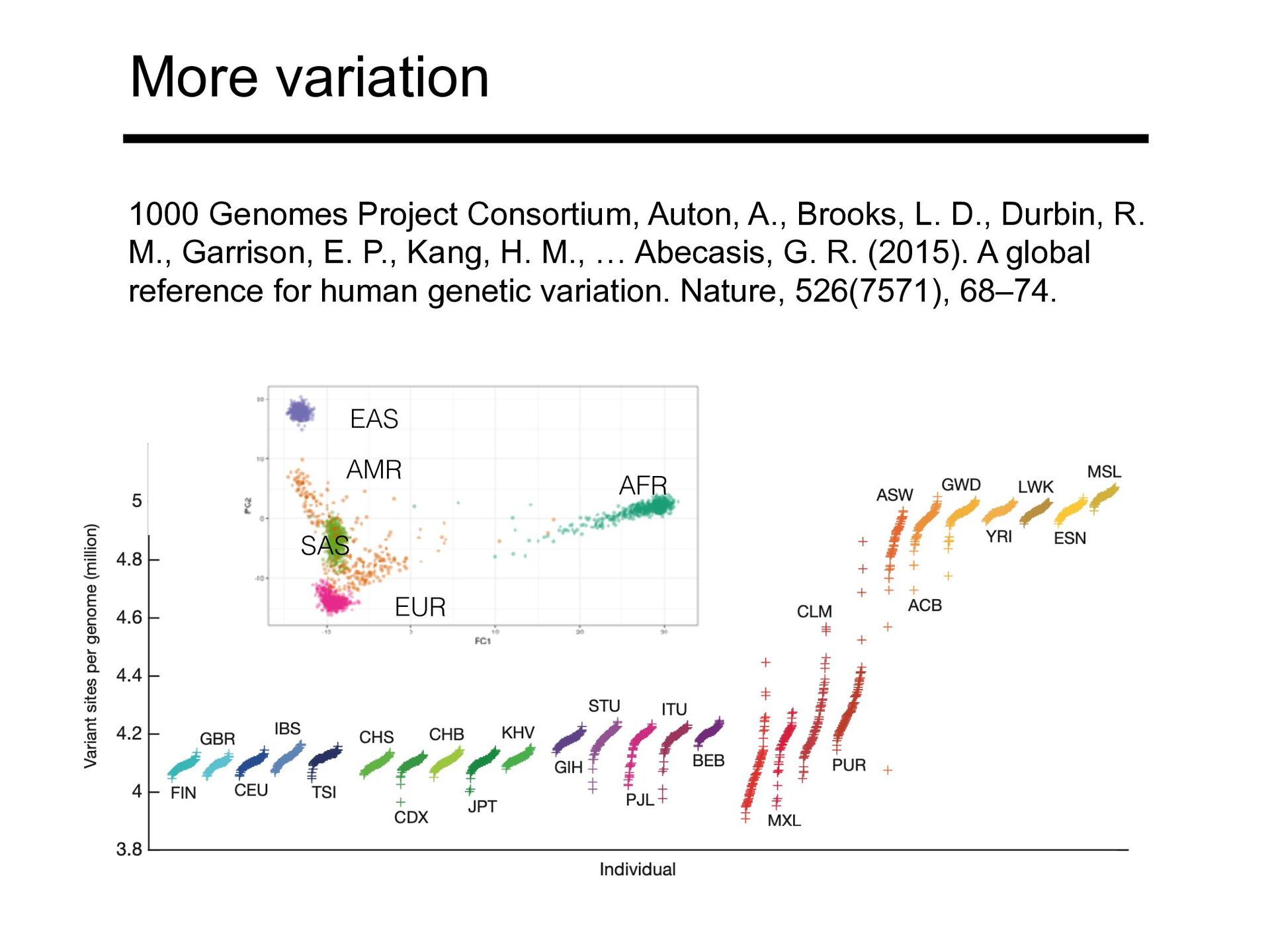
D., Durbin, R. M., Garrison, E. P., Kang, H. M., … Abecasis, G. R. (2015). A global reference for human genetic variation. Nature, 526(7571), 68–74. AFR EAS AMR EUR SAS
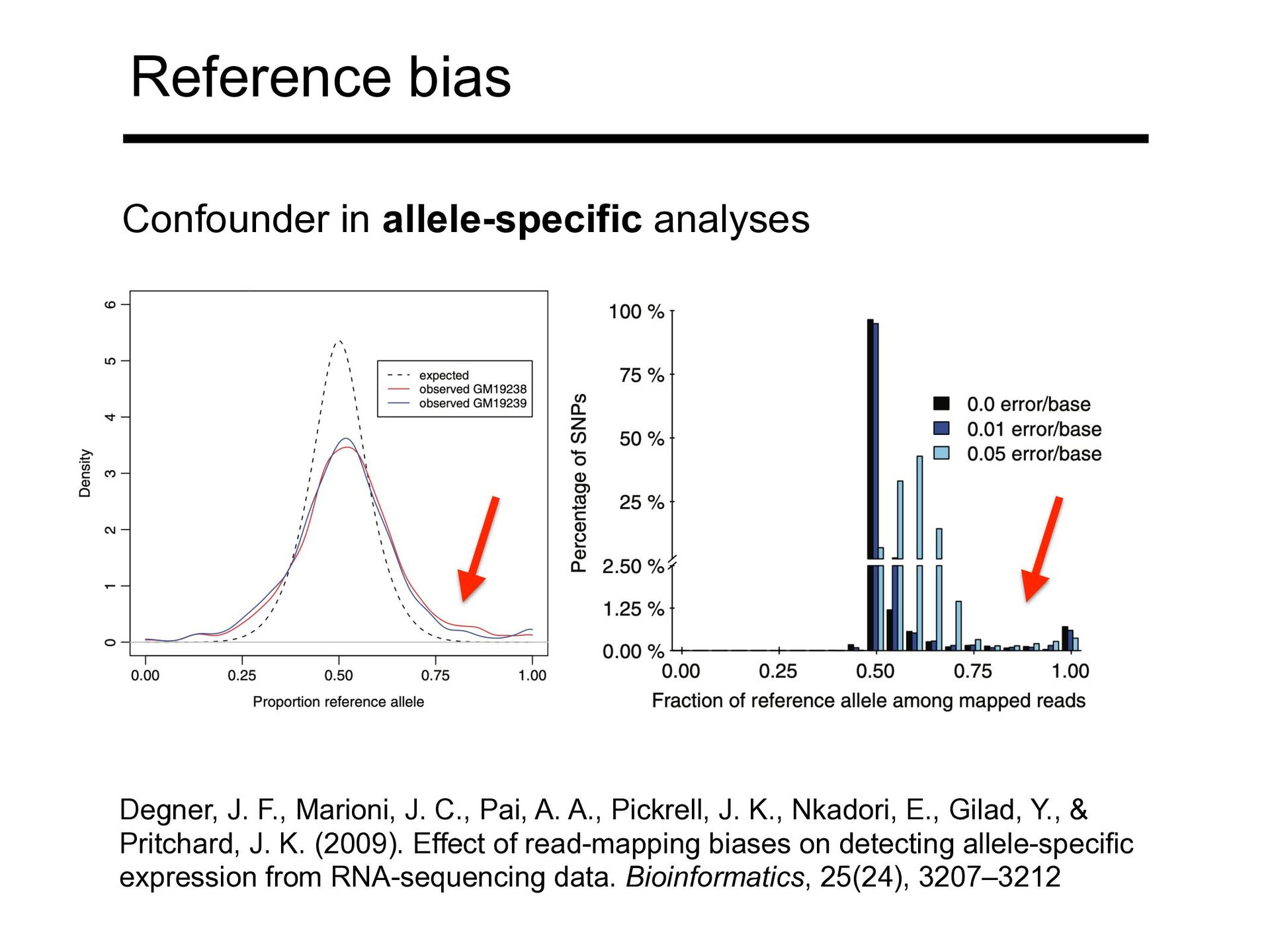
A., Pickrell, J. K., Nkadori, E., Gilad, Y., & Pritchard, J. K. (2009). Effect of read-mapping biases on detecting allele-specific expression from RNA-sequencing data. Bioinformatics, 25(24), 3207–3212 Confounder in allele-specific analyses
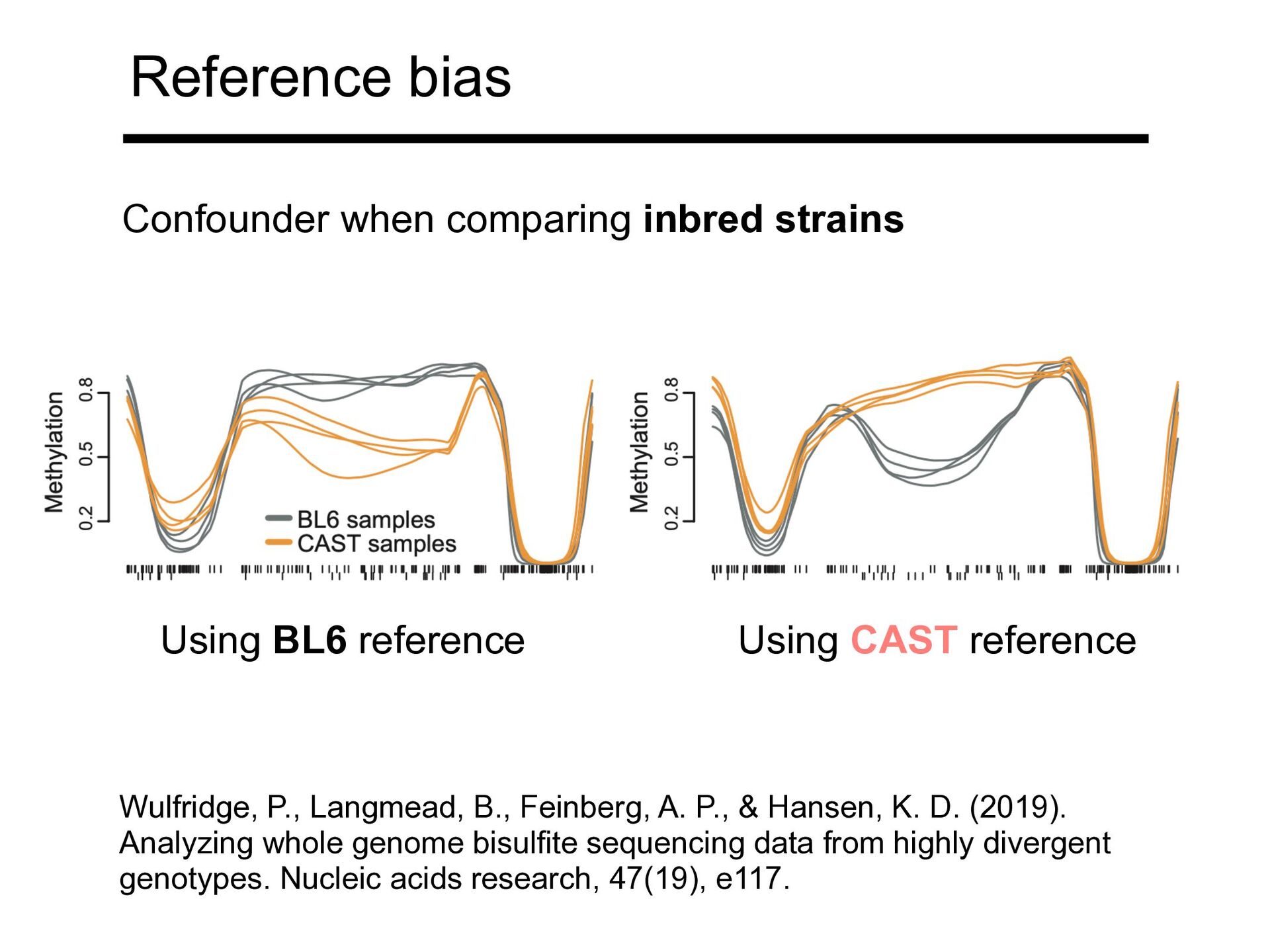
Hansen, K. D. (2019). Analyzing whole genome bisulfite sequencing data from highly divergent genotypes. Nucleic acids research, 47(19), e117. Confounder when comparing inbred strains Using BL6 reference Using CAST reference
& therapeutics are differentially effective by population "...without a more representative reference genome, genetic medicine will never reach some ethnic groups, warns genome scientist Alicia Martin of Mass. General."
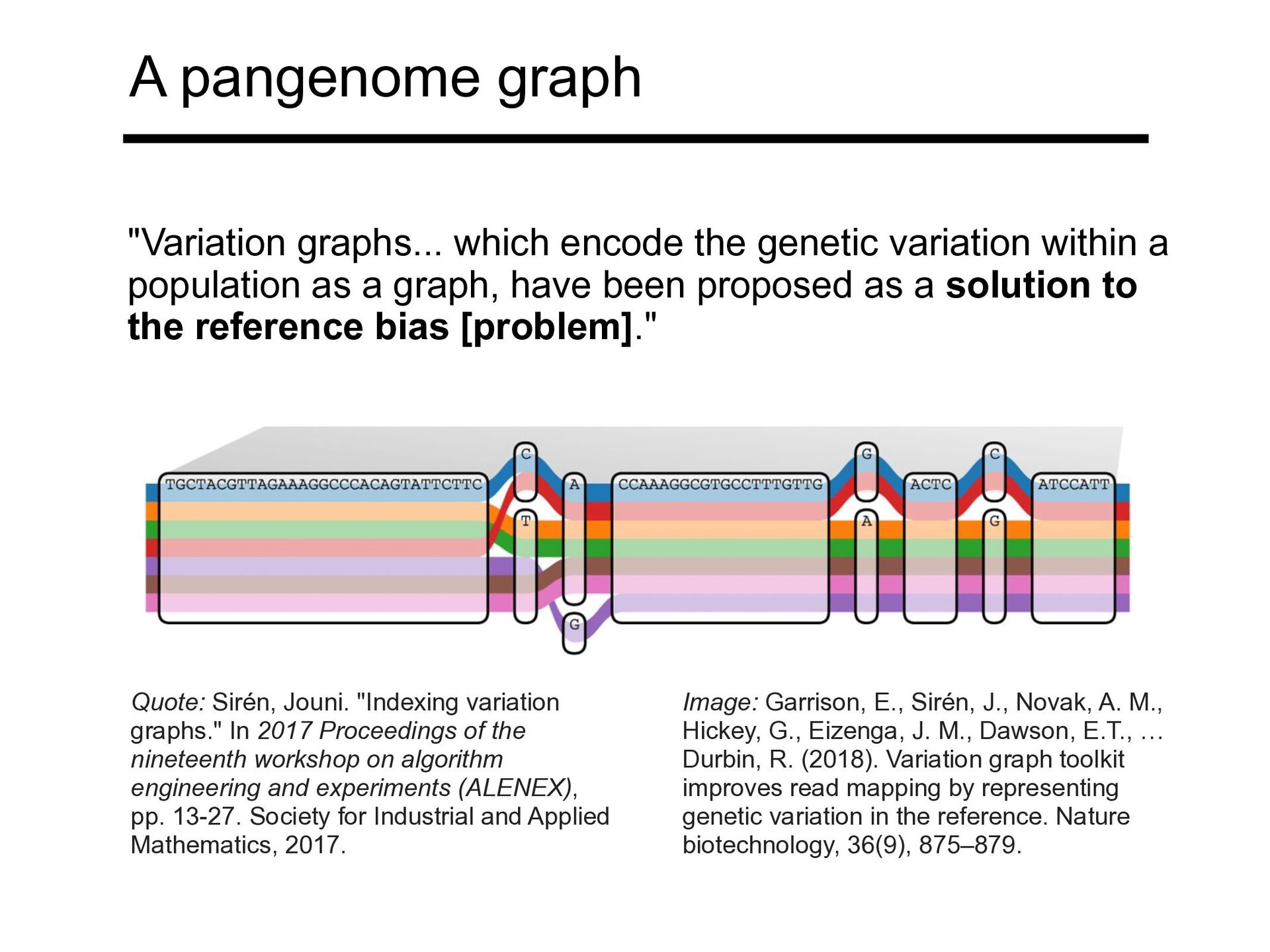
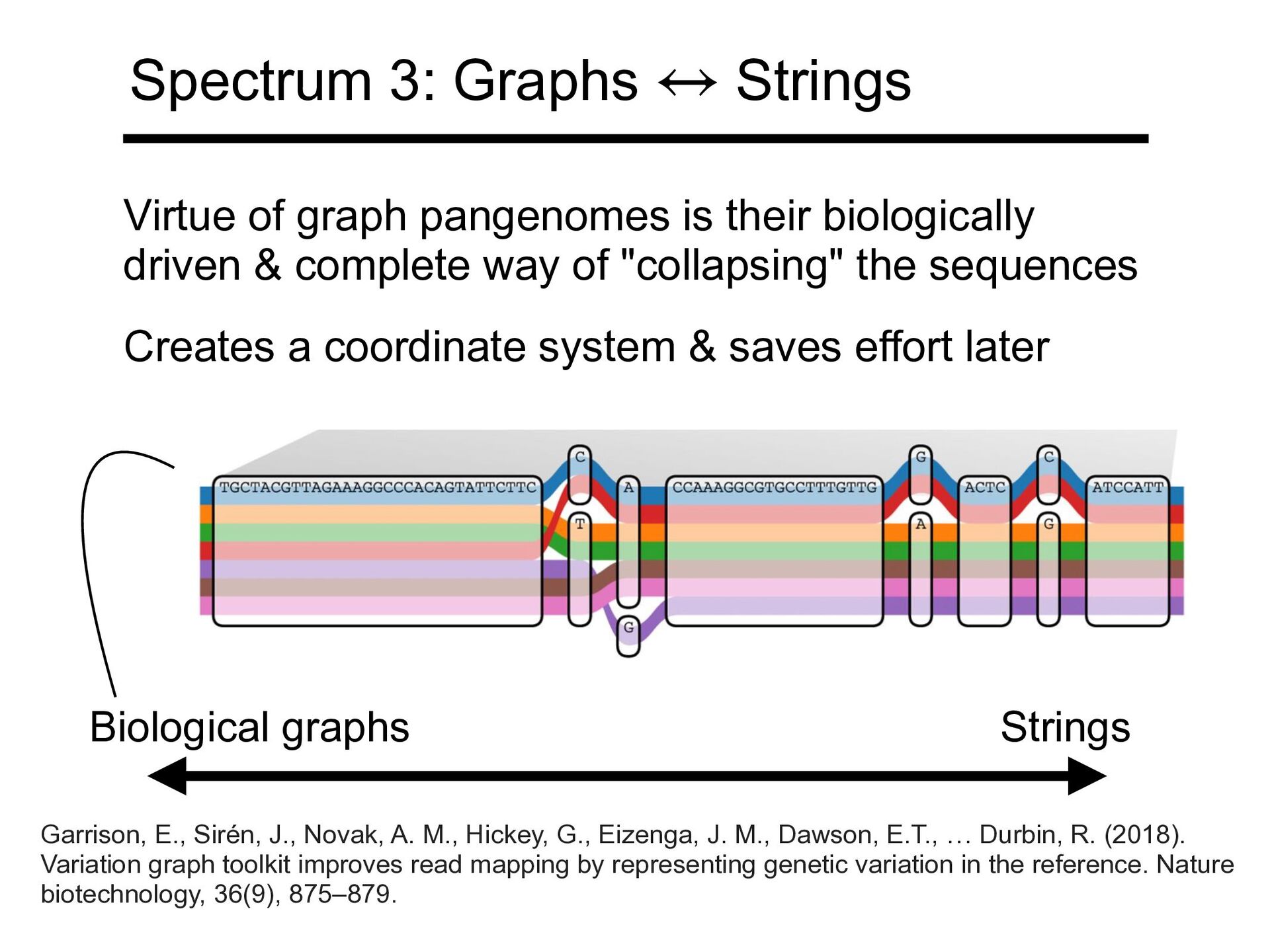
within a population as a graph, have been proposed as a solution to the reference bias [problem]." Quote: Sirén, Jouni. "Indexing variation graphs." In 2017 Proceedings of the nineteenth workshop on algorithm engineering and experiments (ALENEX), pp. 13-27. Society for Industrial and Applied Mathematics, 2017. Image: Garrison, E., Sirén, J., Novak, A. M., Hickey, G., Eizenga, J. M., Dawson, E.T., … Durbin, R. (2018). Variation graph toolkit improves read mapping by representing genetic variation in the reference. Nature biotechnology, 36(9), 875–879.
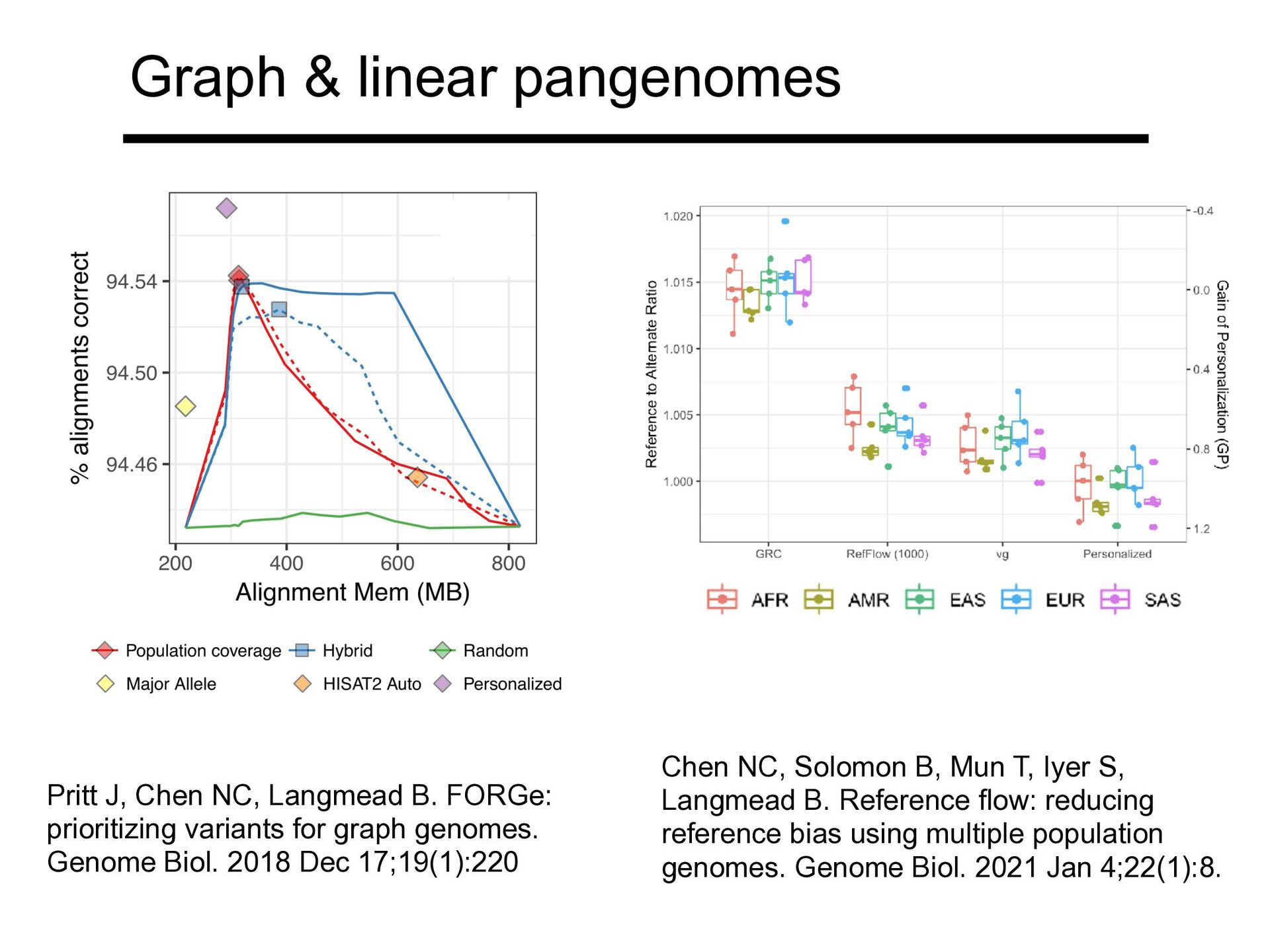
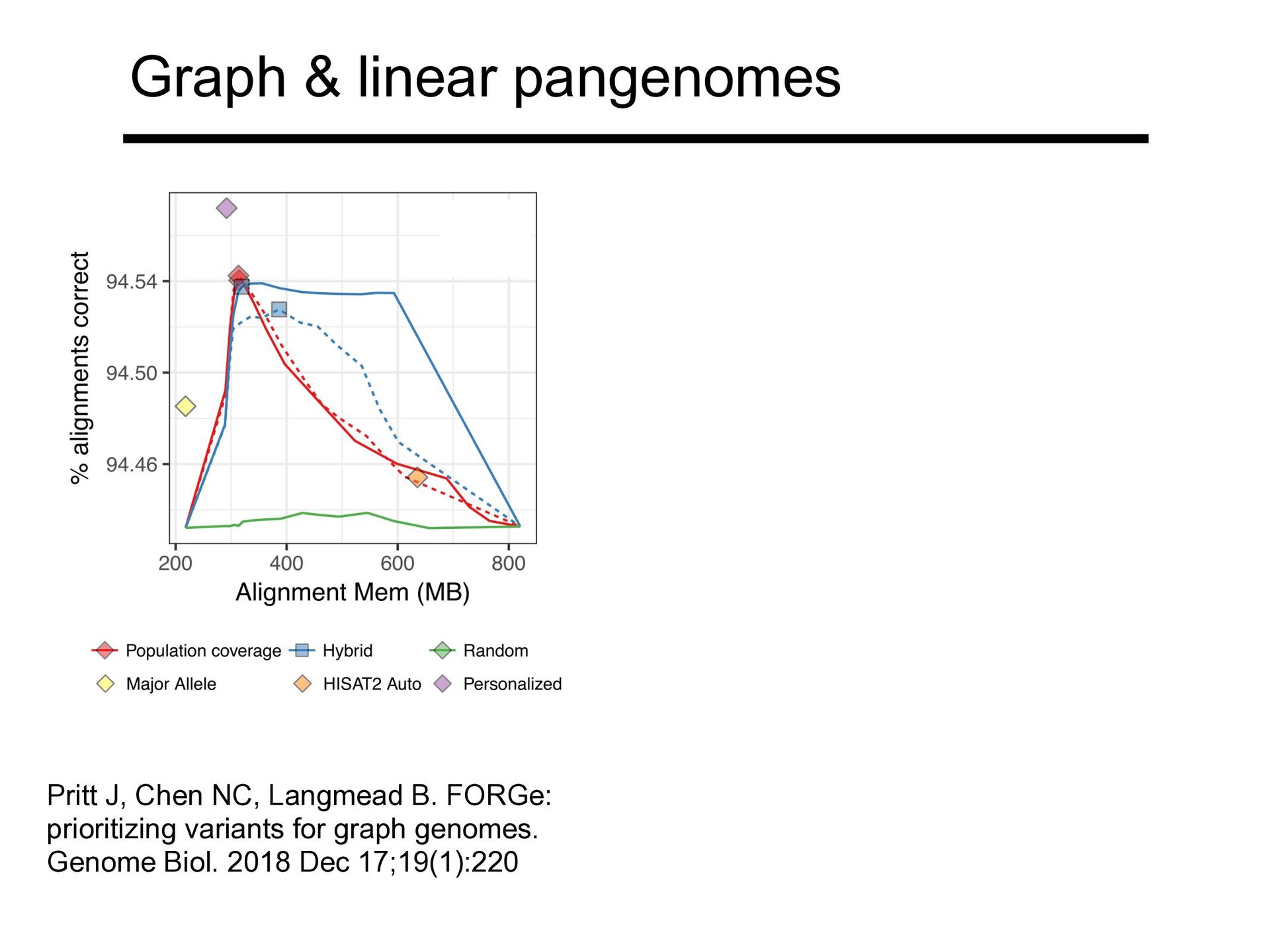
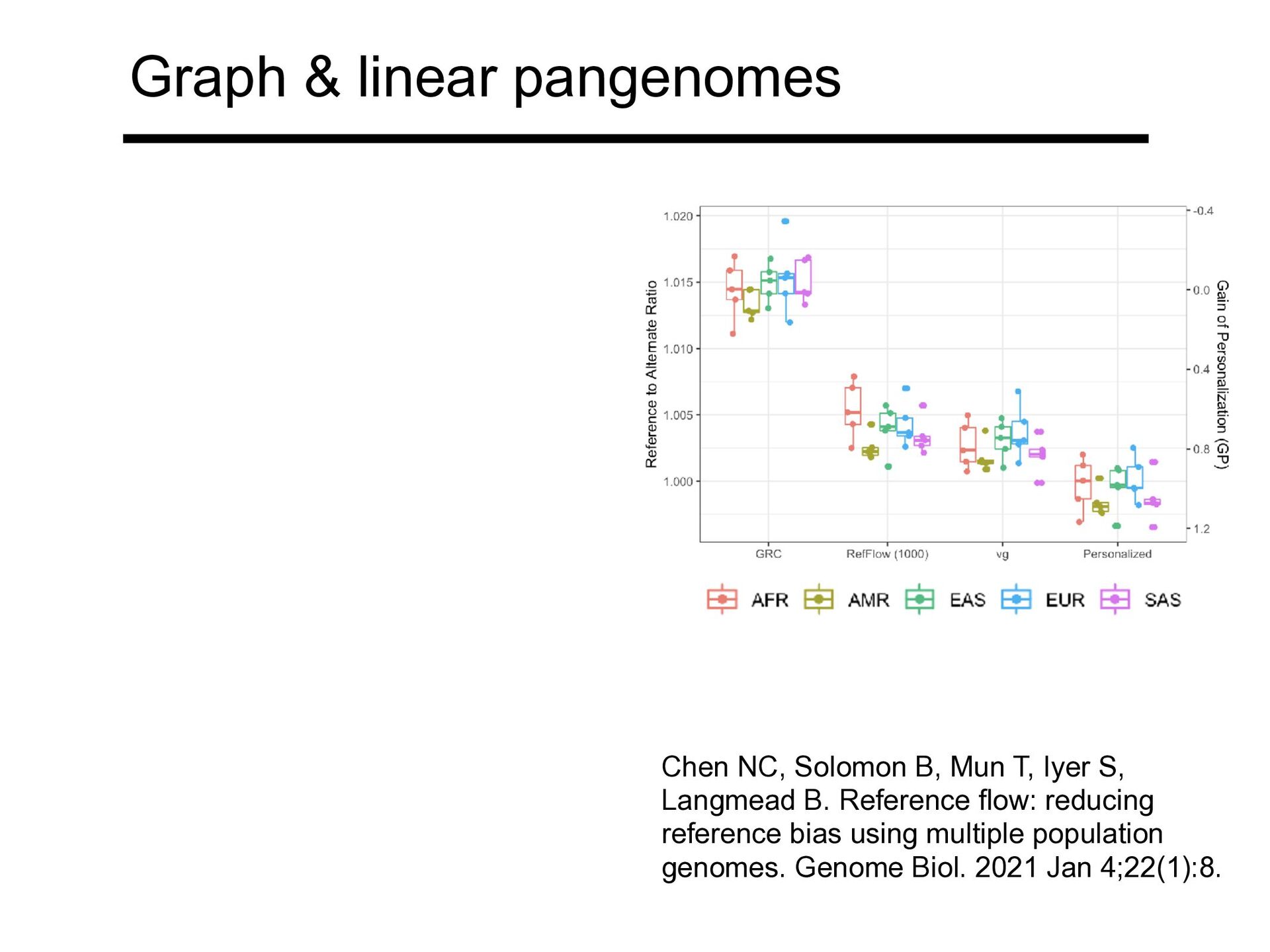
FORGe: prioritizing variants for graph genomes. Genome Biol. 2018 Dec 17;19(1):220 Chen NC, Solomon B, Mun T, Iyer S, Langmead B. Reference flow: reducing reference bias using multiple population genomes. Genome Biol. 2021 Jan 4;22(1):8.
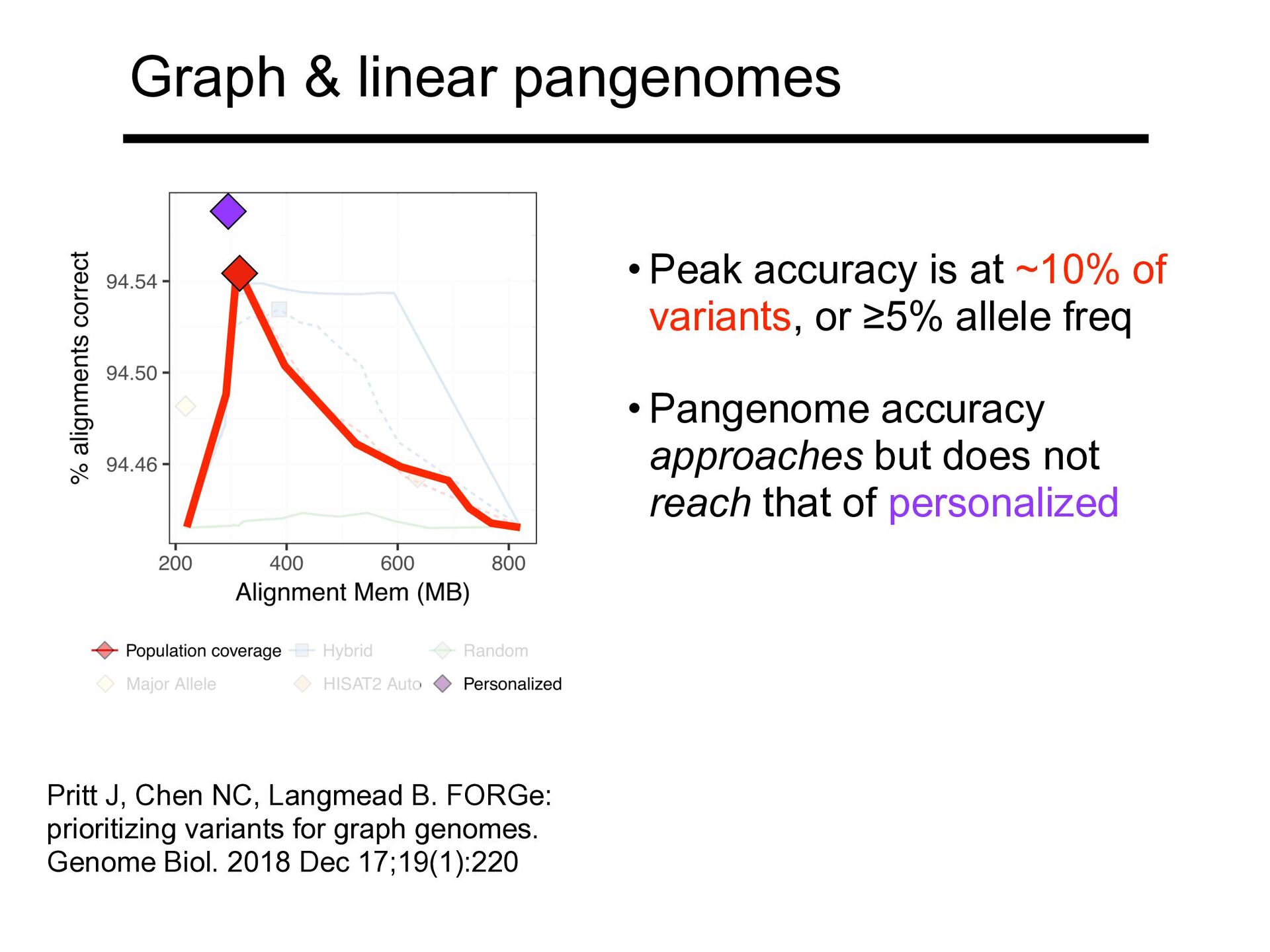
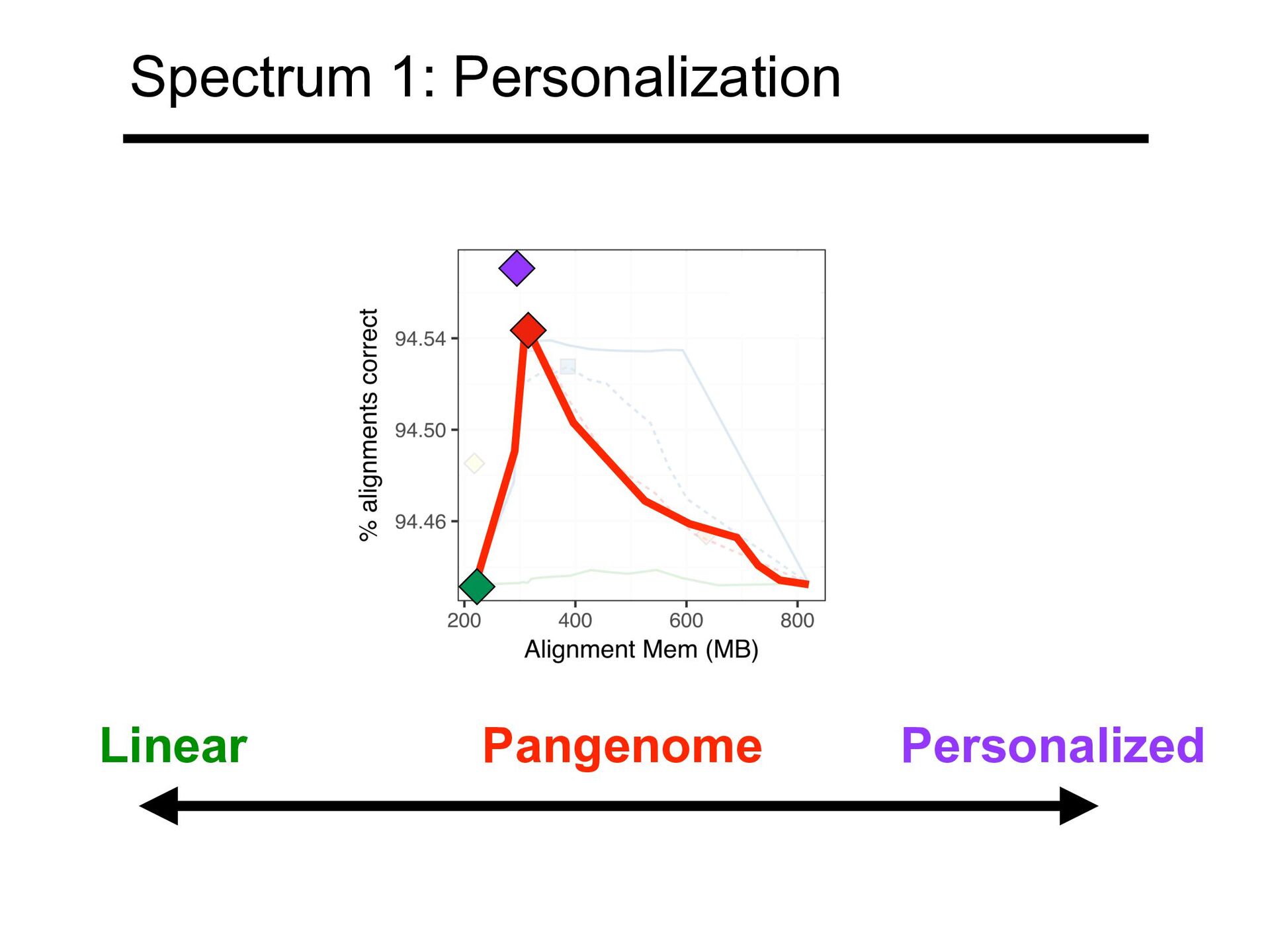
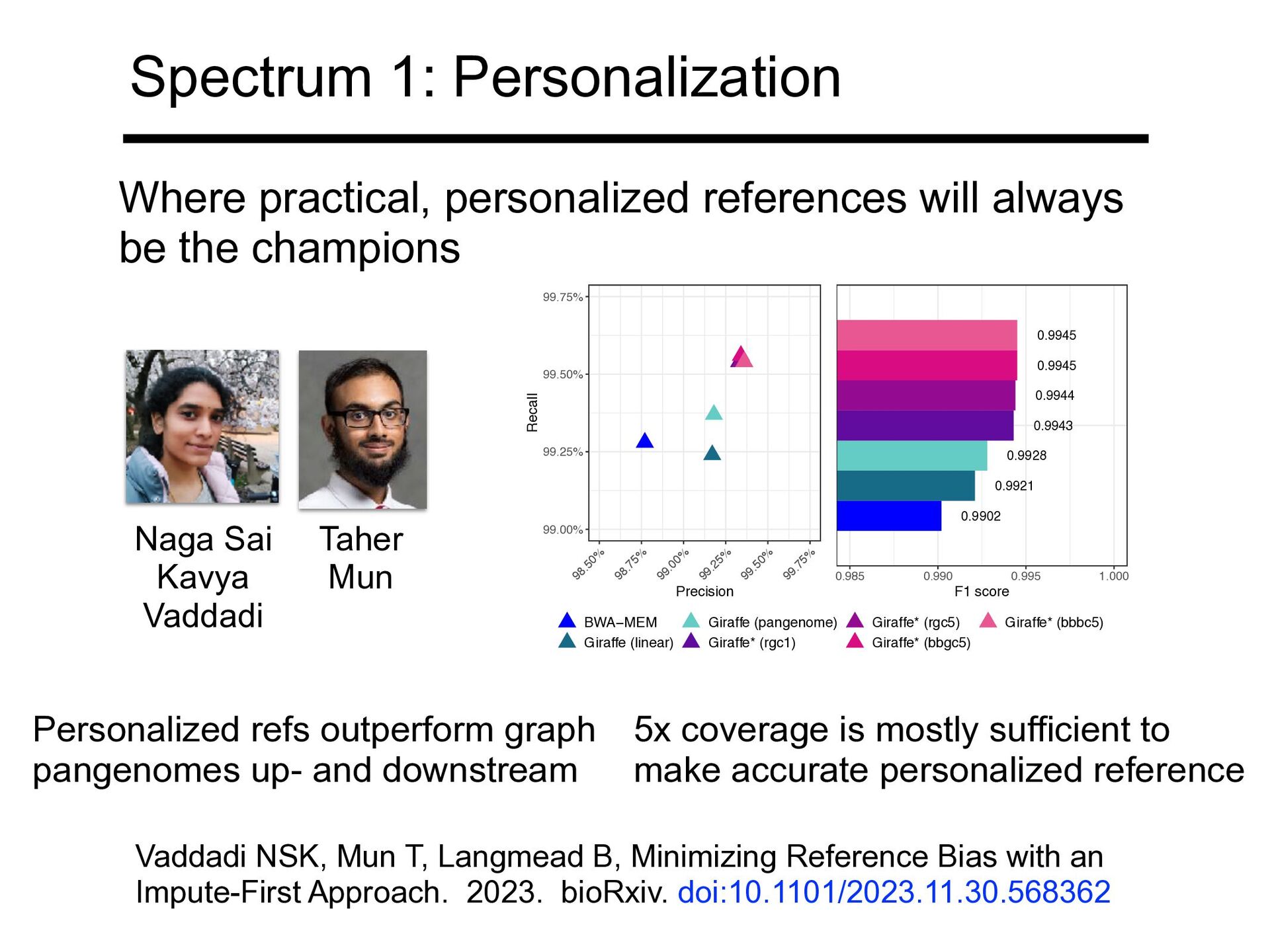
of variants, or ≥5% allele freq • Pangenome accuracy approaches but does not reach that of personalized Pritt J, Chen NC, Langmead B. FORGe: prioritizing variants for graph genomes. Genome Biol. 2018 Dec 17;19(1):220
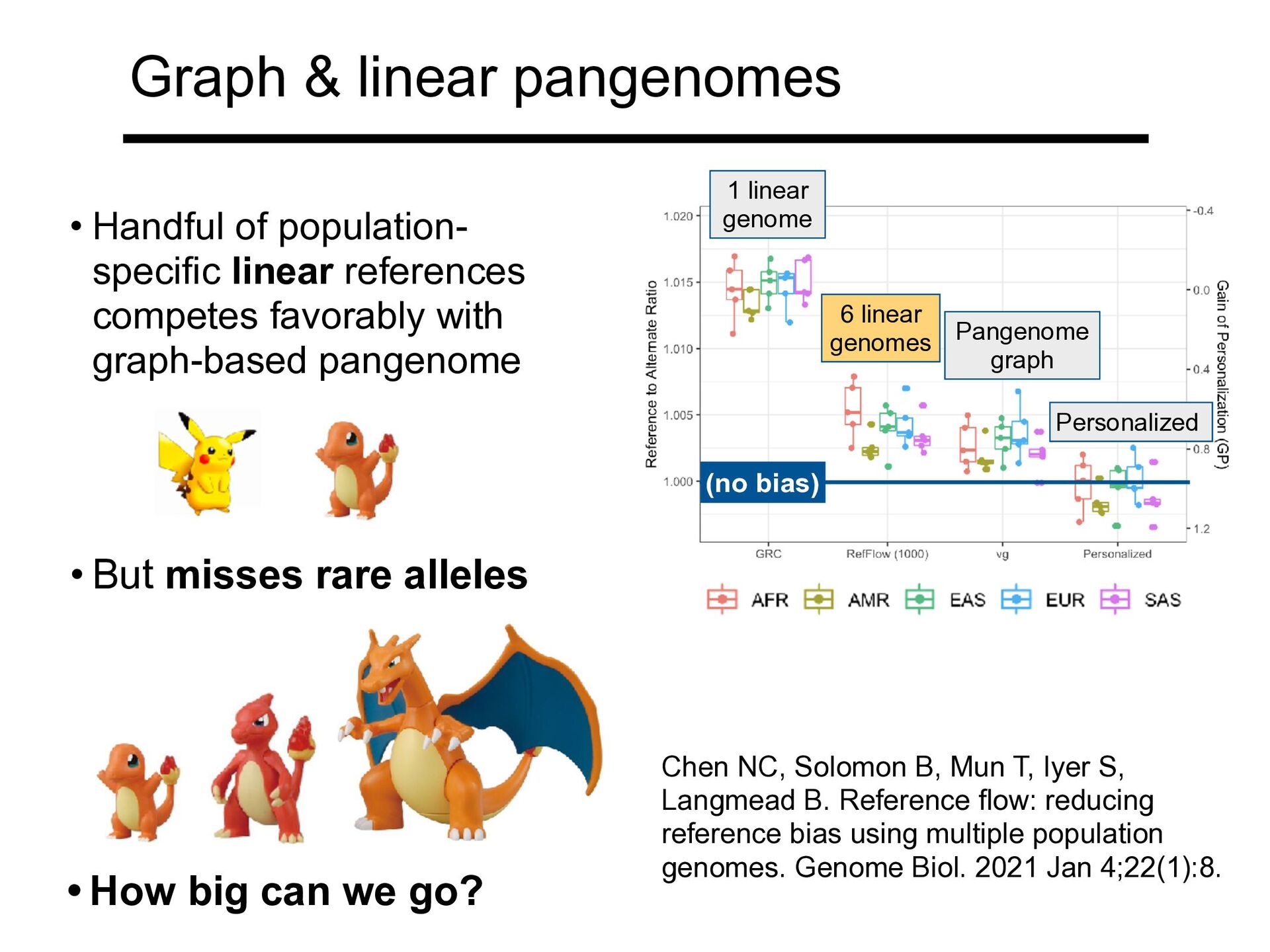
references competes favorably with graph-based pangenome • But misses rare alleles • How big can we go? 1 linear genome (no bias) 6 linear genomes Pangenome graph Personalized Chen NC, Solomon B, Mun T, Iyer S, Langmead B. Reference flow: reducing reference bias using multiple population genomes. Genome Biol. 2021 Jan 4;22(1):8.
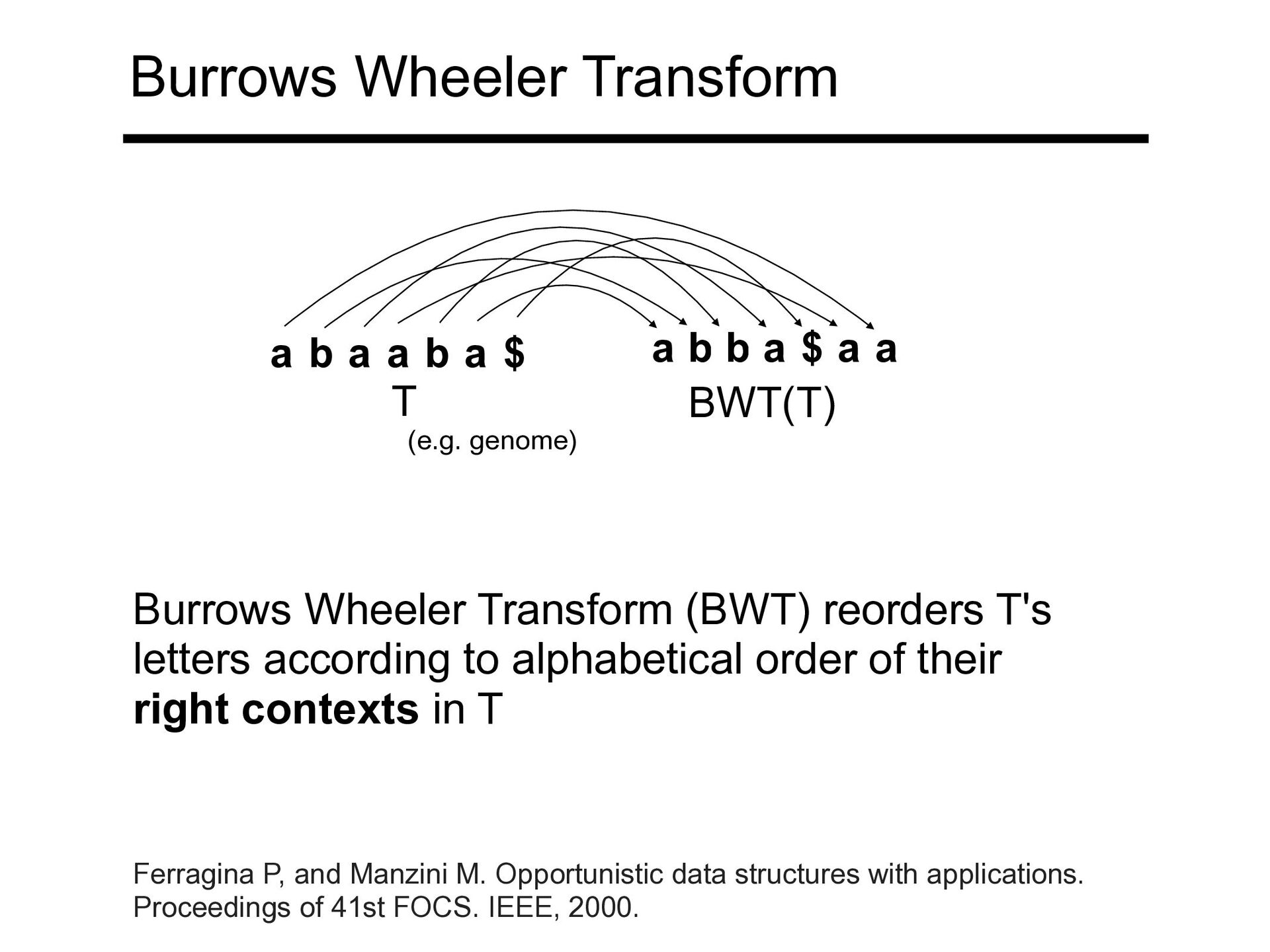
a $ a b b a $ a a Burrows Wheeler Transform (BWT) reorders T's letters according to alphabetical order of their right contexts in T (e.g. genome) Ferragina P, and Manzini M. Opportunistic data structures with applications. Proceedings of 41st FOCS. IEEE, 2000.
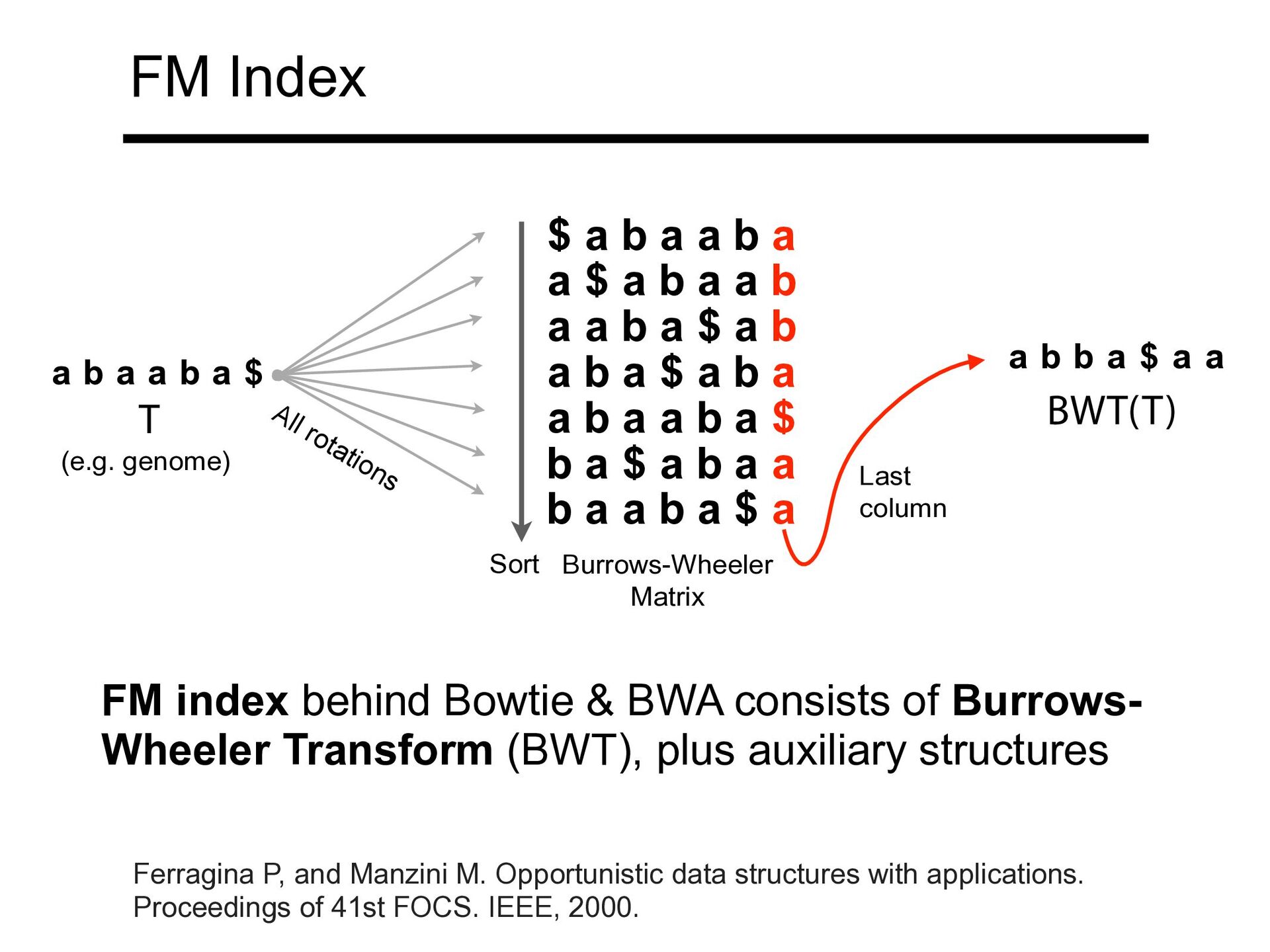
$ a b a a b a a b a $ a b a b a $ a b a a b a a b a $ b a $ a b a a b a a b a $ a T All rotations Sort BWT(T) Last column Burrows-Wheeler Matrix a b a a b a $ a b b a $ a a FM index behind Bowtie & BWA consists of Burrows- Wheeler Transform (BWT), plus auxiliary structures (e.g. genome) Ferragina P, and Manzini M. Opportunistic data structures with applications. Proceedings of 41st FOCS. IEEE, 2000.
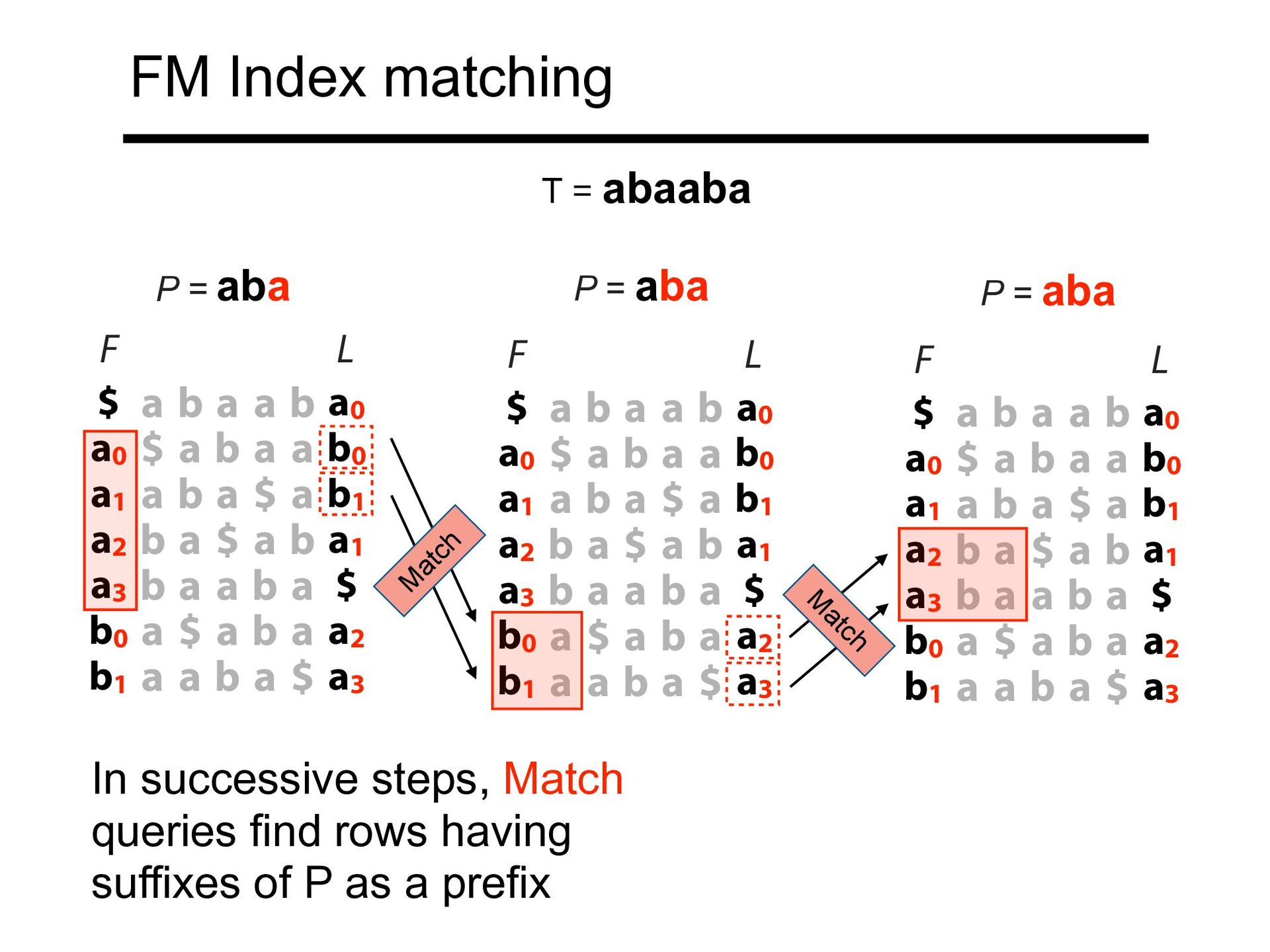
a0 $ a b a a b0 a1 a b a $ a b1 a2 b a $ a b a1 a3 b a a b a $ b0 a $ a b a a2 b1 a a b a $ a3 F L P = aba aba L $ a b a a b a0 a0 $ a b a a b0 a1 a b a $ a b1 a2 b a $ a b a1 a3 b a a b a $ b0 a $ a b a a2 b1 a a b a $ a3 F P = aba $ a b a a b a0 a0 $ a b a a b0 a1 a b a $ a b1 a2 b a $ a b a1 a3 b a a b a $ b0 a $ a b a a2 b1 a a b a $ a3 F L P = aba T = abaaba M atch M atch In successive steps, Match queries find rows having suffixes of P as a prefix
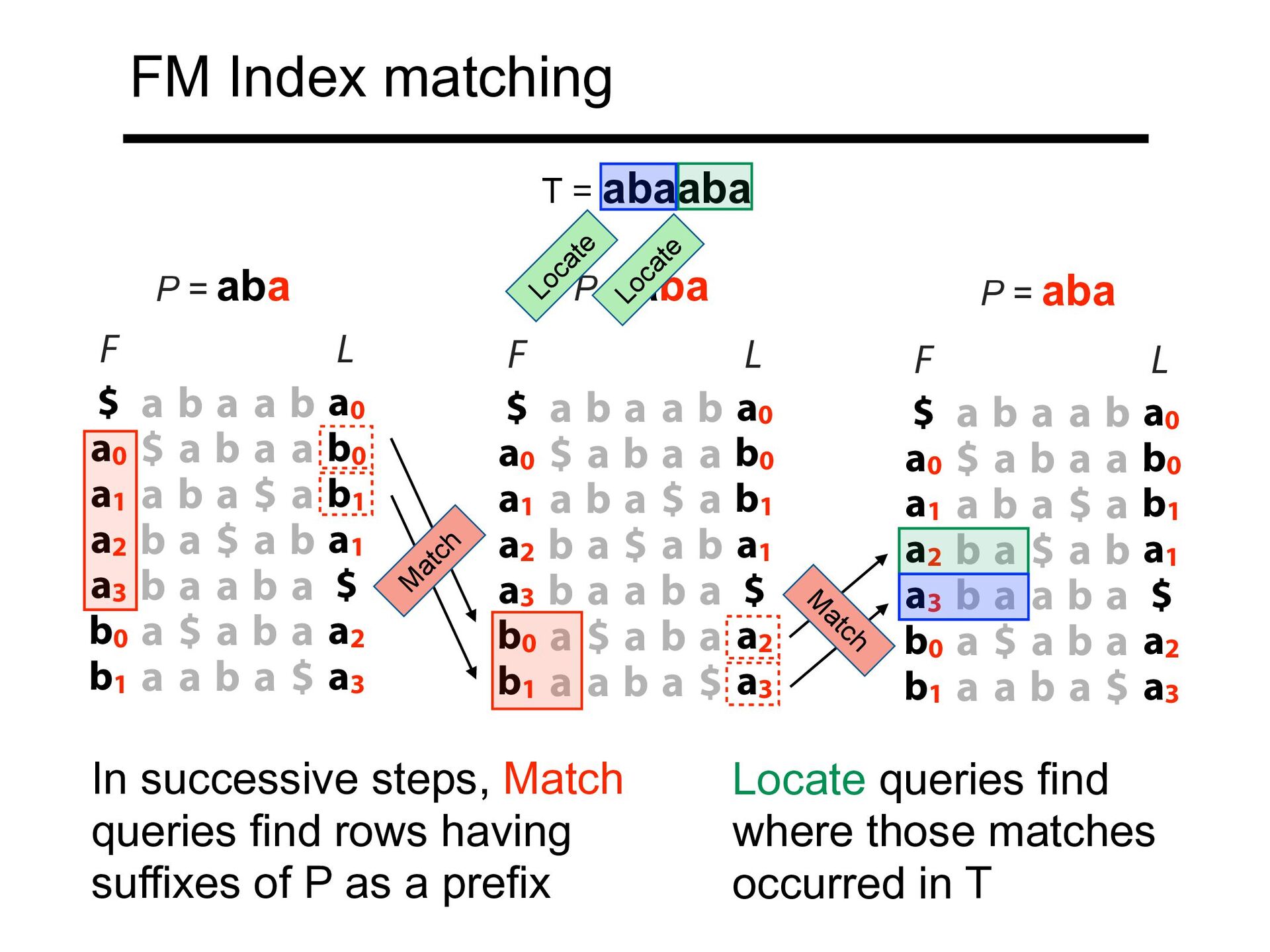
FM Index matching $ a b a a b a0 a0 $ a b a a b0 a1 a b a $ a b1 a2 b a $ a b a1 a3 b a a b a $ b0 a $ a b a a2 b1 a a b a $ a3 F L L $ a b a a b a0 a0 $ a b a a b0 a1 a b a $ a b1 a2 b a $ a b a1 a3 b a a b a $ b0 a $ a b a a2 b1 a a b a $ a3 F In successive steps, Match queries find rows having suffixes of P as a prefix $ a b a a b a0 a0 $ a b a a b0 a1 a b a $ a b1 a2 b a $ a b a1 a3 b a a b a $ b0 a $ a b a a2 b1 a a b a $ a3 F L T = abaaba M atch M atch Locate Locate Locate queries find where those matches occurred in T
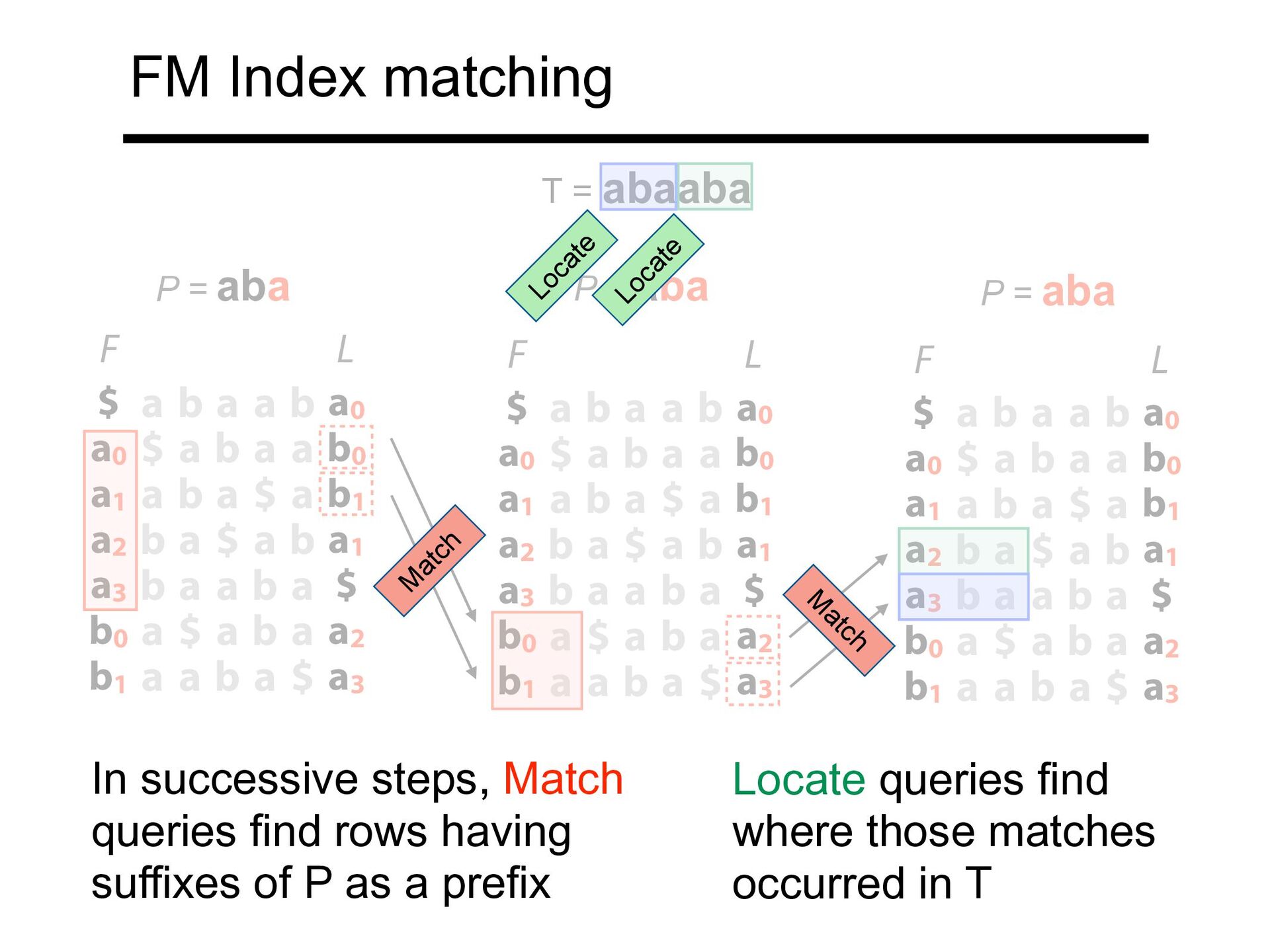
FM Index matching $ a b a a b a0 a0 $ a b a a b0 a1 a b a $ a b1 a2 b a $ a b a1 a3 b a a b a $ b0 a $ a b a a2 b1 a a b a $ a3 F L L $ a b a a b a0 a0 $ a b a a b0 a1 a b a $ a b1 a2 b a $ a b a1 a3 b a a b a $ b0 a $ a b a a2 b1 a a b a $ a3 F $ a b a a b a0 a0 $ a b a a b0 a1 a b a $ a b1 a2 b a $ a b a1 a3 b a a b a $ b0 a $ a b a a2 b1 a a b a $ a3 F L T = abaaba M atch M atch Locate Locate In successive steps, Match queries find rows having suffixes of P as a prefix Locate queries find where those matches occurred in T
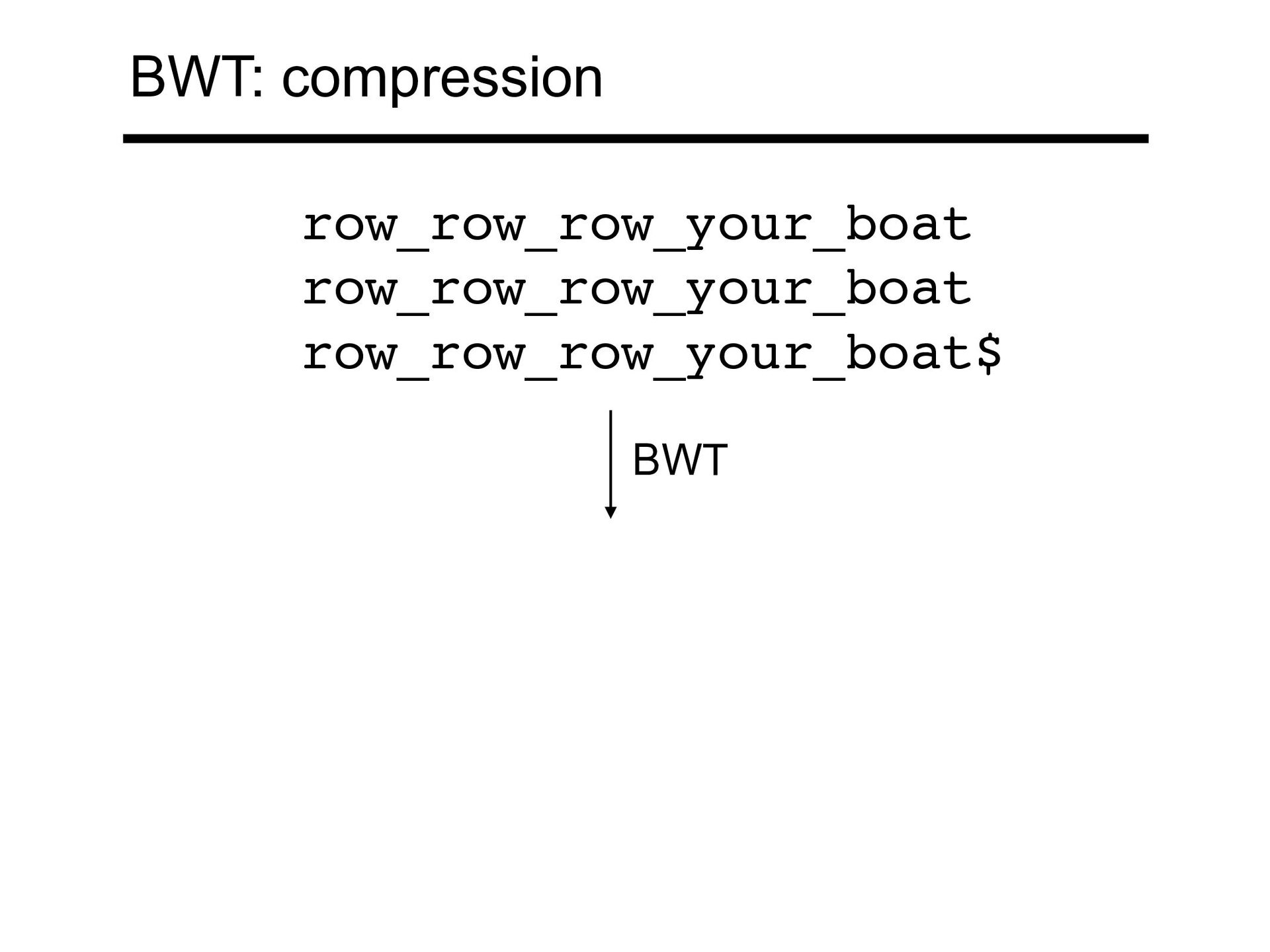
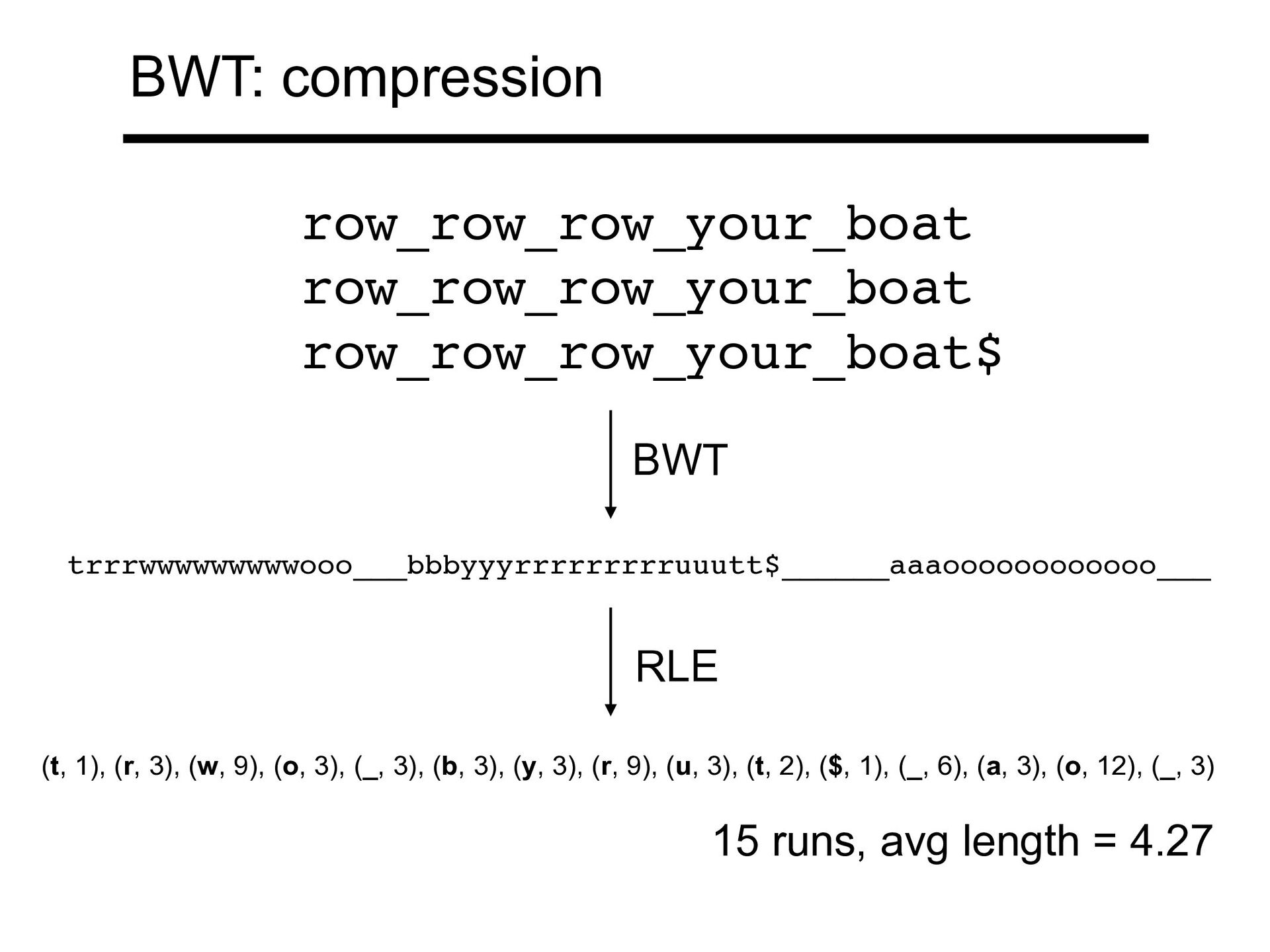
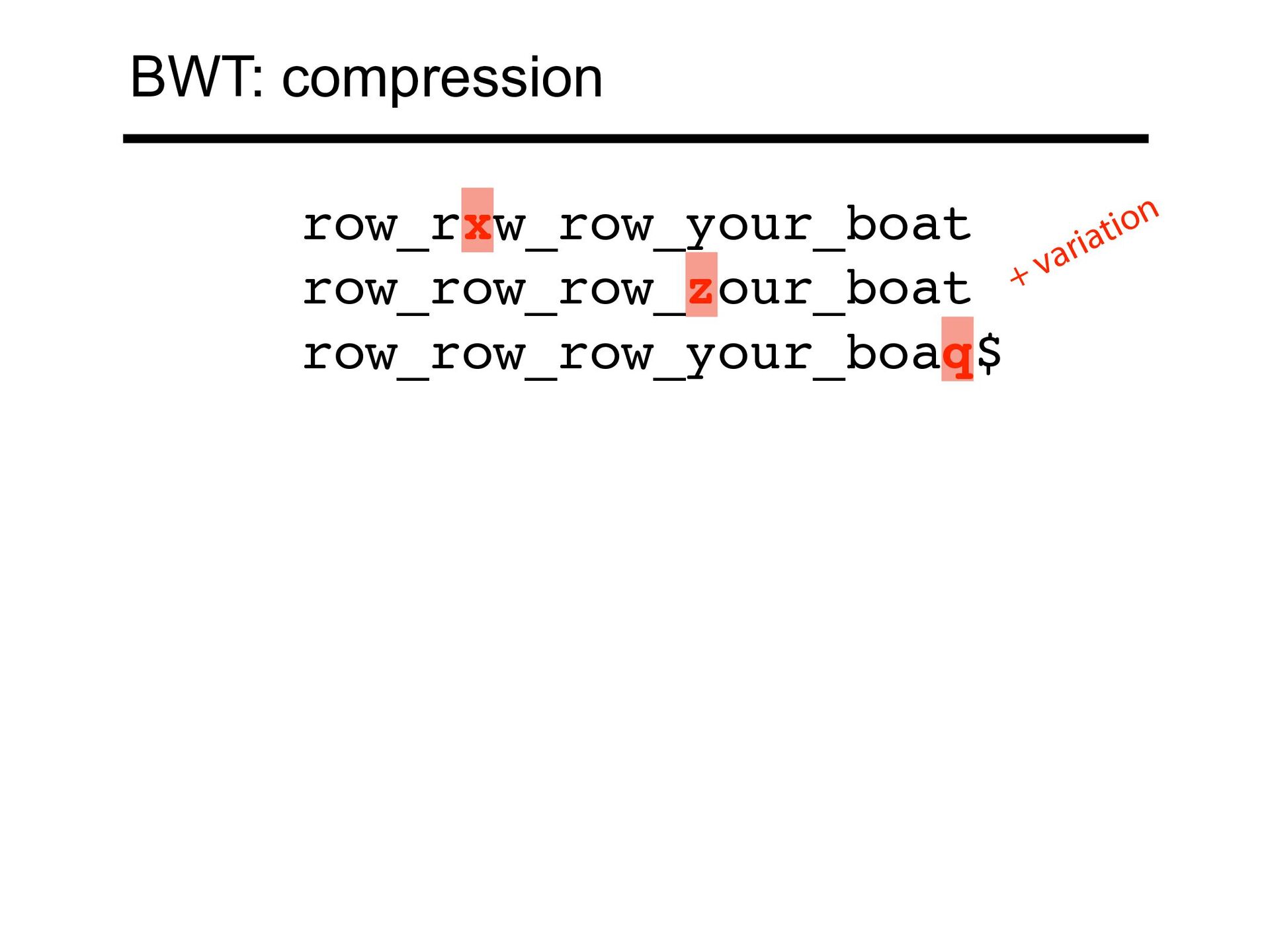
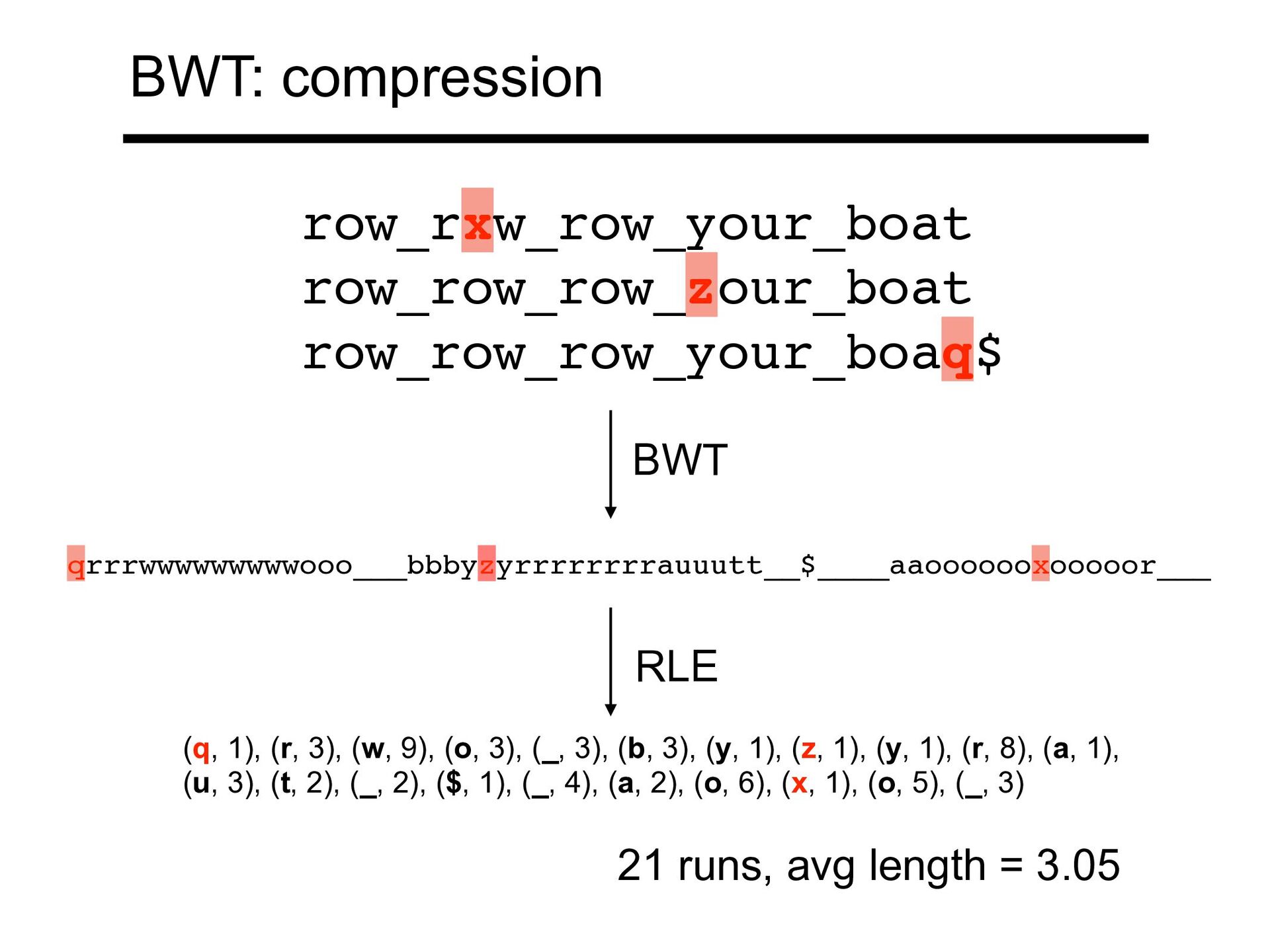
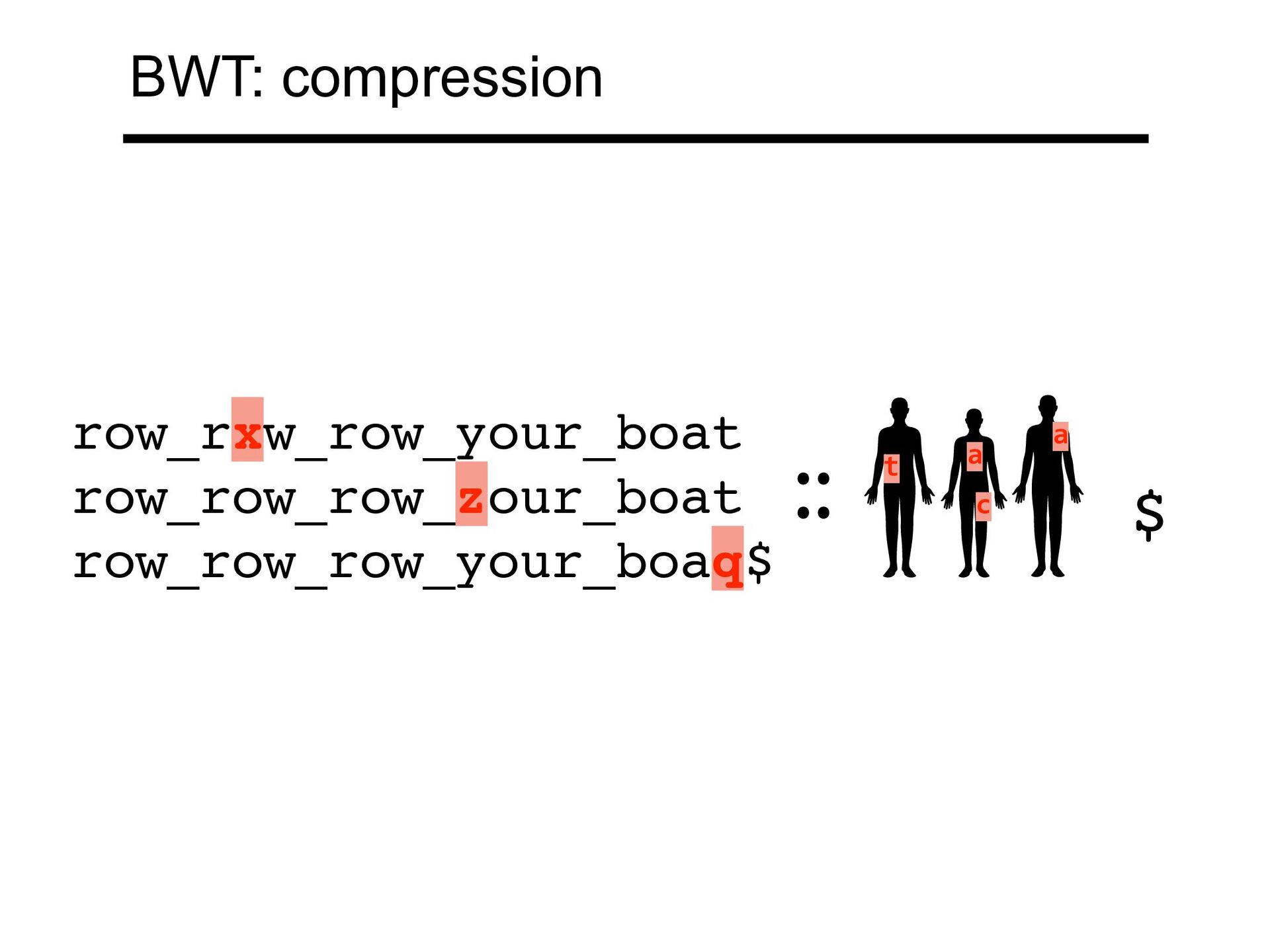
ectangle tends to be preceded by r These rs come together in a BWT run T rectangular_rectangle_divided_into_rectangles$ BWT(T) sedrotttleeeei_lrrrdlnnnv_duggaaaita__$ecccngi BWT: compression
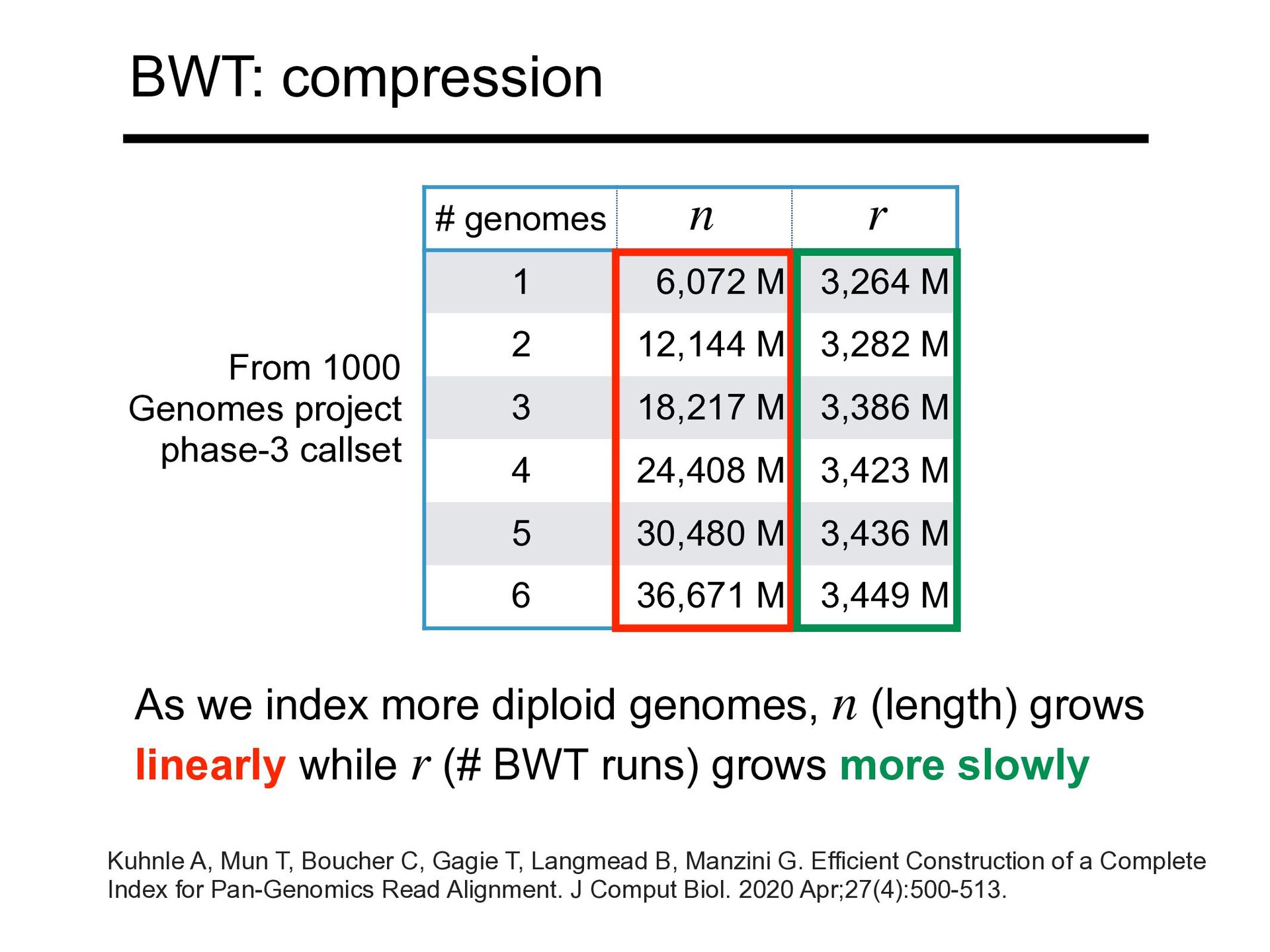
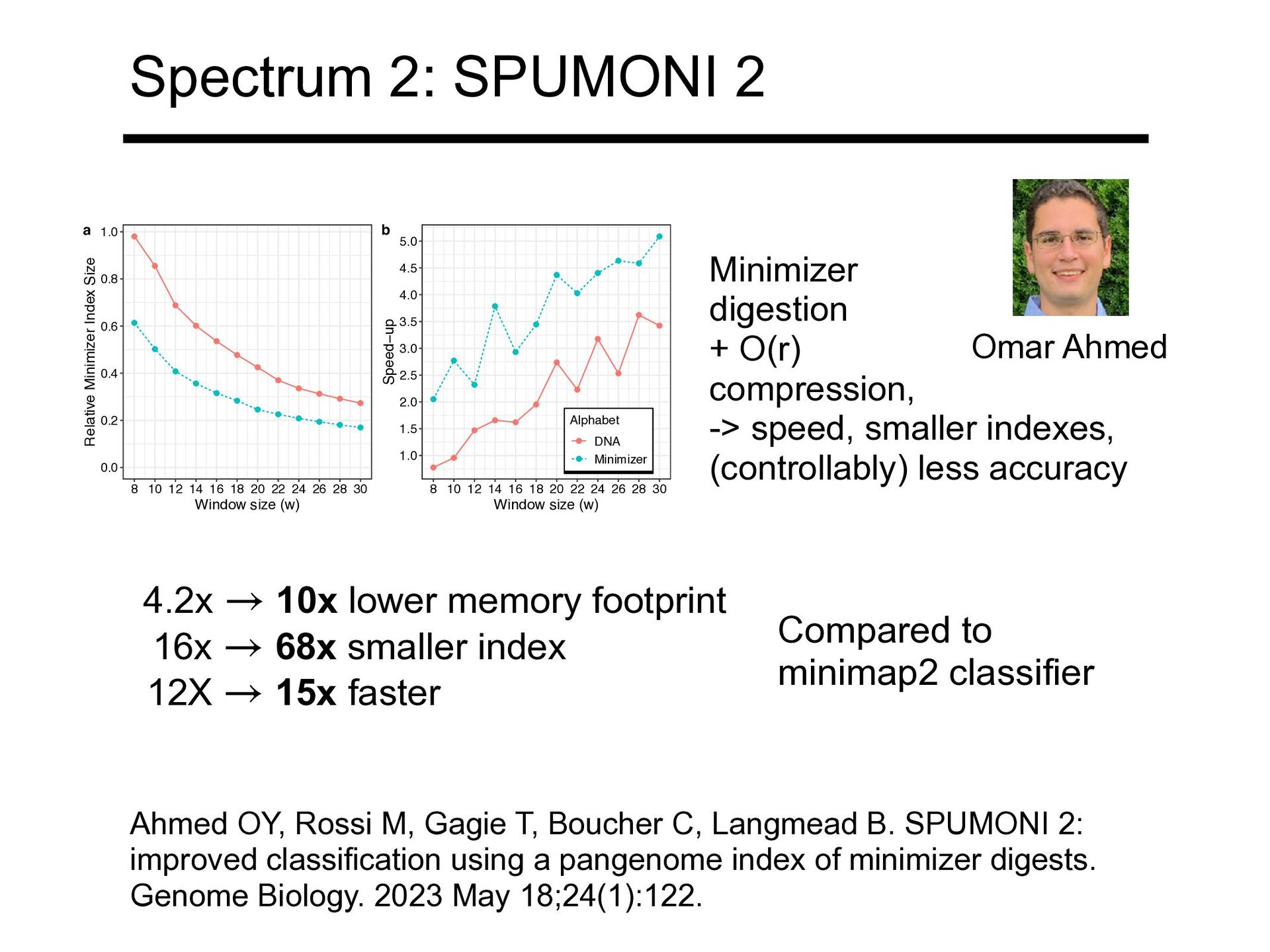
3,282 M 3 18,217 M 3,386 M 4 24,408 M 3,423 M 5 30,480 M 3,436 M 6 36,671 M 3,449 M n r As we index more diploid genomes, (length) grows linearly while (# BWT runs) grows more slowly n r From 1000 Genomes project phase-3 callset Kuhnle A, Mun T, Boucher C, Gagie T, Langmead B, Manzini G. Efficient Construction of a Complete Index for Pan-Genomics Read Alignment. J Comput Biol. 2020 Apr;27(4):500-513. BWT: compression
applications. Proceedings of 41st FOCS. IEEE, 2000. Compressed indexing Match Locate FM Index (2000) Where = # characters, is # BWT runs n r O(n) O(n) Needed: indexes that grow with i.e. use space and handle our favorite queries r O(r)
O(n) O(n) RLFM: Mäkinen V, and Navarro G. Succinct suffix arrays based on run-length encoding. Annual Symposium on CPM. Springer, Berlin, Heidelberg. 2005. pp45–56. O(r) O(n) Needed: indexes that grow with i.e. use space and handle our favorite queries r O(r) FM: Ferragina P, and Manzini M. Opportunistic data structures with applications. Proceedings of 41st FOCS. IEEE, 2000. Where = # characters, is # BWT runs n r
indexing in BWT-runs bounded space. Proceedings of 29th SODA, ACM-SIAM. 2018. pp1459—1477. RLFM: Mäkinen V, and Navarro G. Succinct suffix arrays based on run-length encoding. Annual Symposium on CPM. Springer, Berlin, Heidelberg. 2005. pp45–56. FM: Ferragina P, and Manzini M. Opportunistic data structures with applications. Proceedings of 41st FOCS. IEEE, 2000. Compressed indexing Match Locate FM Index (2000) RLFM Index (2005) r-index (2018) O(n) O(r) O(r) O(n) O(n) O(r) ✅ Needed: indexes that grow with i.e. use space and handle our favorite queries r O(r) Where = # characters, is # BWT runs n r
we can index a human pangenome and compete with Bowtie Christina Boucher Travis Gagie Alan Kuhnle Giovanni Manzini Kuhnle A, Mun T, Boucher C, Gagie T, Langmead B, Manzini G. Efficient Construction of a Complete Index for Pan-Genomics Read Alignment. J Comput Biol. 2020 Apr;27(4):500-513. Taher Mun Boucher C, Gagie T, Kuhnle A, Langmead B, Manzini G, Mun T. Prefix-free parsing for building big BWTs. Algorithms Mol Biol. 2019 May 24;14:13.
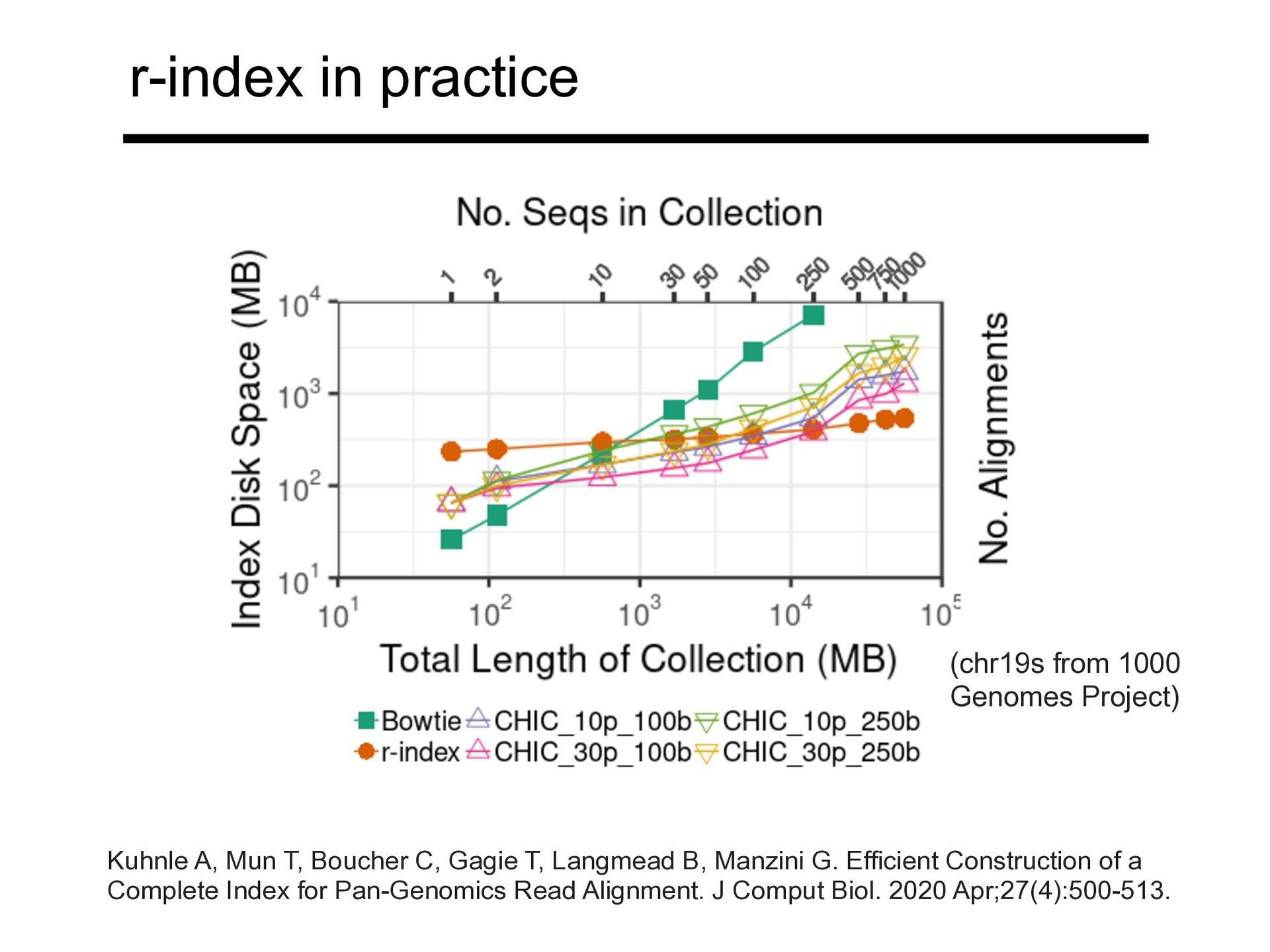
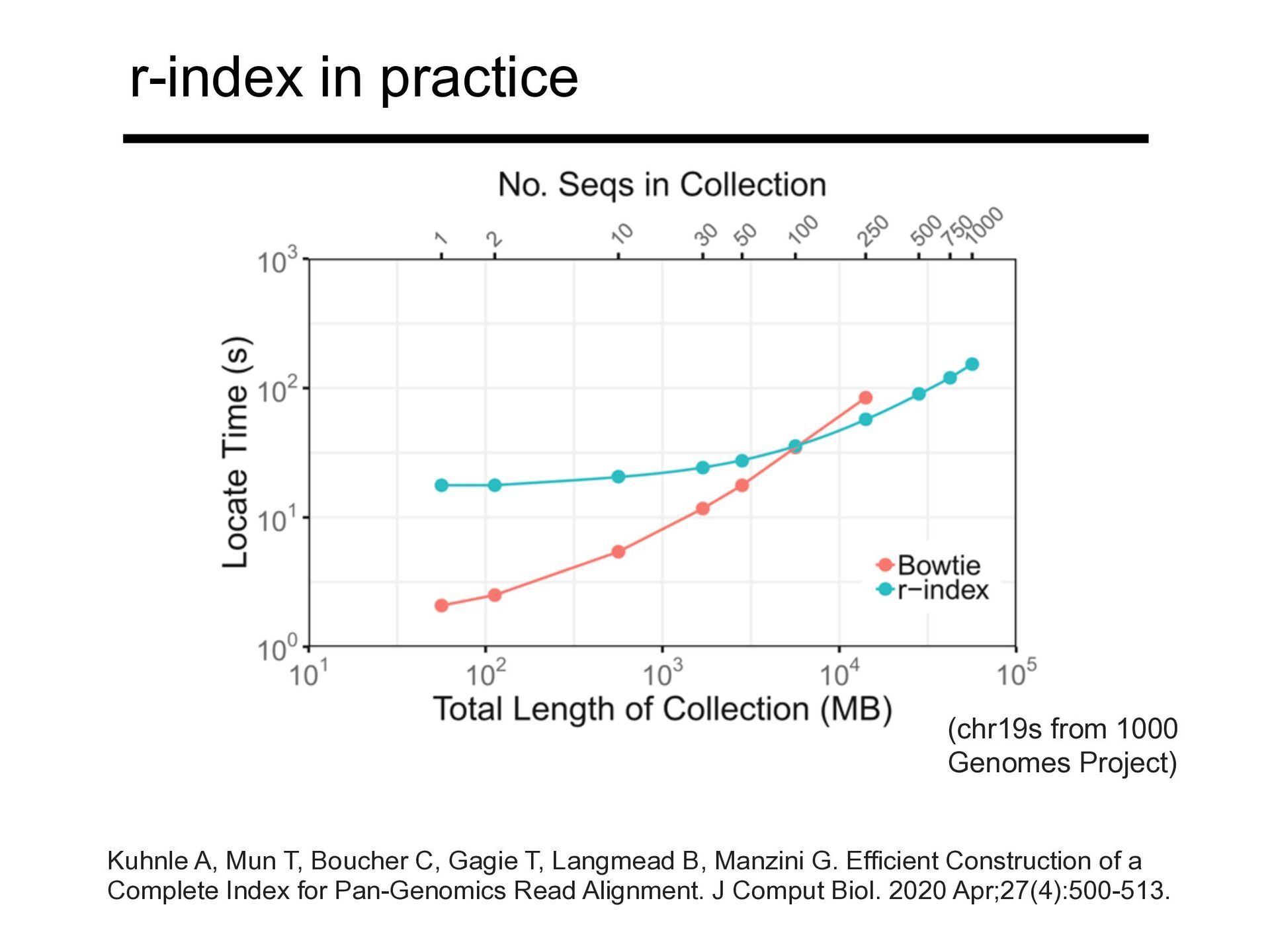
T, Langmead B, Manzini G. Efficient Construction of a Complete Index for Pan-Genomics Read Alignment. J Comput Biol. 2020 Apr;27(4):500-513. (chr19s from 1000 Genomes Project)
Mun T, Boucher C, Gagie T, Langmead B, Manzini G. Efficient Construction of a Complete Index for Pan-Genomics Read Alignment. J Comput Biol. 2020 Apr;27(4):500-513.
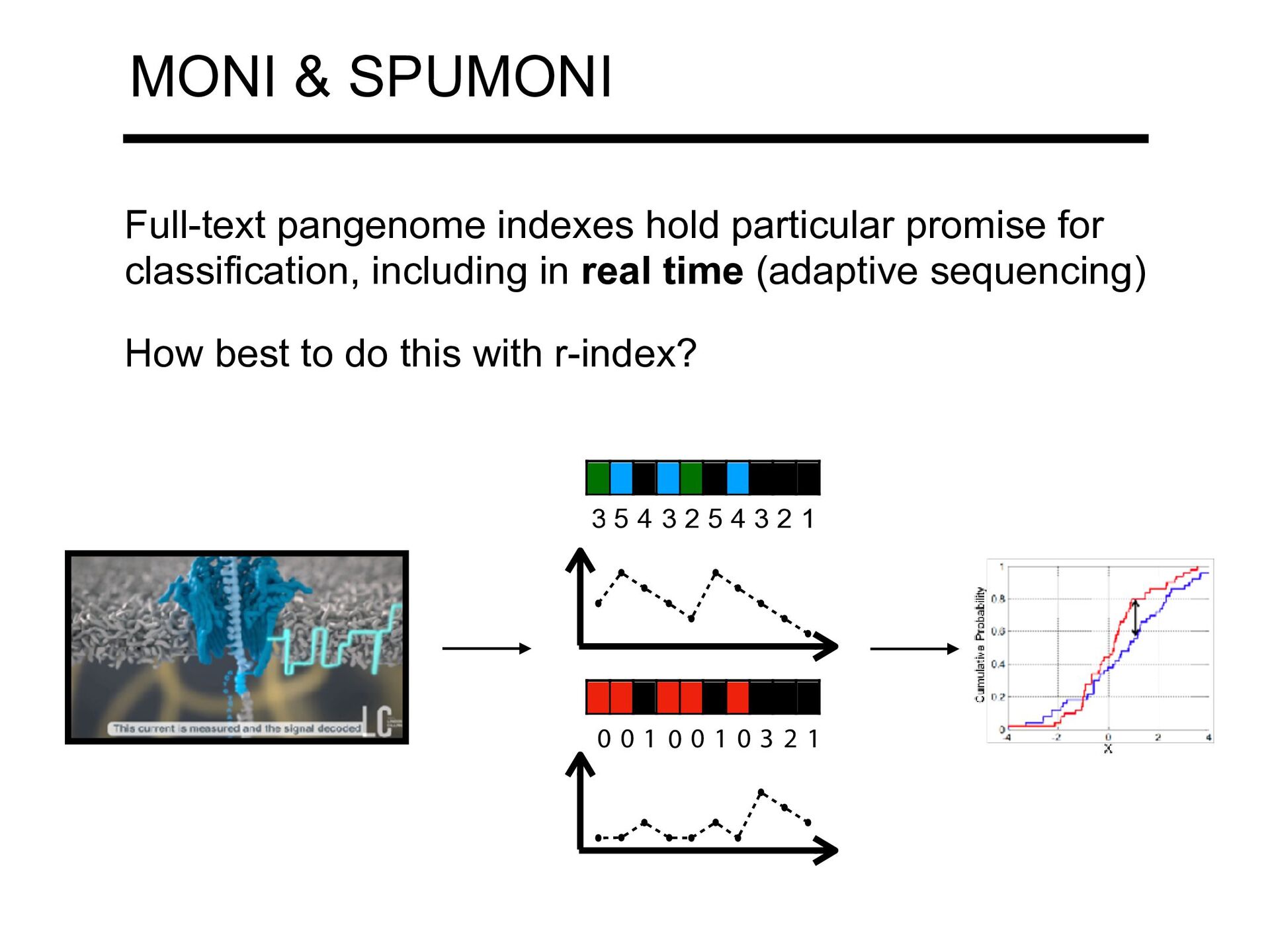
b r a d a d P : c a r a d a d a b r d M S : 2 1 5 4 3 5 4 3 2 1 1 MONI Max Rossi MONI extends r-index to compute matching statistics (& MEMs) = length of the longest prefix of the th suffix that occurs in T MS[i] i 6 5 4 3 2 1 Rossi M, Oliva M, Langmead B, Gagie T, Boucher C. MONI: A Pangenomic Index for Finding Maximal Exact Matches. J Comput Biol. 2022 Feb;29(2):169-187.
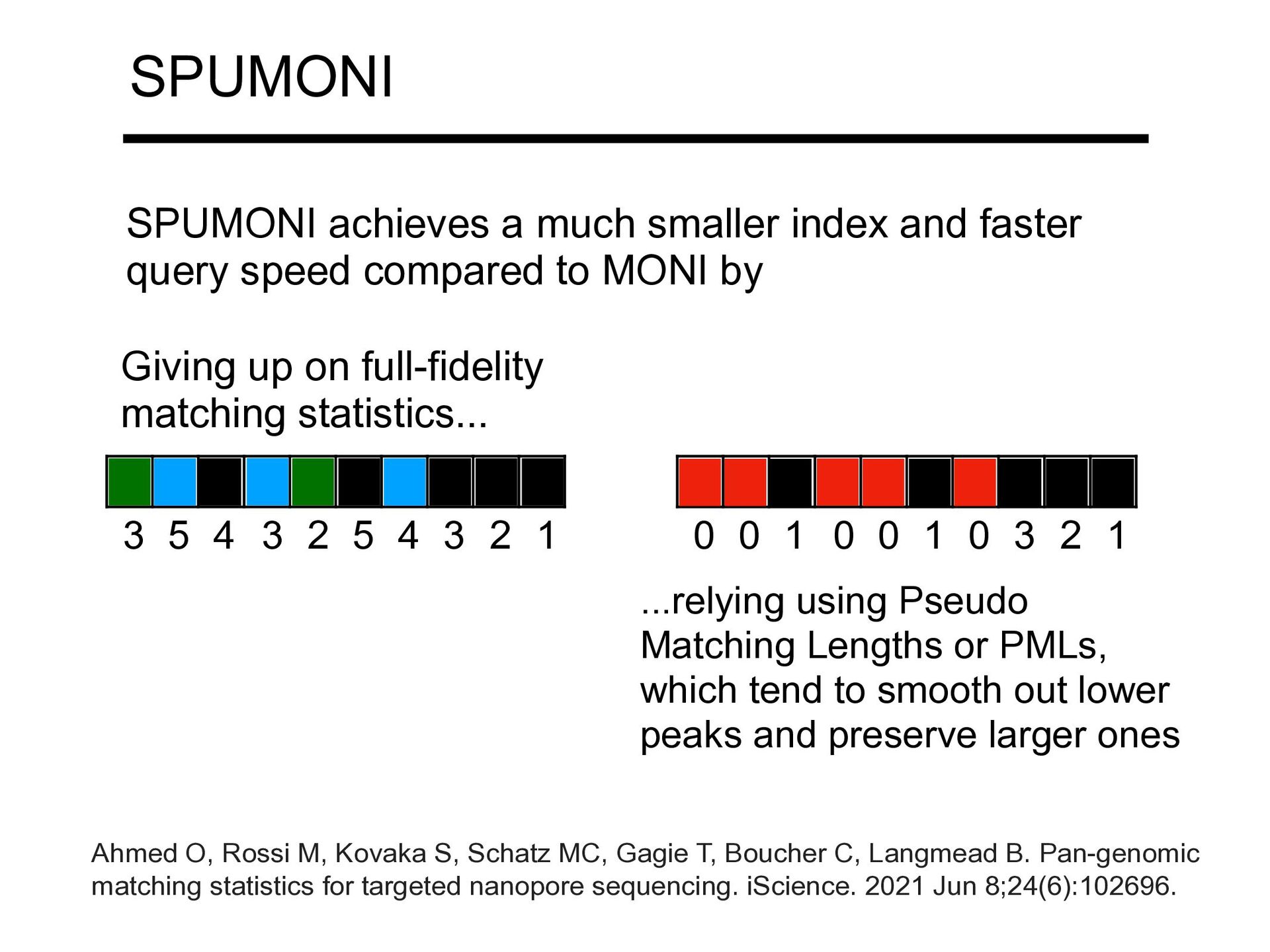
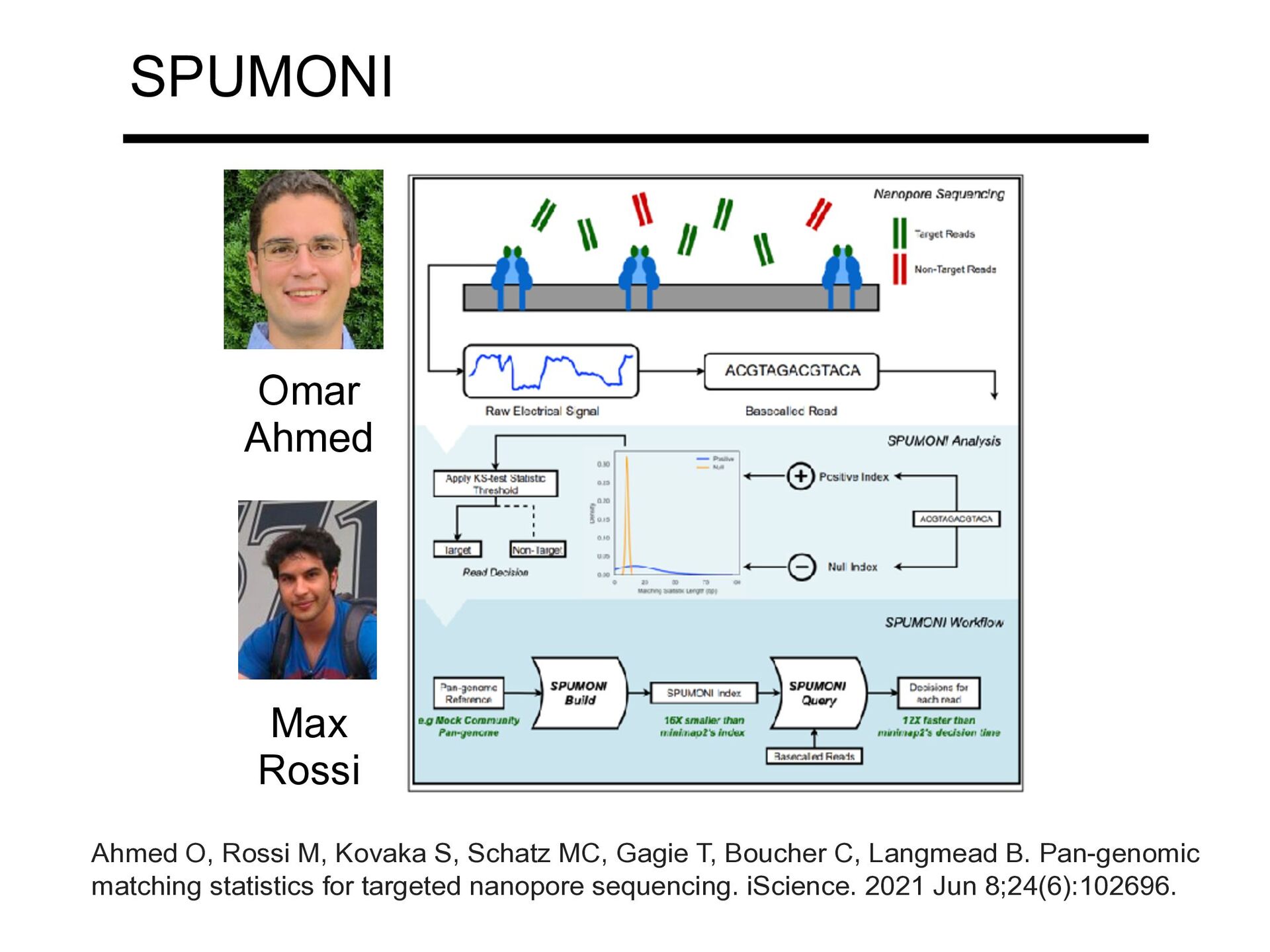
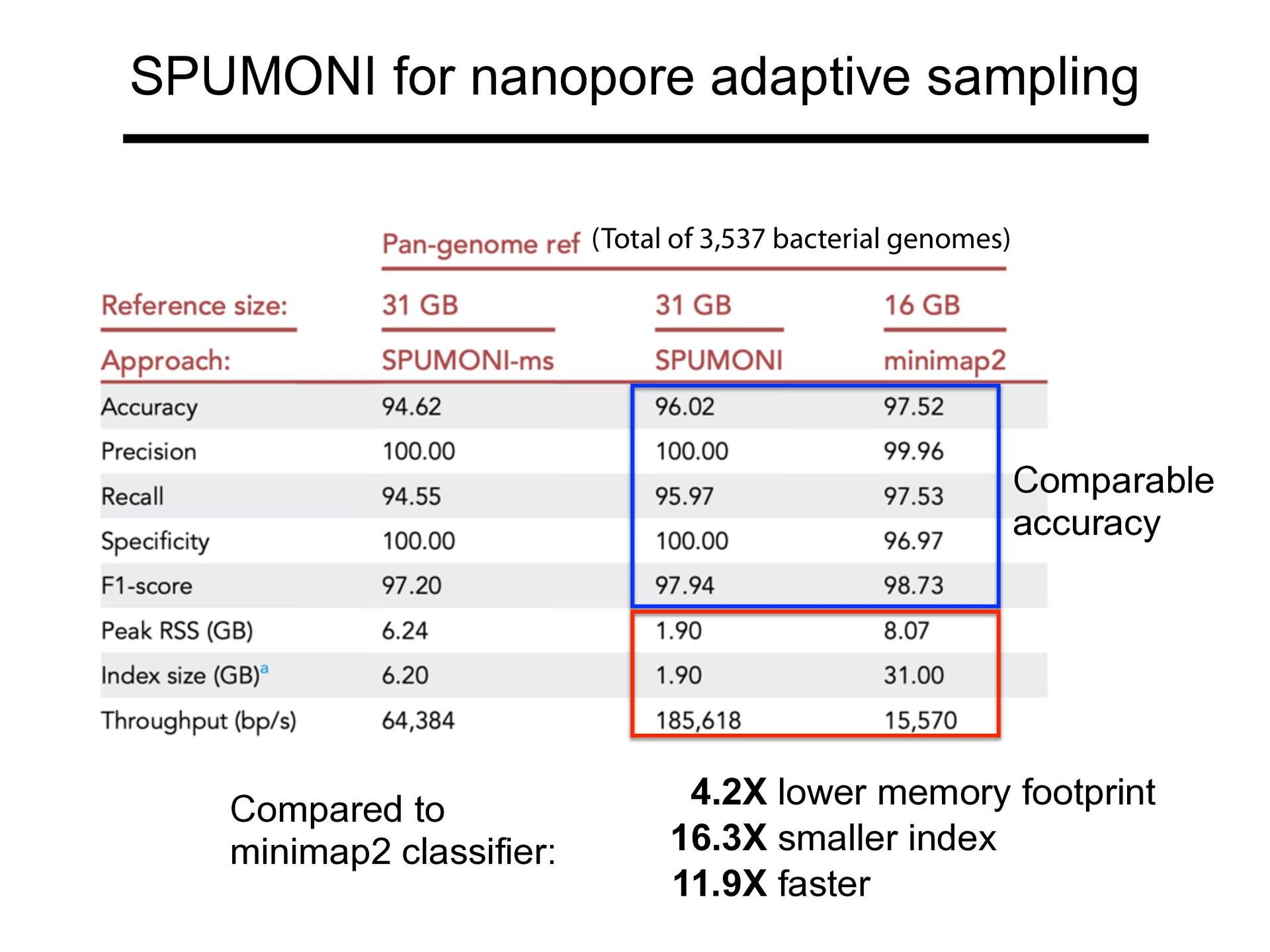
speed compared to MONI by 1 2 3 4 5 2 3 4 5 3 1 2 3 0 1 0 0 1 0 0 Giving up on full-fidelity matching statistics... ...relying using Pseudo Matching Lengths or PMLs, which tend to smooth out lower peaks and preserve larger ones Ahmed O, Rossi M, Kovaka S, Schatz MC, Gagie T, Boucher C, Langmead B. Pan-genomic matching statistics for targeted nanopore sequencing. iScience. 2021 Jun 8;24(6):102696.
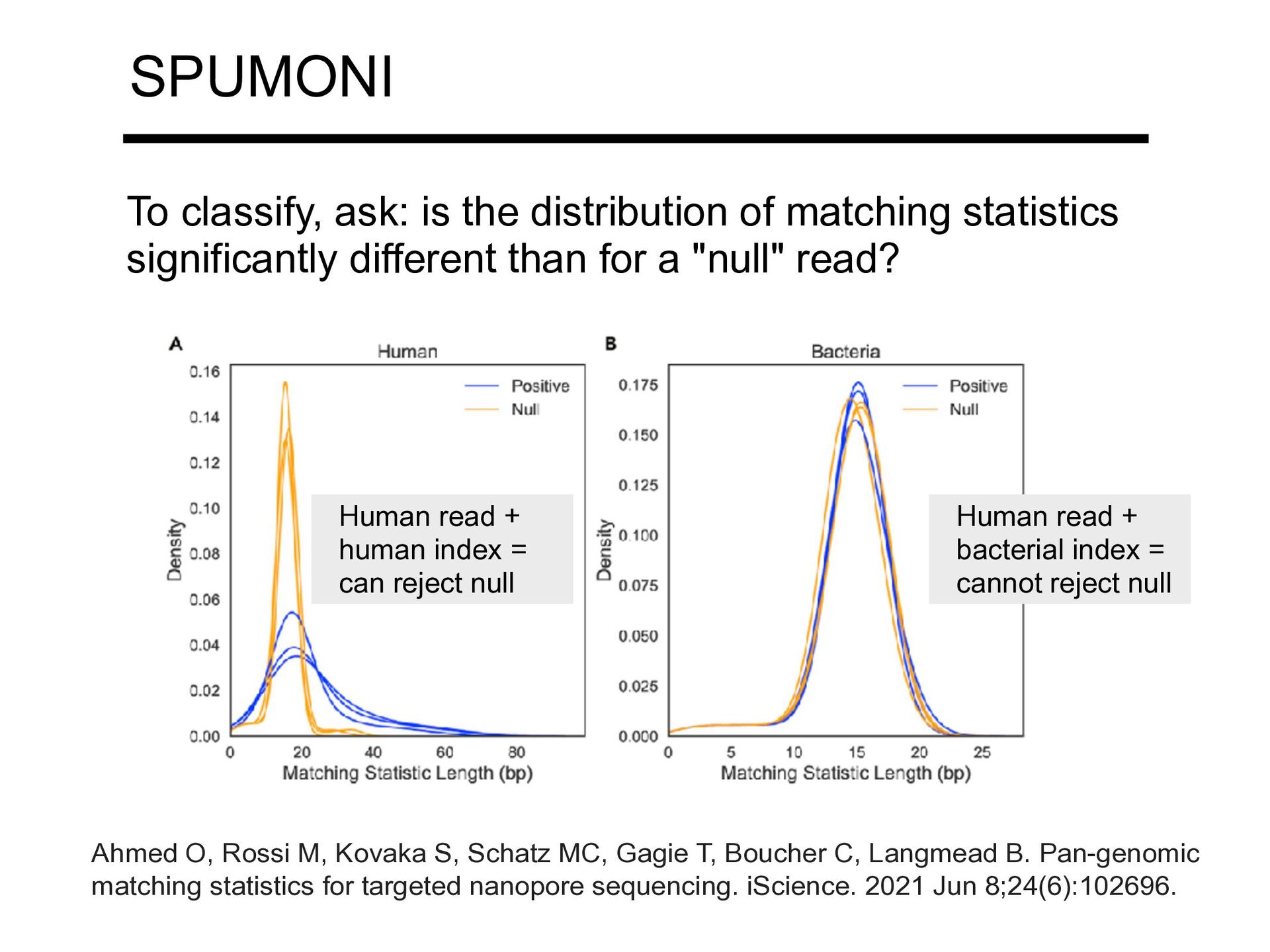
significantly different than for a "null" read? Human read + human index = can reject null Human read + bacterial index = cannot reject null Ahmed O, Rossi M, Kovaka S, Schatz MC, Gagie T, Boucher C, Langmead B. Pan-genomic matching statistics for targeted nanopore sequencing. iScience. 2021 Jun 8;24(6):102696.
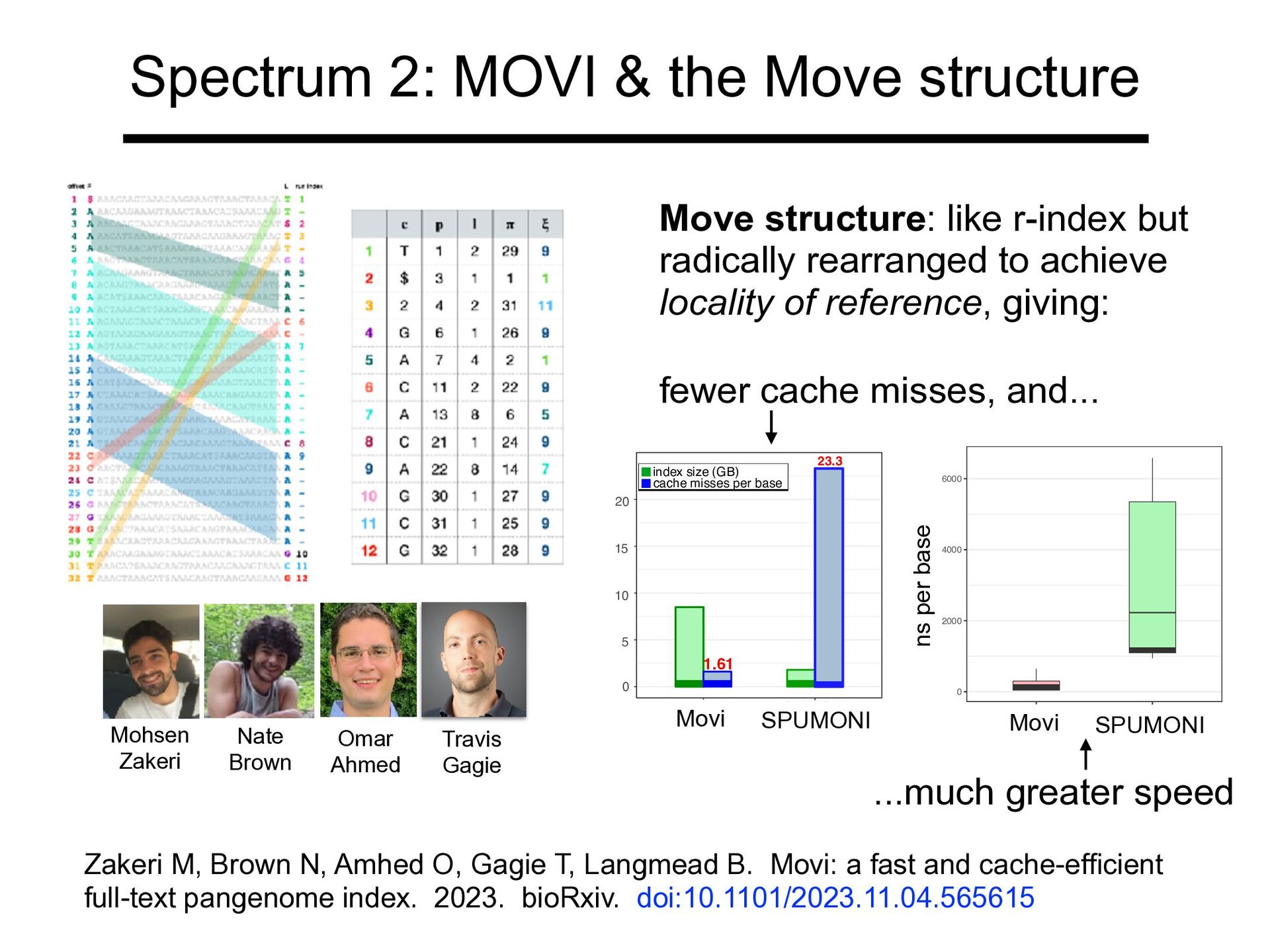
Spectrum 2: MOVI & the Move structure Travis Gagie Omar Ahmed Mohsen Zakeri Nate Brown Move structure: like r-index but radically rearranged to achieve locality of reference, giving: fewer cache misses, and... ...much greater speed Zakeri M, Brown N, Amhed O, Gagie T, Langmead B. Movi: a fast and cache-efficient full-text pangenome index. 2023. bioRxiv. doi:10.1101/2023.11.04.565615 1.61 23.3 0 5 10 15 20 Movi SPUMONI index size (GB) cache misses per base Movi SPUMONI Movi SPUMONI ns per base
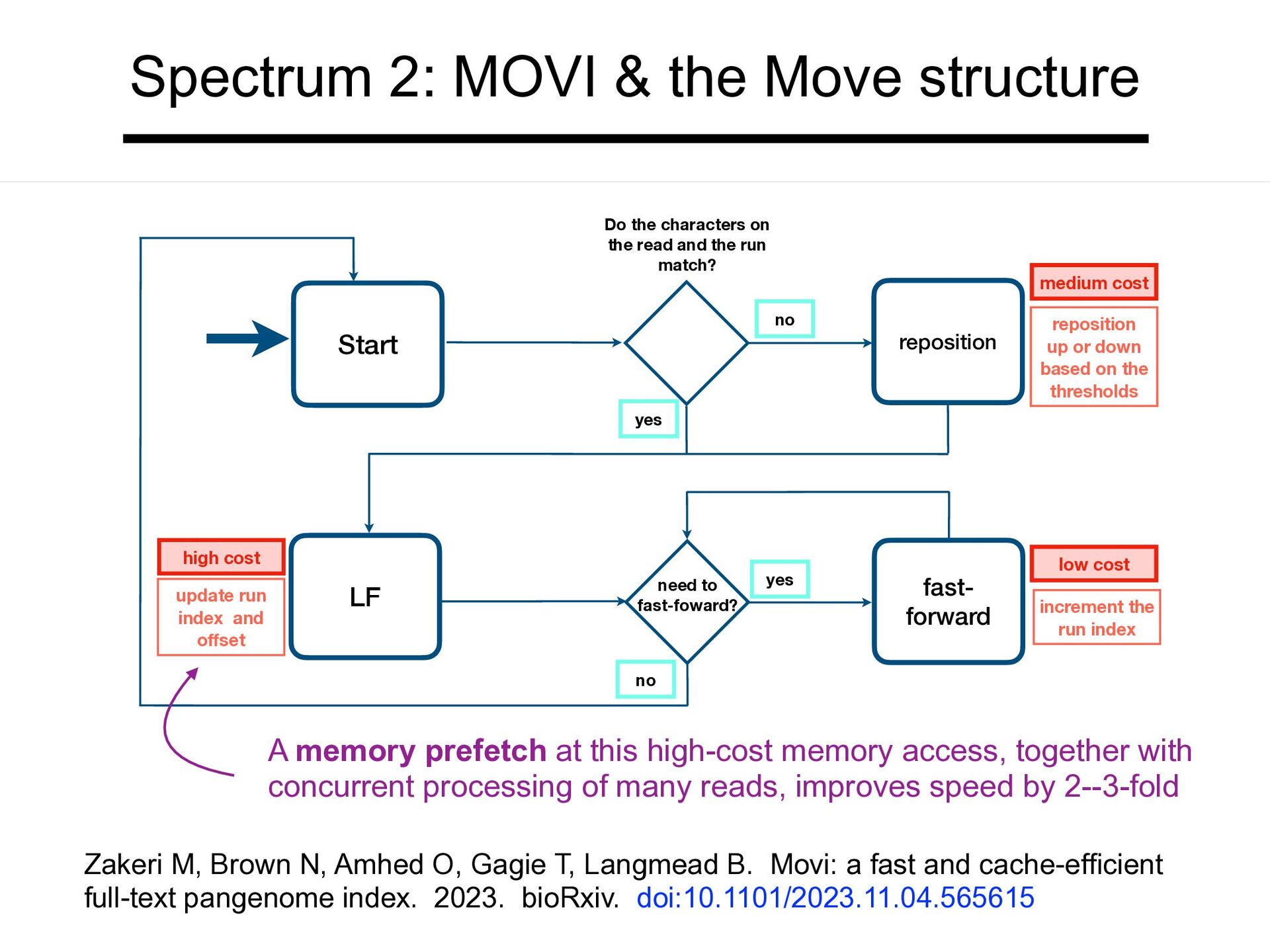
match? reposition reposition up or down based on the thresholds medium cost LF update run index and offset fast- forward need to fast-foward? high cost yes low cost increment the run index no no yes Spectrum 2: MOVI & the Move structure Zakeri M, Brown N, Amhed O, Gagie T, Langmead B. Movi: a fast and cache-efficient full-text pangenome index. 2023. bioRxiv. doi:10.1101/2023.11.04.565615 A memory prefetch at this high-cost memory access, together with concurrent processing of many reads, improves speed by 2--3-fold
N, Amhed O, Gagie T, Langmead B. Movi: a fast and cache-efficient full-text pangenome index. 2023. bioRxiv. doi:10.1101/2023.11.04.565615 • More in this talk if you are interested: https://youtu.be/t7luD8Wnk7w?si=Gb9EVfCjznjiUeSc
driven & complete way of "collapsing" the sequences Creates a coordinate system & saves effort later Garrison, E., Sirén, J., Novak, A. M., Hickey, G., Eizenga, J. M., Dawson, E.T., … Durbin, R. (2018). Variation graph toolkit improves read mapping by representing genetic variation in the reference. Nature biotechnology, 36(9), 875–879. Spectrum 3: Graphs Strings ↔
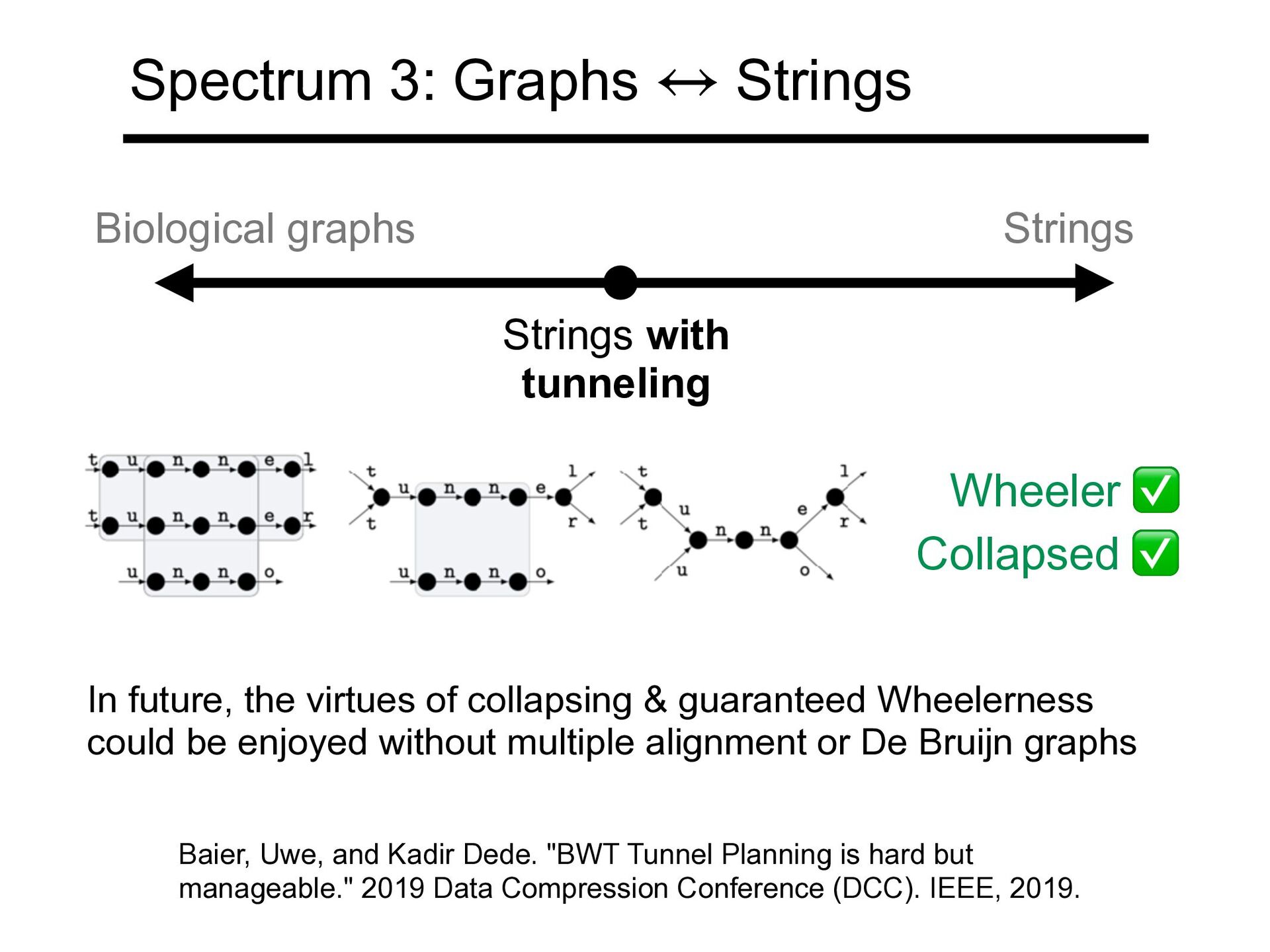
Baier, Uwe, and Kadir Dede. "BWT Tunnel Planning is hard but manageable." 2019 Data Compression Conference (DCC). IEEE, 2019. In future, the virtues of collapsing & guaranteed Wheelerness could be enjoyed without multiple alignment or De Bruijn graphs Spectrum 3: Graphs Strings ↔
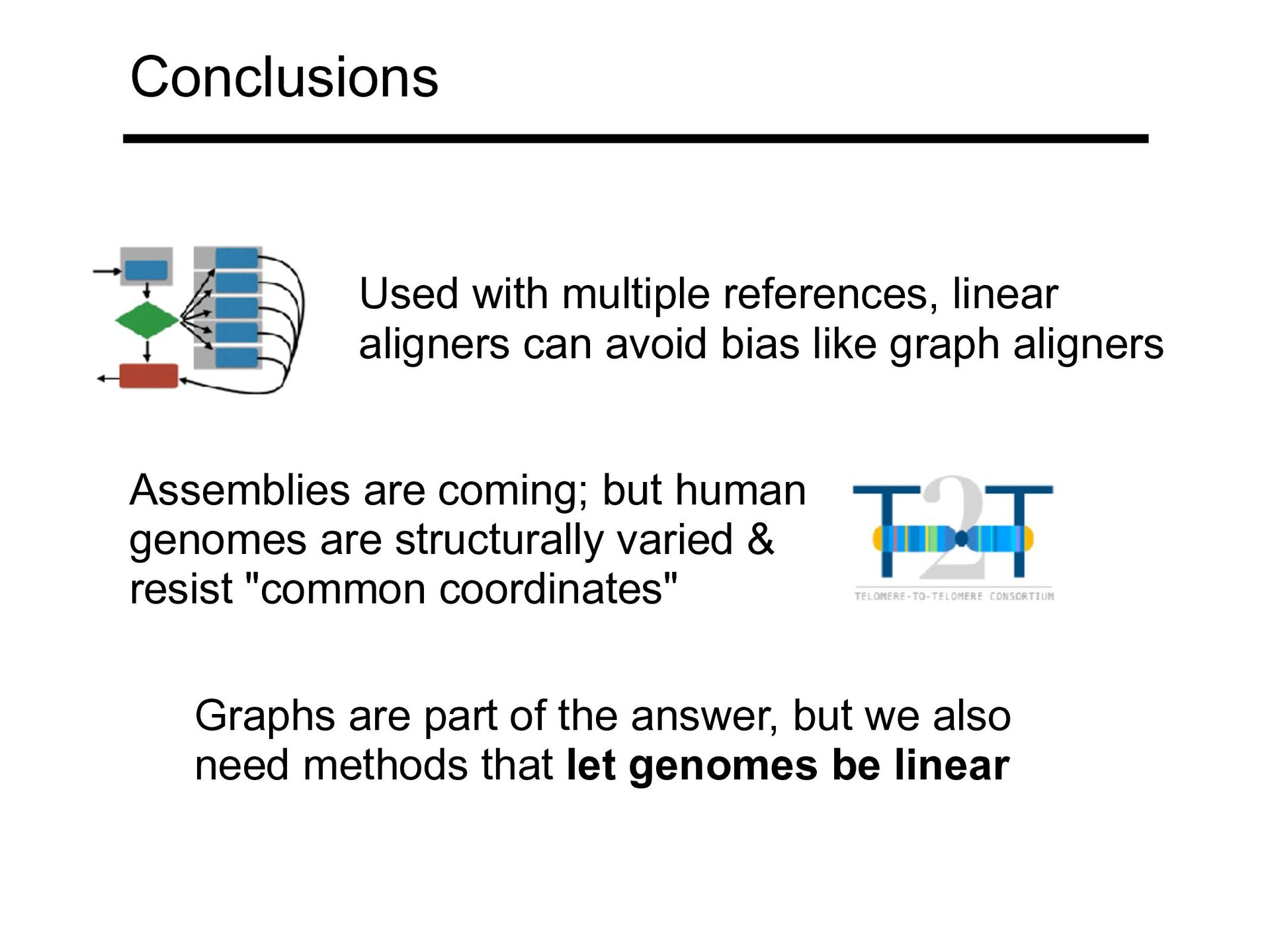
like graph aligners Assemblies are coming; but human genomes are structurally varied & resist "common coordinates" Graphs are part of the answer, but we also need methods that let genomes be linear
Formalisms like Wheeler Graph & r-index are maturing at the right time, but could use more attention • Technical videos available in my "Indexing" playlist (link below) and all over my YouTube channel Conclusions
Gagie Alan Kuhnle Giovanni Manzini Jacob Pritt Nae-Chyun Chen Taher Mun Brad Solomon Sheila Iyer Omar Ahmed Max Rossi Sam Kovaka Mike Schatz Marco Oliva Mohsen Zakeri Nate Brown R01HG011392 R35GM139602 Naga Sai Kavya Vaddadi NIH: NSF: Vikram Shivakuma
![Ben Langmead Associate Professor, JHU Computer Science [email protected], langmead-lab.org, @BenLangmead](https://files.speakerdeck.com/presentations/c2f7dd66575f42bd96a6a50d04ba3f84/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}