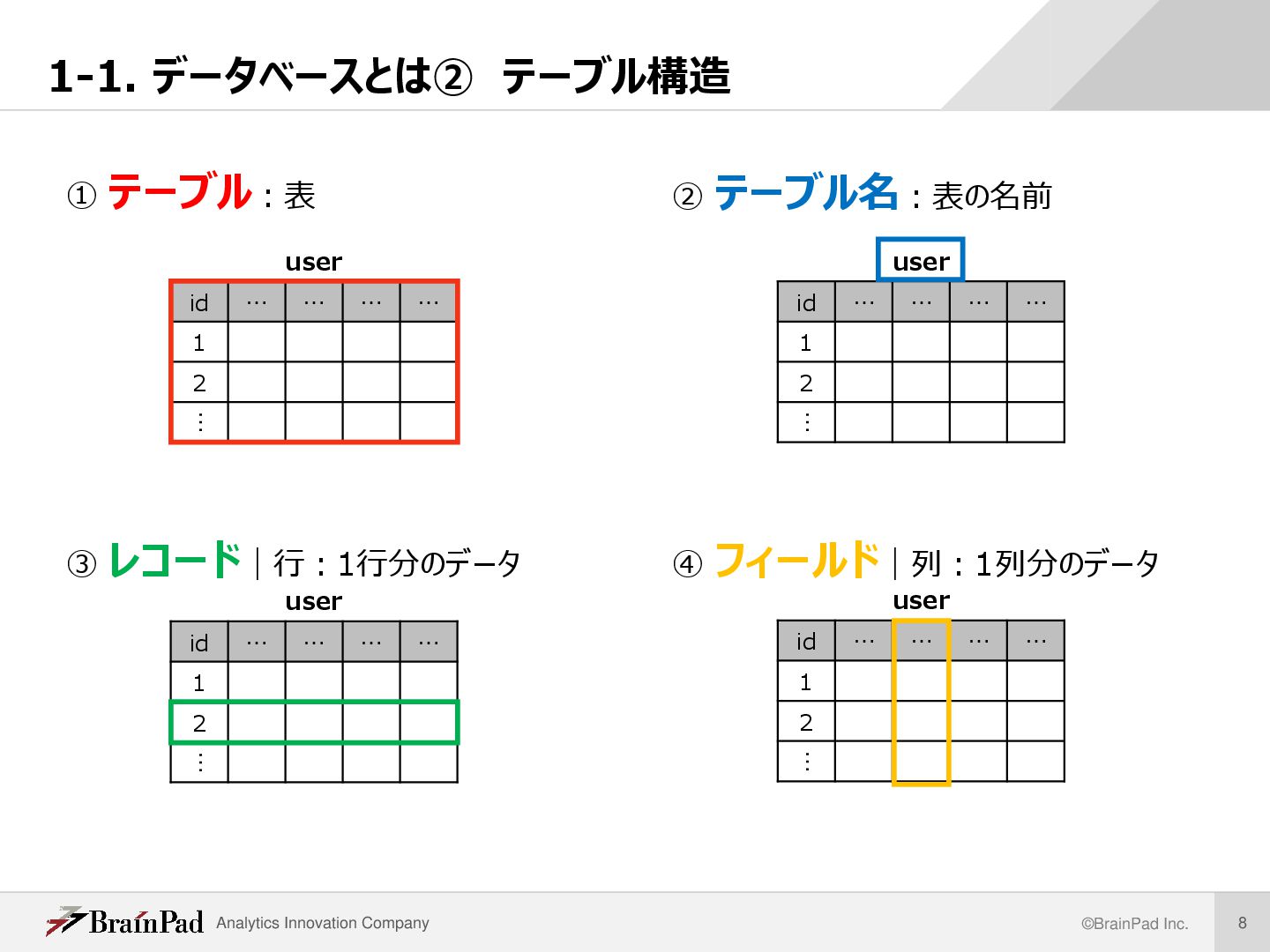
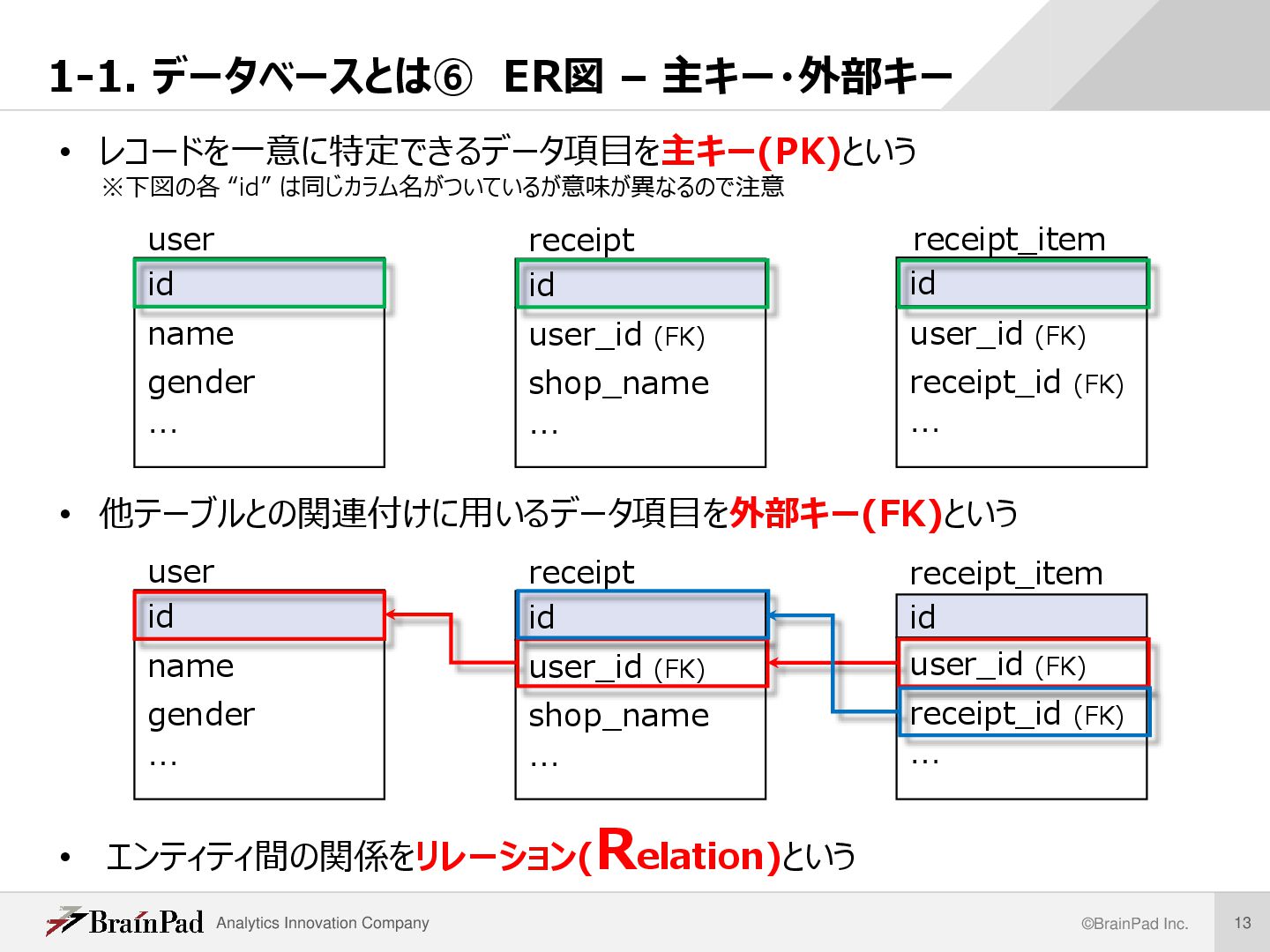
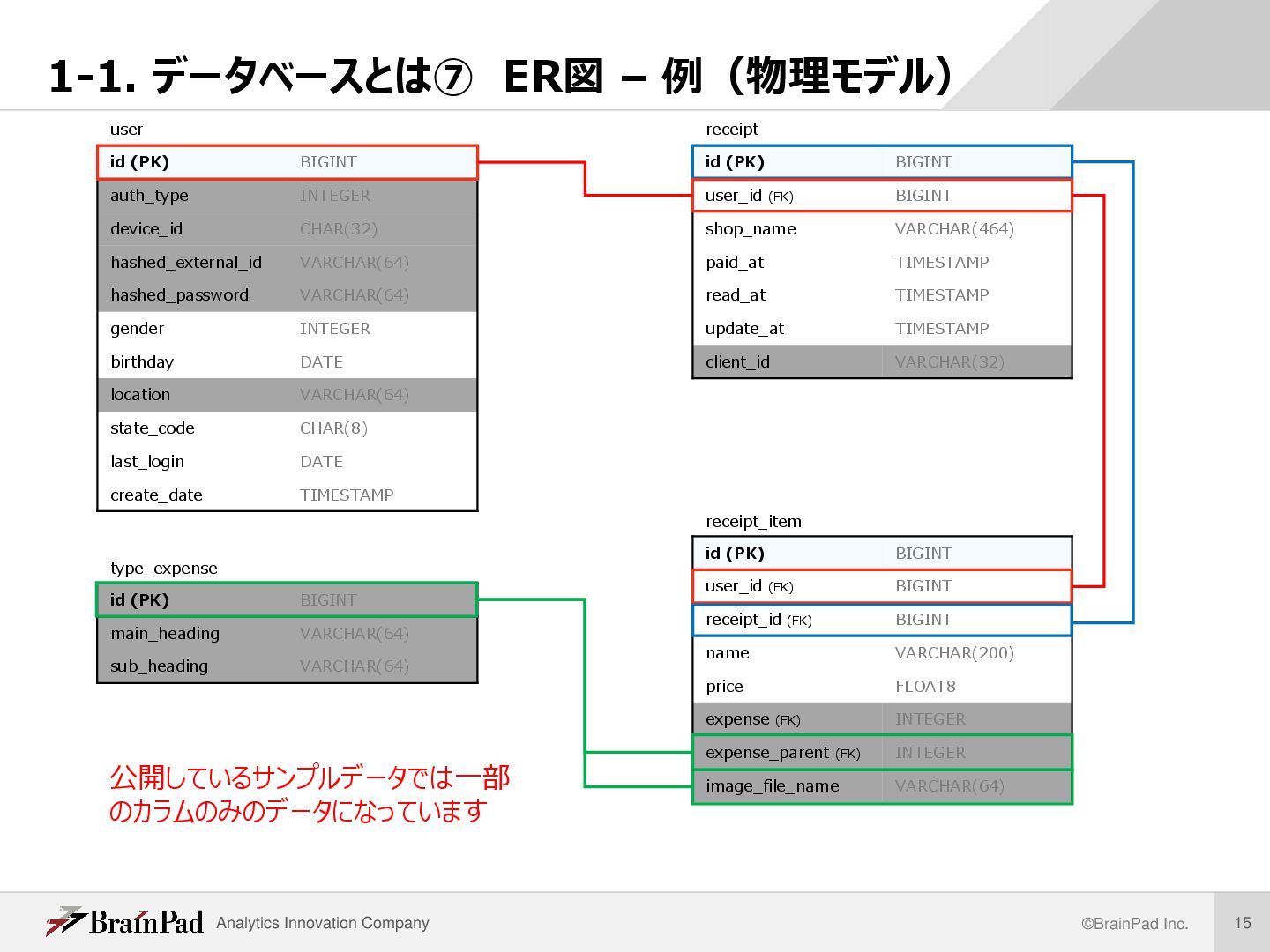
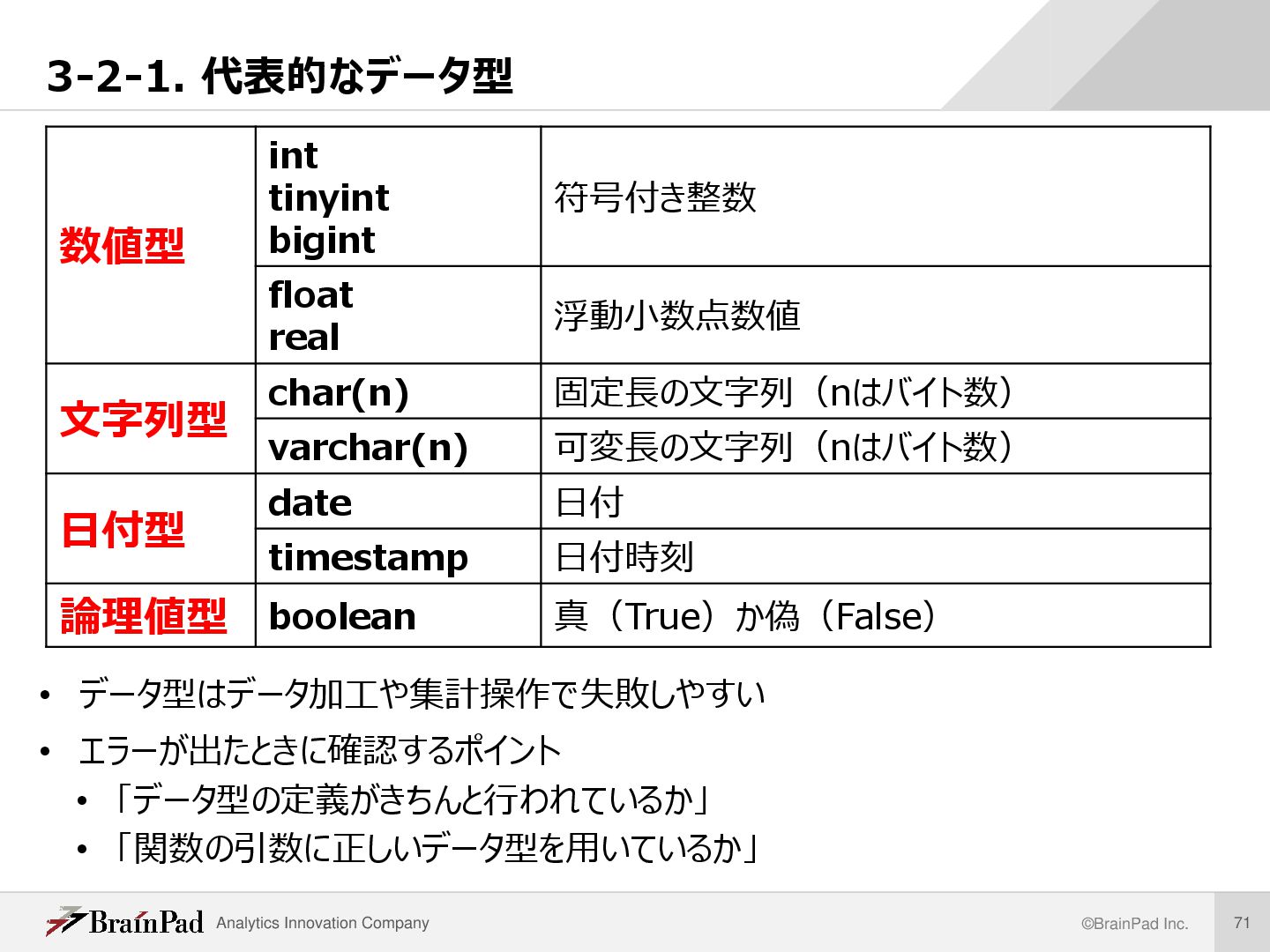
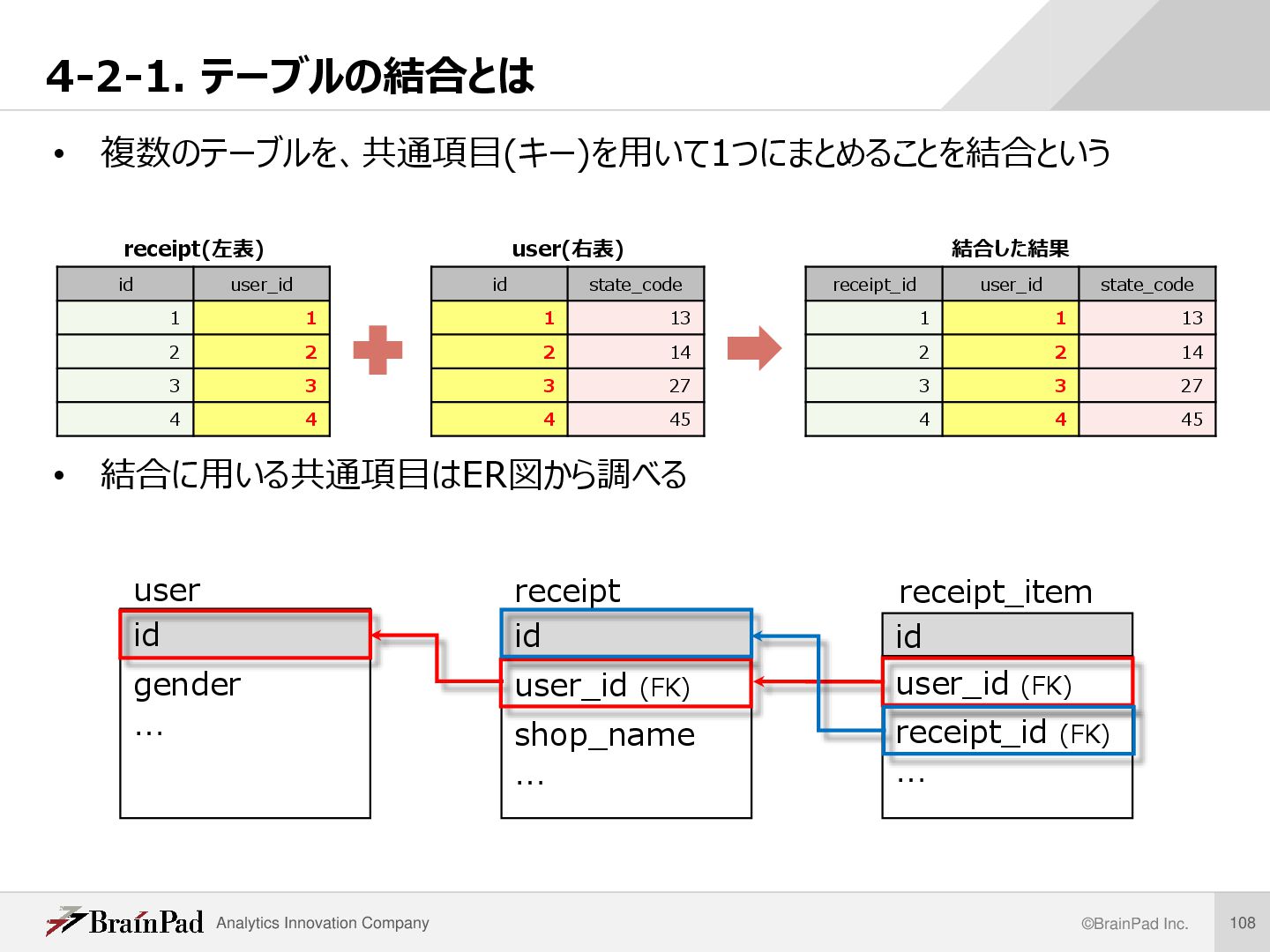
主キー・外部キー id name gender … user id user_id (FK) shop_name … receipt id user_id (FK) receipt_id (FK) … receipt_item id name gender … user id user_id (FK) shop_name … receipt id user_id (FK) receipt_id (FK) … receipt_item • レコードを一意に特定できるデータ項目を主キー(PK)という ※下図の各 “id” は同じカラム名がついているが意味が異なるので注意 • 他テーブルとの関連付けに用いるデータ項目を外部キー(FK)という • エンティティ間の関係をリレーション( Relation)という
userテーブルで、性別が1(男性)かつ state_codeが’13’(東京)である人の 総数を取得する。 */ SELECT COUNT(*) FROM `user` WHERE gender = 1 AND state_code = ’13’ ; 解説 論理演算子 • A AND B (AかつB) • 2つの条件式の両方が真の場合だけ、真となる • A OR B(AまたはB) • 2つの条件式のどちらかが真ならば、真となる AND, ORの優先順位 • AND → ORの順に処理される 例 A OR B AND C ① B AND Cが処理される(=結果) ② A OR (結果)が処理される(=最終結果) ※(A OR B) AND C のように括弧で囲むとORが優先される SQL バッククォート シングルクォーテーション (コピペ時は注意!)
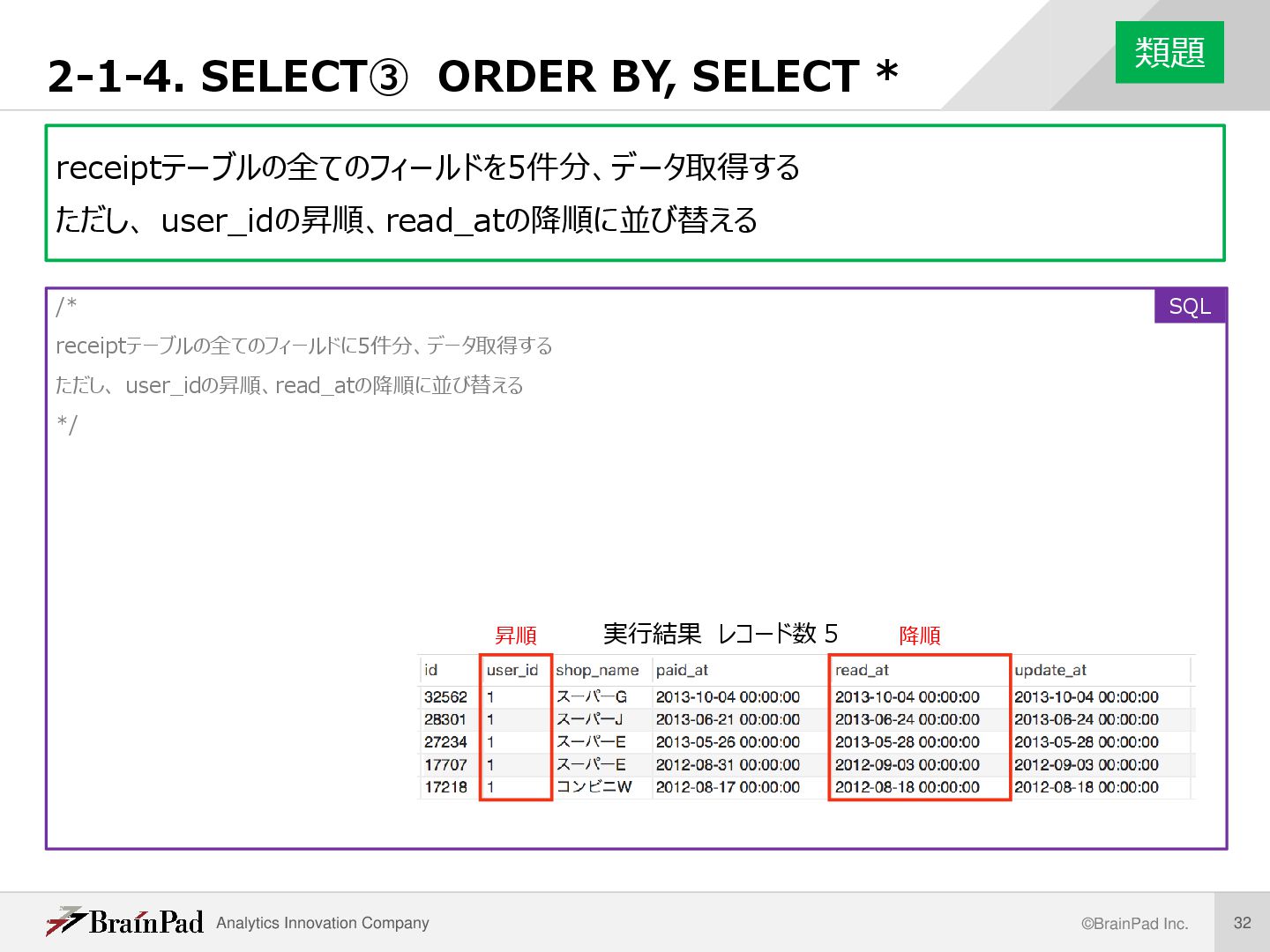
いて、id, gender, last_loginを取得する。ただし、last_loginの昇順に並び替える。 /* userテーブルで、last_loginが2010年1月1日から2015年12月31日までであるデータについて、 id, gender, last_loginのフィールドを取得する。ただし、last_loginの昇順に並び替える。 */ SELECT id ,gender ,last_login FROM `user` WHERE last_login BETWEEN ‘2010-01-01’ AND ‘2015-12-31’ ORDER BY last_login; 例題 実行結果 レコード数416 SQL
userテーブルで、last_loginが2010年1 月1日から2015年12月31日までである データについて、 id, gender, last_loginのフィールドを取 得する。ただし、last_loginの昇順に並び 替える。 */ SELECT id ,gender ,last_login FROM `user` WHERE last_login BETWEEN ‘2010-01-01’ AND ‘2015-12-31’ ORDER BY last_login; 解説 BETWEEN • BETWEEN 値1 AND 値2 • ある範囲内に値が収まっているか判定する • 指定した範囲の境界は含まれるので注意 例 BETWEEN 100 AND 3000 → 100以上 3000以下 BETWEENと比較演算子>=, <= • 例 「priceが100以上、3000以下」 WHERE price BETWEEN 100 AND 3000 WHERE price >= 100 AND price <= 3000 SQL
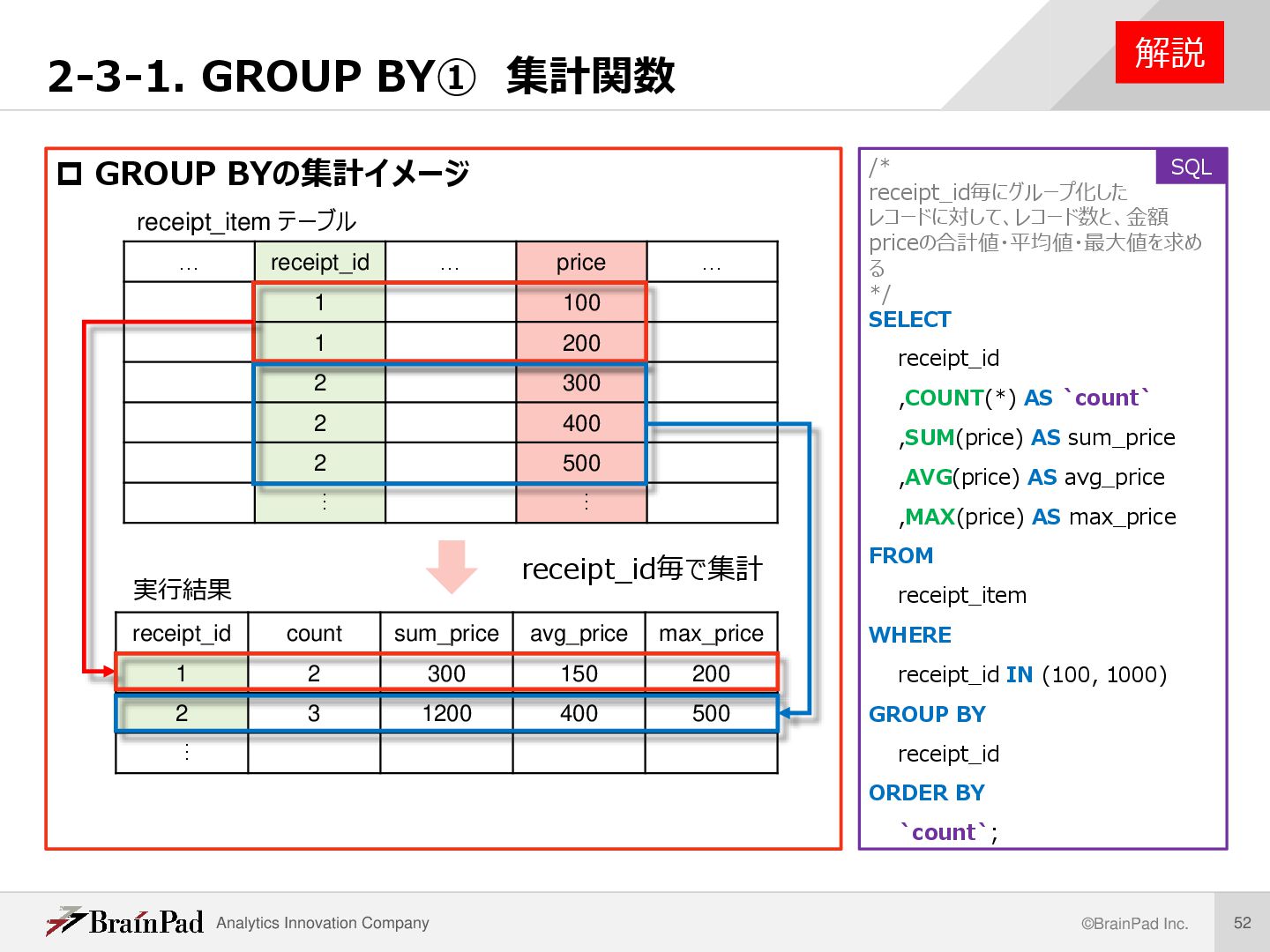
receipt_itemテーブルで、receipt_id毎にグループ化したレコードに対して、 レコード数と、金額priceの合計値・平均値・最大値を求める。ただし、receipt_idが’100’ と’1000’のデータを対象とし、レコード数の昇順に並び替えて表示する。 /* receipt_itemテーブルで、receipt_id毎にグループ化した レコードに対して、レコード数と、金額priceの合計値・ 平均値・最大値を求める。 ただし、receipt_idが’100’と’1000’のデータを対象とし、レコード数 の昇順に並び替えて表示する*/ SELECT receipt_id ,COUNT(*) AS `count` ,SUM(price) AS sum_price ,AVG(price) AS avg_price ,MAX(price) AS max_price FROM receipt_item WHERE receipt_id IN (100, 1000) GROUP BY receipt_id ORDER BY `count` ; 例題 実行結果 レコード数 2 SQL
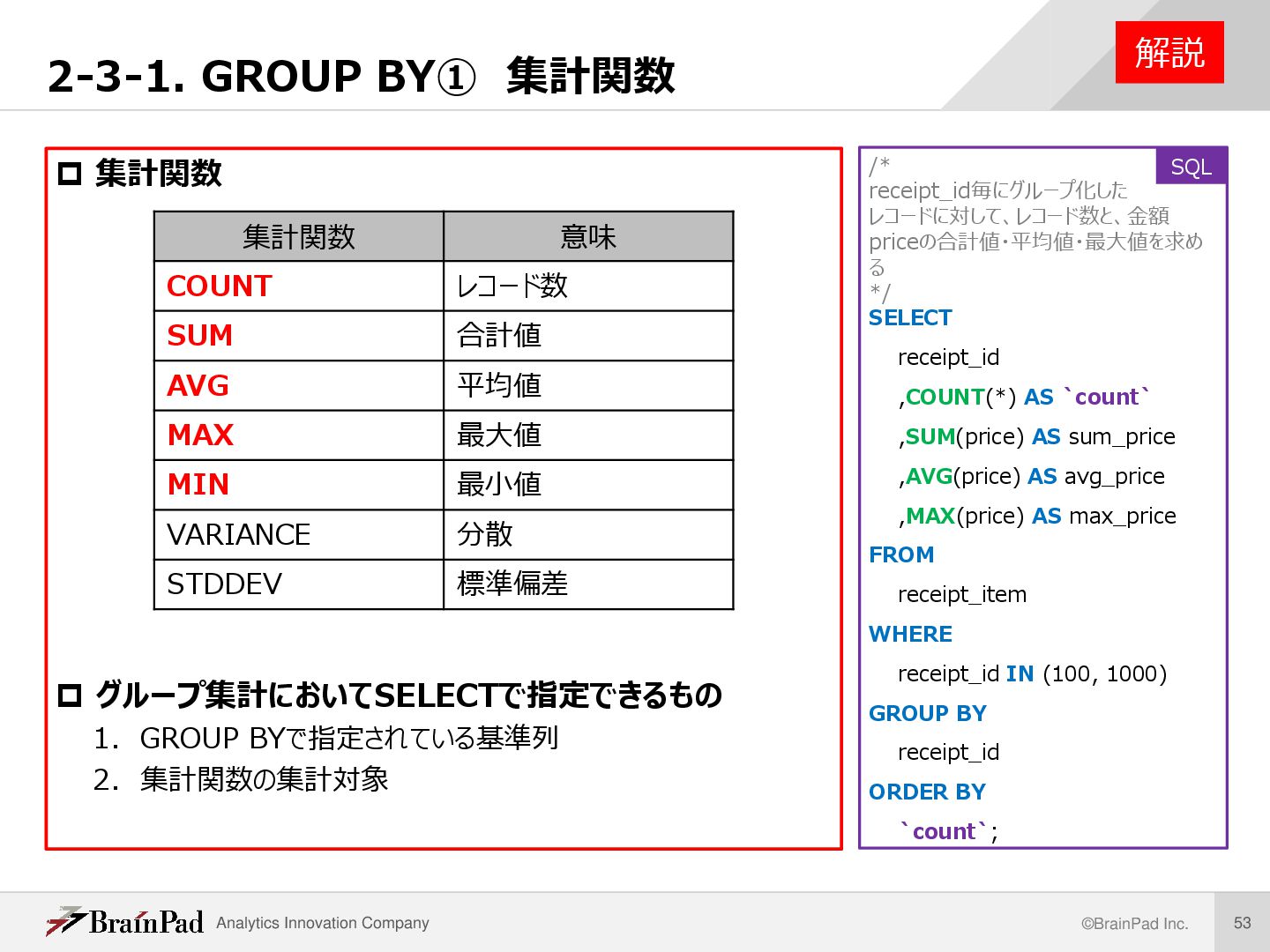
解説 集計関数 グループ集計においてSELECTで指定できるもの 1. GROUP BYで指定されている基準列 2. 集計関数の集計対象 SQL 集計関数 意味 COUNT レコード数 SUM 合計値 AVG 平均値 MAX 最大値 MIN 最小値 VARIANCE 分散 STDDEV 標準偏差 /* receipt_id毎にグループ化した レコードに対して、レコード数と、金額 priceの合計値・平均値・最大値を求め る */ SELECT receipt_id ,COUNT(*) AS `count` ,SUM(price) AS sum_price ,AVG(price) AS avg_price ,MAX(price) AS max_price FROM receipt_item WHERE receipt_id IN (100, 1000) GROUP BY receipt_id ORDER BY `count`;
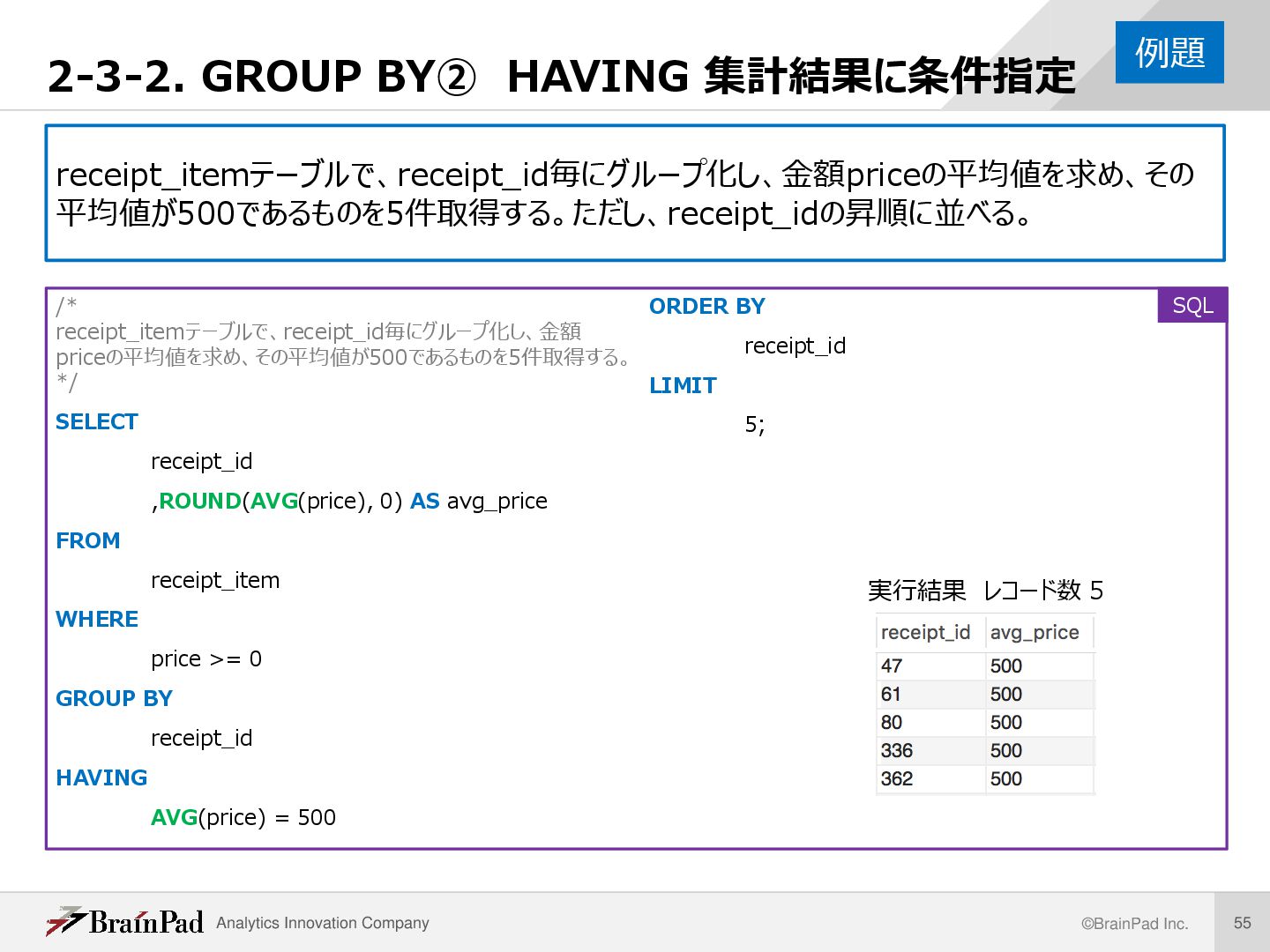
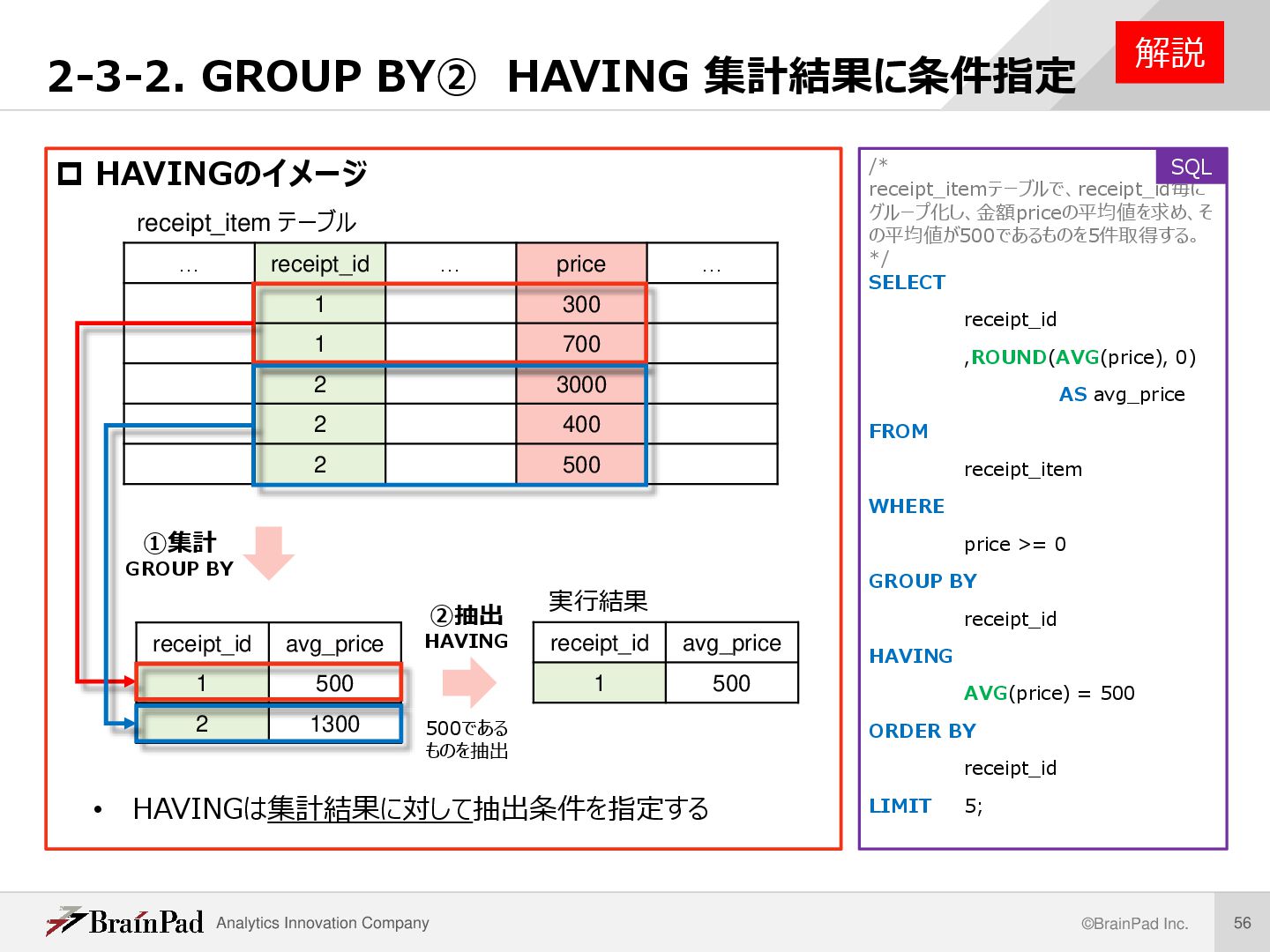
集計結果に条件指定 receipt_itemテーブルで、receipt_id毎にグループ化し、金額priceの平均値を求め、その 平均値が500であるものを5件取得する。ただし、receipt_idの昇順に並べる。 /* receipt_itemテーブルで、receipt_id毎にグループ化し、金額 priceの平均値を求め、その平均値が500であるものを5件取得する。 */ SELECT receipt_id ,ROUND(AVG(price), 0) AS avg_price FROM receipt_item WHERE price >= 0 GROUP BY receipt_id HAVING AVG(price) = 500 ORDER BY receipt_id LIMIT 5; 例題 実行結果 レコード数 5 SQL
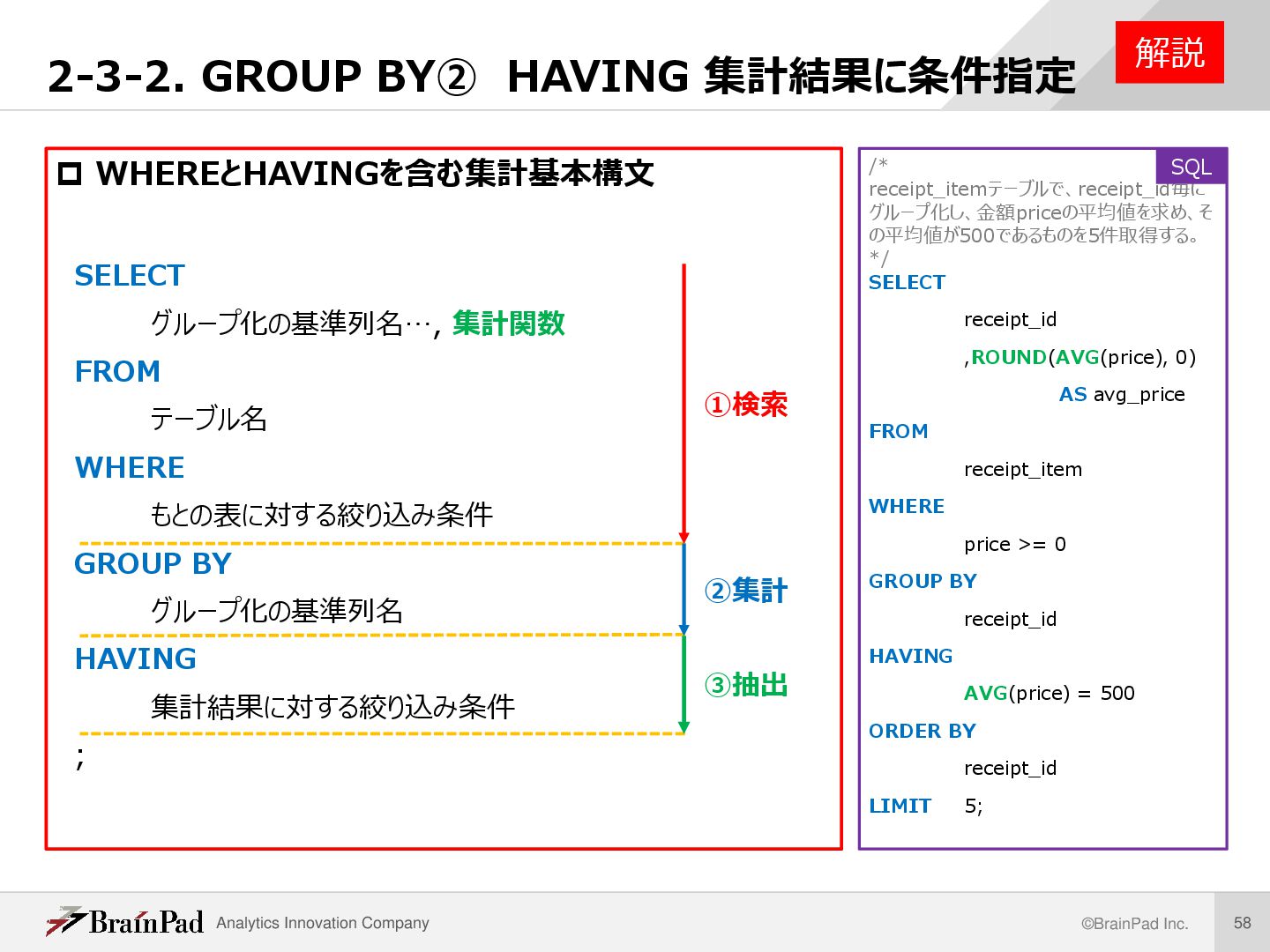
集計結果に条件指定 /* receipt_itemテーブルで、receipt_id毎に グループ化し、金額priceの平均値を求め、そ の平均値が500であるものを5件取得する。 */ SELECT receipt_id ,ROUND(AVG(price), 0) AS avg_price FROM receipt_item WHERE price >= 0 GROUP BY receipt_id HAVING AVG(price) = 500 ORDER BY receipt_id LIMIT 5; 解説 WHEREとHAVINGを含む集計基本構文 SELECT グループ化の基準列名…, 集計関数 FROM テーブル名 WHERE もとの表に対する絞り込み条件 GROUP BY グループ化の基準列名 HAVING 集計結果に対する絞り込み条件 ; SQL ①検索 ②集計 ③抽出
1. FROMで処理対象テーブルを選択 2. WHEREによる絞り込み 3. GROUP BYによるグループ化 4. HAVINGによる絞り込み 5. SELECT 6. ORDER BYによるソート 7. LIMITによる絞り込み • 実行順序を理解することは、SQLのパフォー マンス向上や、複雑なクエリを作成する上で 重要となる SELECT ⑤ receipt_id ,ROUND(AVG(price), 0) AS avg_price FROM ① receipt_item WHERE ② price >= 0 GROUP BY ③ receipt_id HAVING ④ AVG(price) = 500 ORDER BY ⑥ receipt_id LIMIT 5; ⑦ SQL
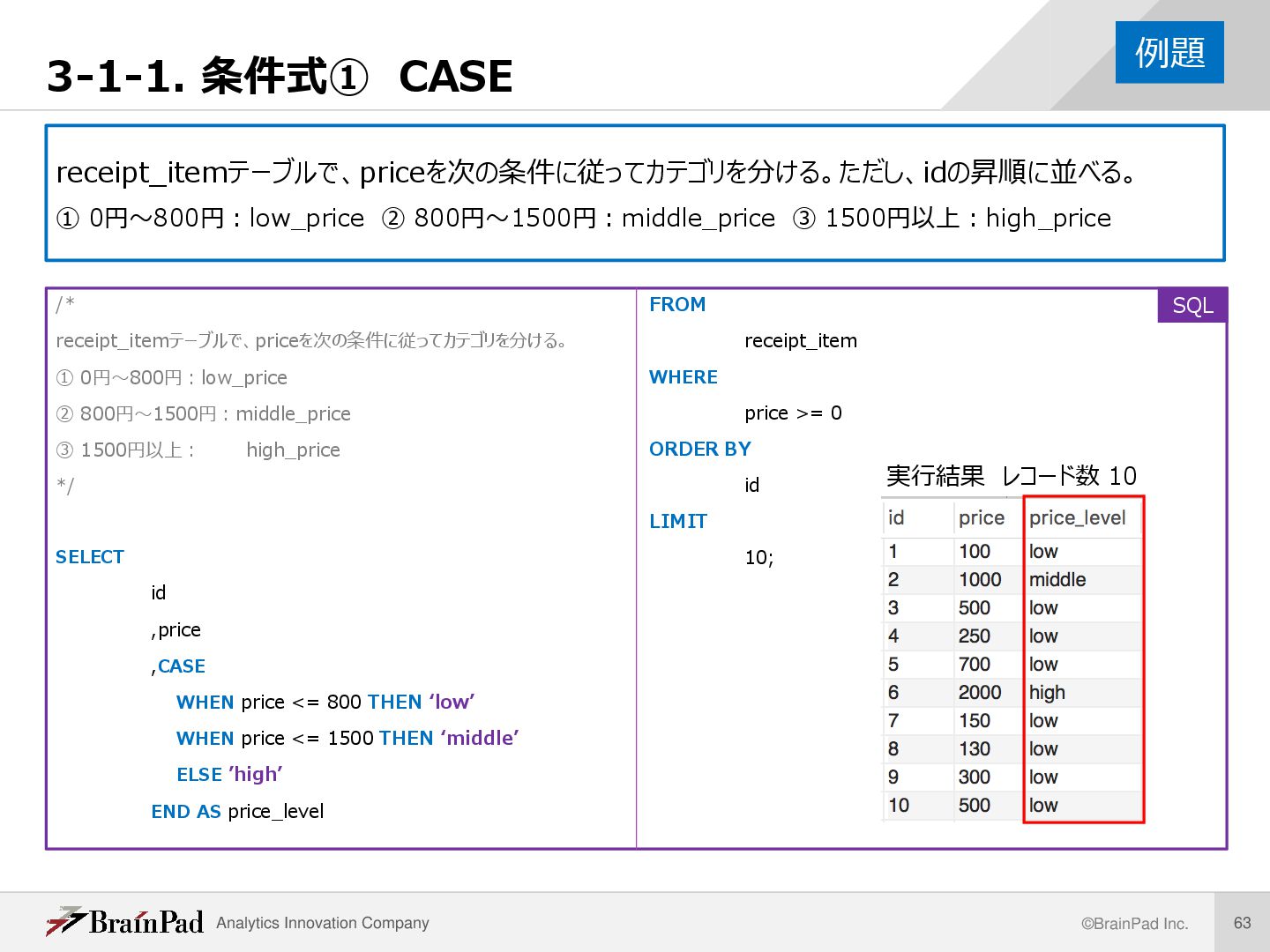
① 0円〜800円:low_price ② 800円〜1500円:middle_price ③ 1500円以上:high_price /* receipt_itemテーブルで、priceを次の条件に従ってカテゴリを分ける。 ① 0円〜800円:low_price ② 800円〜1500円:middle_price ③ 1500円以上: high_price */ SELECT id ,price ,CASE WHEN price <= 800 THEN ‘low’ WHEN price <= 1500 THEN ‘middle’ ELSE ’high’ END AS price_level FROM receipt_item WHERE price >= 0 ORDER BY id LIMIT 10; 例題 実行結果 レコード数 10 SQL
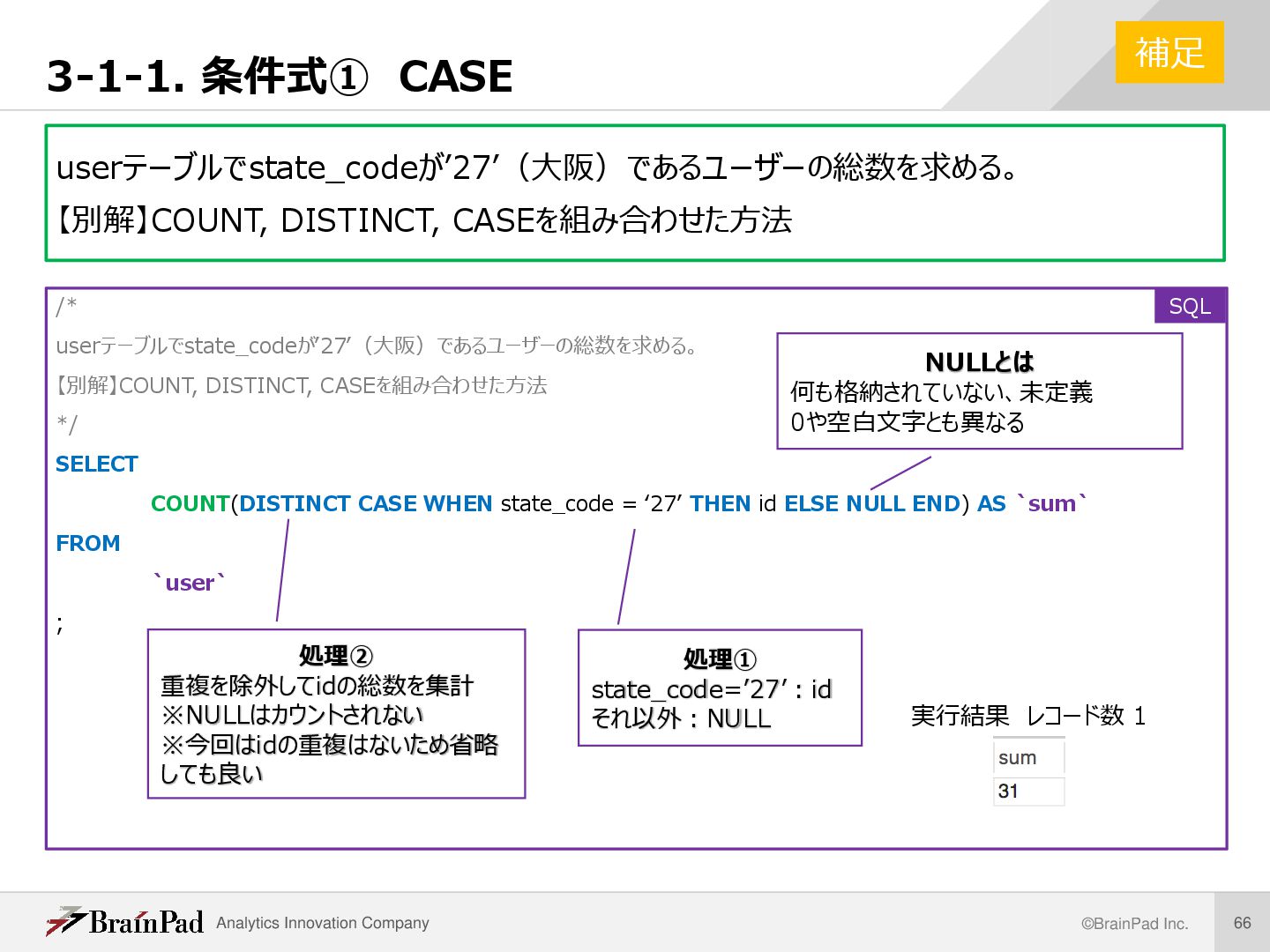
CASE • 条件分岐で値を変換する • 基本構文 CASE WHEN 条件1 THEN 返す値 WHEN 条件2 THEN 返す値… ELSE 上記に合致しないときに返す値 END (AS 別名) • フラグ(条件該当の印)とCASE 例 「state_codeが’13’(東京)のとき1, 他は0」 CASE WHEN state_code = ‘13’ THEN 1 ELSE 0 END 解説 /* receipt_itemテーブルで、priceを次の条件に 従ってカテゴリを分ける。 ① 0円〜800円:low_price ② 800円〜1500円:middle_price ③ 1500円以上:high_price */ SELECT id ,price ,CASE WHEN price <= 800 THEN ‘low’ WHEN price <= 1500 THEN ‘middle’ ELSE ’high’ END AS price_level FROM receipt_item (以下省略) SQL
・抽出フィールド:id, paid_at, cast_paid_at ・idの昇順で5件分表示 /* receiptテーブルで、paid_atをtimestamp型→date型に変換(cast_paid_at)する。 ・抽出フィールド:id, paid_at, cast_paid_at ・idの昇順で5件分表示 */ SELECT id ,paid_at ,CAST(paid_at AS DATE) AS cast_paid_at FROM receipt ORDER BY id LIMIT 5; 例題 実行結果 レコード数5 SQL
CAST • データ型を変換する • CAST(フィールド名 AS 変換後のデータ型) 文字列varchar型 → date型の変換 SELECT ‘20180402’ AS v_date ,CAST(‘20180402’ AS DATE) AS d_date ; 解説 /* receiptテーブルで、paid_atをtimestamp型 →date型に変換(cast_paid_at)する。 ・抽出フィールド:id, paid_at, cast_paid_at ・idの昇順で5件分表示 */ SELECT id ,paid_at ,CAST(paid_at AS DATE) AS cast_paid_at FROM receipt ORDER BY id LIMIT 5; SQL 実行結果 レコード数1 varchar型 date型
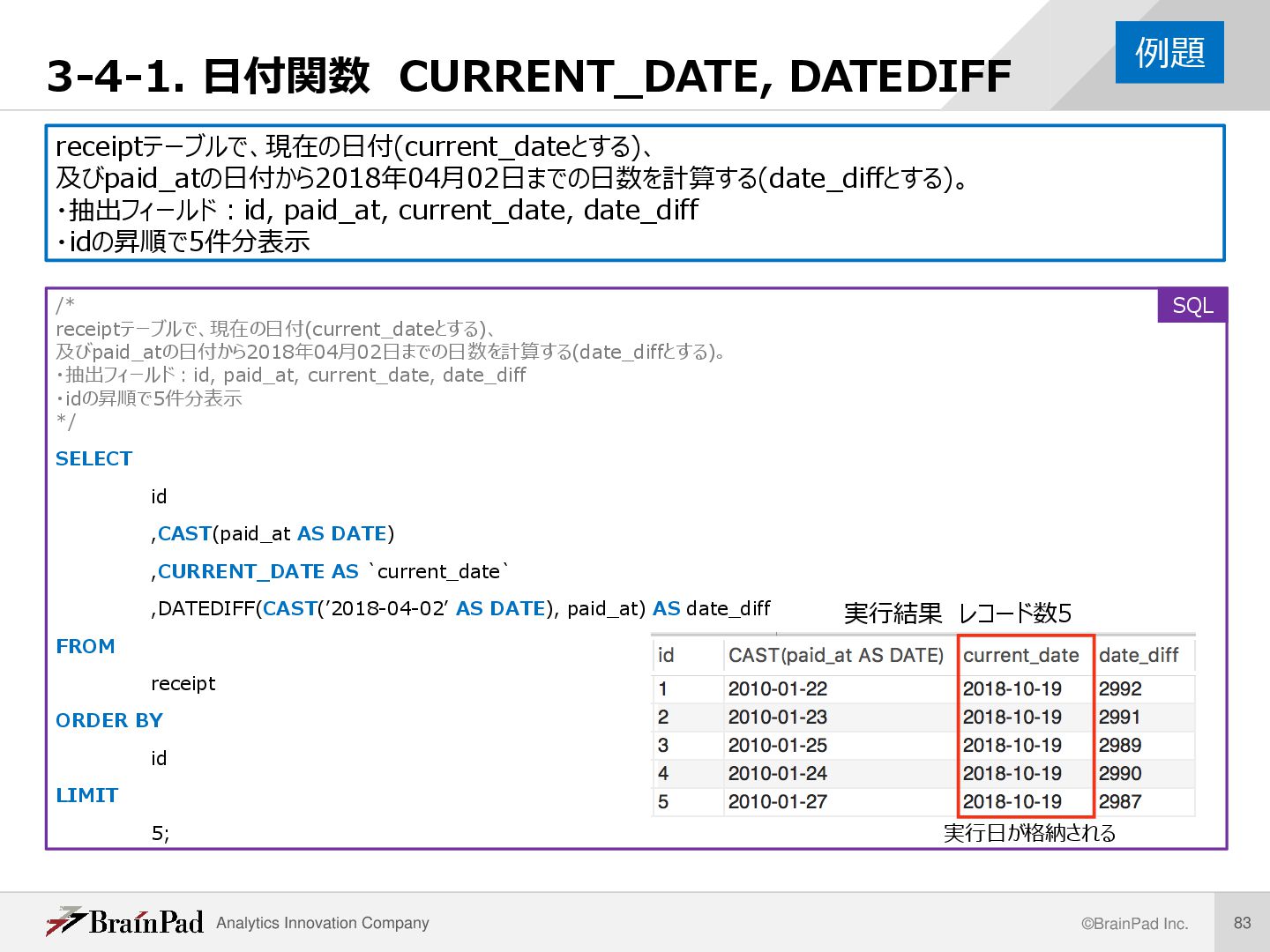
receiptテーブルで、現在の日付(current_dateとする)、 及びpaid_atの日付から2018年04月02日までの日数を計算する(date_diffとする)。 ・抽出フィールド:id, paid_at, current_date, date_diff ・idの昇順で5件分表示 /* receiptテーブルで、現在の日付(current_dateとする)、 及びpaid_atの日付から2018年04月02日までの日数を計算する(date_diffとする)。 ・抽出フィールド:id, paid_at, current_date, date_diff ・idの昇順で5件分表示 */ SELECT id ,CAST(paid_at AS DATE) ,CURRENT_DATE AS `current_date` ,DATEDIFF(CAST(’2018-04-02’ AS DATE), paid_at) AS date_diff FROM receipt ORDER BY id LIMIT 5; 例題 SQL 実行結果 レコード数5 実行日が格納される
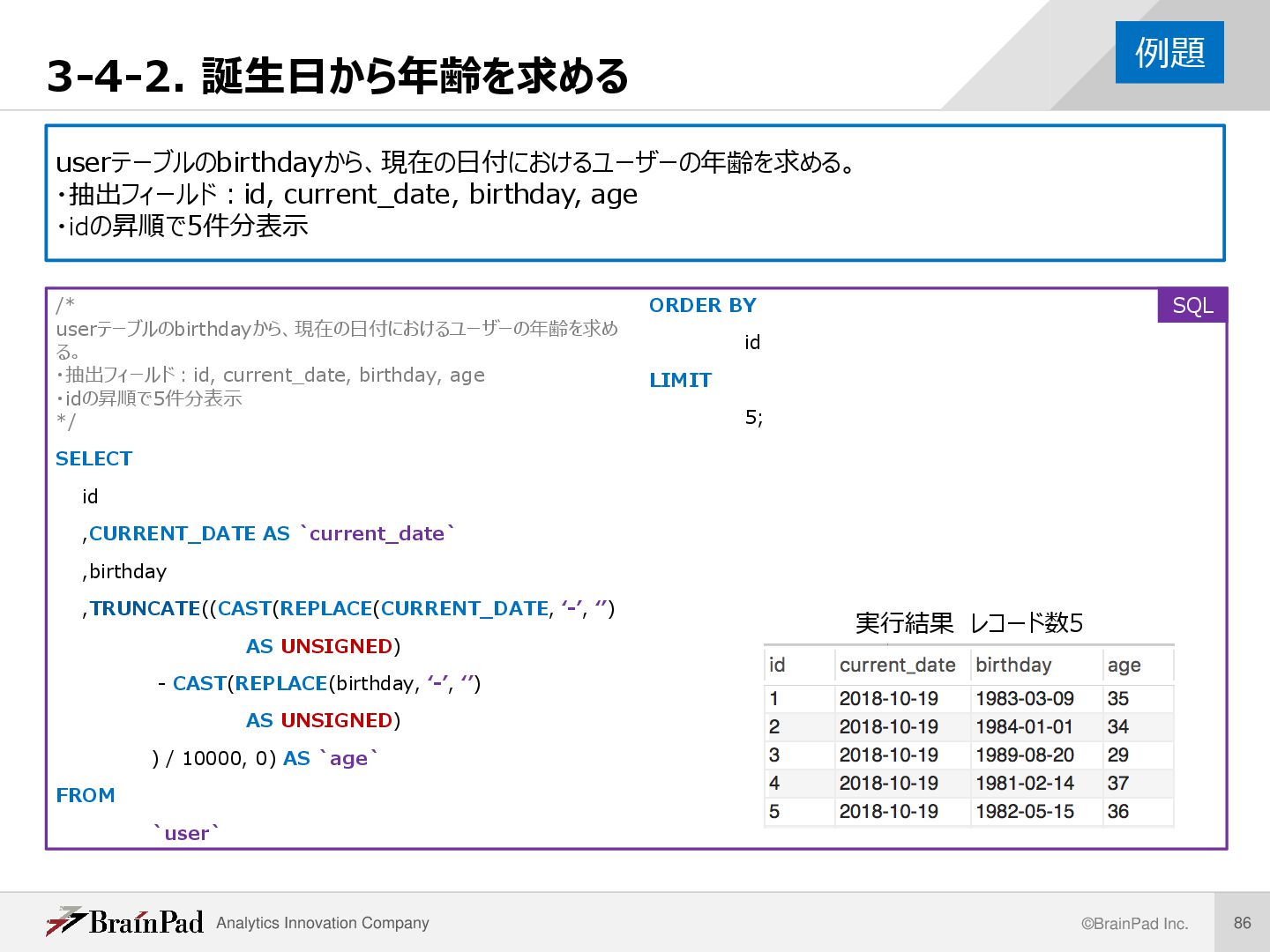
current_date, birthday, age ・idの昇順で5件分表示 /* userテーブルのbirthdayから、現在の日付におけるユーザーの年齢を求め る。 ・抽出フィールド:id, current_date, birthday, age ・idの昇順で5件分表示 */ SELECT id ,CURRENT_DATE AS `current_date` ,birthday ,TRUNCATE((CAST(REPLACE(CURRENT_DATE, ‘-’, ‘’) AS UNSIGNED) - CAST(REPLACE(birthday, ‘-’, ‘’) AS UNSIGNED) ) / 10000, 0) AS `age` FROM `user` ORDER BY id LIMIT 5; 例題 実行結果 レコード数5 SQL
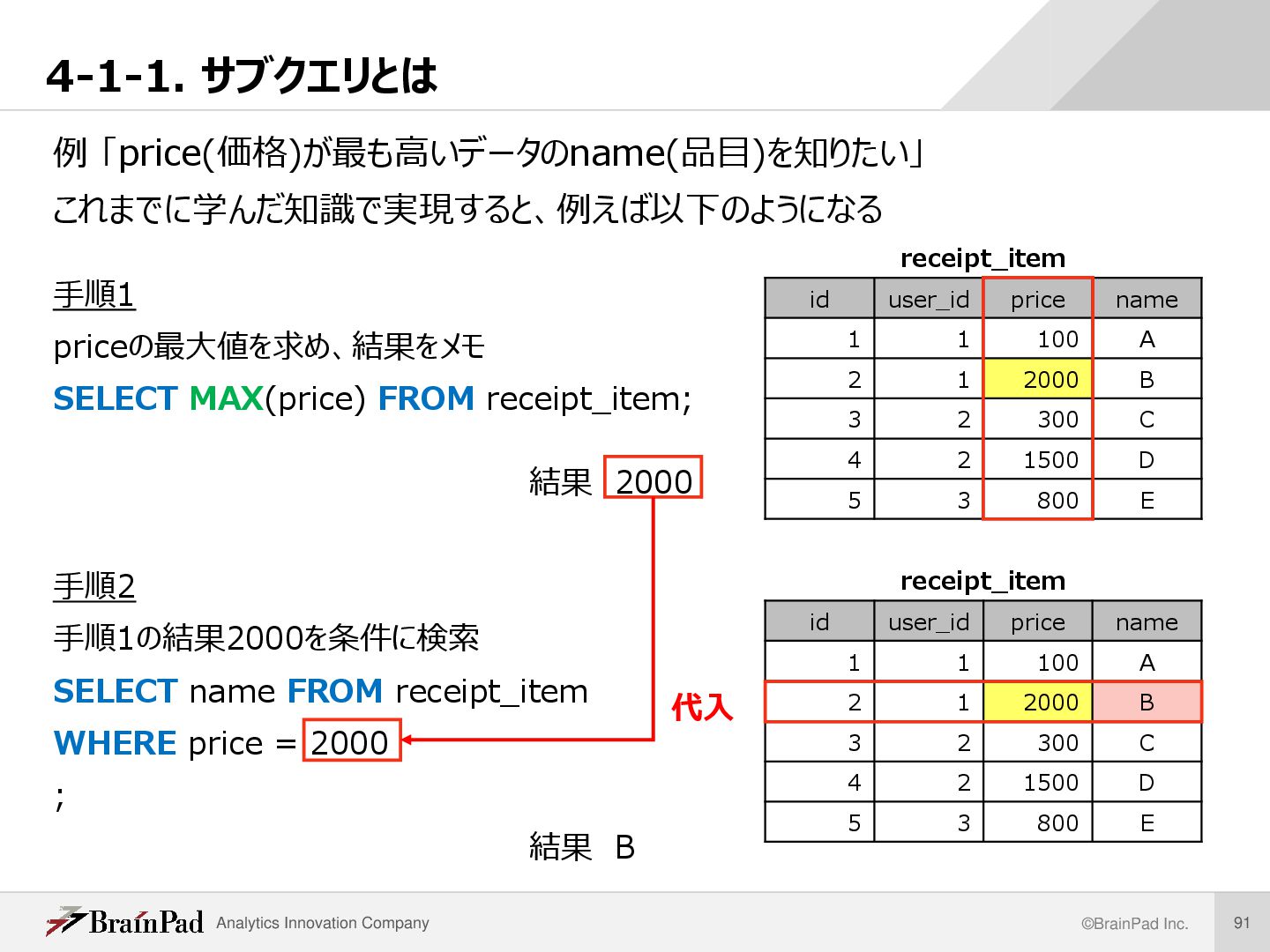
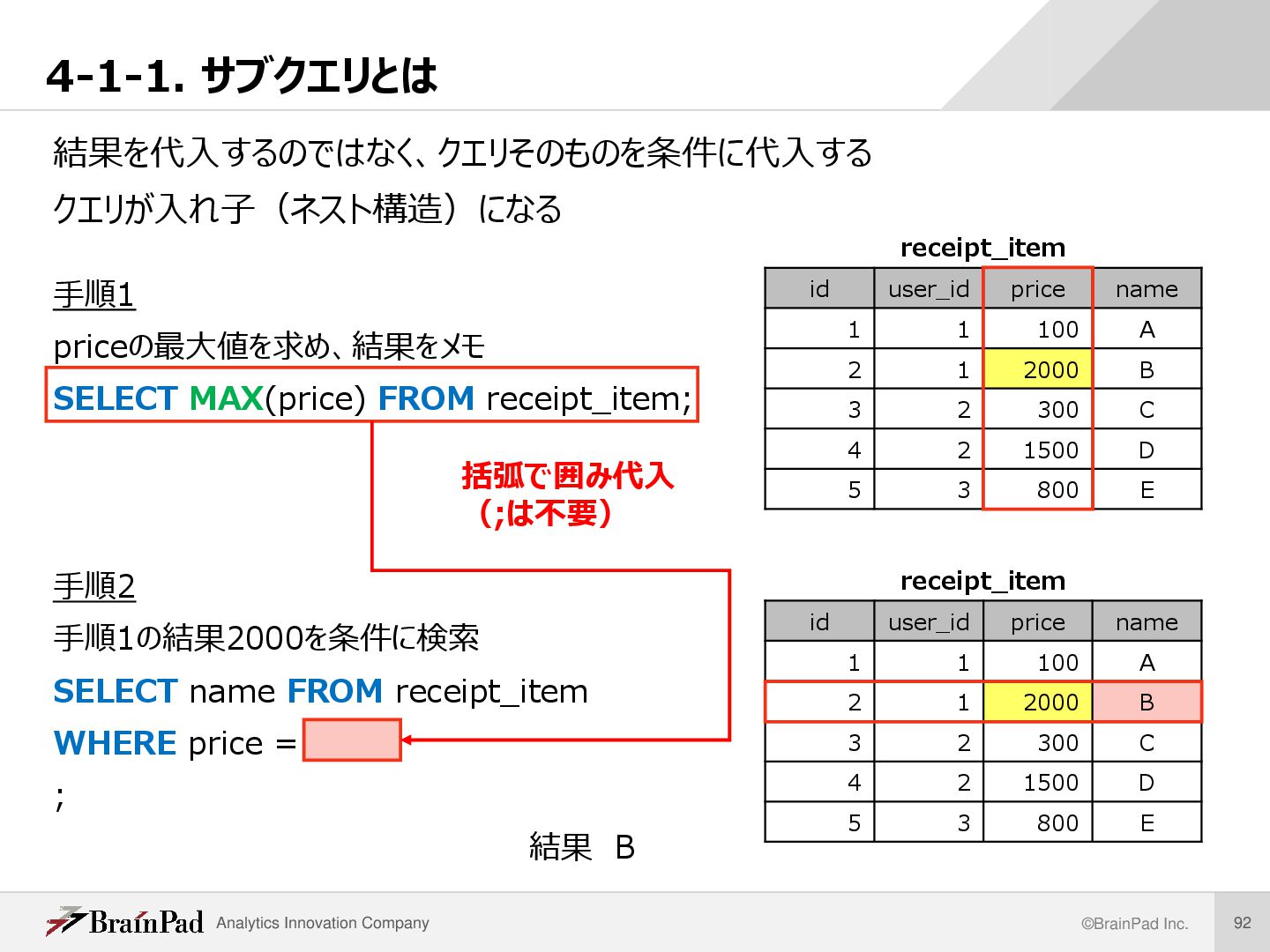
これまでに学んだ知識で実現すると、例えば以下のようになる 手順1 priceの最大値を求め、結果をメモ SELECT MAX(price) FROM receipt_item; 結果 2000 手順2 手順1の結果2000を条件に検索 SELECT name FROM receipt_item WHERE price = 2000 ; 結果 B receipt_item id user_id price name 1 1 100 A 2 1 2000 B 3 2 300 C 4 2 1500 D 5 3 800 E receipt_item id user_id price name 1 1 100 A 2 1 2000 B 3 2 300 C 4 2 1500 D 5 3 800 E 代入
手順1 priceの最大値を求め、結果をメモ SELECT MAX(price) FROM receipt_item; 手順2 手順1の結果2000を条件に検索 SELECT name FROM receipt_item WHERE price = ; 結果 B receipt_item id user_id price name 1 1 100 A 2 1 2000 B 3 2 300 C 4 2 1500 D 5 3 800 E receipt_item id user_id price name 1 1 100 A 2 1 2000 B 3 2 300 C 4 2 1500 D 5 3 800 E 括弧で囲み代入 (;は不要)
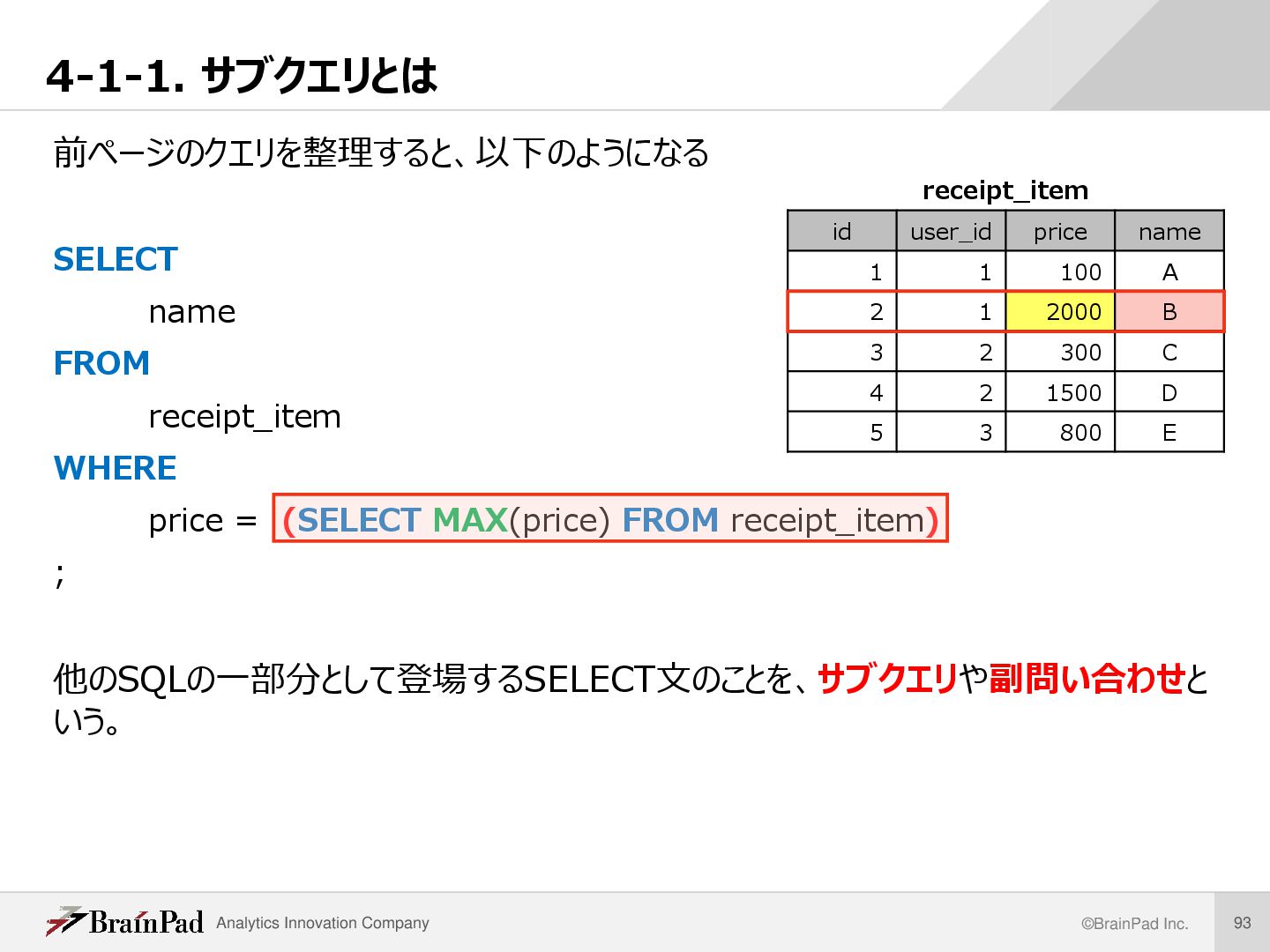
name FROM receipt_item WHERE price = (SELECT MAX(price) FROM receipt_item) ; 他のSQLの一部分として登場するSELECT文のことを、サブクエリや副問い合わせと いう。 receipt_item id user_id price name 1 1 100 A 2 1 2000 B 3 2 300 C 4 2 1500 D 5 3 800 E
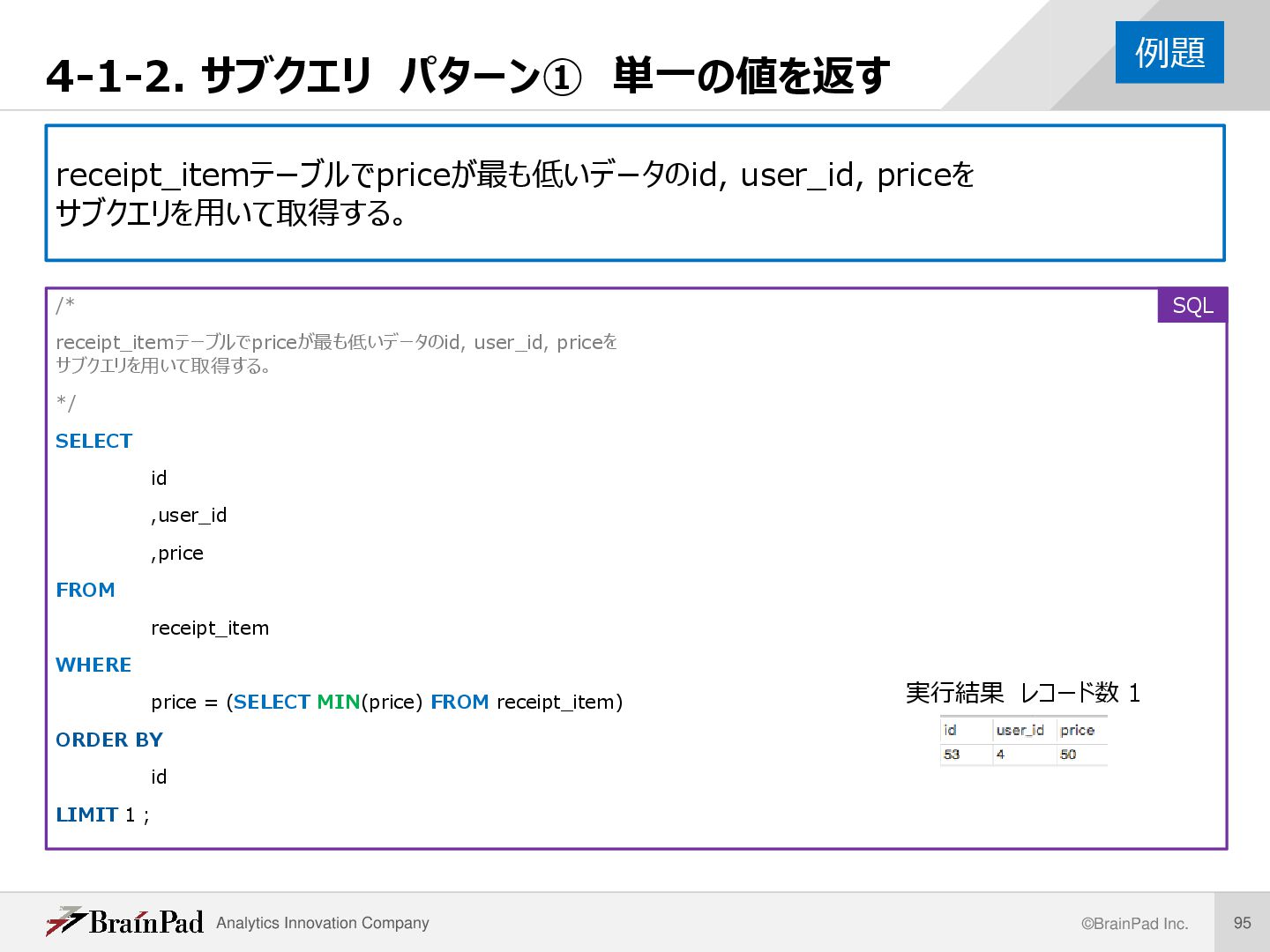
receipt_itemテーブルでpriceが最も低いデータのid, user_id, priceを サブクエリを用いて取得する。 /* receipt_itemテーブルでpriceが最も低いデータのid, user_id, priceを サブクエリを用いて取得する。 */ SELECT id ,user_id ,price FROM receipt_item WHERE price = (SELECT MIN(price) FROM receipt_item) ORDER BY id LIMIT 1 ; 例題 SQL 実行結果 レコード数 1
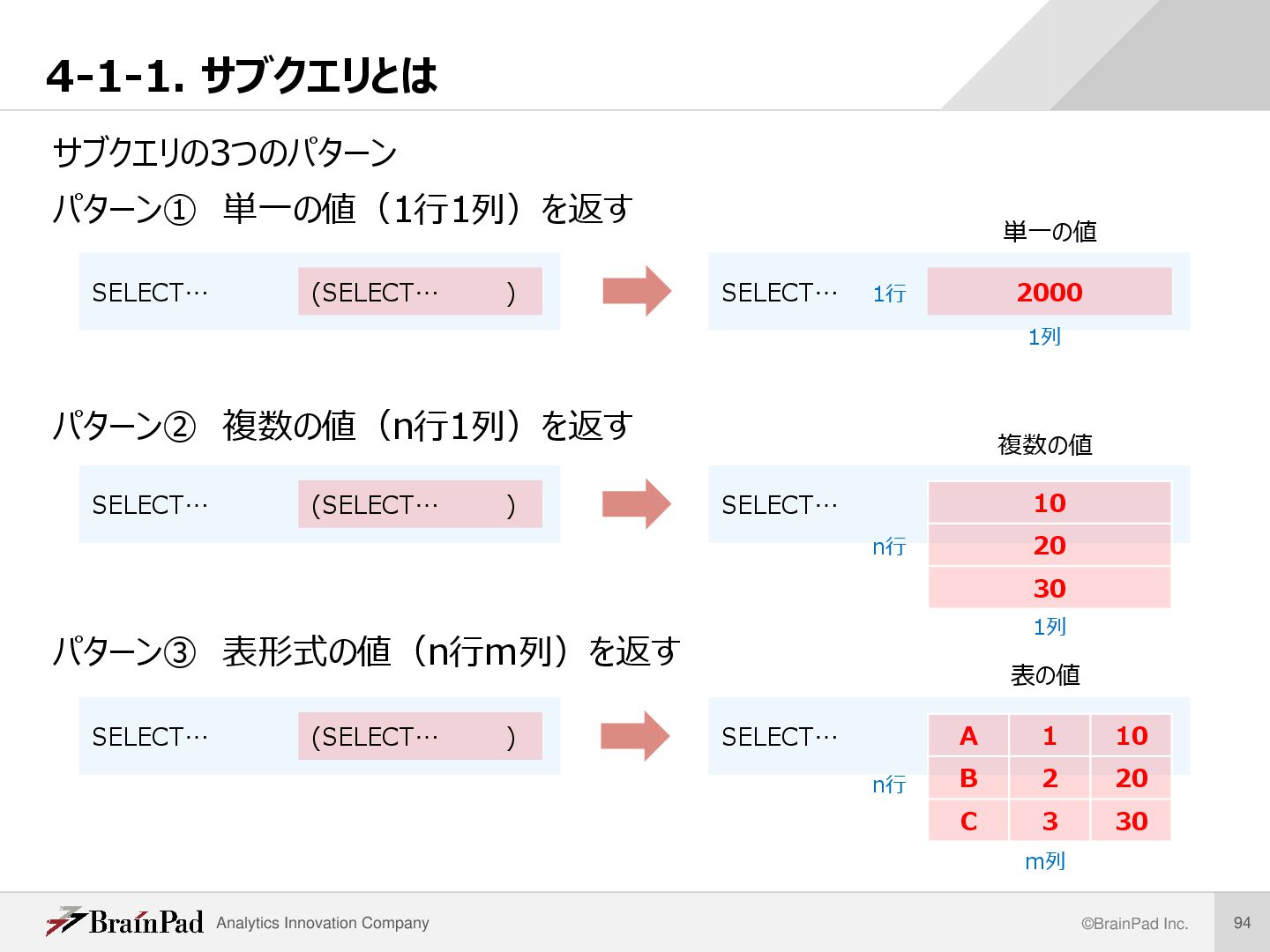
単一行サブクエリ • 検索結果が1行1列の1つの値になるサブクエリ • WHEREの他にSELECTの選択列リストにも記述できる 例 user_id, priceとpriceの全体平均値を並べて表示 SELECT user_id ,price ,(SELECT AVG(price) FROM receipt_item) AS avg_price FROM receipt_item ORDER BY user_id LIMIT 5 ; 解説 /* receipt_itemテーブルでpriceが最も低いデータ のid, user_id, priceをサブクエリを用いて取得す る。 */ SELECT id ,user_id ,price FROM receipt_item WHERE price = (SELECT MIN(price) FROM receipt_item) ORDER BY id LIMIT 1 ; SQL 実行結果 レコード数 5
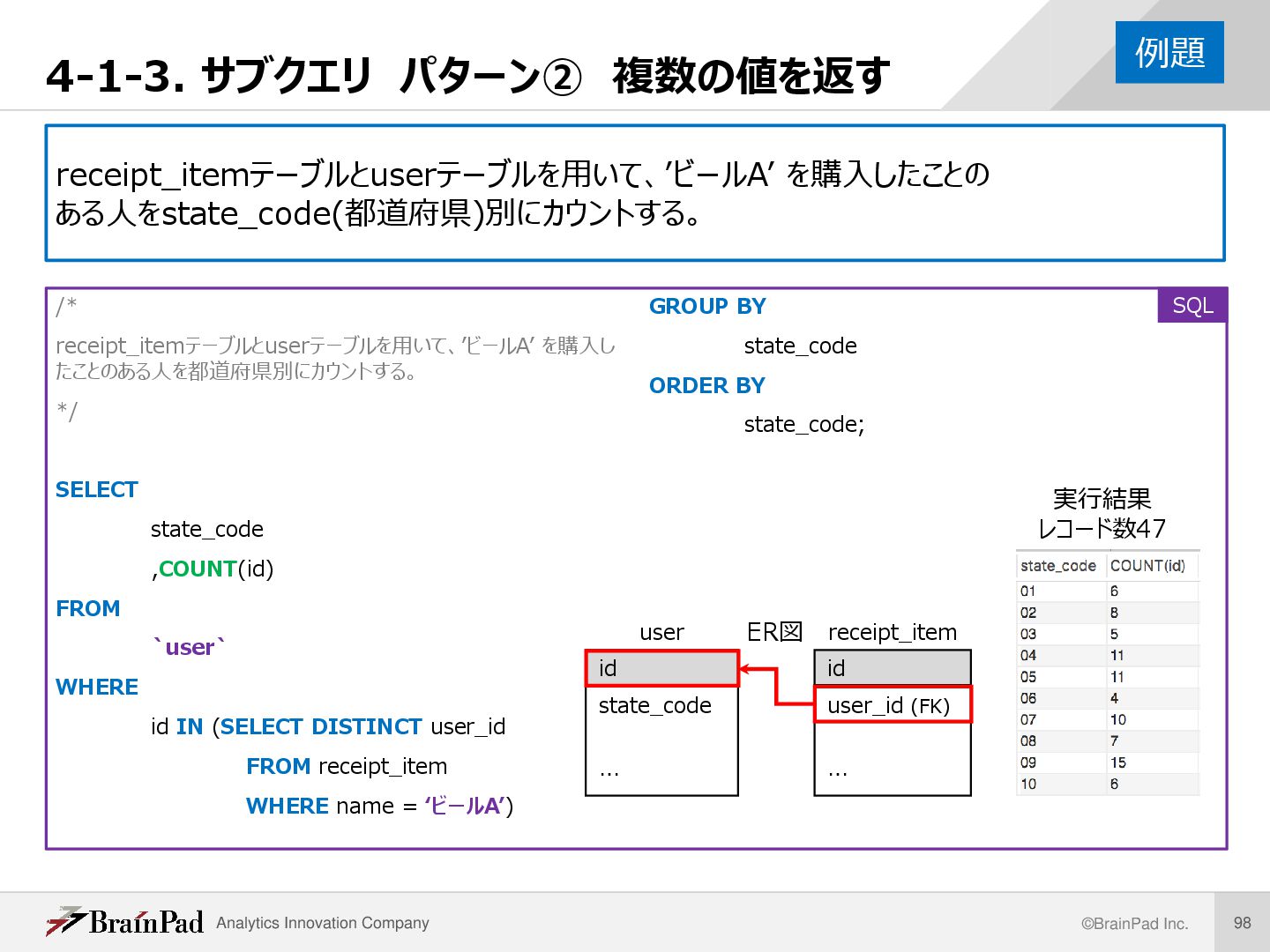
receipt_itemテーブルとuserテーブルを用いて、’ビールA’ を購入したことの ある人をstate_code(都道府県)別にカウントする。 /* receipt_itemテーブルとuserテーブルを用いて、’ビールA’ を購入し たことのある人を都道府県別にカウントする。 */ SELECT state_code ,COUNT(id) FROM `user` WHERE id IN (SELECT DISTINCT user_id FROM receipt_item WHERE name = ‘ビールA’) GROUP BY state_code ORDER BY state_code; 例題 実行結果 レコード数47 SQL id user_id (FK) … receipt_item id state_code … user ER図
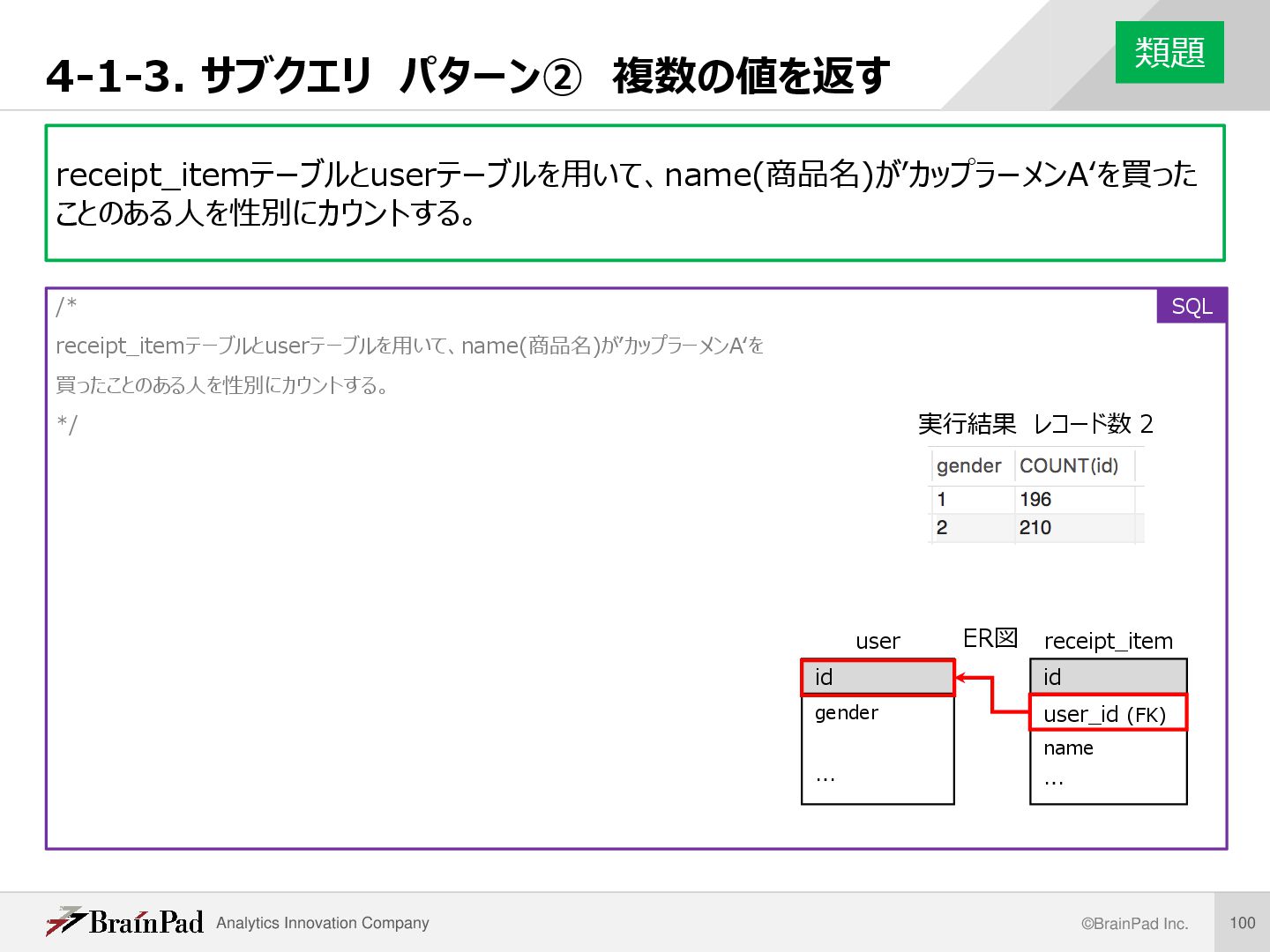
複数行サブクエリ • 検索結果がn行1列の複数の値となるサブクエリ … WHERE id IN (SELECT DISTINCT user_id FROM receipt_item WHERE name = ‘ビールA’) … WHERE id IN 複数の値と比較するするときはIN演算子, ANY/ALL演算子を用い る。比較演算子=,>などは使えないので注意! (復習) • IN演算子:列挙した値のいずれかに一致するか判定 • ANY演算子:それぞれと比較して、いずれかが真なら真 • ALL演算子:それぞれと比較して、全て真なら真 ※redshiftでは一般的なALLはサポートしておらず、<> ALL (= NOT IN)しか使えないので注意 解説 /* receipt_itemテーブルとuserテーブルを用いて、’ アイス’ を購入したことのある人を都道府県別にカ ウントする。 */ SELECT state_code ,COUNT(id) FROM `user` WHERE id IN (SELECT DISTINCT user_id FROM receipt_item WHERE name = ‘ビールA’) … (以下省略) SQL user_id 10 20 …
receipt_itemテーブルを用いて、1回の買い物の合計金額の平均値を求める。 /* receipt_itemテーブルを用いて、1回の買い物の合計金額の平均 値を求める。 */ SELECT AVG(sum_price) FROM (SELECT receipt_id ,SUM(price) AS sum_price FROM receipt_item GROUP BY receipt_id) AS tbl ; 例題 実行結果 レコード数1 SQL id user_id (FK) price … receipt_item
表形式の結果となるサブクエリ • 検索結果がn行m列の表となるサブクエリ … FROM (SELECT receipt_id ,SUM(price) AS sum_price FROM receipt_item GROUP BY receipt_id) AS tbl … FROM • この表のsum_priceの平均値を求めている 解説 /* receipt_itemテーブルとuserテーブルを用いて、1 回の買い物の合計金額の平均値を求める。 */ SELECT AVG(sum_price) FROM (SELECT receipt_id ,SUM(price) AS sum_price FROM receipt_item GROUP BY receipt_id) AS tbl ; SQL receipt_id sum_price 1 409 2 198 … …
を求める。ただし、サブクエリの代わりにWITH句を利用する。 /* receipt_itemテーブルを用いて、1回の買い物の合計金額の平均 値を求める。ただし、サブクエリの代わりにWITH句を利用する。 */ WITH tbl AS ( SELECT receipt_id ,SUM(price) AS sum_price FROM receipt_item GROUP BY receipt_id ) SELECT AVG(sum_price) FROM tbl; 例題 実行結果 レコード数1 SQL id user_id (FK) price … receipt_item
を用いて内部結合する。 ・抽出フィールド:receipt テーブルid, shop_name / userテーブル id, state_code /* receiptテーブルとuserテーブルを、userテーブルのidとreceiptテーブルの user_idを用いて内部結合する。 ・抽出フィールド:receipt テーブルid, shop_name / userテーブル id, state_code */ SELECT r.id AS receipt_id ,u.id AS user_id ,r.shop_name ,u.state_code FROM receipt AS r INNER JOIN `user` AS u ON r.user_id = u.id ORDER BY r.id LIMIT 5; 例題 実行結果 レコード数5 SQL id user_id (FK) shop_name … receipt id state_code … user ER図
結合する。 ・抽出フィールド:receipt テーブルid, shop_name / userテーブル id, state_code ・receiptテーブルのid >= 60を対象とし、昇順で5件表示する。 /* receiptテーブル(左表)とuserテーブル(右表)を、userテーブルのidとreceipt テーブルのuser_idを用いて外部結合する。 ・抽出フィールド:receipt テーブルid, shop_name / userテーブル id, state_code */ SELECT r.id AS receipt_id ,u.id AS user_id ,r.shop_name ,u.state_code FROM receipt AS r LEFT JOIN `user` AS u ON r.user_id = u.id WHERE r.id >= 60 ORDER BY r.id LIMIT 5; 例題 実行結果 レコード数5 SQL id user_id (FK) shop_name … receipt id state_code … user ER図
LEFT JOIN • 左外部結合 対応するレコードがない場合でもレコードが削除されない結合 • 基本構文 FROM テーブルA(左表) LEFT JOIN テーブルB(右表) ON 結合条件 対応するレコードがない場合 • 全てNULLになる 解説 /* receiptテーブルとuserテーブルを、userテーブル のidとreceiptテーブルのuser_idを用いて内部結 合する。 抽出フィールド:receipt テーブルid, shop_name / userテーブル id, state_code */ SELECT r.id AS receipt_id ,u.id AS user_id ,r.shop_name ,u.state_code FROM receipt AS r LEFT JOIN `user` AS u ON r.user_id = u.id … (以下省略) SQL
LEFT JOINのイメージ 解説 user(右表) id state_code 1 13 2 14 3 27 receipt(左表) id user_id shop_name 1 1 A 2 2 B 3 2 C 4 3 C 5 4 D 外部結合した結果 receipt_id user_id shop_name state_code 1 1 A 13 2 2 B 14 3 2 C 14 4 3 C 27 5 4 D (NULL) 結合の相手がいない行も削除され ず、存在しないデータは全てNULL になる • 分析用のデータマートを作成する際は、件数の不整合が生じないよう、一般的にLEFT JOINを用いる
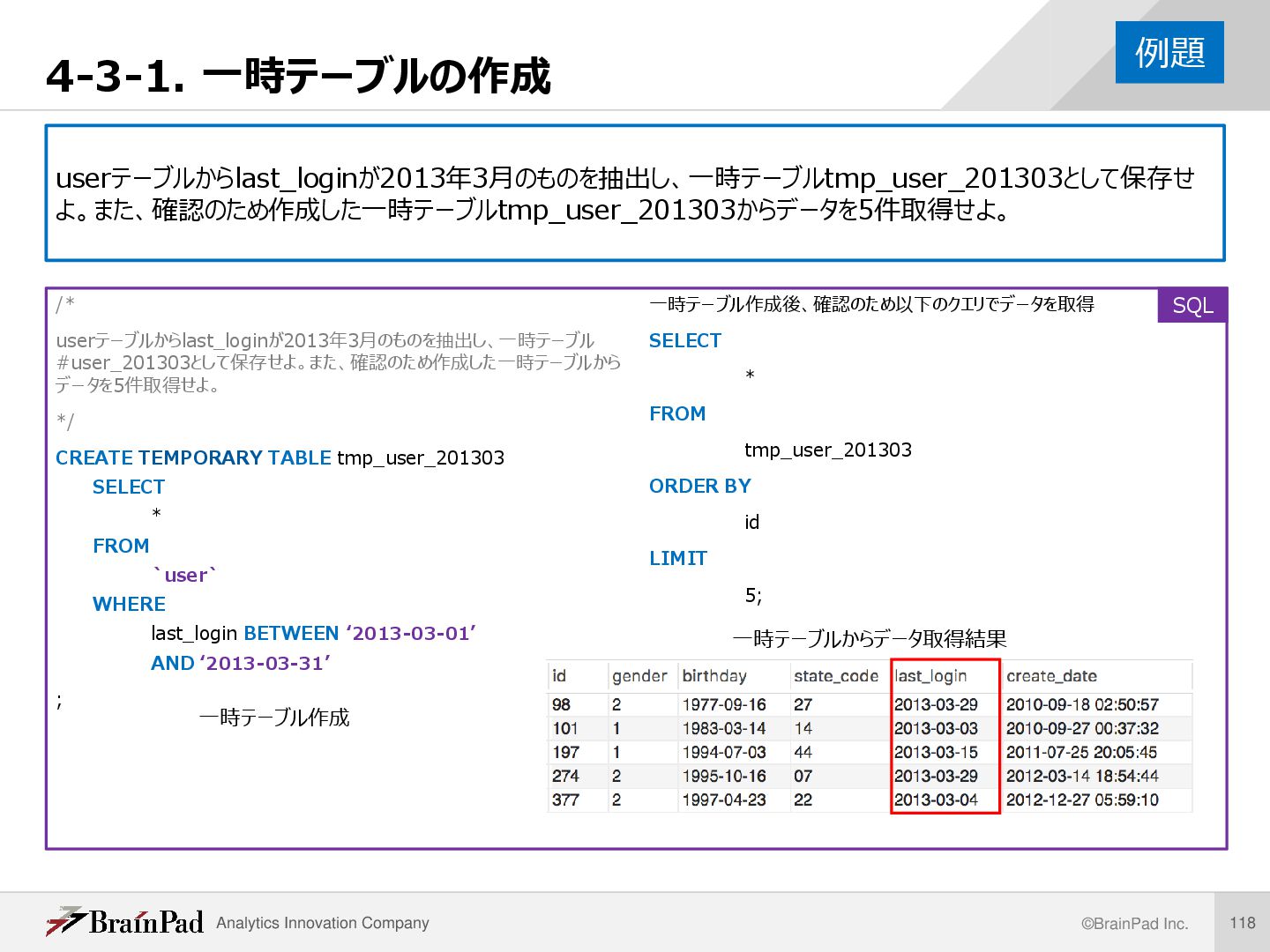
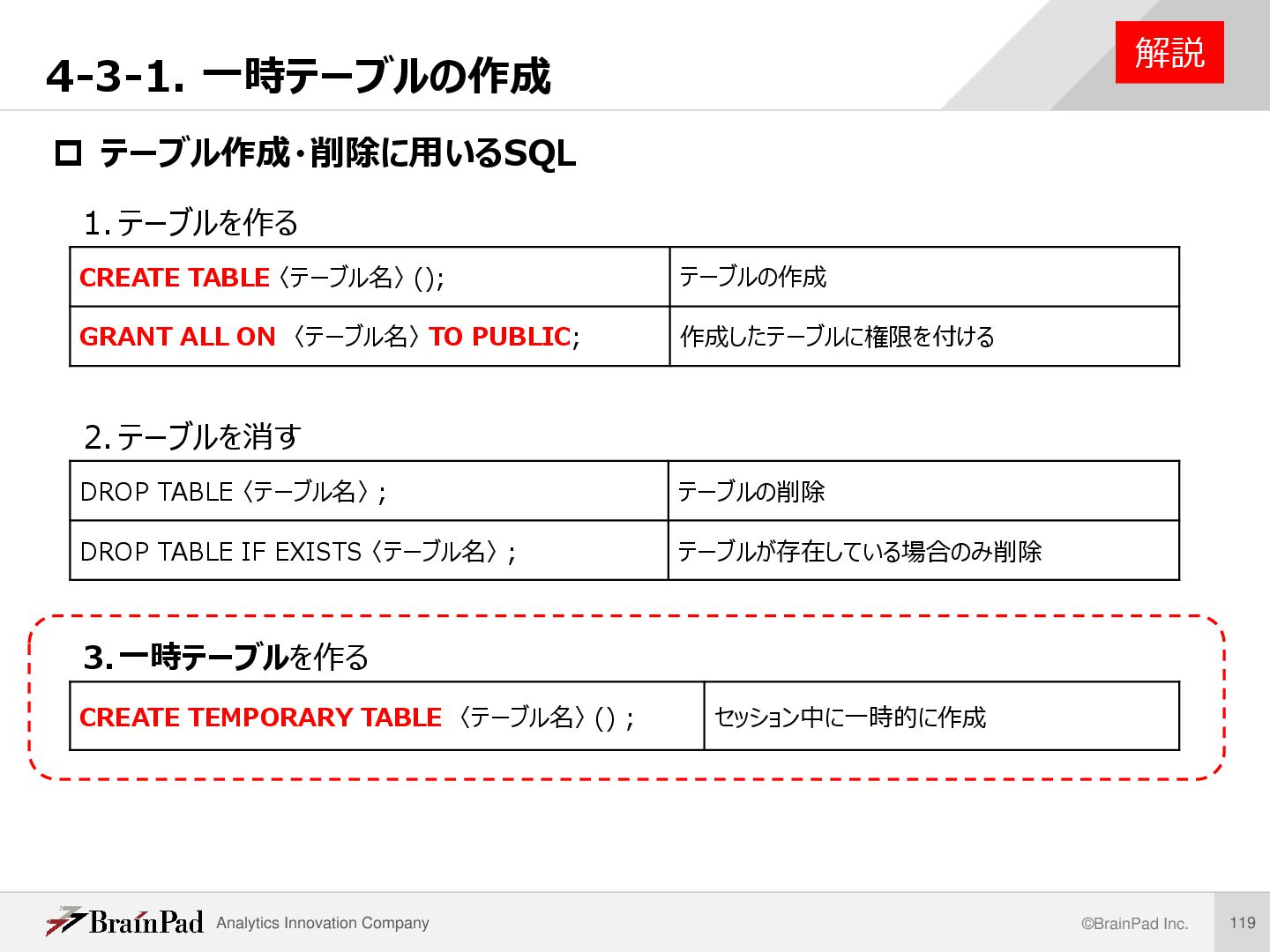
/* userテーブルからlast_loginが2013年3月のものを抽出し、一時テーブル #user_201303として保存せよ。また、確認のため作成した一時テーブルから データを5件取得せよ。 */ CREATE TEMPORARY TABLE tmp_user_201303 SELECT * FROM `user` WHERE last_login BETWEEN ‘2013-03-01’ AND ‘2013-03-31’ ; 一時テーブル作成後、確認のため以下のクエリでデータを取得 SELECT * FROM tmp_user_201303 ORDER BY id LIMIT 5; 例題 SQL 一時テーブル作成 一時テーブルからデータ取得結果
SUM, AVG, MIN, MAXで集計を行う。 ・user_idが5以下のデータを対象とする。 /* receipt_itemテーブルで、user_idで区切ったパーティション毎にSUM, AVG, MIN, MAXで集計を行う。 ・user_idが5以下のデータを対象とする。 */ SELECT user_id ,price ,SUM(price) OVER(PARTITION BY user_id) AS `sum` ,AVG(price) OVER(PARTITION BY user_id) AS `avg` ,MIN(price) OVER(PARTITION BY user_id) AS `min` ,MAX(price) OVER(PARTITION BY user_id) AS `max` FROM receipt_item WHERE user_id <=5 ORDER BY user_id ; 例題 実行結果 レコード数4058 SQL … …
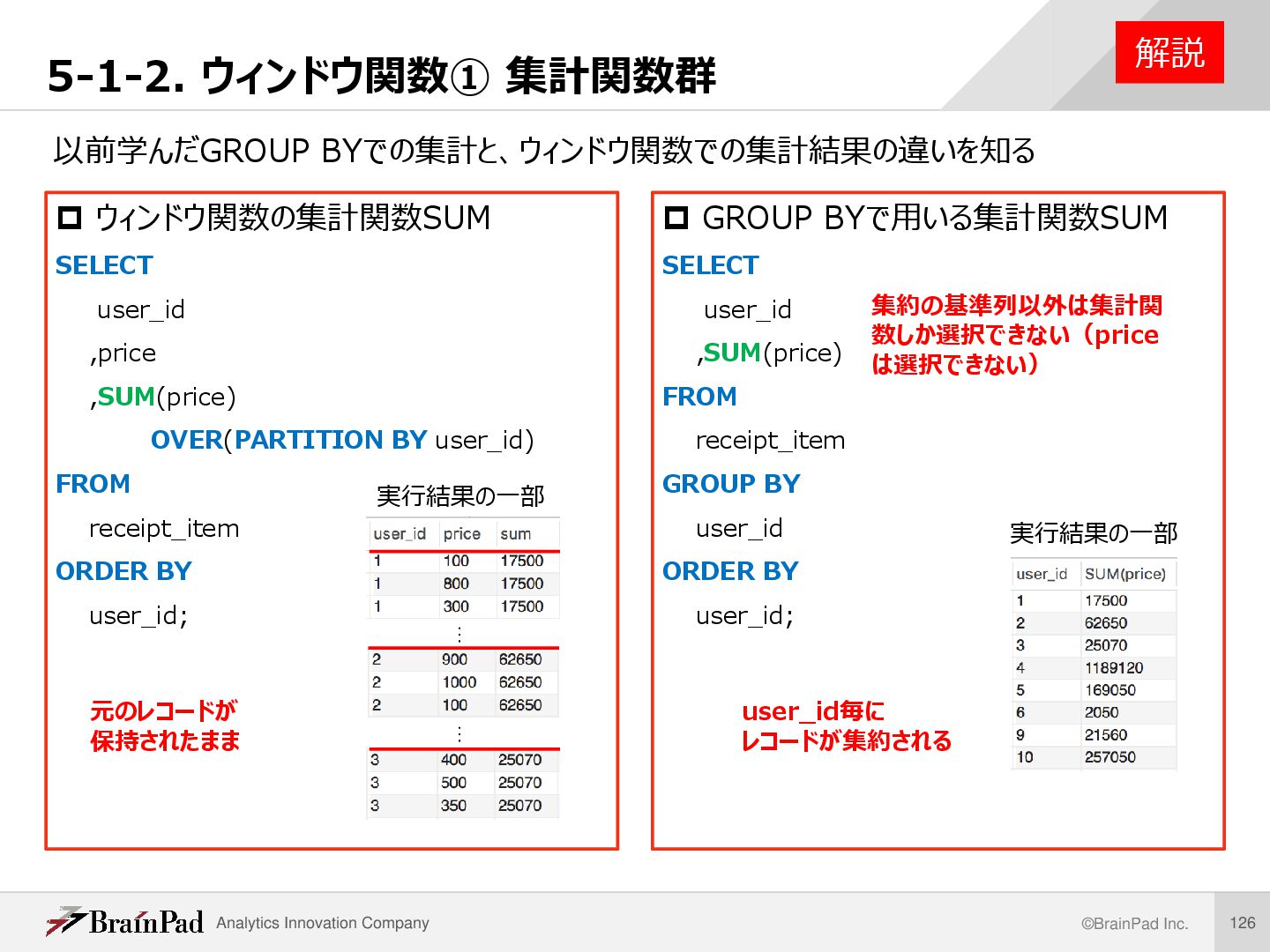
ウィンドウ関数の集計関数SUM SELECT user_id ,price ,SUM(price) OVER(PARTITION BY user_id) FROM receipt_item ORDER BY user_id; 解説 GROUP BYで用いる集計関数SUM SELECT user_id ,SUM(price) FROM receipt_item GROUP BY user_id ORDER BY user_id; 実行結果の一部 実行結果の一部 元のレコードが 保持されたまま user_id毎に レコードが集約される 集約の基準列以外は集計関 数しか選択できない(price は選択できない) 以前学んだGROUP BYでの集計と、ウィンドウ関数での集計結果の違いを知る … …
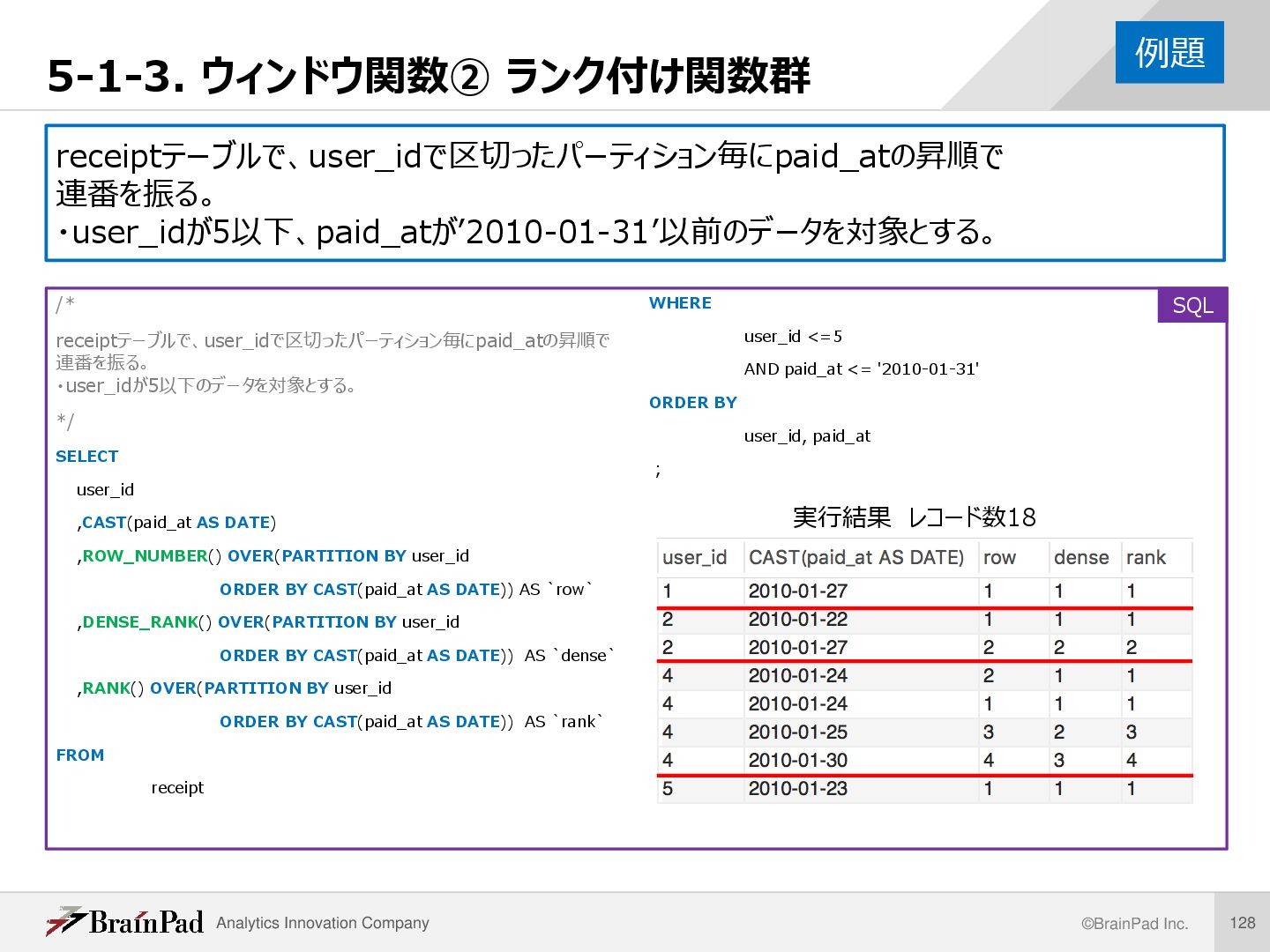
連番を振る。 ・user_idが5以下、paid_atが’2010-01-31’以前のデータを対象とする。 /* receiptテーブルで、user_idで区切ったパーティション毎にpaid_atの昇順で 連番を振る。 ・user_idが5以下のデータを対象とする。 */ SELECT user_id ,CAST(paid_at AS DATE) ,ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY CAST(paid_at AS DATE)) AS `row` ,DENSE_RANK() OVER(PARTITION BY user_id ORDER BY CAST(paid_at AS DATE)) AS `dense` ,RANK() OVER(PARTITION BY user_id ORDER BY CAST(paid_at AS DATE)) AS `rank` FROM receipt WHERE user_id <=5 AND paid_at <= '2010-01-31' ORDER BY user_id, paid_at ; 例題 実行結果 レコード数18 SQL
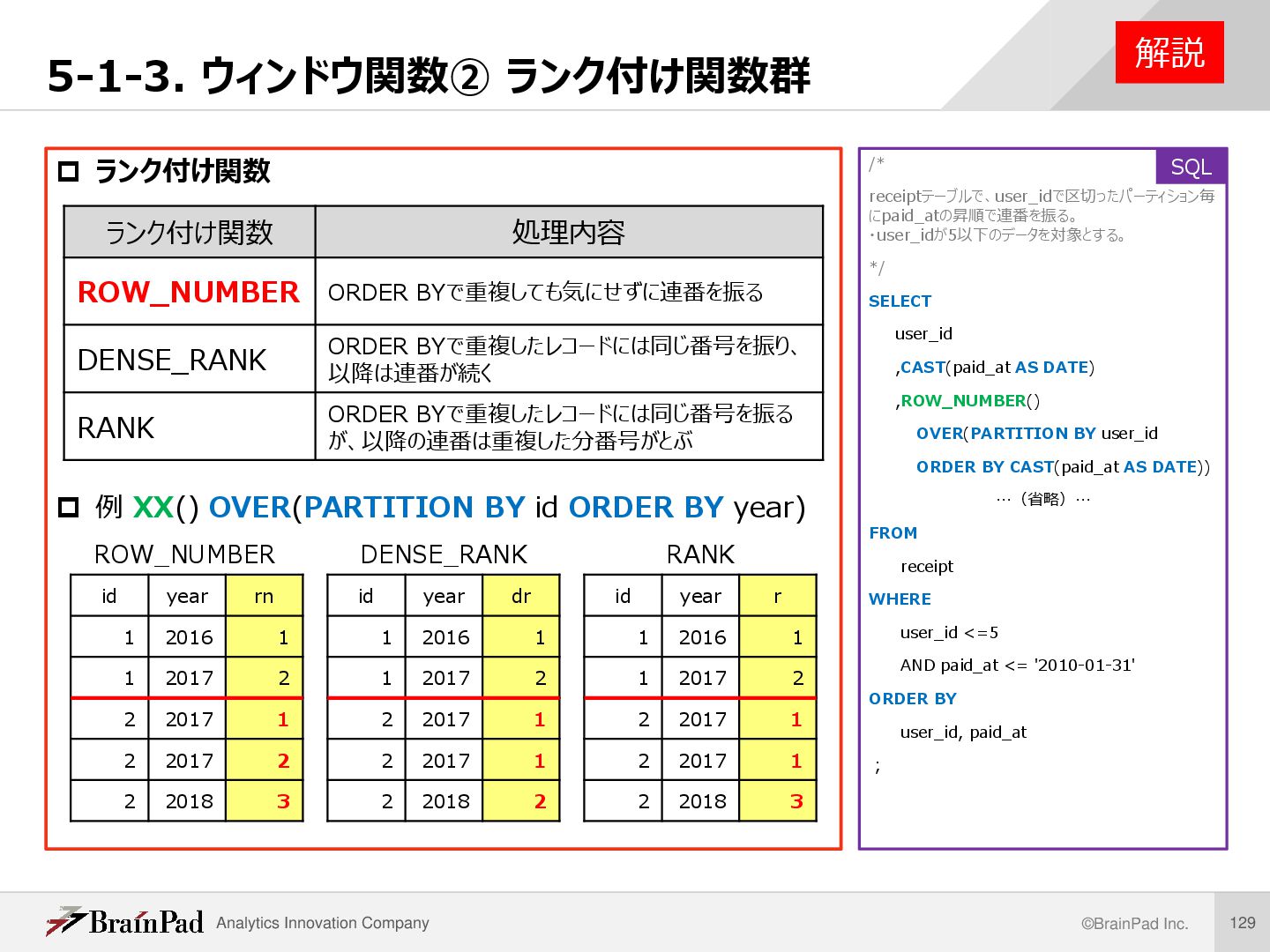
ランク付け関数 例 XX() OVER(PARTITION BY id ORDER BY year) 解説 /* receiptテーブルで、user_idで区切ったパーティション毎 にpaid_atの昇順で連番を振る。 ・user_idが5以下のデータを対象とする。 */ SELECT user_id ,CAST(paid_at AS DATE) ,ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY CAST(paid_at AS DATE)) …(省略)… FROM receipt WHERE user_id <=5 AND paid_at <= '2010-01-31' ORDER BY user_id, paid_at ; SQL ランク付け関数 処理内容 ROW_NUMBER ORDER BYで重複しても気にせずに連番を振る DENSE_RANK ORDER BYで重複したレコードには同じ番号を振り、 以降は連番が続く RANK ORDER BYで重複したレコードには同じ番号を振る が、以降の連番は重複した分番号がとぶ id year rn 1 2016 1 1 2017 2 2 2017 1 2 2017 2 2 2018 3 id year dr 1 2016 1 1 2017 2 2 2017 1 2 2017 1 2 2018 2 id year r 1 2016 1 1 2017 2 2 2017 1 2 2017 1 2 2018 3 ROW_NUMBER DENSE_RANK RANK
ROW_NUMBERの使い道 • グループ毎に最大値(最小値)を持つレコードを抽出する • 例 user_id毎にpriceの最大値を求める(※user_idが5以下のデータを対象) SELECT user_id ,price AS max_price ,name FROM (SELECT * ,ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY price DESC) AS seq FROM receipt_item) AS ri WHERE seq = 1 AND user_id <= 5 ORDER BY user_id ; 解説 実行結果 レコード数5 サブクエリ(次ページで解説)
サブクエリ部分 解説 (SELECT * ,ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY price DESC) AS seq FROM receipt_item) AS ri ※都合により一部のカラムのみ掲載 サブクエリによって得られたテーブル ri 最終結果 WHERE seq = 1 各グループの一 番上を取得 priceの降順に連番を振る …
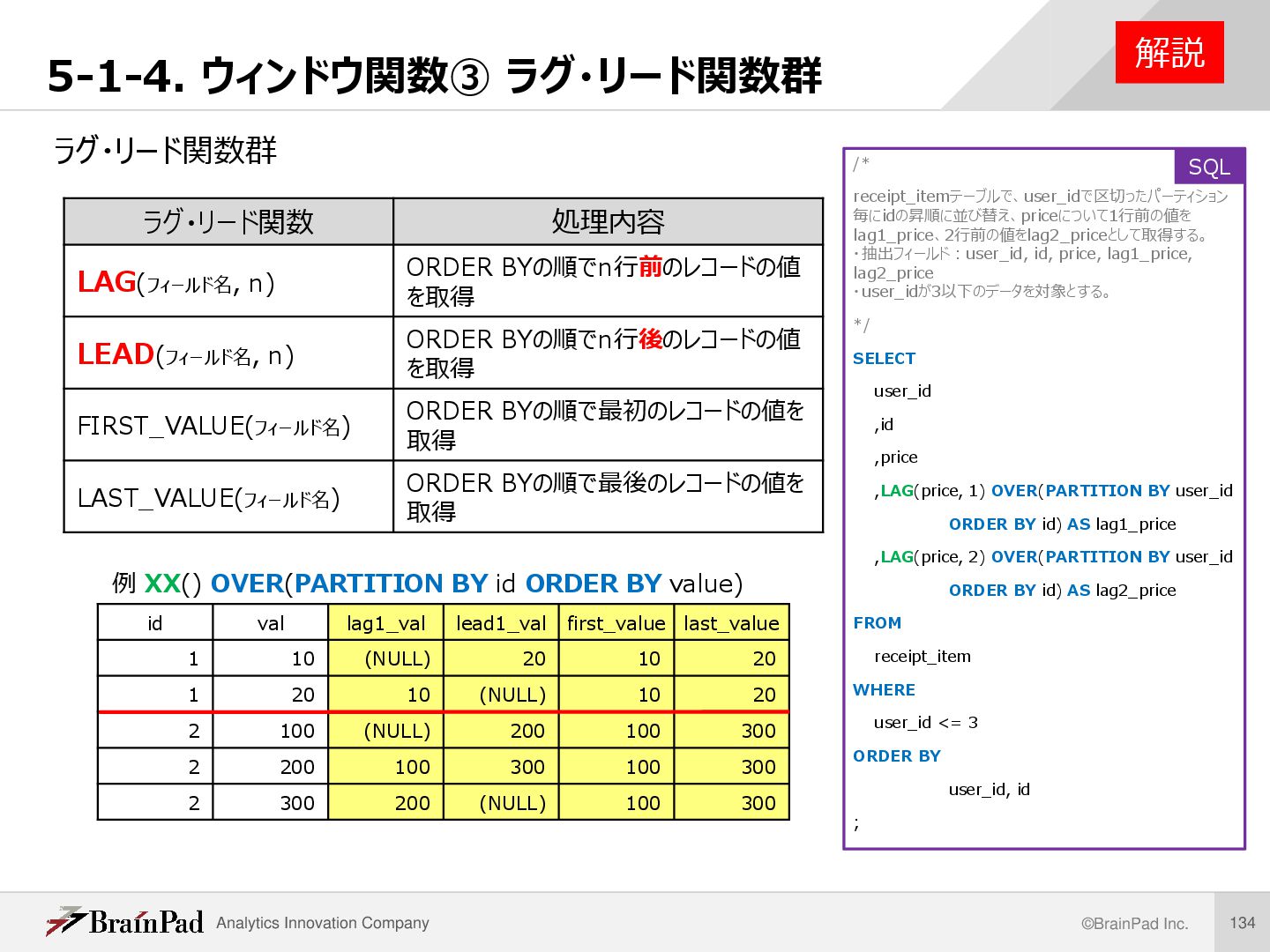
値をlag1_price、2行前の値をlag2_priceとして取得する。 ・抽出フィールド:user_id, id, price, lag1_price, lag2_price ・user_idが3以下のデータを対象とする。 /* receipt_itemテーブルで、user_idで区切ったパーティション毎にidの昇順に 並び替え、priceについて1行前の値をlag1_price、2行前の値を lag2_priceとして取得する。 ・抽出フィールド:user_id, id, price, lag1_price, lag2_price ・user_idが3以下のデータを対象とする。 */ SELECT user_id ,id ,price ,LAG(price, 1) OVER(PARTITION BY user_id ORDER BY id) AS lag1_price ,LAG(price, 2) OVER(PARTITION BY user_id ORDER BY id) AS lag2_price FROM receipt_item WHERE user_id <= 3 ORDER BY user_id, id ; 例題 実行結果 SQL …
解説 /* receipt_itemテーブルで、user_idで区切ったパーティション 毎にidの昇順に並び替え、priceについて1行前の値を lag1_price、2行前の値をlag2_priceとして取得する。 ・抽出フィールド:user_id, id, price, lag1_price, lag2_price ・user_idが3以下のデータを対象とする。 */ SELECT user_id ,id ,price ,LAG(price, 1) OVER(PARTITION BY user_id ORDER BY id) AS lag1_price ,LAG(price, 2) OVER(PARTITION BY user_id ORDER BY id) AS lag2_price FROM receipt_item WHERE user_id <= 3 ORDER BY user_id, id ; SQL ラグ・リード関数 処理内容 LAG(フィールド名, n) ORDER BYの順でn行前のレコードの値 を取得 LEAD(フィールド名, n) ORDER BYの順でn行後のレコードの値 を取得 FIRST_VALUE(フィールド名) ORDER BYの順で最初のレコードの値を 取得 LAST_VALUE(フィールド名) ORDER BYの順で最後のレコードの値を 取得 id val lag1_val lead1_val first_value last_value 1 10 (NULL) 20 10 20 1 20 10 (NULL) 10 20 2 100 (NULL) 200 100 300 2 200 100 300 100 300 2 300 200 (NULL) 100 300 例 XX() OVER(PARTITION BY id ORDER BY value)
ウィンドウ関数全体の基本構文(※関数によって細かな差があるので注意) 関数(集計フィールド名) OVER(PARTITION BY フィールド名 ORDER BY フィールド名 ROWS 集計対象行の範囲) PARTITION BY • パーティションを分ける。「◦◦別で••順に集計」の◦◦ • 省略するとテーブル全体について集計 ORDER BY • 各パーティション内の行の順序。「◦◦別で••順に集計」の•• ROWS • 集計処理する対象行を定義する(詳細は次のページで説明)
ROWS • 集計処理する対象行を定義する • デフォルト「開始点: ウィンドウの最初の行、終了点:ウィンドウの最後の行」 (ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) UNBOUNDED PRECEDING パーティションの最初の行 CURRENT ROW 現在の行 UNBOUNDED FOLLOWING パーティションの最後の行 ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING (※省略した時のデフォルト) ROWS BETWEEN 2 PRECEDING AND CURRENT ROW ROWS BETWEEN 1 PRECEDING AND 2 FOLLOWING ROWS BETWEEN 1 FOLLOWING AND 3 FOLLOWING
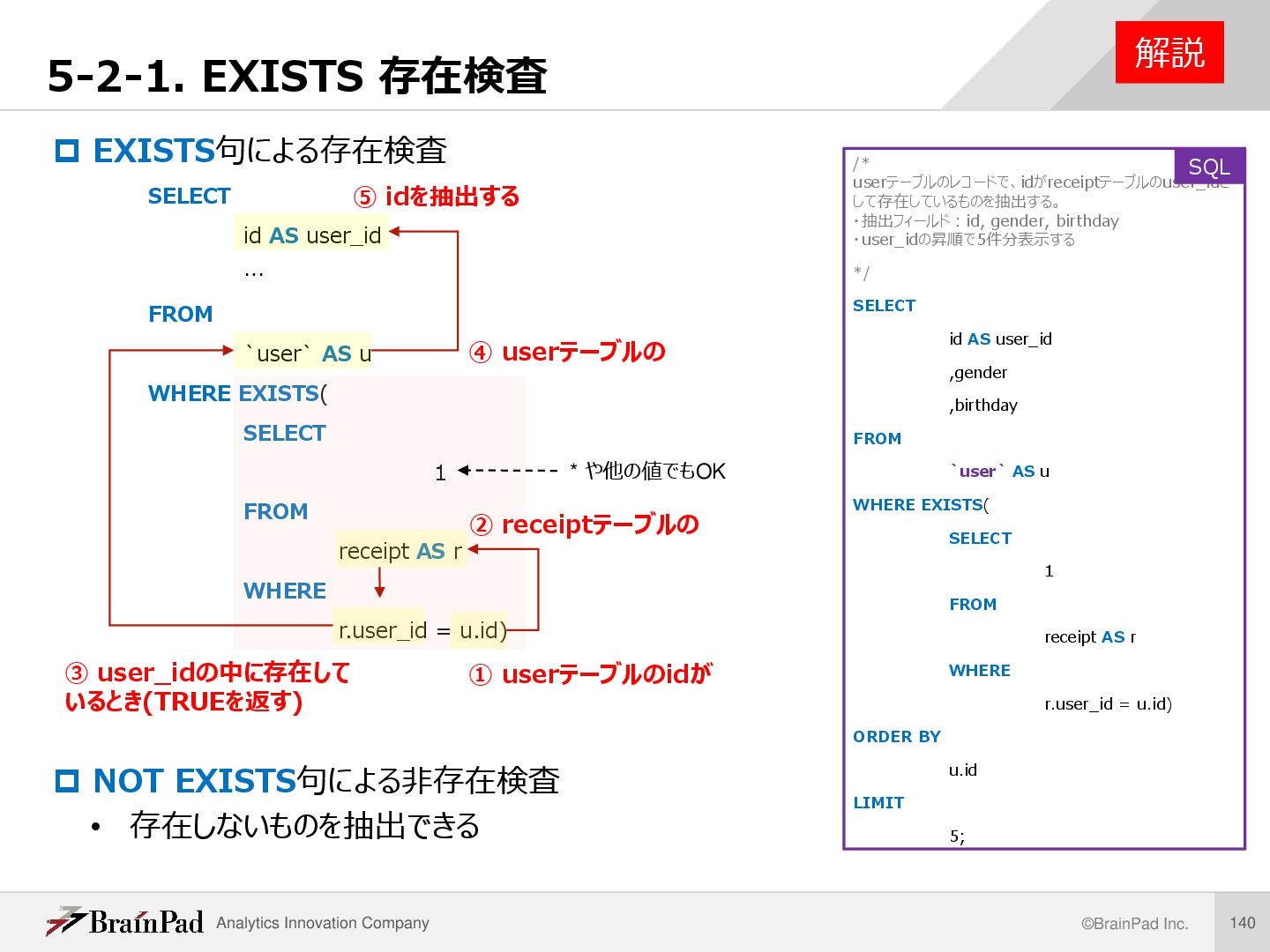
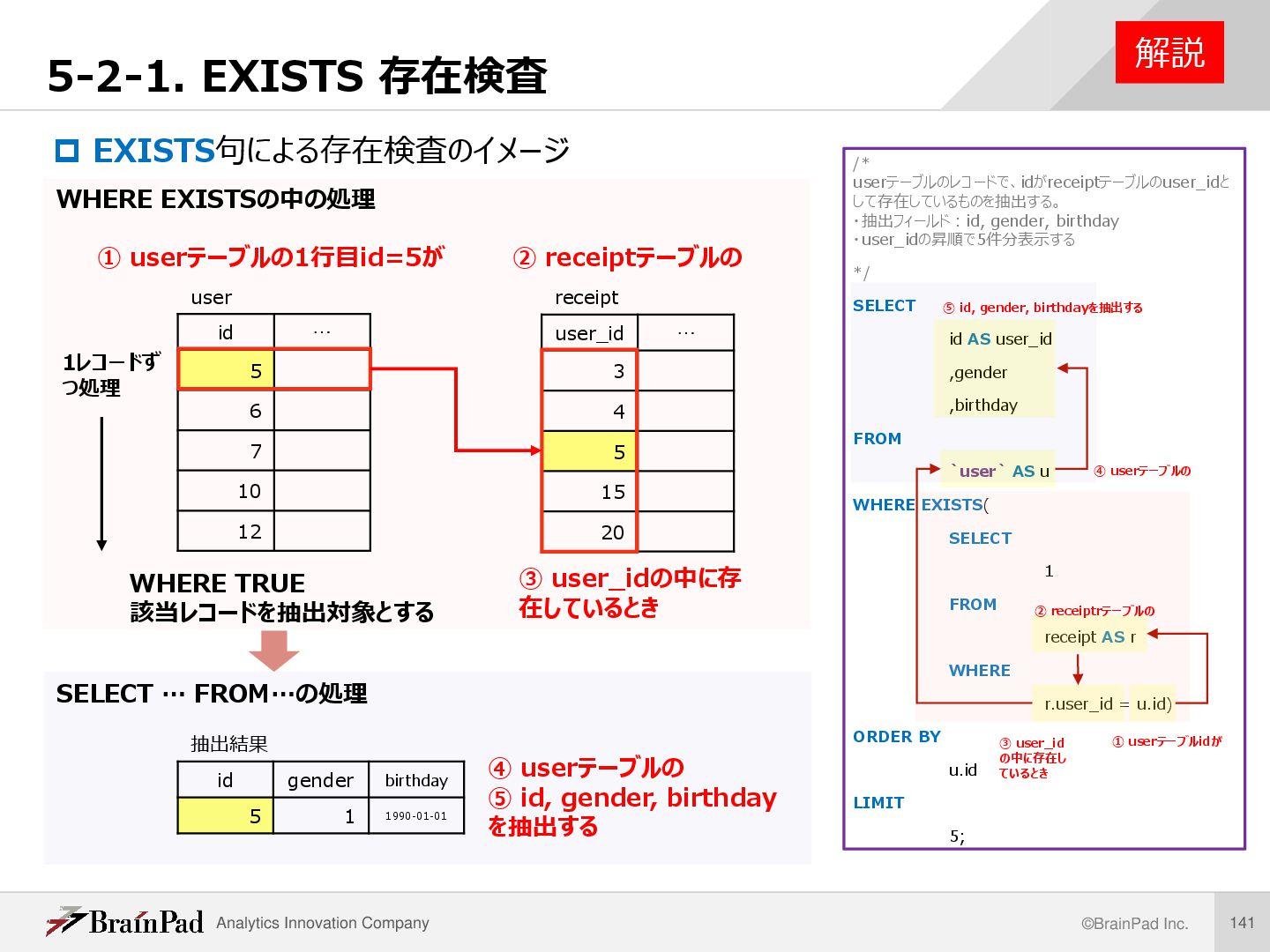
・抽出フィールド:id, gender, birthday ・user_idの昇順で5件分表示する /* userテーブルのレコードで、idがreceiptテーブルのuser_idとして存在している ものを抽出する。 ・抽出フィールド:id, gender, birthday ・user_idの昇順で5件分表示する */ SELECT id AS user_id ,gender ,birthday FROM `user` AS u WHERE EXISTS( SELECT 1 FROM receipt AS r WHERE r.user_id = u.id) ORDER BY u.id LIMIT 5 ; 例題 実行結果 レコード数 5 SQL
EXISTS句による存在検査 SELECT id AS user_id … FROM `user` AS u WHERE EXISTS( SELECT 1 FROM receipt AS r WHERE r.user_id = u.id) NOT EXISTS句による非存在検査 • 存在しないものを抽出できる 解説 /* userテーブルのレコードで、idがreceiptテーブルのuser_idと して存在しているものを抽出する。 ・抽出フィールド:id, gender, birthday ・user_idの昇順で5件分表示する */ SELECT id AS user_id ,gender ,birthday FROM `user` AS u WHERE EXISTS( SELECT 1 FROM receipt AS r WHERE r.user_id = u.id) ORDER BY u.id LIMIT 5; SQL ② receiptテーブルの ③ user_idの中に存在して いるとき(TRUEを返す) ④ userテーブルの ⑤ idを抽出する ① userテーブルのidが * や他の値でもOK
存在検査 解説 /* userテーブルのレコードで、idがreceiptテーブルのuser_idと して存在しているものを抽出する。 ・抽出フィールド:id, gender, birthday ・user_idの昇順で5件分表示する */ SELECT id AS user_id ,gender ,birthday FROM `user` AS u WHERE EXISTS( SELECT 1 FROM receipt AS r WHERE r.user_id = u.id) ORDER BY u.id LIMIT 5; user id … 5 6 7 10 12 receipt user_id … 3 4 5 15 20 1レコードず つ処理 ① userテーブルの1行目id=5が ② receiptテーブルの ③ user_idの中に存 在しているとき ④ userテーブルの ⑤ id, gender, birthday を抽出する WHERE EXISTSの中の処理 ① userテーブルidが ② receiptrテーブルの ③ user_id の中に存在し ているとき ④ userテーブルの ⑤ id, gender, birthdayを抽出する SELECT … FROM…の処理 抽出結果 id gender birthday 5 1 1990-01-01 WHERE TRUE 該当レコードを抽出対象とする
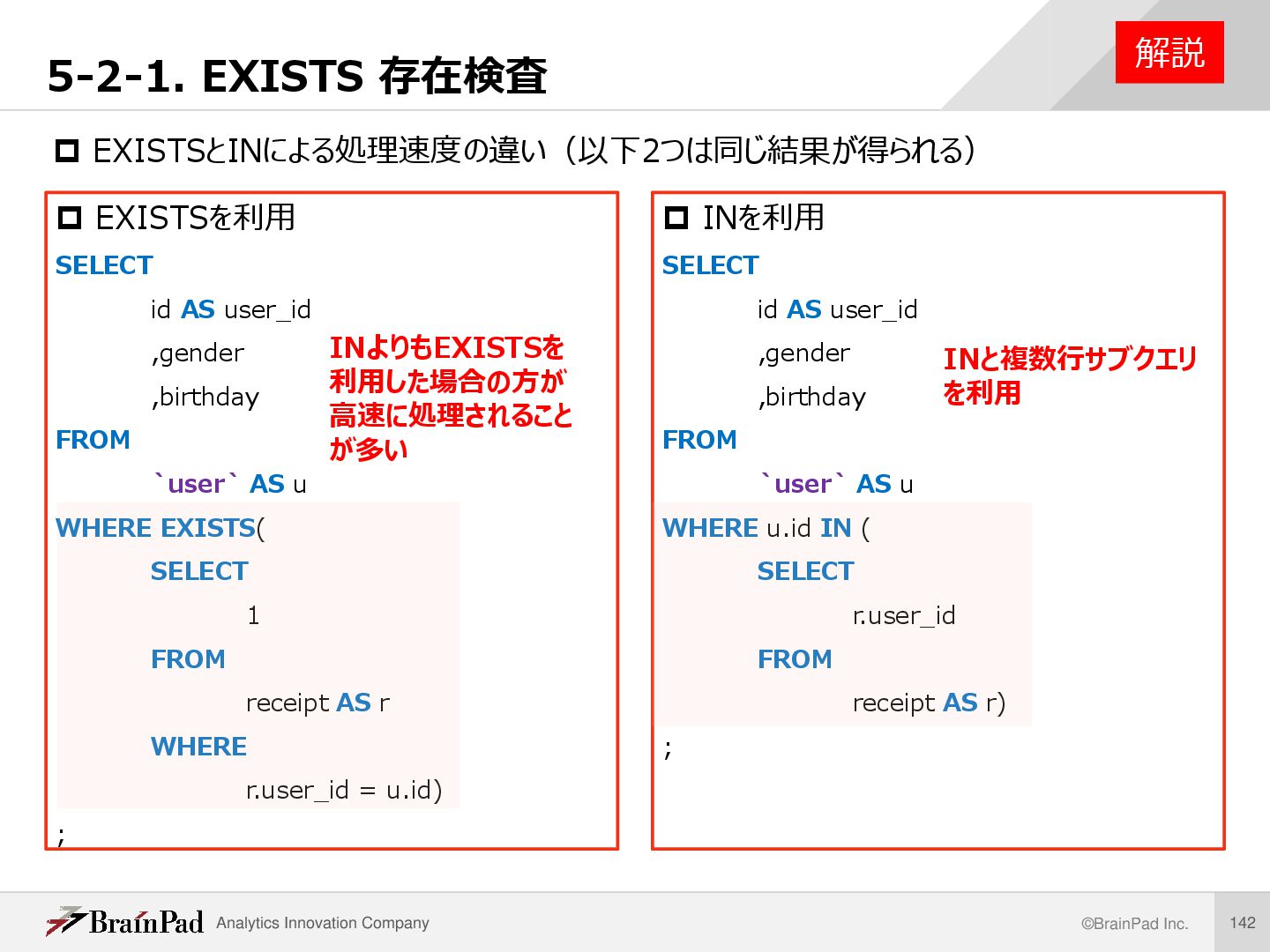
存在検査 解説 EXISTSを利用 SELECT id AS user_id ,gender ,birthday FROM `user` AS u WHERE EXISTS( SELECT 1 FROM receipt AS r WHERE r.user_id = u.id) ; INを利用 SELECT id AS user_id ,gender ,birthday FROM `user` AS u WHERE u.id IN ( SELECT r.user_id FROM receipt AS r) ; INよりもEXISTSを 利用した場合の方が 高速に処理されること が多い INと複数行サブクエリ を利用
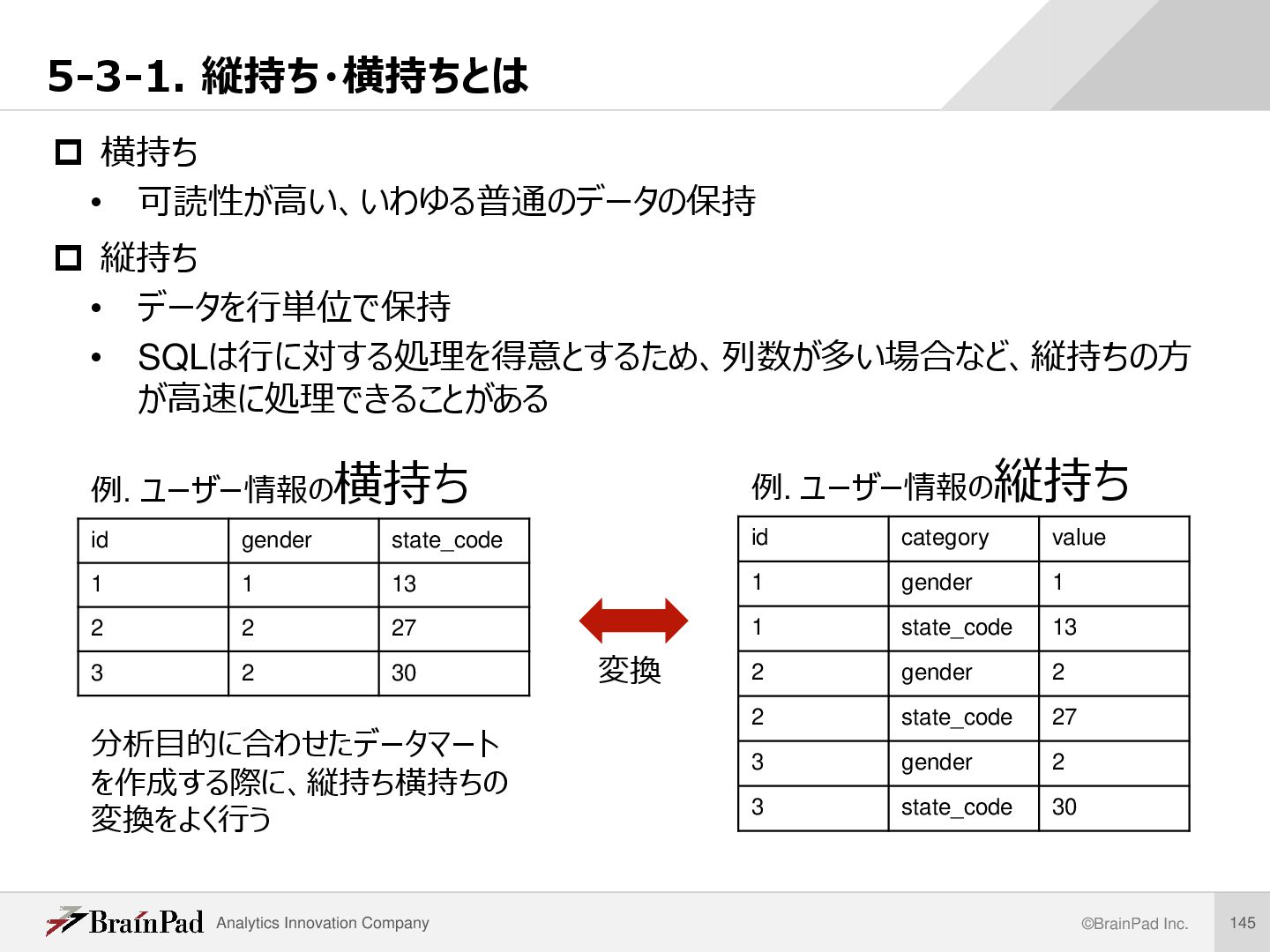
した縦持ちに変換し、一時テーブルtmp_v_userとして保存する。 その後、確認のために一時テーブルtmp_v_userからデータを取得する。 /* userテーブルのgender, state_codeを、それぞれのフィールド名をcategory、 値をvalueとした縦持ちに変換し、一時テーブルtmp_v_userとして保存する。 その後、確認のために一時テーブルtmp_v_userからデータを取得する。 */ CREATE TEMPORARY TABLE tmp_v_user ( SELECT id , 'gender' AS category , gender AS value FROM `user` UNION ALL SELECT id , 'state_code' AS category , CAST(state_code AS UNSIGNED) AS value FROM `user` ) ; 一時テーブル作成後、確認のため以下のクエリでデータを取得 SELECT * FROM tmp_v_user ORDER BY id, category LIMIT 10; 例題 SQL 実行結果
state_codeを、それ ぞれのフィールド名をcategory、値をvalueとし た縦持ちに変換し、一時テーブルtmp_v_user として保存する。 */ CREATE TEMP TABLE tmp_v_user ( SELECT id , 'gender' AS category , gender AS value FROM `user` UNION ALL SELECT id , 'state_code' AS category , CAST(state_code AS UNSIGNED) AS value FROM `user` ); 解説 UNION ALL • 複数のテーブルから取得した結果セットをひとつに結合 • 重複する行を1つにまとめずに、そのまま抽出する • UNIONだけを指定すると、重複行は削除される UNION ALLの注意点 • フィールドの数・順番、データ型が一致している必要があ る • 右の例では、genderの値(整数型)とstate_codeの 値(文字列型)を整数型に揃えてvalueに格納 SQL
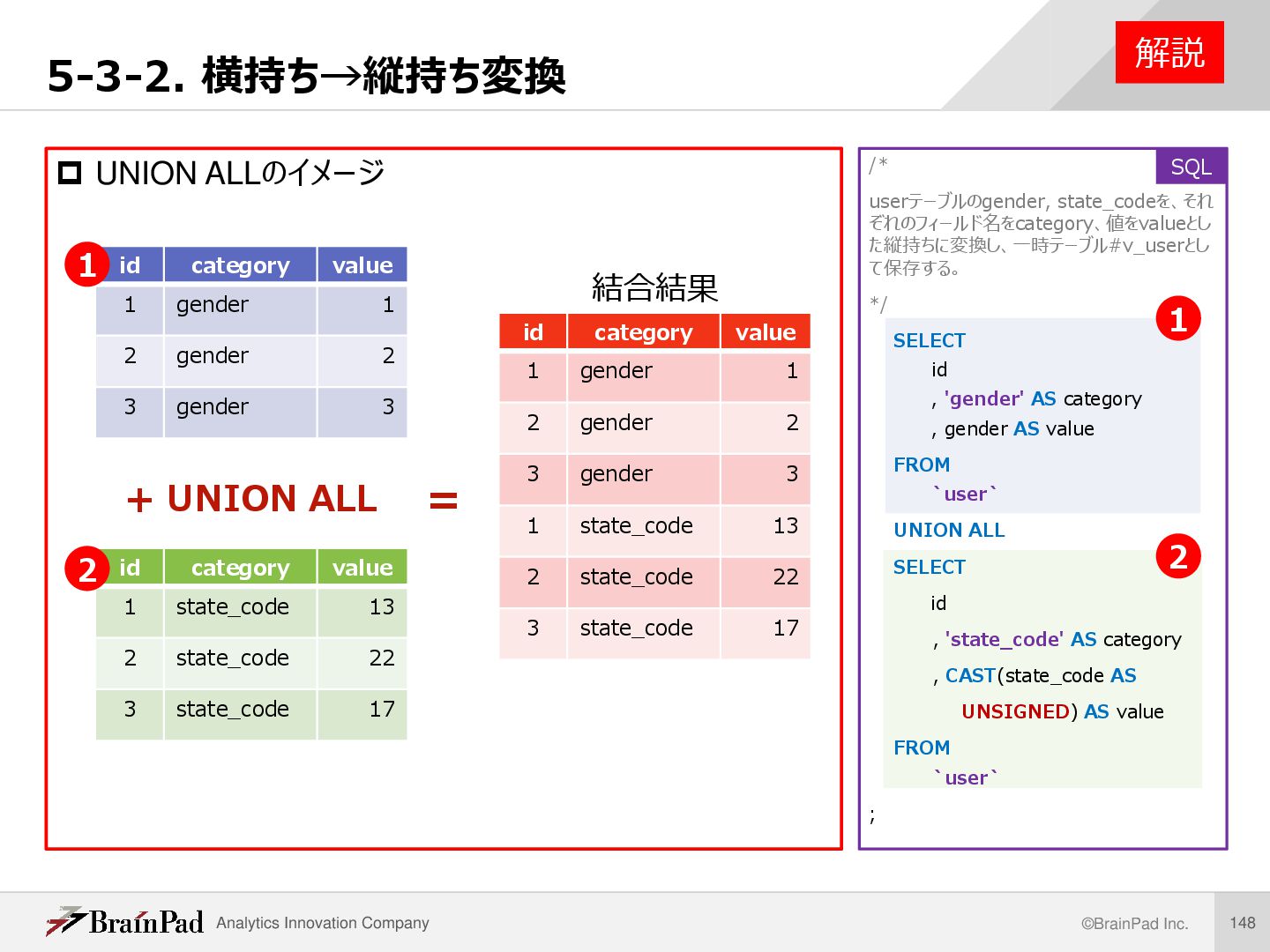
た縦持ちに変換し、一時テーブル#v_userとし て保存する。 */ SELECT id , 'gender' AS category , gender AS value FROM `user` UNION ALL SELECT id , 'state_code' AS category , CAST(state_code AS UNSIGNED) AS value FROM `user` ; 5-3-2. 横持ち→縦持ち変換 解説 UNION ALLのイメージ SQL id category value 1 gender 1 2 gender 2 3 gender 3 + UNION ALL = id category value 1 state_code 13 2 state_code 22 3 state_code 17 id category value 1 gender 1 2 gender 2 3 gender 3 1 state_code 13 2 state_code 22 3 state_code 17 1 2 結合結果 1 2
/* 5-3-2で作成した縦持ちの一時テーブルtmp_v_userを横持ちに変換し、10件表示する。 */ SELECT id ,MAX(CASE WHEN category = 'gender' THEN value END) AS gender ,MAX(CASE WHEN category = 'state_code' THEN value END) AS state_code FROM tmp_v_user GROUP BY id ORDER BY id LIMIT 10; 例題 実行結果 レコード数 10 SQL
*/ SELECT id ,MAX(CASE WHEN category = ‘gender’ THEN value END) AS gender ,MAX(CASE WHEN category = ‘state_code’ THEN value END) AS state_code FROM tmp_v_user GROUP BY id … 以下省略 5-3-3. 縦持ち→横持ち変換 解説 処理①(グループ化、集計する前のCASE文の処理) • 結果の空欄はNULLを表す 処理②(グループ化) • MAX()は、NULLを対象としない SQL SELECT id ,CASE WHEN category = 'gender’ THEN value END AS gender ,CASE WHEN category = 'state_code’ THEN value END AS state_code FROM #v_user; … MAX(CASE WHEN category = 'gender’ THEN value END) AS gender … GROUP BY id 最終結果 途中結果
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}