al., 2020 • Beyond neural scaling laws: beating power law scaling via data pruning, Sorscher et al., 2022 • s1: Simple test-time scaling, Muennighoff et al., 2025 • LIMO: Less is More for Reasoning, Ye et al., 2025 • Climbing the ladder of reasoning: What llms can-and still can’t-solve after sft?, Sun et al., 2025 • Why Less is More (Sometimes): A Theory of Data Curation, Dohmatob et al., 2025 参考文献
{kind=link}
{kind=link}
{kind=link}
{kind=link}
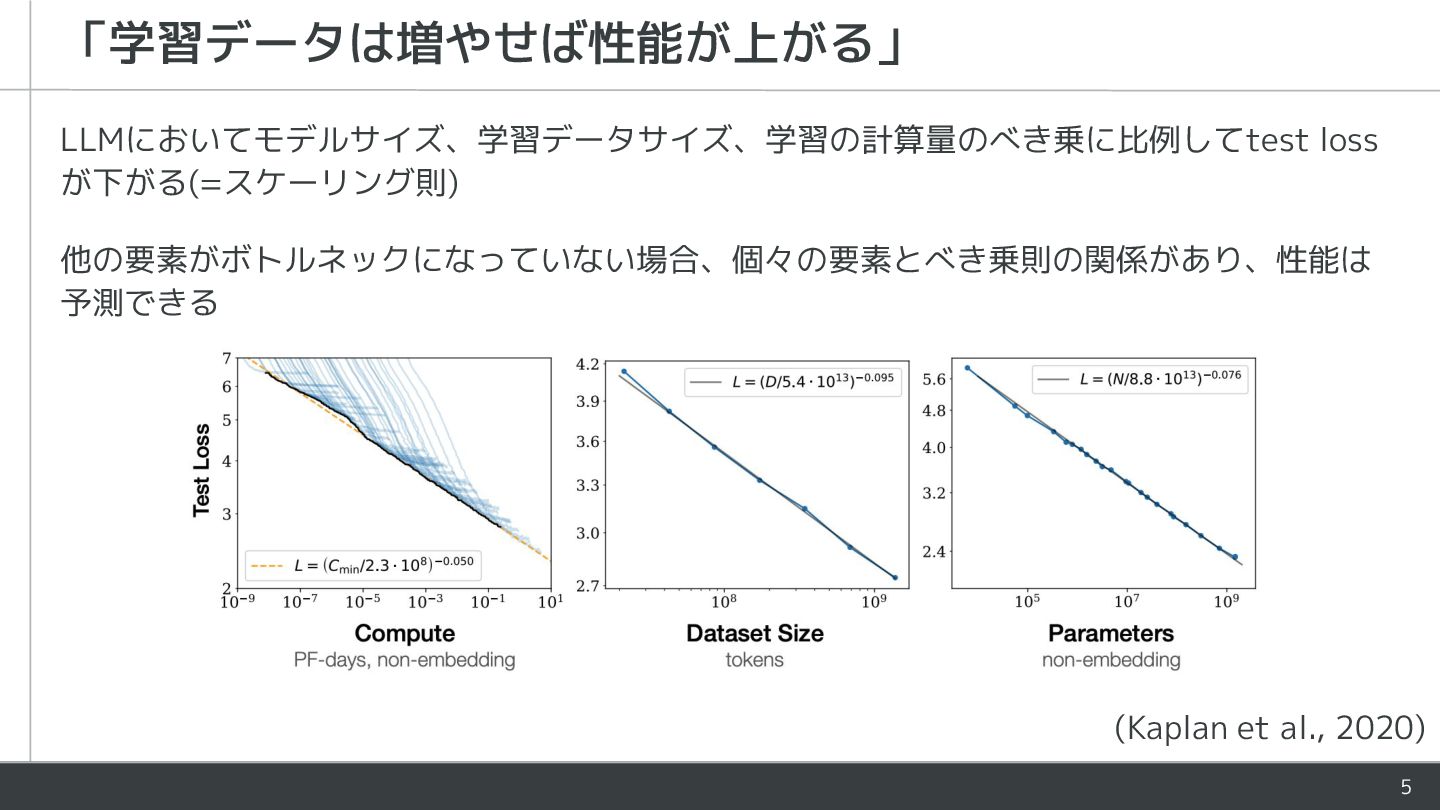{kind=link}
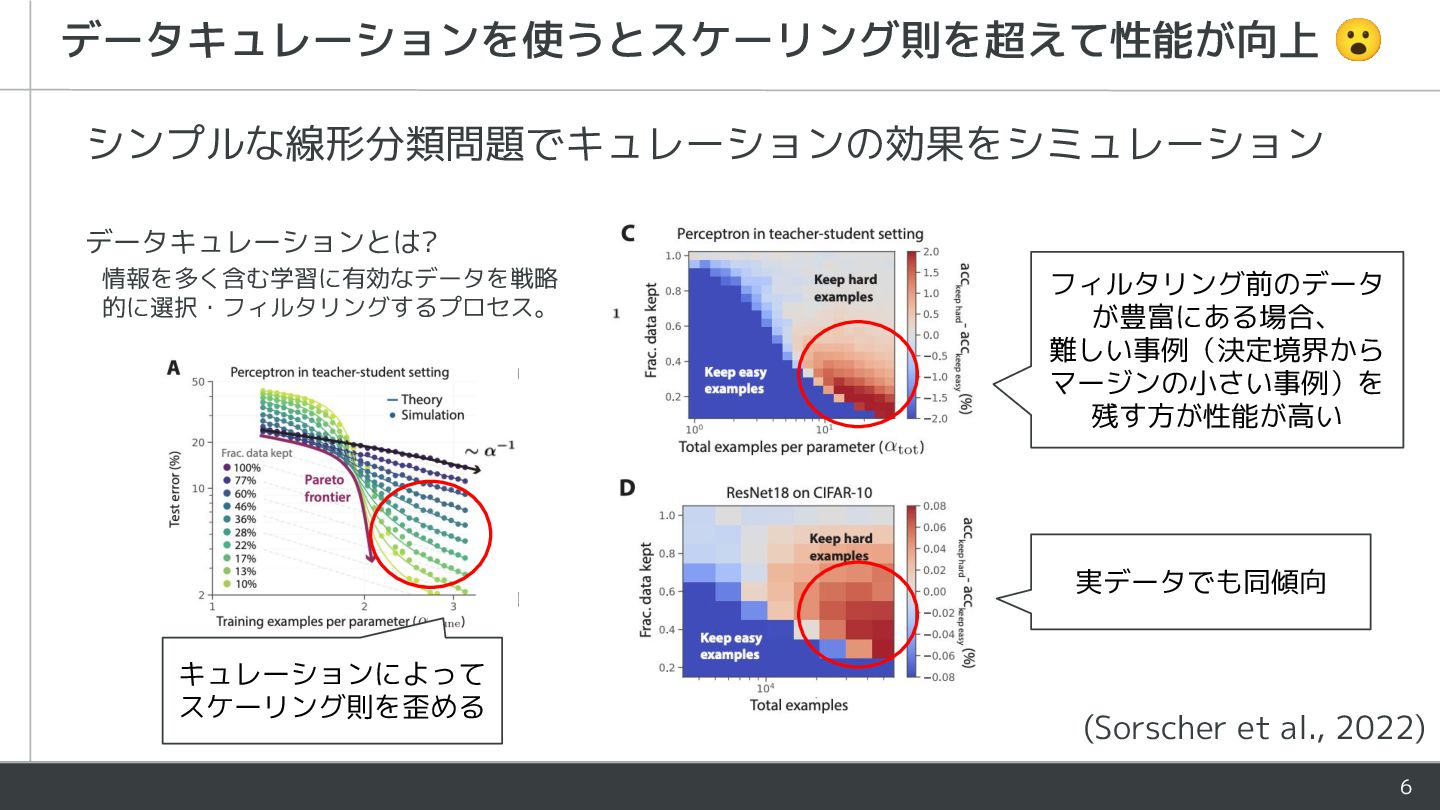{kind=link}
{kind=link}
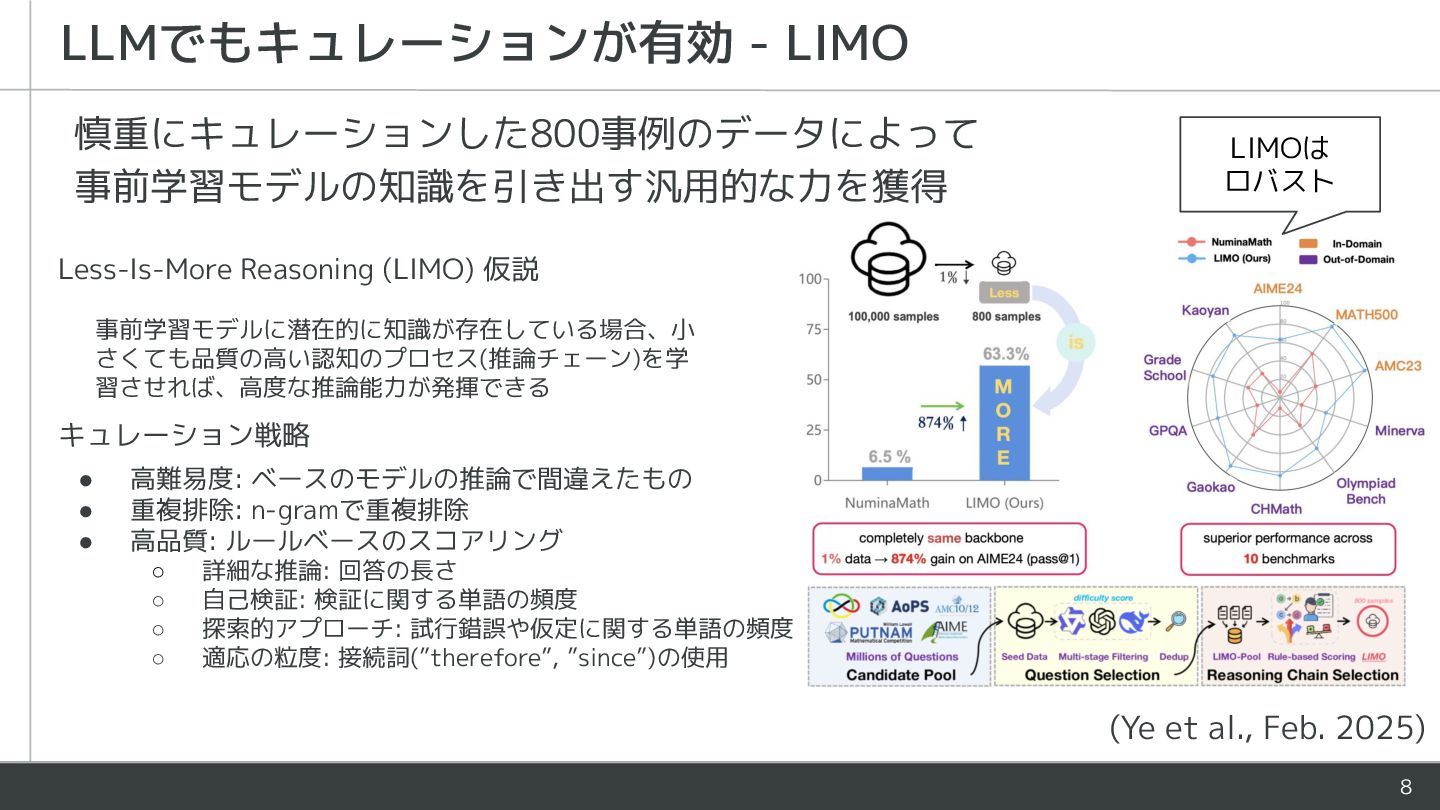{kind=link}
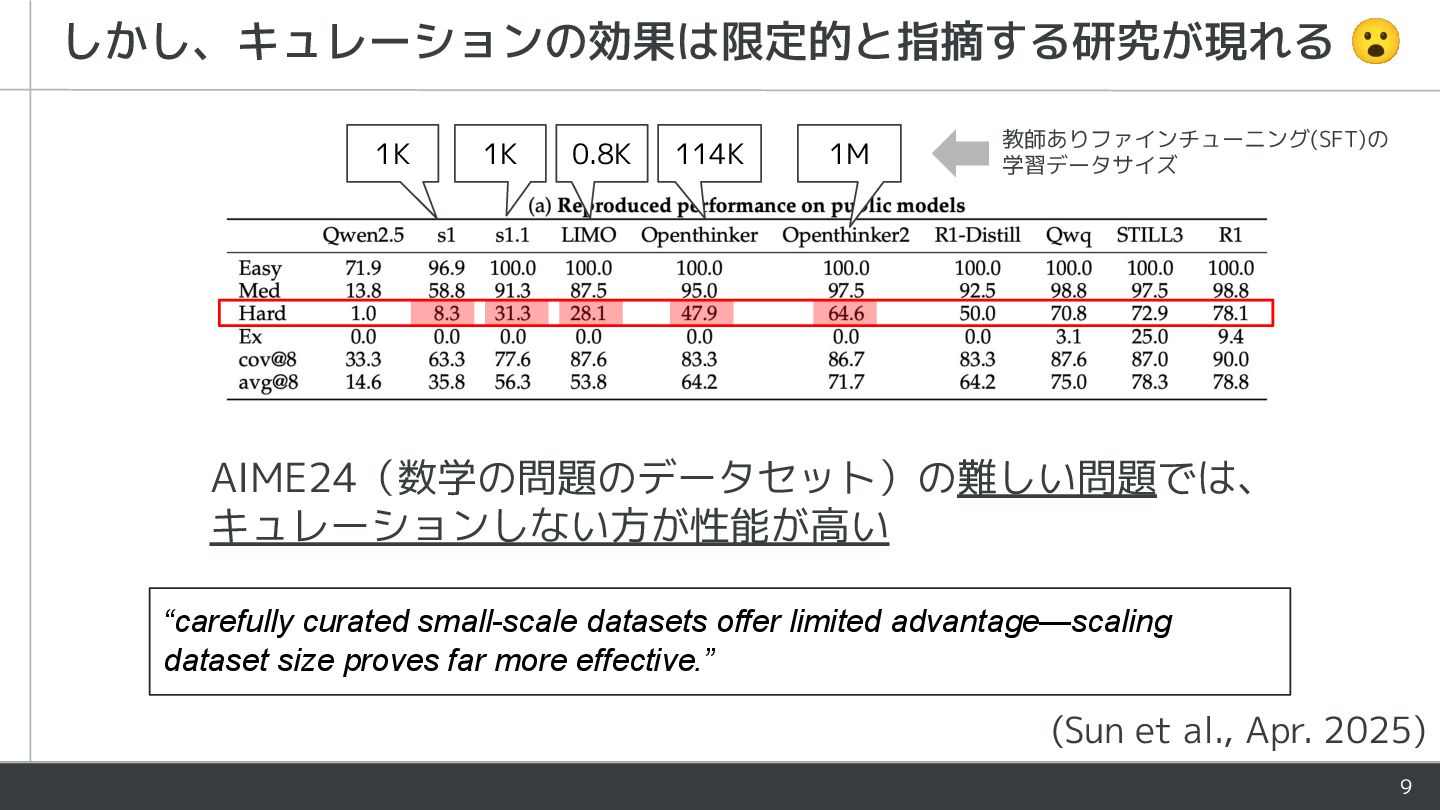{kind=link}
{kind=link}
{kind=link}
{kind=link}
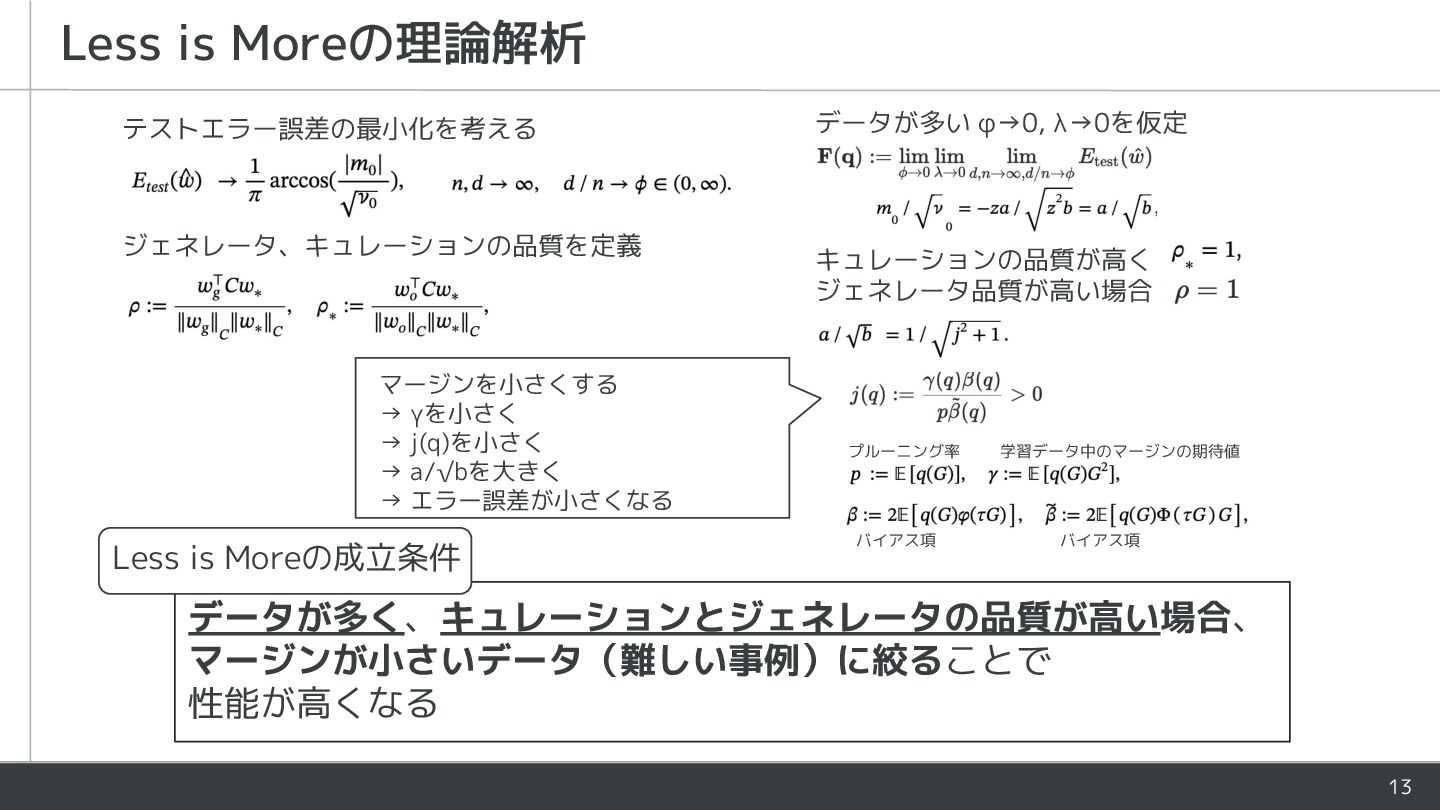{kind=link}
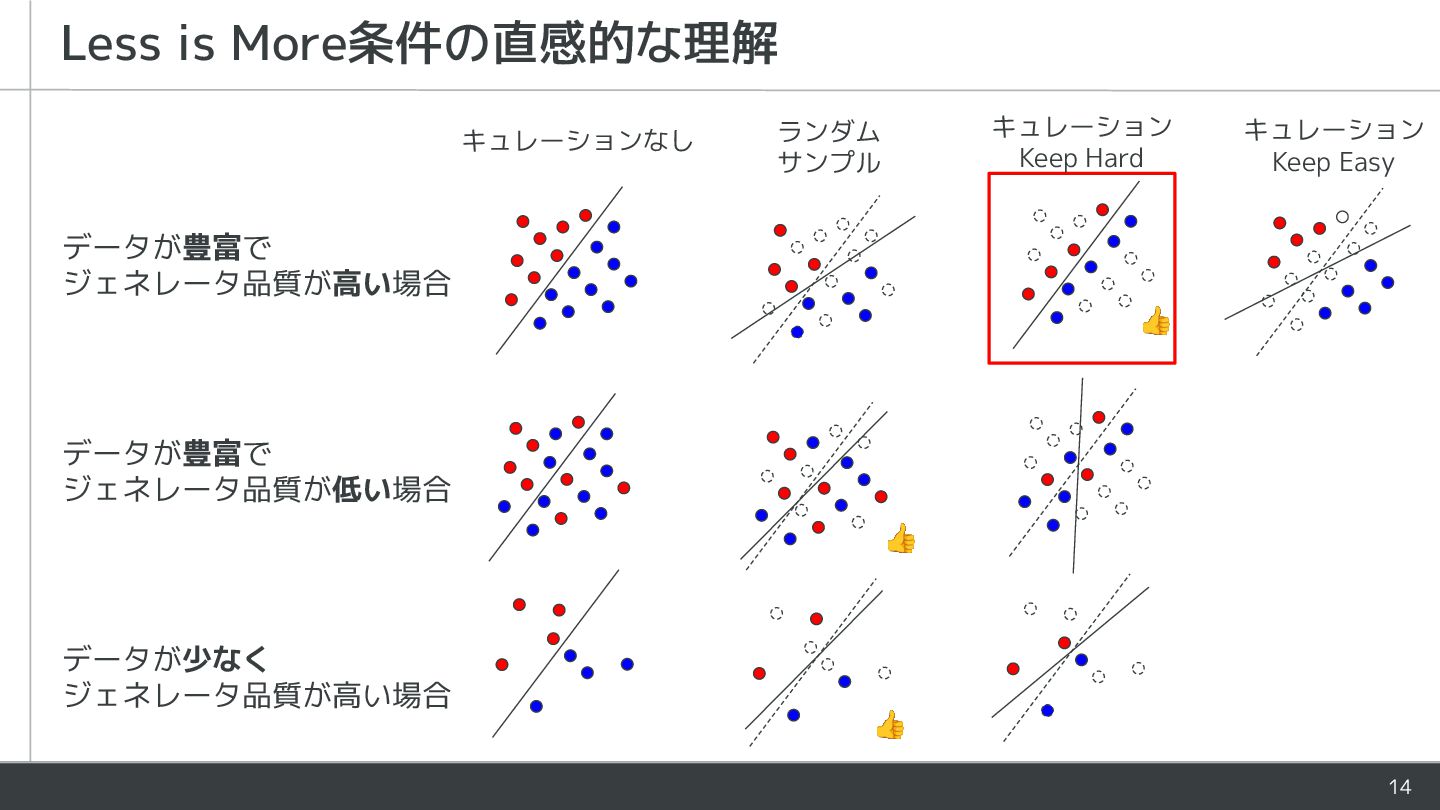{kind=link}
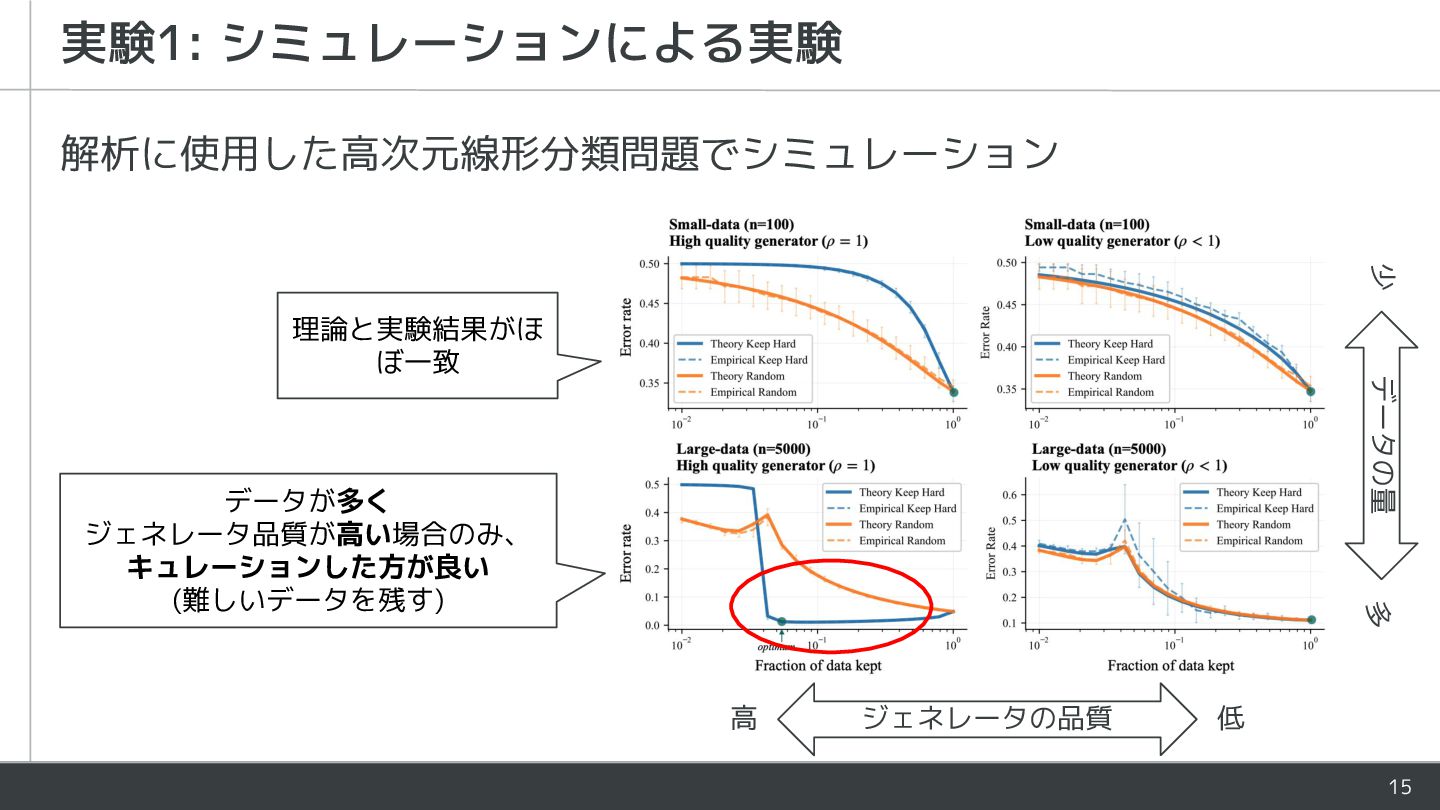{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}