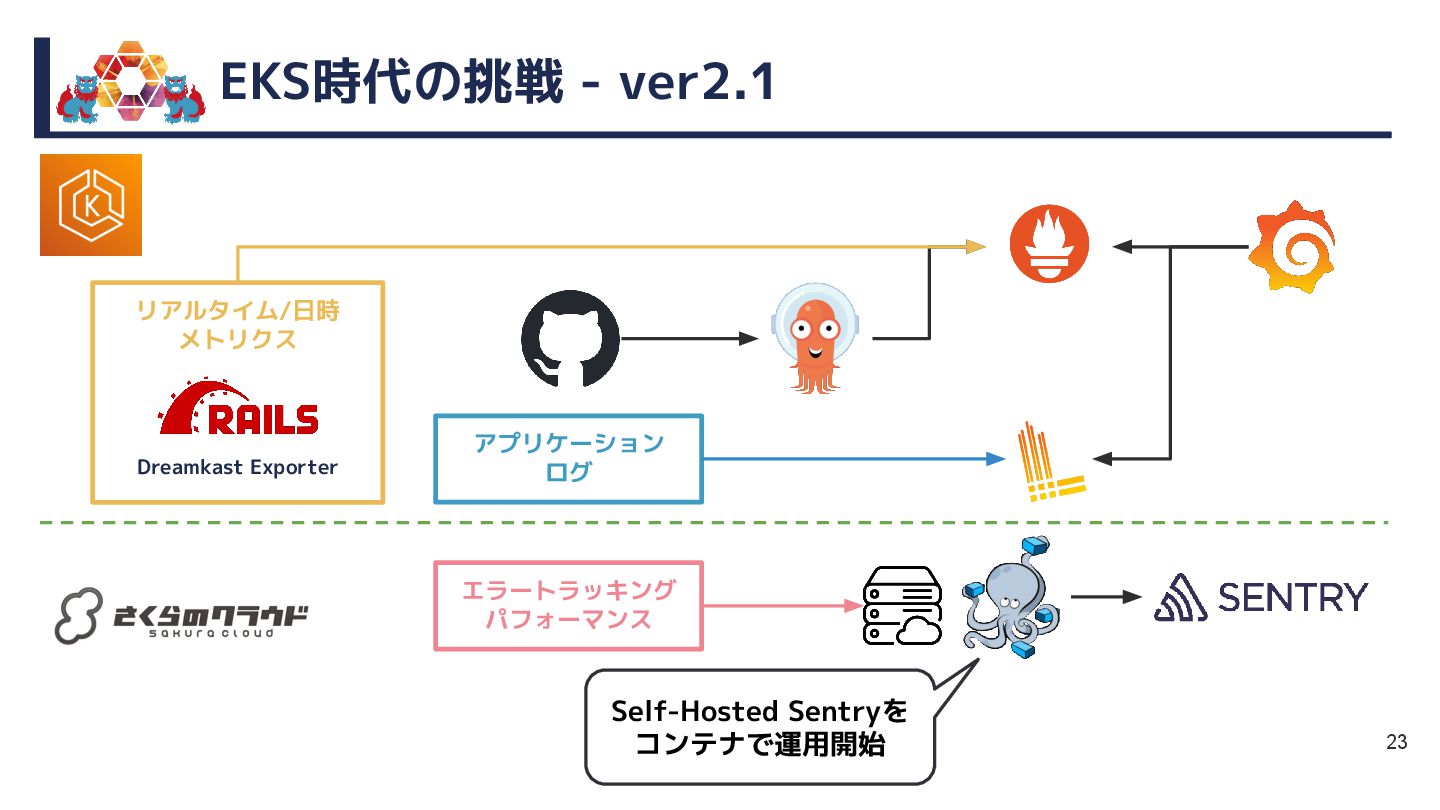{kind=link}
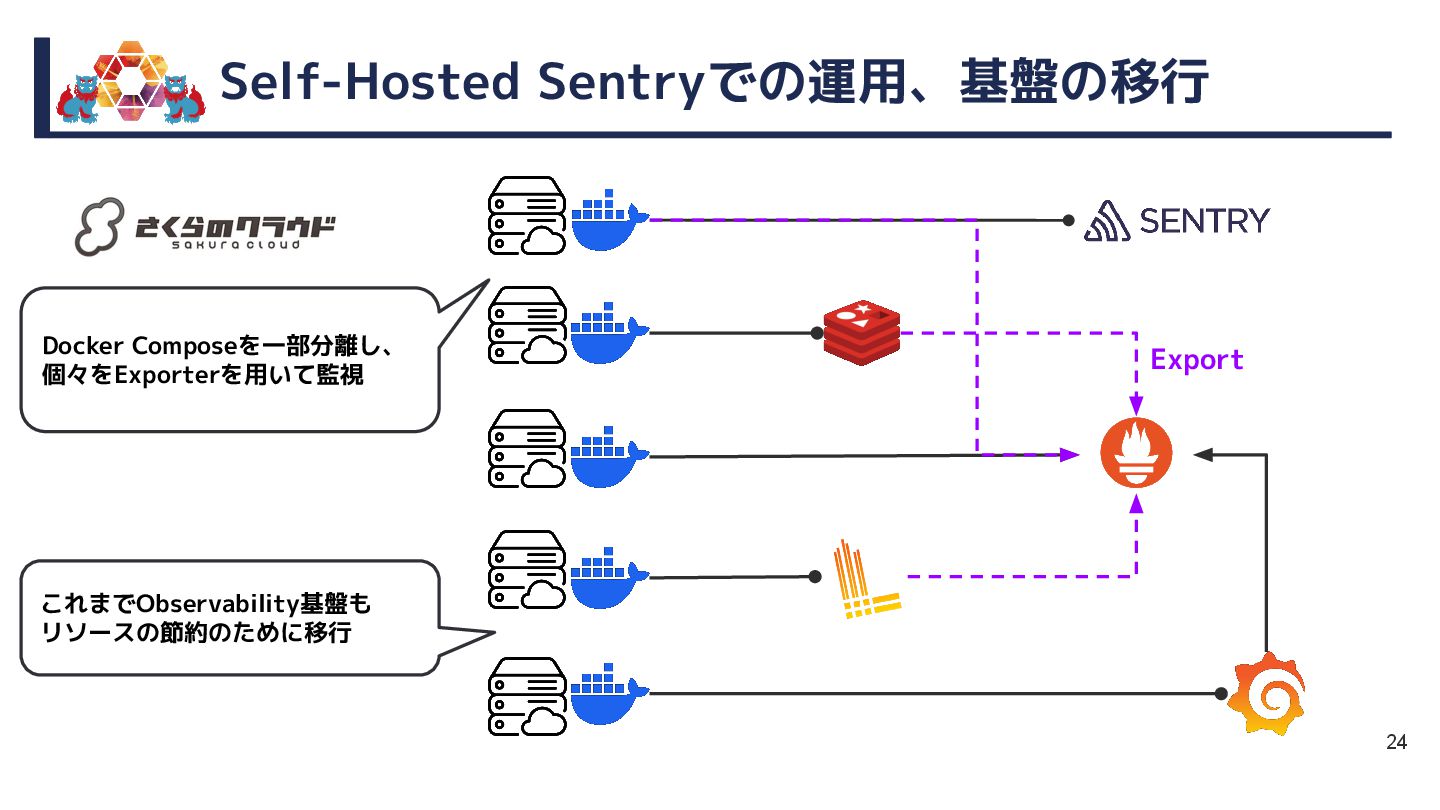{kind=link}
{kind=link}
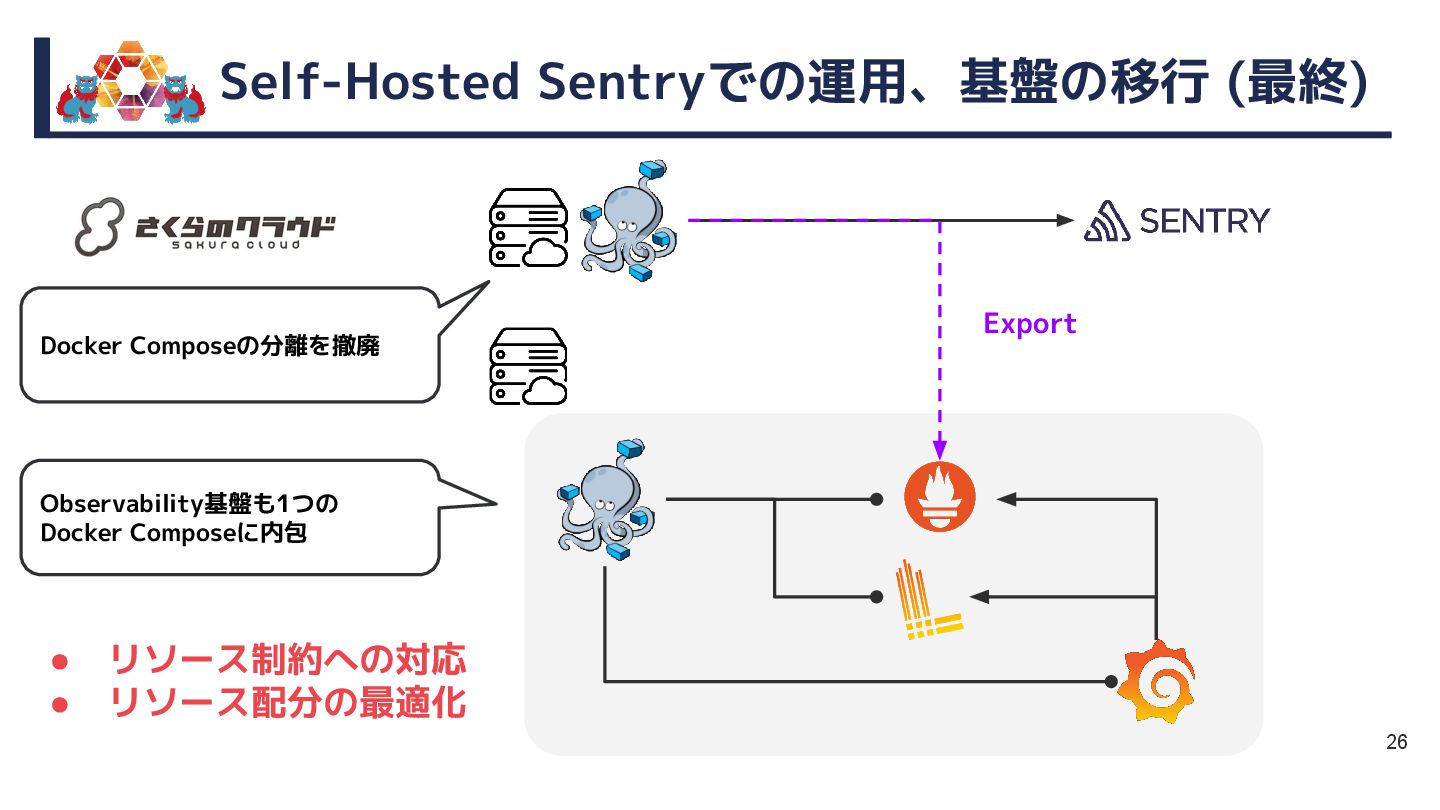{kind=link}
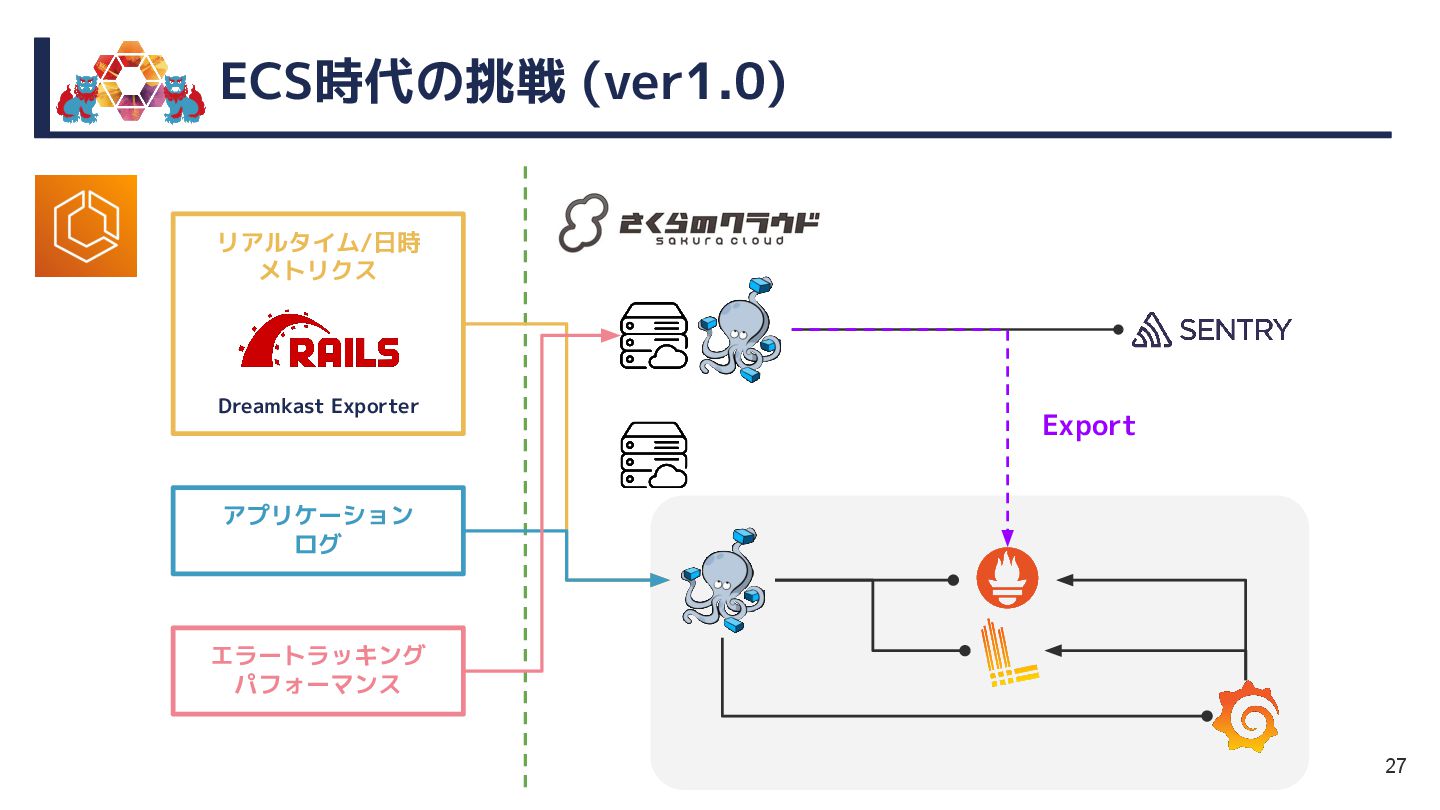{kind=link}
{kind=link}
{kind=link}
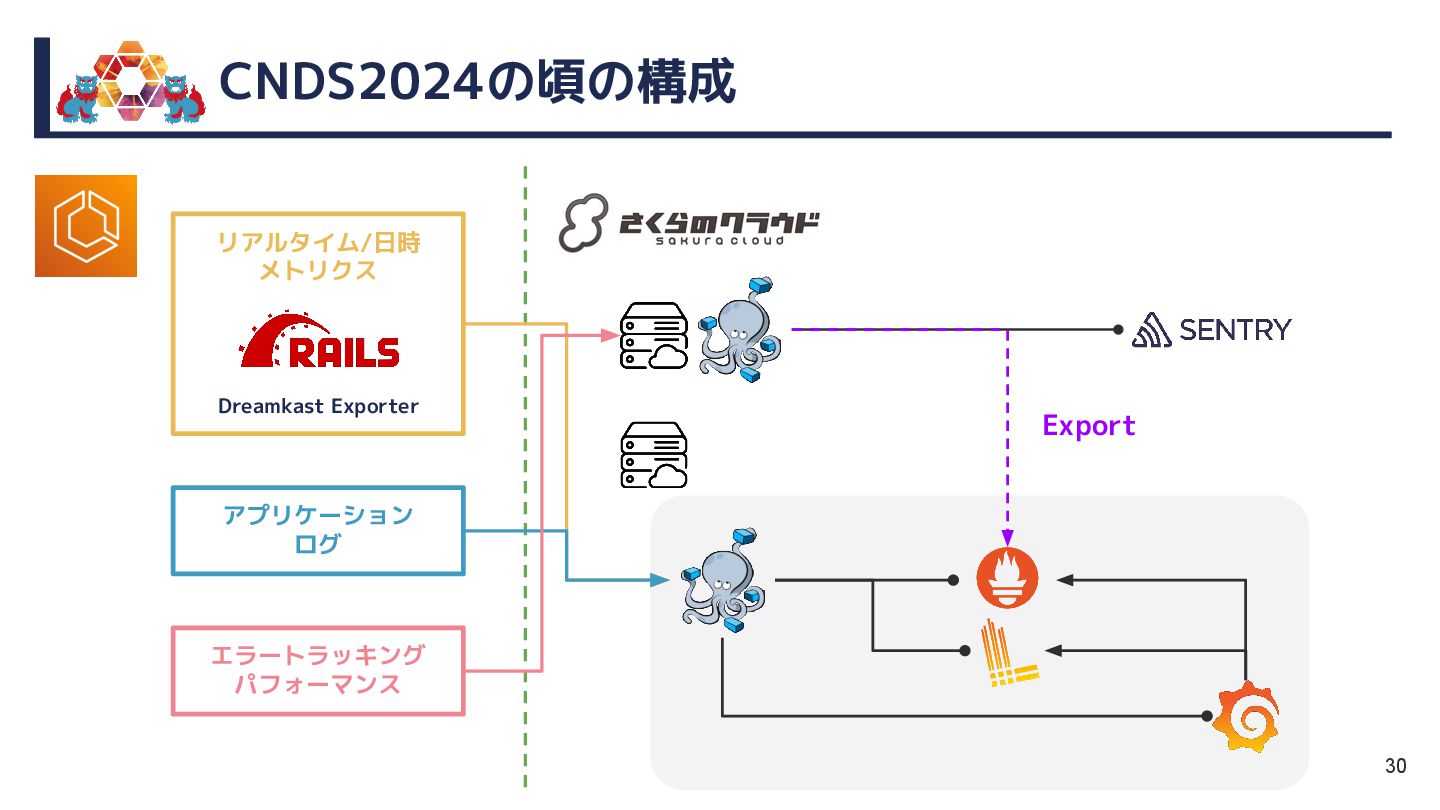{kind=link}
{kind=link}
{kind=link}
{kind=link}
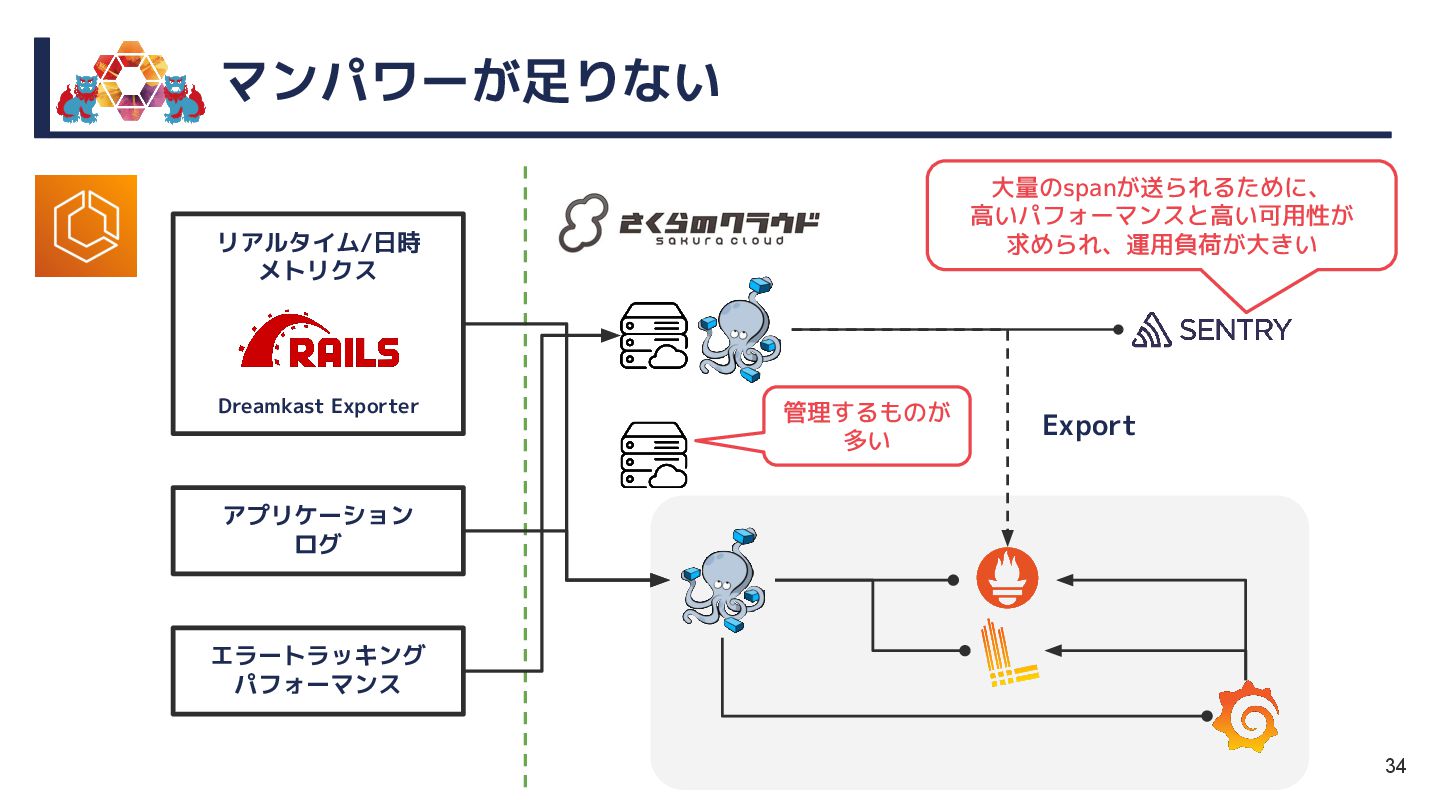{kind=link}
{kind=link}
{kind=link}
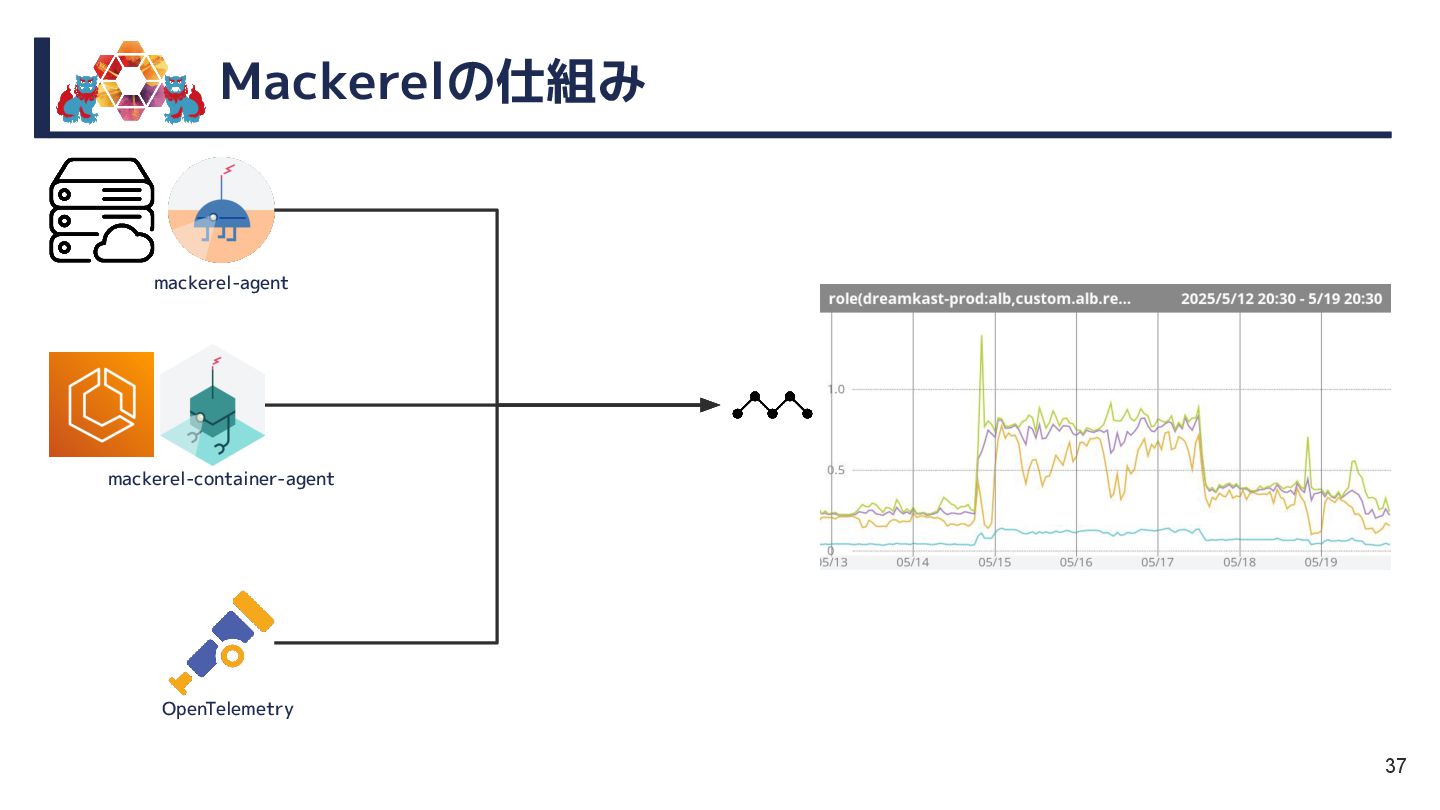{kind=link}
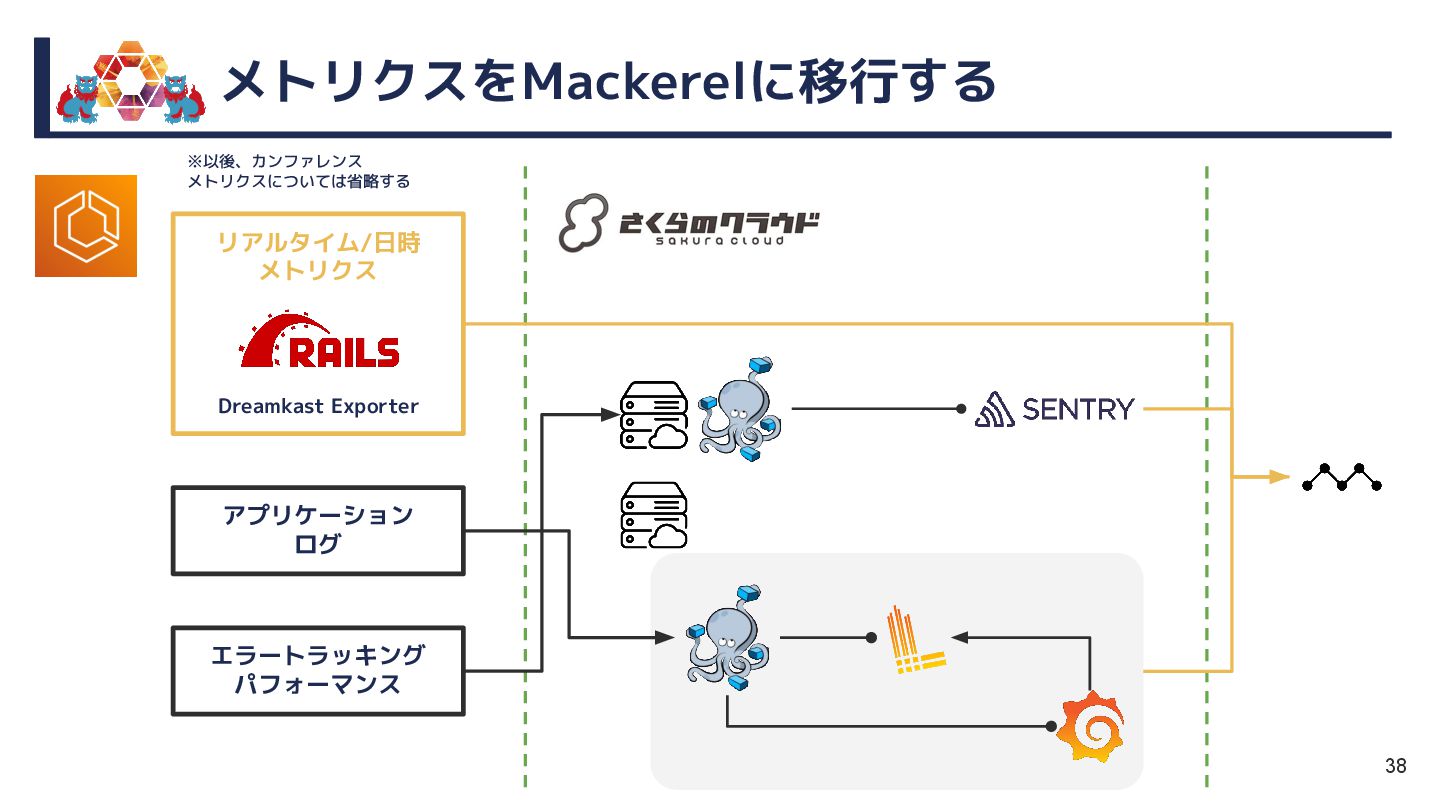{kind=link}
{kind=link}
{kind=link}
{kind=link}
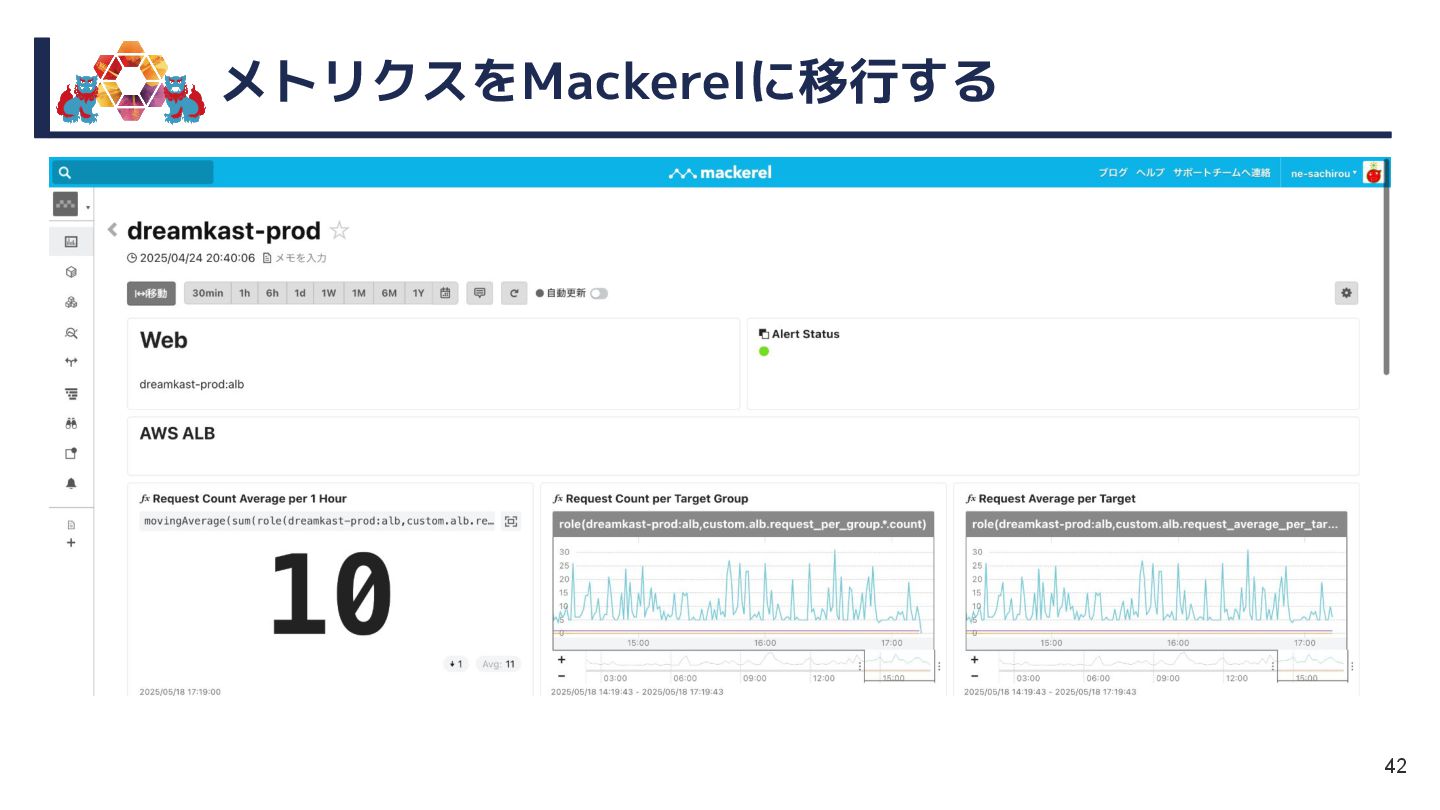{kind=link}
{kind=link}
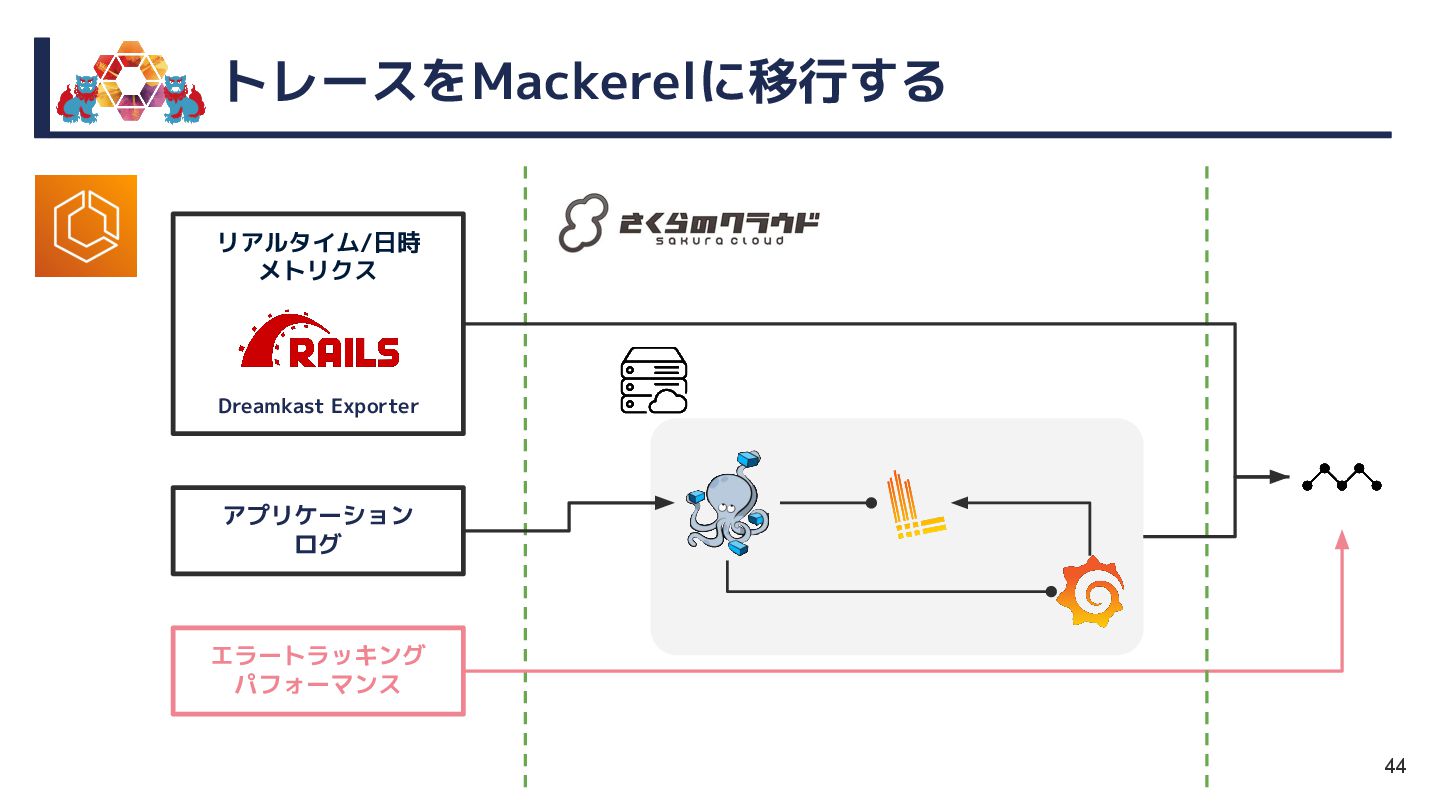{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
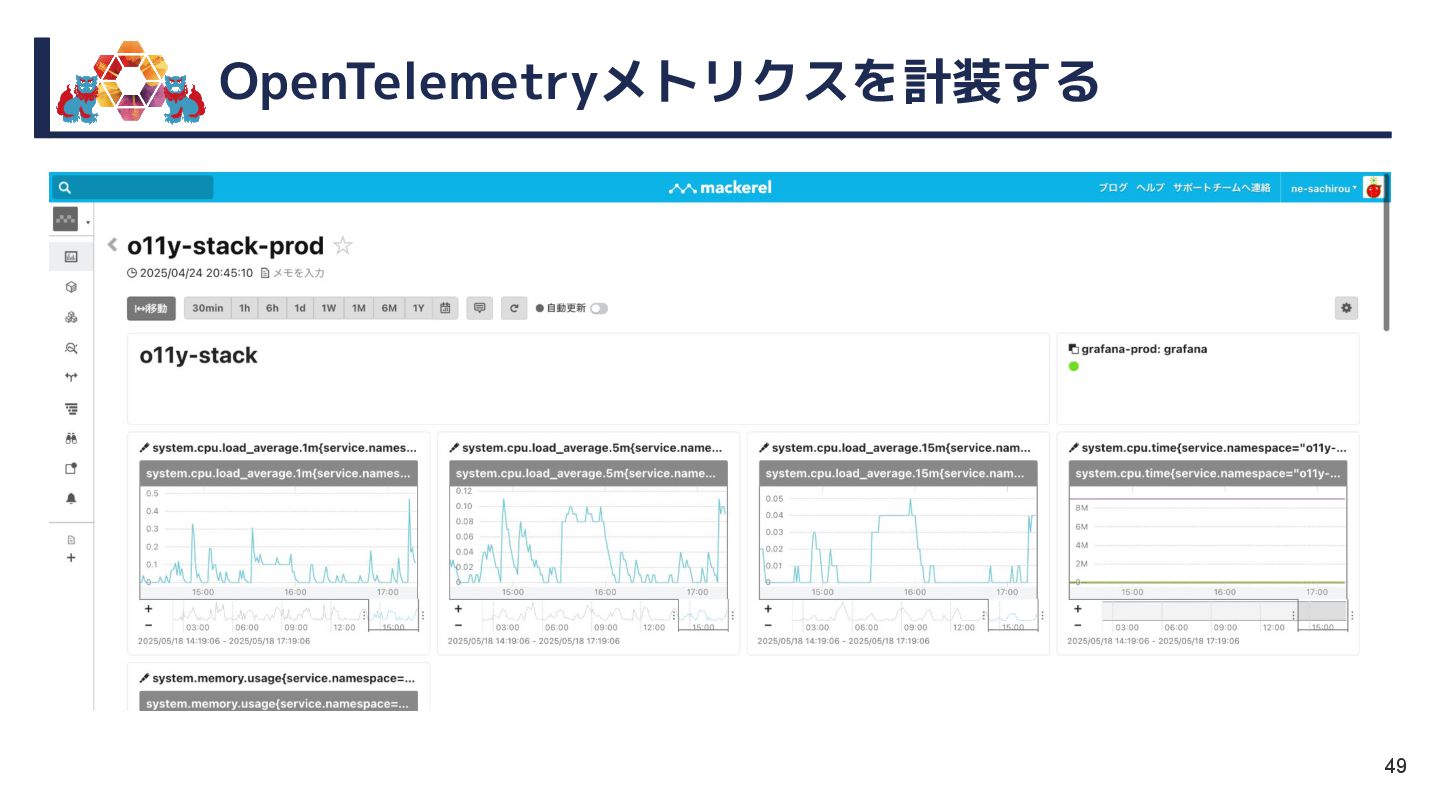{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}