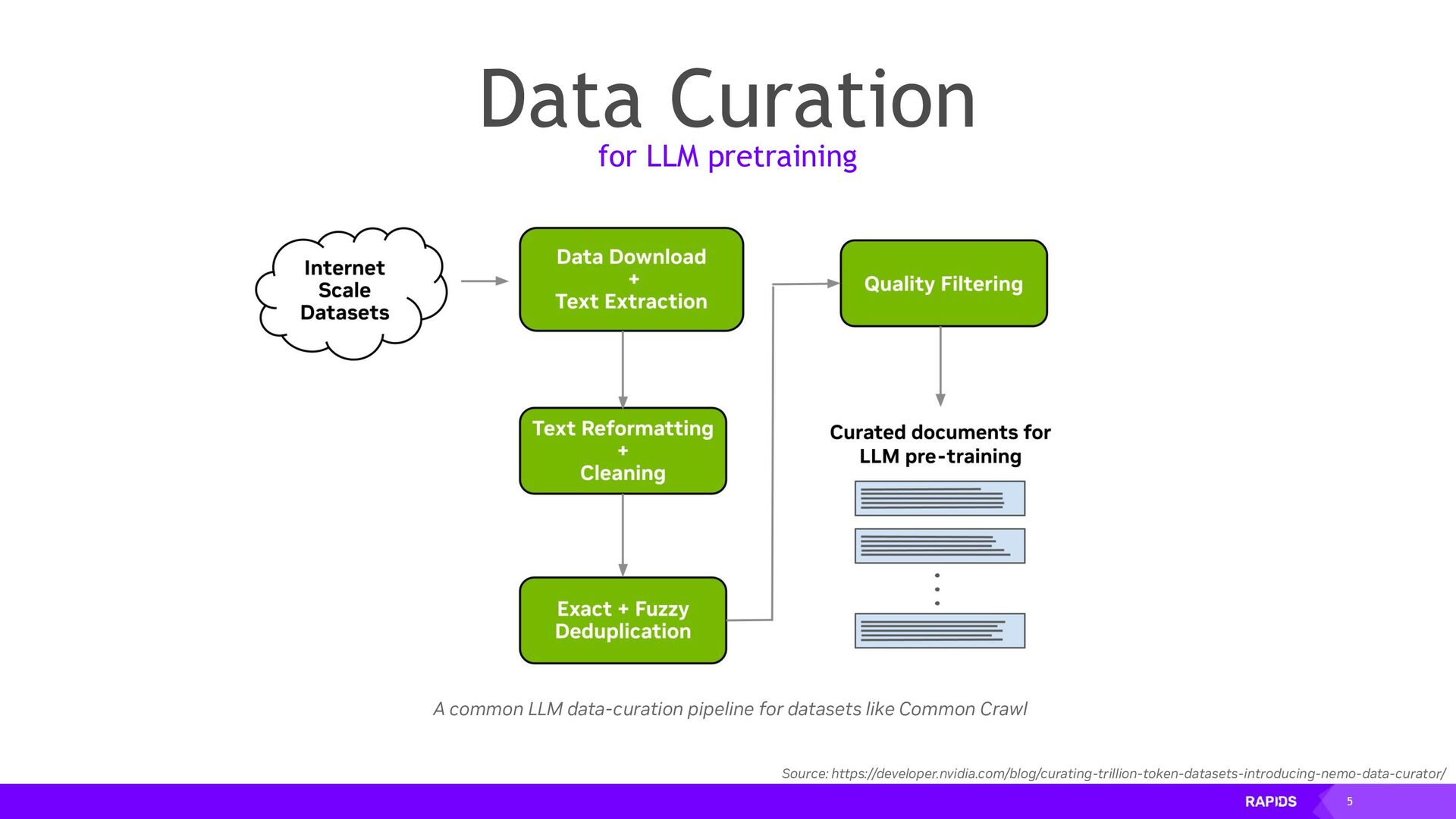
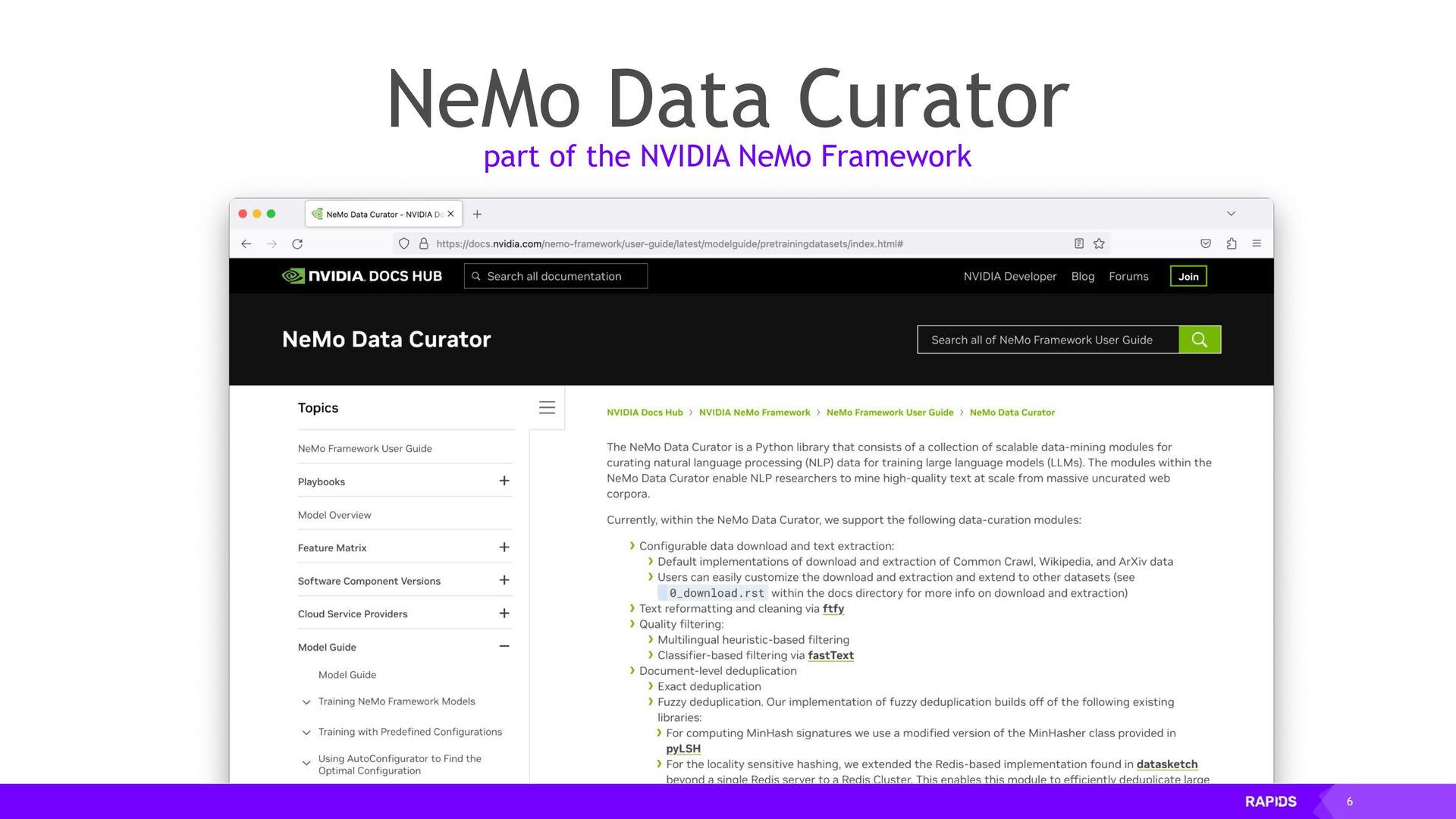
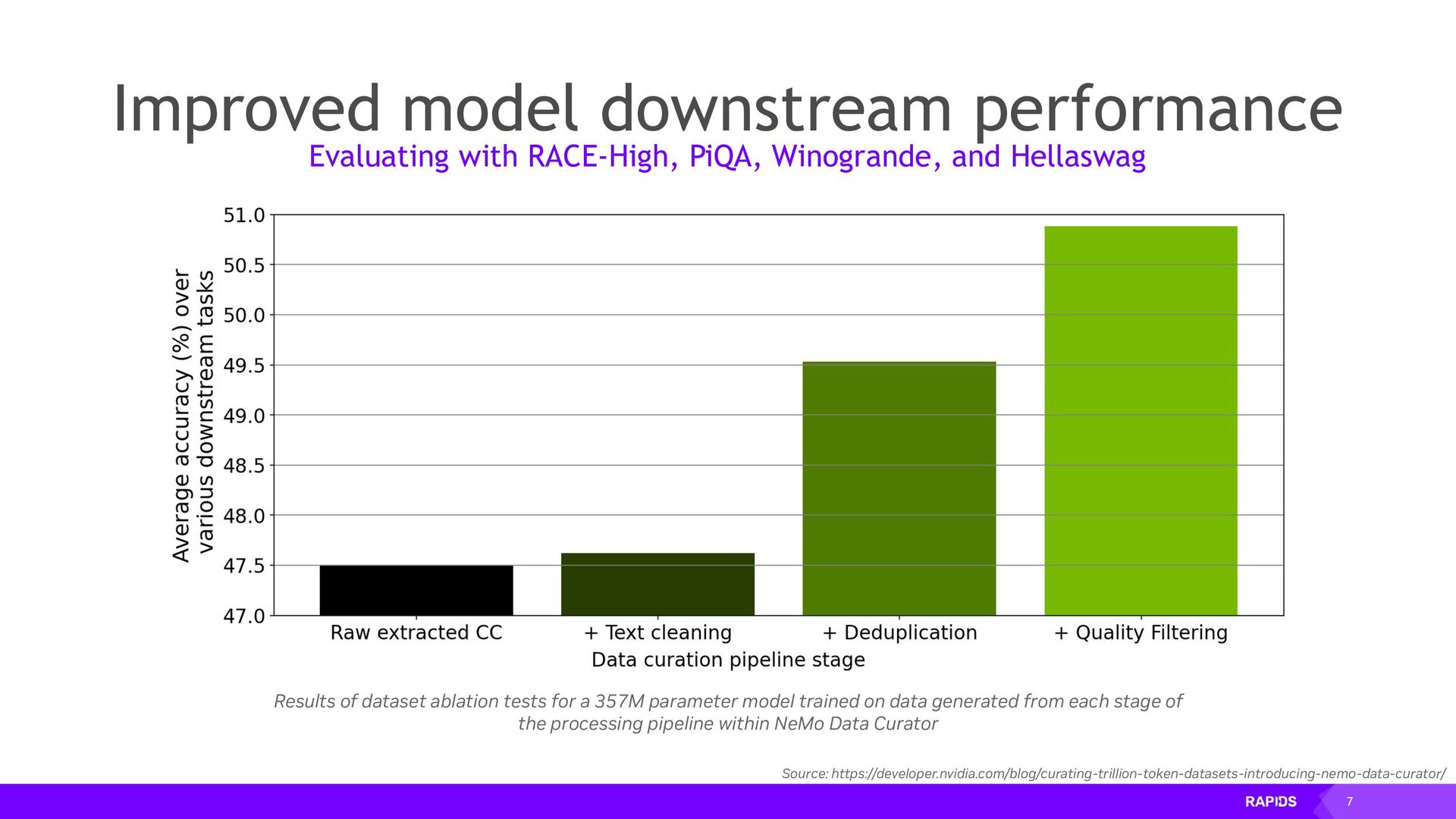
Training Large Language Models (LLMs) requires a vast amount of input data, and the higher the quality of that data the better the model will be at producing useful natural language. NVIDIA NeMo Data Curator is a toolkit built with RAPIDS and Dask for extracting, cleaning, filtering and deduplicating training data for LLMs.
In this session, we will zoom in on one element of LLM pretraining and explore how we can scale out fuzzy deduplication of many terabytes of documents. We can run a distributed Jaccard similarity workload by deploying a RAPIDS accelerated Dask cluster on Kubernetes to remove duplicate documents from our training set.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
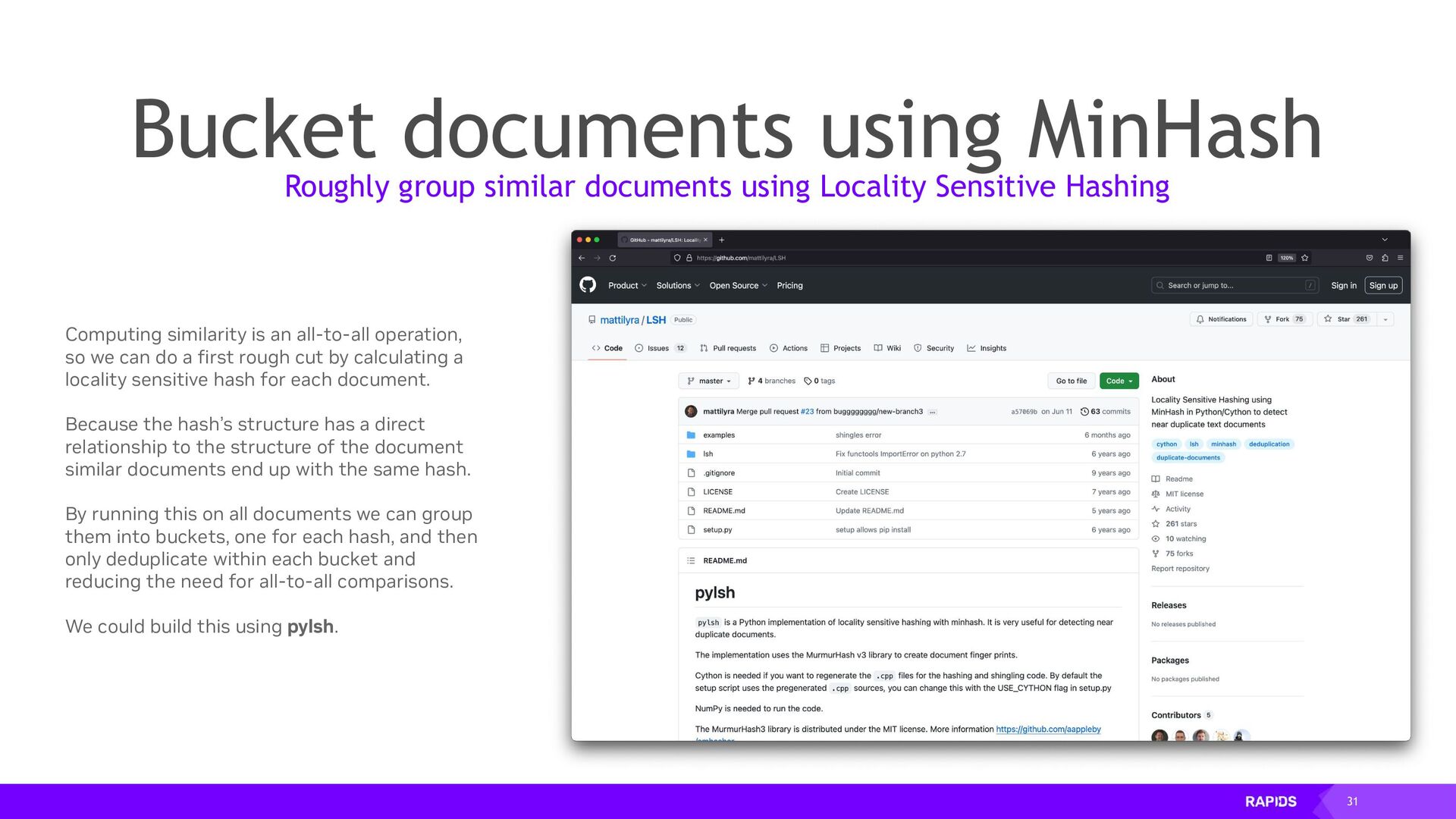{kind=link}
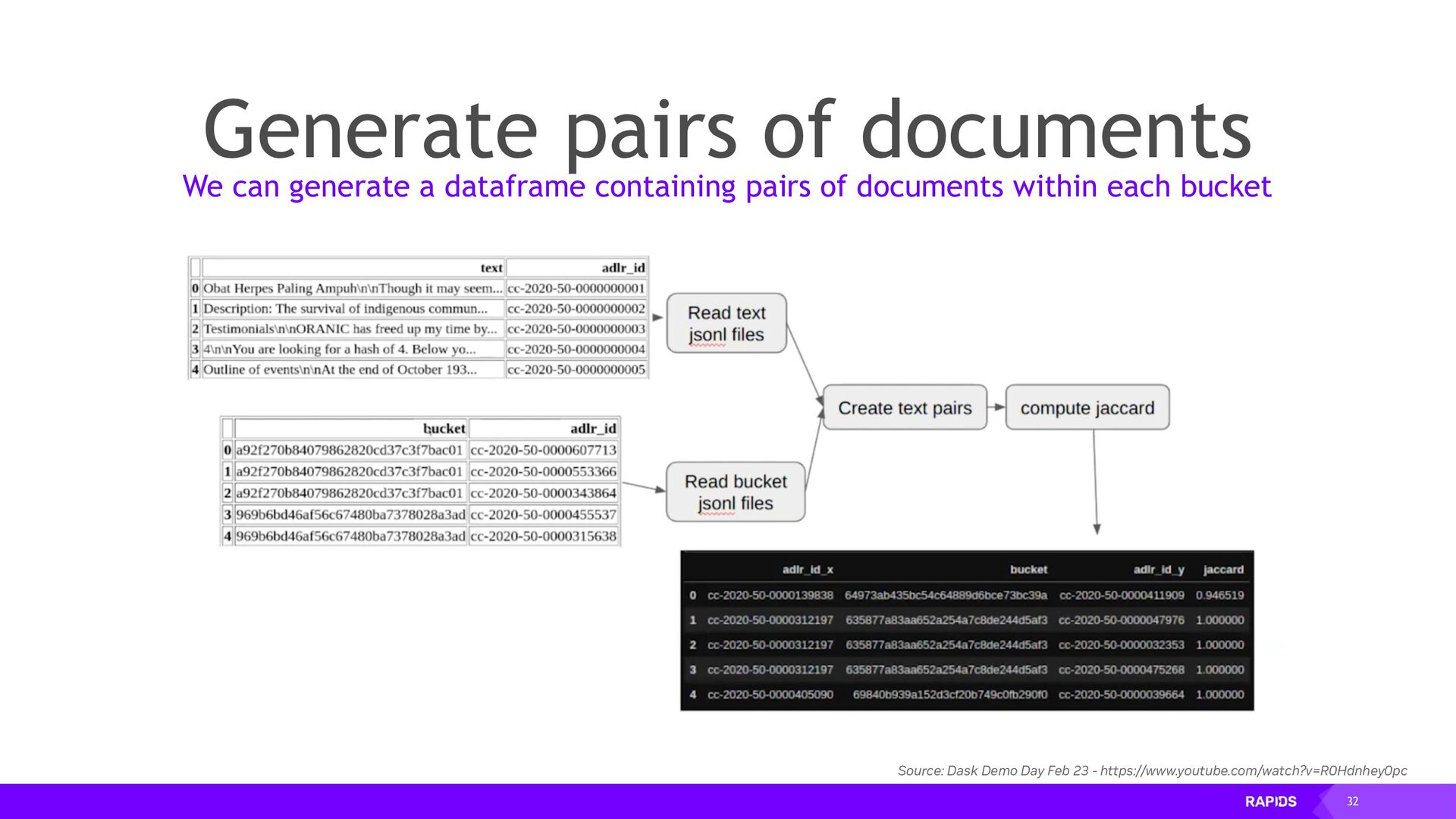{kind=link}
{kind=link}
{kind=link}
{kind=link}
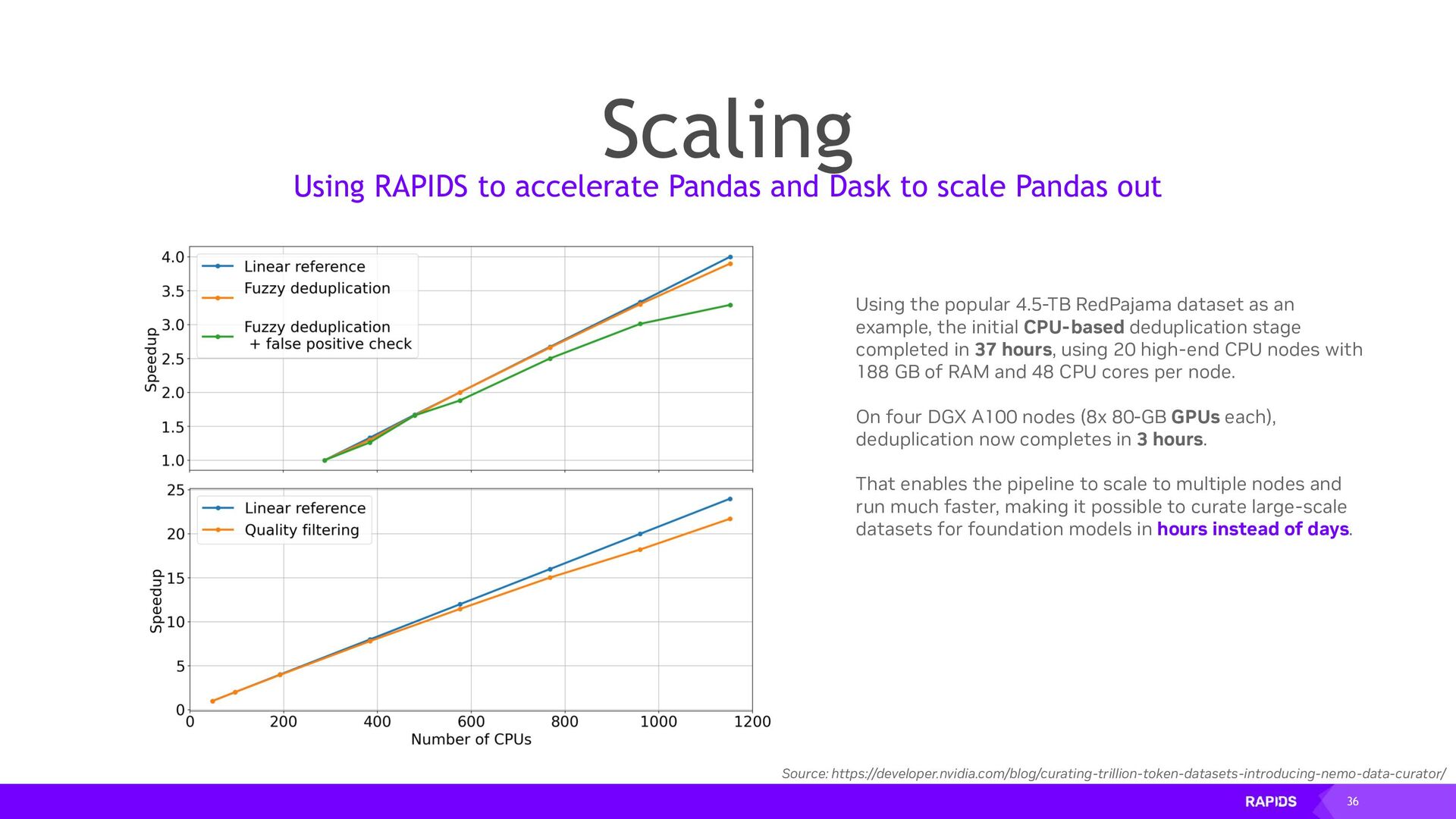{kind=link}
{kind=link}
{kind=link}