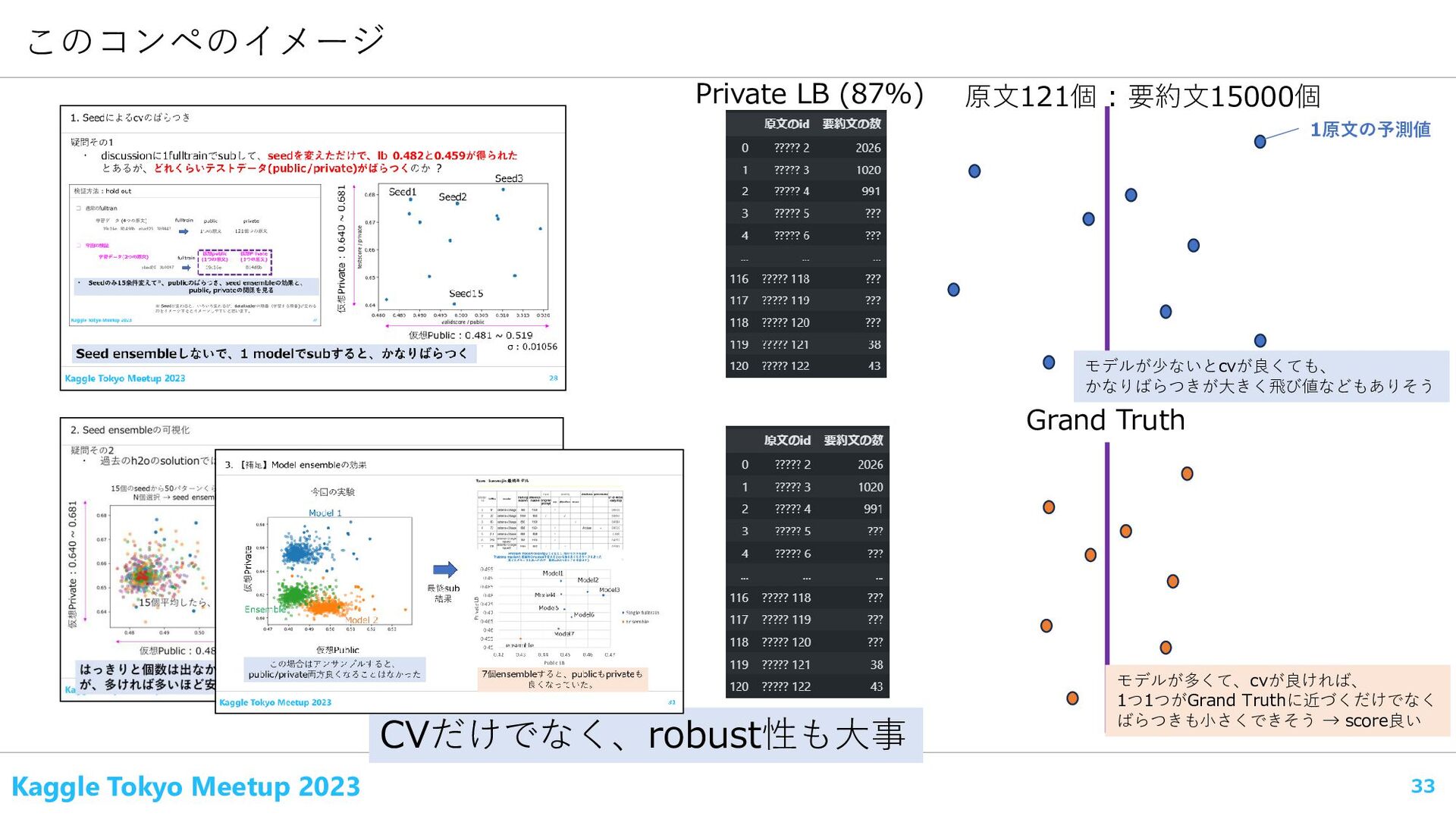
Flowers," the enchanted ground wherein it has been said Ponce de Leon sought for the "fountain of perpetual youth," is not far away; the fountain, quite likely, is as remote as ever, but the land which it was said to bless with its ever flowing and rejuvenating waters, can be reached after a journey of a few days from New York, by steamship if the traveler is not unpleasantly affected by a sea-voyage, or, if the apprehension of "rough weather off Hatteras" should make a different route preferable, then by rail to Charleston, thence by steamer over waters generally smooth to Fernandina, stopping on the way at Savannah just long enough to look about and obtain a general idea of the place. Fernandina, situated on Amelia Island, is the principal town upon the east coast of Florida, and of importance, being the eastern terminus of a line of railway, which connects the Atlantic Ocean with the Gulf of Mexico. Its population is not far from fifteen hundred. At first sight it is not prepossessing, but a walk about the place reveals many buildings of pleasing architecture hidden among the trees. Within a small enclosure not far from the landing, "the ...forefather of the hamlet sleeps." Upon a marble stone may be seen the name of 原文の例※ (Commonlitではないところの著作権フリーの適当な文章) https://etc.usf.edu/lit2go/52/american-naturalist-rambles-in-florida/1003/rambles-in-florida-part-1/ Florida is easily accessible from New York, offering a sea route for those who enjoy it, or an alternative rail and steamer path via Charleston and Savannah for those who prefer calmer travels. Fernandina on Amelia Island is the main eastern town in Florida and a significant railway terminus, with a modest population and attractive architecture nestled among trees. It also features a notable grave of a local forefather. 要約 生徒 A 採点 Content(内容) :-1.73点~3.9点 Wording(文法) :-1.96点~4.31点 生徒 B 生徒 C 生徒 D … 生徒 ZZ 3 年生から 12 年生の生徒が書いた要約を自動的に評価するコンペ ターゲット : ContentとWordingのそれぞれの点数(回帰問題) 指標 MCRMSE : ContentとWordingそれぞれのRMSEの平均値 アノテーター ※ trainデータは原文1個につき、 要約文(生徒数)がそれぞれ1000-2000個 DALL-E 3で作成 Code competition
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}