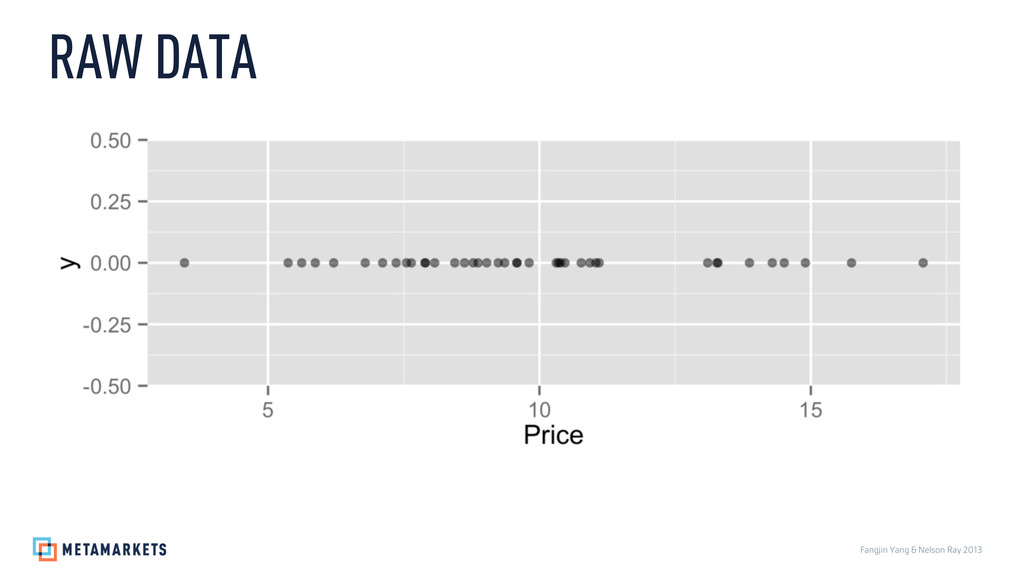
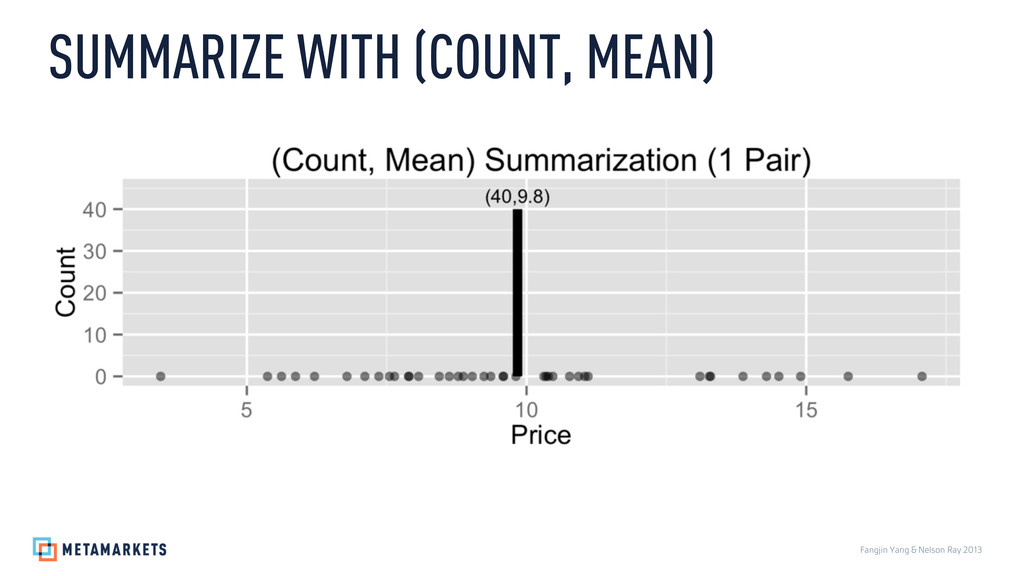
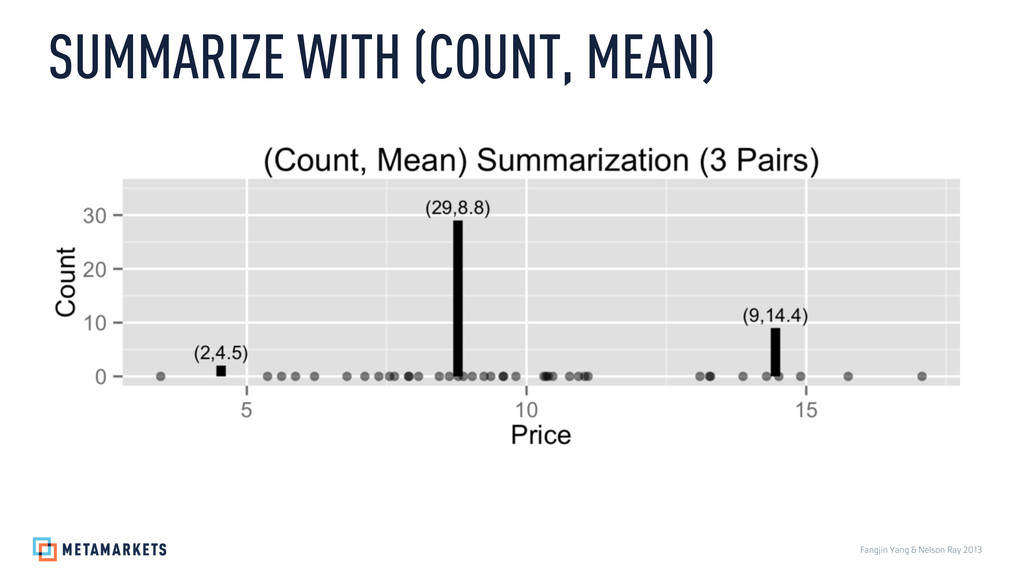
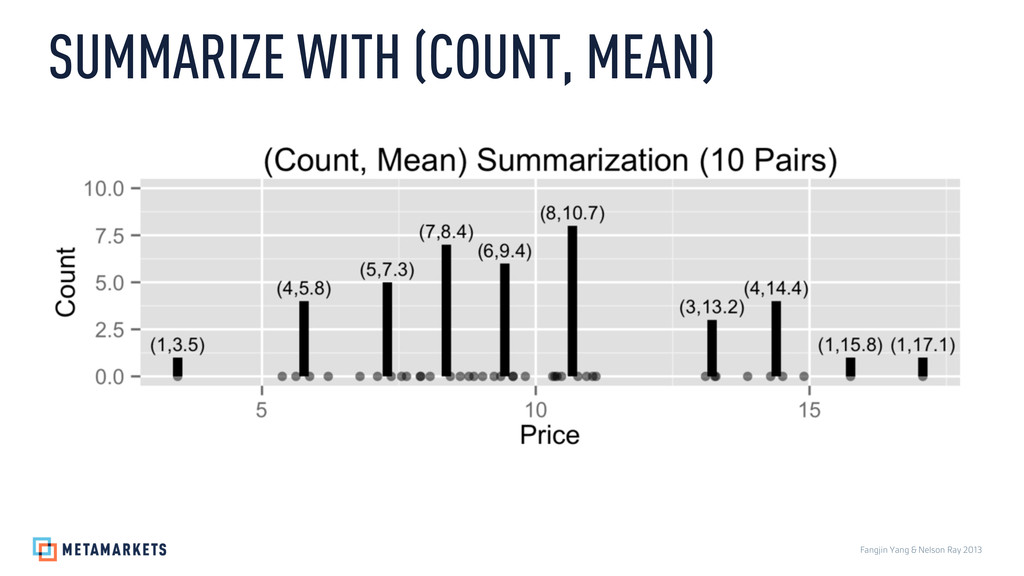
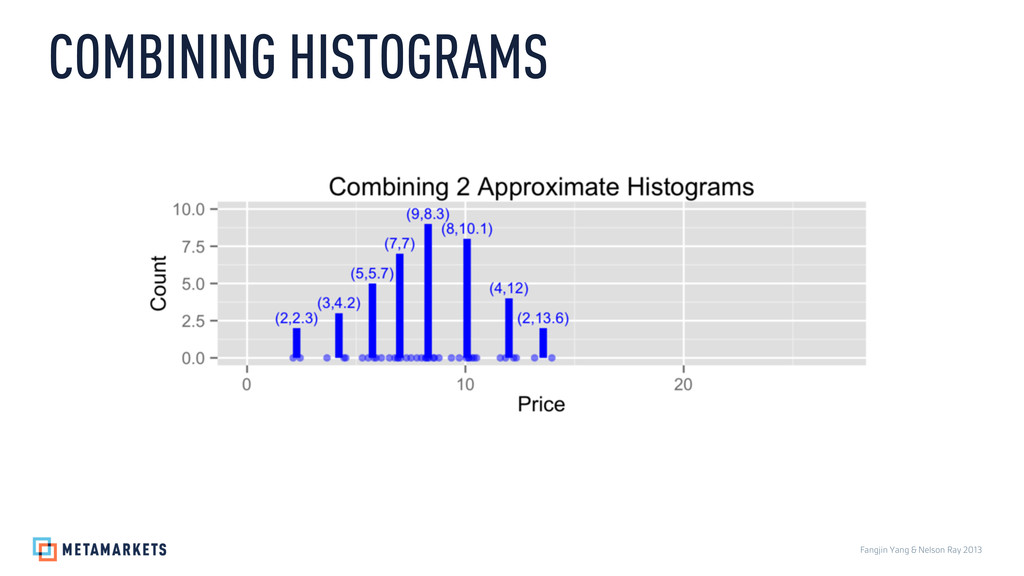
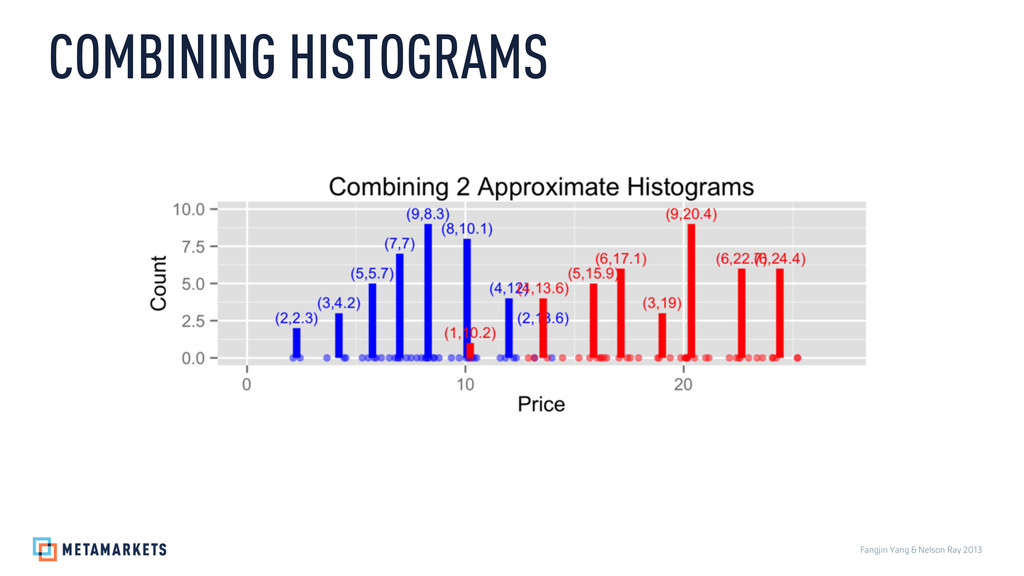
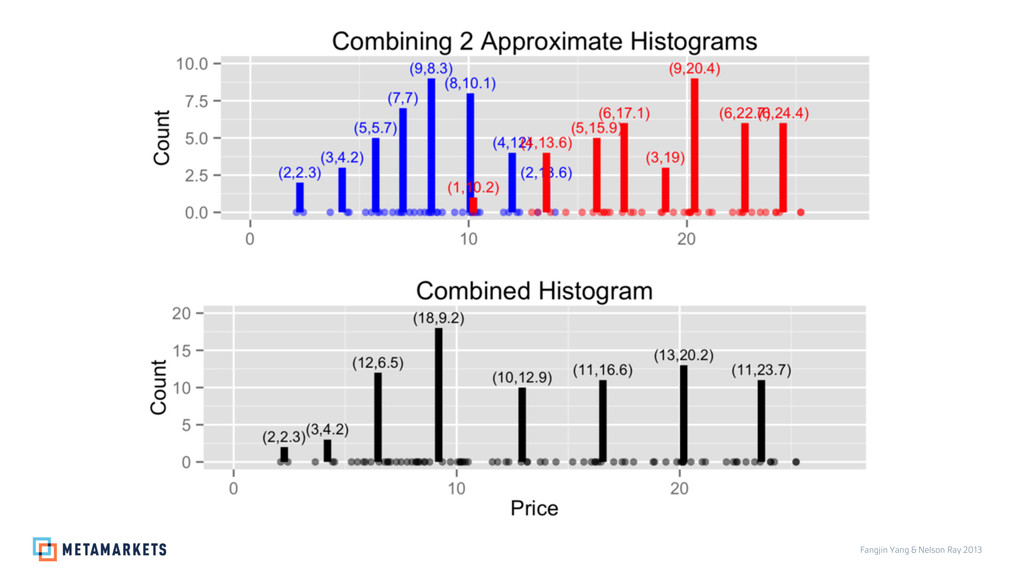
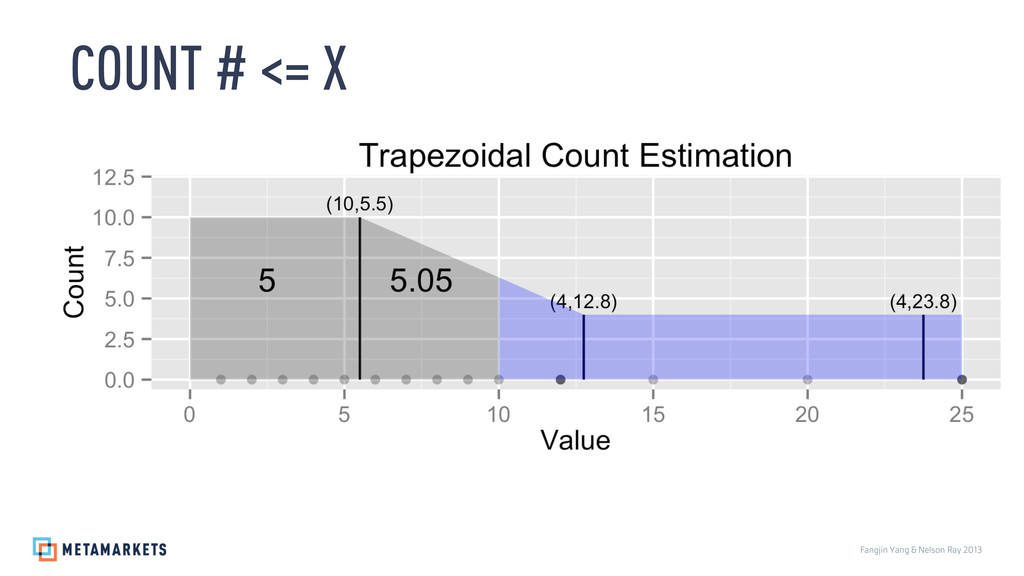
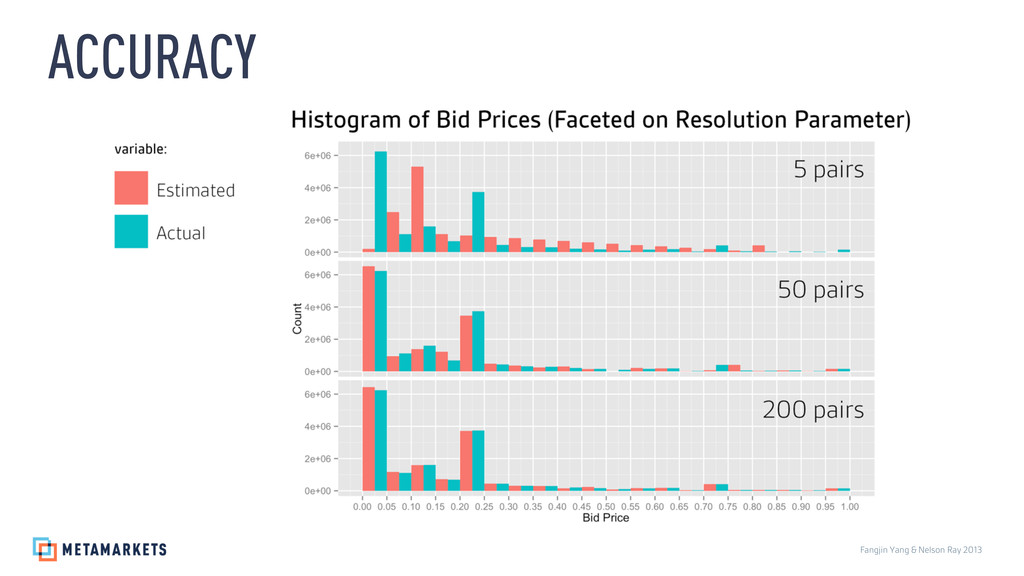
Prices: 3.46, 5.37, 5.62, 5.87, 6.21, 6.79, 7.11, 7.36, 7.55, 7.64, 7.89, 7.9, 8.07, 8.44, 8.62, 8.78, 8.87, 9.03, 9.24, 9.36, 9.58, 9.59, 9.81, 10.31, 10.35, 10.39, 10.47, 10.77, 10.93, 11.04, 11.1, 13.1, 13.27, 13.29, 13.87, 14.29, 14.51, 14.9, 15.75, 17.07
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
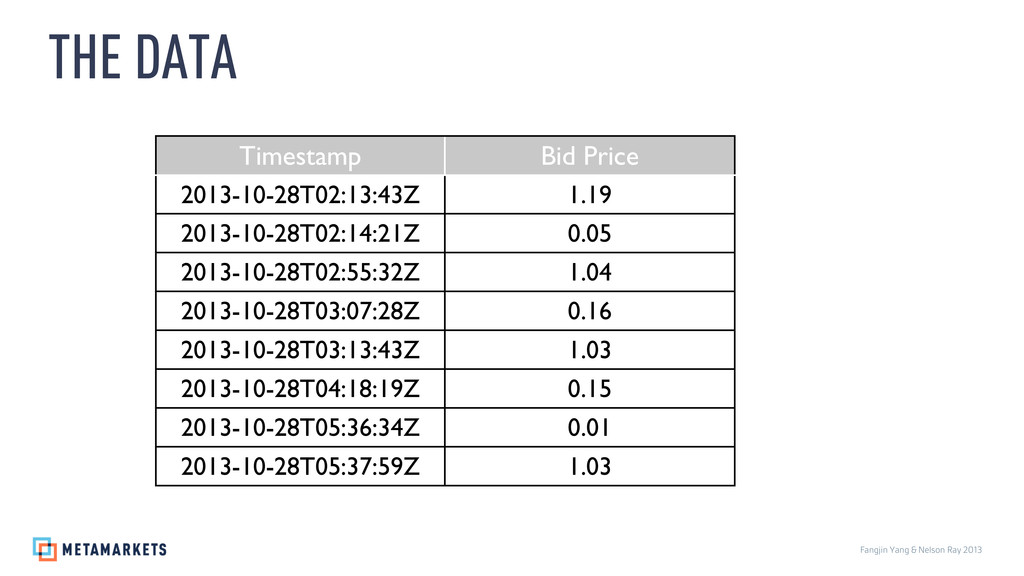{kind=link}
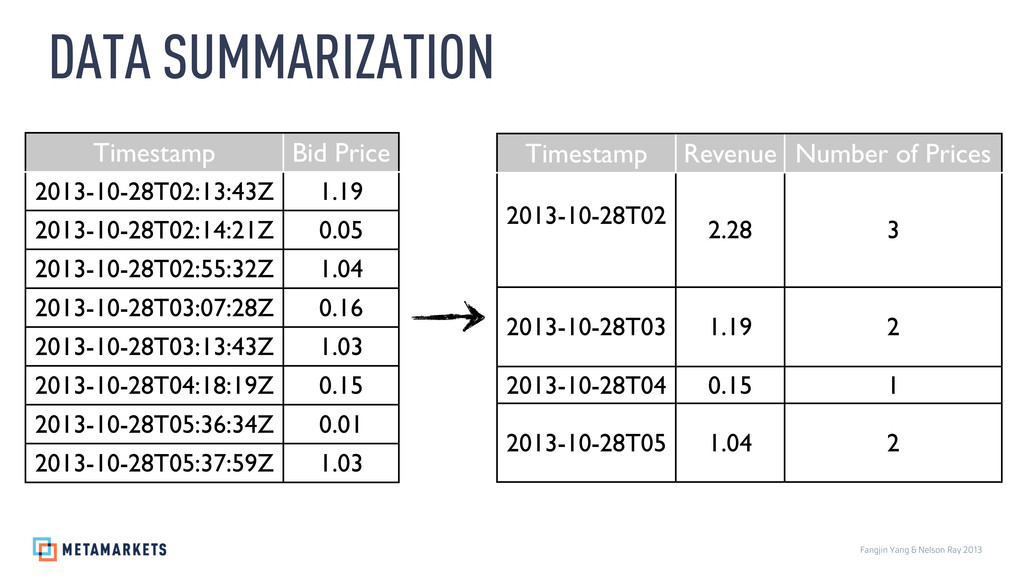{kind=link}
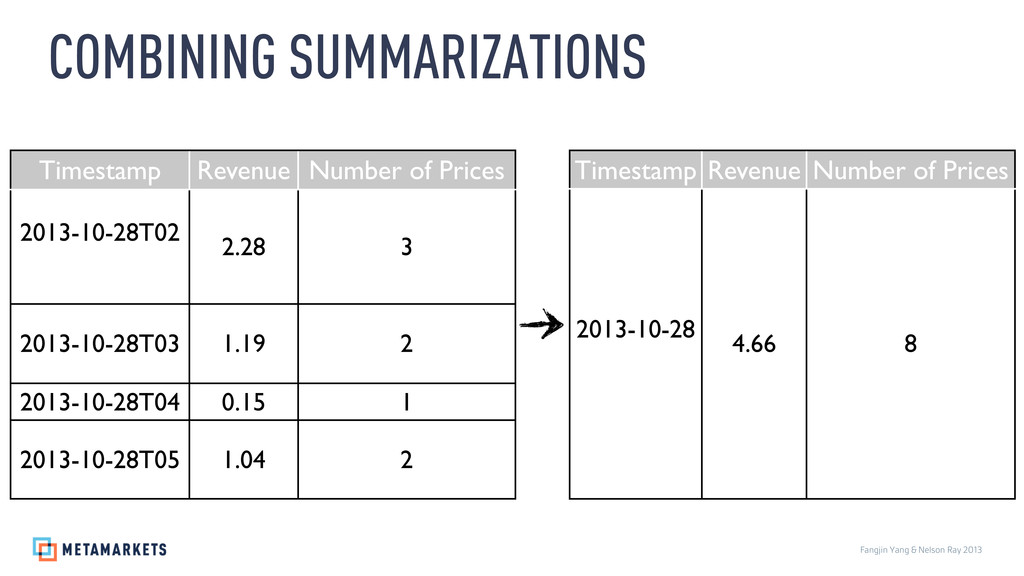{kind=link}
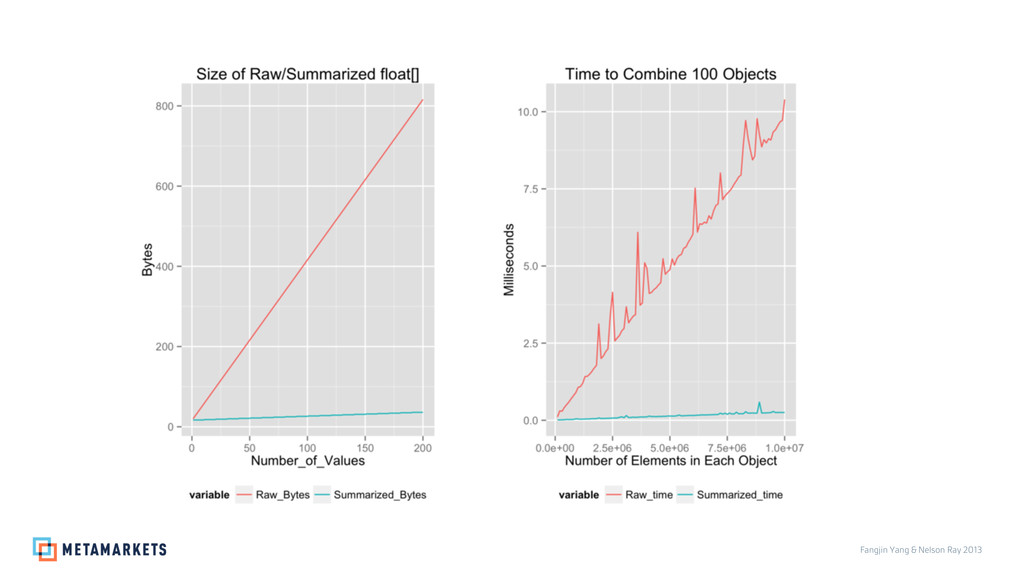{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
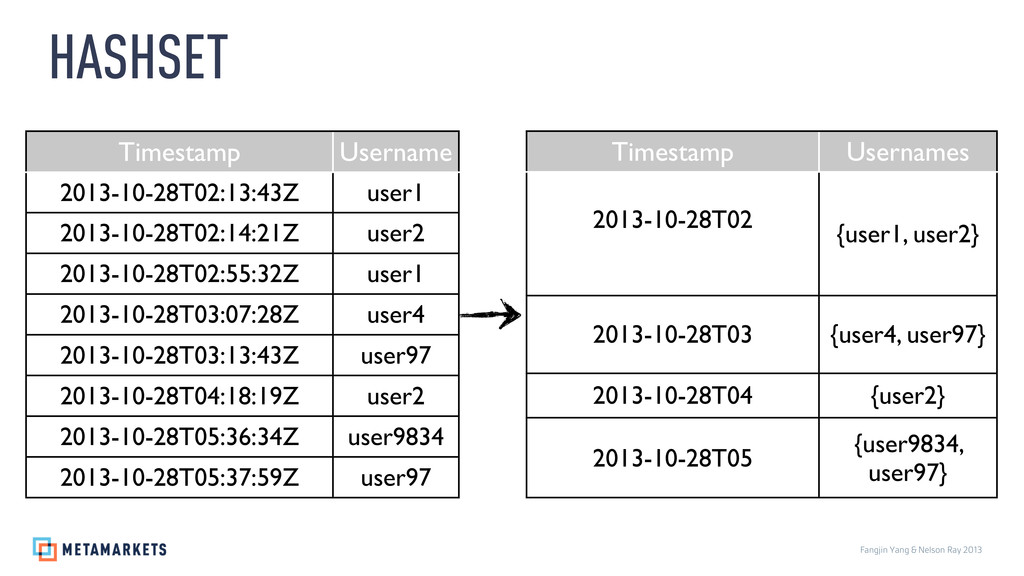{kind=link}
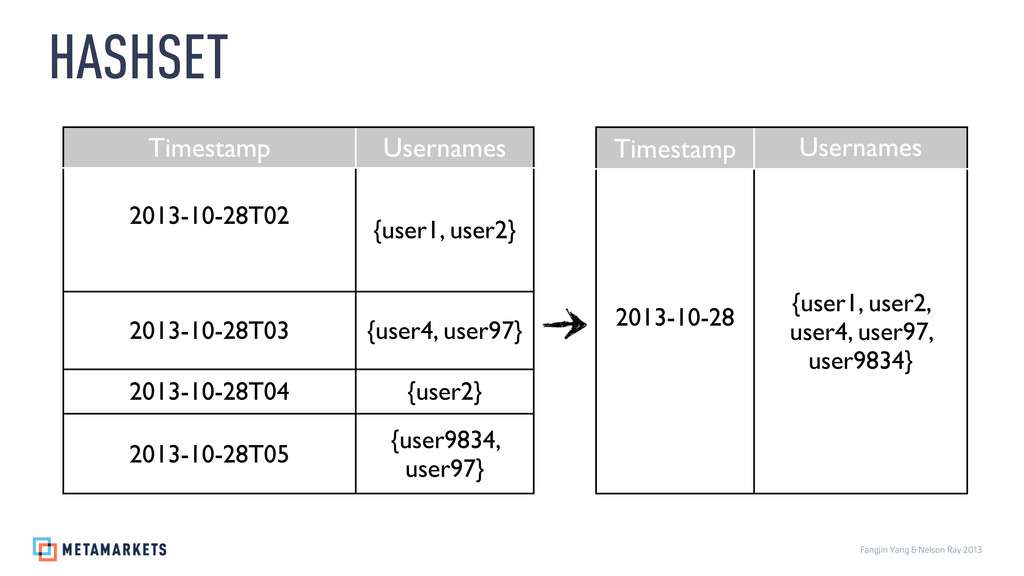{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
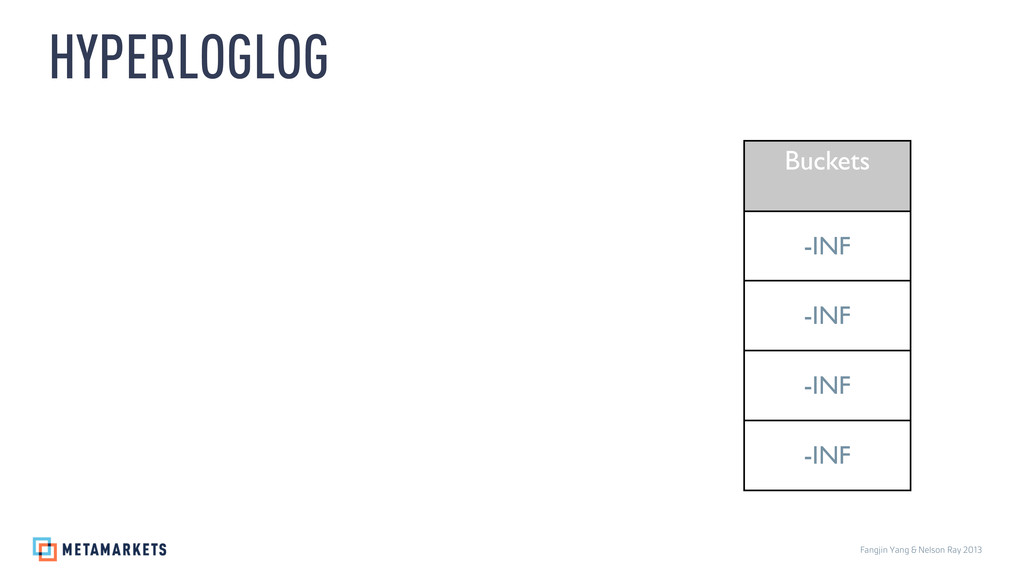{kind=link}
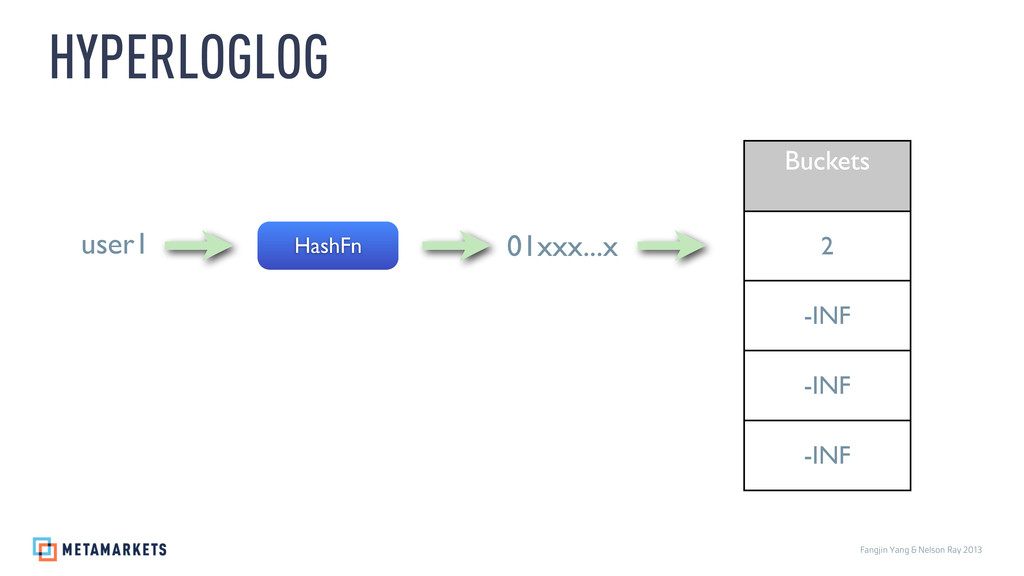{kind=link}
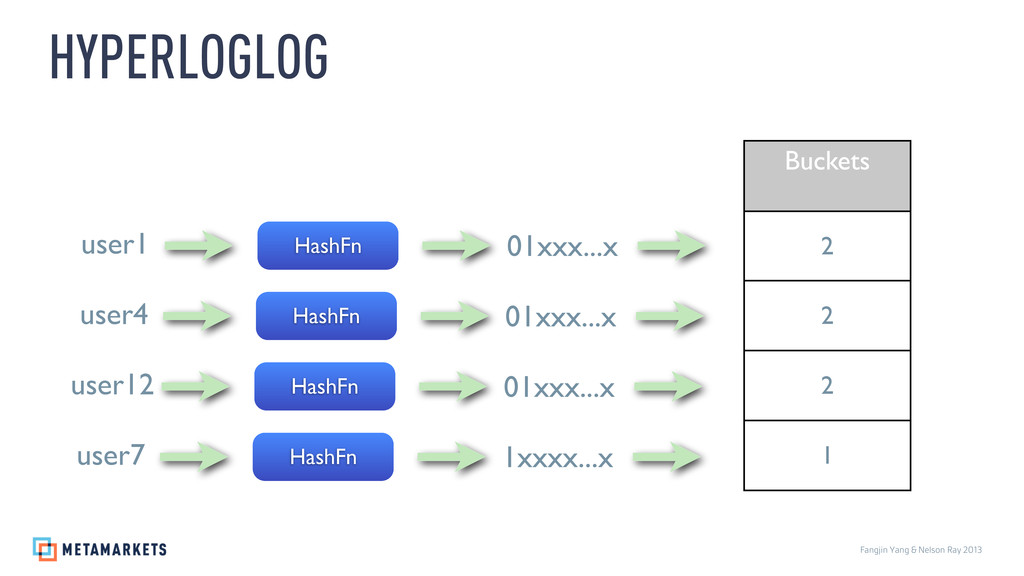{kind=link}
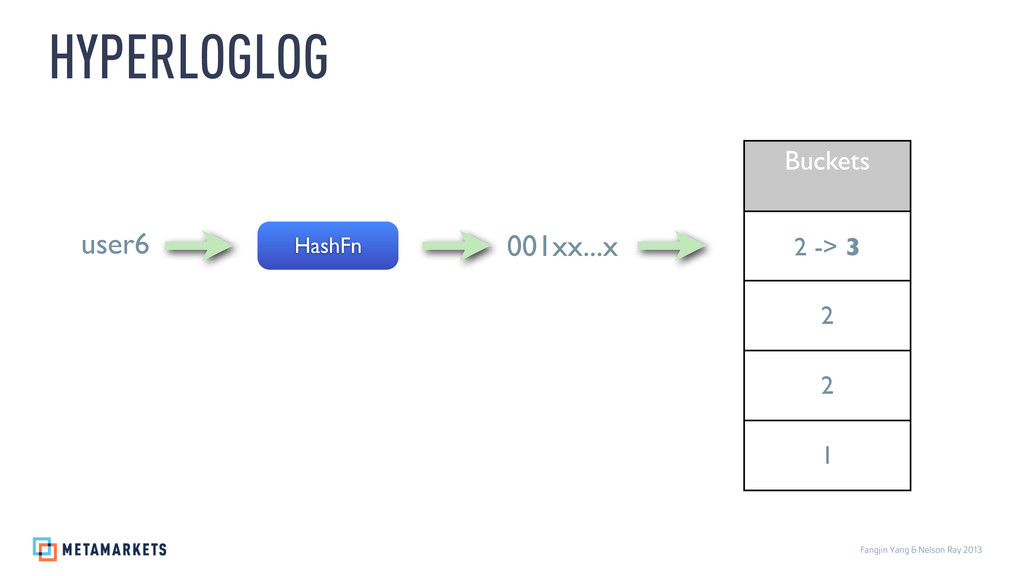{kind=link}
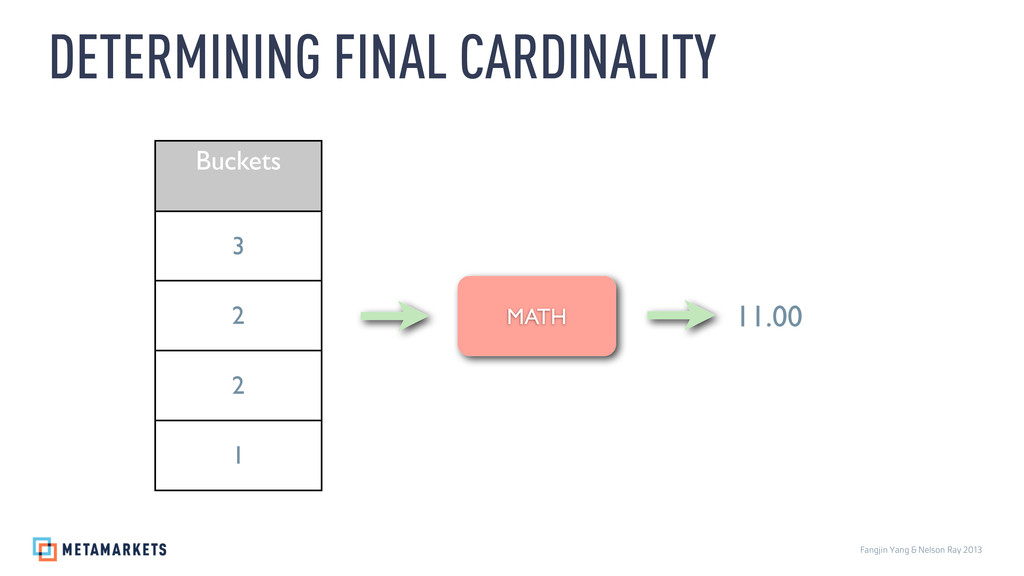{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}