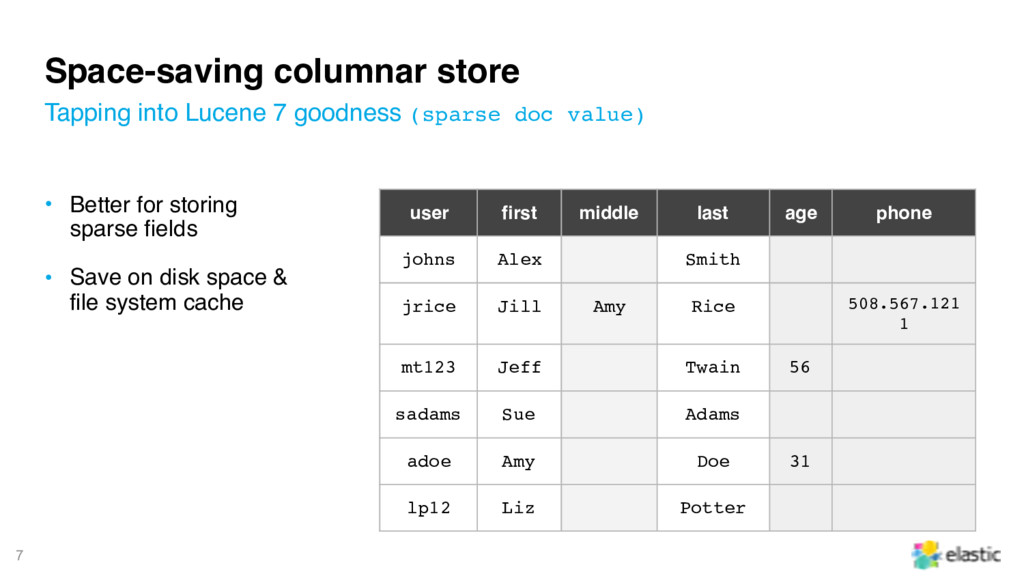
• Save on disk space & file system cache Tapping into Lucene 7 goodness (sparse doc value) user first middle last age phone johns Alex Smith jrice Jill Amy Rice 508.567.121 1 mt123 Jeff Twain 56 sadams Sue Adams adoe Amy Doe 31 lp12 Liz Potter
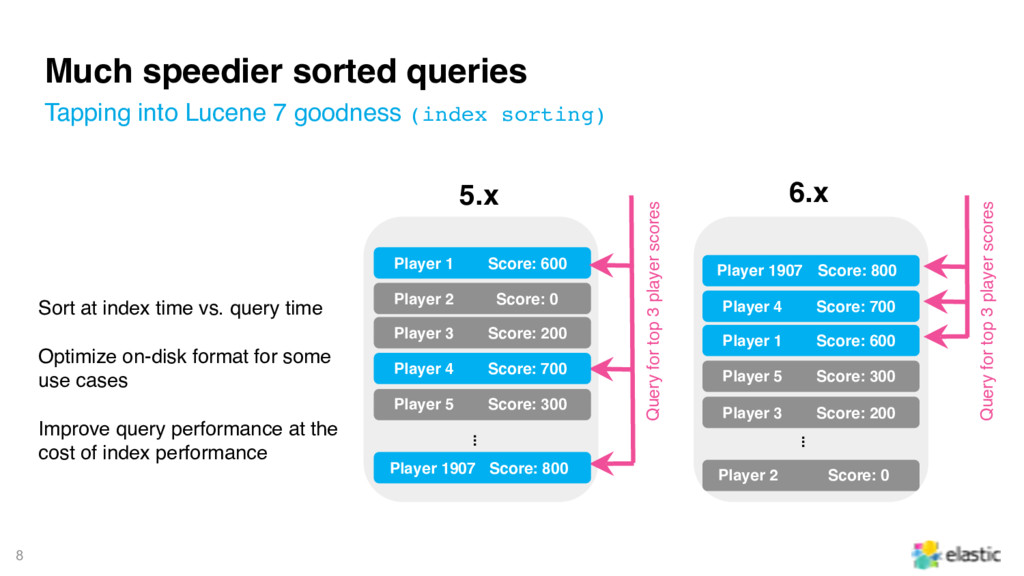
(index sorting) Player 1 Score: 600 5.x Query for top 3 player scores Player 2 Score: 0 Player 3 Score: 200 Player 4 Score: 700 Player 5 Score: 300 Player 1907 Score: 800 ... Query for top 3 player scores ... Player 1907 Score: 800 Player 4 Score: 700 Player 1 Score: 600 Player 5 Score: 300 Player 3 Score: 200 Player 2 Score: 0 6.x Sort at index time vs. query time Optimize on-disk format for some use cases Improve query performance at the cost of index performance
changed documents (instead of file-based recovery) • Fast replica recovery after temporary unavailability (network issues, etc.) • Re-sync on primary failure • Laying foundation for future big league features ‒Cross-datacenter replication ‒Changes API (tbd) New operation-based approach to recovery (sequence numbers)
‒Deprecation logging ‒Upgrade Assistant (UI & APIs) • Refer to Release Notes for complete list • Test, test, test Because major releases is time for major cleanup
• Gradual migration path ‒ 6.0 indices can be created with only one type ‒ Existing 5.x indices using _type will continue to function • Introducing new APIs for type-less operations Say goodbye to _type confusion
_template • Content-Type detection disabled • Set explicit Content-Type in request header • Deprecation of _all • _all can no longer be configured for indices in 6.0 • Use all_fields in query
be reindexed • Re-index into 5.x or 6.0 cluster • Deprecate Groovy, Python, Javascript lang plugin • Rewrite scripts in plainless • Java High Level REST Client • Starting from version 5.6.0 a new Java client has been released.
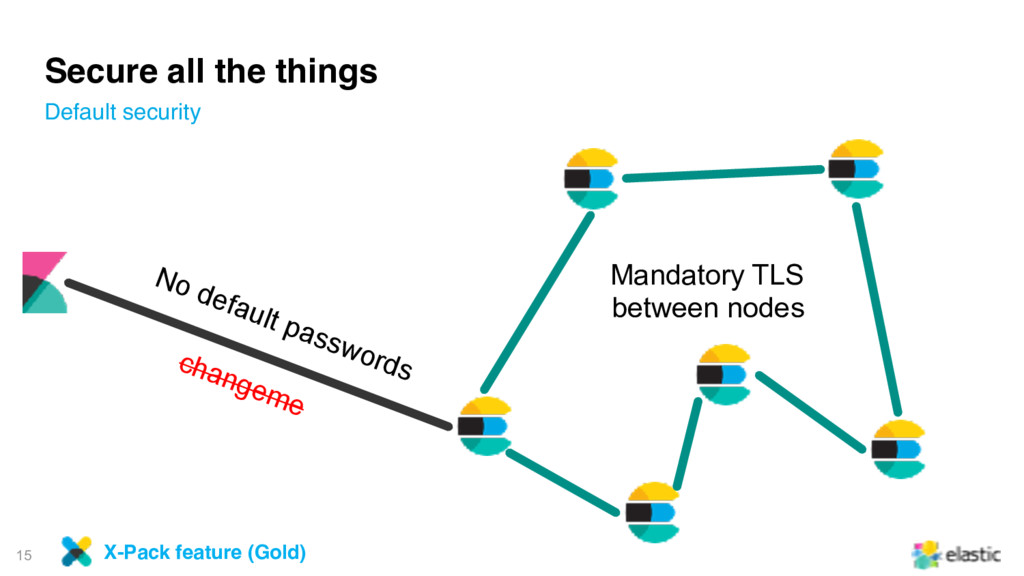
on only the master node • They are executed on nodes which hold shards of the .watches index • Configure all or specific nodes dedicated to watch execution X-Pack feature (Gold)
primary shard is split into some primary shard in new index • Composite Aggregation • Designed to return ALL terms and sorted in ‘natural order’ • Improve indexing throughput • Simple change of _fields metafield • Scripted Similarity • Custom similarity has become much easier
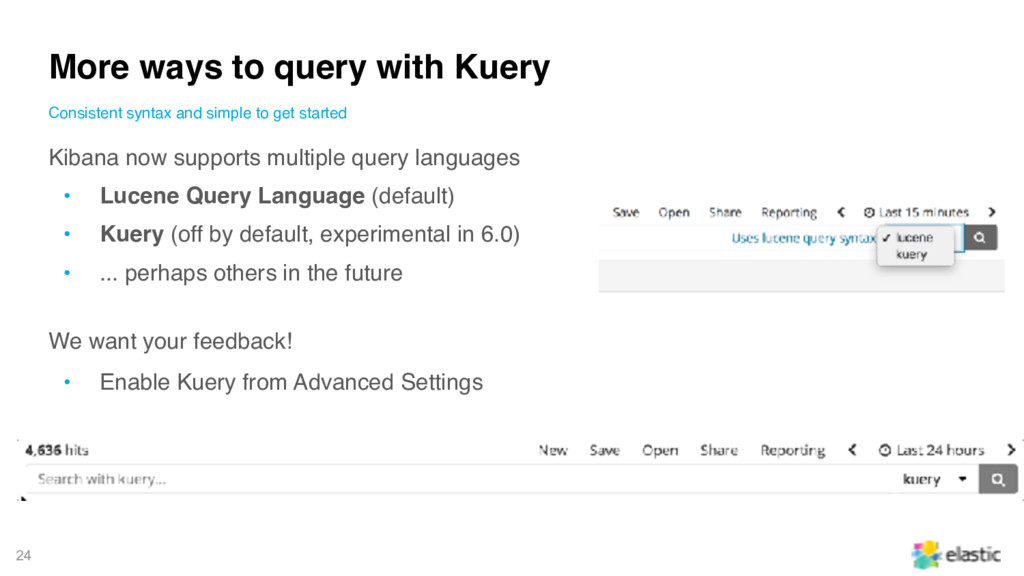
Language (default) • Kuery (off by default, experimental in 6.0) • ... perhaps others in the future We want your feedback! • Enable Kuery from Advanced Settings More ways to query with Kuery Consistent syntax and simple to get started
are built-in Watches for cluster issues • Get e-mails when Cluster Alerts get triggered and resolved • Add admin e-mail in Kibana Advanced Settings X-Pack feature (Gold)
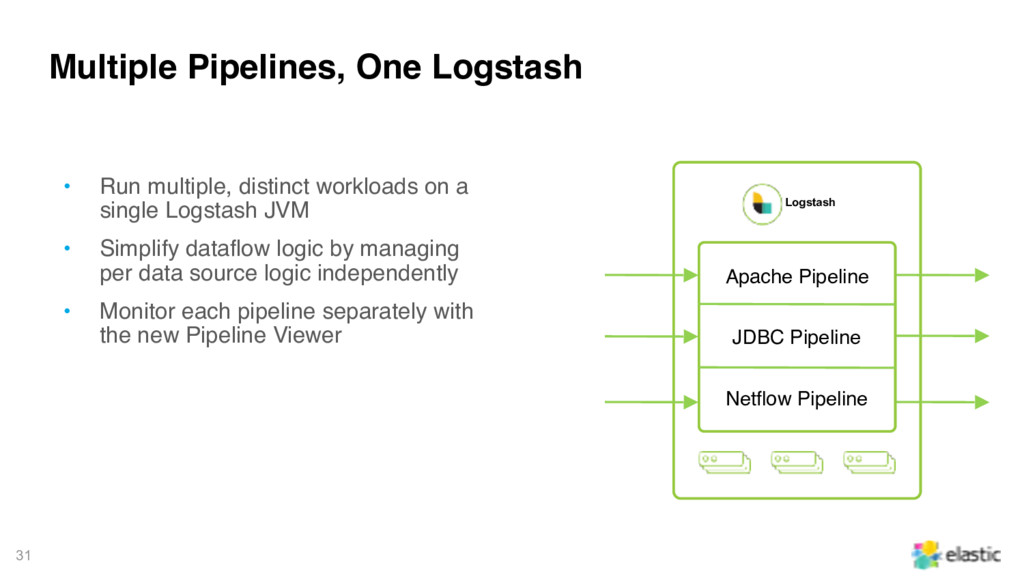
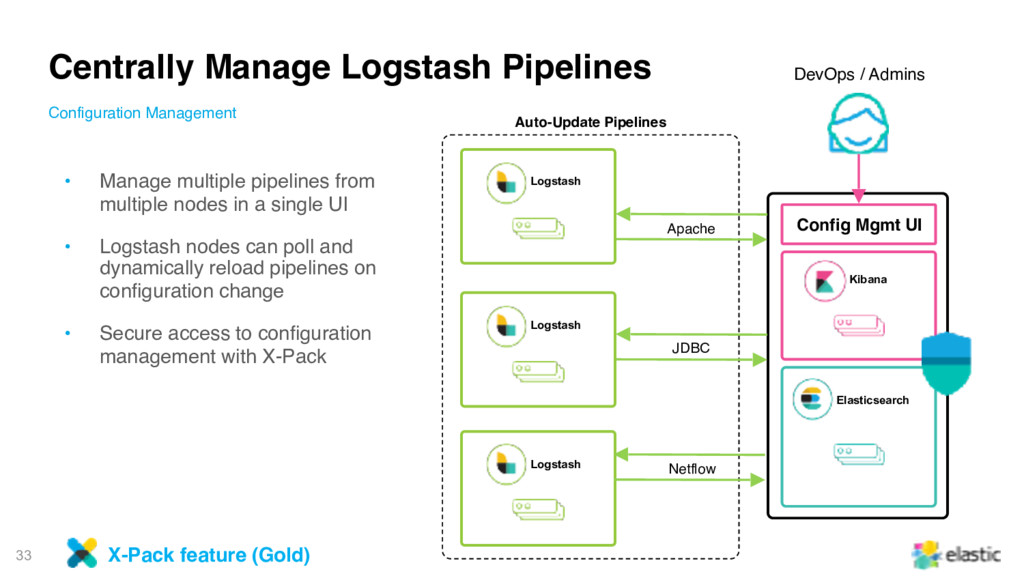
JVM • Simplify dataflow logic by managing per data source logic independently • Monitor each pipeline separately with the new Pipeline Viewer Multiple Pipelines, One Logstash Logstash JDBC Pipeline Netflow Pipeline Apache Pipeline
at the plugin level • Optimize dataflow with better metrics • Integrated with Monitoring UI Zoom in on your Pipelines Pipeline Viewer X-Pack feature (Basic, free)
bytes on network and more. • New processor to add_docker_metadata ‒ Container ID, name, image, labels • New processor to add_kubernetes_metadata ‒ Pod name, pod namespace, container name, pod labels Beats <3 containerization Monitor your Docker and Kubernetes deployments with ease
Auditbeat subscribes to the kernel directly • Reuse auditd rule formats (no need to learn new rule formats) • Plus, file integrity checks on Linux, macOS, and Windows ‒ Watch files or directories (non-recursively) for changes ‒ Report file metadata and MD5, SHA1, SHA256 hashes on changes Auditbeat - a simpler way to track audit logs An alternative to auditd on Linux
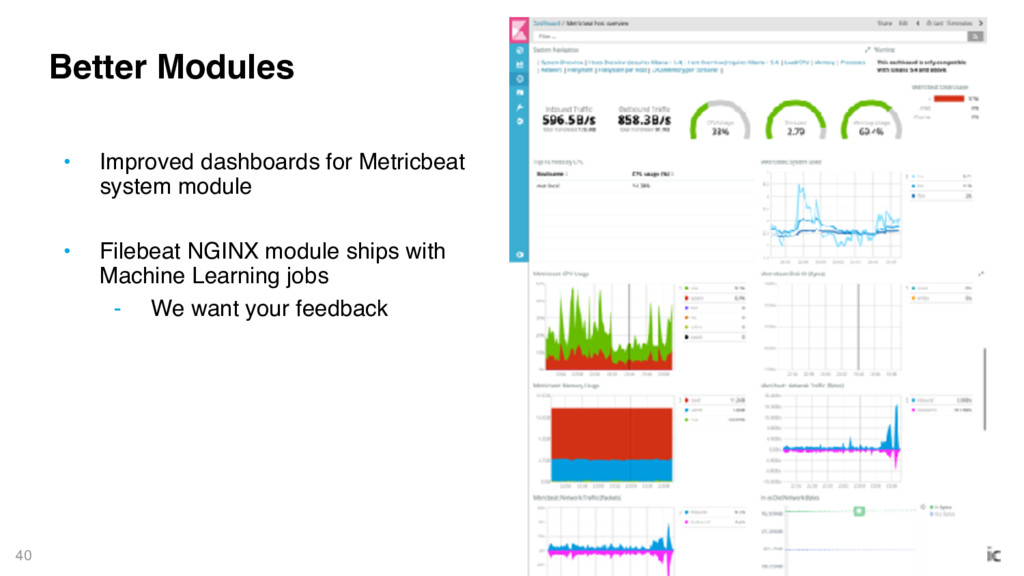
commands and configuration files ‒ module.d directory ‒ ./metricbeat module enable system ‒ Dashboards are easier to load and packaged with the Beat And moar awesome all around
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}